Nhận dạng văn bản vào năm 2023
Ở nhiều công ty và tổ chức, rất nhiều dữ liệu kinh doanh có giá trị được lưu trữ trong các tài liệu. Dữ liệu này là trung tâm của chuyển đổi kỹ thuật số. Thật không may, theo thống kê, 80% tất cả dữ liệu này được nhúng ở các định dạng phi cấu trúc như hóa đơn kinh doanh, email, biên lai, tài liệu PDF, v.v. Do đó, để trích xuất và tận dụng tối đa thông tin từ các tài liệu này, các công ty dần dần bắt đầu dựa vào các dịch vụ dựa trên Trí tuệ nhân tạo (AI). Trong số những công ty cung cấp dịch vụ dựa trên AI, Amazon đã là một trong những công ty nổi bật nhất trong một thời gian dài. Nó có đôi cánh trải rộng trên nhiều giải pháp khác nhau như xử lý văn bản, nhận dạng giọng nói, phân tích văn bản và hơn thế nữa.
Trong blog này, chúng ta sẽ xem xét AWS Textract của Amazon, một dịch vụ máy học được quản lý hoàn toàn có thể tự động trích xuất văn bản in, chữ viết tay, bảng và các dữ liệu khác từ các tài liệu được quét. Bắt đầu nào!
Nói một cách dễ hiểu, AWS Textract là một dịch vụ dựa trên học tập sâu giúp chuyển đổi các loại tài liệu khác nhau thành một định dạng có thể chỉnh sửa. Hãy xem xét chúng tôi có các bản in hóa đơn từ các công ty khác nhau và lưu trữ tất cả các thông tin quan trọng từ chúng trên excel / bảng tính. Thông thường, chúng tôi dựa vào các toán tử nhập dữ liệu để nhập chúng theo cách thủ công, việc này rất bận rộn, tốn thời gian và dễ xảy ra lỗi. Nhưng bằng cách sử dụng Textract, tất cả những gì chúng ta cần làm là tải hóa đơn của mình lên nó và đến lượt nó, nó trả về tất cả văn bản, biểu mẫu, cặp khóa-giá trị và bảng trong tài liệu theo cách có cấu trúc hơn. Dưới đây là ảnh chụp màn hình về cách AWS thực hiện trích xuất thông tin thông minh:
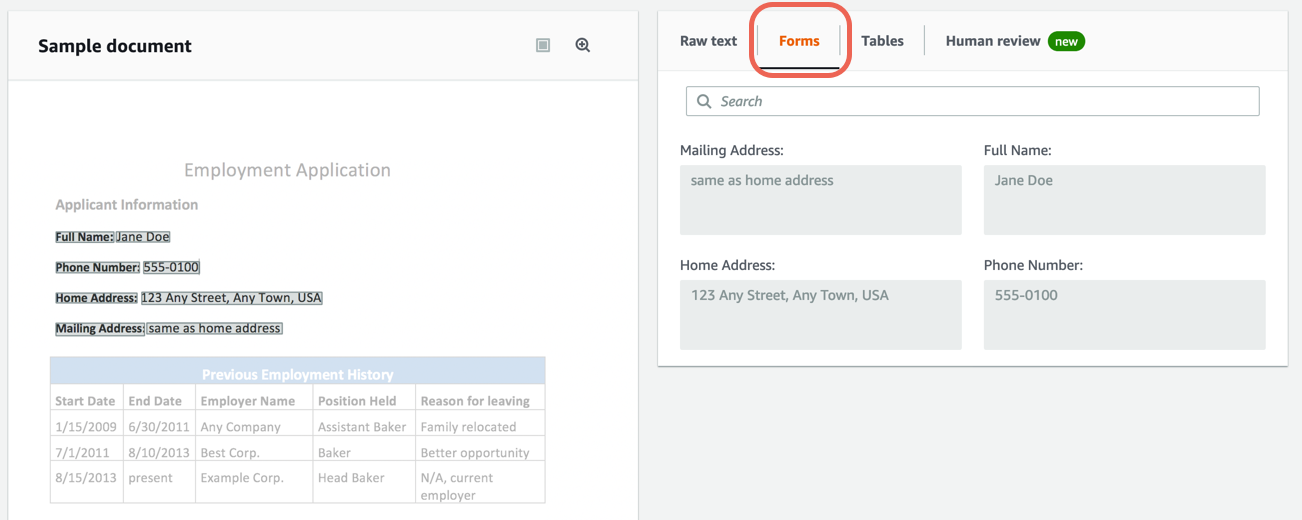
Không chỉ văn bản được đánh máy, AWS Textract còn xác định các văn bản viết tay trong tài liệu. Điều này làm cho việc trích xuất thông tin trở nên hữu ích hơn, vì trong một số trường hợp, trích xuất văn bản viết tay phức tạp hơn để trích xuất văn bản đã đánh máy. Bây giờ chúng ta hãy xem một số trường hợp sử dụng phổ biến để sử dụng Textract:
