Konversationsassistenten mit künstlicher Intelligenz (KI) sind so konzipiert, dass sie präzise Antworten in Echtzeit liefern, indem sie Anfragen intelligent an die am besten geeigneten KI-Funktionen weiterleiten. Mit AWS generative KI-Dienste wie Amazonas Grundgesteinkönnen Entwickler Systeme erstellen, die Benutzeranfragen kompetent verwalten und darauf reagieren. Amazon Bedrock ist ein vollständig verwalteter Dienst, der eine Auswahl leistungsstarker Foundation-Modelle (FMs) von führenden KI-Unternehmen wie AI21 Labs, Anthropic, Cohere, Meta, Stability AI und Amazon über eine einzige API sowie eine breite Palette von bietet Funktionen, die Sie zum Erstellen generativer KI-Anwendungen mit Sicherheit, Datenschutz und verantwortungsvoller KI benötigen.
In diesem Beitrag werden zwei Hauptansätze für die Entwicklung von KI-Assistenten bewertet: die Verwendung verwalteter Dienste wie z Agenten für Amazon Bedrockund den Einsatz von Open-Source-Technologien wie LangChain. Wir erkunden die Vorteile und Herausforderungen jedes einzelnen, damit Sie den für Ihre Bedürfnisse am besten geeigneten Weg wählen können.
Was ist ein KI-Assistent?
Ein KI-Assistent ist ein intelligentes System, das Anfragen in natürlicher Sprache versteht und mit verschiedenen Tools, Datenquellen und APIs interagiert, um Aufgaben auszuführen oder Informationen im Namen des Benutzers abzurufen. Effektive KI-Assistenten verfügen über die folgenden Schlüsselfähigkeiten:
- Verarbeitung natürlicher Sprache (NLP) und Gesprächsfluss
- Integration von Wissensdatenbanken und semantische Suche, um relevante Informationen basierend auf den Nuancen des Konversationskontexts zu verstehen und abzurufen
- Ausführen von Aufgaben wie Datenbankabfragen und benutzerdefinierten AWS Lambda Funktionen
- Bearbeitung von Fachgesprächen und Benutzeranfragen
Den Nutzen von KI-Assistenten demonstrieren wir am Beispiel der Geräteverwaltung im Internet of Things (IoT). In diesem Anwendungsfall kann KI Technikern dabei helfen, Maschinen mithilfe von Befehlen, die Daten abrufen oder Aufgaben automatisieren, effizient zu verwalten und so die Abläufe in der Fertigung zu rationalisieren.
Agents for Amazon Bedrock-Ansatz
Agenten für Amazon Bedrock ermöglicht Ihnen die Erstellung generativer KI-Anwendungen, die mehrstufige Aufgaben in den Systemen und Datenquellen eines Unternehmens ausführen können. Es bietet die folgenden Hauptfunktionen:
- Automatische Erstellung von Eingabeaufforderungen aus Anweisungen, API-Details und Datenquelleninformationen, wodurch wochenlanger Aufwand für die schnelle Entwicklung eingespart wird
- Retrieval Augmented Generation (RAG), um Agenten sicher mit den Datenquellen eines Unternehmens zu verbinden und relevante Antworten bereitzustellen
- Orchestrierung und Ausführung mehrstufiger Aufgaben durch Aufteilen von Anforderungen in logische Sequenzen und Aufrufen erforderlicher APIs
- Einblick in die Argumentation des Agenten durch einen Chain-of-Think (CoT)-Trace, der die Fehlerbehebung und Steuerung des Modellverhaltens ermöglicht
- Prompt-Engineering-Fähigkeiten zur Änderung der automatisch generierten Prompt-Vorlage für eine bessere Kontrolle über Agenten
Sie können Agenten für Amazon Bedrock und verwenden Wissensdatenbanken für Amazon Bedrock um KI-Assistenten für komplexe Routing-Anwendungsfälle zu erstellen und bereitzustellen. Sie bieten Entwicklern und Organisationen einen strategischen Vorteil, indem sie das Infrastrukturmanagement vereinfachen, die Skalierbarkeit verbessern, die Sicherheit verbessern und undifferenzierten Arbeitsaufwand reduzieren. Sie ermöglichen außerdem einen einfacheren Code auf der Anwendungsebene, da die Routing-Logik, die Vektorisierung und der Speicher vollständig verwaltet werden.
