Ngôn ngữ truy vấn có cấu trúc (SQL) là một ngôn ngữ phức tạp đòi hỏi sự hiểu biết về cơ sở dữ liệu và siêu dữ liệu. Hôm nay, trí tuệ nhân tạo có thể hỗ trợ những người không có kiến thức về SQL. Nhiệm vụ AI tổng quát này được gọi là chuyển văn bản sang SQL, tạo ra các truy vấn SQL từ xử lý ngôn ngữ tự nhiên (NLP) và chuyển đổi văn bản thành SQL chính xác về mặt ngữ nghĩa. Giải pháp trong bài đăng này nhằm mục đích đưa hoạt động phân tích doanh nghiệp lên một tầm cao mới bằng cách rút ngắn đường dẫn đến dữ liệu của bạn bằng ngôn ngữ tự nhiên.
Với sự xuất hiện của các mô hình ngôn ngữ lớn (LLM), việc tạo SQL dựa trên NLP đã trải qua một sự chuyển đổi đáng kể. Thể hiện hiệu suất vượt trội, LLM hiện có khả năng tạo các truy vấn SQL chính xác từ các mô tả ngôn ngữ tự nhiên. Tuy nhiên, những thách thức vẫn còn đó. Đầu tiên, ngôn ngữ của con người vốn đã mơ hồ và phụ thuộc vào ngữ cảnh, trong khi SQL lại chính xác, mang tính toán học và có cấu trúc. Khoảng cách này có thể dẫn đến việc chuyển đổi không chính xác nhu cầu của người dùng sang SQL được tạo. Thứ hai, bạn có thể cần xây dựng các tính năng chuyển văn bản sang SQL cho mọi cơ sở dữ liệu vì dữ liệu thường không được lưu trữ trong một mục tiêu duy nhất. Bạn có thể phải tạo lại khả năng cho mọi cơ sở dữ liệu để cho phép người dùng tạo SQL dựa trên NLP. Thứ ba, mặc dù việc áp dụng các giải pháp phân tích tập trung như hồ dữ liệu và kho dữ liệu ngày càng nhiều, độ phức tạp vẫn tăng lên với các tên bảng khác nhau và siêu dữ liệu khác cần thiết để tạo SQL cho các nguồn mong muốn. Do đó, việc thu thập siêu dữ liệu toàn diện và chất lượng cao cũng vẫn là một thách thức. Để tìm hiểu thêm về các phương pháp hay nhất và mẫu thiết kế chuyển văn bản sang SQL, hãy xem Tạo giá trị từ dữ liệu doanh nghiệp: Các phương pháp hay nhất cho Text2SQL và AI tổng quát.
Giải pháp của chúng tôi nhằm giải quyết những thách thức đó bằng cách sử dụng nền tảng Amazon và Dịch vụ phân tích AWS. Chúng tôi sử dụng Nhân chủng học Claude v2.1 trên Amazon Bedrock với tư cách là LLM của chúng tôi. Để giải quyết các thách thức, giải pháp của chúng tôi trước tiên kết hợp siêu dữ liệu của các nguồn dữ liệu trong Danh mục dữ liệu keo AWS để tăng độ chính xác của truy vấn SQL được tạo. Quy trình công việc cũng bao gồm vòng lặp đánh giá và sửa lỗi cuối cùng, trong trường hợp bất kỳ vấn đề SQL nào được xác định bởi amazon Athena, được sử dụng ở phía dưới làm công cụ SQL. Athena cũng cho phép chúng ta sử dụng vô số điểm cuối và trình kết nối được hỗ trợ để bao phủ một tập hợp lớn các nguồn dữ liệu.
Sau khi thực hiện các bước xây dựng giải pháp, chúng tôi trình bày kết quả của một số kịch bản thử nghiệm với mức độ phức tạp SQL khác nhau. Cuối cùng, chúng ta thảo luận về cách kết hợp các nguồn dữ liệu khác nhau vào các truy vấn SQL của bạn một cách đơn giản.
Tổng quan về giải pháp
Có ba thành phần quan trọng trong kiến trúc của chúng tôi: Thế hệ tăng cường truy xuất (RAG) với siêu dữ liệu cơ sở dữ liệu, vòng lặp tự sửa lỗi nhiều bước và Athena là công cụ SQL của chúng tôi.