Thu thập dữ liệu mạnh mẽ và chuẩn hóa: Amazon Textract cho phép trích xuất dữ liệu dạng văn bản và dạng bảng từ nhiều loại tài liệu khác nhau, chẳng hạn như tài liệu tài chính, báo cáo nghiên cứu và ghi chú y tế. Tuy nhiên, đây không phải là các API được tạo tùy chỉnh mà chúng học hỏi từ một lượng lớn dữ liệu mỗi ngày và với việc học hỏi liên tục này, trích xuất không có cấu trúc và dữ liệu có cấu trúc từ tài liệu của bạn sẽ dễ dàng hơn nhiều.
Trích xuất cặp khóa-giá trị: Trích xuất cặp Khóa-Giá trị đã trở thành một vấn đề phổ biến trong xử lý tài liệu nhưng với Amazon Textract, điều này có thể được giải quyết dễ dàng. Chúng ta có thể xây dựng quy trình trích xuất cặp khóa-giá trị bằng cách sử dụng Textract. tự động hóa tài liệu xử lý ngay từ khi quét tài liệu đến đẩy dữ liệu lên bảng excel, v.v.
Tạo chỉ mục tìm kiếm thông minh: Amazon Textract cho phép bạn tạo thư viện văn bản được phát hiện trong tệp hình ảnh và tệp PDF.
Sử dụng tính năng trích xuất văn bản thông minh để xử lý ngôn ngữ tự nhiên (NLP) - Amazon Textract cho phép bạn trích xuất văn bản thành các từ và dòng. Nó cũng nhóm văn bản theo các ô trong bảng nếu tính năng phân tích bảng tài liệu Amazon Textract được bật. Amazon Textract cung cấp cho bạn quyền kiểm soát cách văn bản được nhóm làm đầu vào cho NLP.
Tìm kiếm một giải pháp Nhận dạng Văn bản thông minh? Đi tới Ống nano và sử dụng giải pháp với độ chính xác trên 95%.
Trong phần này, chúng ta sẽ thảo luận về cách thức hoạt động của AWS Textract. Chúng tôi biết rằng các thuật toán AI và ML mạnh mẽ đứng đằng sau chúng; tuy nhiên, không có bất kỳ mô hình mã nguồn mở nào để đi sâu vào các chi tiết cụ thể. Nhưng tôi sẽ cố gắng giải mã các hoạt động bằng cách tóm tắt tài liệu có thể tìm thấy ở đây. Bắt đầu nào!

Thứ nhất, bất cứ khi nào một tài liệu mới hoặc một tài liệu đã quét được gửi vào Textract, nó sẽ tạo ra một danh sách các đối tượng khối cho tất cả văn bản được phát hiện. Ví dụ: giả sử một hóa đơn bao gồm hàng trăm từ ngày nay, AWS tạo ra hàng trăm đối tượng khối cho tất cả các từ. Các khối này chứa thông tin về một mục được phát hiện, vị trí của nó và sự tự tin mà Amazon Textract có được về độ chính xác của quá trình xử lý.
