This post is co-authored by Marios Skevofylakas, Jason Ramchandani and Haykaz Aramyan from Refinitiv, An LSEG Business.
Financial service providers often need to identify relevant news, analyze it, extract insights, and take actions in real time, like trading specific instruments (such as commodities, shares, funds) based on additional information or context of the news item. One such additional piece of information (which we use as an example in this post) is the sentiment of the news.
Refinitiv Data (RD) Libraries provide a comprehensive set of interfaces for uniform access to the Refinitiv Data Catalogue. The library offers multiple layers of abstraction providing different styles and programming techniques suitable for all developers, from low-latency, real-time access to batch ingestions of Refinitiv data.
In this post, we present a prototype AWS architecture that ingests our news feeds using RD Libraries and enhances them with machine learning (ML) model predictions using Amazon SageMaker, a fully managed ML service from AWS.
In an effort to design a modular architecture that could be used in a variety of use cases, like sentiment analysis, named entity recognition, and more, regardless of the ML model used for enhancement, we decided to focus on the real-time space. The reason for this decision is that real-time use cases are generally more complex and that the same architecture can also be used, with minimal adjustments, for batch inference. In our use case, we implement an architecture that ingests our real-time news feed, calculates sentiment on each news headline using ML, and re-serves the AI enhanced feed through a publisher/subscriber architecture.
Moreover, to present a comprehensive and reusable way to productionize ML models by adopting MLOps practices, we introduce the concept of infrastructure as code (IaC) during the entire MLOps lifecycle of the prototype. By using Terraform and a single entry point configurable script, we are able to instantiate the entire infrastructure, in production mode, on AWS in just a few minutes.
In this solution, we don’t address the MLOps aspect of the development, training, and deployment of the individual models. If you’re interested in learning more on this, refer to MLOps foundation roadmap for enterprises with Amazon SageMaker, which explains in detail a framework for model building, training, and deployment following best practices.
Solution overview
In this prototype, we follow a fully automated provisioning methodology in accordance with IaC best practices. IaC is the process of provisioning resources programmatically using automated scripts rather than using interactive configuration tools. Resources can be both hardware and needed software. In our case, we use Terraform to accomplish the implementation of a single configurable entry point that can automatically spin up the entire infrastructure we need, including security and access policies, as well as automated monitoring. With this single entry point that triggers a collection of Terraform scripts, one per service or resource entity, we can fully automate the lifecycle of all or parts of the components of the architecture, allowing us to implement granular control both on the DevOps as well as the MLOps side. After Terraform is correctly installed and integrated with AWS, we can replicate most operations that can be done on the AWS service dashboards.
The following diagram illustrates our solution architecture.
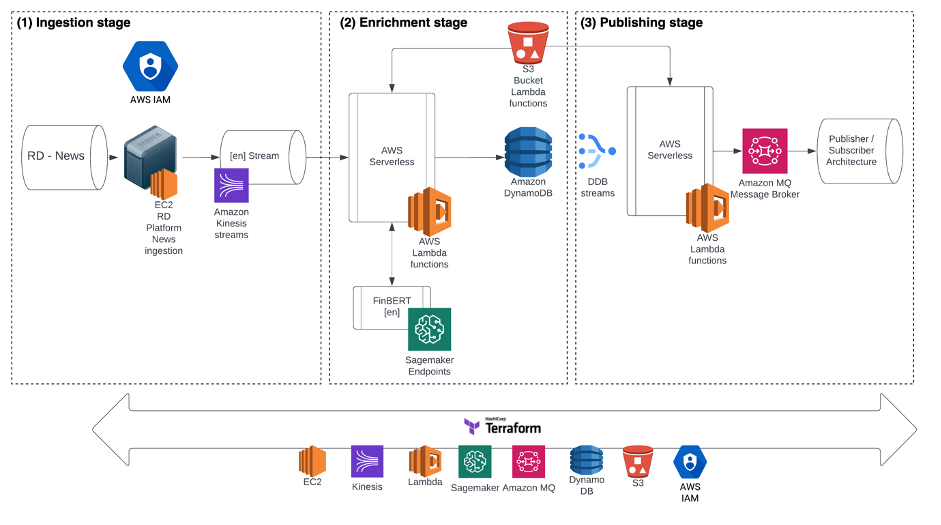
The architecture consists of three stages: ingestion, enrichment, and publishing. During the first stage, the real-time feeds are ingested on an Amazon Elastic Compute Cloud (Amazon EC2) instance that is created through a Refinitiv Data Library-ready AMI. The instance also connects to a data stream via Amazon Kinesis Data Streams, which triggers an AWS Lambda function.
