Các chính sách kiểm soát hiệu quả cho phép các công ty công nghiệp tăng lợi nhuận bằng cách tối đa hóa năng suất đồng thời giảm thời gian ngừng hoạt động đột xuất và tiêu thụ năng lượng. Tìm ra các chính sách kiểm soát tối ưu là một nhiệm vụ phức tạp vì các hệ thống vật lý, chẳng hạn như lò phản ứng hóa học và tua-bin gió, thường khó lập mô hình và do sự trôi dạt trong động lực học của quá trình có thể khiến hiệu suất suy giảm theo thời gian. Học tăng cường ngoại tuyến là một chiến lược kiểm soát cho phép các công ty công nghiệp xây dựng chính sách kiểm soát hoàn toàn từ dữ liệu lịch sử mà không cần mô hình quy trình rõ ràng. Cách tiếp cận này không yêu cầu tương tác trực tiếp với quy trình trong giai đoạn khám phá, điều này loại bỏ một trong những rào cản đối với việc áp dụng học tăng cường trong các ứng dụng quan trọng về an toàn. Trong bài đăng này, chúng tôi sẽ xây dựng một giải pháp toàn diện để tìm ra các chính sách kiểm soát tối ưu chỉ sử dụng dữ liệu lịch sử trên Amazon SageMaker sử dụng Ray RLlib thư viện. Để tìm hiểu thêm về học tăng cường, hãy xem Sử dụng Học tăng cường với Amazon SageMaker.
Trường hợp sử dụng
Kiểm soát công nghiệp liên quan đến việc quản lý các hệ thống phức tạp, chẳng hạn như dây chuyền sản xuất, lưới năng lượng và nhà máy hóa chất, để đảm bảo hoạt động hiệu quả và đáng tin cậy. Nhiều chiến lược kiểm soát truyền thống dựa trên các quy tắc và mô hình được xác định trước, thường yêu cầu tối ưu hóa thủ công. Thông lệ tiêu chuẩn trong một số ngành là giám sát hiệu suất và điều chỉnh chính sách kiểm soát, chẳng hạn như khi thiết bị bắt đầu xuống cấp hoặc điều kiện môi trường thay đổi. Việc điều chỉnh lại có thể mất vài tuần và có thể yêu cầu đưa các kích thích bên ngoài vào hệ thống để ghi lại phản hồi của nó theo phương pháp thử và sai.
Học tăng cường đã nổi lên như một mô hình mới trong kiểm soát quá trình để tìm hiểu các chính sách kiểm soát tối ưu thông qua tương tác với môi trường. Quá trình này yêu cầu chia dữ liệu thành ba loại: 1) các phép đo có sẵn từ hệ thống vật lý, 2) tập hợp các hành động có thể được thực hiện đối với hệ thống và 3) thước đo số (phần thưởng) về hiệu suất của thiết bị. Một chính sách được đào tạo để tìm ra hành động, theo một quan sát nhất định, có khả năng tạo ra phần thưởng cao nhất trong tương lai.
Trong học tăng cường ngoại tuyến, người ta có thể đào tạo chính sách về dữ liệu lịch sử trước khi triển khai nó vào sản xuất. Thuật toán được đào tạo trong bài đăng trên blog này được gọi là “Học tập Q bảo thủ” (CQL). CQL chứa mô hình “tác nhân” và mô hình “phê bình” và được thiết kế để dự đoán một cách thận trọng hiệu suất của chính nó sau khi thực hiện hành động được đề xuất. Trong bài đăng này, quy trình này được thể hiện bằng một bài toán minh họa về điều khiển xe đẩy. Mục tiêu là đào tạo một đặc vụ cách giữ thăng bằng một cột trên xe đẩy đồng thời di chuyển xe tới vị trí mục tiêu được chỉ định. Quy trình đào tạo sử dụng dữ liệu ngoại tuyến, cho phép tác nhân học hỏi từ thông tin có sẵn. Nghiên cứu điển hình về cột xe đẩy này chứng minh quy trình đào tạo và tính hiệu quả của nó trong các ứng dụng tiềm năng trong thế giới thực.