Chúng tôi sử dụng phương pháp RAG để truy xuất mô tả bảng và mô tả lược đồ (cột) từ kho dữ liệu AWS Glue để đảm bảo rằng yêu cầu có liên quan đến bảng và tập dữ liệu phù hợp. Trong giải pháp của mình, chúng tôi đã xây dựng các bước riêng lẻ để chạy khung RAG với Danh mục dữ liệu AWS Glue nhằm mục đích minh họa. Tuy nhiên, bạn cũng có thể sử dụng cơ sở kiến thức trong Amazon Bedrock để xây dựng giải pháp RAG một cách nhanh chóng.
Thành phần nhiều bước cho phép LLM sửa truy vấn SQL được tạo để đảm bảo độ chính xác. Ở đây, SQL được tạo sẽ được gửi để tìm lỗi cú pháp. Chúng tôi sử dụng thông báo lỗi Athena để làm phong phú thêm lời nhắc về LLM nhằm sửa lỗi chính xác và hiệu quả hơn trong SQL được tạo.
Bạn có thể coi các thông báo lỗi thỉnh thoảng đến từ Athena giống như phản hồi. Chi phí của bước sửa lỗi là không đáng kể so với giá trị mang lại. Bạn thậm chí có thể bao gồm các bước khắc phục này dưới dạng ví dụ học tập tăng cường có giám sát để tinh chỉnh LLM của mình. Tuy nhiên, chúng tôi không đề cập đến luồng này trong bài viết của mình vì mục đích đơn giản.
Lưu ý rằng luôn có rủi ro cố hữu về sự thiếu chính xác, điều này đương nhiên đi kèm với các giải pháp AI tổng hợp. Ngay cả khi thông báo lỗi của Athena có hiệu quả cao trong việc giảm thiểu rủi ro này, bạn vẫn có thể thêm nhiều biện pháp kiểm soát và chế độ xem khác, chẳng hạn như phản hồi của con người hoặc truy vấn mẫu để tinh chỉnh, nhằm giảm thiểu hơn nữa những rủi ro đó.
Athena không chỉ cho phép chúng tôi sửa các truy vấn SQL mà còn đơn giản hóa vấn đề tổng thể cho chúng tôi vì nó đóng vai trò là trung tâm, trong đó các nan hoa là nhiều nguồn dữ liệu. Quản lý quyền truy cập, cú pháp SQL và nhiều nội dung khác đều được xử lý thông qua Athena.