In the second stage, the Lambda function that is triggered from Kinesis Data Streams connects to and sends the news headlines to a SageMaker FinBERT endpoint, which returns the calculated sentiment for the news item. This calculated sentiment is the enrichment in the real-time data that the Lambda function then wraps the news item with and stores in an Amazon DynamoDB table.
In the third stage of the architecture, a DynamoDB stream triggers a Lambda function on new item inserts, which is integrated with an Amazon MQ server running RabbitMQ, which re-serves the AI enhanced stream.
The decision on this three-stage engineering design, rather than the first Lambda layer directly communicating with the Amazon MQ server or implementing more functionality in the EC2 instance, was made to enable exploration of more complex, less coupled AI design architectures in the future.
Building and deploying the prototype
We present this prototype in a series of three detailed blueprints. In each blueprint and for every service used, you will find overviews and relevant information on its technical implementations as well as Terraform scripts that allow you to automatically start, configure, and integrate the service with the rest of the structure. At the end of each blueprint, you will find instructions on how to make sure that everything is working as expected up to each stage. The blueprints are as follows:
To start the implementation of this prototype, we suggest creating a new Python environment dedicated to it and installing the necessary packages and tools separately from other environments you may have. To do so, create and activate the new environment in Anaconda using the following commands:
We’re now ready to install the AWS Command Line Interface (AWS CLI) toolset that will allow us to build all the necessary programmatic interactions in and between AWS services:
Now that the AWS CLI is installed, we need to install Terraform. HashiCorp provides Terraform with a binary installer, which you can download and install.
After you have both tools installed, ensure that they properly work using the following commands:
You’re now ready to follow the detailed blueprints on each of the three stages of the implementation.
This blueprint represents the initial stages of the architecture that allow us to ingest the real-time news feeds. It consists of the following components:
- Amazon EC2 preparing your instance for RD News ingestion – This section sets up an EC2 instance in a way that it enables the connection to the RD Libraries API and the real-time stream. We also show how to save the image of the created instance to ensure its reusability and scalability.
- Real-time news ingestion from Amazon EC2 – A detailed implementation of the configurations needed to enable Amazon EC2 to connect the RD Libraries as well as the scripts to start the ingestion.
- Creating and launching Amazon EC2 from the AMI – Launch a new instance by simultaneously transferring ingestion files to the newly created instance, all automatically using Terraform.
- Creating a Kinesis data stream – This section provides an overview of Kinesis Data Streams and how to set up a stream on AWS.
- Connecting and pushing data to Kinesis – Once the ingestion code is working, we need to connect it and send data to a Kinesis stream.
- Testing the prototype so far – We use Amazon CloudWatch and command line tools to verify that the prototype is working up to this point and that we can continue to the next blueprint. The log of ingested data should look like the following screenshot.

In this second blueprint, we focus on the main part of the architecture: the Lambda function that ingests and analyzes the news item stream, attaches the AI inference to it, and stores it for further use. It includes the following components:
- Lambda – Define a Terraform Lambda configuration allowing it to connect to a SageMaker endpoint.
- Amazon S3 – To implement Lambda, we need to upload the appropriate code to Amazon Simple Storage Service (Amazon S3) and allow the Lambda function to ingest it in its environment. This section describes how we can use Terraform to accomplish that.
- Implementing the Lambda function: Step 1, Handling the Kinesis event – In this section, we start building the Lambda function. Here, we build the Kinesis data stream response handler part only.
- SageMaker – In this prototype, we use a pre-trained Hugging Face model that we store into a SageMaker endpoint. Here, we present how this can be achieved using Terraform scripts and how the appropriate integrations take place to allow SageMaker endpoints and Lambda functions work together.
- At this point, you can instead use any other model that you have developed and deployed behind a SageMaker endpoint. Such a model could provide a different enhancement to the original news data, based on your needs. Optionally, this can be extrapolated to multiple models for multiple enhancements if such exist. Thanks to the rest of the architecture, any such models will enrich your data sources in real time.
- Building the Lambda function: Step 2, Invoking the SageMaker endpoint – In this section, we build up our original Lambda function by adding the SageMaker block to get a sentiment enhanced news headline by invoking the SageMaker endpoint.
- DynamoDB – Finally, when the AI inference is in the memory of the Lambda function, it re-bundles the item and sends it to a DynamoDB table for storage. Here, we discuss both the appropriate Python code needed to accomplish that, as well as the necessary Terraform scripts that enable these interactions.
- Building the Lambda function: Step 3, Pushing enhanced data to DynamoDB – Here, we continue building up our Lambda function by adding the last part that creates an entry in the Dynamo table.
