Die Posenschätzung ist eine Computer-Vision-Technik, die eine Reihe von Punkten auf Objekten (z. B. Personen oder Fahrzeugen) in Bildern oder Videos erkennt. Die Posenschätzung findet reale Anwendungen in den Bereichen Sport, Robotik, Sicherheit, Augmented Reality, Medien und Unterhaltung, medizinische Anwendungen und mehr. Posenschätzungsmodelle werden anhand von Bildern oder Videos trainiert, die mit einem konsistenten Satz von Punkten (Koordinaten) versehen sind, die durch ein Rig definiert werden. Um genaue Modelle zur Posenschätzung zu trainieren, müssen Sie zunächst einen großen Datensatz mit kommentierten Bildern erfassen. Viele Datensätze verfügen über Zehntausende oder Hunderttausende annotierter Bilder und erfordern erhebliche Ressourcen für die Erstellung. Es ist wichtig, Fehler bei der Kennzeichnung zu erkennen und zu verhindern, da die Modellleistung für Posenschätzungsmodelle stark von der Qualität und dem Datenvolumen der gekennzeichneten Daten abhängt.
In diesem Beitrag zeigen wir, wie Sie einen benutzerdefinierten Etikettierungsworkflow verwenden können Amazon Sagemaker Ground Truth speziell für die Schlüsselpunktbeschriftung entwickelt. Dieser benutzerdefinierte Workflow trägt dazu bei, den Beschriftungsprozess zu rationalisieren und Beschriftungsfehler zu minimieren, wodurch die Kosten für den Erhalt hochwertiger Posenbeschriftungen gesenkt werden.
Bedeutung hochwertiger Daten und Reduzierung von Etikettierungsfehlern
Hochwertige Daten sind für das Training robuster und zuverlässiger Posenschätzungsmodelle von grundlegender Bedeutung. Die Genauigkeit dieser Modelle hängt direkt von der Richtigkeit und Präzision der jedem Posenschlüsselpunkt zugewiesenen Beschriftungen ab, was wiederum von der Effektivität des Annotationsprozesses abhängt. Darüber hinaus sorgt die große Menge an vielfältigen und gut kommentierten Daten dafür, dass das Modell ein breites Spektrum an Posen, Variationen und Szenarien erlernen kann, was zu einer verbesserten Generalisierung und Leistung in verschiedenen realen Anwendungen führt. An der Erfassung dieser großen, kommentierten Datensätze sind menschliche Annotatoren beteiligt, die die Bilder sorgfältig mit Poseninformationen kennzeichnen. Beim Beschriften interessanter Punkte im Bild ist es hilfreich, beim Beschriften die Skelettstruktur des Objekts zu sehen, um dem Annotator eine visuelle Orientierung zu geben. Dies ist hilfreich, um Beschriftungsfehler zu identifizieren, bevor sie in den Datensatz integriert werden, wie z. B. Links-Rechts-Vertauschungen oder falsche Beschriftungen (z. B. die Markierung eines Fußes als Schulter). Beispielsweise kann ein Beschriftungsfehler wie der im folgenden Beispiel vorgenommene Links-Rechts-Vertausch leicht an der Kreuzung der Skelett-Rig-Linien und der Nichtübereinstimmung der Farben erkannt werden. Diese visuellen Hinweise helfen Etikettierern, Fehler zu erkennen und führen zu einem saubereren Etikettensatz.
Aufgrund des manuellen Charakters der Kennzeichnung kann die Beschaffung großer und präziser gekennzeichneter Datensätze unerschwingliche Kosten verursachen, und dies gilt umso mehr, wenn das Kennzeichnungssystem ineffizient ist. Daher sind Effizienz und Genauigkeit der Etikettierung bei der Gestaltung Ihres Etikettierungs-Workflows von entscheidender Bedeutung. In diesem Beitrag zeigen wir, wie Sie einen benutzerdefinierten SageMaker Ground Truth-Beschriftungsworkflow verwenden, um Bilder schnell und genau mit Anmerkungen zu versehen und so den Aufwand bei der Entwicklung großer Datensätze für Workflows zur Posenschätzung zu reduzieren.

Lösungsübersicht
Diese Lösung stellt ein Online-Webportal bereit, in dem sich die Beschriftungsmitarbeiter über einen Webbrowser anmelden, auf Beschriftungsaufträge zugreifen und Bilder über die Benutzeroberfläche (UI) von crowd-2d-skeleton kommentieren können, eine benutzerdefinierte Benutzeroberfläche, die für die Beschriftung von Schlüsselpunkten und Posen entwickelt wurde SageMaker-Grundwahrheit. Die vom Etikettierungsteam erstellten Anmerkungen oder Etiketten werden dann in eine exportiert Amazon Simple Storage-Service (Amazon S3)-Bucket, wo sie für nachgelagerte Prozesse wie das Training von Deep-Learning-Computer-Vision-Modellen verwendet werden können. Diese Lösung führt Sie durch die Einrichtung und Bereitstellung der erforderlichen Komponenten zum Erstellen eines Webportals sowie durch die Erstellung von Etikettierungsaufträgen für diesen Etikettierungsworkflow.
