Namuhla, sijabule ukumemezela amandla okushuna kahle amamodeli e-Code Llama kusetshenziswa i-Meta I-Amazon SageMaker JumpStart. Umndeni we-Code Llama wamamodeli wezilimi ezinkulu (LLMs) iqoqo lamamodeli okukhiqiza amakhodi aqeqeshwe kusengaphambili futhi acushwe kahle asukela esikalini esisuka kubhiliyoni elingu-7 kuya kupharamitha eyizigidi eziyizinkulungwane ezingama-70. Amamodeli e-Code Llama acushwe kahle ahlinzeka ngokunemba okungcono nokuchazeka ngaphezu kwamamodeli e-Code Llama eyisisekelo, njengoba kubonakala ekuhlolweni kwawo ngokumelene nawo. HumanEval kanye namasethi edatha e-MBPP. Ungakwazi ukushuna kahle futhi usebenzise amamodeli e-Code Llama nge-SageMaker JumpStart usebenzisa i I-Amazon SageMaker Studio I-UI ngokuchofoza okumbalwa noma kusetshenziswa i-SageMaker Python SDK. Ukucushwa kahle kwamamodeli we-Llama kusekelwe emibhalweni enikezwe ku- I-llama-recipes GitHub repo kusuka ku-Meta kusetshenziswa i-PyTorch FSDP, PEFT/LoRA, kanye namasu okulinganisa we-Int8.
Kulokhu okuthunyelwe, sihamba endleleni yokushuna kahle amamodeli e-Code Llama aqeqeshwe kusengaphambili nge-SageMaker JumpStart ngokuchofoza okukodwa kwe-UI kanye ne-SDK etholakala kulokhu okulandelayo. IGitHub repository.
Iyini i-SageMaker JumpStart
Nge-SageMaker JumpStart, ochwepheshe bokufunda ngomshini (ML) bangakhetha ekukhetheni okubanzi kwamamodeli esisekelo atholakala esidlangalaleni. Abasebenzi be-ML bangasebenzisa amamodeli esisekelo kwabazinikele I-Amazon SageMaker izimo ezivela endaweni ehlukanisiwe yenethiwekhi futhi wenze ngokwezifiso amamodeli usebenzisa i-SageMaker ukuze uthole ukuqeqeshwa kwemodeli nokusetshenziswa.
Yini Ikhodi Llama
I-Code Llama inguqulo yekhodi ekhethekile Ilala 2 edalwe ngokuqhubeka nokuqeqesha i-Llama 2 kumadathasethi ayo ekhodi ethile nokuthatha isampula yedatha eyengeziwe kuleyo dathasethi isikhathi eside. I-Code Llama ihlanganisa amakhono okubhala amakhodi athuthukisiwe. Ingakwazi ukukhiqiza ikhodi nolimi lwemvelo mayelana nekhodi, kusukela kukho kokubili ikhodi nokwaziswa kolimi lwemvelo (isibonelo, “Ngibhalele umsebenzi okhipha ukulandelana kwe-Fibonacci”). Ungakwazi futhi ukuyisebenzisela ukuqedela ikhodi nokulungisa iphutha. Isekela izilimi eziningi zokuhlela ezaziwa kakhulu ezisetshenziswa namuhla, okuhlanganisa iPython, C++, Java, PHP, Typescript (JavaScript), C#, Bash, nokuningi.
Kungani ucule kahle amamodeli e-Code Llama
I-Meta ishicilele amabhentshimakhi wokusebenza we-Code Llama ku I-HumanEval ne-MBPP ngezilimi ezijwayelekile zokubhala amakhodi njengePython, Java, neJavaScript. Ukusebenza kwamamodeli we-Code Llama Python ku-HumanEval kubonise ukusebenza okuhlukahlukene kuzo zonke izilimi zokubhala ezihlukene nemisebenzi esukela ku-38% kumodeli ye-7B Python kuya ku-57% kumamodeli angu-70B Python. Ngaphezu kwalokho, amamodeli e-Code Llama acushwe kahle kulimi lohlelo lwe-SQL abonise imiphumela engcono, njengoba kubonakala kumabhentshimakhi okuhlola e-SQL. Lawa mabhentshimakhi ashicilelwe agqamisa izinzuzo ezingaba khona zamamodeli e-Code Llama yokushuna kahle, okuvumela ukusebenza okungcono, ukwenza ngendlela oyifisayo, nokuzivumelanisa nezizinda ezithile zokubhala amakhodi nemisebenzi.
Ukulungiswa kahle kwe-No-code nge-SageMaker Studio UI
Ukuze uqale ukulungisa kahle amamodeli akho e-Llama usebenzisa i-SageMaker Studio, qedela lezi zinyathelo ezilandelayo:
- Ku-SageMaker Studio console, khetha I-JumpStart kufasitela lokuhambisa.
Uzothola uhlu lwamamodeli angaphezu kuka-350 kusukela kumthombo ovulekile namamodeli wobunikazi.
- Sesha amamodeli e-Code Llama.

