Vào tháng 2022 năm XNUMX, chúng tôi công bố rằng khách hàng AWS có thể tạo hình ảnh từ văn bản với Khuếch tán ổn định mô hình trong Khởi động Amazon SageMaker. Khuếch tán ổn định là một mô hình học sâu cho phép bạn tạo ra hình ảnh chân thực, chất lượng cao và tác phẩm nghệ thuật tuyệt đẹp chỉ trong vài giây. Mặc dù việc tạo ra những hình ảnh ấn tượng có thể được sử dụng trong các ngành từ nghệ thuật đến NFT và hơn thế nữa, ngày nay chúng tôi cũng kỳ vọng AI có thể cá nhân hóa được. Hôm nay, chúng tôi thông báo rằng bạn có thể cá nhân hóa mô hình tạo hình ảnh cho trường hợp sử dụng của mình bằng cách tinh chỉnh nó trên tập dữ liệu tùy chỉnh của bạn trong Khởi động Amazon SageMaker. Điều này có thể hữu ích khi tạo tác phẩm nghệ thuật, biểu trưng, thiết kế tùy chỉnh, NFT, v.v. hoặc những nội dung thú vị như tạo hình ảnh AI tùy chỉnh về thú cưng hoặc hình đại diện của chính bạn.
Trong bài đăng này, chúng tôi cung cấp tổng quan về cách tinh chỉnh mô hình Khuếch tán ổn định theo hai cách: lập trình thông qua API JumpStart có sẵn trong SDK Python của SageMakervà giao diện người dùng (UI) của JumpStart trong Xưởng sản xuất Amazon SageMaker. Chúng tôi cũng thảo luận về cách đưa ra các lựa chọn thiết kế bao gồm chất lượng tập dữ liệu, kích thước của tập dữ liệu đào tạo, lựa chọn giá trị siêu tham số và khả năng áp dụng cho nhiều tập dữ liệu. Cuối cùng, chúng ta thảo luận về hơn 80 mô hình tinh chỉnh có sẵn công khai với các kiểu và ngôn ngữ nhập khác nhau được thêm gần đây vào JumpStart.
Truyền bá ổn định và học tập chuyển giao
Khuếch tán ổn định là một mô hình chuyển văn bản thành hình ảnh cho phép bạn tạo ra những hình ảnh chân thực chỉ bằng một lời nhắc văn bản. Một mô hình khuếch tán đào tạo bằng cách học cách loại bỏ nhiễu đã được thêm vào hình ảnh thực. Quá trình khử nhiễu này tạo ra hình ảnh chân thực. Các mô hình này cũng có thể tạo hình ảnh từ văn bản một mình bằng cách điều chỉnh quá trình tạo trên văn bản. Chẳng hạn, Khuếch tán ổn định là sự khuếch tán tiềm ẩn trong đó mô hình học cách nhận dạng các hình dạng trong hình ảnh nhiễu thuần túy và dần dần đưa các hình dạng này vào tiêu điểm nếu các hình dạng khớp với các từ trong văn bản đầu vào. Trước tiên, văn bản phải được nhúng vào một không gian tiềm ẩn bằng mô hình ngôn ngữ. Sau đó, một loạt các hoạt động bổ sung tiếng ồn và loại bỏ tiếng ồn được thực hiện trong không gian tiềm ẩn với kiến trúc U-Net. Cuối cùng, đầu ra khử nhiễu được giải mã thành không gian pixel.

Trong học máy (ML), khả năng chuyển kiến thức học được trong lĩnh vực này sang lĩnh vực khác được gọi là học chuyển. Bạn có thể sử dụng phương pháp học chuyển giao để tạo ra các mô hình chính xác trên tập dữ liệu nhỏ hơn của mình, với chi phí đào tạo thấp hơn nhiều so với chi phí đào tạo mô hình ban đầu. Với học chuyển đổi, bạn có thể tinh chỉnh mô hình khuếch tán ổn định trên tập dữ liệu của riêng mình chỉ với năm hình ảnh. Ví dụ, bên trái là các hình ảnh huấn luyện của một con chó tên là Doppler được sử dụng để tinh chỉnh mô hình, ở giữa và bên phải là các hình ảnh do mô hình tinh chỉnh tạo ra khi được yêu cầu dự đoán hình ảnh Doppler trên bãi biển và một bản phác thảo bằng bút chì.

Bên trái là hình ảnh chiếc ghế màu trắng được sử dụng để tinh chỉnh mô hình và hình ảnh chiếc ghế màu đỏ do mô hình tinh chỉnh tạo ra. Bên phải là hình ảnh chiếc ghế dài được sử dụng để tinh chỉnh mô hình và hình ảnh chú mèo ngồi trên chiếc ghế dài.