Das Folgende ist ein Diagramm der Gesamtarchitektur.

Diese Architektur besteht aus mehreren Schlüsselkomponenten, die wir in den folgenden Abschnitten jeweils ausführlicher erläutern. Diese Architektur stellt den Etikettierungsmitarbeitern ein Online-Webportal zur Verfügung, das von SageMaker Ground Truth gehostet wird. Über dieses Portal kann sich jeder Etikettierer anmelden und seine Etikettieraufträge einsehen. Nachdem er sich angemeldet hat, kann der Etikettierer einen Etikettierungsauftrag auswählen und mit dem Kommentieren von Bildern über die von gehostete benutzerdefinierte Benutzeroberfläche beginnen Amazon CloudFront. Wir gebrauchen AWS Lambda Funktionen für die Datenverarbeitung vor und nach der Annotation.
Der folgende Screenshot ist ein Beispiel für die Benutzeroberfläche.
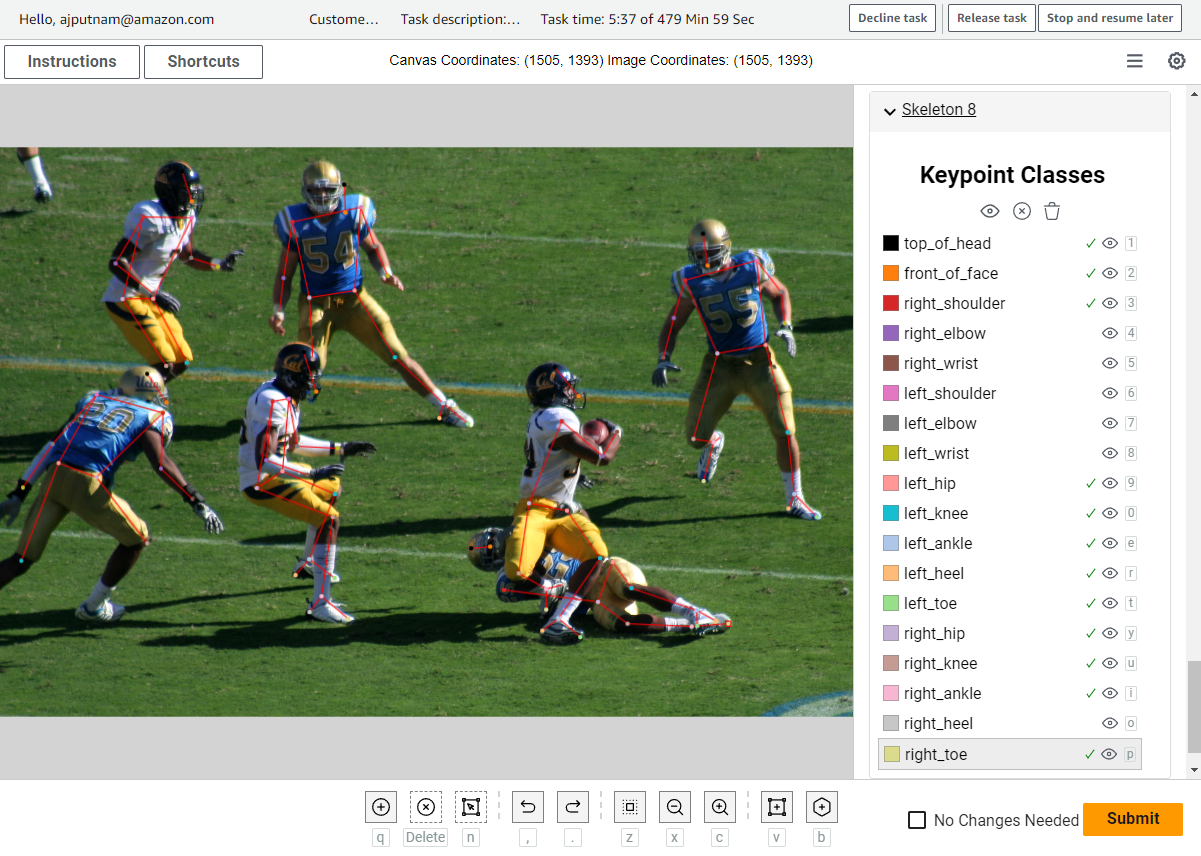
Der Etikettierer kann über die Benutzeroberfläche bestimmte Schlüsselpunkte auf dem Bild markieren. Die Linien zwischen Schlüsselpunkten werden für den Benutzer automatisch basierend auf einer Skelett-Rig-Definition gezeichnet, die die Benutzeroberfläche verwendet. Die Benutzeroberfläche ermöglicht viele Anpassungen, wie zum Beispiel die folgenden:
- Benutzerdefinierte Schlüsselpunktnamen
- Konfigurierbare Schlüsselpunktfarben
- Konfigurierbare Rig-Linienfarben
- Konfigurierbare Skelett- und Rig-Strukturen
Bei jeder dieser Funktionen handelt es sich um gezielte Funktionen zur Verbesserung der Einfachheit und Flexibilität der Etikettierung. Spezifische Details zur UI-Anpassung finden Sie im GitHub Repo und werden später in diesem Beitrag zusammengefasst. Beachten Sie, dass wir in diesem Beitrag die Schätzung der menschlichen Pose als Grundaufgabe verwenden, Sie können diese jedoch erweitern, um die Pose von Objekten mit einem vordefinierten Rig auch für andere Objekte wie Tiere oder Fahrzeuge zu kennzeichnen. Im folgenden Beispiel zeigen wir, wie dies zur Kennzeichnung der Weichen eines Kastenwagens angewendet werden kann.