Tổng quan về giải pháp
Giải pháp được trình bày trong bài đăng này tự động hóa việc triển khai quy trình làm việc toàn diện để học tăng cường ngoại tuyến với dữ liệu lịch sử. Sơ đồ sau đây mô tả kiến trúc được sử dụng trong quy trình làm việc này. Dữ liệu đo được tạo ra ở rìa bởi một thiết bị công nghiệp (ở đây được mô phỏng bởi một AWS Lambda chức năng). Dữ liệu được đưa vào một Amazon Kinesis Data Firehose, nơi lưu trữ nó trong Dịch vụ lưu trữ đơn giản của Amazon (Amazon S3). Amazon S3 là giải pháp lưu trữ bền bỉ, hiệu quả và chi phí thấp cho phép bạn cung cấp khối lượng lớn dữ liệu cho quy trình đào tạo machine learning.
Keo AWS lập danh mục dữ liệu và làm cho nó có thể truy vấn được bằng cách sử dụng amazon Athena. Athena chuyển đổi dữ liệu đo lường thành dạng mà thuật toán học tăng cường có thể nhập vào rồi tải dữ liệu đó trở lại Amazon S3. Amazon SageMaker tải dữ liệu này vào công việc đào tạo và tạo ra mô hình được đào tạo. Sau đó, SageMaker phân phát mô hình đó ở điểm cuối SageMaker. Sau đó, thiết bị công nghiệp có thể truy vấn điểm cuối đó để nhận đề xuất hành động.
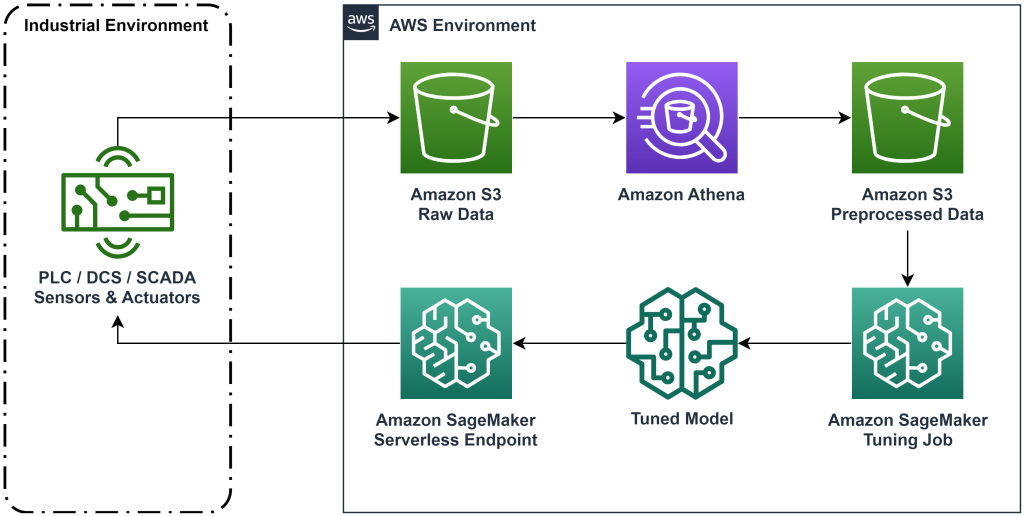
Hình 1: Sơ đồ kiến trúc hiển thị quy trình học tăng cường từ đầu đến cuối.
Trong bài đăng này, chúng tôi sẽ chia nhỏ quy trình làm việc theo các bước sau:
- Xây dựng vấn đề. Quyết định những hành động nào có thể được thực hiện, những phép đo nào để đưa ra khuyến nghị dựa trên đó và xác định bằng số lượng từng hành động được thực hiện tốt như thế nào.
- Chuẩn bị dữ liệu. Chuyển đổi bảng đo thành định dạng mà thuật toán máy học có thể sử dụng.
- Huấn luyện thuật toán trên dữ liệu đó.
- Chọn quá trình đào tạo tốt nhất dựa trên số liệu đào tạo.
- Triển khai mô hình đến điểm cuối SageMaker.
- Đánh giá hiệu quả của mô hình trong sản xuất.