Tinh chỉnh các mô hình lớn như Khuếch tán ổn định thường yêu cầu bạn cung cấp các tập lệnh đào tạo. Có rất nhiều vấn đề, bao gồm các vấn đề về bộ nhớ, vấn đề về kích thước tải trọng, v.v. Hơn nữa, bạn phải chạy thử nghiệm từ đầu đến cuối để đảm bảo rằng tập lệnh, mô hình và phiên bản mong muốn hoạt động cùng nhau một cách hiệu quả. JumpStart đơn giản hóa quy trình này bằng cách cung cấp các tập lệnh sẵn sàng sử dụng đã được thử nghiệm mạnh mẽ. Kịch bản tinh chỉnh JumpStart cho các mô hình Khuếch tán Ổn định được xây dựng trên kịch bản tinh chỉnh từ Dream Booth. Bạn có thể truy cập các tập lệnh này chỉ bằng một cú nhấp chuột thông qua Giao diện người dùng Studio hoặc với rất ít dòng mã thông qua API JumpStart.
Lưu ý rằng bằng cách sử dụng mô hình Khuếch tán ổn định, bạn đồng ý với Giấy phép CreativeML Open RAIL++-M.
Sử dụng JumpStart theo lập trình với SageMaker SDK
Phần này mô tả cách đào tạo và triển khai mô hình với SDK Python của SageMaker. Chúng tôi chọn một mô hình được đào tạo trước phù hợp trong JumpStart, đào tạo mô hình này với công việc đào tạo SageMaker và triển khai mô hình được đào tạo tới điểm cuối SageMaker. Hơn nữa, chúng tôi chạy suy luận trên điểm cuối đã triển khai, tất cả đều sử dụng SageMaker Python SDK. Các ví dụ sau đây chứa các đoạn mã. Để biết mã đầy đủ với tất cả các bước trong bản trình diễn này, hãy xem phần Giới thiệu về JumpStart – Chuyển văn bản thành hình ảnh sổ tay ví dụ.
Huấn luyện và tinh chỉnh mô hình Khuếch tán ổn định
Mỗi mô hình được xác định bởi một duy nhất model_id. Mã sau đây cho biết cách tinh chỉnh mô hình cơ sở Khuếch tán ổn định 2.1 được xác định bởi model_id model-txt2img-stabilityai-stable-diffusion-v2-1-base trên tập dữ liệu huấn luyện tùy chỉnh. Đối với một danh sách đầy đủ của model_id các giá trị và mô hình nào có thể tinh chỉnh được, hãy tham khảo Các thuật toán tích hợp với Bảng mô hình được đào tạo trước. Cho mỗi model_id, để bắt đầu công việc đào tạo SageMaker thông qua Người định giá của SageMaker Python SDK, bạn cần tìm nạp URI hình ảnh Docker, URI tập lệnh đào tạo và URI mô hình được đào tạo trước thông qua các chức năng tiện ích được cung cấp trong SageMaker. URI tập lệnh đào tạo chứa tất cả mã cần thiết để xử lý dữ liệu, tải mô hình được đào tạo trước, đào tạo mô hình và lưu mô hình được đào tạo để suy luận. URI mô hình được đào tạo trước chứa định nghĩa kiến trúc mô hình được đào tạo trước và các tham số của mô hình. URI mô hình được đào tạo trước dành riêng cho mô hình cụ thể. Các tarball mô hình được đào tạo trước đã được tải xuống trước từ Hugging Face và được lưu với chữ ký mô hình thích hợp trong Dịch vụ lưu trữ đơn giản của Amazon (Amazon S3) nhóm, để công việc đào tạo chạy trong sự cô lập của mạng. Xem đoạn mã sau:
Với các tạo tác đào tạo theo mô hình cụ thể này, bạn có thể tạo một đối tượng của Người định giá lớp học:
Tập dữ liệu đào tạo
Sau đây là các hướng dẫn về cách định dạng dữ liệu đào tạo:
- Đầu vào – Một thư mục chứa các ảnh ví dụ,
dataset_info.json, với cấu hình sau:- Hình ảnh có thể ở định dạng .png, .jpg hoặc .jpeg
- Sản phẩm
dataset_info.jsontập tin phải có định dạng{'instance_prompt':<<instance_prompt>>}
- Đầu ra – Một mô hình được đào tạo có thể được triển khai để suy luận
Đường dẫn S3 sẽ giống như s3://bucket_name/input_directory/. Lưu ý dấu vết / bắt buộc.
Sau đây là một định dạng mẫu của dữ liệu huấn luyện:
Để biết hướng dẫn về cách định dạng dữ liệu trong khi sử dụng bảo quản trước, hãy tham khảo phần bảo quản trước trong bài đăng này.
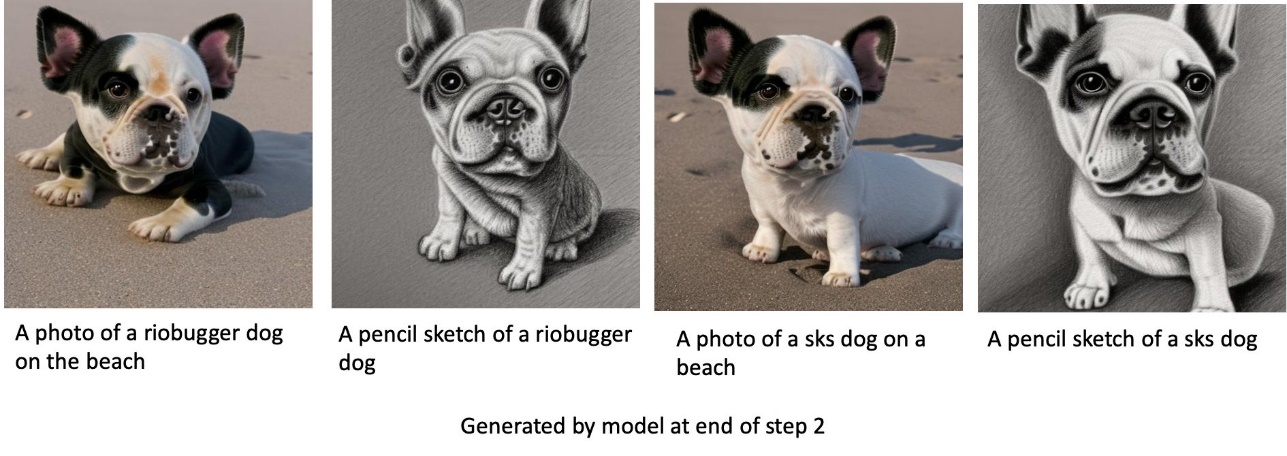
Chúng tôi cung cấp bộ dữ liệu mặc định về hình ảnh mèo. Nó bao gồm tám hình ảnh (hình ảnh mẫu tương ứng với dấu nhắc mẫu) của một con mèo không có hình ảnh lớp. Nó có thể được tải về từ GitHub. Nếu sử dụng tập dữ liệu mặc định, hãy thử lời nhắc “ảnh của một con mèo riobugger” trong khi thực hiện suy luận trong sổ ghi chép demo.
