使用容器运行机器学习 (ML) 工作负载正在成为一种常见做法。 容器不仅可以完全封装您的训练代码,还可以完全封装整个依赖项堆栈,直至硬件库和驱动程序。 您得到的是一个一致且可移植的 ML 开发环境。 使用容器,在集群上进行扩展变得更加容易。
2022 年底,AWS 宣布正式推出 Amazon EC2 Trn1 实例 powered by AWS 培训 加速器,专为高性能深度学习训练而打造。 与其他同类产品相比,Trn1 实例可节省高达 50% 的培训成本 亚马逊弹性计算云 (亚马逊 EC2)实例。 此外, AWS 神经元开发工具包 发布是为了改进这种加速,为开发人员提供工具来与这种技术交互,例如编译、运行时和配置文件,以实现高性能和具有成本效益的模型训练。
亚马逊弹性容器服务 (Amazon ECS) 是一种完全托管的容器编排服务,可简化容器化应用程序的部署、管理和扩展。 只需描述您的应用程序和所需的资源,Amazon ECS 将通过灵活的计算选项启动、监控和扩展您的应用程序,并自动集成到您的应用程序需要的其他支持性 AWS 服务。
在本文中,我们将向您展示如何使用 Amazon ECS 在容器中运行 ML 训练作业,以部署、管理和扩展您的 ML 工作负载。