Lösungsüberblick
Diese Lösung führt einen dialogorientierten KI-Assistenten ein, der auf die Verwaltung und den Betrieb von IoT-Geräten zugeschnitten ist, wenn Claude v2.1 von Anthropic auf Amazon Bedrock verwendet wird. Die Kernfunktionalität des KI-Assistenten wird durch einen umfassenden Befehlssatz geregelt, der als a bezeichnet wird Systemaufforderung, das seine Fähigkeiten und Fachgebiete beschreibt. Diese Anleitung stellt sicher, dass der KI-Assistent ein breites Aufgabenspektrum bewältigen kann, von der Verwaltung von Geräteinformationen bis hin zur Ausführung von Betriebsbefehlen.
Ausgestattet mit diesen Funktionen, wie in der Systemaufforderung beschrieben, folgt der KI-Assistent einem strukturierten Arbeitsablauf, um Benutzerfragen zu beantworten. Die folgende Abbildung bietet eine visuelle Darstellung dieses Workflows und veranschaulicht jeden Schritt von der ersten Benutzerinteraktion bis zur endgültigen Antwort.

Der Workflow besteht aus folgenden Schritten:
- Der Prozess beginnt, wenn ein Benutzer den Assistenten auffordert, eine Aufgabe auszuführen. Fragen Sie beispielsweise nach den maximalen Datenpunkten für ein bestimmtes IoT-Gerät
device_xxx. Diese Texteingabe wird erfasst und an den KI-Assistenten gesendet. - Der KI-Assistent interpretiert die Texteingabe des Benutzers. Es nutzt den bereitgestellten Gesprächsverlauf, Aktionsgruppen und Wissensdatenbanken, um den Kontext zu verstehen und die notwendigen Aufgaben zu bestimmen.
- Nachdem die Absicht des Benutzers analysiert und verstanden wurde, definiert der KI-Assistent Aufgaben. Dies basiert auf den Anweisungen, die der Assistent entsprechend der Systemaufforderung und den Benutzereingaben interpretiert.
- Die Aufgaben werden dann über eine Reihe von API-Aufrufen ausgeführt. Dies geschieht mit Reagieren Eingabeaufforderung, die die Aufgabe in eine Reihe von Schritten unterteilt, die nacheinander verarbeitet werden:
- Für die Überprüfung der Gerätemetriken verwenden wir die
check-device-metricsAktionsgruppe, die einen API-Aufruf an Lambda-Funktionen beinhaltet, die dann eine Abfrage durchführen Amazonas Athena für die angeforderten Daten. - Für direkte Geräteaktionen wie Starten, Stoppen oder Neustarten verwenden wir die
action-on-deviceAktionsgruppe, die eine Lambda-Funktion aufruft. Diese Funktion initiiert einen Prozess, der Befehle an das IoT-Gerät sendet. Für diesen Beitrag sendet die Lambda-Funktion Benachrichtigungen mit Einfacher Amazon-E-Mail-Dienst (Amazon-SES). - Wir verwenden Wissensdatenbanken für Amazon Bedrock, um historische Daten abzurufen, die als Einbettungen in gespeichert sind Amazon OpenSearch-Dienst Vektordatenbank.
- Für die Überprüfung der Gerätemetriken verwenden wir die
- Nachdem die Aufgaben abgeschlossen sind, wird die endgültige Antwort von Amazon Bedrock FM generiert und an den Benutzer zurückgesendet.
- Agenten für Amazon Bedrock speichern Informationen automatisch mithilfe einer zustandsbehafteten Sitzung, um die gleiche Konversation aufrechtzuerhalten. Der Status wird nach Ablauf eines konfigurierbaren Leerlauf-Timeouts gelöscht.
Technische Übersicht
Das folgende Diagramm veranschaulicht die Architektur zur Bereitstellung eines KI-Assistenten mit Agents for Amazon Bedrock.
