Việc tạo ra các quy trình máy học (ML) có khả năng mở rộng và hiệu quả là rất quan trọng để hợp lý hóa quá trình phát triển, triển khai và quản lý các mô hình ML. Trong bài đăng này, chúng tôi trình bày một khuôn khổ để tự động hóa việc tạo biểu đồ chu kỳ có hướng (DAG) cho Đường ống Amazon SageMaker dựa trên các tập tin cấu hình đơn giản. Các mã khung và ví dụ được trình bày ở đây chỉ bao gồm các quy trình đào tạo mô hình, nhưng cũng có thể dễ dàng mở rộng sang các quy trình suy luận hàng loạt.
Khung động này sử dụng các tệp cấu hình để sắp xếp các bước tiền xử lý, đào tạo, đánh giá và đăng ký cho cả trường hợp sử dụng mô hình đơn và đa mô hình dựa trên tập lệnh Python do người dùng xác định, nhu cầu cơ sở hạ tầng (bao gồm cả Đám mây riêng ảo Amazon mạng con và nhóm bảo mật (Amazon VPC), Quản lý truy cập và nhận dạng AWS (IAM) vai trò, Dịch vụ quản lý khóa AWS Khóa (AWS KMS), sổ đăng ký vùng chứa và loại phiên bản), đầu vào và đầu ra Dịch vụ lưu trữ đơn giản của Amazon đường dẫn (Amazon S3) và thẻ tài nguyên. Các tệp cấu hình (YAML và JSON) cho phép những người thực hành ML chỉ định mã không phân biệt để điều phối các quy trình đào tạo bằng cú pháp khai báo. Điều này cho phép các nhà khoa học dữ liệu nhanh chóng xây dựng và lặp lại trên các mô hình ML, đồng thời trao quyền cho các kỹ sư ML chạy qua các đường ống ML tích hợp liên tục và phân phối liên tục (CI/CD) nhanh hơn, giảm thời gian sản xuất cho các mô hình.
Tổng quan về giải pháp
Mã khung được đề xuất bắt đầu bằng cách đọc các tệp cấu hình. Sau đó, nó tự động tạo DAG SageMaker Pipelines dựa trên các bước được khai báo trong tệp cấu hình cũng như sự tương tác và phụ thuộc giữa các bước. Khung điều phối này phục vụ cho cả trường hợp sử dụng mô hình đơn và đa mô hình, đồng thời cung cấp luồng dữ liệu và quy trình suôn sẻ. Sau đây là những lợi ích chính của giải pháp này:
- Tự động hóa – Toàn bộ quy trình làm việc ML, từ tiền xử lý dữ liệu đến đăng ký mô hình, đều được điều phối mà không cần can thiệp thủ công. Điều này làm giảm thời gian và công sức cần thiết cho việc thử nghiệm và vận hành mô hình.
- Khả năng tái lập – Với tệp cấu hình được xác định trước, các nhà khoa học dữ liệu và kỹ sư ML có thể tái tạo toàn bộ quy trình làm việc, đạt được kết quả nhất quán trên nhiều lần chạy và môi trường.
- khả năng mở rộng – Amazon SageMaker được sử dụng trong toàn bộ quy trình, cho phép những người thực hành ML xử lý các tập dữ liệu lớn và đào tạo các mô hình phức tạp mà không cần lo lắng về cơ sở hạ tầng.
- Linh hoạt – Khung này linh hoạt và có thể đáp ứng nhiều trường hợp sử dụng ML, khung ML (chẳng hạn như XGBoost và TensorFlow), đào tạo đa mô hình và đào tạo nhiều bước. Mỗi bước của DAG đào tạo có thể được tùy chỉnh thông qua tệp cấu hình.
- Quản trị mô hình - Cơ quan đăng ký mô hình Amazon SageMaker Tích hợp cho phép theo dõi các phiên bản mô hình và do đó tự tin đưa chúng vào sản xuất.