解决方案概述
我们将引导您完成以下高级步骤:
- 提供 Trn1 实例的 ECS 集群 AWS CloudFormation.
- 使用 Neuron SDK 构建自定义容器镜像并将其推送到 Amazon Elastic Container注册 (Amazon ECR)。
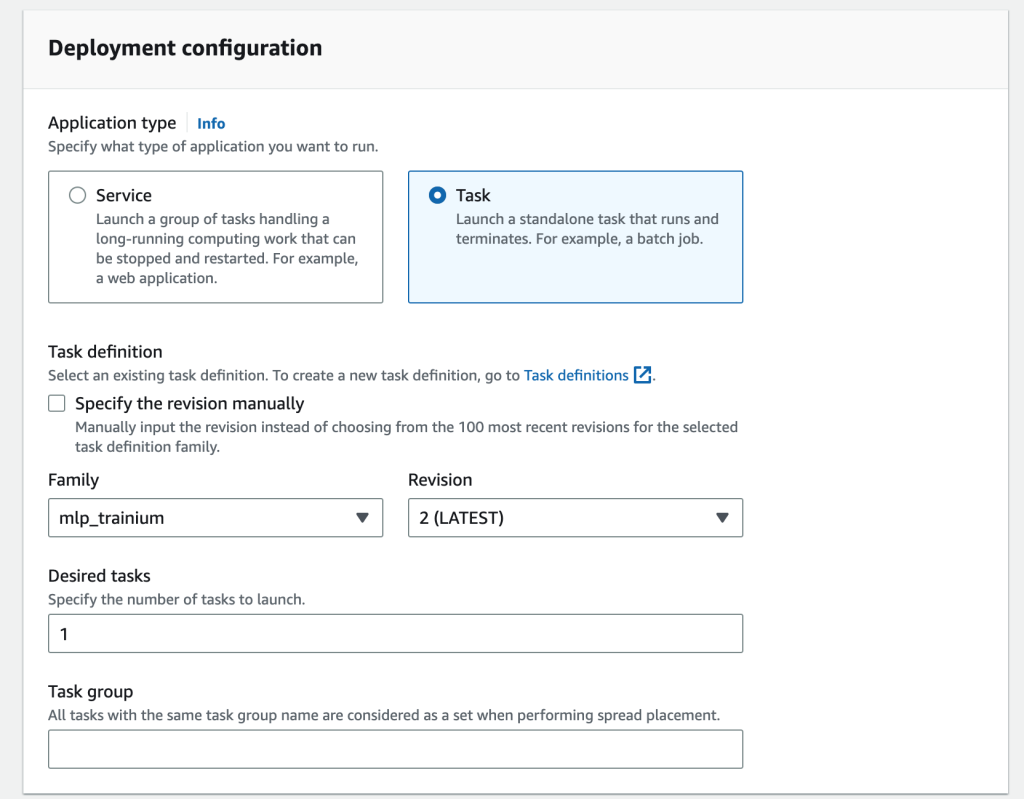
- 创建任务定义以定义要由 Amazon ECS 运行的 ML 训练作业。
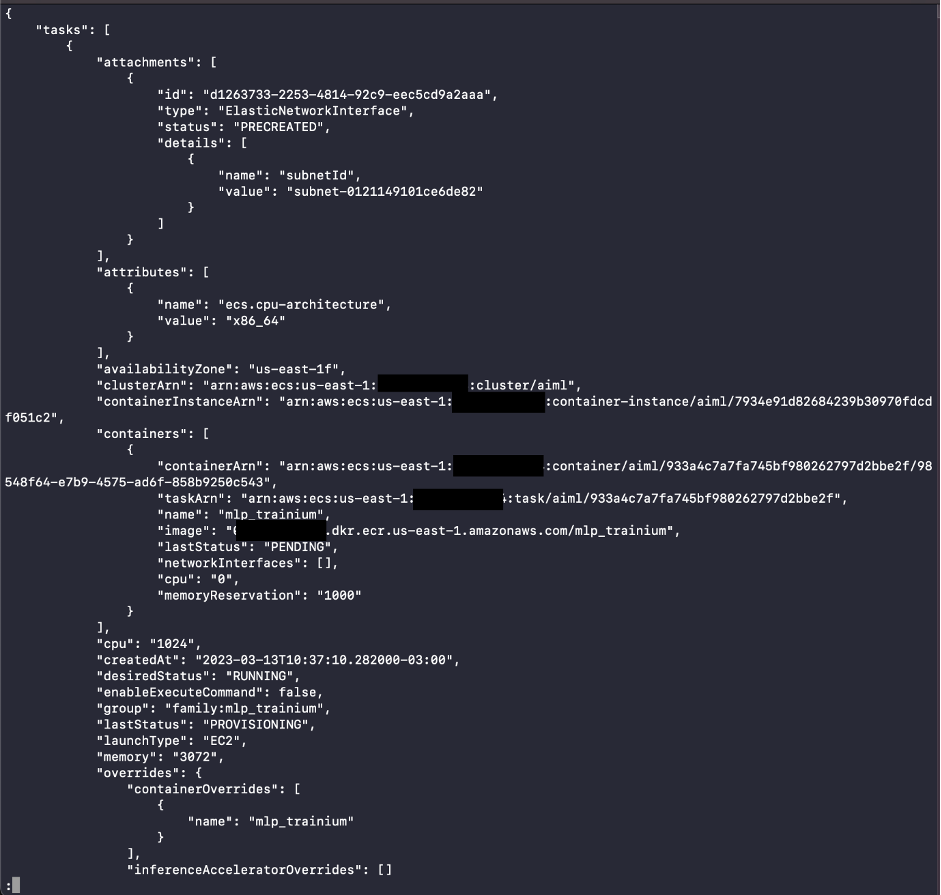
- 在 Amazon ECS 上运行 ML 任务。
先决条件
要继续学习,需要熟悉 Amazon EC2 和 Amazon ECS 等核心 AWS 服务。
提供 Trn1 实例的 ECS 集群
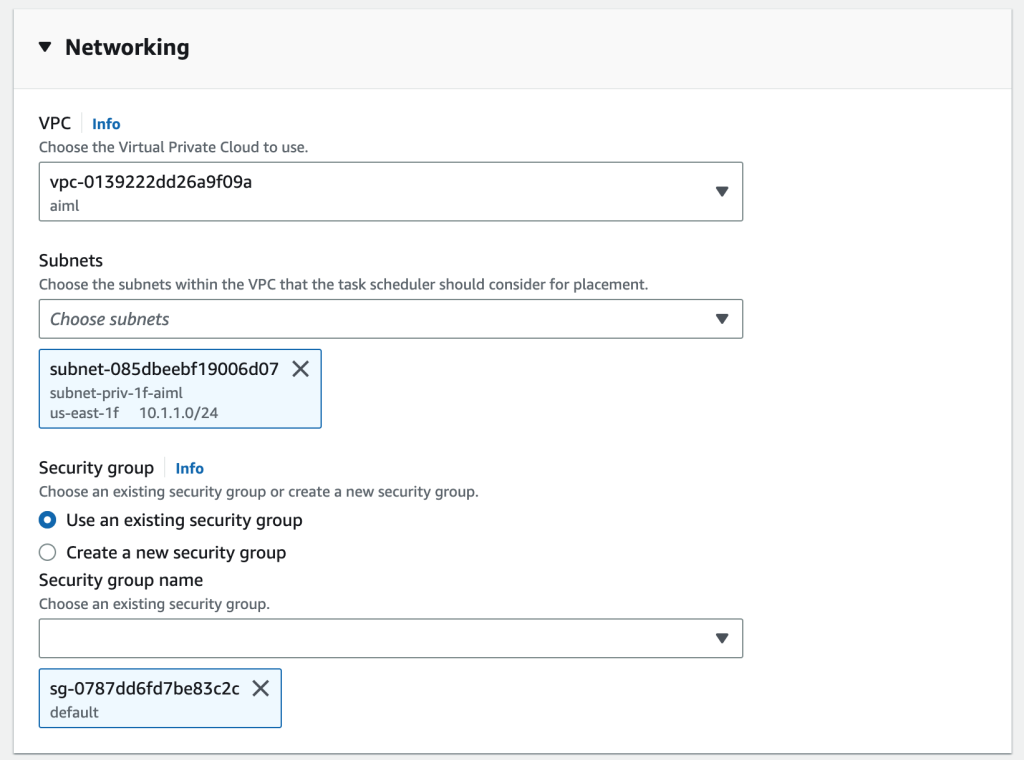
首先,启动提供的 CloudFormation模板,它将提供所需的资源,例如 VPC、ECS 集群和 EC2 Trainium 实例。