Điều kiện tiên quyết
Để hoàn thành hướng dẫn này, bạn cần có một Tài khoản AWS và giao diện dòng lệnh với Đã cài đặt AWS SAM. Hãy làm theo các bước sau để triển khai mẫu AWS SAM nhằm chạy quy trình làm việc này và tạo dữ liệu đào tạo:
- Tải xuống kho mã bằng lệnh
- Thay đổi thư mục vào repo:
- Xây dựng kho lưu trữ:
- Triển khai kho lưu trữ
- Sử dụng các lệnh sau để gọi tập lệnh bash, tạo ra dữ liệu mô phỏng bằng hàm AWS Lambda.
sudo yum install jqcd utilssh generate_mock_data.sh
Hướng dẫn giải pháp
Xây dựng bài toán
Hệ thống của chúng tôi trong bài đăng trên blog này là một chiếc xe đẩy có cột cân bằng ở trên. Hệ thống hoạt động tốt khi cột thẳng đứng và vị trí xe đẩy gần với vị trí khung thành. Ở bước tiên quyết, chúng tôi đã tạo dữ liệu lịch sử từ hệ thống này.
Bảng sau đây hiển thị dữ liệu lịch sử được thu thập từ hệ thống.
| Vị trí giỏ hàng | Vận tốc xe đẩy | Góc cực | Vận tốc góc cực | Vị trí mục tiêu | Ngoại lực | Khen thưởng | Thời gian |
| 0.53 | -0.79 | -0.08 | 0.16 | 0.50 | -0.04 | 11.5 | 5:37:54 chiều |
| 0.51 | -0.82 | -0.07 | 0.17 | 0.50 | -0.04 | 11.9 | 5:37:55 chiều |
| 0.50 | -0.84 | -0.07 | 0.18 | 0.50 | -0.03 | 12.2 | 5:37:56 chiều |
| 0.48 | -0.85 | -0.07 | 0.18 | 0.50 | -0.03 | 10.5 | 5:37:57 chiều |
| 0.46 | -0.87 | -0.06 | 0.19 | 0.50 | -0.03 | 10.3 | 5:37:58 chiều |
Bạn có thể truy vấn thông tin lịch sử hệ thống bằng Amazon Athena bằng truy vấn sau:
Trạng thái của hệ thống này được xác định bởi vị trí xe đẩy, vận tốc xe đẩy, góc cực, vận tốc góc cực và vị trí mục tiêu. Tác dụng được thực hiện ở mỗi bước thời gian là ngoại lực tác dụng lên xe. Môi trường mô phỏng tạo ra giá trị phần thưởng cao hơn khi xe đẩy gần vị trí mục tiêu hơn và cột thẳng đứng hơn.
Chuẩn bị dữ liệu
Để trình bày thông tin hệ thống cho mô hình học tăng cường, hãy chuyển đổi nó thành các đối tượng JSON với các khóa phân loại các giá trị thành trạng thái (còn gọi là danh mục quan sát), hành động và phần thưởng. Lưu trữ các đối tượng này trong Amazon S3. Dưới đây là ví dụ về đối tượng JSON được tạo từ các bước thời gian trong bảng trước.
|
{“obs”:[[0.53,-0.79,-0.08,0.16,0.5]], “action”:[[-0.04]], “reward”:[11.5] ,”next_obs”:[[0.51,-0.82,-0.07,0.17,0.5]]} |
|
{“obs”:[[0.51,-0.82,-0.07,0.17,0.5]], “action”:[[-0.04]], “reward”:[11.9], “next_obs”:[[0.50,-0.84,-0.07,0.18,0.5]]} |
|
{“obs”:[[0.50,-0.84,-0.07,0.18,0.5]], “action”:[[-0.03]], “reward”:[12.2], “next_obs”:[[0.48,-0.85,-0.07,0.18,0.5]]} |
Ngăn xếp AWS CloudFormation chứa một đầu ra có tên AthenaQueryToCreateJsonFormatedData. Chạy truy vấn này trong Amazon Athena để thực hiện chuyển đổi và lưu trữ các đối tượng JSON trong Amazon S3. Thuật toán học tăng cường sử dụng cấu trúc của các đối tượng JSON này để hiểu giá trị nào làm cơ sở đề xuất và kết quả của việc thực hiện hành động trong dữ liệu lịch sử.