Uma ungawaboni amamodeli e-Code Llama, ungabuyekeza inguqulo yakho ye-SageMaker Studio ngokuvala bese uqala kabusha. Ukuze uthole ulwazi olwengeziwe mayelana nezibuyekezo zenguqulo, bheka ku Vala futhi Ubuyekeze Izinhlelo Zokusebenza Zesitudiyo. Ungathola nezinye izinhlobo zemodeli ngokukhetha Hlola wonke Amamodeli Okukhiqiza Ikhodi noma ukucinga Ikhodi Llama ebhokisini lokusesha.

I-SageMaker JumpStart okwamanje isekela ukulungiswa kahle kweziyalezo zamamodeli e-Code Llama. Isithombe-skrini esilandelayo sibonisa ikhasi lokulungisa kahle lemodeli ye-Code Llama 2 70B.
- Ukuze Ukuqeqesha indawo yesethi yedatha, ungakhomba ku Isevisi ye-Amazon Simple Storage (I-Amazon S3) ibhakede eliqukethe idathasethi yokuqeqeshwa nokuqinisekisa ukuze ilungiswe kahle.
- Setha ukucushwa kwakho kokuthunyelwa, ama-hyperparameter, nezilungiselelo zokuphepha ukuze zilungiswe kahle.
- Khetha Train ukuqala umsebenzi wokuhlela kahle kusibonelo se-SageMaker ML.
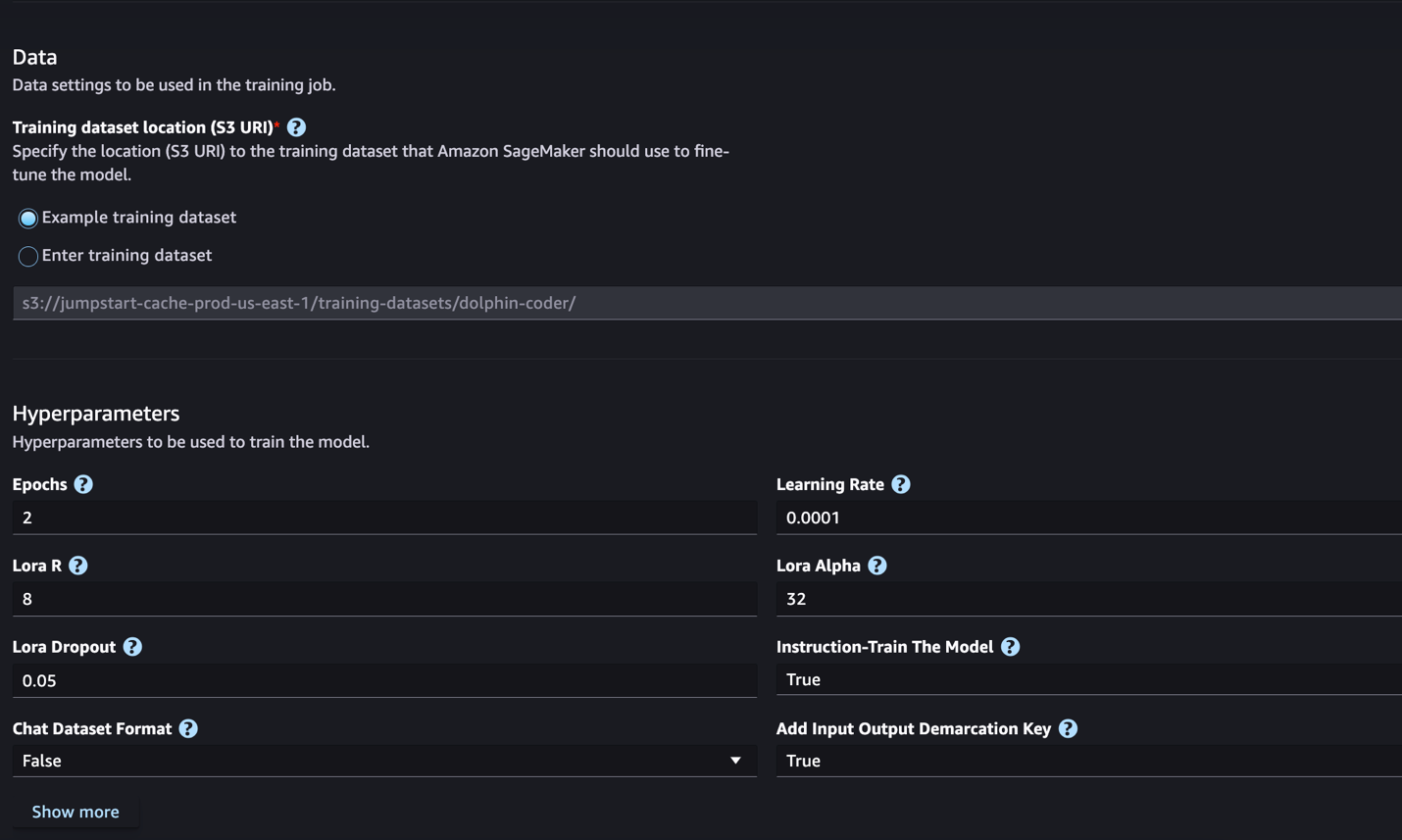
Sixoxa ngefomethi yesethi yedatha oyidingayo ukuze ulungiselele ukulungiswa kahle kwemiyalelo esigabeni esilandelayo.
