When a customer has a production-ready intelligent document processing (IDP) workload, we often receive requests for a Well-Architected review. To build an enterprise solution, developer resources, cost, time and user-experience have to be balanced to achieve the desired business outcome. The AWS Well-Architected Framework provides a systematic way for organizations to learn operational and architectural best practices for designing and operating reliable, secure, efficient, cost-effective, and sustainable workloads in the cloud.
The IDP Well-Architected Custom Lens follows the AWS Well-Architected Framework, reviewing the solution with six pillars with the granularity of a specific AI or machine learning (ML) use case, and providing the guidance to tackle common challenges. The IDP Well-Architected Custom Lens in the Well-Architected Tool contains questions regarding each of the pillars. By answering these questions, you can identify potential risks and resolve them by following your improvement plan.
This post focuses on the Performance Efficiency pillar of the IDP workload. We dive deep into designing and implementing the solution to optimize for throughput, latency, and overall performance. We start with discussing some common indicators that you should conduct a Well-Architected review, and introduce the fundamental approaches with design principles. Then we go through each focus area from a technical perspective.
To follow along with this post, you should be familiar with the previous posts in this series (Part 1 and Part 2) and the guidelines in Guidance for Intelligent Document Processing on AWS. These resources introduce common AWS services for IDP workloads and suggested workflows. With this knowledge, you’re now ready to learn more about productionizing your workload.
Common indicators
The following are common indicators that you should conduct a Well-Architected Framework review for the Performance Efficiency pillar:
- High latency – When the latency of optical character recognition (OCR), entity recognition, or the end-to-end workflow takes longer than your previous benchmark, this may be an indicator that the architecture design doesn’t cover load testing or error handling.
- Frequent throttling – You may experience throttling by AWS services like Amazon Textract due to request limits. This means that the architecture needs to be adjusted by reviewing the architecture workflow, synchronous and asynchronous implementation, transactions per second (TPS) calculation, and more.
- Debugging difficulties – When there’s a document process failure, you may not have an effective way to identify where the error is located in the workflow, which service it’s related to, and why the failure occurred. This means the system lacks visibility into logs and failures. Consider revisiting the logging design of the telemetry data and adding infrastructure as code (IaC), such as document processing pipelines, to the solution.
| Indicators | Description | Architectural Gap |
| High Latency | OCR, entity recognition, or end-to-end workflow latency exceeds previous benchmark |
|
| Frequent Throttling | Throttling by AWS services like Amazon Textract due to request limits |
|
| Hard to Debug | No visibility into location, cause, and reason for document processing failures |
|
Design principles
In this post, we discuss three design principles: delegating complex AI tasks, IaC architectures, and serverless architectures. When you encounter a trade-off between two implementations, you can revisit the design principles with the business priorities of your organization so that you can make decisions effectively.
- Delegating complex AI tasks – You can enable faster AI adoption in your organization by offloading the ML model development lifecycle to managed services and taking advantage of the model development and infrastructure provided by AWS. Rather than requiring your data science and IT teams to build and maintain AI models, you can use pre-trained AI services that can automate tasks for you. This allows your teams to focus on higher-value work that differentiates your business, while the cloud provider handles the complexity of training, deploying, and scaling the AI models.
- IaC architectures – When running an IDP solution, the solution includes multiple AI services to perform the end-to-end workflow chronologically. You can architect the solution with workflow pipelines using AWS Step Functions to enhance fault tolerance, parallel processing, visibility, and scalability. These advantages can enable you to optimize the usage and cost of underlying AI services.
- Serverless architectures – IDP is often an event-driven solution, initiated by user uploads or scheduled jobs. The solution can be horizontally scaled out by increasing the call rates for the AI services, AWS Lambda, and other services involved. A serverless approach provides scalability without over-provisioning resources, preventing unnecessary expenses. The monitoring behind the serverless design assists in detecting performance issues.