Giấy phép: MIT.
Siêu tham số
Tiếp theo, để học chuyển giao trên tập dữ liệu tùy chỉnh của bạn, bạn có thể cần phải thay đổi các giá trị mặc định của siêu tham số đào tạo. Bạn có thể lấy một từ điển Python của các siêu đường kính này với các giá trị mặc định của chúng bằng cách gọi hyperparameters.retrieve_default, cập nhật chúng khi cần, sau đó chuyển chúng đến lớp Công cụ ước tính. Xem đoạn mã sau:
Các siêu đường kính sau đây được hỗ trợ bởi thuật toán tinh chỉnh:
- with_prior_preservation – Gắn cờ để thêm tổn thất bảo quản trước. Bảo quản trước là một bộ điều chỉnh để tránh trang bị quá mức. (Lựa chọn:
[“True”,“False”], mặc định:“False”.) - num_class_images – Các lớp ảnh tối thiểu để bảo quản trước mất mát. Nếu như
with_prior_preservation = Truevà không có đủ hình ảnh đã có trongclass_data_dir, hình ảnh bổ sung sẽ được lấy mẫu vớiclass_prompt. (Giá trị: số nguyên dương, mặc định: 100.) - Kỷ nguyên – Số lượt mà thuật toán tinh chỉnh thực hiện thông qua tập dữ liệu huấn luyện. (Giá trị: số nguyên dương, mặc định: 20.)
- Max_bước – Tổng số bước huấn luyện cần thực hiện. Nếu không
None, ghi đè các kỷ nguyên. (Giá trị:“None”hoặc một chuỗi số nguyên, mặc định:“None”.) - Kích thước lô –: Số lượng ví dụ đào tạo được thực hiện trước khi trọng số mô hình được cập nhật. Giống như kích thước lô trong quá trình tạo ảnh lớp nếu
with_prior_preservation = True. (Giá trị: số nguyên dương, mặc định: 1.) - tỷ lệ học – Tốc độ mà các trọng số của mô hình được cập nhật sau khi làm việc qua từng lô ví dụ huấn luyện. (Giá trị: float dương, mặc định: 2e-06.)
- before_loss_weight – Khối lượng hao hụt trước bảo quản. (Giá trị: float dương, mặc định: 1.0.)
- center_crop – Có cắt hình ảnh trước khi thay đổi kích thước thành độ phân giải mong muốn hay không. (Lựa chọn:
[“True”/“False”], mặc định:“False”.) - lr_scheduler – Loại bộ lập lịch tỷ lệ học tập. (Lựa chọn:
["linear", "cosine", "cosine_with_restarts", "polynomial", "constant", "constant_with_warmup"], mặc định:"constant".) Để biết thêm thông tin, xem Bộ lập lịch tỷ lệ học tập. - adam_weight_decay – Trọng số phân rã để áp dụng (nếu không phải là XNUMX) cho tất cả các lớp ngoại trừ tất cả độ lệch và
LayerNormtrọng lượng trongAdamWtrình tối ưu hóa. (Giá trị: float, mặc định: 1e-2.) - adam_beta1 – Siêu tham số beta1 (tốc độ phân rã theo cấp số nhân cho ước tính thời điểm đầu tiên) cho
AdamWtrình tối ưu hóa. (Giá trị: float, mặc định: 0.9.) - adam_beta2 – Siêu tham số beta2 (tốc độ phân rã theo cấp số nhân cho ước tính thời điểm đầu tiên) cho
AdamWtrình tối ưu hóa. (Giá trị: float, mặc định: 0.999.) - adam_epsilon -
epsilonsiêu tham số choAdamWtrình tối ưu hóa. Nó thường được đặt thành một giá trị nhỏ để tránh chia cho 0. (Giá trị: float, mặc định: 1e-8.) - gradient_accumulation_steps – Số bước cập nhật cần tích lũy trước khi thực hiện chuyển lùi/cập nhật. (Giá trị: số nguyên, mặc định: 1.)
- max_grad_norm – Định mức độ dốc tối đa (đối với cắt độ dốc). (Giá trị: float, mặc định: 1.0.)
- hạt giống – Sửa trạng thái ngẫu nhiên để đạt được kết quả có thể lặp lại trong đào tạo. (Giá trị: số nguyên, mặc định: 0.)
Triển khai mô hình được đào tạo tốt
Sau khi quá trình đào tạo mô hình kết thúc, bạn có thể trực tiếp triển khai mô hình đến một điểm cuối liên tục, theo thời gian thực. Chúng tôi tìm nạp các URI hình ảnh Docker và URI tập lệnh cần thiết rồi triển khai mô hình. Xem đoạn mã sau:
Bên trái là hình ảnh huấn luyện của chú mèo tên riobugger dùng để tinh chỉnh mô hình (các thông số mặc định ngoại trừ max_steps = 400). Ở giữa và bên phải là những hình ảnh do mô hình tinh chỉnh tạo ra khi được yêu cầu dự đoán hình ảnh của riobugger trên bãi biển và một bản phác thảo bằng bút chì.