Sơ đồ kiến trúc sau đây mô tả cách bạn có thể sử dụng khung được đề xuất trong cả quá trình thử nghiệm và vận hành các mô hình ML. Trong quá trình thử nghiệm, bạn có thể sao chép kho lưu trữ mã khung được cung cấp trong bài đăng này và kho lưu trữ mã nguồn dành riêng cho dự án của bạn vào Xưởng sản xuất Amazon SageMakervà đặt môi trường ảo của bạn (chi tiết ở phần sau của bài đăng này). Sau đó, bạn có thể lặp lại các tập lệnh tiền xử lý, đào tạo và đánh giá cũng như các lựa chọn cấu hình. Để tạo và chạy DAG đào tạo SageMaker Pipelines, bạn có thể gọi điểm vào của khung, điểm này sẽ đọc tất cả các tệp cấu hình, tạo các bước cần thiết và sắp xếp chúng dựa trên thứ tự bước và các yếu tố phụ thuộc đã chỉ định.
Trong quá trình vận hành, quy trình CI sao chép kho lưu trữ mã khung và kho đào tạo dành riêng cho dự án thành một Xây dựng mã AWS công việc, trong đó tập lệnh điểm đầu vào của khung được gọi để tạo hoặc cập nhật DAG đào tạo của SageMaker Pipelines, sau đó chạy tập lệnh đó.

Cấu trúc kho lưu trữ
Sản phẩm Kho GitHub chứa các thư mục và tập tin sau:
- /framework/conf/ – Thư mục này chứa tệp cấu hình được sử dụng để đặt các biến chung trên tất cả các đơn vị lập mô hình như mạng con, nhóm bảo mật và vai trò IAM trong thời gian chạy. Đơn vị mô hình hóa là một chuỗi gồm tối đa sáu bước để đào tạo mô hình ML.
- /framework/createmodel/ – Thư mục này chứa tập lệnh Python tạo ra một Mô hình SageMaker đối tượng dựa trên các tạo phẩm mô hình từ một Bước đào tạo về SageMaker Pipeline. Đối tượng mô hình sau đó được sử dụng trong Chuyển đổi hàng loạt SageMaker công việc để đánh giá hiệu suất của mô hình trên một tập kiểm tra.
- /framework/modelmetrics/ – Thư mục này chứa tập lệnh Python tạo ra một Chế biến Amazon SageMaker công việc tạo báo cáo JSON số liệu mô hình cho mô hình được đào tạo dựa trên kết quả của công việc chuyển đổi hàng loạt SageMaker được thực hiện trên dữ liệu thử nghiệm.
- /khung/đường ống/ – Thư mục này chứa các tập lệnh Python sử dụng các lớp Python được xác định trong các thư mục khung khác để tạo hoặc cập nhật DAG SageMaker Pipelines dựa trên các cấu hình đã chỉ định. Tập lệnh model_unit.py được pipe_service.py sử dụng để tạo một hoặc nhiều đơn vị mô hình hóa. Mỗi đơn vị mô hình hóa là một chuỗi gồm tối đa sáu bước để đào tạo mô hình ML: xử lý, huấn luyện, tạo mô hình, chuyển đổi, đo lường và đăng ký mô hình. Cấu hình cho từng đơn vị mô hình phải được chỉ định trong kho lưu trữ tương ứng của mô hình. pipe_service.py cũng đặt các phần phụ thuộc giữa các bước của SageMaker Pipelines (cách các bước trong và giữa các đơn vị mô hình hóa được sắp xếp theo thứ tự hoặc xâu chuỗi) dựa trên phần sagemakerPipeline, phần này phải được xác định trong tệp cấu hình của một trong các kho lưu trữ mô hình (mô hình neo). Điều này cho phép bạn ghi đè các phần phụ thuộc mặc định do SageMaker Pipelines suy ra. Chúng ta sẽ thảo luận về cấu trúc tệp cấu hình sau trong bài đăng này.
- /khung/xử lý/ – Thư mục này chứa tập lệnh Python tạo công việc Xử lý SageMaker dựa trên tập lệnh điểm nhập và hình ảnh Docker được chỉ định.
- /khung/đăng ký mô hình/ – Thư mục này chứa tập lệnh Python để đăng ký mô hình được đào tạo cùng với các số liệu được tính toán của nó trong Sổ đăng ký mô hình SageMaker.
- /khuôn khổ/đào tạo/ – Thư mục này chứa tập lệnh Python tạo công việc đào tạo SageMaker.
- /khung/chuyển đổi/ – Thư mục này chứa tập lệnh Python tạo công việc chuyển đổi hàng loạt SageMaker. Trong bối cảnh đào tạo mô hình, điều này được sử dụng để tính toán chỉ số hiệu suất của mô hình được đào tạo trên dữ liệu thử nghiệm.