Sơ đồ sau minh họa kiến trúc giải pháp.
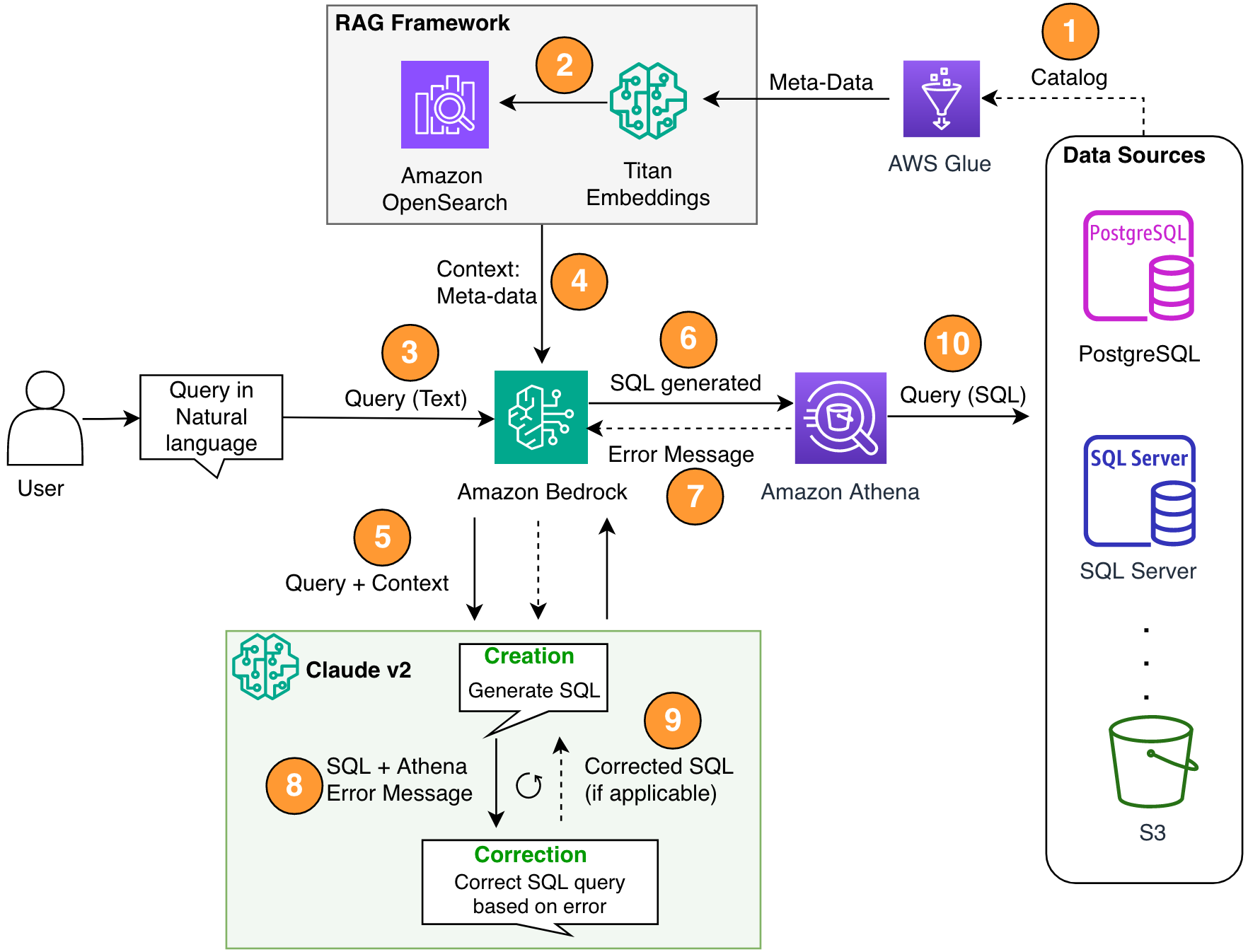
Hình 1. Cấu trúc giải pháp và quy trình.
Luồng quy trình bao gồm các bước sau:
- Tạo danh mục dữ liệu AWS Glue sử dụng trình thu thập thông tin AWS Glue (hoặc một phương pháp khác).
- Sử dụng Mô hình Titan-Text-Embeddings trên Amazon Bedrock, chuyển đổi siêu dữ liệu thành các phần nhúng và lưu trữ nó trong một Amazon OpenSearch Serverless cửa hàng vector, đóng vai trò là cơ sở kiến thức trong khuôn khổ RAG của chúng tôi.
Ở giai đoạn này, quy trình đã sẵn sàng nhận truy vấn bằng ngôn ngữ tự nhiên. Bước 7–9 thể hiện vòng điều chỉnh, nếu có.
- Người dùng nhập truy vấn của họ bằng ngôn ngữ tự nhiên. Bạn có thể sử dụng bất kỳ ứng dụng web nào để cung cấp giao diện người dùng trò chuyện. Do đó, chúng tôi không đề cập đến chi tiết giao diện người dùng trong bài đăng của mình.
- Giải pháp áp dụng khung RAG thông qua tìm kiếm sự tương đồng, bổ sung thêm ngữ cảnh từ siêu dữ liệu từ cơ sở dữ liệu vectơ. Bảng này được sử dụng để tìm bảng, cơ sở dữ liệu và thuộc tính chính xác.
- Truy vấn được hợp nhất với ngữ cảnh và gửi đến Nhân chủng học Claude v2.1 trên Amazon Bedrock.
- Mô hình nhận truy vấn SQL được tạo và kết nối với Athena để xác thực cú pháp.
- Nếu Athena cung cấp thông báo lỗi đề cập đến cú pháp không chính xác thì mô hình sẽ sử dụng văn bản lỗi từ phản hồi của Athena.
- Lời nhắc mới bổ sung thêm phản hồi của Athena.
- Mô hình tạo SQL đã sửa và tiếp tục quá trình. Việc lặp lại này có thể được thực hiện nhiều lần.