Để biết thêm chi tiết về suy luận, bao gồm các tham số được hỗ trợ, định dạng phản hồi, v.v., hãy tham khảo Tạo hình ảnh từ văn bản với mô hình khuếch tán ổn định trên Amazon SageMaker JumpStart.
Truy cập JumpStart thông qua giao diện người dùng Studio
Trong phần này, chúng tôi trình bày cách huấn luyện và triển khai các mô hình JumpStart thông qua Studio UI. Video sau đây cho biết cách tìm mô hình Khuếch tán ổn định được đào tạo trước trên JumpStart, đào tạo và sau đó triển khai nó. Trang mô hình chứa thông tin có giá trị về mô hình và cách sử dụng nó. Sau khi định cấu hình phiên bản đào tạo SageMaker, hãy chọn Train. Sau khi mô hình được đào tạo, bạn có thể triển khai mô hình được đào tạo bằng cách chọn Triển khai. Sau khi điểm cuối ở giai đoạn “đang hoạt động”, nó sẵn sàng đáp ứng các yêu cầu suy luận.
Để rút ngắn thời gian suy luận, JumpStart cung cấp một sổ ghi chép mẫu cho biết cách chạy suy luận trên điểm cuối mới được tạo. Để truy cập sổ ghi chép trong Studio, hãy chọn Mở Notebook trong Sử dụng Điểm cuối từ Studio phần của trang điểm cuối mô hình.
JumpStart cũng cung cấp một sổ ghi chép đơn giản mà bạn có thể sử dụng để tinh chỉnh mô hình khuếch tán ổn định và triển khai mô hình đã tinh chỉnh kết quả. Bạn có thể sử dụng nó để tạo ra những hình ảnh vui nhộn về chú chó của mình. Để truy cập sổ ghi chép, hãy tìm kiếm “Tạo hình ảnh Vui nhộn về chú chó của bạn” trong thanh tìm kiếm Khởi động. Để thực thi sổ ghi chép, bạn có thể sử dụng ít nhất năm hình ảnh đào tạo và tải lên thư mục studio cục bộ. Nếu bạn có nhiều hơn năm hình ảnh, bạn cũng có thể tải chúng lên. Notebook tải hình ảnh huấn luyện lên S3, huấn luyện mô hình trên tập dữ liệu của bạn và triển khai mô hình kết quả. Đào tạo có thể mất 20 phút để hoàn thành. Bạn có thể thay đổi số bước để tăng tốc độ luyện tập. Notebook cung cấp một số lời nhắc mẫu để thử với mô hình đã triển khai nhưng bạn có thể thử bất kỳ lời nhắc nào bạn muốn. Bạn cũng có thể điều chỉnh sổ ghi chép để tạo hình đại diện cho chính mình hoặc thú cưng của mình. Chẳng hạn, thay vì con chó của bạn, bạn có thể tải lên hình ảnh con mèo của mình trong bước đầu tiên, sau đó thay đổi lời nhắc từ chó thành mèo và mô hình sẽ tạo ra hình ảnh con mèo của bạn.
cân nhắc tinh chỉnh
Huấn luyện Các mô hình phổ biến ổn định có xu hướng phù hợp nhanh chóng. Để có được hình ảnh chất lượng tốt, chúng ta phải tìm sự cân bằng tốt giữa các siêu tham số đào tạo có sẵn, chẳng hạn như số bước đào tạo và tốc độ học tập. Trong phần này, chúng tôi hiển thị một số kết quả thử nghiệm và cung cấp hướng dẫn về cách đặt các tham số này.
Khuyến nghị
Hãy xem xét các khuyến nghị sau:
- Bắt đầu với chất lượng hình ảnh đào tạo tốt (4–20). Nếu đào tạo trên khuôn mặt người, bạn có thể cần nhiều hình ảnh hơn.
- Huấn luyện trong 200–400 bước khi huấn luyện chó hoặc mèo và các đối tượng không phải con người khác. Nếu đào tạo trên khuôn mặt của con người, bạn có thể cần nhiều bước hơn. Nếu quá khớp xảy ra, hãy giảm số bước. Nếu xảy ra tình trạng thiếu khớp (mô hình tinh chỉnh không thể tạo ra hình ảnh của đối tượng mục tiêu), hãy tăng số bước.
- Nếu đào tạo trên khuôn mặt không phải con người, bạn có thể thiết lập
with_prior_preservation = Falsebởi vì nó không ảnh hưởng đáng kể đến hiệu suất. Trên khuôn mặt người, bạn có thể cần phải đặtwith_prior_preservation=True. - Nếu thiết lập
with_prior_preservation=True, hãy sử dụng loại phiên bản ml.g5.2xlarge. - Khi huấn luyện tuần tự trên nhiều đối tượng, nếu các đối tượng rất giống nhau (ví dụ: tất cả chó), mô hình sẽ giữ lại đối tượng cuối cùng và quên các đối tượng trước đó. Nếu các đối tượng khác nhau (ví dụ: đầu tiên là một con mèo, sau đó là một con chó), thì mô hình sẽ giữ lại cả hai đối tượng.
- Chúng tôi khuyên bạn nên sử dụng tỷ lệ học tập thấp và tăng dần số bước cho đến khi đạt được kết quả khả quan.
Tập dữ liệu đào tạo
Chất lượng của mô hình tinh chỉnh bị ảnh hưởng trực tiếp bởi chất lượng của hình ảnh đào tạo. Do đó, bạn cần thu thập những hình ảnh chất lượng cao để có được kết quả tốt. Hình ảnh mờ hoặc độ phân giải thấp sẽ ảnh hưởng đến chất lượng của mô hình tinh chỉnh. Hãy ghi nhớ các tham số bổ sung sau:
- Số lượng hình ảnh đào tạo – Bạn có thể tinh chỉnh mô hình trên ít nhất bốn hình ảnh huấn luyện. Chúng tôi đã thử nghiệm với các tập dữ liệu huấn luyện có kích thước nhỏ nhất là 4 hình ảnh và nhiều nhất là 16 hình ảnh. Trong cả hai trường hợp, tinh chỉnh có thể điều chỉnh mô hình cho phù hợp với đối tượng.
- Định dạng tập dữ liệu – Chúng tôi đã thử nghiệm thuật toán tinh chỉnh trên hình ảnh có định dạng .png, .jpg và .jpeg. Các định dạng khác cũng có thể hoạt động.
- Độ phân giải hình ảnh – Hình ảnh đào tạo có thể ở bất kỳ độ phân giải nào. Thuật toán tinh chỉnh sẽ thay đổi kích thước tất cả các hình ảnh đào tạo trước khi bắt đầu tinh chỉnh. Nói như vậy, nếu bạn muốn có nhiều quyền kiểm soát hơn đối với việc cắt xén và thay đổi kích thước hình ảnh đào tạo, chúng tôi khuyên bạn nên tự thay đổi kích thước hình ảnh theo độ phân giải cơ bản của mô hình (trong ví dụ này là 512×512 pixel).
Cài đặt thử nghiệm
Trong thử nghiệm trong bài đăng này, trong khi tinh chỉnh, chúng tôi sử dụng các giá trị mặc định của siêu tham số trừ khi được chỉ định. Hơn nữa, chúng tôi sử dụng một trong bốn bộ dữ liệu:
- Chó1-8 – Con chó 1 với 8 hình ảnh
- Chó1-16 – Con chó 1 với 16 hình ảnh
- Chó2-4 – Con chó 2 với bốn hình ảnh
- con mèo-8 – Con mèo với 8 hình ảnh
Để giảm sự lộn xộn, chúng tôi chỉ hiển thị một hình ảnh đại diện của tập dữ liệu trong mỗi phần cùng với tên tập dữ liệu. Bạn có thể tìm thấy bộ đào tạo đầy đủ trong phần Bộ dữ liệu thử nghiệm trong bài đăng này.
trang bị quá mức
Các mô hình Khuếch tán ổn định có xu hướng overfit khi tinh chỉnh trên một số hình ảnh. Do đó, bạn cần chọn các thông số như epochs, max_epochs, và tỷ lệ học tập cẩn thận. Trong phần này, chúng tôi đã sử dụng bộ dữ liệu Dog1-16.