- /khung/tiện ích/ – Thư mục này chứa các tập lệnh tiện ích để đọc và nối các tệp cấu hình cũng như ghi nhật ký.
- /framework_entrypoint.py – Tệp này là điểm vào của mã khung. Nó gọi một hàm được xác định trong thư mục /framework/pipeline/ để tạo hoặc cập nhật DAG SageMaker Pipelines và chạy nó.
- /ví dụ/ – Thư mục này chứa một số ví dụ về cách bạn có thể sử dụng khung tự động hóa này để tạo DAG đào tạo đơn giản và phức tạp.
- /env.env – Tệp này cho phép bạn đặt các biến phổ biến như mạng con, nhóm bảo mật và vai trò IAM làm biến môi trường.
- /requirements.txt – Tệp này chỉ định các thư viện Python được yêu cầu cho mã khung.
Điều kiện tiên quyết
Bạn cần có các điều kiện tiên quyết sau trước khi triển khai giải pháp này:
- Tài khoản AWS
- Studio SageMaker
- Vai trò SageMaker với quyền đọc/ghi Amazon S3 và quyền mã hóa/giải mã AWS KMS
- Bộ chứa S3 để lưu trữ dữ liệu, tập lệnh và thành phần mô hình
- Tùy chọn, Giao diện dòng lệnh AWS (AWS CLI)
- Python3 (Python 3.7 trở lên) và các gói Python sau:
- boto3
- nhà làm hiền triết
- PyYAML
- Các gói Python bổ sung được sử dụng trong tập lệnh tùy chỉnh của bạn
Triển khai giải pháp
Hoàn thành các bước sau để triển khai giải pháp:
- Tổ chức kho đào tạo mô hình của bạn theo cấu trúc sau:
- Sao chép mã khung và mã nguồn mô hình của bạn từ kho Git:
-
- Clone
dynamic-sagemaker-pipelines-frameworkrepo vào một thư mục đào tạo. Trong đoạn mã sau, chúng tôi giả sử thư mục đào tạo được gọi làaws-train: - Sao chép mã nguồn mô hình trong cùng thư mục. Để đào tạo nhiều mô hình, hãy lặp lại bước này cho số lượng mô hình mà bạn cần đào tạo.
- Clone
Đối với đào tạo mô hình đơn, thư mục của bạn sẽ trông như sau:
Đối với đào tạo đa mô hình, thư mục của bạn sẽ trông như sau:
- Thiết lập các biến môi trường sau. Dấu hoa thị cho biết các biến môi trường được yêu cầu; phần còn lại là tùy chọn.
| Biến môi trường | Mô tả |
SMP_ACCOUNTID* |
Tài khoản AWS nơi quy trình SageMaker được chạy |
SMP_REGION* |
Khu vực AWS nơi đường dẫn SageMaker được chạy |
SMP_S3BUCKETNAME* |
Tên bộ chứa S3 |
SMP_ROLE* |
Vai trò của SageMaker |
SMP_MODEL_CONFIGPATH* |
Đường dẫn tương đối của tệp cấu hình một mô hình hoặc nhiều mô hình |
SMP_SUBNETS |
ID mạng con cho cấu hình mạng SageMaker |
SMP_SECURITYGROUPS |
ID nhóm bảo mật cho cấu hình mạng SageMaker |
Đối với các trường hợp sử dụng một mô hình, SMP_MODEL_CONFIGPATH sẽ được <MODEL-DIR>/conf/conf.yaml. Đối với các trường hợp sử dụng nhiều mô hình, SMP_MODEL_CONFIGPATH sẽ được */conf/conf.yaml, cho phép bạn tìm thấy tất cả conf.yaml các tệp bằng mô-đun toàn cầu của Python và kết hợp chúng để tạo thành tệp cấu hình chung. Trong quá trình thử nghiệm (thử nghiệm cục bộ), bạn có thể chỉ định các biến môi trường bên trong tệp env.env rồi xuất chúng bằng cách chạy lệnh sau trong thiết bị đầu cuối của mình:
Lưu ý rằng các giá trị của biến môi trường trong env.env nên được đặt trong dấu ngoặc kép (ví dụ: SMP_REGION="us-east-1"). Trong quá trình vận hành, các biến môi trường này phải được quy trình CI đặt.