- Ngemuva kokuthi imodeli isicushwe kahle, ungayisebenzisa usebenzisa ikhasi eliyimodeli ku-SageMaker JumpStart.
Inketho yokuphakela imodeli ecushwe kahle izovela uma ukulungisa kahle sekuqediwe, njengoba kukhonjisiwe kusithombe-skrini esilandelayo.

Hlela kahle nge-SageMaker Python SDK
Kulesi sigaba, sibonisa indlela yokushuna kahle amamodeli e-Code LIama usebenzisa i-SageMaker Python SDK kudathasethi efomethwe iziyalezo. Ngokukhethekile, imodeli ilungiselwe kahle isethi yemisebenzi yokucubungula ulimi lwemvelo (NLP) echazwe kusetshenziswa imiyalelo. Lokhu kusiza ukuthuthukisa ukusebenza kwemodeli yemisebenzi engabonakali ngemiyalo yokushutha iqanda.
Qedela lezi zinyathelo ezilandelayo ukuze uqedele umsebenzi wakho wokuhlela kahle. Ungathola yonke ikhodi yokushuna kahle kusuka ku- IGitHub repository.
Okokuqala, ake sibheke ifomethi yedathasethi edingekayo ukuze kulungiswe kahle iziyalezo. Idatha yokuqeqeshwa kufanele ifomethwe ngefomethi yemigqa ye-JSON (.jsonl), lapho umugqa ngamunye uyisichazamazwi esimelela isampula yedatha. Yonke idatha yokuqeqeshwa kufanele ibe kufolda eyodwa. Nokho, ingalondolozwa kumafayela amaningi we-.jsonl. Okulandelayo kuyisampula kufomethi yemigqa ye-JSON:
Ifolda yokuqeqesha ingaba ne-a template.json ifayela elichaza okokufaka nokukhipha amafomethi. Okulandelayo isifanekiso esiyisibonelo:
Ukuze ufanise isifanekiso, isampula ngayinye kulayini we-JSON amafayela kufanele ihlanganise system_prompt, question, Futhi response amasimu. Kulo mboniso, sisebenzisa i- Isethi yedatha ye-Dolphin Coder kusuka ku-Hugging Face.
Ngemva kokulungisa idathasethi futhi uyilayishe kubhakede le-S3, ungaqala ukulungisa kahle usebenzisa ikhodi elandelayo:
Ungakwazi ukuphakela imodeli ecushwe kahle ngqo kusuka kusilinganisi, njengoba kukhonjisiwe kukhodi elandelayo. Ukuze uthole imininingwane, bheka i-notebook ku- IGitHub repository.
Amasu okushuna kahle
Amamodeli olimi afana ne-Llama angaphezulu kuka-10 GB noma ngisho no-100 GB ngosayizi. Ukuhlela kahle amamodeli amakhulu kangaka kudinga izimo ezinememori ye-CUDA ephezulu kakhulu. Ngaphezu kwalokho, ukuqeqesha lawa mamodeli kungase kuhambe kancane ngenxa yobukhulu bemodeli. Ngakho-ke, ukuze silungise kahle, sisebenzisa lokhu okulandelayo:
- Ukuzijwayeza Kwezinga Eliphansi (LoRA) - Lolu uhlobo lwepharamitha yokulungisa kahle kahle (i-PEFT) yokulungisa kahle amamodeli amakhulu. Ngale ndlela, umisa yonke imodeli bese wengeza kuphela isethi encane yemingcele elungisekayo noma izendlalelo kumodeli. Isibonelo, esikhundleni sokuqeqesha wonke amapharamitha ayizigidi eziyizinkulungwane ezingu-7 we-Llama 2 7B, ungakwazi ukushuna kahle ngaphansi kuka-1% wamapharamitha. Lokhu kusiza ekwehliseni okukhulu isidingo senkumbulo ngoba udinga kuphela ukugcina ama-gradient, izifunda ze-optimizer, nolunye ulwazi oluhlobene nokuqeqeshwa ngo-1% kuphela wamapharamitha. Ngaphezu kwalokho, lokhu kusiza ekwehliseni isikhathi sokuqeqeshwa kanye nezindleko. Ukuze uthole imininingwane eyengeziwe ngale ndlela, bheka ku I-LoRA: Ukuguqulwa Kwezinga Eliphansi Lamamodeli Olimi Olukhulu.
- I-Int8 quantization - Ngisho nokulungiselelwa okufana ne-LoRA, amamodeli afana ne-Llama 70B asemakhulu kakhulu ukuthi angaqeqeshwa. Ukuze wehlise inkumbulo yonyawo ngesikhathi sokuqeqeshwa, ungasebenzisa ukulinganisa kwe-Int8 phakathi nokuqeqeshwa. Ukulinganisa amanani ngokuvamile kunciphisa ukunemba kwezinhlobo zedatha yezindawo ezintantayo. Nakuba lokhu kunciphisa inkumbulo edingekayo ukuze kugcinwe izisindo zemodeli, kwehlisa isithunzi ukusebenza ngenxa yokulahlekelwa ulwazi. Ukulinganisa kwe-Int8 kusebenzisa ukunemba kwekota kuphela kodwa akubangeli ukuwohloka kokusebenza ngoba akumane nje kuwise izingcezu. Izungeza idatha isuka kolunye uhlobo iye kolunye. Ukuze ufunde mayelana ne-Int8 quantization, bheka I-LLM.int8(): I-8-bit Matrix Ukuphindaphinda Kwama-Transformers Esikalini.