Để đánh giá hiệu suất của mô hình, chúng tôi đánh giá mô hình tinh chỉnh cho bốn nhiệm vụ:
- Mô hình tinh chỉnh có thể tạo ra hình ảnh của đối tượng (chó Doppler) trong cùng bối cảnh như nó đã được đào tạo không?
- Quan sát – Có thể. Điều đáng chú ý là hiệu suất của mô hình tăng theo số bước đào tạo.
- Mô hình tinh chỉnh có thể tạo ra hình ảnh của đối tượng trong một bối cảnh khác với bối cảnh được đào tạo không? Ví dụ, nó có thể tạo ra hình ảnh Doppler trên bãi biển không?
- Quan sát – Có thể. Điều đáng chú ý là hiệu suất của mô hình tăng theo số bước đào tạo cho đến một điểm nhất định. Tuy nhiên, nếu mô hình được đào tạo quá lâu, hiệu suất của mô hình sẽ giảm xuống do mô hình có xu hướng quá khớp.
- Mô hình tinh chỉnh có thể tạo ra hình ảnh của một lớp mà đối tượng đào tạo thuộc về không? Ví dụ: nó có thể tạo ra hình ảnh của một con chó chung chung không?
- Quan sát – Khi chúng ta tăng số bước huấn luyện, mô hình bắt đầu khớp quá mức. Kết quả là, nó quên đi lớp chung của một con chó và sẽ chỉ tạo ra những hình ảnh liên quan đến chủ đề này.
- Mô hình tinh chỉnh có thể tạo ra hình ảnh của một lớp hoặc chủ đề không có trong tập dữ liệu huấn luyện không? Ví dụ, nó có thể tạo ra hình ảnh của một con mèo không?
- Quan sát – Khi chúng ta tăng số bước huấn luyện, mô hình bắt đầu khớp quá mức. Do đó, nó sẽ chỉ tạo ra các hình ảnh liên quan đến chủ đề, bất kể lớp được chỉ định.
Chúng tôi tinh chỉnh mô hình cho một số bước khác nhau (bằng cách đặt max_steps siêu đường kính) và đối với mỗi mô hình được tinh chỉnh, chúng tôi tạo hình ảnh trên mỗi trong số bốn lời nhắc sau (hiển thị trong các ví dụ sau từ trái sang phải:
- “Một bức ảnh của một con chó Doppler”
- “Bức ảnh chụp một chú chó Doppler trên bãi biển”
- “Một bức ảnh của một con chó”
- “Ảnh về một con mèo”
Những hình ảnh sau đây là từ mô hình được đào tạo với 50 bước.

