亞馬遜泰坦圖像生成器 G1 是一種尖端的文本到圖像模型,可通過 亞馬遜基岩,它能夠理解在不同上下文中描述多個物件的提示,並在其生成的圖像中捕獲這些相關細節。它已在美國東部(維吉尼亞北部)和美國西部(俄勒岡)AWS 區域推出,可執行高級影像編輯任務,例如智慧裁剪、修復和背景變更。然而,使用者希望使模型適應模型尚未訓練的自訂資料集中的獨特特徵。自訂資料集可以包含與您的品牌指南或特定風格(例如先前的行銷活動)一致的高度專有的資料。為了解決這些用例並產生完全個人化的圖像,您可以使用您自己的資料微調 Amazon Titan Image Generator Amazon Bedrock 的自訂模型.
從生成圖像到編輯圖像,文字到圖像模型在各個行業都有廣泛的應用。它們可以增強員工的創造力,並提供僅透過文字描述想像新可能性的能力。例如,它可以幫助建築師進行設計和平面圖規劃,並透過提供可視化各種設計的能力來實現更快的創新,而無需手動創建它們。同樣,它可以透過簡化圖形和插圖的生成來幫助各個行業的設計,例如製造業、零售業的時裝設計和遊戲設計。文字轉圖像模型還允許個人化廣告以及媒體和娛樂用例中的互動式和沈浸式視覺聊天機器人,從而增強您的客戶體驗。
在這篇文章中,我們將引導您完成對 Amazon Titan 圖像生成器模型進行微調的過程,以了解兩個新類別:我們最喜歡的寵物 Ron 狗和 Smila 貓。我們討論如何為模型微調任務準備資料以及如何在 Amazon Bedrock 中建立模型自訂作業。最後,我們向您展示如何測試和部署您的微調模型 預置吞吐量.
 |
 |
| 羅恩狗 | 斯米拉貓 |
在微調作業之前評估模型功能
基礎模型經過大量資料的訓練,因此您的模型可能開箱即用,運作良好。這就是為什麼檢查您是否確實需要針對您的用例微調模型或即時工程是否足夠的原因是一個很好的做法。讓我們嘗試使用基本 Amazon Titan 圖像生成器模型生成狗 Ron 和貓 Smila 的一些圖像,如下所示。


正如預期的那樣,開箱即用的模型還不認識 Ron 和 Smila,並且產生的輸出顯示不同的狗和貓。透過一些及時的工程設計,我們可以提供更多細節,以更接近我們最喜歡的寵物的外觀。


儘管生成的圖像與 Ron 和 Smila 更相似,但我們發現模型無法再現他們的完整相似之處。現在讓我們開始對 Ron 和 Smila 的照片進行微調,以獲得一致的個人化輸出。
微調 Amazon Titan 影像產生器
Amazon Bedrock 為您提供無伺服器體驗,用於微調 Amazon Titan 影像產生器模型。您只需準備資料並選擇超參數,AWS 將為您處理繁重的工作。
當您使用 Amazon Titan Image Generator 模型進行微調時,將在由 AWS 擁有和管理的 AWS 模型開發帳戶中建立該模型的副本,並建立模型自訂作業。然後,該作業存取來自 VPC 的微調數據,並且亞馬遜 Titan 模型的權重已更新。然後將新模型儲存到 亞馬遜簡單存儲服務 (Amazon S3) 與預訓練模型位於同一模型開發帳戶中。現在它只能由您的帳戶用於推理,不會與任何其他 AWS 帳戶共用。運行推理時,您可以透過 預配置容量計算 或直接使用 Amazon Bedrock 的批量推理。獨立於所選的推理模式,您的資料保留在您的帳戶中,不會複製到任何 AWS 擁有的帳戶或用於改進 Amazon Titan Image Generator 模型。
下圖說明了此工作流程。

資料隱私和網路安全
用於微調的資料(包括提示)以及自訂模型在您的 AWS 帳戶中保持私密。它們不會共享或用於模型訓練或服務改進,也不會與第三方模型提供者共用。所有用於微調的資料在傳輸和靜態時都經過加密。資料保留在處理 API 呼叫的相同區域中。您也可以使用 AWS私有鏈接 在您的資料所在的 AWS 帳戶與 VPC 之間建立私有連線。
資料準備
在創建模型定製作業之前,您需要 準備你的訓練資料集。訓練資料集的格式取決於您正在建立的自訂作業的類型(微調或持續預訓練)以及資料的形式(文字轉文字、文字到圖像或圖像到圖像)嵌入)。對於 Amazon Titan 圖像生成器模型,您需要提供要用於微調的圖像以及每個圖像的標題。 Amazon Bedrock 希望您的圖像儲存在 Amazon S3 上,並且圖像和標題對以包含多個 JSON 行的 JSONL 格式提供。
每個 JSON 行都是一個範例,其中包含圖像引用、圖像的 S3 URI 以及包含圖像文字提示的標題。您的圖像必須是 JPEG 或 PNG 格式。以下程式碼顯示了該格式的範例:
