Im Januar 2024, Amazon Sage Maker eine neue Version gestartet (0.26.0) von Large Model Inference (LMI) Deep Learning Containern (DLCs). Diese Version bietet Unterstützung für neue Modelle (einschließlich Mixture of Experts), Leistungs- und Benutzerfreundlichkeitsverbesserungen bei Inferenz-Backends sowie neue Generationsdetails für eine bessere Kontrolle und Erklärbarkeit von Vorhersagen (z. B. Grund für den Abschluss der Generation und Protokollwahrscheinlichkeiten auf Token-Ebene).
LMI-DLCs bieten eine Low-Code-Schnittstelle, die die Verwendung modernster Techniken und Hardware zur Inferenzoptimierung vereinfacht. Mit LMI können Sie Tensorparallelität anwenden. die neuesten effizienten Aufmerksamkeits-, Batch-, Quantisierungs- und Speicherverwaltungstechniken; Token-Streaming; und vieles mehr, indem Sie lediglich die Modell-ID und optionale Modellparameter benötigen. Mit LMI-DLCs auf SageMaker können Sie die Wertschöpfungszeit für Ihr Unternehmen verkürzen generative künstliche Intelligenz (KI) Anwendungen, entlasten infrastrukturbezogene Schwerstarbeit und optimieren große Sprachmodelle (LLMs) für die Hardware Ihrer Wahl, um ein erstklassiges Preis-Leistungs-Verhältnis zu erzielen.
In diesem Beitrag untersuchen wir die neuesten Funktionen, die in dieser Version eingeführt wurden, untersuchen Leistungsbenchmarks und bieten eine detaillierte Anleitung zur Bereitstellung neuer LLMs mit LMI-DLCs bei hoher Leistung.
Neue Funktionen mit LMI-DLCs
In diesem Abschnitt besprechen wir neue Funktionen in allen LMI-Backends und gehen auf einige andere Backend-spezifische Funktionen ein. LMI unterstützt derzeit die folgenden Backends:
- LMI-verteilte Bibliothek – Dies ist das AWS-Framework zum Ausführen von Inferenzen mit LLMs, inspiriert von OSS, um die bestmögliche Latenz und Genauigkeit des Ergebnisses zu erzielen
- LMI vLLM – Dies ist die AWS-Backend-Implementierung des speichereffizienten vLLM Inferenzbibliothek
- LMI TensorRT-LLM-Toolkit – Dies ist die AWS-Backend-Implementierung von NVIDIA TensorRT-LLM, das GPU-spezifische Engines erstellt, um die Leistung auf verschiedenen GPUs zu optimieren
- LMI DeepSpeed – Dies ist die AWS-Adaption von Tiefgeschwindigkeit, was echtes kontinuierliches Batching, SmoothQuant-Quantisierung und die Möglichkeit hinzufügt, den Speicher während der Inferenz dynamisch anzupassen
- LMI NeuronX – Sie können dies für die Bereitstellung verwenden AWS Inferentia2 und AWS-Training-basierte Instanzen mit echtem kontinuierlichem Batching und Beschleunigungen, basierend auf dem AWS Neuron-SDK
Die folgende Tabelle fasst die neu hinzugefügten Funktionen zusammen, sowohl allgemeine als auch Backend-spezifische.
|
In allen Backends üblich |
|||
|
|||
|
Backend-spezifisch |
|||
|
LMI-verteilt |
vLLM | TensorRT-LLM |
NeuronX |
|
|
|
|
Neue Modelle werden unterstützt
Neue beliebte Modelle werden über Backends hinweg unterstützt, wie Mistral-7B (alle Backends), das MoE-basierte Mixtral (alle Backends außer Transformers-NeuronX) und Llama2-70B (Transformers-NeuronX).
Techniken zur Kontextfenstererweiterung
Die auf RoPE (Rotary Positional Embedding) basierende Kontextskalierung ist jetzt auf den Backends LMI-Dist, vLLM und TensorRT-LLM verfügbar. Die RoPE-Skalierung ermöglicht die Erweiterung der Sequenzlänge eines Modells während der Inferenz auf nahezu jede Größe, ohne dass eine Feinabstimmung erforderlich ist.