- I-Fully Shared Data Parallel (FSDP) – Lolu uhlobo lwe-algorithm yokuqeqeshwa okuhambisana nedatha ehlukanisa amapharamitha emodeli kubasebenzi abahambisanayo bedatha futhi ingakhulula ngokuzithandela ingxenye yokubala yokuqeqeshwa kuma-CPU. Yize amapharamitha abiwa kuma-GPU ahlukene, ukubalwa kwe-microbatch ngayinye kusendaweni yesisebenzi se-GPU. Ihlakaza amapharamitha ngokufana kakhulu futhi ifinyelela ukusebenza okuthuthukisiwe ngokuxhumana nokubala ngokweqa ngesikhathi sokuqeqeshwa.
Ithebula elilandelayo lifingqa imininingwane yemodeli ngayinye ngezilungiselelo ezihlukile.
| imodeli | Ukusetha Okuzenzakalelayo | I-LORA + FSDP | I-LORA + Ayikho i-FSDP | I-Int8 Quantization + LORA + Ayikho i-FSDP |
| Ikhodi Llama 2 7B | I-LORA + FSDP | Yebo | Yebo | Yebo |
| Ikhodi Llama 2 13B | I-LORA + FSDP | Yebo | Yebo | Yebo |
| Ikhodi Llama 2 34B | INT8 + LORA + NO FSDP | Cha | Cha | Yebo |
| Ikhodi Llama 2 70B | INT8 + LORA + NO FSDP | Cha | Cha | Yebo |
Ukucushwa kahle kwamamodeli we-Llama kusekelwe emibhalweni enikezwe ngokulandelayo GitHub repo.
Ama-hyperparameter asekelwe okuqeqeshwa
Ukucushwa kahle kwe-Code Llama 2 kusekela inani lamapharamitha, ngalinye elingathinta imfuneko yenkumbulo, isivinini sokuqeqesha, nokusebenza kwemodeli ecushwe kahle:
- inkathi - Inani lamaphasi athathwa yi-algorithm yokulungisa kahle idathasethi yokuqeqeshwa. Kumelwe kube inombolo enkulu kuno-1. Okuzenzakalelayo ngu-5.
- izinga_lokufunda - Izinga lapho izisindo zemodeli zibuyekezwa khona ngemva kokusebenza ngeqoqo ngalinye lezibonelo zokuqeqeshwa. Kufanele kube ukuntanta okuhle okukhulu kuno-0. Okuzenzakalelayo kungu-1e-4.
- umyalo_ulungisiwe - Ukuthi ufundise - uqeqeshe imodeli noma cha. Kumele
TrueorFalse. Okuzenzakalelayo nguFalse. - inqwaba_yedivayisi_yesitimela_usayizi - Usayizi weqoqo nge-GPU core/CPU ngayinye yokuqeqeshwa. Kufanele kube inombolo ephozithivu. Okuzenzakalelayo kungu-4.
- per_device_eval_batch_size - Usayizi weqoqo nge-GPU core/CPU ngayinye ukuze uhlolwe. Kumele kube inombolo ephozithivu. Okuzenzakalelayo ngu-1.
- amasampula_esitimela_max - Ngezinjongo zokususa iphutha noma ukuqeqeshwa okusheshayo, nciphisa inani lezibonelo zokuqeqeshwa kuleli nani. Inani -1 lisho ukusebenzisa wonke amasampula okuqeqesha. Kufanele kube inombolo ephozithivu noma -1. Okuzenzakalelayo ngu-1.
- max_val_sampuli - Ngezinjongo zokususa iphutha noma ukuqeqeshwa okusheshayo, nciphisa inani lezibonelo zokuqinisekisa kuleli nani. Inani -1 lisho ukusebenzisa wonke amasampula okuqinisekisa. Kufanele kube inombolo ephozithivu noma -1. Okuzenzakalelayo ngu-1.
- ubuningi_wokufaka_ubude - Ubude obukhulu bokulandelana kokufakwayo ngemuva kokwenziwa kwamathokheni. Ukulandelana okude kunalokhu kuzoncishiswa. Uma -1,
max_input_lengthisethelwe kokuncane okungu-1024 kanye nobude bemodeli obukhulu obuchazwe i-tokenizer. Uma isethelwe kunani eliphozithivu,max_input_lengthisethwe ebuncaneni bevelu enikeziwe kanye ne-model_max_lengthkuchazwe i-tokenizer. Kufanele kube inombolo ephozithivu noma -1. Okuzenzakalelayo ngu-1. - validation_split_ratio - Uma isiteshi sokuqinisekisa sikhona
none, isilinganiso sokuhlukaniswa kokuqinisekiswa kwesitimela kusuka kudatha yesitimela kufanele sibe phakathi kuka-0–1. Okuzenzakalelayo ngu-0.2. - train_data_split_seed - Uma idatha yokuqinisekisa ingekho, lokhu kulungisa ukuhlukaniswa okungahleliwe kwedatha yokuqeqeshwa kokufaka kudatha yokuqeqeshwa nokuqinisekisa esetshenziswa i-algorithm. Kufanele kube inombolo ephelele. Okuzenzakalelayo ngu-0.