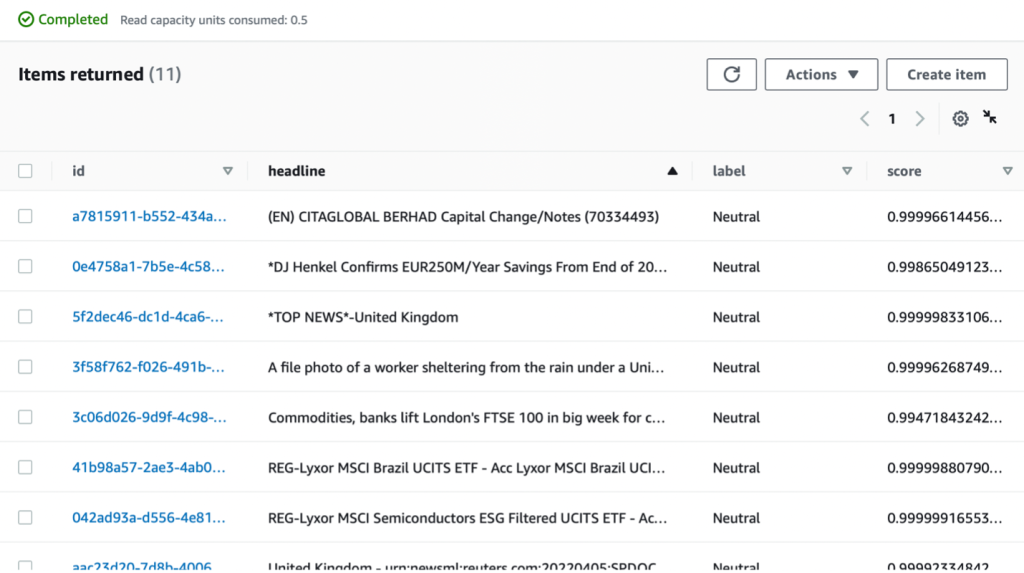
- Testing the prototype so far – We can navigate to the DynamoDB table on the DynamoDB console to verify that our enhancements are appearing in the table.
This third Blueprint finalizes this prototype. It focuses on redistributing the newly created, AI enhanced data item to a RabbitMQ server in Amazon MQ, allowing consumers to connect and retrieve the enhanced news items in real time. It includes the following components:
- DynamoDB Streams – When the enhanced news item is in DynamoDB, we set up an event getting triggered that can then be captured from the appropriate Lambda function.
- Writing the Lambda producer – This Lambda function captures the event and acts as a producer of the RabbitMQ stream. This new function introduces the concept of Lambda layers as it uses Python libraries to implement the producer functionality.
- Amazon MQ and RabbitMQ consumers – The final step of the prototype is setting up the RabbitMQ service and implementing an example consumer that will connect to the message stream and receive the AI enhanced news items.
- Final test of the prototype – We use an end-to-end process to verify that the prototype is fully working, from ingestion to re-serving and consuming the new AI-enhanced stream.
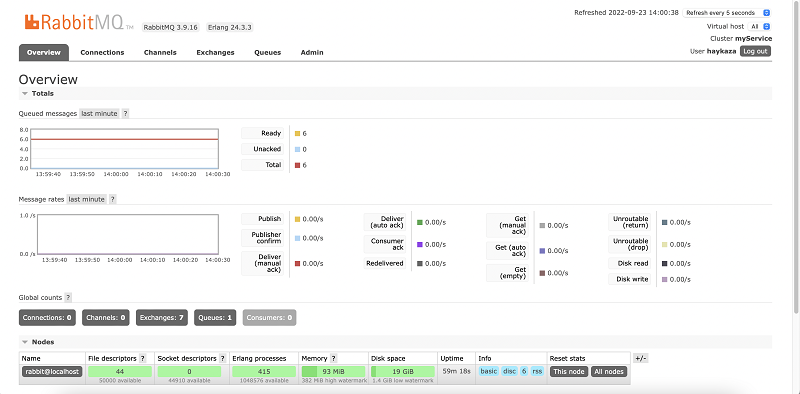
At this stage, you can validate that everything has been working by navigating to the RabbitMQ dashboard, as shown in the following screenshot.
In the final blueprint, you also find a detailed test vector to make sure that the entire architecture is behaving as planned.
Conclusion
In this post, we shared a solution using ML on the cloud with AWS services like SageMaker (ML), Lambda (serverless), and Kinesis Data Streams (streaming) to enrich streaming news data provided by Refinitiv Data Libraries. The solution adds a sentiment score to news items in real time and scales the infrastructure using code.