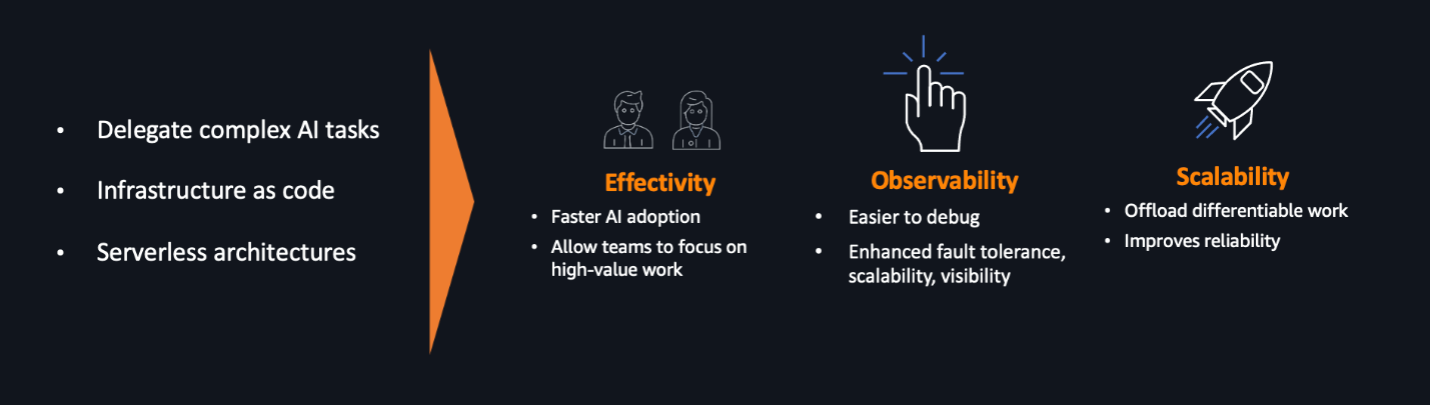
Figure 1.The benefit when applying design principles.
With these three design principles in mind, organizations can establish an effective foundation for AI/ML adoption on cloud platforms. By delegating complexity, implementing resilient infrastructure, and designing for scale, organizations can optimize their AI/ML solutions.
In the following sections, we discuss how to address common challenges in regards to technical focus areas.
Focus areas
When reviewing performance efficiency, we review the solution from five focus areas: architecture design, data management, error handling, system monitoring, and model monitoring. With these focus areas, you can conduct an architecture review from different aspects to enhance the effectivity, observability, and scalability of the three components of an AI/ML project, data, model, or business goal.
Architecture design
By going through the questions in this focus area, you will review the existing workflow to see if it follows best practices. The suggested workflow provides a common pattern that organizations can follow and prevents trial-and-error costs.
Based on the proposed architecture, the workflow follows the six stages of data capture, classification, extraction, enrichment, review and validation, and consumption. In the common indicators we discussed earlier, two out of three come from architecture design problems. This is because when you start a project with an improvised approach, you may meet project restraints when trying to align your infrastructure to your solution. With the architecture design review, the improvised design can be decoupled as stages, and each of them can be reevaluated and reordered.
You can save time, money, and labor by implementing classifications in your workflow, and documents go to downstream applications and APIs based on document type. This enhances the observability of the document process and makes the solution straightforward to maintain when adding new document types.
Data management
Performance of an IDP solution includes latency, throughput, and the end-to-end user experience. How to manage the document and its extracted information in the solution is the key to data consistency, security, and privacy. Additionally, the solution must handle high data volumes with low latency and high throughput.
When going through the questions of this focus area, you will review the document workflow. This includes data ingestion, data preprocessing, converting documents to document types accepted by Amazon Textract, handling incoming document streams, routing documents by type, and implementing access control and retention policies.