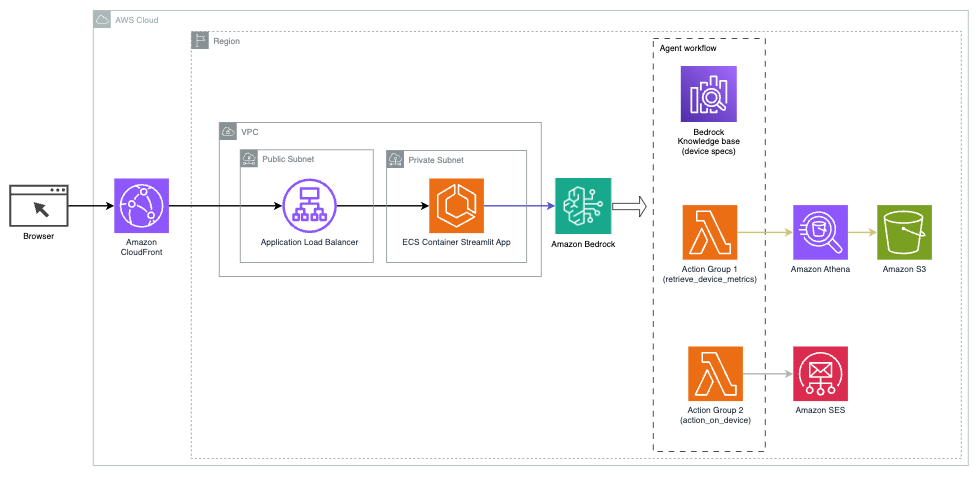
Es besteht aus folgenden Schlüsselkomponenten:
- Konversationsschnittstelle – Die Konversationsschnittstelle nutzt Streamlit, eine Open-Source-Python-Bibliothek, die die Erstellung benutzerdefinierter, optisch ansprechender Web-Apps für maschinelles Lernen (ML) und Datenwissenschaft vereinfacht. Es wird gehostet auf Amazon Elastic Container-Service (Amazon ECS) mit AWS Fargate, und der Zugriff erfolgt über einen Application Load Balancer. Sie können Fargate mit Amazon ECS ausführen Behälter ohne Server, Cluster oder virtuelle Maschinen verwalten zu müssen.
- Agenten für Amazon Bedrock – Agents for Amazon Bedrock vervollständigt die Benutzeranfragen durch eine Reihe von Argumentationsschritten und entsprechenden darauf basierenden Aktionen ReAct-Aufforderung:
- Wissensdatenbanken für Amazon Bedrock – Wissensdatenbanken für Amazon Bedrock bieten eine vollständige Verwaltung RAG um dem KI-Assistenten Zugriff auf Ihre Daten zu gewähren. In unserem Anwendungsfall haben wir Gerätespezifikationen in eine hochgeladen Amazon Simple Storage-Service (Amazon S3) Eimer. Es dient als Datenquelle für die Wissensdatenbank.
- Aktionsgruppen – Hierbei handelt es sich um definierte API-Schemas, die bestimmte Lambda-Funktionen aufrufen, um mit IoT-Geräten und anderen AWS-Diensten zu interagieren.
- Anthropic Claude v2.1 auf Amazon Bedrock – Dieses Modell interpretiert Benutzeranfragen und orchestriert den Aufgabenfluss.
- Amazon Titan-Einbettungen – Dieses Modell dient als Texteinbettungsmodell und wandelt Text in natürlicher Sprache – von einzelnen Wörtern bis hin zu komplexen Dokumenten – in numerische Vektoren um. Dies ermöglicht Vektorsuchfunktionen, die es dem System ermöglichen, Benutzeranfragen semantisch mit den relevantesten Wissensdatenbankeinträgen abzugleichen, um eine effektive Suche zu ermöglichen.
Die Lösung ist in AWS-Dienste wie Lambda zum Ausführen von Code als Reaktion auf API-Aufrufe, Athena zum Abfragen von Datensätzen, OpenSearch Service zum Durchsuchen von Wissensdatenbanken und Amazon S3 für die Speicherung integriert. Diese Dienste arbeiten zusammen, um ein nahtloses Erlebnis für die Betriebsverwaltung von IoT-Geräten durch Befehle in natürlicher Sprache zu bieten.