Im Folgenden sind zwei wichtige Überlegungen bei der Verwendung von RoPE aufgeführt:
- Modell-Ratlosigkeit – Mit zunehmender Sequenzlänge, so kann die Models Verwirrung. Dieser Effekt kann teilweise ausgeglichen werden, indem eine minimale Feinabstimmung an Eingabesequenzen durchgeführt wird, die größer sind als diejenigen, die im ursprünglichen Training verwendet wurden. Ein detailliertes Verständnis darüber, wie sich RoPE auf die Modellqualität auswirkt, finden Sie unter Erweiterung des RoPE.
- Inferenzleistung – Längere Sequenzlängen verbrauchen den Hochbandbreitenspeicher (HBM) des höheren Beschleunigers. Diese erhöhte Speichernutzung kann sich negativ auf die Anzahl gleichzeitiger Anforderungen auswirken, die Ihr Beschleuniger verarbeiten kann.
Generierungsdetails hinzugefügt
Sie können jetzt zwei detaillierte Details zu den Generierungsergebnissen abrufen:
- fertig_grund – Dies gibt den Grund für den Abschluss der Generierung an, der das Erreichen der maximalen Generierungslänge, die Generierung eines Satzende-Tokens (EOS) oder die Generierung eines benutzerdefinierten Stopp-Tokens sein kann. Es wird mit dem letzten gestreamten Sequenzblock zurückgegeben.
- log_probs – Dies gibt die vom Modell zugewiesene Protokollwahrscheinlichkeit für jedes Token im gestreamten Sequenzblock zurück. Sie können diese als grobe Schätzung der Modellzuverlässigkeit verwenden, indem Sie die gemeinsame Wahrscheinlichkeit einer Sequenz als Summe der berechnen
log_probsder einzelnen Token, was für die Bewertung und Einstufung der Modellausgaben nützlich sein kann. Beachten Sie, dass LLM-Token-Wahrscheinlichkeiten ohne Kalibrierung im Allgemeinen zu zuversichtlich sind.
Sie können die Ausgabe der Generierungsergebnisse aktivieren, indem Sie „details=True“ in Ihre Eingabenutzlast für LMI einfügen und alle anderen Parameter unverändert lassen:
payload = {“inputs”:“your prompt”,
“parameters”:{max_new_tokens”:256,...,“details”:True}
}Konsolidierte Konfigurationsparameter
Schließlich wurden auch die LMI-Konfigurationsparameter konsolidiert. Weitere Informationen zu allen allgemeinen und Backend-spezifischen Bereitstellungskonfigurationsparametern finden Sie unter Große Modellinferenzkonfigurationen.
LMI-verteiltes Backend
Auf der AWS re:Invent 2023 hat LMI-Dist neue, optimierte kollektive Operationen hinzugefügt, um die Kommunikation zwischen GPUs zu beschleunigen, was zu geringerer Latenz und höherem Durchsatz für Modelle führt, die zu groß für eine einzelne GPU sind. Diese Kollektive sind exklusiv für SageMaker für p4d-Instanzen verfügbar.
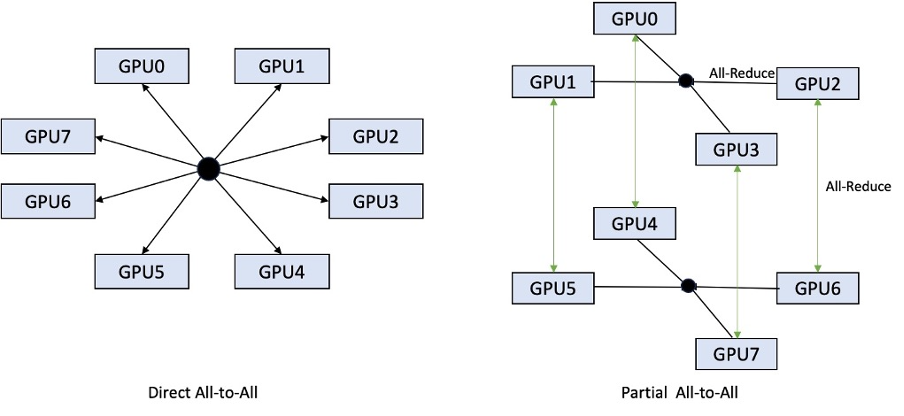
Während die vorherige Iteration nur Sharding über alle 8 GPUs hinweg unterstützte, führt LMI 0.26.0 die Unterstützung für einen Tensor-Parallelitätsgrad von 4 in einem partiellen All-to-All-Muster ein. Dies kann mit kombiniert werden SageMaker-Inferenzkomponenten, mit dem Sie granular konfigurieren können, wie viele Beschleuniger jedem hinter einem Endpunkt bereitgestellten Modell zugewiesen werden sollen. Zusammen bieten diese Funktionen eine bessere Kontrolle über die Ressourcennutzung der zugrunde liegenden Instanz und ermöglichen es Ihnen, die Mehrmandantenfähigkeit des Modells zu erhöhen, indem Sie verschiedene Modelle hinter einem Endpunkt hosten, oder den Gesamtdurchsatz Ihrer Bereitstellung genau abzustimmen, um ihn an Ihre Modell- und Verkehrsmerkmale anzupassen.