Mô hình sau được đào tạo với 100 bước.

Chúng tôi đã đào tạo mô hình sau với 200 bước.

Những hình ảnh sau đây là từ một mô hình được đào tạo với 400 bước.

Cuối cùng, những hình ảnh sau đây là kết quả của 800 bước.

Đào tạo trên nhiều bộ dữ liệu
Trong khi tinh chỉnh, bạn có thể muốn tinh chỉnh trên nhiều đối tượng và để mô hình tinh chỉnh có thể tạo ảnh của tất cả các đối tượng. Thật không may, JumpStart hiện chỉ giới hạn trong việc đào tạo về một chủ đề duy nhất. Bạn không thể tinh chỉnh mô hình trên nhiều đối tượng cùng một lúc. Hơn nữa, việc tinh chỉnh mô hình cho các đối tượng khác nhau một cách tuần tự dẫn đến việc mô hình quên đối tượng đầu tiên nếu các đối tượng tương tự nhau.
Chúng tôi xem xét thử nghiệm sau trong phần này:
- Tinh chỉnh mô hình cho Đối tượng A.
- Tinh chỉnh mô hình kết quả từ Bước 1 cho Đối tượng B.
- Tạo hình ảnh của Đối tượng A và Đối tượng B bằng cách sử dụng mô hình đầu ra từ Bước 2.
Trong các thí nghiệm sau, chúng tôi nhận thấy rằng:
- Nếu A là con chó 1 và B là con chó 2, thì tất cả các hình ảnh được tạo ở Bước 3 giống với con chó 2
- Nếu A là con chó 2 và B là con chó 1, thì tất cả các hình ảnh được tạo ở Bước 3 giống với con chó 1
- Nếu A là con chó 1 và B là con mèo, thì hình ảnh được tạo bằng lời nhắc về con chó sẽ giống với con chó 1 và hình ảnh được tạo bằng lời nhắc về con mèo giống như con mèo
Huấn luyện chó 1 rồi chó 2
Ở Bước 1, chúng tôi tinh chỉnh mô hình cho 200 bước trên 1 hình ảnh của con chó 2. Ở Bước 200, chúng tôi tinh chỉnh mô hình thêm 2 bước trên XNUMX hình ảnh của con chó XNUMX.