Benefits
Diese Lösung bietet folgende Vorteile:
- Komplexität der Implementierung:
- Es sind weniger Codezeilen erforderlich, da Agents for Amazon Bedrock einen Großteil der zugrunde liegenden Komplexität abstrahiert und so den Entwicklungsaufwand reduziert
- Die Verwaltung von Vektordatenbanken wie OpenSearch Service wird vereinfacht, da Knowledge Bases für Amazon Bedrock die Vektorisierung und Speicherung übernimmt
- Die Integration mit verschiedenen AWS-Diensten wird durch vordefinierte Aktionsgruppen optimiert
- Entwicklererfahrung:
- Die Amazon Bedrock-Konsole bietet eine benutzerfreundliche Oberfläche für schnelle Entwicklung, Tests und Ursachenanalyse (RCA) und verbessert so das gesamte Entwicklererlebnis
- Agilität und Flexibilität:
- Agents für Amazon Bedrock ermöglichen nahtlose Upgrades auf neuere FMs (z. B. Claude 3.0), sobald diese verfügbar sind, sodass Ihre Lösung mit den neuesten Entwicklungen auf dem neuesten Stand bleibt
- Servicekontingente und -beschränkungen werden von AWS verwaltet, wodurch der Aufwand für die Überwachung und Skalierung der Infrastruktur reduziert wird
- Sicherheit:
- Amazon Bedrock ist ein vollständig verwalteter Dienst, der die strengen Sicherheits- und Compliance-Standards von AWS einhält und möglicherweise die Sicherheitsüberprüfungen von Organisationen vereinfacht
Obwohl Agents for Amazon Bedrock eine optimierte und verwaltete Lösung für die Erstellung von Konversations-KI-Anwendungen bietet, bevorzugen einige Organisationen möglicherweise einen Open-Source-Ansatz. In solchen Fällen können Sie Frameworks wie LangChain verwenden, die wir im nächsten Abschnitt besprechen.
LangChain-Ansatz für dynamisches Routing
LangChain ist ein Open-Source-Framework, das den Aufbau von Konversations-KI vereinfacht, indem es die Integration großer Sprachmodelle (LLMs) und dynamische Routing-Funktionen ermöglicht. Mit der LangChain Expression Language (LCEL) können Entwickler die definieren Routing, wodurch Sie nichtdeterministische Ketten erstellen können, bei denen die Ausgabe eines vorherigen Schritts den nächsten Schritt definiert. Routing trägt dazu bei, Struktur und Konsistenz bei Interaktionen mit LLMs zu gewährleisten.
Für diesen Beitrag verwenden wir dasselbe Beispiel wie den KI-Assistenten für die IoT-Geräteverwaltung. Der Hauptunterschied besteht jedoch darin, dass wir die Systemaufforderungen separat behandeln und jede Kette als separate Einheit behandeln müssen. Die Routing-Kette entscheidet über die Zielkette basierend auf den Eingaben des Benutzers. Die Entscheidung wird mit Unterstützung eines LLM getroffen, indem die Systemaufforderung, der Chatverlauf und die Frage des Benutzers übergeben werden.
Lösungsüberblick
Das folgende Diagramm veranschaulicht den Workflow der dynamischen Routing-Lösung.

Der Arbeitsablauf besteht aus den folgenden Schritten:
- Der Benutzer stellt dem KI-Assistenten eine Frage. Beispiel: „Was sind die maximalen Messwerte für Gerät 1009?“
- Ein LLM wertet jede Frage zusammen mit dem Chat-Verlauf derselben Sitzung aus, um ihre Art und den Themenbereich zu bestimmen (z. B. SQL, Aktion, Suche oder SME). Das LLM klassifiziert die Eingabe und die LCEL-Routingkette übernimmt diese Eingabe.
- Die Router-Kette wählt die Zielkette basierend auf der Eingabe aus und der LLM erhält die folgende Systemaufforderung:
Das LLM wertet die Frage des Benutzers zusammen mit dem Chatverlauf aus, um die Art der Anfrage und den Themenbereich zu bestimmen, zu dem sie gehört. Anschließend klassifiziert das LLM die Eingabe und gibt eine JSON-Antwort im folgenden Format aus:
Die Routerkette verwendet diese JSON-Antwort, um die entsprechende Zielkette aufzurufen. Es gibt vier fachspezifische Zielketten mit jeweils eigener Systemaufforderung:
- SQL-bezogene Abfragen werden für Datenbankinteraktionen an die SQL-Zielkette gesendet. Sie können LCEL verwenden, um das zu erstellen SQL-Kette.
- Aktionsorientierte Fragen rufen die benutzerdefinierte Lambda-Zielkette für die Ausführung von Vorgängen auf. Mit LCEL können Sie Ihre eigenen definieren benutzerdefinierte Funktion; In unserem Fall handelt es sich um eine Funktion zum Ausführen einer vordefinierten Lambda-Funktion, um eine E-Mail mit einer analysierten Geräte-ID zu senden. Eine Beispiel-Benutzereingabe könnte „Gerät 1009 herunterfahren“ lauten.
- Suchorientierte Anfragen werden an die weitergegeben RAG Zielkette für den Informationsabruf.