SageMaker-Grundwahrheit
In dieser Lösung verwenden wir SageMaker Ground Truth, um den Etikettiermitarbeitern ein Online-Portal und eine Möglichkeit zur Verwaltung von Etikettieraufträgen bereitzustellen. In diesem Beitrag wird davon ausgegangen, dass Sie mit SageMaker Ground Truth vertraut sind. Weitere Informationen finden Sie unter Amazon Sagemaker Ground Truth.
CloudFront-Verteilung
Für diese Lösung erfordert die Beschriftungs-Benutzeroberfläche eine benutzerdefinierte JavaScript-Komponente namens crowd-2d-skeleton. Diese Komponente finden Sie auf GitHub als Teil der Open-Source-Initiativen von Amazon. Die CloudFront-Distribution wird zum Hosten verwendet crowd-2d-skeleton.js, das von der SageMaker Ground Truth-Benutzeroberfläche benötigt wird. Der CloudFront-Verteilung wird eine Ursprungszugriffsidentität zugewiesen, die es der CloudFront-Verteilung ermöglicht, auf die crowd-2d-skeleton.js im S3-Bucket zuzugreifen. Der S3-Bucket bleibt privat und keine anderen Objekte in diesem Bucket sind über die CloudFront-Distribution verfügbar, da wir die Ursprungszugriffsidentität durch eine Bucket-Richtlinie einschränken. Dies ist eine empfohlene Vorgehensweise zur Einhaltung des Prinzips der geringsten Privilegien.
Amazon S3 Eimer
Wir verwenden den S3-Bucket, um die Eingabe- und Ausgabemanifestdateien von SageMaker Ground Truth, die benutzerdefinierte UI-Vorlage, Bilder für die Beschriftungsaufträge und den für die benutzerdefinierte Benutzeroberfläche erforderlichen JavaScript-Code zu speichern. Dieser Bucket ist privat und für die Öffentlichkeit nicht zugänglich. Der Bucket verfügt außerdem über eine Bucket-Richtlinie, die die CloudFront-Verteilung darauf beschränkt, nur auf den für die Benutzeroberfläche erforderlichen JavaScript-Code zuzugreifen. Dadurch wird verhindert, dass die CloudFront-Distribution andere Objekte im S3-Bucket hostet.
Lambda-Funktion vor der Annotation
SageMaker Ground Truth-Beschriftungsaufträge verwenden normalerweise eine Eingabemanifestdatei im JSON-Lines-Format. Diese Eingabemanifestdatei enthält Metadaten für einen Beschriftungsauftrag, fungiert als Referenz auf die Daten, die beschriftet werden müssen, und hilft bei der Konfiguration, wie die Daten den Annotatoren präsentiert werden sollen. Die Lambda-Funktion vor der Annotation verarbeitet Elemente aus der Eingabemanifestdatei, bevor die Manifestdaten in die benutzerdefinierte UI-Vorlage eingegeben werden. Hier können Formatierungen oder spezielle Änderungen an den Elementen vorgenommen werden, bevor die Daten den Annotatoren in der Benutzeroberfläche präsentiert werden. Weitere Informationen zu Lambda-Funktionen vor der Annotation finden Sie unter Lambda vor der Anmerkung.
