In the items view, items are provided in the form of a timely ordered list, with every item containing additional metadata information:
{ "results": { "items": [ { "channel_label": "ch_0", "start_time": "1.509", "speaker_label": "spk_0", "end_time": "2.21", "alternatives": [ { "confidence": "0.999", "content": "Hi" } ], "type": "pronunciation" }, { "channel_label": "ch_0", "speaker_label": "spk_0", "alternatives": [ { "confidence": "0.0", "content": "," } ], "type": "punctuation" }, { "channel_label": "ch_0", "start_time": "2.22", "speaker_label": "spk_0", "end_time": "2.9", "alternatives": [ { "confidence": "0.999", "content": "welcome" } ], "type": "pronunciation" }, { "channel_label": "ch_0", "speaker_label": "spk_0", "alternatives": [ { "confidence": "0.0", "content": "." } ], "type": "punctuation" } ] }
}
The metadata is as follows:
- Type – The type value indicates if the specific item is a punctuation or a pronunciation. Examples of supported punctuations are comma, full stop, and question mark.
- Alternatives – An array of objects containing the actual transcription, along with confidence level, ordered by confidence level. When alternative results feature is not enabled, this list always has one item only.
- Confidence – An indication of how confident Amazon Transcribe is about the correctness of transcription. It uses values from 0–1, with 1 indicating 100% confidence.
- Content – The transcribed word.
- Start time – A time pointer of the audio or video file indicating the start of the item in ss.SSS format.
- End time – A time pointer of the audio or video file indicating the end of the item in ss.SSS format.
- Channel label – The channel identifier, which is present in the item only when the channel identification feature was enabled in the job configuration.
- Speaker label – The speaker identifier, which is present in the item only when the speaker partitioning feature was enabled in the job configuration.
Identifying paragraphs
Identification of paragraphs relies on metadata information in the items view. In particular, we utilize start and end time information along with transcription type and content to identify sentences and then decide which sentences are the best candidates for paragraph entry points.
A sentence is considered to be a list of transcription items that exists between punctuation items that indicate full stop. Exceptions to this are the start and end of the transcript, which are by default sentence boundaries. The following figure shows an example of these items.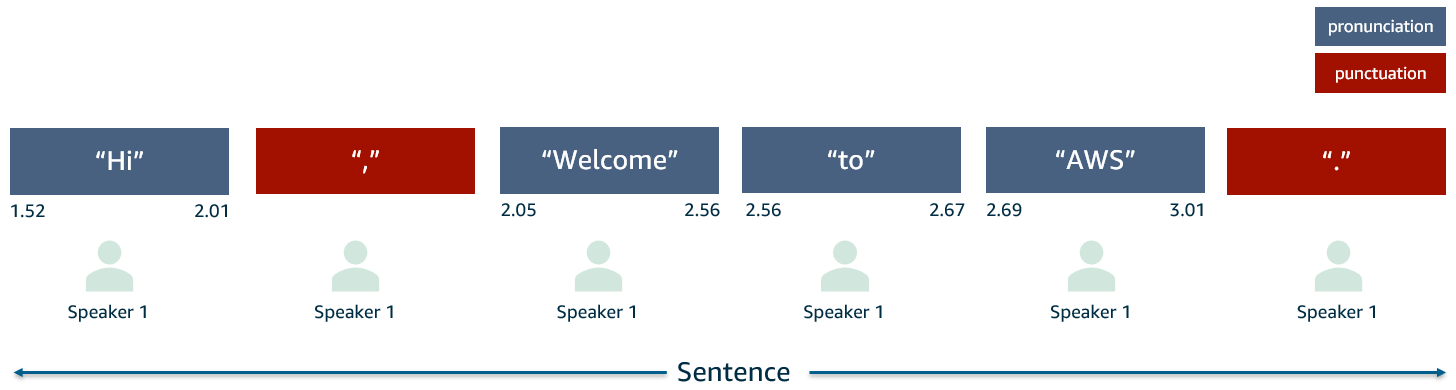
Sentence identification is straightforward with Amazon Transcribe because punctuation is an out-of-the-box feature, along with the punctuation types comma, full stop, question mark. In this concept, we utilize a full stop as the sentence boundary.
Not every sentence should be a paragraph point. To identify paragraphs, we introduce a new insight at the sentence level called a start delay, as illustrated in the following figure. We use a start delay to define the time delay the speaker introduces to the pronunciation of the current sentence in comparison to the previous one.
Calculation of the start delay requires the start time of the current sentence and end time of the previous one per speaker. Because Amazon Transcribe provides start and end times per item, the calculation requires the usage of the first and last items of the current and previous sentences, respectively.
Knowing the start delays of every sentence, we can apply statistical analysis and figure out the significance of every delay in comparison to the total population of delays. In our context, significant delays are those that are over the population’s typical duration. The following graph shows an example.
For this concept, we decide to accept the sentences with start delays greater than the mean value as significant, and introduce a paragraph point at the beginning of every such sentence. Apart from the mean value, there are other options, like accepting all start delays greater than the median, or third quantile or upper fence value of the population.
We add one more additional step to the paragraph identification process, taking into consideration the number of words contained by each paragraph. When paragraphs contain a significant number of words, we run a split operation, thereby adding one more paragraph to the final result.
In the context of word counts, we define as significant the word counts that exceed the upper fence value. We make this decision deliberately, so that we restrict split operations to the paragraphs that truly behave as outliers in our results. The following graph shows an example.