Thông thường, hầu hết các tài liệu được tạo thành từ các khối sau:
- Trang
- Các dòng và từ của văn bản
- Dữ liệu biểu mẫu (Các cặp khóa-giá trị)
- Bảng và ô
- Các yếu tố lựa chọn
Dưới đây là ví dụ và cấu trúc dữ liệu khối của AWS Textract:
{ "Blocks":[ { "Geometry": { "BoundingBox": { "Width": 1.0, "Top": 0.0, "Left": 0.0, "Height": 1.0 }, "Polygon": [ { "Y": 0.0, "X": 0.0 }, { "Y": 0.0, "X": 1.0 }, { "Y": 1.0, "X": 1.0 }, { "Y": 1.0, "X": 0.0 } ] }, "Relationships": [ { "Type": "CHILD", "Ids": [ "2602b0a6-20e3-4e6e-9e46-3be57fd0844b", "82aedd57-187f-43dd-9eb1-4f312ca30042", "52be1777-53f7-42f6-a7cf-6d09bdc15a30", "7ca7caa6-00ef-4cda-b1aa-5571dfed1a7c" ] } ], "BlockType": "PAGE", "Id": "8136b2dc-37c1-4300-a9da-6ed8b276ea97" }..... ], "DocumentMetadata": { "Pages": 1 }
}
Tuy nhiên, nội dung bên trong các khối thay đổi dựa trên hoạt động mà chúng tôi gọi. Đối với hoạt động phát hiện văn bản, các khối sẽ trả về các trang, dòng và từ của văn bản được phát hiện. Nếu chúng ta đang sử dụng các thao tác phân tích tài liệu, các khối sẽ trả về các trang được phát hiện, cặp khóa-giá trị, bảng, phần tử lựa chọn và văn bản. Tuy nhiên, điều này chỉ giải thích hoạt động cấp cao hơn của Textract, trong phần tiếp theo chúng ta hãy đi sâu vào OCR đằng sau Textract.
Không có chi tiết cụ thể nào về loại OCR mà Amazon Textract sử dụng vì nó là một sản phẩm thương mại. Tuy nhiên, chúng ta có thể so sánh nó với một trong những OCR nguồn mở phổ biến nhất, “Tesseract”, để hiểu độ chính xác và khả năng trích xuất các loại tài liệu khác nhau của nó.
Tesseract OCR dựa trên LSTM, một kiến trúc mạng thần kinh dựa trên học sâu, hoạt động đặc biệt tốt trên dữ liệu văn bản. Sau đây là các định dạng tài liệu mà tesseract hỗ trợ: văn bản thuần túy, hOCR (HTML), PDF, PDF chỉ văn bản ẩn, TSV. Nó có hỗ trợ Unicode (UTF-8) và hỗ trợ hơn 100 ngôn ngữ. Tuy nhiên, vì tất cả mã đều là mã nguồn mở nên nó có thể được đào tạo để nhận ra các ngôn ngữ khác, nhưng điều này đòi hỏi phải học sâu và chuyên môn về thị giác máy tính. Khi nói đến bảng và trích xuất cặp khóa-giá trị, tesseract không thành công. Tuy nhiên, chúng tôi có thể xây dựng các đường ống tùy chỉnh để giải quyết vấn đề này.