我们使用 Neuron SDK 在 AWS 推理 和基于 Trainium 的实例。 它支持您在端到端 ML 开发生命周期中创建新模型、优化它们,然后将它们部署到生产环境中。 要使用 Trainium 训练您的模型,您需要在运行 ECS 任务的 EC2 实例上安装 Neuron SDK,以映射与硬件关联的 NeuronDevice,以及将被推送到 Amazon ECR 以访问命令的 Docker 映像训练你的模型。
Amazon Linux 2 或 Ubuntu 20 的标准版本没有安装 AWS Neuron 驱动程序。 因此,我们有两种不同的选择。
第一个选项是使用已安装 Neuron SDK 的深度学习亚马逊机器映像 (DLAMI)。 样品可在 GitHub回购. 您可以根据 操作系统. 然后运行以下命令获取 AMI ID:
输出将如下所示:
ami-06c40dd4f80434809
此 AMI ID 会随时间变化,因此请确保使用命令获取正确的 AMI ID。
现在,您可以在 CloudFormation 脚本中更改此 AMI ID,并使用现成的 Neuron SDK。 为此,请寻找 EcsAmiId in Parameters:
第二个选项是创建一个实例来填充 userdata 堆栈创建期间的字段。 您不需要安装它,因为 CloudFormation 会进行设置。 有关详细信息,请参阅 神经元设置指南.