Die folgende Abbildung vergleicht die direkte Alles-zu-Alle mit der teilweisen Alles-zu-Alle.
TensorRT-LLM-Backend
NVIDIAs TensorRT-LLM wurde als Teil der vorherigen LMI-DLC-Version (0.25.0) eingeführt und ermöglicht modernste GPU-Leistung und Optimierungen wie SmoothQuant, FP8 und kontinuierliches Batching für LLMs bei Verwendung von NVIDIA-GPUs.
TensorRT-LLM erfordert, dass Modelle vor der Bereitstellung in effiziente Engines kompiliert werden. Der LMI TensorRT-LLM DLC kann automatisch eine Liste der unterstützten Modelle Just-in-Time (JIT) erstellen, bevor der Server gestartet und das Modell für Echtzeit-Inferenz geladen wird. Version 0.26.0 des DLC erweitert die Liste der unterstützten Modelle für die JIT-Kompilierung und führt die Modelle Baichuan, ChatGLM, GPT2, GPT-J, InternLM, Mistral, Mixtral, Qwen, SantaCoder und StarCoder ein.
Durch die JIT-Kompilierung erhöht sich der Mehraufwand für die Endpunktbereitstellung und -skalierung um mehrere Minuten. Es wird daher immer empfohlen, Ihr Modell im Voraus zu kompilieren. Eine Anleitung dazu und eine Liste der unterstützten Modelle finden Sie unter TensorRT-LLM-Tutorial zur vorzeitigen Kompilierung von Modellen. Wenn Ihr ausgewähltes Modell noch nicht unterstützt wird, lesen Sie weiter TensorRT-LLM-Tutorial zur manuellen Kompilierung von Modellen um jedes andere Modell zu kompilieren, das von TensorRT-LLM unterstützt wird.
Darüber hinaus stellt LMI jetzt die native TensorRT-LLM SmootQuant-Quantisierung mit Parametern zur Steuerung von Alpha und Skalierungsfaktor nach Token oder Kanal bereit. Weitere Informationen zu den entsprechenden Konfigurationen finden Sie unter TensorRT-LLM.
vLLM-Backend
Die im LMI-DLC enthaltene aktualisierte Version von vLLM bietet Leistungsverbesserungen von bis zu 50 %, die durch den CUDA-Grafikmodus anstelle des Eager-Modus erzielt werden. CUDA-Diagramme beschleunigen GPU-Arbeitslasten, indem sie mehrere GPU-Vorgänge auf einmal starten, anstatt sie einzeln zu starten, was den Overhead reduziert. Dies ist besonders effektiv für kleine Modelle, wenn Tensorparallelität verwendet wird.
Die zusätzliche Leistung geht einher mit einem zusätzlichen GPU-Speicherverbrauch. Der CUDA-Grafikmodus ist jetzt Standard für das vLLM-Backend. Wenn Sie also auf die Menge des verfügbaren GPU-Speichers beschränkt sind, können Sie ihn festlegen option.enforce_eager=True um den PyTorch-Eager-Modus zu erzwingen.
Transformers-NeuronX-Backend
Die aktualisierte Version von NeuronX Das im LMI NeuronX DLC enthaltene Programm unterstützt jetzt Modelle, die über den Grouped-Query-Attention-Mechanismus verfügen, wie Mistral-7B und LLama2-70B. Die Aufmerksamkeit bei gruppierten Abfragen ist eine wichtige Optimierung des standardmäßigen Transformator-Aufmerksamkeitsmechanismus, bei dem das Modell mit weniger Schlüssel- und Wertköpfen als Abfrageköpfen trainiert wird. Dadurch wird die Größe des KV-Cache im GPU-Speicher reduziert, was eine größere Parallelität ermöglicht und das Preis-Leistungs-Verhältnis verbessert.
Die folgende Abbildung veranschaulicht Multi-Head-, Grouped-Query- und Multi-Query-Attention-Methoden (Quelle).