Post-Annotation-Lambda-Funktion
Ähnlich wie die Lambda-Funktion vor der Annotation übernimmt die Funktion nach der Annotation die zusätzliche Datenverarbeitung, die Sie möglicherweise durchführen möchten, nachdem alle Labeler die Beschriftung abgeschlossen haben, aber bevor die endgültigen Ausgabeergebnisse der Annotation geschrieben werden. Diese Verarbeitung erfolgt durch eine Lambda-Funktion, die für die Formatierung der Daten für die Ausgabeergebnisse des Etikettierungsauftrags verantwortlich ist. In dieser Lösung verwenden wir es einfach, um die Daten in unserem gewünschten Ausgabeformat zurückzugeben. Weitere Informationen zu Lambda-Funktionen nach der Annotation finden Sie unter Lambda nach der Anmerkung.
Rolle der Lambda-Funktion nach der Annotation
Wir verwenden eine AWS Identity and Access Management and (IAM)-Rolle, um der Post-Annotation-Lambda-Funktion Zugriff auf den S3-Bucket zu gewähren. Dies ist erforderlich, um die Anmerkungsergebnisse zu lesen und etwaige Änderungen vorzunehmen, bevor die endgültigen Ergebnisse in die Ausgabemanifestdatei geschrieben werden.
SageMaker Ground Truth-Rolle
Wir verwenden diese IAM-Rolle, um dem SageMaker Ground Truth-Beschriftungsauftrag die Möglichkeit zu geben, die Lambda-Funktionen aufzurufen und die Bilder, Manifestdateien und benutzerdefinierten UI-Vorlagen im S3-Bucket zu lesen.
Voraussetzungen:
Für diese exemplarische Vorgehensweise sollten Sie die folgenden Voraussetzungen erfüllen:
Für diese Lösung verwenden wir das AWS CDK, um die Architektur bereitzustellen. Anschließend erstellen wir einen Beispiel-Beschriftungsauftrag, beschriften die Bilder im Beschriftungsauftrag mithilfe des Anmerkungsportals und untersuchen die Beschriftungsergebnisse.
Erstellen Sie den AWS CDK-Stack
Nachdem Sie alle Voraussetzungen erfüllt haben, können Sie die Lösung bereitstellen.
Richten Sie Ihre Ressourcen ein
Führen Sie die folgenden Schritte aus, um Ihre Ressourcen einzurichten:
- Laden Sie den Beispiel-Stack von herunter GitHub Repo.
- Verwenden Sie den Befehl cd, um in das Repository zu wechseln.
- Erstellen Sie Ihre Python-Umgebung und installieren Sie die erforderlichen Pakete (weitere Informationen finden Sie im Repository README.md).
- Führen Sie bei aktivierter Python-Umgebung den folgenden Befehl aus:
- Führen Sie den folgenden Befehl aus, um das AWS CDK bereitzustellen:
- Führen Sie den folgenden Befehl aus, um das Post-Deployment-Skript auszuführen:
Erstellen Sie einen Etikettierauftrag
Nachdem Sie Ihre Ressourcen eingerichtet haben, können Sie einen Etikettierungsauftrag erstellen. Für die Zwecke dieses Beitrags erstellen wir einen Etikettierungsauftrag unter Verwendung der im Repository bereitgestellten Beispielskripte und Bilder.
- CD in die
scriptsVerzeichnis im Repository. - Laden Sie die Beispielbilder aus dem Internet herunter, indem Sie den folgenden Code ausführen:
Dieses Skript lädt einen Satz von 10 Bildern herunter, die wir in unserem Beispiel-Etikettierungsauftrag verwenden. Wir besprechen später in diesem Beitrag, wie Sie Ihre eigenen benutzerdefinierten Eingabedaten verwenden.
- Erstellen Sie einen Etikettierungsauftrag, indem Sie den folgenden Code ausführen:
Dieses Skript verwendet einen privaten Workforce-ARN von SageMaker Ground Truth als Argument. Dies sollte der ARN für einen Workforce sein, den Sie in demselben Konto haben, in dem Sie diese Architektur bereitgestellt haben. Das Skript erstellt die Eingabemanifestdatei für unseren Beschriftungsauftrag, lädt sie auf Amazon S3 hoch und erstellt einen benutzerdefinierten Beschriftungsauftrag für SageMaker Ground Truth. Wir gehen später in diesem Beitrag tiefer auf die Details dieses Skripts ein.
Beschriften Sie den Datensatz
Nachdem Sie den Beispiel-Etikettierungsjob gestartet haben, wird er sowohl auf der SageMaker-Konsole als auch im Workforce-Portal angezeigt.

Wählen Sie im Workforce-Portal den Etikettierungsauftrag aus und wählen Sie Beginne zu arbeiten.

Ihnen wird ein Bild aus dem Beispieldatensatz angezeigt. An dieser Stelle können Sie die benutzerdefinierte Benutzeroberfläche von crowd-2d-skeleton verwenden, um die Bilder mit Anmerkungen zu versehen. Sie können sich mit der Benutzeroberfläche von crowd-2d-skeleton vertraut machen, indem Sie auf klicken Überblick über die Benutzeroberfläche. Wir verwenden die Rig-Definition aus dem Herausforderung für COCO-Schlüsselpunkterkennungsdatensätze als menschliches Posen-Rig. Um es noch einmal zu betonen: Sie können dies ohne unsere benutzerdefinierte UI-Komponente anpassen, um Punkte entsprechend Ihren Anforderungen zu entfernen oder hinzuzufügen.