- Tạo và kích hoạt môi trường ảo bằng cách chạy các lệnh sau:
- Cài đặt các gói Python cần thiết bằng cách chạy lệnh sau:
- Chỉnh sửa đào tạo mô hình của bạn
conf.yamlcác tập tin. Chúng ta thảo luận về cấu trúc tệp cấu hình trong phần tiếp theo. - Từ thiết bị đầu cuối, hãy gọi điểm vào của khung để tạo hoặc cập nhật và chạy DAG đào tạo Đường ống SageMaker:
- Xem và gỡ lỗi Quy trình SageMaker chạy trên Đường ống tab của giao diện người dùng SageMaker Studio.
Cấu trúc tập tin cấu hình
Có hai loại tệp cấu hình trong giải pháp được đề xuất: cấu hình khung và cấu hình mô hình. Trong phần này, chúng tôi mô tả từng chi tiết.
Cấu hình khung
Sản phẩm /framework/conf/conf.yaml tập tin đặt các biến phổ biến trên tất cả các đơn vị mô hình hóa. Điêu nay bao gôm SMP_S3BUCKETNAME, SMP_ROLE, SMP_MODEL_CONFIGPATH, SMP_SUBNETS, SMP_SECURITYGROUPSvà SMP_MODELNAME. Tham khảo Bước 3 của hướng dẫn triển khai để biết mô tả về các biến này và cách đặt chúng thông qua biến môi trường.
Cấu hình mô hình
Đối với mỗi mô hình trong dự án, chúng ta cần chỉ định những điều sau trong phần <MODEL-DIR>/conf/conf.yaml tập tin (dấu hoa thị cho biết các phần bắt buộc; phần còn lại là tùy chọn):
- /conf/mô hình* – Trong phần này, bạn có thể cấu hình một hoặc nhiều đơn vị mô hình hóa. Khi mã khung được chạy, nó sẽ tự động đọc tất cả các tệp cấu hình trong thời gian chạy và nối chúng vào cây cấu hình. Về mặt lý thuyết, bạn có thể chỉ định tất cả các đơn vị mô hình trong cùng một
conf.yamlnhưng bạn nên chỉ định từng cấu hình đơn vị mô hình hóa trong thư mục tương ứng hoặc kho lưu trữ Git để giảm thiểu lỗi. Các đơn vị như sau:- {tên mẫu máy}* – Tên của mô hình.
- nguồn_thư mục* - Điểm chung
source_dirđường dẫn để sử dụng cho tất cả các bước trong đơn vị mô hình hóa. - tiền xử lý – Phần này chỉ định các tham số tiền xử lý.
- xe lửa* – Phần này quy định cụ thể các thông số công việc đào tạo.
- biến đổi* – Phần này chỉ định các tham số công việc SageMaker Transform để đưa ra dự đoán trên dữ liệu thử nghiệm.
- đánh giá – Phần này chỉ định các tham số công việc Xử lý SageMaker để tạo báo cáo JSON số liệu mô hình cho mô hình được đào tạo.
- đăng ký* – Phần này chỉ định các tham số để đăng ký mô hình được đào tạo trong Sổ đăng ký mô hình SageMaker.
- /conf/sagemakerPipeline* – Phần này xác định luồng Quy trình SageMaker, bao gồm cả sự phụ thuộc giữa các bước. Đối với các trường hợp sử dụng một mô hình, phần này được xác định ở cuối tệp cấu hình. Đối với các trường hợp sử dụng nhiều mô hình,
sagemakerPipelinephần chỉ cần được xác định trong tệp cấu hình của một trong các mô hình (bất kỳ mô hình nào). Chúng tôi gọi mô hình này là mô hình mỏ neo. Các thông số như sau:- tên đường ống* – Tên của quy trình SageMaker.
- mô hình* – Danh sách các đơn vị mô hình lồng nhau:
- {tên mẫu máy}* – Mã định danh mô hình phải khớp với mã định danh {model-name} trong phần /conf/models.
- bước* –
- tên_bước* – Tên bước sẽ được hiển thị trong DAG Đường ống SageMaker.
- bước_class* – (Liên minh [Xử lý, Đào tạo, CreateModel, Chuyển đổi, Số liệu, RegisterModel])
- bước_type* – Tham số này chỉ bắt buộc đối với các bước tiền xử lý và cần được đặt thành tiền xử lý. Điều này là cần thiết để phân biệt các bước tiền xử lý và đánh giá, cả hai đều có một
step_classcủa việc xử lý. - kích hoạt_cache – ([Liên minh[Đúng, Sai]]). Điều này cho biết có nên kích hoạt hay không Bộ nhớ đệm đường ống SageMaker cho bước này.