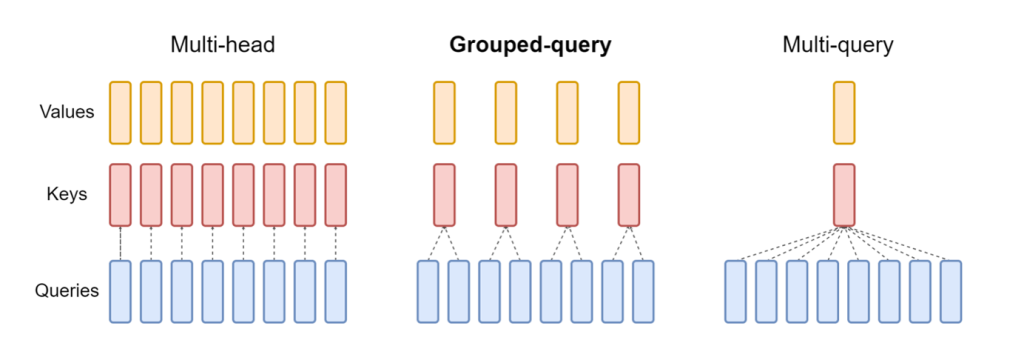
Für verschiedene Arten von Arbeitslasten stehen verschiedene KV-Cache-Sharding-Strategien zur Verfügung. Weitere Informationen zu Sharding-Strategien finden Sie unter Unterstützung für Grouped-Query Attention (GQA).. Sie können Ihre gewünschte Strategie aktivieren (shard-over-heads, zum Beispiel) mit folgendem Code:
Darüber hinaus führt die neue Implementierung von NeuronX DLC eine Cache-API für TransformerNeuronX ein, die den Zugriff auf den KV-Cache ermöglicht. Es ermöglicht Ihnen, KV-Cache-Zeilen aus neuen Anforderungen einzufügen und zu entfernen, während Sie Batch-Inferenzen durchführen. Vor der Einführung dieser API wurde der KV-Cache für alle neu hinzugefügten Anfragen neu berechnet. Im Vergleich zu LMI V7 (0.25.0) haben wir die Latenz bei gleichzeitigen Anfragen um mehr als 33 % verbessert und unterstützen einen viel höheren Durchsatz.
Auswahl des richtigen Backends
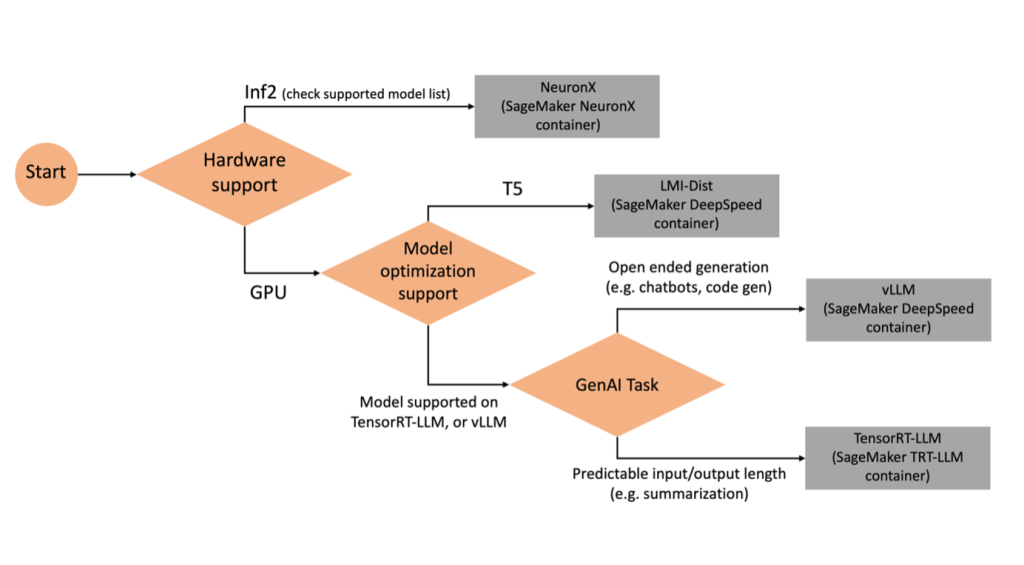
Um zu entscheiden, welches Backend basierend auf dem ausgewählten Modell und der ausgewählten Aufgabe verwendet werden soll, verwenden Sie das folgende Flussdiagramm. Einzelne Backend-Benutzerhandbücher sowie unterstützte Modelle finden Sie unter LMI Backend-Benutzerhandbücher.