Wenn Sie mit dem Kommentieren eines Bildes fertig sind, wählen Sie Absenden. Dadurch gelangen Sie zum nächsten Bild im Datensatz, bis alle Bilder beschriftet sind.

Greifen Sie auf die Beschriftungsergebnisse zu
Wenn Sie mit der Beschriftung aller Bilder im Beschriftungsauftrag fertig sind, ruft SageMaker Ground Truth die Post-Annotation-Lambda-Funktion auf und erstellt eine Datei „output.manifest“, die alle Anmerkungen enthält. Das output.manifest wird im S3-Bucket gespeichert. In unserem Fall sollte der Speicherort des Ausgabemanifests dem S3-URI-Pfad folgen s3://<bucket name> /labeling_jobs/output/<labeling job name>/manifests/output/output.manifest. Bei der Datei „output.manifest“ handelt es sich um eine JSON-Zeilendatei, in der jede Zeile einem einzelnen Bild und seinen Anmerkungen von der Beschriftungsgruppe entspricht. Jedes JSON-Lines-Element ist ein JSON-Objekt mit vielen Feldern. Das Feld, das uns interessiert, heißt label-results. Der Wert dieses Feldes ist ein Objekt, das die folgenden Felder enthält:
- dataset_object_id – Die ID oder der Index des Eingabemanifestelements
- data_object_s3_uri – Der Amazon S3-URI des Bildes
- Bilddateiname – Der Dateiname des Bildes
- image_s3_location – Die Amazon S3-URL des Bildes
- original_annotations – Die ursprünglichen Anmerkungen (nur festgelegt und verwendet, wenn Sie einen Voranmerkungs-Workflow verwenden)
- aktualisierte_annotationen – Die Anmerkungen zum Bild
- worker_id – Der Mitarbeiter, der die Anmerkungen gemacht hat
- no_changes_needed – Ob das Kontrollkästchen Keine Änderungen erforderlich aktiviert wurde
- wurde modifiziert – Ob sich die Anmerkungsdaten von den ursprünglichen Eingabedaten unterscheiden
- total_time_in_seconds – Die Zeit, die der Mitarbeiter benötigte, um das Bild mit Anmerkungen zu versehen
Mit diesen Feldern können Sie auf Ihre Anmerkungsergebnisse für jedes Bild zugreifen und Berechnungen wie die durchschnittliche Zeit zum Beschriften eines Bildes durchführen.
Erstellen Sie Ihre eigenen Etikettierungsaufträge
Nachdem wir nun einen Beispiel-Labeling-Job erstellt haben und Sie den Gesamtprozess verstehen, führen wir Sie durch den Code, der für die Erstellung der Manifestdatei und das Starten des Labeling-Jobs verantwortlich ist. Wir konzentrieren uns auf die wichtigsten Teile des Skripts, die Sie möglicherweise ändern möchten, um Ihre eigenen Etikettierungsaufträge zu starten.
Wir behandeln Codeausschnitte aus dem create_example_labeling_job.py Skript befindet sich in der GitHub-Repository. Das Skript beginnt mit der Einrichtung von Variablen, die später im Skript verwendet werden. Einige der Variablen sind der Einfachheit halber fest codiert, während andere, die vom Stapel abhängig sind, dynamisch zur Laufzeit importiert werden, indem die von unserem AWS CDK-Stack erstellten Werte abgerufen werden.
Der erste wichtige Abschnitt in diesem Skript ist die Erstellung der Manifestdatei. Denken Sie daran, dass es sich bei der Manifestdatei um eine JSON-Zeilendatei handelt, die die Details für einen SageMaker Ground Truth-Beschriftungsauftrag enthält. Jedes JSON-Lines-Objekt stellt ein Element (z. B. ein Bild) dar, das beschriftet werden muss. Für diesen Workflow sollte das Objekt die folgenden Felder enthalten:
- Quellenangabe – Der Amazon S3-URI für das Bild, das Sie kennzeichnen möchten.
- Anmerkungen – Eine Liste von Anmerkungsobjekten, die zum Voranmerken von Arbeitsabläufen verwendet wird. Siehe die Crowd-2D-Skeleton-Dokumentation Weitere Einzelheiten zu den erwarteten Werten finden Sie hier.