{“image-ref”:“s3://bucket/path/to/image001.png”,“標題”:“"} {"image-ref": "s3://bucket/path/to/image002.png", "標題": ""} {"image-ref": "s3://bucket/path/to/image003.png", "標題": ""}
由於「Ron」和「Smila」是也可以在其他上下文中使用的名稱,例如人名,因此我們在創建提示以微調模型時添加標識符「Ron the dogs」和「Smila the cat」 。儘管這不是微調工作流程的要求,但這些附加資訊在為新類別定制模型時為模型提供了更多的上下文清晰度,並且將避免“Ron the dogs”與一個叫 Ron 的人以及“斯米拉貓」與烏克蘭斯米拉市。使用這種邏輯,下圖顯示了我們的訓練資料集的範例。
 |
 |
 |
| 羅恩狗躺在白色的狗床上 | 羅恩狗坐在瓷磚地板上 | 榮恩狗躺在汽車座椅上 |
 |
 |
 |
| 躺在沙發上的斯米拉貓 | 貓咪斯米拉躺在沙發上盯著相機 | 躺在寵物籠裡的斯米拉貓 |
當將資料轉換為定製作業所需的格式時,我們得到以下範例結構:
{“圖像參考”:“/ron_01.jpg", "caption": "羅恩狗躺在白色的狗床上"} {"image-ref": "/ron_02.jpg", "caption": "羅恩狗坐在磁磚地板上"} {"image-ref": "/ron_03.jpg", "caption": "羅恩狗躺在汽車座椅上"} {"image-ref": "/smila_01.jpg", "caption": "躺在沙發上的 Smila 貓"} {"image-ref": "/smila_02.jpg", "caption": "Smila 貓坐在窗邊,旁邊是一隻雕像貓"} {"image-ref": "/smila_03.jpg", "caption": "躺在寵物籠上的 Smila 貓"}
建立 JSONL 檔案後,我們需要將其儲存在 S3 儲存桶上以開始自訂作業。 Amazon Titan Image Generator G1 微調作業將處理 5-10,000 張影像。對於本文討論的範例,我們使用 60 張圖像:30 張狗 Ron 的圖像和 30 張貓 Smila 的圖像。一般來說,提供更多您想要學習的風格或類別將提高微調模型的準確性。但是,用於微調的影像越多,完成微調作業所需的時間就越多。使用的圖像數量也會影響微調工作的定價。參考 亞馬遜基岩定價 獲取更多訊息
微調 Amazon Titan 影像產生器
現在我們已經準備好了訓練數據,我們可以開始新的客製化工作。此程序可以透過 Amazon Bedrock 主控台或 API 完成。若要使用 Amazon Bedrock 控制台,請完成以下步驟:
- 在 Amazon Bedrock 控制台上,選擇 客製化型號 在導航窗格中。
- 上 客製化型號 菜單,選擇 建立微調作業.
- 為 微調型號名稱,輸入新模型的名稱。
- 為 作業配置,輸入訓練作業的名稱。
- 為 輸入數據,輸入輸入資料的S3路徑。

- 在 超參數 部分,提供以下值:
- 步數 – 模型暴露於每批的次數。
- 批量大小 – 更新模型參數之前處理的樣本數。
- 學習率 – 每批次後模型參數更新的速率。這些參數的選擇取決於給定的資料集。作為一般準則,我們建議您先將批次大小固定為 8,將學習率固定為 1e-5,並根據使用的圖像數量設定步數,如下表所示。
| 提供的圖像數量 | 8 | 32 | 64 | 1,000 | 10,000 |
| 建議步數 | 1,000 | 4,000 | 8,000 | 10,000 | 12,000 |
如果微調工作的結果不令人滿意,如果您在生成的圖像中沒有觀察到任何樣式的跡象,請考慮增加步數;如果您在生成的圖像中觀察到樣式,但仍然存在,請考慮減少步數。存在偽影或模糊。如果微調後的模型即使經過 40,000 個步驟也無法學習資料集中的獨特風格,請考慮增加批量大小或學習率。
- 在 輸出數據 部分,輸入儲存驗證輸出的 S3 輸出路徑,包括定期記錄的驗證損耗和準確性指標。
- 在 服務接入 部分,產生一個新的 AWS身份和訪問管理 (IAM) 角色或選擇具有存取 S3 儲存桶所需權限的現有 IAM 角色。
此授權使 Amazon Bedrock 能夠從您指定的儲存桶中檢索輸入和驗證資料集,並將驗證輸出無縫儲存在您的 S3 儲存桶中。
- 選擇 微調模型.