Stellen Sie Mixtral mit LMI DLC mit zusätzlichen Attributen bereit
Lassen Sie uns durchgehen, wie Sie das Mixtral-8x7B-Modell mit dem LMI 0.26.0-Container bereitstellen und zusätzliche Details wie generieren können log_prob und finish_reason als Teil der Ausgabe. Wir besprechen auch, wie Sie durch einen Anwendungsfall zur Inhaltsgenerierung von diesen zusätzlichen Attributen profitieren können.
Das komplette Notizbuch mit ausführlicher Anleitung finden Sie im GitHub Repo.
Wir beginnen mit dem Import der Bibliotheken und der Konfiguration der Sitzungsumgebung:
Sie können SageMaker LMI-Container zum Hosten von Modellen ohne zusätzlichen Inferenzcode verwenden. Sie können den Modellserver entweder über die Umgebungsvariablen oder a konfigurieren serving.properties Datei. Optional könnten Sie eine haben model.py Datei für eine etwaige Vor- oder Nachbearbeitung und a requirements.txt Datei für alle zusätzlichen Pakete, die installiert werden müssen.
In diesem Fall verwenden wir die serving.properties Datei, um die Parameter zu konfigurieren und das Verhalten des LMI-Containers anzupassen. Weitere Einzelheiten finden Sie im GitHub Repo. Das Repo erläutert Details zu den verschiedenen Konfigurationsparametern, die Sie festlegen können. Wir benötigen folgende Schlüsselparameter:
- Sie – Gibt die Laufzeit-Engine an, die DJL verwenden soll. Dies steuert das Sharding und die Modellladestrategie in den Beschleunigern für das Modell.
- option.model_id – Gibt die an Amazon Simple Storage-Service (Amazon S3) URI des vorab trainierten Modells oder die Modell-ID eines vorab trainierten Modells, das in einem Modell-Repository gehostet wird Gesicht umarmen. In diesem Fall stellen wir die Modell-ID für das Modell Mixtral-8x7B bereit.
- option.tensor_parallel_degree – Legt die Anzahl der GPU-Geräte fest, über die Accelerate das Modell partitionieren muss. Dieser Parameter steuert auch die Anzahl der Worker pro Modell, die gestartet werden, wenn die DJL-Bereitstellung ausgeführt wird. Wir setzen diesen Wert auf
max(maximale GPU auf der aktuellen Maschine). - option.rolling_batch – Ermöglicht eine kontinuierliche Chargenbildung zur Optimierung der Beschleunigernutzung und des Gesamtdurchsatzes. Für den TensorRT-LLM-Container verwenden wir
auto. - option.model_loading_timeout – Legt den Zeitüberschreitungswert für das Herunterladen und Laden des Modells fest, um die Inferenz zu ermöglichen.
- option.max_rolling_batch – Legt die maximale Größe des kontinuierlichen Stapels fest und definiert, wie viele Sequenzen zu einem bestimmten Zeitpunkt parallel verarbeitet werden können.
Wir verpacken die serving.properties Konfigurationsdatei im tar.gz-Format, damit sie den Hosting-Anforderungen von SageMaker entspricht. Wir konfigurieren den DJL LMI-Container mit tensorrtllm als Backend-Engine. Zusätzlich geben wir die neueste Version des Containers an (0.26.0).
Als nächstes laden wir den lokalen Tarball hoch (enthält serving.properties Konfigurationsdatei) in ein S3-Präfix umwandeln. Wir verwenden den Bild-URI für den DJL-Container und den Amazon S3-Speicherort, an den der Tarball für die Modellbereitstellungsartefakte hochgeladen wurde, um das SageMaker-Modellobjekt zu erstellen.
Als Teil von LMI 0.26.0 können Sie jetzt zwei zusätzliche detaillierte Details zur generierten Ausgabe verwenden:
- log_probs – Dies ist die vom Modell zugewiesene Protokollwahrscheinlichkeit für jedes Token im gestreamten Sequenzblock. Sie können diese als grobe Schätzung der Modellkonfidenz verwenden, indem Sie die gemeinsame Wahrscheinlichkeit einer Sequenz als Summe der Log-Wahrscheinlichkeiten der einzelnen Token berechnen, was für die Bewertung und Einstufung der Modellausgaben nützlich sein kann. Beachten Sie, dass LLM-Token-Wahrscheinlichkeiten ohne Kalibrierung im Allgemeinen zu zuversichtlich sind.