Das Skript erstellt für jedes Bild im Bildverzeichnis eine Manifestzeile mit dem folgenden Codeabschnitt:
Wenn Sie andere Bilder verwenden oder auf ein anderes Bildverzeichnis verweisen möchten, können Sie diesen Abschnitt des Codes ändern. Wenn Sie außerdem einen Arbeitsablauf vor der Annotation verwenden, können Sie das Annotations-Array mit einer JSON-Zeichenfolge aktualisieren, die aus dem Array und allen seinen Annotationsobjekten besteht. Die Details des Formats dieses Arrays sind in dokumentiert Crowd-2D-Skeleton-Dokumentation.
Mit den nun erstellten Manifest-Einzelposten können Sie die Manifestdatei erstellen und in den S3-Bucket hochladen, den Sie zuvor erstellt haben:
Nachdem Sie nun eine Manifestdatei mit den Bildern erstellt haben, die Sie kennzeichnen möchten, können Sie einen Kennzeichnungsauftrag erstellen. Sie können den Etikettierungsauftrag programmgesteuert mit erstellen AWS SDK für Python (Boto3). Der Code zum Erstellen eines Etikettierungsauftrags lautet wie folgt:
Folgende Aspekte dieses Codes möchten Sie möglicherweise ändern: LabelingJobName, TaskTitle und TaskDescriptiondem „Vermischten Geschmack“. Seine LabelingJobName ist der eindeutige Name des Etikettierungsauftrags, den SageMaker zur Referenzierung Ihres Auftrags verwendet. Dies ist auch der Name, der auf der SageMaker-Konsole angezeigt wird. TaskTitle dient einem ähnlichen Zweck, muss jedoch nicht eindeutig sein und ist der Name der Stelle, die im Workforce-Portal angezeigt wird. Möglicherweise möchten Sie diese spezifischer auf das ausrichten, was Sie etikettieren oder wozu die Etikettierungsaufgabe dienen soll. Zuletzt haben wir die TaskDescription Feld. Dieses Feld wird im Workforce-Portal angezeigt, um den Etikettierern zusätzlichen Kontext zur Art der Aufgabe bereitzustellen, z. B. Anweisungen und Anleitungen für die Aufgabe. Weitere Informationen zu diesen und den anderen Feldern finden Sie im create_labeling_job-Dokumentation.
Nehmen Sie Anpassungen an der Benutzeroberfläche vor
In diesem Abschnitt gehen wir auf einige Möglichkeiten ein, wie Sie die Benutzeroberfläche anpassen können. Im Folgenden finden Sie eine Liste der häufigsten möglichen Anpassungen der Benutzeroberfläche, um sie an Ihre Modellierungsaufgabe anzupassen:
- Sie können festlegen, welche Schlüsselpunkte beschriftet werden können. Dazu gehören der Name des Schlüsselpunkts und seine Farbe.
- Sie können die Struktur des Skeletts ändern (welche Schlüsselpunkte verbunden sind).
- Sie können die Linienfarben für bestimmte Linien zwischen bestimmten Schlüsselpunkten ändern.
Alle diese UI-Anpassungen können durch Argumente konfiguriert werden, die an die Crowd-2D-Skeleton-Komponente übergeben werden, bei der es sich um die hier verwendete JavaScript-Komponente handelt benutzerdefinierte Workflow-Vorlage. In dieser Vorlage finden Sie die Verwendung der Crowd-2D-Skeleton-Komponente. Eine vereinfachte Version ist im folgenden Code dargestellt:
Im vorherigen Codebeispiel können Sie die folgenden Attribute der Komponente sehen: imgSrc, keypointClasses, skeletonRig, skeletonBoundingBox und intialValues. Wir beschreiben den Zweck jedes Attributs in den folgenden Abschnitten, aber das Anpassen der Benutzeroberfläche ist so einfach wie das Ändern der Werte für diese Attribute, das Speichern der Vorlage und das erneute Ausführen post_deployment_script.py die wir zuvor verwendet haben.