Sau đây là những hình ảnh được tạo bởi mô hình tinh chỉnh ở cuối Bước 2 cho các lời nhắc khác nhau.
Huấn luyện chó 2 rồi chó 1
Ở Bước 1, chúng tôi tinh chỉnh mô hình cho 200 bước trên bốn hình ảnh của con chó 2. Ở Bước 2, chúng tôi tinh chỉnh mô hình thêm 200 bước trên tám hình ảnh của con chó 1.

Sau đây là những hình ảnh được tạo bởi mô hình tinh chỉnh ở cuối Bước 2 với các lời nhắc khác nhau.

Huấn luyện chó và mèo
Ở Bước 1, chúng tôi tinh chỉnh mô hình cho 200 bước trên tám hình ảnh của một con mèo. Sau đó, chúng tôi tinh chỉnh mô hình thêm 200 bước trên tám hình ảnh của con chó 1.

Sau đây là những hình ảnh được tạo bởi mô hình tinh chỉnh ở cuối Bước 2. Hình ảnh có lời nhắc liên quan đến mèo trông giống như con mèo trong Bước 1 của quá trình tinh chỉnh và hình ảnh có lời nhắc liên quan đến chó trông giống như con chó trong Bước 2 của tinh chỉnh.

bảo quản trước
Bảo quản trước là một kỹ thuật sử dụng các hình ảnh bổ sung của cùng một lớp mà chúng tôi đang cố gắng đào tạo. Chẳng hạn, nếu dữ liệu huấn luyện bao gồm hình ảnh của một con chó cụ thể, với sự bảo quản trước, chúng tôi sẽ kết hợp hình ảnh lớp của những con chó chung. Nó cố gắng tránh trang bị quá mức bằng cách hiển thị hình ảnh của những con chó khác nhau trong khi huấn luyện một con chó cụ thể. Một thẻ cho biết con chó cụ thể hiện diện trong dấu nhắc ví dụ bị thiếu trong dấu nhắc lớp. Chẳng hạn, lời nhắc của cá thể có thể là “ảnh của một con mèo riobugger” và lời nhắc của lớp có thể là “ảnh của một con mèo”. Bạn có thể kích hoạt bảo toàn trước bằng cách đặt siêu tham số with_prior_preservation = True. Nếu thiết lập with_prior_preservation = True, bạn phải bao gồm class_prompt in dataset_info.json và có thể bao gồm bất kỳ hình ảnh lớp nào có sẵn cho bạn. Sau đây là định dạng tập dữ liệu huấn luyện khi thiết lập with_prior_preservation = True:
- Đầu vào – Một thư mục chứa các ảnh ví dụ,
dataset_info.jsonvà (tùy chọn) thư mụcclass_data_dir. Lưu ý những điều dưới đây:- Hình ảnh có thể có định dạng .png, .jpg, .jpeg.
- Sản phẩm
dataset_info.jsontập tin phải có định dạng{'instance_prompt':<<instance_prompt>>,'class_prompt':<<class_prompt>>}. - Sản phẩm
class_data_dirthư mục phải có hình ảnh lớp. Nếu nhưclass_data_dirkhông có hoặc không có đủ hình ảnh đã có trongclass_data_dir, hình ảnh bổ sung sẽ được lấy mẫu vớiclass_prompt.
Đối với các bộ dữ liệu như mèo và chó, việc bảo quản trước không ảnh hưởng đáng kể đến hiệu suất của mô hình tinh chỉnh và do đó có thể tránh được. Tuy nhiên, khi đào tạo trên khuôn mặt, điều này là cần thiết. Để biết thêm thông tin, hãy tham khảo Đào tạo khuếch tán ổn định với Dreambooth bằng bộ khuếch tán.
Các loại phiên bản
Tinh chỉnh các mô hình Khuếch tán ổn định yêu cầu tính toán tăng tốc do các phiên bản hỗ trợ GPU cung cấp. Chúng tôi thử nghiệm tinh chỉnh với các phiên bản ml.g4dn.2xlarge (bộ nhớ CUDA 16 GB, 1 GPU) và ml.g5.2xlarge (bộ nhớ CUDA 24 GB, 1 GPU). Yêu cầu bộ nhớ cao hơn khi tạo hình ảnh lớp. Do đó, nếu thiết lập with_prior_preservation=True, hãy sử dụng loại phiên bản ml.g5.2xlarge, vì quá trình đào tạo dẫn đến sự cố CUDA hết bộ nhớ trên phiên bản ml.g4dn.2xlarge. Tập lệnh tinh chỉnh JumpStart hiện sử dụng một GPU và do đó, việc tinh chỉnh trên các phiên bản đa GPU sẽ không mang lại hiệu suất tăng. Để biết thêm thông tin về các loại phiên bản khác nhau, hãy tham khảo Các loại phiên bản Amazon EC2.
Hạn chế và sai lệch
Mặc dù Stable Diffusion có hiệu suất ấn tượng trong việc tạo hình ảnh, nhưng nó có một số hạn chế và sai lệch. Chúng bao gồm nhưng không giới hạn ở:
- Mô hình có thể không tạo ra khuôn mặt hoặc chân tay chính xác vì dữ liệu đào tạo không bao gồm đủ hình ảnh với các tính năng này
- Người mẫu được huấn luyện trên Bộ dữ liệu LAION-5B, có nội dung người lớn và có thể không phù hợp để sử dụng sản phẩm mà không cần xem xét thêm
- Mô hình có thể không hoạt động tốt với các ngôn ngữ không phải tiếng Anh vì mô hình đã được đào tạo về văn bản tiếng Anh
- Mô hình không thể tạo văn bản tốt trong hình ảnh
Để biết thêm thông tin về các hạn chế và sai lệch, hãy xem Thẻ mô hình cơ sở v2-1 khuếch tán ổn định. Những hạn chế này đối với mô hình được đào tạo trước cũng có thể chuyển sang các mô hình tinh chỉnh.
Làm sạch
Sau khi bạn chạy xong sổ ghi chép, hãy đảm bảo xóa tất cả các tài nguyên được tạo trong quy trình để đảm bảo rằng quá trình lập hóa đơn được dừng lại. Mã để dọn dẹp điểm cuối được cung cấp trong liên kết Giới thiệu về JumpStart – Chuyển văn bản thành hình ảnh sổ tay ví dụ.
Các mô hình tinh chỉnh có sẵn công khai trong JumpStart
Mặc dù các mô hình Khuếch tán ổn định được phát hành bởi Ổn địnhAI có hiệu suất ấn tượng, họ có những hạn chế về ngôn ngữ hoặc lĩnh vực được đào tạo. Ví dụ: các mô hình Khuếch tán ổn định đã được đào tạo về văn bản tiếng Anh, nhưng bạn có thể cần tạo hình ảnh từ văn bản không phải tiếng Anh. Ngoài ra, các mô hình Khuếch tán ổn định đã được đào tạo để tạo hình ảnh chân thực, nhưng bạn có thể cần tạo hình ảnh động hoặc nghệ thuật.
JumpStart cung cấp hơn 80 mô hình có sẵn công khai với nhiều ngôn ngữ và chủ đề khác nhau. Các mô hình này thường là phiên bản tinh chỉnh từ các mô hình Khuếch tán ổn định do StabilityAI phát hành. Nếu trường hợp sử dụng của bạn phù hợp với một trong các mô hình đã tinh chỉnh, thì bạn không cần phải thu thập và tinh chỉnh tập dữ liệu của riêng mình. Bạn có thể chỉ cần triển khai một trong các mô hình này thông qua Studio UI hoặc sử dụng các API JumpStart dễ sử dụng. Để triển khai mô hình Khuếch tán Ổn định đã được đào tạo trước trong JumpStart, hãy tham khảo Tạo hình ảnh từ văn bản với mô hình khuếch tán ổn định trên Amazon SageMaker JumpStart.
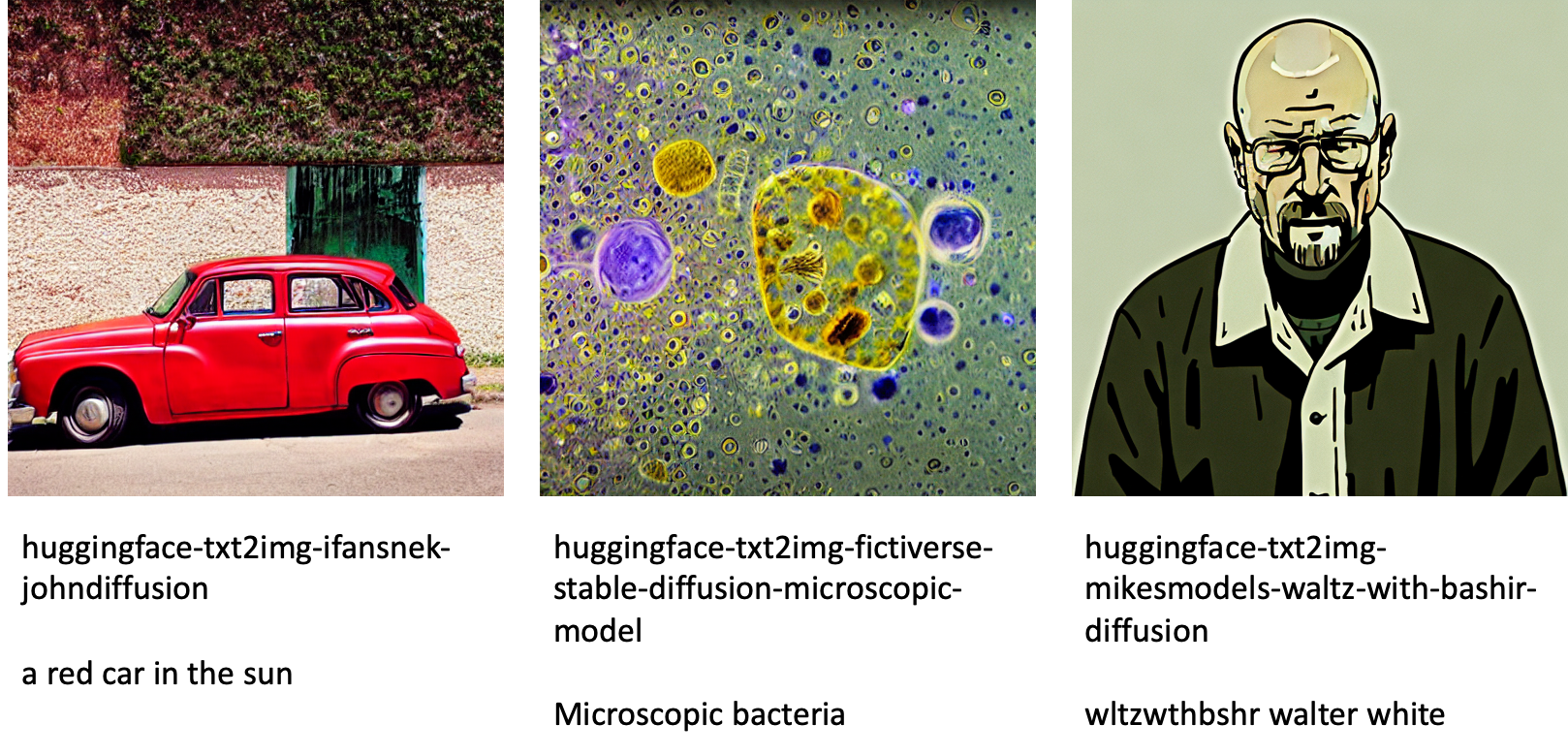
Sau đây là một số ví dụ về hình ảnh được tạo bởi các mẫu khác nhau có sẵn trong JumpStart.