Đại lý tàu hỏa
Bây giờ chúng ta có thể bắt đầu công việc đào tạo để tạo ra mô hình đề xuất hành động đã được đào tạo. Amazon SageMaker cho phép bạn nhanh chóng khởi chạy nhiều công việc đào tạo để xem các cấu hình khác nhau ảnh hưởng như thế nào đến mô hình được đào tạo thu được. Gọi hàm Lambda có tên TuningJobLauncherFunction để bắt đầu công việc điều chỉnh siêu tham số nhằm thử nghiệm bốn bộ siêu tham số khác nhau khi huấn luyện thuật toán.
Chọn chương trình đào tạo tốt nhất
Để tìm ra công việc đào tạo nào tạo ra mô hình tốt nhất, hãy kiểm tra các đường cong tổn thất được tạo ra trong quá trình đào tạo. Mô hình phê bình của CQL ước tính hiệu suất của tác nhân (được gọi là giá trị Q) sau khi thực hiện hành động được đề xuất. Một phần của hàm mất mát của nhà phê bình bao gồm lỗi chênh lệch thời gian. Số liệu này đo lường độ chính xác của giá trị Q của nhà phê bình. Hãy tìm các lần chạy huấn luyện có giá trị Q trung bình cao và sai số chênh lệch thời gian thấp. Tờ giấy này, Quy trình học tập tăng cường robot không có mô hình ngoại tuyến, chi tiết cách chọn chương trình đào tạo tốt nhất. Kho lưu trữ mã có một tệp, /utils/investigate_training.py, điều đó tạo ra một hình vẽ html mô tả công việc đào tạo mới nhất. Chạy tệp này và sử dụng kết quả đầu ra để chọn quá trình đào tạo tốt nhất.
Chúng ta có thể sử dụng giá trị Q trung bình để dự đoán hiệu suất của mô hình được đào tạo. Các giá trị Q được đào tạo để dự đoán một cách thận trọng tổng giá trị phần thưởng đã chiết khấu trong tương lai. Đối với các quy trình chạy dài, chúng ta có thể chuyển đổi con số này thành giá trị trung bình theo cấp số nhân bằng cách nhân giá trị Q với (1-“tỷ lệ chiết khấu”). Quá trình đào tạo tốt nhất trong tập hợp này đã đạt được giá trị Q trung bình là 539. Tỷ lệ chiết khấu của chúng tôi là 0.99, do đó, mô hình dự đoán phần thưởng trung bình ít nhất là 5.39 cho mỗi bước thời gian. Bạn có thể so sánh giá trị này với hiệu suất lịch sử của hệ thống để biết liệu mô hình mới có hoạt động tốt hơn chính sách kiểm soát lịch sử hay không. Trong thử nghiệm này, phần thưởng trung bình của dữ liệu lịch sử cho mỗi bước thời gian là 4.3, do đó, mô hình CQL dự đoán hiệu suất tốt hơn 25% so với hệ thống đạt được trước đây.
Triển khai mô hình
Điểm cuối của Amazon SageMaker cho phép bạn cung cấp các mô hình machine learning theo nhiều cách khác nhau để đáp ứng nhiều trường hợp sử dụng khác nhau. Trong bài đăng này, chúng tôi sẽ sử dụng loại điểm cuối không có máy chủ để điểm cuối của chúng tôi tự động thay đổi quy mô theo nhu cầu và chúng tôi chỉ trả tiền cho mức sử dụng điện toán khi điểm cuối tạo ra suy luận. Để triển khai điểm cuối không có máy chủ, hãy bao gồm một ProductionVariantServerlessConfig trong biến thể sản xuất của SageMaker cấu hình điểm cuối. Đoạn mã sau đây cho thấy cách triển khai điểm cuối phi máy chủ trong ví dụ này bằng bộ công cụ phát triển phần mềm Amazon SageMaker dành cho Python. Tìm mã mẫu được sử dụng để triển khai mô hình tại sagemaker-offline-gia cố-học-ray-cql.