对于这篇文章,我们使用选项 2,以防您需要使用自定义图像。 完成以下步骤:
- 启动提供的 CloudFormation 模板。
- 针对 键名,输入所需密钥对的名称,它将预加载参数。 对于这篇文章,我们使用
trainium-key. - 输入堆栈的名称。
- 如果你在运行
us-east-1区域,您可以保留以下值 ALB名称 和 氨基酸 默认情况下。
要检查区域中哪些可用区有 Trn1 可用,请运行以下命令:

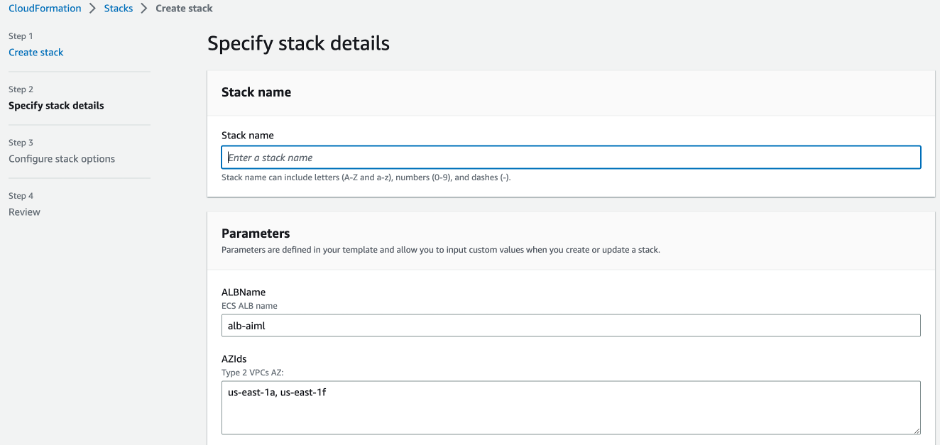
- 下一页 并完成创建堆栈。
堆叠完成后,您可以进入下一步。
使用 Neuron SDK 准备并推送 ECR 镜像
Amazon ECR 是一个完全托管的容器注册表,提供高性能托管,因此您可以在任何地方可靠地部署应用程序映像和构件。 我们使用 Amazon ECR 来存储自定义 Docker 映像,其中包含我们的脚本和 Neuron 包,这些映像需要使用在 Trn1 实例上运行的 ECS 作业来训练模型。 您可以使用 AWS命令行界面 (AWS CLI) 或 AWS管理控制台. 对于这篇文章,我们使用控制台。 完成以下步骤:
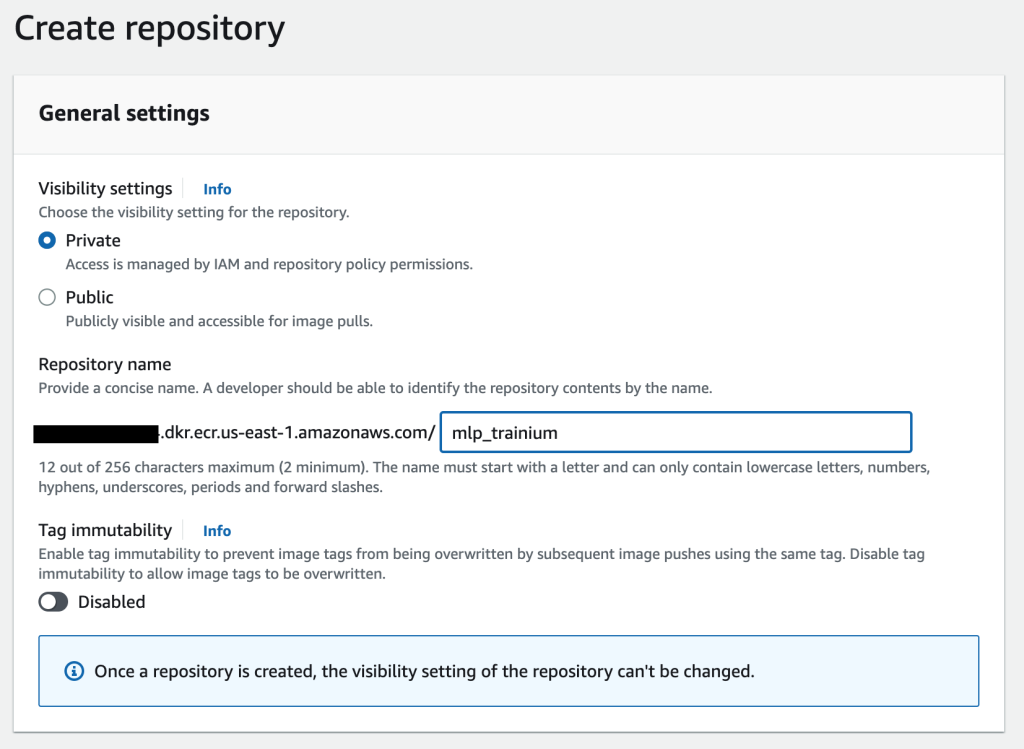
- 在 Amazon ECR 控制台上,创建一个新存储库。
- 针对 可见性设置选择 私做.
- 针对 存储库名称,输入名称。
- 创建存储库.