- Bei Fragen zu KMU wenden Sie sich an die Zielkette KMU/Experte, um spezielle Einblicke zu erhalten.
- Jede Zielkette nimmt die Eingabe entgegen und führt die erforderlichen Modelle oder Funktionen aus:
- Die SQL-Kette verwendet Athena zum Ausführen von Abfragen.
- Die RAG-Kette nutzt OpenSearch Service für die semantische Suche.
- Die benutzerdefinierte Lambda-Kette führt Lambda-Funktionen für Aktionen aus.
- Die KMU-/Expertenkette liefert Erkenntnisse mithilfe des Amazon Bedrock-Modells.
- Antworten aus jeder Zielkette werden vom LLM in kohärente Erkenntnisse formuliert. Diese Erkenntnisse werden dann dem Benutzer übermittelt und schließen den Abfragezyklus ab.
- Benutzereingaben und Antworten werden in gespeichert Amazon DynamoDB um dem LLM Kontext für die aktuelle Sitzung und vergangene Interaktionen bereitzustellen. Die Dauer der persistenten Informationen in DynamoDB wird von der Anwendung gesteuert.
Technische Übersicht
Das folgende Diagramm veranschaulicht die Architektur der dynamischen Routing-Lösung von LangChain.
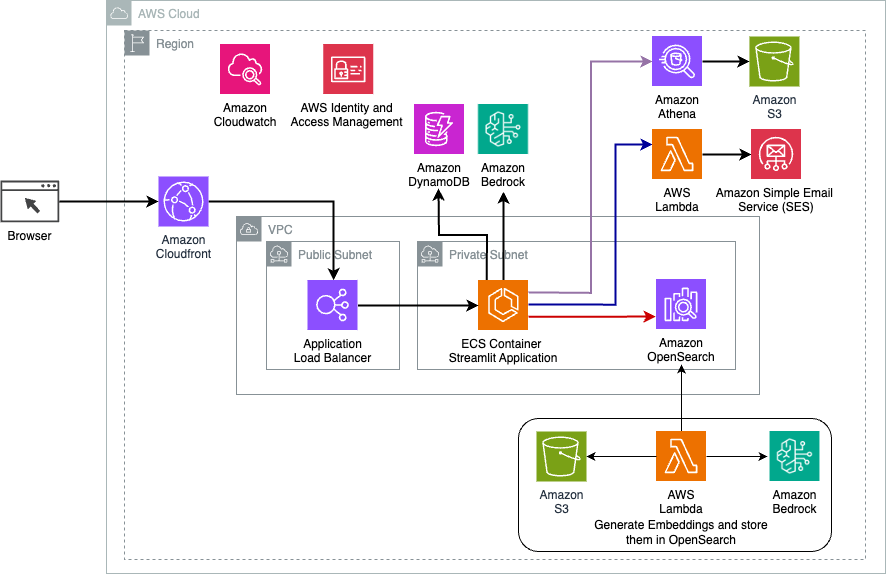
Die Webanwendung basiert auf Streamlit, das auf Amazon ECS mit Fargate gehostet wird, und der Zugriff erfolgt über einen Application Load Balancer. Wir verwenden Claude v2.1 von Anthropic auf Amazon Bedrock als unser LLM. Die Webanwendung interagiert mit dem Modell über LangChain-Bibliotheken. Es interagiert auch mit einer Vielzahl anderer AWS-Dienste wie OpenSearch Service, Athena und DynamoDB, um die Anforderungen der Endbenutzer zu erfüllen.
Benefits
Diese Lösung bietet folgende Vorteile:
- Komplexität der Implementierung:
- Obwohl mehr Code und benutzerdefinierte Entwicklung erforderlich sind, bietet LangChain eine größere Flexibilität und Kontrolle über die Routing-Logik und die Integration mit verschiedenen Komponenten.
- Die Verwaltung von Vektordatenbanken wie OpenSearch Service erfordert zusätzlichen Einrichtungs- und Konfigurationsaufwand. Der Vektorisierungsprozess ist im Code implementiert.
- Die Integration mit AWS-Diensten erfordert möglicherweise mehr benutzerdefinierten Code und mehr Konfiguration.
- Entwicklererfahrung:
- Der Python-basierte Ansatz und die umfangreiche Dokumentation von LangChain können für Entwickler attraktiv sein, die bereits mit Python und Open-Source-Tools vertraut sind.