imgSrc-Attribut
Das imgSrc Das Attribut steuert, welches Bild beim Beschriften in der Benutzeroberfläche angezeigt werden soll. Normalerweise wird für jede Manifestzeile ein anderes Bild verwendet, daher wird dieses Attribut häufig mithilfe der integrierten Funktion dynamisch ausgefüllt Flüssigkeit Vorlagesprache. Im vorherigen Codebeispiel können Sie sehen, dass der Attributwert auf festgelegt ist {{ task.input.image_s3_uri | grant_read_access }}, eine Liquid-Vorlagenvariable, die durch die tatsächliche ersetzt wird image_s3_uri Wert, wenn die Vorlage gerendert wird. Der Rendervorgang beginnt, wenn der Benutzer ein Bild zur Kommentierung öffnet. Dieser Prozess ruft eine Zeile aus der Eingabemanifestdatei ab und sendet sie als eine an die Lambda-Funktion vor der Annotation event.dataObject. Die Voranmerkungsfunktion entnimmt der Werbebuchung die benötigten Informationen und gibt a zurück taskInput Wörterbuch, das dann an die Liquid-Rendering-Engine übergeben wird, die alle Liquid-Variablen in Ihrer Vorlage ersetzt. Nehmen wir zum Beispiel an, Sie haben eine Manifestdatei mit der folgenden Zeile:
Diese Daten würden an die Voranmerkungsfunktion übergeben. Der folgende Code zeigt, wie die Funktion die Werte aus dem Ereignisobjekt extrahiert:
Das von der Funktion zurückgegebene Objekt würde in diesem Fall wie der folgende Code aussehen:
Die von der Funktion zurückgegebenen Daten stehen dann der Liquid-Vorlagen-Engine zur Verfügung, die die Vorlagenwerte in der Vorlage durch die von der Funktion zurückgegebenen Datenwerte ersetzt. Das Ergebnis wäre etwa der folgende Code:
keypointClasses-Attribut
Das keypointClasses Das Attribut definiert, welche Schlüsselpunkte in der Benutzeroberfläche angezeigt und von den Annotatoren verwendet werden. Dieses Attribut akzeptiert einen JSON-String, der eine Liste von Objekten enthält. Jedes Objekt stellt einen Schlüsselpunkt dar. Jedes Schlüsselpunktobjekt sollte die folgenden Felder enthalten:
- id – Ein eindeutiger Wert zur Identifizierung dieses Schlüsselpunkts.
- Farbe – Die Farbe des Schlüsselpunkts, dargestellt als HTML-Hex-Farbe.
- Etikette – Der Name oder die Schlüsselpunktklasse.
- x – Dieses optionale Attribut ist nur erforderlich, wenn Sie die Funktion zum Zeichnen eines Skeletts in der Benutzeroberfläche verwenden möchten. Der Wert für dieses Attribut ist die x-Position des Schlüsselpunkts relativ zum Begrenzungsrahmen des Skeletts. Dieser Wert wird normalerweise durch ermittelt Skeleton Rig Creator-Tool. Wenn Sie Schlüsselpunktanmerkungen erstellen und nicht das gesamte Skelett auf einmal zeichnen müssen, können Sie diesen Wert auf 0 setzen.
- y – Dieses optionale Attribut ähnelt x, jedoch für die vertikale Dimension.
Für weitere Informationen über die keypointClasses Attribut finden Sie im keypointClasses-Dokumentation.
SkeletonRig-Attribut
Das skeletonRig Das Attribut steuert, zwischen welchen Schlüsselpunkten Linien gezeichnet werden sollen. Dieses Attribut akzeptiert eine JSON-Zeichenfolge, die eine Liste von Schlüsselpunkt-Beschriftungspaaren enthält. Jedes Paar teilt der Benutzeroberfläche mit, zwischen welchen Schlüsselpunkten Linien gezogen werden sollen. Zum Beispiel, '[["left_ankle","left_knee"],["left_knee","left_hip"]]' Informiert die Benutzeroberfläche, Linien dazwischen zu zeichnen "left_ankle" und "left_knee" und zeichne Linien dazwischen "left_knee" und "left_hip". Dies kann durch die erzeugt werden Skeleton Rig Creator-Tool.
SkeletonBoundingBox-Attribut
Das skeletonBoundingBox Das Attribut ist optional und wird nur benötigt, wenn Sie die Funktion zum Zeichnen eines Skeletts in der Benutzeroberfläche verwenden möchten. Die Funktion „Skelett zeichnen“ bietet die Möglichkeit, ganze Skelette mit einer einzigen Anmerkungsaktion zu kommentieren. Auf diese Funktion gehen wir in diesem Beitrag nicht ein. Der Wert für dieses Attribut sind die Abmessungen des Begrenzungsrahmens des Skeletts. Dieser Wert wird normalerweise durch ermittelt Skeleton Rig Creator-Tool. Wenn Sie Schlüsselpunktanmerkungen erstellen und nicht das gesamte Skelett auf einmal zeichnen müssen, können Sie diesen Wert auf Null setzen. Es wird empfohlen, das Skeleton Rig Creator-Tool zu verwenden, um diesen Wert zu erhalten.
intialValues-Attribut
Das initialValues Das Attribut wird verwendet, um die Benutzeroberfläche vorab mit Anmerkungen zu füllen, die aus einem anderen Prozess stammen (z. B. einem anderen Etikettierungsauftrag oder einem Modell für maschinelles Lernen). Dies ist nützlich, wenn Sie Anpassungs- oder Überprüfungsarbeiten durchführen. Die Daten für dieses Feld werden normalerweise dynamisch in derselben Beschreibung für das ausgefüllt imgSrc Attribut. Weitere Details finden Sie im Crowd-2D-Skeleton-Dokumentation.