For example, by storing a document in the different processed phases, you can reverse processing to the previous step if needed. The data lifecycle ensures the reliability and compliance for the workload. By using the Amazon Textract Service Quotas Calculator (see the following screenshot), asynchronous features on Amazon Textract, Lambda, Step Functions, Amazon Simple Queue Service (Amazon SQS), and Amazon Simple Notification Service (Amazon SNS), organizations can automate and scale document processing tasks to meet specific workload needs.
Figure 2. Amazon Textract Service Quota Calculator.
Error handling
Robust error handling is critical for tracking the document process status, and it provides the operation team time to react to any abnormal behaviors, such as unexpected document volumes, new document types, or other unplanned issues from third-party services. From the organization’s perspective, proper error handling can enhance system uptime and performance.
You can break down error handling into two key aspects:
- AWS service configuration – You can implement retry logic with exponential backoff to handle transient errors like throttling. When you start processing by calling an asynchronous Start* operation, such as StartDocumentTextDetection, you can specify that the completion status of the request is published to an SNS topic in the NotificationChannel configuration. This helps you avoid throttling limits on API calls due to polling the Get* APIs. You can also implement alarms in Amazon CloudWatch and triggers to alert when unusual error spikes occur.
- Error report enhancement – This includes detailed messages with an appropriate level of detail by error type and descriptions of error handling responses. With the proper error handling setup, systems can be more resilient by implementing common patterns like automatically retrying intermittent errors, using circuit breakers to handle cascading failures, and monitoring services to gain insight into errors. This allows the solution to balance between retry limits and prevents never-ending circuit loops.
Model monitoring
The performance of ML models is monitored for degradation over time. As data and system conditions change, the model performance and efficiency metrics are tracked to ensure retraining is performed when needed.
The ML model in an IDP workflow can be an OCR model, entity recognition model, or classification model. The model can come from an AWS AI service, an open source model on Amazon SageMaker, Amazon Bedrock, or other third-party services. You must understand the limitations and use cases of each service in order to identify ways to improve the model with human feedback and enhance service performance over time.
A common approach is using service logs to understand different levels of accuracy. These logs can help the data science team identify and understand any need for model retraining. Your organization can choose the retraining mechanism—it can be quarterly, monthly, or based on science metrics, such as when accuracy drops below a given threshold.
The goal of monitoring is not just detecting issues, but closing the loop to continuously refine models and keep the IDP solution performing as the external environment evolves.
System monitoring
After you deploy the IDP solution in production, it’s important to monitor key metrics and automation performance to identify areas for improvement. The metrics should include business metrics and technical metrics. This allows the company to evaluate the system’s performance, identify issues, and make improvements to models, rules, and workflows over time to increase the automation rate to understand the operational impact.
On the business side, metrics like extraction accuracy for important fields, overall automation rate indicating the percentage of documents processed without human intervention, and average processing time per document are paramount. These business metrics help quantify the end-user experience and operational efficiency gains.
Technical metrics including error and exception rates occurring throughout the workflow are essential to track from an engineering perspective. The technical metrics can also monitor at each level from end to end and provide a comprehensive view of a complex workload. You can break the metrics down into different levels, such as solution level, end-to-end workflow level, document type level, document level, entity recognition level, and OCR level.
Now that you have reviewed all the questions in this pillar, you can assess the other pillars and develop an improvement plan for your IDP workload.
Conclusion
In this post, we discussed common indicators that you may need to perform a Well-Architected Framework review for the Performance Efficiency pillar for your IDP workload. We then walked through design principles to provide a high-level overview and discuss the solution goal. By following these suggestions in reference to the IDP Well-Architected Custom Lens and by reviewing the questions by focus area, you should now have a project improvement plan.
About the Authors
 Mia Chang is a ML Specialist Solutions Architect for Amazon Web Services. She works with customers in EMEA and shares best practices for running AI/ML workloads on the cloud with her background in applied mathematics, computer science, and AI/ML. She focuses on NLP-specific workloads, and shares her experience as a conference speaker and a book author. In her free time, she enjoys hiking, board games, and brewing coffee.