- chuỗi_input_source_step – ([danh sách[tên_bước]]). Bạn có thể sử dụng tùy chọn này để đặt đầu ra kênh của bước khác làm đầu vào cho bước này.
- chuỗi_input_bổ sung_prefix – Điều này chỉ được phép đối với các bước của Transform
step_class, và có thể được sử dụng kết hợp vớichain_input_source_steptham số để xác định tệp sẽ được sử dụng làm đầu vào cho bước chuyển đổi.
- bước* –
- {tên mẫu máy}* – Mã định danh mô hình phải khớp với mã định danh {model-name} trong phần /conf/models.
- phụ thuộc – Phần này chỉ định trình tự các bước trong Quy trình SageMaker sẽ được chạy. Chúng tôi đã điều chỉnh ký hiệu Luồng khí Apache cho phần này (ví dụ:
{step_name} >> {step_name}). Nếu phần này được để trống, các phụ thuộc rõ ràng được chỉ định bởichain_input_source_steptham số hoặc các phần phụ thuộc ngầm định xác định luồng DAG của SageMaker Pipelines.
Lưu ý rằng chúng tôi khuyên bạn nên có một bước đào tạo cho mỗi đơn vị mô hình hóa. Nếu nhiều bước huấn luyện được xác định cho một đơn vị mô hình, thì các bước tiếp theo sẽ thực hiện bước huấn luyện cuối cùng để tạo đối tượng mô hình, tính toán số liệu và đăng ký mô hình. Nếu bạn cần đào tạo nhiều mô hình, bạn nên tạo nhiều đơn vị mô hình hóa.
Các ví dụ
Trong phần này, chúng tôi trình bày ba ví dụ về DAG đào tạo mô hình ML được tạo bằng khung được trình bày.
Đào tạo mô hình đơn: LightGBM
Đây là một ví dụ mô hình đơn cho trường hợp sử dụng phân loại trong đó chúng tôi sử dụng LightGBM ở chế độ tập lệnh trên SageMaker. Các tập dữ liệu bao gồm các biến phân loại và số để dự đoán nhãn nhị phân Doanh thu (để dự đoán xem đối tượng có mua hàng hay không). Các tập lệnh tiền xử lý được sử dụng để mô hình hóa dữ liệu cho việc huấn luyện và kiểm tra, sau đó sắp xếp nó trong nhóm S3. Các đường dẫn S3 sau đó được cung cấp cho bước đào tạo trong tệp cấu hình.
Khi bước đào tạo chạy, SageMaker tải tệp trên vùng chứa tại /opt/ml/input/data/{channelName}/, có thể truy cập thông qua biến môi trường SM_CHANNEL_{channelName} trên thùng chứa (channelName= 'đào tạo' hoặc 'kiểm tra').Các kịch bản đào tạo thực hiện như sau:
- Tải các tệp cục bộ từ các đường dẫn vùng chứa cục bộ bằng cách sử dụng Tải NumPy mô-đun.
- Đặt siêu tham số cho thuật toán đào tạo.
- Lưu mô hình được đào tạo tại đường dẫn container cục bộ
/opt/ml/model/.
SageMaker lấy nội dung trong /opt/ml/model/ để tạo tarball dùng để triển khai mô hình lên SageMaker để lưu trữ.