- fertig_grund – Dies ist der Grund für den Abschluss der Generierung. Dies kann das Erreichen der maximalen Generierungslänge, die Generierung eines EOS-Tokens oder die Generierung eines benutzerdefinierten Stopp-Tokens sein. Dies wird mit dem letzten gestreamten Sequenzblock zurückgegeben.
Sie können diese durch Übergeben aktivieren "details"=True als Teil Ihrer Eingabe in das Modell.
Sehen wir uns an, wie Sie diese Details generieren können. Wir verwenden ein Beispiel zur Inhaltsgenerierung, um ihre Anwendung zu verstehen.
Wir definieren a LineIterator Hilfsklasse, die über Funktionen zum langsamen Abrufen von Bytes aus einem Antwortstrom, zum Puffern dieser und zum Aufteilen des Puffers in Zeilen verfügt. Die Idee besteht darin, Bytes aus dem Puffer bereitzustellen und gleichzeitig mehr Bytes aus dem Stream asynchron abzurufen.
Generieren und verwenden Sie die Token-Wahrscheinlichkeit als zusätzliches Detail
Stellen Sie sich einen Anwendungsfall vor, bei dem wir Inhalte generieren. Konkret haben wir die Aufgabe, für eine Lifestyle-Website einen kurzen Absatz über die Vorteile regelmäßiger körperlicher Betätigung zu verfassen. Wir möchten Inhalte generieren und einen indikativen Wert für das Vertrauen ausgeben, das das Modell in den generierten Inhalt hat.
Wir rufen den Modellendpunkt mit unserer Eingabeaufforderung auf und erfassen die generierte Antwort. Legen wir fest "details": True als Laufzeitparameter innerhalb der Eingabe in das Modell. Da die Log-Wahrscheinlichkeit für jedes Ausgabetoken generiert wird, hängen wir die einzelnen Log-Wahrscheinlichkeiten an eine Liste an. Wir erfassen auch den gesamten generierten Text aus der Antwort.
Um den Gesamtkonfidenzwert zu berechnen, berechnen wir den Mittelwert aller einzelnen Token-Wahrscheinlichkeiten und erhalten anschließend den Exponentialwert zwischen 0 und 1. Dies ist unser abgeleiteter Gesamtkonfidenzwert für den generierten Text, in diesem Fall ein Absatz über die Vorteile von regelmäßiger körperlicher Betätigung.

Dies war ein Beispiel dafür, wie Sie generieren und verwenden können log_prob, im Kontext eines Anwendungsfalls zur Inhaltsgenerierung. Ebenso können Sie verwenden log_prob als Maß für den Konfidenzwert für Klassifizierungsanwendungsfälle.
Alternativ können Sie es für die gesamte Ausgabesequenz oder die Bewertung auf Satzebene verwenden, um die Auswirkung von Parametern wie der Temperatur auf die generierte Ausgabe zu bewerten.
Erzeugen und verwenden Sie den Endgrund als zusätzliches Detail
Lassen Sie uns auf demselben Anwendungsfall aufbauen, aber dieses Mal haben wir die Aufgabe, einen längeren Artikel zu schreiben. Darüber hinaus möchten wir sicherstellen, dass die Ausgabe nicht aufgrund von Problemen mit der Generierungslänge (maximale Token-Länge) oder aufgrund von Stop-Tokens abgeschnitten wird.
Um dies zu erreichen, verwenden wir die finish_reason Attribut, das in der Ausgabe generiert wurde, überwachen Sie seinen Wert und fahren Sie mit der Generierung fort, bis die gesamte Ausgabe generiert ist.
Wir definieren eine Inferenzfunktion, die eine Nutzlasteingabe entgegennimmt und den SageMaker-Endpunkt aufruft, eine Antwort zurückstreamt und die Antwort verarbeitet, um generierten Text zu extrahieren. Die Nutzlast enthält den Eingabeaufforderungstext als Eingaben und Parameter wie maximale Token und Details. Die Antwort wird in einem Stream gelesen und Zeile für Zeile verarbeitet, um die generierten Text-Tokens in eine Liste zu extrahieren. Wir extrahieren Details wie finish_reason. Wir rufen die Inferenzfunktion in einer Schleife auf (verkettete Anfragen), fügen dabei jedes Mal mehr Kontext hinzu und verfolgen die Anzahl der generierten Token und die Anzahl der gesendeten Anfragen, bis das Modell fertig ist.