Các tệp mô hình đã đào tạo được đặt tại các tạo phẩm mô hình S3 cho mỗi lần chạy đào tạo. Để triển khai mô hình machine learning, hãy tìm các tệp mô hình của quá trình đào tạo tốt nhất và gọi hàm Lambda có tên là “ModelDeployerFunction” với một sự kiện chứa dữ liệu mô hình này. Hàm Lambda sẽ khởi chạy điểm cuối không có máy chủ của SageMaker để phục vụ mô hình đã đào tạo. Sự kiện mẫu để sử dụng khi gọi “ModelDeployerFunction"
Đánh giá hiệu suất mô hình được đào tạo
Đã đến lúc xem mô hình được đào tạo của chúng tôi hoạt động như thế nào trong sản xuất! Để kiểm tra hiệu suất của mô hình mới, hãy gọi hàm Lambda có tên “RunPhysicsSimulationFunction” với tên điểm cuối SageMaker trong sự kiện. Thao tác này sẽ chạy mô phỏng bằng cách sử dụng các hành động được điểm cuối đề xuất. Sự kiện mẫu để sử dụng khi gọi RunPhysicsSimulatorFunction:
Sử dụng truy vấn Athena sau đây để so sánh hiệu suất của mô hình đã đào tạo với hiệu suất hệ thống trước đây.
| Nguồn hành động | Phần thưởng trung bình mỗi bước thời gian |
trained_model |
10.8 |
historic_data |
4.3 |
Các hoạt ảnh sau đây cho thấy sự khác biệt giữa một tập mẫu từ dữ liệu huấn luyện và một tập trong đó mô hình đã huấn luyện được sử dụng để chọn hành động cần thực hiện. Trong hoạt ảnh, hộp màu xanh lam là xe đẩy, đường màu xanh lam là cột và hình chữ nhật màu xanh lá cây là vị trí mục tiêu. Mũi tên màu đỏ biểu thị lực tác dụng lên xe ở mỗi bước thời gian. Mũi tên màu đỏ trong dữ liệu huấn luyện nhảy qua nhảy lại khá nhiều vì dữ liệu được tạo bằng 50% hành động của chuyên gia và 50% hành động ngẫu nhiên. Mô hình được đào tạo đã học được chính sách điều khiển giúp di chuyển xe nhanh chóng đến vị trí mục tiêu trong khi vẫn duy trì sự ổn định, hoàn toàn từ việc quan sát các cuộc trình diễn của những người không có chuyên môn.
 |
 |
Làm sạch
Để xóa các tài nguyên được sử dụng trong quy trình công việc này, hãy điều hướng đến phần tài nguyên của ngăn xếp Amazon CloudFormation và xóa nhóm S3 cũng như vai trò IAM. Sau đó xóa chính ngăn xếp CloudFormation.
Kết luận
Học tăng cường ngoại tuyến có thể giúp các công ty công nghiệp tự động hóa việc tìm kiếm các chính sách tối ưu mà không ảnh hưởng đến sự an toàn bằng cách sử dụng dữ liệu lịch sử. Để triển khai phương pháp này trong hoạt động của bạn, hãy bắt đầu bằng cách xác định các phép đo tạo nên hệ thống do trạng thái xác định, các hành động bạn có thể kiểm soát và các số liệu cho biết hiệu suất mong muốn. Sau đó, truy cập kho GitHub này để triển khai giải pháp toàn diện tự động bằng Ray và Amazon SageMaker.
Bài viết này chỉ giới thiệu sơ qua về những gì bạn có thể làm với Amazon SageMaker RL. Hãy dùng thử và vui lòng gửi phản hồi cho chúng tôi bằng cách Diễn đàn thảo luận Amazon SageMaker hoặc thông qua các liên hệ AWS thông thường của bạn.
Về các tác giả
 Walt Mayfield là Kiến trúc sư giải pháp tại AWS và giúp các công ty năng lượng hoạt động an toàn và hiệu quả hơn. Trước khi gia nhập AWS, Walt từng làm Kỹ sư vận hành cho Công ty năng lượng Hilcorp. Anh ấy thích làm vườn và thả cá vào thời gian rảnh rỗi.