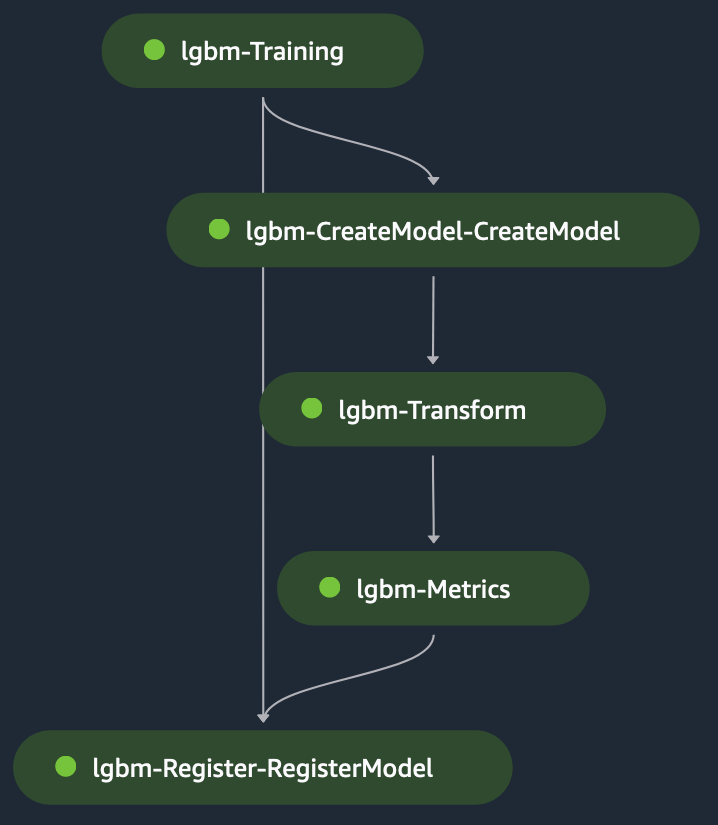
Bước biến đổi lấy làm đầu vào cho giai đoạn tập tin kiểm tra làm đầu vào và mô hình được đào tạo để đưa ra dự đoán trên mô hình được đào tạo. Đầu ra của bước biến đổi là xích đến bước đo lường để đánh giá mô hình dựa trên thực địa, được cung cấp rõ ràng cho bước số liệu. Cuối cùng, đầu ra của bước số liệu được liên kết ngầm với bước đăng ký để đăng ký mô hình trong Sổ đăng ký mô hình SageMaker với thông tin về hiệu suất của mô hình được tạo ra trong bước số liệu. Hình dưới đây minh họa trực quan về DAG đào tạo. Bạn có thể tham khảo các tập lệnh và tệp cấu hình cho ví dụ này trong phần Repo GitHub.
Đào tạo mô hình đơn: Tinh chỉnh LLM
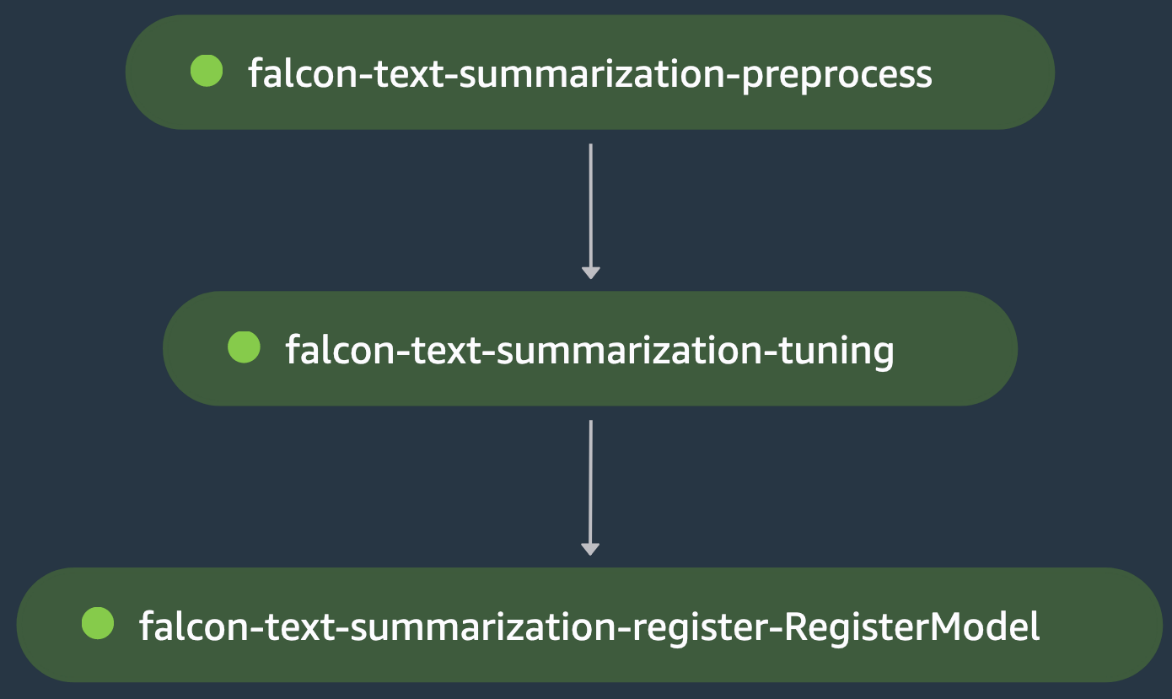
Đây là một ví dụ đào tạo mô hình đơn khác, trong đó chúng tôi phối hợp tinh chỉnh mô hình ngôn ngữ lớn (LLM) Falcon-40B từ Hugging Face Hub cho trường hợp sử dụng tóm tắt văn bản. Các tập lệnh tiền xử lý tải samsum tập dữ liệu từ Ôm mặt, tải mã thông báo cho mô hình và xử lý việc phân tách dữ liệu huấn luyện/kiểm tra để tinh chỉnh mô hình trên dữ liệu miền này trong bước tiền xử lý falcon-text-tóm tắt-tóm tắt.