設定正確的配置後,Amazon Bedrock 現在將訓練您的自訂模型。
部署具有預先配置吞吐量的經過微調的 Amazon Titan 影像產生器
建立自訂模型後,預置吞吐量可讓您為自訂模型指派預定的固定速率的處理能力。這種分配為處理工作負載提供了一致的效能和容量水平,從而提高了生產工作負載的效能。預先配置吞吐量的第二個優點是成本控制,因為採用按需推理模式的基於標準代幣的定價可能難以大規模預測。
模型微調完成後,該模型將出現在 客製化型號' Amazon Bedrock 控制台上的頁面。
若要購買預先配置吞吐量,請選擇您剛剛微調的自訂模型,然後選擇 購買預配置吞吐量.
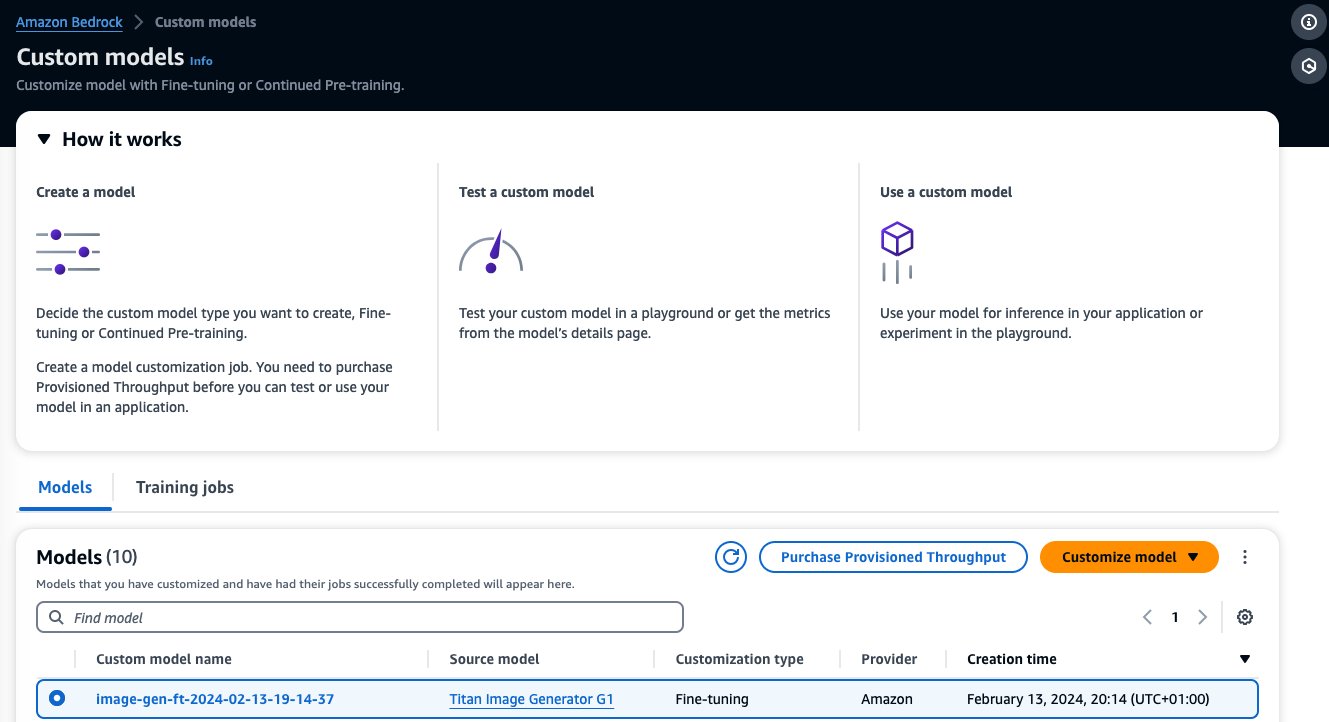
這會預先填入您要為其購買預先配置吞吐量的選定模型。若要在部署之前測試微調模型,請將模型單位設為值 1 並將承諾期限設為 沒有承諾。這可以讓您快速開始使用自訂提示測試模型並檢查訓練是否足夠。而且,當新的微調模型和新版本出現時,只要用同模型的其他版本更新就可以更新Provisioned Throughput。

微調結果
對於我們在狗 Ron 和貓 Smila 上定制模型的任務,實驗表明最佳超參數是 5,000 步,批量大小為 8,學習率為 1e-5。
以下是定制模型生成的圖像的一些範例。
 |
 |
 |
| 榮恩小狗穿著超級英雄斗篷 | 月球上的狗羅恩 | 羅恩狗在游泳池裡戴著墨鏡 |
 |
 |
 |
| 雪地上的斯米拉貓 | Smila 黑白相間的貓咪盯著相機 | 戴著聖誕帽的貓咪史米拉 |
結論
在這篇文章中,我們討論了何時使用微調而不是設計提示以產生更高品質的圖像。我們展示如何微調 Amazon Titan Image Generator 模型並在 Amazon Bedrock 上部署自訂模型。我們還提供了有關如何準備資料進行微調和設定最佳超參數以實現更準確的模型自訂的一般指南。
下一步,您可以調整以下內容 例子 根據您的使用案例,使用 Amazon Titan Image Generator 產生超個人化影像。
關於作者
 瑪拉·拉德拉·坦克 是 AWS 的高級生成人工智慧資料科學家。她擁有機器學習背景,擁有 10 多年與各行業客戶一起設計和建立 AI 應用程式的經驗。身為技術主管,她透過 Amazon Bedrock 上的生成式 AI 解決方案幫助客戶加速實現業務價值。在空閒時間,Maira 喜歡旅行、與她的貓 Smila 玩耍,以及與家人在溫暖的地方共度時光。