- ukucubungula_inani_labasebenzi - Inani lezinqubo ezizosetshenziselwa ukucubungula ngaphambili. Uma
None, inqubo eyinhloko isetshenziselwa ukucubungula ngaphambili. Okuzenzakalelayo nguNone. - lora_r – U-Lora R. Kumelwe abe inombolo ephelele. Okuzenzakalelayo kungu-8.
- lora_alpha – Lora Alpha. Kumele kube inombolo ephozithivu. Okuzenzakalelayo kungu-32
- u-lora_dropout – Lora Dropout. kufanele kube ukuntanta okuhle phakathi kuka-0 no-1. Okuzenzakalelayo ngu-0.05.
- I-int8_quantization - Uma
True, imodeli ilayishwe ngokunemba kwe-8-bit yokuqeqeshwa. Okuzenzakalelayo kokuthi 7B kanye no-13B nguFalse. Okuzenzakalelayo kokuthi 70B nguTrue. - vumela_fsdp - Uma kuyiqiniso, ukuqeqeshwa kusebenzisa i-FSDP. Okuzenzakalelayo kokuthi 7B kanye no-13B kuyiqiniso. Okuzenzakalelayo kokuthi 70B Amanga. Qaphela ukuthi
int8_quantizationayisekelwe ne-FSDP.
Lapho ukhetha ama-hyperparameters, cabanga ngalokhu okulandelayo:
- Setting
int8_quantization=Truekunciphisa isidingo senkumbulo futhi kuholela ekuqeqeshweni okusheshayo. - Yehlisa
per_device_train_batch_sizefuthimax_input_lengthyehlisa isidingo sememori ngakho-ke ingaqhutshwa ezimweni ezincane. Nokho, ukusetha amanani aphansi kakhulu kungase kwandise isikhathi sokuqeqesha. - Uma ungasebenzisi i-Int8 quantization (
int8_quantization=False), sebenzisa i-FSDP (enable_fsdp=True) ukuze uthole ukuqeqeshwa okusheshayo nangempumelelo.
Izinhlobo zezibonelo ezisekelwe zokuqeqeshwa
Ithebula elilandelayo lifingqa izinhlobo zezibonelo ezisekelwayo zokuqeqesha amamodeli ahlukene.
| imodeli | Uhlobo Lwesimo Esizenzakalelayo | Izinhlobo Zezimo Ezisekelwe |
| Ikhodi Llama 2 7B | ml.g5.12xlarge |
ml.g5.12xlarge, ml.g5.24xlarge, ml.g5.48xlarge, ml.p3dn.24xlarge, ml.g4dn.12xlarge |
| Ikhodi Llama 2 13B | ml.g5.12xlarge |
ml.g5.24xlarge, ml.g5.48xlarge, ml.p3dn.24xlarge, ml.g4dn.12xlarge |
| Ikhodi Llama 2 70B | ml.g5.48xlarge |
ml.g5.48xlarge ml.p4d.24xlarge |
Lapho ukhetha uhlobo lwesibonelo, cabangela lokhu okulandelayo:
- Izimo ze-G5 zinikeza uqeqesho olusebenza kahle kakhulu phakathi kwezinhlobo zezibonelo ezisekelwayo. Ngakho-ke, uma unezimo ze-G5 ezitholakalayo, kufanele uzisebenzise.
- Isikhathi sokuqeqesha sincike kakhulu enanini lama-GPU kanye nenkumbulo ye-CUDA etholakalayo. Ngakho-ke, ukuqeqeshwa ezimweni ezinenani elifanayo lama-GPU (isibonelo, ml.g5.2xlarge kanye ne-ml.g5.4xlarge) kucishe kufane. Ngakho-ke, ungasebenzisa isibonelo esishibhile sokuqeqesha (ml.g5.2xlarge).
- Uma usebenzisa izimo ze-p3, ukuqeqeshwa kuzokwenziwa ngokunemba okungu-32-bit ngoba i-bfloat16 ayisekelwe kulezi zimo. Ngakho-ke, umsebenzi wokuqeqesha uzodla kabili inani lenkumbulo ye-CUDA lapho uqeqeshwa ezimweni ze-p3 uma kuqhathaniswa nezimo ze-g5.
Ukuze ufunde ngezindleko zokuqeqeshwa ngokwesibonelo, bheka ku I-Amazon EC2 G5 Instances.