Đầu ra là xích đến bước điều chỉnh tóm tắt văn bản chim ưng, trong đó kịch bản đào tạo tải Falcon-40B LLM từ Hugging Face Hub và bắt đầu tăng tốc tinh chỉnh bằng cách sử dụng LoRA trên chuyến tàu chia cắt. Mô hình được đánh giá ở bước tương tự sau khi tinh chỉnh, người gác cổng tổn thất đánh giá do bước điều chỉnh tóm tắt văn bản falcon không thành công, khiến quy trình SageMaker dừng trước khi có thể đăng ký mô hình tinh chỉnh. Nếu không, bước điều chỉnh tóm tắt văn bản falcon sẽ chạy thành công và mô hình được đăng ký trong Sổ đăng ký mô hình SageMaker. Hình dưới đây hiển thị hình ảnh trực quan của DAG tinh chỉnh LLM. Các tập lệnh và tệp cấu hình cho ví dụ này có sẵn trong Repo GitHub.
Đào tạo đa mô hình
Đây là ví dụ đào tạo đa mô hình trong đó mô hình phân tích thành phần chính (PCA) được đào tạo để giảm kích thước và mô hình Perceptron đa lớp TensorFlow được đào tạo để Dự đoán giá nhà ở California. Bước tiền xử lý của mô hình TensorFlow sử dụng mô hình PCA đã được đào tạo để giảm tính chiều của dữ liệu đào tạo. Chúng tôi thêm phần phụ thuộc vào cấu hình để đảm bảo mô hình TensorFlow được đăng ký sau khi đăng ký mô hình PCA. Hình dưới đây trình bày trực quan về ví dụ DAG đào tạo đa mô hình. Các tập lệnh và tệp cấu hình cho ví dụ này có sẵn trong Repo GitHub.

Làm sạch
Hoàn thành các bước sau để dọn sạch tài nguyên của bạn:
- Sử dụng AWS CLI để và tẩy mọi quy trình còn lại được tạo bởi tập lệnh Python.
- Tùy chọn xóa các tài nguyên AWS khác như nhóm S3 hoặc vai trò IAM được tạo bên ngoài Đường ống SageMaker.
Kết luận
Trong bài đăng này, chúng tôi đã trình bày một khuôn khổ để tự động hóa quá trình tạo DAG của SageMaker Pipelines dựa trên các tệp cấu hình. Khung đề xuất cung cấp một giải pháp hướng tới tương lai cho thách thức điều phối khối lượng công việc ML phức tạp. Bằng cách sử dụng tệp cấu hình, SageMaker Pipelines mang lại sự linh hoạt để xây dựng điều phối với mã tối thiểu, do đó bạn có thể hợp lý hóa quy trình tạo và quản lý cả quy trình đơn mô hình và đa mô hình. Cách tiếp cận này không chỉ tiết kiệm thời gian và nguồn lực mà còn thúc đẩy các phương pháp hay nhất của MLOps, góp phần vào thành công chung của các sáng kiến ML. Để biết thêm thông tin về chi tiết triển khai, hãy xem lại Repo GitHub.
Về các tác giả
 Luis Felipe Yepez Barrios, là Kỹ sư Machine Learning với Dịch vụ chuyên nghiệp của AWS, tập trung vào các hệ thống phân tán và công cụ tự động hóa có thể mở rộng để đẩy nhanh quá trình đổi mới khoa học trong lĩnh vực Machine Learning (ML). Hơn nữa, anh còn hỗ trợ khách hàng doanh nghiệp tối ưu hóa các giải pháp máy học của họ thông qua các dịch vụ AWS.