- Cuối cùng, chúng tôi chạy SQL bằng Athena và tạo đầu ra. Ở đây, đầu ra được trình bày cho người dùng. Để đơn giản về mặt kiến trúc, chúng tôi không trình bày bước này.
Điều kiện tiên quyết
Đối với bài đăng này, bạn nên hoàn thành các điều kiện tiên quyết sau:
- Có một Tài khoản AWS.
- đặt các Giao diện dòng lệnh AWS (AWS CLI).
- Thiết lập SDK cho Python (Boto3).
- Tạo danh mục dữ liệu AWS Glue sử dụng trình thu thập thông tin AWS Glue (hoặc một phương pháp khác).
- Sử dụng Mô hình Titan-Text-Embeddings trên Amazon Bedrock, chuyển đổi siêu dữ liệu thành các phần nhúng và lưu trữ nó trong OpenSearch Serverless cửa hàng vector.
Thực hiện giải pháp
Bạn có thể sử dụng như sau Máy tính xách tay Jupyter, bao gồm tất cả các đoạn mã được cung cấp trong phần này, để xây dựng giải pháp. Chúng tôi khuyên bạn nên sử dụng Xưởng sản xuất Amazon SageMaker để mở sổ ghi chép này bằng phiên bản ml.t3.medium với hạt nhân Python 3 (Khoa học dữ liệu). Để biết hướng dẫn, hãy tham khảo Đào tạo mô hình học máy. Hoàn tất các bước sau để thiết lập giải pháp:
- Tạo cơ sở kiến thức trong Dịch vụ OpenSearch cho khung RAG:
- Xây dựng lời nhắc (
final_question) bằng cách kết hợp đầu vào của người dùng bằng ngôn ngữ tự nhiên (user_query), siêu dữ liệu có liên quan từ kho lưu trữ vectơ (vector_search_match) và hướng dẫn của chúng tôi (details): - Gọi Amazon Bedrock cho LLM (Claude v2) và nhắc nó tạo truy vấn SQL. Trong đoạn mã sau, nó thực hiện nhiều lần thử để minh họa bước tự sửa lỗi:x
- Nếu nhận được bất kỳ vấn đề nào với truy vấn SQL được tạo (
{sqlgenerated}) từ phản hồi của Athena ({syntaxcheckmsg}), lời nhắc mới (prompt) được tạo dựa trên phản hồi và mô hình sẽ thử lại để tạo SQL mới: - Sau khi SQL được tạo, máy khách Athena được gọi để chạy và tạo đầu ra:
Kiểm tra giải pháp
Trong phần này, chúng tôi chạy giải pháp của mình với các kịch bản ví dụ khác nhau để kiểm tra mức độ phức tạp khác nhau của truy vấn SQL.
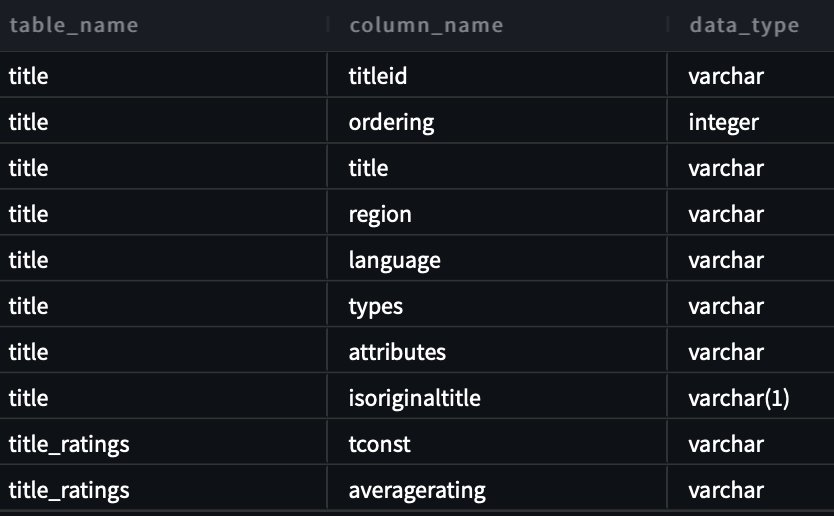
Để kiểm tra khả năng chuyển văn bản sang SQL, chúng tôi sử dụng hai bộ dữ liệu có sẵn từ IMDB. Các tập hợp con dữ liệu IMDb có sẵn cho mục đích sử dụng cá nhân và phi thương mại. Bạn có thể tải xuống các tập dữ liệu và lưu trữ chúng trong Dịch vụ lưu trữ đơn giản của Amazon (Amazon S3). Bạn có thể sử dụng đoạn mã Spark SQL sau để tạo bảng trong AWS Glue. Đối với ví dụ này, chúng tôi sử dụng title_ratings và title:
Lưu trữ dữ liệu trên Amazon S3 và siêu dữ liệu trong AWS Glue
Trong trường hợp này, tập dữ liệu của chúng tôi được lưu trữ trong vùng lưu trữ S3. Athena có trình kết nối S3 cho phép bạn sử dụng Amazon S3 làm nguồn dữ liệu có thể truy vấn.