The split operation selects the new paragraph entry point by considering the maximum sentence start delay insight. This way, the new paragraph is introduced at the sentence that exhibits the max start delay inside the current paragraph. Splits can be repeated until no word count exceeds the selected boundary, in our case the upper fence value. The following figure shows an example.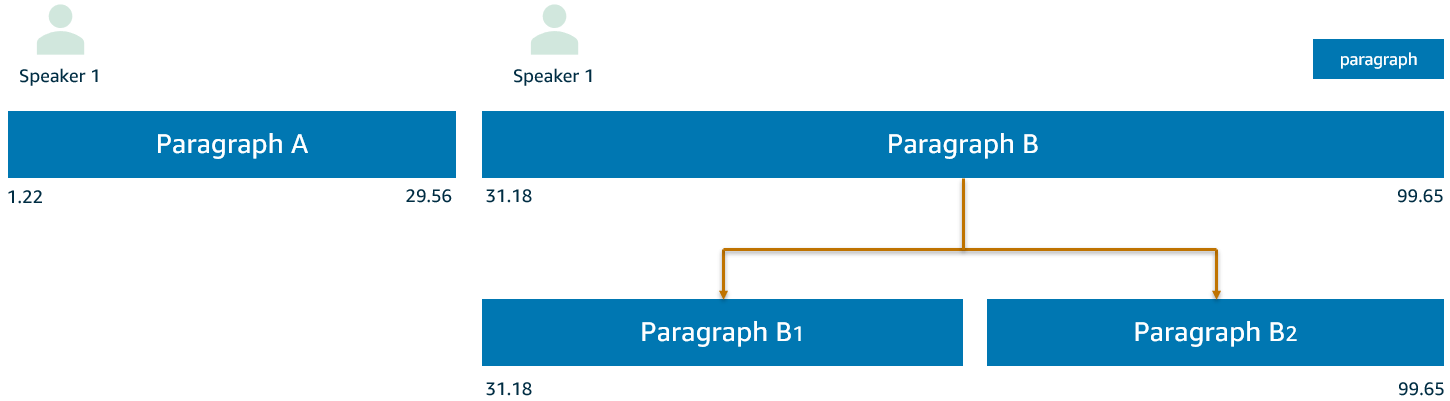
Conclusion
In this post, we presented a concept to automatically introduce paragraphs to your transcripts, without manual intervention, based on the metadata Amazon Transcribe provides along with the actual transcript.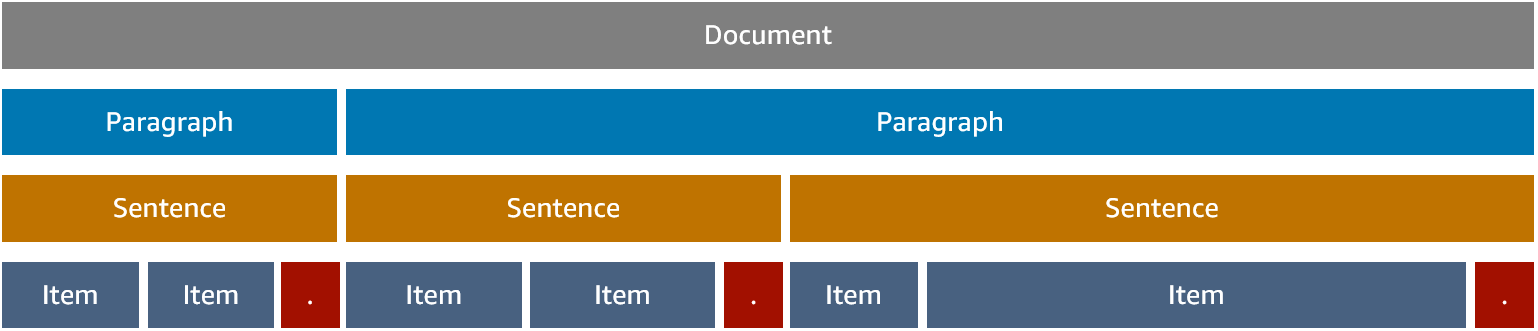
This concept is not language or accent specific, because it relies on non-linguistic metadata to suggest paragraph entry points. Future variations can include grammatical or semantic information on a per-language case, further enhancing the paragraph identification logic.
If you have feedback about this post, submit your comments in the comments section. We look forward to hearing from you. Check out Amazon Transcribe Features for additional features that will help you get the most value out of your transcripts.
About the Authors
![]() Kostas Tzouvanas is an Enterprise Solution Architect at Amazon Web Services. He helps customers architect cloud-based solutions to achieve their business potential. His main focus is trading platforms and high performance computing systems. He is also passionate about genomics and bioinformatics.
Kostas Tzouvanas is an Enterprise Solution Architect at Amazon Web Services. He helps customers architect cloud-based solutions to achieve their business potential. His main focus is trading platforms and high performance computing systems. He is also passionate about genomics and bioinformatics.
![]() Pavlos Kaimakis is an Enterprise Solutions Architect looking after Enterprise customers in GR/CY/MT supporting them with his experience to design and implement solutions that drive value to them. Pavlos has spent the biggest amount of time in his career in the product and customer support sector – both from an engineering and a management perspective. Pavlos loves travelling and he’s always up for exploring new places in the world.
Pavlos Kaimakis is an Enterprise Solutions Architect looking after Enterprise customers in GR/CY/MT supporting them with his experience to design and implement solutions that drive value to them. Pavlos has spent the biggest amount of time in his career in the product and customer support sector – both from an engineering and a management perspective. Pavlos loves travelling and he’s always up for exploring new places in the world.
- SEO Powered Content & PR Distribution. Get Amplified Today.
- PlatoAiStream. Web3 Data Intelligence. Knowledge Amplified. Access Here.
- Minting the Future w Adryenn Ashley. Access Here.
- Buy and Sell Shares in PRE-IPO Companies with PREIPO®. Access Here.
- Source: https://aws.amazon.com/blogs/machine-learning/arrange-your-transcripts-into-paragraphs-with-amazon-transcribe/