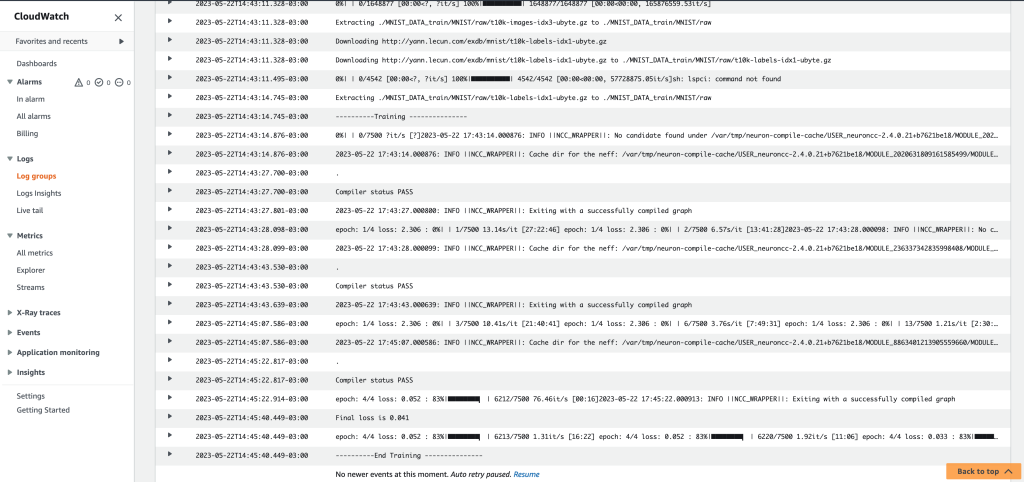
现在你有了一个存储库,让我们构建并推送一个图像,它可以在本地构建(到你的笔记本电脑中)或在 AWS 云9 环境。 我们正在训练多层感知器 (MLP) 模型。 原代码参考 多层感知器训练教程.
它已经与 Neuron 兼容,因此您无需更改任何代码。
- 5。 创建一个 Dockerfile 具有安装 Neuron SDK 和训练脚本的命令:


 纪列美·里奇 是 Amazon Web Services 的高级初创公司解决方案架构师,帮助初创公司实现应用程序的现代化和优化成本。 他在金融领域的公司拥有超过 10 年的经验,目前正在与一个 AI/ML 专家团队合作。
纪列美·里奇 是 Amazon Web Services 的高级初创公司解决方案架构师,帮助初创公司实现应用程序的现代化和优化成本。 他在金融领域的公司拥有超过 10 年的经验,目前正在与一个 AI/ML 专家团队合作。 埃万德罗佛朗哥 是一名 AI/ML 专家解决方案架构师,致力于 Amazon Web Services。 他帮助 AWS 客户克服与基于 AWS 的 AI/ML 相关的业务挑战。 他从事技术工作超过 15 年,从软件开发、基础设施、无服务器到机器学习。
埃万德罗佛朗哥 是一名 AI/ML 专家解决方案架构师,致力于 Amazon Web Services。 他帮助 AWS 客户克服与基于 AWS 的 AI/ML 相关的业务挑战。 他从事技术工作超过 15 年,从软件开发、基础设施、无服务器到机器学习。 马修·麦克莱恩 领导 Annapurna ML 解决方案架构团队,帮助客户采用 AWS Trainium 和 AWS Inferentia 产品。 他热衷于生成式 AI,在过去 10 年里一直在帮助客户采用 AWS 技术。
马修·麦克莱恩 领导 Annapurna ML 解决方案架构团队,帮助客户采用 AWS Trainium 和 AWS Inferentia 产品。 他热衷于生成式 AI,在过去 10 年里一直在帮助客户采用 AWS 技术。
- SEO 支持的内容和 PR 分发。 今天得到放大。
- 柏拉图爱流。 Web3 数据智能。 知识放大。 访问这里。
- 与 Adryenn Ashley 一起铸造未来。 访问这里。
- 使用 PREIPO® 买卖 PRE-IPO 公司的股票。 访问这里。
- Sumber: https://aws.amazon.com/blogs/machine-learning/scale-your-machine-learning-workloads-on-amazon-ecs-powered-by-aws-trainium-instances/