Aufräumen
Um zukünftige Gebühren zu vermeiden, sollten Sie die Objekte in Ihrem S3-Bucket löschen und Ihren AWS CDK-Stack löschen. Sie können Ihre S3-Objekte über die Amazon SageMaker-Konsole oder das löschen AWS-Befehlszeilenschnittstelle (AWS CLI). Nachdem Sie alle S3-Objekte im Bucket gelöscht haben, können Sie das AWS CDK zerstören, indem Sie den folgenden Code ausführen:
Dadurch werden die zuvor erstellten Ressourcen entfernt.
Überlegungen
Möglicherweise sind zusätzliche Schritte erforderlich, um Ihren Workflow produktiv zu gestalten. Abhängig vom Risikoprofil Ihres Unternehmens sind hier einige Überlegungen aufgeführt:
- Zugriffs- und Anwendungsprotokollierung hinzufügen
- Hinzufügen einer Web Application Firewall (WAF)
- Anpassen der IAM-Berechtigungen an die geringste Berechtigung
Zusammenfassung
In diesem Beitrag haben wir die Bedeutung der Kennzeichnungseffizienz und -genauigkeit beim Erstellen von Posenschätzungsdatensätzen hervorgehoben. Um bei beiden Punkten zu helfen, haben wir gezeigt, wie Sie mit SageMaker Ground Truth benutzerdefinierte Beschriftungsworkflows erstellen können, um skelettbasierte Posenbeschriftungsaufgaben zu unterstützen und so die Effizienz und Präzision während des Beschriftungsprozesses zu verbessern. Wir haben gezeigt, wie Sie den Code und die Beispiele auf verschiedene Beschriftungsanforderungen für benutzerdefinierte Posenschätzungen erweitern können.
Wir empfehlen Ihnen, diese Lösung für Ihre Etikettierungsaufgaben zu verwenden und sich für Unterstützung oder Anfragen zu benutzerdefinierten Etikettierungs-Workflows an AWS zu wenden.
Über die Autoren
 Artur Putnam ist ein Full-Stack-Datenwissenschaftler bei AWS Professional Services. Arthurs Fachwissen konzentriert sich auf die Entwicklung und Integration von Front-End- und Back-End-Technologien in KI-Systeme. Außerhalb der Arbeit erkundet Arthur gerne die neuesten Fortschritte in der Technologie, verbringt Zeit mit seiner Familie und genießt die Natur.
Artur Putnam ist ein Full-Stack-Datenwissenschaftler bei AWS Professional Services. Arthurs Fachwissen konzentriert sich auf die Entwicklung und Integration von Front-End- und Back-End-Technologien in KI-Systeme. Außerhalb der Arbeit erkundet Arthur gerne die neuesten Fortschritte in der Technologie, verbringt Zeit mit seiner Familie und genießt die Natur.
 Ben Fenker ist Senior Data Scientist bei AWS Professional Services und hat Kunden dabei geholfen, ML-Lösungen in Branchen wie Sport, Gesundheitswesen und Fertigung zu entwickeln und bereitzustellen. Er hat einen Ph.D. in Physik von der Texas A&M University und 6 Jahre Branchenerfahrung. Ben genießt Baseball, liest und erzieht seine Kinder.
Ben Fenker ist Senior Data Scientist bei AWS Professional Services und hat Kunden dabei geholfen, ML-Lösungen in Branchen wie Sport, Gesundheitswesen und Fertigung zu entwickeln und bereitzustellen. Er hat einen Ph.D. in Physik von der Texas A&M University und 6 Jahre Branchenerfahrung. Ben genießt Baseball, liest und erzieht seine Kinder.
 Jarvis Lee ist Senior Data Scientist bei AWS Professional Services. Er ist seit über sechs Jahren bei AWS und arbeitet mit Kunden an maschinellen Lern- und Computer-Vision-Problemen. Außerhalb der Arbeit fährt er gerne Fahrrad.
Jarvis Lee ist Senior Data Scientist bei AWS Professional Services. Er ist seit über sechs Jahren bei AWS und arbeitet mit Kunden an maschinellen Lern- und Computer-Vision-Problemen. Außerhalb der Arbeit fährt er gerne Fahrrad.
- SEO-gestützte Content- und PR-Distribution. Holen Sie sich noch heute Verstärkung.
- PlatoData.Network Vertikale generative KI. Motiviere dich selbst. Hier zugreifen.
- PlatoAiStream. Web3-Intelligenz. Wissen verstärkt. Hier zugreifen.
- PlatoESG. Kohlenstoff, CleanTech, Energie, Umwelt, Solar, Abfallwirtschaft. Hier zugreifen.
- PlatoHealth. Informationen zu Biotechnologie und klinischen Studien. Hier zugreifen.
- Quelle: https://aws.amazon.com/blogs/machine-learning/skeleton-based-pose-annotation-labeling-using-amazon-sagemaker-ground-truth/