Kulinganisa
Ukuhlola kuyisinyathelo esibalulekile sokuhlola ukusebenza kwamamodeli acushwe kahle. Sethula kokubili ukuhlola kwekhwalithi nokwenani ukuze sibonise ukuthuthukiswa kwamamodeli ashunwe kahle kunalawo angashuniwe kahle. Ekuhloleni kwekhwalithi, sibonisa impendulo eyisibonelo kuwo womabili amamodeli ashunwe kahle nangashuthekisiwe. Ekuhloleni komthamo, sisebenzisa HumanEval, i-suite yokuhlola eyakhiwe i-OpenAI ukuze ikhiqize ikhodi ye-Python ukuhlola amakhono okukhiqiza imiphumela elungile nenembile. Inqolobane ye-HumanEval ingaphansi kwelayisensi ye-MIT. Silungise kahle izinhlobo zePython zazo zonke izinhlobo ze-Code LIama ezinosayizi abahlukene (Ikhodi LIama Python 7B, 13B, 34B, kanye no-70B ku- Isethi yedatha ye-Dolphin Coder), bese wethula imiphumela yokuhlola ezigabeni ezilandelayo.
Ukuhlola ngendlela efanele
Ngokusetshenziswa kwemodeli yakho ecushwe kahle, ungaqala ukusebenzisa indawo yokugcina ukuze ukhiqize ikhodi. Esibonelweni esilandelayo, sethula izimpendulo ezivela kokubili okuyisisekelo kanye nokucushwe kahle kweKhodi engu-LIama 34B Python kusampula yokuhlola Isethi yedatha ye-Dolphin Coder:
Imodeli ye-Code Llama ecushwe kahle, ngaphezu kokunikeza ikhodi yombuzo owandulele, ikhiqiza incazelo enemininingwane yendlela yokwenza kanye nekhodi mbumbulu.
Ikhodi Llama 34b Python Impendulo Engashuniwe Kahle:
Ikhodi Llama 34B Python Impendulo Elungiswe Kahle
Iqiniso eliyisisekelo
Kuyathakazelisa ukuthi inguqulo yethu ecushwe kahle ye-Code Llama 34B Python ihlinzeka ngesixazululo esiguquguqukayo esisekelwe ohlelweni kuchungechunge oluncane lwe-palindromic olude kakhulu, oluhlukile kusixazululo esinikezwe eqinisweni eliyisisekelo kusukela kusibonelo sokuhlola esikhethiwe. Imodeli yethu ecushwe kahle ifaka izizathu futhi ichaza isisombululo esisekelwe ohlelweni ngokuningiliziwe. Ngakolunye uhlangothi, imodeli engashuniwe kahle iveza imiphumela engaba khona ngemva nje kwe- print isitatimende (esiboniswe kuseli engakwesokunxele) ngenxa yokuphumayo axyzzyx akuyona i-palindrome ende kunazo zonke ochungechungeni olunikeziwe. Ngokuphathelene nesikhathi esiyinkimbinkimbi, isixazululo sokuhlela esiguqukayo ngokuvamile singcono kunendlela yokuqala. Isixazululo sokuhlela esiguqukayo sinesikhathi esiyinkimbinkimbi se-O(n^2), lapho u-n engubude beyunithi yezinhlamvu yokufaka. Lokhu kusebenza kahle kakhulu kunesixazululo sokuqala esisuka kumodeli engashuniwe, nayo ebinobunzima besikhathi obuphindwe kane kwe-O(n^2) kodwa ngendlela elungiselelwe kancane.
Lokhu kubukeka kuthembisa! Khumbula, silungise kahle kuphela ukwahluka kwe-Code LIama Python ngo-10% we Isethi yedatha ye-Dolphin Coder. Kuningi ongakuhlola!
Naphezu kwemiyalo ephelele ekuphenduleni, sisadinga ukuhlola ukunemba kwekhodi yePython enikezwe esixazululweni. Okulandelayo, sisebenzisa uhlaka lokuhlola olubizwa ngokuthi U-Eva Womuntu ukwenza izivivinyo zokuhlanganisa empendulweni ekhiqiziwe evela ku-Code LIama ukuze ihlole ngokuhlelekile ikhwalithi yayo.
Ukuhlola okulinganiselwe nge-HumanEval
I-HumanEval iyihhanisi yokuhlola yokuhlola amandla e-LLM okuxazulula izinkinga ezinkingeni zokubhala ezisekelwe kuPython, njengoba kuchazwe ephepheni. Ukuhlola Amamodeli Olimi Amakhulu Aqeqeshwe Ngekhodi. Ngokukhethekile, iqukethe izinkinga zokuhlela ezisekelwe ku-Python zoqobo eziyi-164 ezihlola ikhono lemodeli yolimi lokukhiqiza ikhodi ngokusekelwe olwazini olunikeziwe njengesiginesha yokusebenza, i-docstring, umzimba, nokuhlolwa kweyunithi.