Đối với truy vấn đầu tiên, chúng tôi cung cấp thông tin đầu vào “Tôi chưa quen với vấn đề này. Bạn có thể giúp tôi xem tất cả các bảng và cột trong lược đồ imdb không?
Sau đây là truy vấn được tạo:
Ảnh chụp màn hình và mã sau đây hiển thị kết quả của chúng tôi.
Đối với truy vấn thứ hai, chúng tôi yêu cầu “Hiển thị cho tôi tất cả tiêu đề và thông tin chi tiết ở khu vực Hoa Kỳ có xếp hạng cao hơn 9.5”.
Sau đây là truy vấn được tạo của chúng tôi:
Câu trả lời như sau.

Đối với truy vấn thứ ba, chúng tôi nhập “Phản hồi tuyệt vời! Bây giờ hãy cho tôi xem tất cả các tựa sách loại gốc có xếp hạng trên 7.5 và không ở khu vực Hoa Kỳ.”
Truy vấn sau đây được tạo ra:
Chúng tôi nhận được kết quả sau đây.

Tạo SQL tự sửa
Tình huống này mô phỏng một truy vấn SQL có vấn đề về cú pháp. Tại đây, SQL được tạo ra sẽ tự sửa dựa trên phản hồi từ Athena. Trong câu trả lời sau đây, Athena đã đưa ra một COLUMN_NOT_FOUND lỗi và đề cập rằng table_description không thể giải quyết được:
Sử dụng giải pháp với các nguồn dữ liệu khác
Để sử dụng giải pháp với các nguồn dữ liệu khác, Athena sẽ xử lý công việc này cho bạn. Để làm điều này, Athena sử dụng kết nối nguồn dữ liệu có thể được sử dụng với truy vấn liên hợp. Bạn có thể coi trình kết nối là phần mở rộng của công cụ truy vấn Athena. Trình kết nối nguồn dữ liệu Athena dựng sẵn tồn tại cho các nguồn dữ liệu như Nhật ký Amazon CloudWatch, Máy phát điện Amazon, Amazon DocumentDB (với khả năng tương thích MongoDB)và Dịch vụ cơ sở dữ liệu quan hệ của Amazon (Amazon RDS) và các nguồn dữ liệu quan hệ tuân thủ JDBC như MySQL và PostgreSQL theo giấy phép Apache 2.0. Sau khi thiết lập kết nối với bất kỳ nguồn dữ liệu nào, bạn có thể sử dụng cơ sở mã trước đó để mở rộng giải pháp. Để biết thêm thông tin, hãy tham khảo Truy vấn bất kỳ nguồn dữ liệu nào bằng truy vấn liên kết mới của Amazon Athena.
Làm sạch
Để dọn sạch tài nguyên, bạn có thể bắt đầu bằng cách dọn dẹp thùng S3 của bạn nơi dữ liệu cư trú. Trừ khi ứng dụng của bạn gọi Amazon Bedrock, nếu không ứng dụng sẽ không phải chịu bất kỳ chi phí nào. Vì mục đích thực hành tốt nhất về quản lý cơ sở hạ tầng, chúng tôi khuyên bạn nên xóa các tài nguyên được tạo trong phần trình diễn này.