Luis Felipe Yepez Barrios, là Kỹ sư Machine Learning với Dịch vụ chuyên nghiệp của AWS, tập trung vào các hệ thống phân tán và công cụ tự động hóa có thể mở rộng để đẩy nhanh quá trình đổi mới khoa học trong lĩnh vực Machine Learning (ML). Hơn nữa, anh còn hỗ trợ khách hàng doanh nghiệp tối ưu hóa các giải pháp máy học của họ thông qua các dịch vụ AWS.
 Kim Chiêu Phong, là Kỹ sư máy học tại AWS Professional Services. Ông tập trung vào việc kiến trúc và triển khai các giải pháp đường dẫn ML cổ điển và AI sáng tạo quy mô lớn. Anh ấy chuyên về FMOps, LLMOps và đào tạo phân tán.
Kim Chiêu Phong, là Kỹ sư máy học tại AWS Professional Services. Ông tập trung vào việc kiến trúc và triển khai các giải pháp đường dẫn ML cổ điển và AI sáng tạo quy mô lớn. Anh ấy chuyên về FMOps, LLMOps và đào tạo phân tán.
 Asnani khắc nghiệt, là Kỹ sư máy học tại AWS. Nền tảng của anh ấy là về Khoa học dữ liệu ứng dụng với trọng tâm là vận hành khối lượng công việc Machine Learning trên đám mây ở quy mô lớn.
Asnani khắc nghiệt, là Kỹ sư máy học tại AWS. Nền tảng của anh ấy là về Khoa học dữ liệu ứng dụng với trọng tâm là vận hành khối lượng công việc Machine Learning trên đám mây ở quy mô lớn.
 Hasan Shojaei, là Nhà khoa học dữ liệu cấp cao của Dịch vụ chuyên nghiệp AWS, nơi ông giúp khách hàng thuộc các ngành khác nhau giải quyết các thách thức kinh doanh của họ thông qua việc sử dụng dữ liệu lớn, máy học và công nghệ đám mây. Trước vai trò này, Hasan đã lãnh đạo nhiều sáng kiến phát triển các kỹ thuật lập mô hình dựa trên dữ liệu và dựa trên vật lý mới cho các công ty năng lượng hàng đầu. Ngoài công việc, Hasan đam mê sách, đi bộ đường dài, chụp ảnh và lịch sử.
Hasan Shojaei, là Nhà khoa học dữ liệu cấp cao của Dịch vụ chuyên nghiệp AWS, nơi ông giúp khách hàng thuộc các ngành khác nhau giải quyết các thách thức kinh doanh của họ thông qua việc sử dụng dữ liệu lớn, máy học và công nghệ đám mây. Trước vai trò này, Hasan đã lãnh đạo nhiều sáng kiến phát triển các kỹ thuật lập mô hình dựa trên dữ liệu và dựa trên vật lý mới cho các công ty năng lượng hàng đầu. Ngoài công việc, Hasan đam mê sách, đi bộ đường dài, chụp ảnh và lịch sử.
 Alec Jenab, là Kỹ sư Máy học, chuyên phát triển và vận hành các giải pháp máy học trên quy mô lớn cho khách hàng doanh nghiệp. Alec đam mê đưa các giải pháp đổi mới ra thị trường, đặc biệt là trong các lĩnh vực mà học máy có thể cải thiện đáng kể trải nghiệm của người dùng cuối. Ngoài công việc, anh thích chơi bóng rổ, trượt ván trên tuyết và khám phá những viên ngọc ẩn giấu ở San Francisco.
Alec Jenab, là Kỹ sư Máy học, chuyên phát triển và vận hành các giải pháp máy học trên quy mô lớn cho khách hàng doanh nghiệp. Alec đam mê đưa các giải pháp đổi mới ra thị trường, đặc biệt là trong các lĩnh vực mà học máy có thể cải thiện đáng kể trải nghiệm của người dùng cuối. Ngoài công việc, anh thích chơi bóng rổ, trượt ván trên tuyết và khám phá những viên ngọc ẩn giấu ở San Francisco.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- PlatoSức khỏe. Tình báo thử nghiệm lâm sàng và công nghệ sinh học. Truy cập Tại đây.
- nguồn: https://aws.amazon.com/blogs/machine-learning/automate-amazon-sagemaker-pipelines-dag-creation/