Textract OCR cũng là một kiến trúc mạng nơ-ron dựa trên học sâu, nhưng điều này không thể hoàn toàn tùy chỉnh hoặc được đào tạo trên một tập dữ liệu tùy chỉnh. Công việc của nó là phân tích cú pháp và trích xuất tất cả dữ liệu bên trong một tài liệu. Tuy nhiên, Textract tự động điều chỉnh dữ liệu của bạn và đạt được độ chính xác cao hơn khi đang di chuyển nếu có người xác minh thông tin được trích xuất (người trong vòng lặp). Đối với các tác vụ như trích xuất bảng và trích xuất cặp khóa-giá trị, Textract thực hiện công việc tốt khi đạt được độ chính xác cao hơn Tesseract. Nhưng nó chỉ giới hạn ở một số ngôn ngữ và định dạng tài liệu.
Dưới đây là một số loại tài liệu có thể được xử lý bằng AWS Textract:
- Hóa đơn / Hóa đơn thông thường
- Chứng từ tài chính
- Tài liệu y tế
- Tài liệu viết tay
- Payslips hoặc tài liệu nhân viên
Trong phần tiếp theo, chúng ta hãy xem xét API Textract Python.
Tìm kiếm một người thông minh Giải pháp OCR để trích xuất thông tin từ tài liệu của bạn? Đi qua Ống nano để trích xuất văn bản từ tài liệu ở bất kỳ định dạng nào bằng bất kỳ ngôn ngữ nào.
API Textract của Amazon có thể được sử dụng trong các ngôn ngữ lập trình khác nhau. Trong phần này, chúng ta sẽ xem xét khối mã chiết xuất khóa-giá trị bằng cách sử dụng Textract với Python. Để biết thêm thông tin về ngôn ngữ và hỗ trợ API, hãy xem tài liệu tại đây.
Đoạn mã này là một ví dụ về cách chúng tôi có thể thực hiện trích xuất cặp khóa-giá trị trên các tài liệu sử dụng API Python của Textract. Để điều này hoạt động, chúng tôi cũng sẽ phải định cấu hình khóa API trên trang tổng quan AWS. Bây giờ chúng ta hãy đi sâu vào đoạn mã,
Đầu tiên, chúng tôi nhập tất cả các gói cần thiết để đẩy tài liệu sang AWS và xử lý văn bản được trích xuất.
import boto3
import sys
import re
import json
Tiếp theo, chúng ta có một hàm có tên get_kv_map, ở đây chúng tôi sử dụng boto3 để giao tiếp với API Textract của Amazon, tải lên tài liệu và tìm nạp phản hồi khối. Bây giờ chúng tôi nhận được tất cả các cặp khóa-giá trị bằng cách kiểm tra 'BlockType' và gửi lại nó trong từ điển.
def get_kv_map(file_name): with open(file_name, 'rb') as file: img_test = file.read() bytes_test = bytearray(img_test) print('Image loaded', file_name) # process using image bytes client = boto3.client('textract') response = client.analyze_document(Document={'Bytes': bytes_test}, FeatureTypes=['FORMS']) # Get the text blocks blocks=response['Blocks'] # get key and value maps key_map = {} value_map = {} block_map = {} for block in blocks: block_id = block['Id'] block_map[block_id] = block if block['BlockType'] == "KEY_VALUE_SET": if 'KEY' in block['EntityTypes']: key_map[block_id] = block else: value_map[block_id] = block return key_map, value_map, block_map
Sau đó, chúng ta có một hàm nhận mối quan hệ giữa các cặp khóa-giá trị được trích xuất bằng cách sử dụng các mục khối. Về cơ bản, bằng cách sử dụng các mối quan hệ có trong thông tin khối (JSON), hàm này liên kết các khóa và giá trị trong tài liệu.
def get_kv_relationship(key_map, value_map, block_map): kvs = {} for block_id, key_block in key_map.items(): value_block = find_value_block(key_block, value_map) key = get_text(key_block, block_map) val = get_text(value_block, block_map) kvs[key] = val return kvs def find_value_block(key_block, value_map): for relationship in key_block['Relationships']: if relationship['Type'] == 'VALUE': for value_id in relationship['Ids']: value_block = value_map[value_id] return value_block
Cuối cùng, chúng tôi trả về văn bản có trong các cặp khóa-giá trị đã lưu.