Wie wir sehen können, obwohl die max_new_token Wenn der Parameter auf 256 gesetzt ist, verwenden wir das Detailattribut „finish_reason“ als Teil der Ausgabe, um mehrere Anforderungen an den Endpunkt zu verketten, bis die gesamte Ausgabe generiert ist.

Ebenso können Sie je nach Anwendungsfall verwenden stop_reason um eine unzureichende Ausgabesequenzlänge für eine bestimmte Aufgabe oder einen unbeabsichtigten Abschluss aufgrund einer menschlichen Stoppsequenz zu erkennen.
Zusammenfassung
In diesem Beitrag haben wir die Version v0.26.0 des AWS LMI-Containers besprochen. Wir haben wichtige Leistungsverbesserungen, die Unterstützung neuer Modelle und neue Benutzerfreundlichkeitsfunktionen hervorgehoben. Mit diesen Funktionen können Sie Kosten- und Leistungsmerkmale besser in Einklang bringen und gleichzeitig Ihren Endbenutzern ein besseres Erlebnis bieten.
Weitere Informationen zu den LMI-DLC-Funktionen finden Sie unter Modellparallelität und große Modellinferenz. Wir sind gespannt, wie Sie diese neuen Funktionen von SageMaker nutzen.
Über die Autoren
 Joao Moura ist Senior AI/ML Specialist Solutions Architect bei AWS. João hilft AWS-Kunden – von kleinen Start-ups bis hin zu großen Unternehmen – große Modelle effizient zu trainieren und bereitzustellen und allgemeiner ML-Plattformen auf AWS aufzubauen.
Joao Moura ist Senior AI/ML Specialist Solutions Architect bei AWS. João hilft AWS-Kunden – von kleinen Start-ups bis hin zu großen Unternehmen – große Modelle effizient zu trainieren und bereitzustellen und allgemeiner ML-Plattformen auf AWS aufzubauen.
 Rahul Sharma ist Senior Solutions Architect bei AWS und unterstützt AWS-Kunden beim Entwerfen und Erstellen von KI/ML-Lösungen. Bevor er zu AWS kam, war Rahul mehrere Jahre im Finanz- und Versicherungssektor tätig und unterstützte Kunden beim Aufbau von Daten- und Analyseplattformen.
Rahul Sharma ist Senior Solutions Architect bei AWS und unterstützt AWS-Kunden beim Entwerfen und Erstellen von KI/ML-Lösungen. Bevor er zu AWS kam, war Rahul mehrere Jahre im Finanz- und Versicherungssektor tätig und unterstützte Kunden beim Aufbau von Daten- und Analyseplattformen.
 Qing Lan ist Softwareentwicklungsingenieur bei AWS. Er hat an mehreren herausfordernden Produkten bei Amazon gearbeitet, darunter Hochleistungs-ML-Inferenzlösungen und Hochleistungs-Protokollierungssysteme. Das Team von Qing führte erfolgreich das erste Billion-Parameter-Modell in Amazon Advertising mit sehr geringer Latenz ein. Qing verfügt über fundierte Kenntnisse in den Bereichen Infrastrukturoptimierung und Deep-Learning-Beschleunigung.
Qing Lan ist Softwareentwicklungsingenieur bei AWS. Er hat an mehreren herausfordernden Produkten bei Amazon gearbeitet, darunter Hochleistungs-ML-Inferenzlösungen und Hochleistungs-Protokollierungssysteme. Das Team von Qing führte erfolgreich das erste Billion-Parameter-Modell in Amazon Advertising mit sehr geringer Latenz ein. Qing verfügt über fundierte Kenntnisse in den Bereichen Infrastrukturoptimierung und Deep-Learning-Beschleunigung.
 Jian Sheng ist ein Softwareentwicklungsingenieur bei Amazon Web Services, der an mehreren Schlüsselaspekten maschineller Lernsysteme gearbeitet hat. Er hat maßgeblich zum SageMaker Neo-Dienst beigetragen und sich dabei auf die Deep-Learning-Kompilierung und die Optimierung der Framework-Laufzeit konzentriert. Kürzlich hat er seine Bemühungen gelenkt und dazu beigetragen, das maschinelle Lernsystem für die Inferenz großer Modelle zu optimieren.