Kumbuzo ngamunye wokuhlela osuselwe kuPython, siwuthumela kumodeli ye-Code LIama efakwe endaweni yokugcina ye-SageMaker ukuze sithole izimpendulo zika-k. Okulandelayo, sisebenzisa impendulo ngayinye k ekuhlolweni kokuhlanganisa endaweni yokugcina ye-HumanEval. Uma noma iyiphi impendulo ye-k iphumelela ekuhlolweni kokuhlanganisa, sibala lelo cala liphumelele; kungenjalo, kwehlulekile. Bese siphinda inqubo yokubala isilinganiso samacala aphumelele njengomphumela wokugcina wokuhlola oqanjwe pass@k. Ngokulandela ukuzijwayeza okujwayelekile, simisa u-k njengo-1 ekuhlaziyeni kwethu, ukuze sikhiqize impendulo eyodwa kuphela ngombuzo ngamunye futhi sihlole ukuthi uyaphumelela yini ukuhlolwa kokuhlanganisa.
Okulandelayo ikhodi yesampula yokusebenzisa inqolobane ye-HumanEval. Ungafinyelela kudathasethi futhi ukhiqize impendulo eyodwa usebenzisa iphoyinti lokugcina le-SageMaker. Ukuze uthole imininingwane, bheka i-notebook ku- IGitHub repository.
Ithebula elilandelayo libonisa ukuthuthukiswa kwamamodeli e-Code LIama Python ashunwe kahle ngaphezu kwamamodeli angashuniwe kuwo wonke amamodeli amasayizi ahlukene. Ukuze siqinisekise ukulunga, siphinde sikhiphe amamodeli we-Code LIama angashuniwe kahle kuma-SageMaker endpoints futhi siqhube nokuhlola kokuhlolwa kwabantu. I dlula@1 izinombolo (umugqa wokuqala kuthebula elilandelayo) zifanisa izinombolo ezibikiwe ku- Iphepha locwaningo lekhodi Llama. Imingcele ye-inference isethwe ngokungaguquki njenge "parameters": {"max_new_tokens": 384, "temperature": 0.2}.
Njengoba singabona emiphumeleni, zonke izinhlobo ze-Code LIama Python ezicushwe kahle zibonisa ukuthuthuka okuphawulekayo kumamodeli angashuniwe kahle. Ikakhulukazi, i-Code LIama Python 70B idlula imodeli engashuniwe cishe ngo-12%.
| . | I-7B Python | I-13B Python | I-34B | I-34B Python | I-70B Python |
| Ukusebenza kwemodeli okuqeqeshwe kusengaphambili (pass@1) | 38.4 | 43.3 | 48.8 | 53.7 | 57.3 |
| Ukusebenza kwemodeli ecushwe kahle (pass@1) | 45.12 | 45.12 | 59.1 | 61.5 | 69.5 |
Manje ungazama ukulungisa kahle amamodeli e-Code LIama kudathasethi yakho.
Hlanza
Uma unquma ukuthi awusafuni ukugcina i-endpoint ye-SageMaker isebenza, ungayisusa usebenzisa I-AWS SDK yePython (Boto3), I-AWS Command Line Interface (AWS CLI), noma ikhonsoli ye-SageMaker. Ukuze uthole ukwaziswa okwengeziwe, bheka Susa Amaphoyinti Okugcina Nezinsiza. Ngaphezu kwalokho, ungakwazi vala izinsiza zeSageMaker Studio ezingasadingeki.
Isiphetho
Kulokhu okuthunyelwe, sixoxe ngokulungisa kahle amamodeli we-Meta's Code Llama 2 sisebenzisa i-SageMaker JumpStart. Sibonise ukuthi ungasebenzisa ikhonsoli ye-SageMaker JumpStart ku-SageMaker Studio noma i-SageMaker Python SDK ukuze ucule kahle futhi usebenzise lawa mamodeli. Siphinde saxoxa ngendlela yokuhlela kahle, izinhlobo zezibonelo, nama-hyperparameter asekelwe. Ngaphezu kwalokho, siveze izincomo zokuqeqeshwa okulungiselelwe okusekelwe ezivivinyweni ezahlukahlukene esizenzile. Njengoba singabona kule miphumela yokulungisa kahle amamodeli amathathu kumadathasethi amabili, ukulungisa kahle kuthuthukisa ukufinyezwa uma kuqhathaniswa namamodeli angashuniwe kahle. Njengesinyathelo esilandelayo, ungazama ukulungisa kahle lawa mamodeli kudathasethi yakho usebenzisa ikhodi enikezwe endaweni yokugcina ye-GitHub ukuze uhlole futhi ulinganisele imiphumela yezimo zakho zokusebenzisa.
Mayelana Ababhali
 UDkt Xin Huang unguSayensi Omkhulu Osetshenziswayo we-Amazon SageMaker JumpStart kanye ne-Amazon SageMaker eyakhelwe ngaphakathi ama-algorithms. Ugxile ekuthuthukiseni ama-algorithms okufunda komshini angakala. Izithakazelo zakhe zocwaningo zisendaweni yokucubungula ulimi lwemvelo, ukufunda okujulile okuchazekayo kudatha yethebula, nokuhlaziywa okuqinile kokuhlanganisa okungeyona ingxenye yepharamitha yesikhala sesikhathi. Ushicilele amaphepha amaningi ezinkomfeni ze-ACL, ICDM, KDD, kanye neRoyal Statistical Society: Series A.