Lưu ý rằng các mô hình này không được tinh chỉnh bằng tập lệnh JumpStart hoặc tập lệnh DreamBooth. Bạn có thể tải xuống danh sách đầy đủ các mô hình tinh chỉnh có sẵn công khai với lời nhắc ví dụ từ tại đây.
Để biết thêm ví dụ về hình ảnh được tạo từ các mô hình này, vui lòng xem phần Các mô hình tinh chỉnh có nguồn mở trong phần mục lục.
Kết luận
Trong bài đăng này, chúng tôi đã trình bày cách tinh chỉnh mô hình Khuếch tán ổn định cho chuyển văn bản thành hình ảnh và sau đó triển khai nó bằng JumpStart. Ngoài ra, chúng tôi đã thảo luận về một số cân nhắc bạn nên thực hiện trong khi tinh chỉnh mô hình và cách nó có thể ảnh hưởng đến hiệu suất của mô hình đã tinh chỉnh. Chúng tôi cũng đã thảo luận về hơn 80 mô hình tinh chỉnh sẵn sàng sử dụng có sẵn trong JumpStart. Chúng tôi đã hiển thị các đoạn mã trong bài đăng này—để biết mã đầy đủ với tất cả các bước trong bản trình diễn này, hãy xem phần Giới thiệu về JumpStart – Chuyển văn bản thành hình ảnh sổ ví dụ. Hãy thử giải pháp của riêng bạn và gửi cho chúng tôi ý kiến của bạn.
Để tìm hiểu thêm về mô hình và tinh chỉnh DreamBooth, hãy xem các tài nguyên sau:
Để tìm hiểu thêm về JumpStart, hãy xem các bài đăng trên blog sau:
Về các tác giả
 Tiến sĩ Vivek Madan là một Nhà Khoa học Ứng dụng của nhóm Amazon SageMaker JumpStart. Ông lấy bằng Tiến sĩ tại Đại học Illinois tại Urbana-Champaign và là Nhà nghiên cứu Sau Tiến sĩ tại Georgia Tech. Anh ấy là một nhà nghiên cứu tích cực về học máy và thiết kế thuật toán và đã xuất bản các bài báo trong các hội nghị EMNLP, ICLR, COLT, FOCS và SODA.
Tiến sĩ Vivek Madan là một Nhà Khoa học Ứng dụng của nhóm Amazon SageMaker JumpStart. Ông lấy bằng Tiến sĩ tại Đại học Illinois tại Urbana-Champaign và là Nhà nghiên cứu Sau Tiến sĩ tại Georgia Tech. Anh ấy là một nhà nghiên cứu tích cực về học máy và thiết kế thuật toán và đã xuất bản các bài báo trong các hội nghị EMNLP, ICLR, COLT, FOCS và SODA.
 Heiko Hotz là Kiến trúc sư giải pháp cấp cao về AI & Machine Learning, tập trung đặc biệt vào xử lý ngôn ngữ tự nhiên (NLP), mô hình ngôn ngữ lớn (LLM) và AI tổng quát. Trước khi đảm nhận vai trò này, ông là Trưởng phòng Khoa học Dữ liệu cho Dịch vụ Khách hàng Châu Âu của Amazon. Heiko giúp khách hàng của chúng tôi thành công trong hành trình AI/ML của họ trên AWS và đã làm việc với các tổ chức trong nhiều ngành, bao gồm bảo hiểm, dịch vụ tài chính, truyền thông và giải trí, chăm sóc sức khỏe, tiện ích và sản xuất. Khi rảnh rỗi, Heiko đi du lịch nhiều nhất có thể.
Heiko Hotz là Kiến trúc sư giải pháp cấp cao về AI & Machine Learning, tập trung đặc biệt vào xử lý ngôn ngữ tự nhiên (NLP), mô hình ngôn ngữ lớn (LLM) và AI tổng quát. Trước khi đảm nhận vai trò này, ông là Trưởng phòng Khoa học Dữ liệu cho Dịch vụ Khách hàng Châu Âu của Amazon. Heiko giúp khách hàng của chúng tôi thành công trong hành trình AI/ML của họ trên AWS và đã làm việc với các tổ chức trong nhiều ngành, bao gồm bảo hiểm, dịch vụ tài chính, truyền thông và giải trí, chăm sóc sức khỏe, tiện ích và sản xuất. Khi rảnh rỗi, Heiko đi du lịch nhiều nhất có thể.
Phụ lục: Bộ dữ liệu thử nghiệm
Phần này chứa các tập dữ liệu được sử dụng trong các thử nghiệm trong bài đăng này.
Chó1-8

Chó1-16

Chó2-4

Chó3-8

Phụ lục: Các mô hình tinh chỉnh có mã nguồn mở
Sau đây là một số ví dụ về hình ảnh được tạo bởi các mẫu khác nhau có sẵn trong JumpStart. Mỗi hình ảnh được chú thích bằng một model_id bắt đầu bằng một tiền tố huggingface-txt2img- theo sau là lời nhắc được sử dụng để tạo hình ảnh trong dòng tiếp theo.
























- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- Platoblockchain. Web3 Metaverse Intelligence. Khuếch đại kiến thức. Truy cập Tại đây.
- nguồn: https://aws.amazon.com/blogs/machine-learning/fine-tune-text-to-image-stable-diffusion-models-with-amazon-sagemaker-jumpstart/