Jian Sheng ist ein Softwareentwicklungsingenieur bei Amazon Web Services, der an mehreren Schlüsselaspekten maschineller Lernsysteme gearbeitet hat. Er hat maßgeblich zum SageMaker Neo-Dienst beigetragen und sich dabei auf die Deep-Learning-Kompilierung und die Optimierung der Framework-Laufzeit konzentriert. Kürzlich hat er seine Bemühungen gelenkt und dazu beigetragen, das maschinelle Lernsystem für die Inferenz großer Modelle zu optimieren.
 Tyler Osterberg ist Softwareentwicklungsingenieur bei AWS. Er ist auf die Entwicklung leistungsstarker Inferenzerfahrungen für maschinelles Lernen in SageMaker spezialisiert. In letzter Zeit lag sein Fokus auf der Optimierung der Leistung von Inferentia Deep Learning Containern auf der SageMaker-Plattform. Tyler zeichnet sich dadurch aus, dass er leistungsstarke Hosting-Lösungen für große Sprachmodelle implementiert und die Benutzererfahrung mithilfe modernster Technologie verbessert.
Tyler Osterberg ist Softwareentwicklungsingenieur bei AWS. Er ist auf die Entwicklung leistungsstarker Inferenzerfahrungen für maschinelles Lernen in SageMaker spezialisiert. In letzter Zeit lag sein Fokus auf der Optimierung der Leistung von Inferentia Deep Learning Containern auf der SageMaker-Plattform. Tyler zeichnet sich dadurch aus, dass er leistungsstarke Hosting-Lösungen für große Sprachmodelle implementiert und die Benutzererfahrung mithilfe modernster Technologie verbessert.
 Rupinder Grewal ist Senior AI/ML Specialist Solutions Architect bei AWS. Derzeit konzentriert er sich auf die Bereitstellung von Modellen und MLOps auf Amazon SageMaker. Vor dieser Rolle arbeitete er als Ingenieur für maschinelles Lernen beim Erstellen und Hosten von Modellen. Außerhalb der Arbeit spielt er gerne Tennis und radelt auf Bergwegen.
Rupinder Grewal ist Senior AI/ML Specialist Solutions Architect bei AWS. Derzeit konzentriert er sich auf die Bereitstellung von Modellen und MLOps auf Amazon SageMaker. Vor dieser Rolle arbeitete er als Ingenieur für maschinelles Lernen beim Erstellen und Hosten von Modellen. Außerhalb der Arbeit spielt er gerne Tennis und radelt auf Bergwegen.
 Dhawal Patel ist Principal Machine Learning Architect bei AWS. Er hat mit Organisationen von großen Unternehmen bis hin zu mittelständischen Startups an Problemen im Zusammenhang mit verteiltem Computing und künstlicher Intelligenz gearbeitet. Er konzentriert sich auf Deep Learning, einschließlich NLP- und Computer Vision-Domänen. Er hilft Kunden, hochleistungsfähige Modellinferenz auf SageMaker zu erreichen.
Dhawal Patel ist Principal Machine Learning Architect bei AWS. Er hat mit Organisationen von großen Unternehmen bis hin zu mittelständischen Startups an Problemen im Zusammenhang mit verteiltem Computing und künstlicher Intelligenz gearbeitet. Er konzentriert sich auf Deep Learning, einschließlich NLP- und Computer Vision-Domänen. Er hilft Kunden, hochleistungsfähige Modellinferenz auf SageMaker zu erreichen.
 Raghu Ramesha ist Senior ML Solutions Architect im Amazon SageMaker Service-Team. Er konzentriert sich darauf, Kunden bei der Erstellung, Bereitstellung und Migration von ML-Produktions-Workloads in großem Maßstab zu SageMaker zu unterstützen. Er ist auf die Bereiche maschinelles Lernen, KI und Computer Vision spezialisiert und verfügt über einen Master-Abschluss in Informatik von der UT Dallas. In seiner Freizeit reist und fotografiert er gerne.
Raghu Ramesha ist Senior ML Solutions Architect im Amazon SageMaker Service-Team. Er konzentriert sich darauf, Kunden bei der Erstellung, Bereitstellung und Migration von ML-Produktions-Workloads in großem Maßstab zu SageMaker zu unterstützen. Er ist auf die Bereiche maschinelles Lernen, KI und Computer Vision spezialisiert und verfügt über einen Master-Abschluss in Informatik von der UT Dallas. In seiner Freizeit reist und fotografiert er gerne.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/machine-learning/boost-inference-performance-for-mixtral-and-llama-2-models-with-new-amazon-sagemaker-containers/