UDkt Xin Huang unguSayensi Omkhulu Osetshenziswayo we-Amazon SageMaker JumpStart kanye ne-Amazon SageMaker eyakhelwe ngaphakathi ama-algorithms. Ugxile ekuthuthukiseni ama-algorithms okufunda komshini angakala. Izithakazelo zakhe zocwaningo zisendaweni yokucubungula ulimi lwemvelo, ukufunda okujulile okuchazekayo kudatha yethebula, nokuhlaziywa okuqinile kokuhlanganisa okungeyona ingxenye yepharamitha yesikhala sesikhathi. Ushicilele amaphepha amaningi ezinkomfeni ze-ACL, ICDM, KDD, kanye neRoyal Statistical Society: Series A.
 Vishaal Yalamanchali i-Startup Solutions Architect esebenza ne-AI ekhiqizayo yesigaba sangaphambi kwesikhathi, amarobhothi, nezinkampani zezimoto ezizimele. U-Vishaal usebenza namakhasimende akhe ukuletha izixazululo ze-ML ezisezingeni eliphezulu futhi unentshisekelo mathupha ekufundeni okuqiniswayo, ukuhlolwa kwe-LLM, kanye nokukhiqizwa kwamakhodi. Ngaphambi kwe-AWS, uVishaal wayeneziqu e-UCI, egxile kuma-bioinformatics kanye nezinhlelo ezihlakaniphile.
Vishaal Yalamanchali i-Startup Solutions Architect esebenza ne-AI ekhiqizayo yesigaba sangaphambi kwesikhathi, amarobhothi, nezinkampani zezimoto ezizimele. U-Vishaal usebenza namakhasimende akhe ukuletha izixazululo ze-ML ezisezingeni eliphezulu futhi unentshisekelo mathupha ekufundeni okuqiniswayo, ukuhlolwa kwe-LLM, kanye nokukhiqizwa kwamakhodi. Ngaphambi kwe-AWS, uVishaal wayeneziqu e-UCI, egxile kuma-bioinformatics kanye nezinhlelo ezihlakaniphile.
 Meenakshisundaram Thandavarayan usebenzela i-AWS njengochwepheshe be-AI/ML. Unothando lokuklama, ukudala, nokukhuthaza idatha egxile kumuntu kanye nolwazi lwezibalo. I-Meena igxile ekuthuthukiseni amasistimu aqhubekayo aletha izinzuzo ezilinganisekayo, ezincintisanayo kumakhasimende ahlakaniphile we-AWS. U-Meena ungumxhumanisi nomcabango wokuklama, futhi ulwela ukushayela amabhizinisi ezindleleni ezintsha zokusebenza ngokusungula izinto ezintsha, ukufukamela, kanye nentando yeningi.
Meenakshisundaram Thandavarayan usebenzela i-AWS njengochwepheshe be-AI/ML. Unothando lokuklama, ukudala, nokukhuthaza idatha egxile kumuntu kanye nolwazi lwezibalo. I-Meena igxile ekuthuthukiseni amasistimu aqhubekayo aletha izinzuzo ezilinganisekayo, ezincintisanayo kumakhasimende ahlakaniphile we-AWS. U-Meena ungumxhumanisi nomcabango wokuklama, futhi ulwela ukushayela amabhizinisi ezindleleni ezintsha zokusebenza ngokusungula izinto ezintsha, ukufukamela, kanye nentando yeningi.
 UDkt. Ashish Khetan i-Senior Applied Scientist ene-Amazon SageMaker eyakhelwe ngaphakathi algorithm futhi isiza ukuthuthukisa ubuhlakani bokufunda komshini. Uthole i-PhD yakhe e-University of Illinois Urbana-Champaign. Ungumcwaningi okhuthele ekufundeni komshini kanye nezibalo zezibalo, futhi ushicilele amaphepha amaningi kuzinkomfa ze-NeurIPS, ICML, ICLR, JMLR, ACL, kanye ne-EMNLP.
UDkt. Ashish Khetan i-Senior Applied Scientist ene-Amazon SageMaker eyakhelwe ngaphakathi algorithm futhi isiza ukuthuthukisa ubuhlakani bokufunda komshini. Uthole i-PhD yakhe e-University of Illinois Urbana-Champaign. Ungumcwaningi okhuthele ekufundeni komshini kanye nezibalo zezibalo, futhi ushicilele amaphepha amaningi kuzinkomfa ze-NeurIPS, ICML, ICLR, JMLR, ACL, kanye ne-EMNLP.
- I-SEO Powered Content & PR Distribution. Khuliswa Namuhla.
- I-PlatoData.Network Vertical Generative Ai. Zinike Amandla. Finyelela Lapha.
- I-PlatoAiStream. I-Web3 Intelligence. Ulwazi Lukhulisiwe. Finyelela Lapha.
- I-PlatoESG. Ikhabhoni, I-CleanTech, Amandla, Environment, Ilanga, Ukuphathwa Kwemfucuza. Finyelela Lapha.
- I-PlatoHealth. I-Biotech kanye ne-Clinical Trials Intelligence. Finyelela Lapha.
- Source: https://aws.amazon.com/blogs/machine-learning/fine-tune-code-llama-on-amazon-sagemaker-jumpstart/