- Eine zeitnahe Entwicklung und Fehlerbehebung erfordern im Vergleich zur Verwendung der Amazon Bedrock-Konsole möglicherweise mehr manuellen Aufwand.
- Agilität und Flexibilität:
- LangChain unterstützt eine breite Palette von LLMs, sodass Sie zwischen verschiedenen Modellen oder Anbietern wechseln und so die Flexibilität fördern können.
- Der Open-Source-Charakter von LangChain ermöglicht von der Community vorangetriebene Verbesserungen und Anpassungen.
- Sicherheit:
- Als Open-Source-Framework erfordert LangChain möglicherweise strengere Sicherheitsüberprüfungen und -überprüfungen innerhalb von Organisationen, was möglicherweise zu zusätzlichem Aufwand führt.
Zusammenfassung
Konversations-KI-Assistenten sind transformative Werkzeuge zur Rationalisierung von Abläufen und zur Verbesserung der Benutzererfahrung. In diesem Beitrag wurden zwei leistungsstarke Ansätze unter Verwendung von AWS-Diensten untersucht: die verwalteten Agenten für Amazon Bedrock und das flexible, dynamische Open-Source-Routing von LangChain. Die Wahl zwischen diesen Ansätzen hängt von den Anforderungen Ihres Unternehmens, den Entwicklungspräferenzen und dem gewünschten Maß an Anpassung ab. Unabhängig vom eingeschlagenen Weg ermöglicht Ihnen AWS die Entwicklung intelligenter KI-Assistenten, die Geschäfts- und Kundeninteraktionen revolutionieren
Den Lösungscode und die Bereitstellungsressourcen finden Sie in unserem GitHub-Repository, wo Sie die detaillierten Schritte für jeden Konversations-KI-Ansatz befolgen können.
Über die Autoren
 Ameer Hakme ist ein AWS-Lösungsarchitekt mit Sitz in Pennsylvania. Er arbeitet mit unabhängigen Softwareanbietern (ISVs) in der Nordostregion zusammen und unterstützt sie beim Entwurf und Aufbau skalierbarer und moderner Plattformen in der AWS Cloud. Als Experte für KI/ML und generative KI unterstützt Ameer Kunden dabei, das Potenzial dieser Spitzentechnologien auszuschöpfen. In seiner Freizeit fährt er gerne Motorrad und verbringt viel Zeit mit seiner Familie.
Ameer Hakme ist ein AWS-Lösungsarchitekt mit Sitz in Pennsylvania. Er arbeitet mit unabhängigen Softwareanbietern (ISVs) in der Nordostregion zusammen und unterstützt sie beim Entwurf und Aufbau skalierbarer und moderner Plattformen in der AWS Cloud. Als Experte für KI/ML und generative KI unterstützt Ameer Kunden dabei, das Potenzial dieser Spitzentechnologien auszuschöpfen. In seiner Freizeit fährt er gerne Motorrad und verbringt viel Zeit mit seiner Familie.
 Sharon Lic ist ein KI/ML-Lösungsarchitekt bei Amazon Web Services mit Sitz in Boston, mit einer Leidenschaft für das Entwerfen und Erstellen generativer KI-Anwendungen auf AWS. Sie arbeitet mit Kunden zusammen, um AWS AI/ML-Services für innovative Lösungen zu nutzen.
Sharon Lic ist ein KI/ML-Lösungsarchitekt bei Amazon Web Services mit Sitz in Boston, mit einer Leidenschaft für das Entwerfen und Erstellen generativer KI-Anwendungen auf AWS. Sie arbeitet mit Kunden zusammen, um AWS AI/ML-Services für innovative Lösungen zu nutzen.
 Kawsar Kamal ist leitender Lösungsarchitekt bei Amazon Web Services mit über 15 Jahren Erfahrung im Bereich Infrastrukturautomatisierung und Sicherheit. Er unterstützt Kunden beim Entwurf und Aufbau skalierbarer DevSecOps- und AI/ML-Lösungen in der Cloud.
Kawsar Kamal ist leitender Lösungsarchitekt bei Amazon Web Services mit über 15 Jahren Erfahrung im Bereich Infrastrukturautomatisierung und Sicherheit. Er unterstützt Kunden beim Entwurf und Aufbau skalierbarer DevSecOps- und AI/ML-Lösungen in der Cloud.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/machine-learning/enhance-conversational-ai-with-advanced-routing-techniques-with-amazon-bedrock/