Walt Mayfield là Kiến trúc sư giải pháp tại AWS và giúp các công ty năng lượng hoạt động an toàn và hiệu quả hơn. Trước khi gia nhập AWS, Walt từng làm Kỹ sư vận hành cho Công ty năng lượng Hilcorp. Anh ấy thích làm vườn và thả cá vào thời gian rảnh rỗi.
 Felipe López là Kiến trúc sư giải pháp cấp cao tại AWS, tập trung vào Hoạt động sản xuất dầu khí. Trước khi gia nhập AWS, Felipe đã làm việc với GE Digital và Schlumberger, nơi ông tập trung vào mô hình hóa và tối ưu hóa các sản phẩm cho ứng dụng công nghiệp.
Felipe López là Kiến trúc sư giải pháp cấp cao tại AWS, tập trung vào Hoạt động sản xuất dầu khí. Trước khi gia nhập AWS, Felipe đã làm việc với GE Digital và Schlumberger, nơi ông tập trung vào mô hình hóa và tối ưu hóa các sản phẩm cho ứng dụng công nghiệp.
 Yingwei Yu là Nhà khoa học ứng dụng tại Vườn ươm AI sáng tạo, AWS. Anh có kinh nghiệm làm việc với một số tổ chức trong nhiều ngành về các bằng chứng khác nhau về khái niệm trong học máy, bao gồm xử lý ngôn ngữ tự nhiên, phân tích chuỗi thời gian và bảo trì dự đoán. Khi rảnh rỗi, anh thích bơi lội, vẽ tranh, đi bộ đường dài và dành thời gian cho gia đình và bạn bè.
Yingwei Yu là Nhà khoa học ứng dụng tại Vườn ươm AI sáng tạo, AWS. Anh có kinh nghiệm làm việc với một số tổ chức trong nhiều ngành về các bằng chứng khác nhau về khái niệm trong học máy, bao gồm xử lý ngôn ngữ tự nhiên, phân tích chuỗi thời gian và bảo trì dự đoán. Khi rảnh rỗi, anh thích bơi lội, vẽ tranh, đi bộ đường dài và dành thời gian cho gia đình và bạn bè.
 Hạo Châu Vương là nhà khoa học nghiên cứu tại Amazon Bedrock tập trung vào việc xây dựng các mô hình nền tảng Titan của Amazon. Trước đây, anh làm việc tại Phòng thí nghiệm giải pháp máy học Amazon với tư cách là đồng lãnh đạo của ngành dọc Học tập tăng cường và giúp khách hàng xây dựng các giải pháp ML nâng cao với nghiên cứu mới nhất về học tập tăng cường, xử lý ngôn ngữ tự nhiên và học tập bằng đồ thị. Haozhu nhận bằng Tiến sĩ về Kỹ thuật Điện và Máy tính tại Đại học Michigan.
Hạo Châu Vương là nhà khoa học nghiên cứu tại Amazon Bedrock tập trung vào việc xây dựng các mô hình nền tảng Titan của Amazon. Trước đây, anh làm việc tại Phòng thí nghiệm giải pháp máy học Amazon với tư cách là đồng lãnh đạo của ngành dọc Học tập tăng cường và giúp khách hàng xây dựng các giải pháp ML nâng cao với nghiên cứu mới nhất về học tập tăng cường, xử lý ngôn ngữ tự nhiên và học tập bằng đồ thị. Haozhu nhận bằng Tiến sĩ về Kỹ thuật Điện và Máy tính tại Đại học Michigan.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Ô tô / Xe điện, Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- PlatoSức khỏe. Tình báo thử nghiệm lâm sàng và công nghệ sinh học. Truy cập Tại đây.
- ChartPrime. Nâng cao trò chơi giao dịch của bạn với ChartPrime. Truy cập Tại đây.
- BlockOffsets. Hiện đại hóa quyền sở hữu bù đắp môi trường. Truy cập Tại đây.
- nguồn: https://aws.amazon.com/blogs/machine-learning/optimize-equipment-performance-with-historical-data-ray-and-amazon-sagemaker/