瑪拉·拉德拉·坦克 是 AWS 的高級生成人工智慧資料科學家。她擁有機器學習背景,擁有 10 多年與各行業客戶一起設計和建立 AI 應用程式的經驗。身為技術主管,她透過 Amazon Bedrock 上的生成式 AI 解決方案幫助客戶加速實現業務價值。在空閒時間,Maira 喜歡旅行、與她的貓 Smila 玩耍,以及與家人在溫暖的地方共度時光。
 丹尼·米切爾 是 Amazon Web Services 的 AI/ML 專家解決方案架構師。他專注於電腦視覺用例並幫助歐洲、中東和非洲地區的客戶加快他們的機器學習之旅。
丹尼·米切爾 是 Amazon Web Services 的 AI/ML 專家解決方案架構師。他專注於電腦視覺用例並幫助歐洲、中東和非洲地區的客戶加快他們的機器學習之旅。
 巴拉蒂·斯里尼瓦桑 是 AWS Professional Services 的資料科學家,她喜歡在 Amazon Bedrock 上建立很酷的東西。她熱衷於從機器學習應用程式中驅動商業價值,並專注於負責任的人工智慧。除了為客戶建立新的人工智慧體驗之外,巴拉蒂還喜歡寫科幻小說並透過耐力運動挑戰自己。
巴拉蒂·斯里尼瓦桑 是 AWS Professional Services 的資料科學家,她喜歡在 Amazon Bedrock 上建立很酷的東西。她熱衷於從機器學習應用程式中驅動商業價值,並專注於負責任的人工智慧。除了為客戶建立新的人工智慧體驗之外,巴拉蒂還喜歡寫科幻小說並透過耐力運動挑戰自己。
 阿欽·賈因 是 Amazon 通用人工智慧 (AGI) 團隊的應用科學家。他擁有文字到圖像模型方面的專業知識,並專注於建立 Amazon Titan 圖像生成器。
阿欽·賈因 是 Amazon 通用人工智慧 (AGI) 團隊的應用科學家。他擁有文字到圖像模型方面的專業知識,並專注於建立 Amazon Titan 圖像生成器。
- SEO 支持的內容和 PR 分發。 今天得到放大。
- PlatoData.Network 垂直生成人工智能。 賦予自己力量。 訪問這裡。
- 柏拉圖愛流。 Web3 智能。 知識放大。 訪問這裡。
- 柏拉圖ESG。 碳, 清潔科技, 能源, 環境, 太陽能, 廢物管理。 訪問這裡。
- 柏拉圖健康。 生物技術和臨床試驗情報。 訪問這裡。
- 資源: https://aws.amazon.com/blogs/machine-learning/fine-tune-your-amazon-titan-image-generator-g1-model-using-amazon-bedrock-model-customization/