def get_text(result, blocks_map): text = '' if 'Relationships' in result: for relationship in result['Relationships']: if relationship['Type'] == 'CHILD': for child_id in relationship['Ids']: word = blocks_map[child_id] if word['BlockType'] == 'WORD': text += word['Text'] + ' ' if word['BlockType'] == 'SELECTION_ELEMENT': if word['SelectionStatus'] == 'SELECTED': text += 'X' return text def print_kvs(kvs): for key, value in kvs.items(): print(key, ":", value) def search_value(kvs, search_key): for key, value in kvs.items(): if re.search(search_key, key, re.IGNORECASE): return value def main(file_name): key_map, value_map, block_map = get_kv_map(file_name) # Get Key Value relationship kvs = get_kv_relationship(key_map, value_map, block_map) print("nn== FOUND KEY : VALUE pairs ===n") print_kvs(kvs) # Start searching a key value while input('n Do you want to search a value for a key? (enter "n" for exit) ') != 'n': search_key = input('n Enter a search key:') print('The value is:', search_value(kvs, search_key)) if __name__ == "__main__": file_name = sys.argv[1] main(file_name)
Bằng cách này, chúng ta có thể sử dụng AWS Textract API để thực hiện các tác vụ trích xuất thông tin khác nhau. Các hàm / cách tiếp cận tương tự như hầu hết các ngôn ngữ lập trình. Chúng tôi cũng có thể tùy chỉnh phương pháp dựa trên các trường hợp sử dụng của mình nếu chúng tôi sử dụng các API.
Bạn muốn tự động nhập dữ liệu từ các tài liệu? Giải pháp OCR dựa trên AI của Nanonets có thể giúp trích xuất thông tin quan trọng từ các tài liệu có cấu trúc / phi cấu trúc và đưa quy trình vào chế độ tự động thí điểm!
Ưu và nhược điểm của việc sử dụng AWS Textract
Ưu điểm:
Thiết lập dễ dàng với Dịch vụ AWS: Thiết lập Textract với một dịch vụ AWS khác là một nhiệm vụ dễ dàng so với các nhà cung cấp khác. Ví dụ: lưu trữ thông tin tài liệu được trích xuất bằng Amazon DynamoDB hoặc S3 có thể được thực hiện bằng cách định cấu hình tiện ích bổ sung.
An toàn: Amazon Textract tuân theo mô hình trách nhiệm chung AWS, bao gồm các quy định và hướng dẫn về bảo vệ dữ liệu. AWS chịu trách nhiệm bảo vệ cơ sở hạ tầng toàn cầu chạy tất cả các dịch vụ AWS; do đó chúng ta không cần lo lắng về việc dữ liệu của mình bị rò rỉ hoặc bị sử dụng bởi bất kỳ người nào khác.
Nhược điểm:
Không có khả năng trích xuất các trường tùy chỉnh: Có thể có nhiều trường dữ liệu trong một hóa đơn nhất định, chẳng hạn như ID hóa đơn, Ngày đến hạn, Ngày giao dịch, v.v. Những trường này là một cái gì đó phổ biến trong hầu hết các hóa đơn. Nhưng nếu chúng ta muốn trích xuất một trường tùy chỉnh từ hóa đơn, chẳng hạn như số GST hoặc thông tin ngân hàng, thì Textract thực hiện một cách kém hiệu quả.
Tích hợp với các nhà cung cấp thượng nguồn và hạ nguồn: Textract không cho phép bạn tích hợp với các nhà cung cấp khác nhau một cách dễ dàng, chẳng hạn như, chúng tôi sẽ phải xây dựng đường ống RPA với dịch vụ của bên thứ ba; sẽ rất khó để tìm các plugin thích hợp phù hợp với Textract.