The benefit of this modular architecture is that you can reuse it with your own model to perform other types of data augmentation, in a serverless, scalable, and cost-efficient way that can be applied on top of Refinitiv Data Library. This can add value for trading/investment/risk management workflows.
If you have any comments or questions, please leave them in the comments section.
Related Information
About the Authors
 Marios Skevofylakas comes from a financial services, investment banking and consulting technology background. He holds an engineering Ph.D. in Artificial Intelligence and an M.Sc. in Machine Vision. Throughout his career, he has participated in numerous multidisciplinary AI and DLT projects. He is currently a Developer Advocate with Refinitiv, an LSEG business, focusing on AI and Quantum applications in financial services.
Marios Skevofylakas comes from a financial services, investment banking and consulting technology background. He holds an engineering Ph.D. in Artificial Intelligence and an M.Sc. in Machine Vision. Throughout his career, he has participated in numerous multidisciplinary AI and DLT projects. He is currently a Developer Advocate with Refinitiv, an LSEG business, focusing on AI and Quantum applications in financial services.
 Jason Ramchandani has worked at Refinitiv, an LSEG Business, for 8 years as Lead Developer Advocate helping to build their Developer Community. Previously he has worked in financial markets for over 15 years with a quant background in the equity/equity-linked space at Okasan Securities, Sakura Finance and Jefferies LLC. His alma mater is UCL.
Jason Ramchandani has worked at Refinitiv, an LSEG Business, for 8 years as Lead Developer Advocate helping to build their Developer Community. Previously he has worked in financial markets for over 15 years with a quant background in the equity/equity-linked space at Okasan Securities, Sakura Finance and Jefferies LLC. His alma mater is UCL.
 Haykaz Aramyan comes from a finance and technology background. He holds a Ph.D. in Finance, and an M.Sc. in Finance, Technology and Policy. Through 10 years of professional experience Haykaz worked on several multidisciplinary projects involving pension, VC funds and technology startups. He is currently a Developer Advocate with Refinitiv, An LSEG Business, focusing on AI applications in financial services.
Haykaz Aramyan comes from a finance and technology background. He holds a Ph.D. in Finance, and an M.Sc. in Finance, Technology and Policy. Through 10 years of professional experience Haykaz worked on several multidisciplinary projects involving pension, VC funds and technology startups. He is currently a Developer Advocate with Refinitiv, An LSEG Business, focusing on AI applications in financial services.
 Georgios Schinas is a Senior Specialist Solutions Architect for AI/ML in the EMEA region. He is based in London and works closely with customers in UK and Ireland. Georgios helps customers design and deploy machine learning applications in production on AWS with a particular interest in MLOps practices and enabling customers to perform machine learning at scale. In his spare time, he enjoys traveling, cooking and spending time with friends and family.
Georgios Schinas is a Senior Specialist Solutions Architect for AI/ML in the EMEA region. He is based in London and works closely with customers in UK and Ireland. Georgios helps customers design and deploy machine learning applications in production on AWS with a particular interest in MLOps practices and enabling customers to perform machine learning at scale. In his spare time, he enjoys traveling, cooking and spending time with friends and family.
 Muthuvelan Swaminathan is an Enterprise Solutions Architect based out of New York. He works with enterprise customers providing architectural guidance in building resilient, cost-effective, innovative solutions that address their business needs and help them execute at scale using AWS products and services.
Muthuvelan Swaminathan is an Enterprise Solutions Architect based out of New York. He works with enterprise customers providing architectural guidance in building resilient, cost-effective, innovative solutions that address their business needs and help them execute at scale using AWS products and services.
 Mayur Udernani leads AWS AI & ML business with commercial enterprises in UK & Ireland. In his role, Mayur spends majority of his time with customers and partners to help create impactful solutions that solve the most pressing needs of a customer or for a wider industry leveraging AWS Cloud, AI & ML services. Mayur lives in the London area. He has an MBA from Indian Institute of Management and Bachelors in Computer Engineering from Mumbai University.
Mayur Udernani leads AWS AI & ML business with commercial enterprises in UK & Ireland. In his role, Mayur spends majority of his time with customers and partners to help create impactful solutions that solve the most pressing needs of a customer or for a wider industry leveraging AWS Cloud, AI & ML services. Mayur lives in the London area. He has an MBA from Indian Institute of Management and Bachelors in Computer Engineering from Mumbai University.
- SEO Powered Content & PR Distribution. Get Amplified Today.
- Platoblockchain. Web3 Metaverse Intelligence. Knowledge Amplified. Access Here.
- Source: https://aws.amazon.com/blogs/machine-learning/enriching-real-time-news-streams-with-the-refinitiv-data-library-aws-services-and-amazon-sagemaker/