Kết luận
Trong bài đăng này, chúng tôi đã trình bày một giải pháp cho phép bạn sử dụng NLP để tạo các truy vấn SQL phức tạp với nhiều tài nguyên được Athena kích hoạt. Chúng tôi cũng đã tăng độ chính xác của các truy vấn SQL được tạo thông qua vòng đánh giá gồm nhiều bước dựa trên thông báo lỗi từ các quy trình tiếp theo. Ngoài ra, chúng tôi đã sử dụng siêu dữ liệu trong Danh mục dữ liệu AWS Glue để xem xét tên bảng được yêu cầu trong truy vấn thông qua khung RAG. Sau đó, chúng tôi đã thử nghiệm giải pháp trong nhiều tình huống thực tế khác nhau với mức độ phức tạp của truy vấn khác nhau. Cuối cùng, chúng tôi đã thảo luận về cách áp dụng giải pháp này cho các nguồn dữ liệu khác nhau được Athena hỗ trợ.
Amazon Bedrock là trung tâm của giải pháp này. Amazon Bedrock có thể giúp bạn xây dựng nhiều ứng dụng AI có tính tổng hợp. Để bắt đầu với Amazon Bedrock, chúng tôi khuyên bạn nên làm theo hướng dẫn bắt đầu nhanh sau đây Repo GitHub và làm quen với việc xây dựng các ứng dụng AI có tính sáng tạo. Bạn cũng có thể thử cơ sở kiến thức trong Amazon Bedrock để nhanh chóng xây dựng các giải pháp RAG như vậy.
Về các tác giả
 Gấu trúc Sanjeeb là kỹ sư Dữ liệu và ML tại Amazon. Với nền tảng về AI/ML, Khoa học dữ liệu và Dữ liệu lớn, Sanjeeb thiết kế và phát triển các giải pháp ML và dữ liệu đổi mới nhằm giải quyết các thách thức kỹ thuật phức tạp và đạt được các mục tiêu chiến lược cho người bán 3P toàn cầu quản lý doanh nghiệp của họ trên Amazon. Ngoài công việc là kỹ sư Dữ liệu và ML tại Amazon, Sanjeeb Panda còn là một người đam mê ẩm thực và âm nhạc.
Gấu trúc Sanjeeb là kỹ sư Dữ liệu và ML tại Amazon. Với nền tảng về AI/ML, Khoa học dữ liệu và Dữ liệu lớn, Sanjeeb thiết kế và phát triển các giải pháp ML và dữ liệu đổi mới nhằm giải quyết các thách thức kỹ thuật phức tạp và đạt được các mục tiêu chiến lược cho người bán 3P toàn cầu quản lý doanh nghiệp của họ trên Amazon. Ngoài công việc là kỹ sư Dữ liệu và ML tại Amazon, Sanjeeb Panda còn là một người đam mê ẩm thực và âm nhạc.
 Burak Gozluklu là Kiến trúc sư chính về Giải pháp Chuyên gia AI/ML có trụ sở tại Boston, MA. Anh giúp các khách hàng chiến lược áp dụng các công nghệ AWS và đặc biệt là các giải pháp Generative AI để đạt được mục tiêu kinh doanh của họ. Burak có bằng Tiến sĩ về Kỹ thuật Hàng không Vũ trụ tại METU, bằng Thạc sĩ Kỹ thuật Hệ thống và bằng tiến sĩ về động lực học hệ thống tại MIT ở Cambridge, MA. Burak vẫn là một chi nhánh nghiên cứu ở MIT. Burak đam mê yoga và thiền định.
Burak Gozluklu là Kiến trúc sư chính về Giải pháp Chuyên gia AI/ML có trụ sở tại Boston, MA. Anh giúp các khách hàng chiến lược áp dụng các công nghệ AWS và đặc biệt là các giải pháp Generative AI để đạt được mục tiêu kinh doanh của họ. Burak có bằng Tiến sĩ về Kỹ thuật Hàng không Vũ trụ tại METU, bằng Thạc sĩ Kỹ thuật Hệ thống và bằng tiến sĩ về động lực học hệ thống tại MIT ở Cambridge, MA. Burak vẫn là một chi nhánh nghiên cứu ở MIT. Burak đam mê yoga và thiền định.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- PlatoSức khỏe. Tình báo thử nghiệm lâm sàng và công nghệ sinh học. Truy cập Tại đây.
- nguồn: https://aws.amazon.com/blogs/machine-learning/build-a-robust-text-to-sql-solution-generating-complex-queries-self-correcting-and-querying-diverse-data-sources/