Khả năng xác định tiêu đề bảng: Đối với các tác vụ trích xuất bảng, textract không cho phép bạn xác định tiêu đề bảng. Do đó, sẽ không dễ dàng để tìm kiếm hoặc tìm một cột hoặc một bảng cụ thể trong một tài liệu nhất định.
Kiểm tra Không gian lận: Các OCR hiện đại giờ đây có thể tìm xem một tài liệu nhất định là tài liệu gốc hay giả bằng cách xác thực ngày tháng và tìm các vùng có pixel. AWS Textract không đi kèm với điều này, công việc duy nhất của nó là chọn tất cả văn bản từ một tài liệu đã tải lên.
Không có trích xuất văn bản dọc: Trong một số tài liệu, số hóa đơn hoặc địa chỉ có thể được tìm thấy theo chiều dọc. Hiện tại, AWS chỉ hỗ trợ trích xuất văn bản theo chiều ngang bằng cách xoay nhẹ trong mặt phẳng.
Giới hạn ngôn ngữ: Amazon Textract hỗ trợ phát hiện văn bản tiếng Anh, tiếng Tây Ban Nha, tiếng Đức, tiếng Pháp, tiếng Ý và tiếng Bồ Đào Nha. Amazon Textract sẽ không trả về ngôn ngữ được phát hiện trong đầu ra của nó.
Đám mây của mọi thứ: Mọi tài liệu được xử lý bằng Textract sẽ được đưa vào đám mây, chỉ hỗ trợ một vài vùng. Thêm thông tin tại đây. Tuy nhiên, một số công ty có thể không quan tâm đến việc đưa tài liệu của họ lên đám mây vì những lý do như yêu cầu bảo mật hoặc pháp lý. Tuy nhiên, rất tiếc, AWS Textract không hỗ trợ bất kỳ triển khai tại chỗ nào để xử lý tài liệu.
Đào tạo lại: Nếu độ chính xác của chúng tôi thấp đối với các tác vụ trích xuất thông tin cho một bộ tài liệu, thì Textract không cho phép chúng tôi đào tạo lại chúng. Để giải quyết vấn đề này, chúng tôi sẽ phải đầu tư lại vào quy trình đánh giá của con người, trong đó người điều hành phải xác minh và chú thích theo cách thủ công các giá trị được trích xuất sai, điều này lại tốn thời gian.
Kết luận
Chúng tôi hy vọng bài đánh giá này về AWS Textract sẽ hữu ích khi bạn xem xét các giải pháp khác nhau để trích xuất dữ liệu/nhận dạng văn bản từ tài liệu của mình.
Chúng tôi có những phân tích tương tự nếu bạn đang tìm kiếm đánh giá hoặc lựa chọn thay thế cho Kofax or Tầm nhìn của Google.
Chúng tôi sẽ tiếp tục cập nhật bài đăng này định kỳ để cập nhật những thay đổi mới nhất. Để biết thêm chi tiết về Phần mềm OCR đây là một đánh giá chi tiết trong số các giải pháp OCR hàng đầu hiện có trên thị trường.
Vui lòng thêm suy nghĩ và câu hỏi của bạn về việc sử dụng giải pháp Textract của Amazon trong phần nhận xét.
Nguồn: Hình ảnh anh hùng từ trang web AWS.
- Phân phối nội dung và PR được hỗ trợ bởi SEO. Được khuếch đại ngay hôm nay.
- PlatoData.Network Vertical Generative Ai. Trao quyền cho chính mình. Truy cập Tại đây.
- PlatoAiStream. Thông minh Web3. Kiến thức khuếch đại. Truy cập Tại đây.
- Trung tâmESG. Ô tô / Xe điện, Than đá, công nghệ sạch, Năng lượng, Môi trường Hệ mặt trời, Quản lý chất thải. Truy cập Tại đây.
- BlockOffsets. Hiện đại hóa quyền sở hữu bù đắp môi trường. Truy cập Tại đây.
- nguồn: https://nanonets.com/blog/aws-textract-teardown-pros-cons-review/