Mia Chang is a ML Specialist Solutions Architect for Amazon Web Services. She works with customers in EMEA and shares best practices for running AI/ML workloads on the cloud with her background in applied mathematics, computer science, and AI/ML. She focuses on NLP-specific workloads, and shares her experience as a conference speaker and a book author. In her free time, she enjoys hiking, board games, and brewing coffee.
 Brijesh Pati is an Enterprise Solutions Architect at AWS. His primary focus is helping enterprise customers adopt cloud technologies for their workloads. He has a background in application development and enterprise architecture and has worked with customers from various industries such as sports, finance, energy and professional services. His interests include serverless architectures and AI/ML.
Brijesh Pati is an Enterprise Solutions Architect at AWS. His primary focus is helping enterprise customers adopt cloud technologies for their workloads. He has a background in application development and enterprise architecture and has worked with customers from various industries such as sports, finance, energy and professional services. His interests include serverless architectures and AI/ML.
 Rui Cardoso is a partner solutions architect at Amazon Web Services (AWS). He is focusing on AI/ML and IoT. He works with AWS Partners and support them in developing solutions in AWS. When not working, he enjoys cycling, hiking and learning new things.
Rui Cardoso is a partner solutions architect at Amazon Web Services (AWS). He is focusing on AI/ML and IoT. He works with AWS Partners and support them in developing solutions in AWS. When not working, he enjoys cycling, hiking and learning new things.
 Tim Condello is a senior artificial intelligence (AI) and machine learning (ML) specialist solutions architect at Amazon Web Services (AWS). His focus is natural language processing and computer vision. Tim enjoys taking customer ideas and turning them into scalable solutions.
Tim Condello is a senior artificial intelligence (AI) and machine learning (ML) specialist solutions architect at Amazon Web Services (AWS). His focus is natural language processing and computer vision. Tim enjoys taking customer ideas and turning them into scalable solutions.
 Sherry Ding is a senior artificial intelligence (AI) and machine learning (ML) specialist solutions architect at Amazon Web Services (AWS). She has extensive experience in machine learning with a PhD degree in computer science. She mainly works with public sector customers on various AI/ML related business challenges, helping them accelerate their machine learning journey on the AWS Cloud. When not helping customers, she enjoys outdoor activities.
Sherry Ding is a senior artificial intelligence (AI) and machine learning (ML) specialist solutions architect at Amazon Web Services (AWS). She has extensive experience in machine learning with a PhD degree in computer science. She mainly works with public sector customers on various AI/ML related business challenges, helping them accelerate their machine learning journey on the AWS Cloud. When not helping customers, she enjoys outdoor activities.
 Suyin Wang is an AI/ML Specialist Solutions Architect at AWS. She has an interdisciplinary education background in Machine Learning, Financial Information Service and Economics, along with years of experience in building Data Science and Machine Learning applications that solved real-world business problems. She enjoys helping customers identify the right business questions and building the right AI/ML solutions. In her spare time, she loves singing and cooking.
Suyin Wang is an AI/ML Specialist Solutions Architect at AWS. She has an interdisciplinary education background in Machine Learning, Financial Information Service and Economics, along with years of experience in building Data Science and Machine Learning applications that solved real-world business problems. She enjoys helping customers identify the right business questions and building the right AI/ML solutions. In her spare time, she loves singing and cooking.
- SEO Powered Content & PR Distribution. Get Amplified Today.
- PlatoData.Network Vertical Generative Ai. Empower Yourself. Access Here.
- PlatoAiStream. Web3 Intelligence. Knowledge Amplified. Access Here.
- PlatoESG. Carbon, CleanTech, Energy, Environment, Solar, Waste Management. Access Here.
- PlatoHealth. Biotech and Clinical Trials Intelligence. Access Here.
- Source: https://aws.amazon.com/blogs/machine-learning/build-well-architected-idp-solutions-with-a-custom-lens-part-4-performance-efficiency/

