بڑے لینگویج ماڈلز (LLMs) کو فائن ٹیوننگ آپ کو اپنے ڈومین کے مخصوص کاموں پر بہتر کارکردگی حاصل کرنے کے لیے اوپن سورس فاؤنڈیشنل ماڈلز کو ایڈجسٹ کرنے کی اجازت دیتا ہے۔ اس پوسٹ میں، ہم استعمال کرنے کے فوائد پر تبادلہ خیال کرتے ہیں۔ ایمیزون سیج میکر جدید ترین اوپن سورس ماڈلز کے لیے نوٹ بک۔ ہم استعمال کرتے ہیں۔ ہگنگ فیس کا پیرامیٹر موثر فائن ٹیوننگ (PEFT) لائبریری اور کوانٹائزیشن تکنیک کے ذریعے بٹ سینڈ بائٹس ایک ہی نوٹ بک مثال کا استعمال کرتے ہوئے انتہائی بڑے ماڈلز کی انٹرایکٹو فائن ٹیوننگ کو سپورٹ کرنے کے لیے۔ خاص طور پر، ہم دکھاتے ہیں کہ کس طرح ٹھیک کرنا ہے۔ Falcon-40B ایک ml.g5.12xlarge مثال (4 A10G GPUs) کا استعمال کرتے ہوئے، لیکن وہی حکمت عملی اس سے بھی بڑے ماڈلز کو ٹیون کرنے کے لیے کام کرتی ہے۔ p4d/p4de نوٹ بک مثالیں۔.
عام طور پر، ان بہت بڑے ماڈلز کی مکمل درستگی کی نمائندگی ایک یا کئی GPUs پر میموری میں فٹ نہیں ہوتی ہے۔ ایک انٹرایکٹو نوٹ بک ماحول کی مدد کرنے کے لیے اس سائز کے ماڈلز کو ٹھیک بنانے اور انفرنس چلانے کے لیے، ہم ایک نئی تکنیک کا استعمال کرتے ہیں کم رینک اڈاپٹر (QLoRA) کے ساتھ کوانٹائزڈ LLMs. QLoRA ایک موثر فائن ٹیوننگ اپروچ ہے جو ٹھوس کارکردگی کو برقرار رکھتے ہوئے LLMs کے میموری استعمال کو کم کرتا ہے۔ گلے لگانا چہرہ اور مذکورہ مقالے کے مصنفین نے شائع کیا ہے۔ تفصیلی بلاگ پوسٹ جو ٹرانسفارمرز اور PEFT لائبریریوں کے ساتھ بنیادی باتوں اور انضمام کا احاطہ کرتا ہے۔
ایل ایل ایم کو ٹھیک کرنے کے لیے نوٹ بک کا استعمال
SageMaker ڈیٹا کو تلاش کرنے اور مشین لرننگ (ML) ماڈلز بنانے کے لیے مکمل طور پر منظم نوٹ بک کو گھمانے کے لیے دو اختیارات کے ساتھ آتا ہے۔ پہلا آپشن تیزی سے شروع کرنا ہے، باہمی تعاون پر مبنی نوٹ بک اس کے اندر قابل رسائی ہے۔ ایمیزون سیج میکر اسٹوڈیوML کے لیے مکمل طور پر مربوط ترقیاتی ماحول (IDE)۔ آپ SageMaker سٹوڈیو میں نوٹ بکس کو تیزی سے لانچ کر سکتے ہیں، اپنے کام میں خلل ڈالے بغیر بنیادی کمپیوٹ وسائل کو ڈائل یا نیچے کر سکتے ہیں، اور یہاں تک کہ حقیقی وقت میں اپنی نوٹ بکس میں شریک ترمیم اور تعاون کر سکتے ہیں۔ نوٹ بک بنانے کے علاوہ، آپ SageMaker اسٹوڈیو میں شیشے کے ایک پین میں اپنے ماڈلز کو بنانے، تربیت دینے، ڈیبگ کرنے، ٹریک کرنے، تعینات کرنے اور ان کی نگرانی کے لیے تمام ML ترقیاتی اقدامات انجام دے سکتے ہیں۔ دوسرا آپشن ہے a سیج میکر نوٹ بک مثال, ایک واحد، مکمل طور پر منظم ایم ایل کمپیوٹ مثال کے طور پر کلاؤڈ میں نوٹ بک چل رہی ہے، جو آپ کو آپ کی نوٹ بک کنفیگریشنز پر مزید کنٹرول فراہم کرتی ہے۔
اس پوسٹ کے بقیہ حصے کے لیے، ہم سیج میکر اسٹوڈیو نوٹ بک استعمال کرتے ہیں کیونکہ ہم استعمال کرنا چاہتے ہیں۔ سیج میکر اسٹوڈیو کے زیر انتظام ٹینسر بورڈ TensorBoard کے لیے Hugging Face Transformer کی مدد سے ٹریکنگ کا تجربہ کریں۔ تاہم، پورے مثال کے کوڈ میں دکھائے گئے وہی تصورات نوٹ بک مثالوں پر کام کریں گے۔ conda_pytorch_p310 دانا یہ بات قابل غور ہے کہ سیج میکر اسٹوڈیو کا ایمیزون لچکدار فائل سسٹم (ایمیزون ای ایف ایس) والیوم کا مطلب ہے کہ آپ کو پہلے سے طے شدہ فراہمی کی ضرورت نہیں ہے۔ ایمیزون لچکدار بلاک اسٹور (ایمیزون ای بی ایس) والیوم سائز، جو LLMs میں ماڈل وزن کے بڑے سائز کے پیش نظر مفید ہے۔
بڑی GPU مثالوں کی حمایت یافتہ نوٹ بک کا استعمال کولڈ اسٹارٹ کنٹینر لانچ کے بغیر تیز رفتار پروٹو ٹائپنگ اور ڈیبگنگ کو قابل بناتا ہے۔ تاہم، اس کا یہ مطلب بھی ہے کہ اضافی اخراجات سے بچنے کے لیے آپ کو اپنی نوٹ بک کی مثالیں بند کرنے کی ضرورت ہے۔ دوسرے اختیارات جیسے ایمیزون سیج میکر جمپ اسٹارٹ اور SageMaker Hugging Face کنٹینرز کو فائن ٹیوننگ کے لیے استعمال کیا جا سکتا ہے، اور ہم تجویز کرتے ہیں کہ آپ اپنے اور آپ کی ٹیم کے لیے بہترین آپشن کا انتخاب کرنے کے لیے مذکورہ بالا طریقوں پر درج ذیل پوسٹس کا حوالہ دیں:
شرائط
اگر یہ آپ کی پہلی بار سیج میکر اسٹوڈیو کے ساتھ کام کر رہی ہے، تو آپ کو پہلے ایک تخلیق کرنے کی ضرورت ہے۔ سیج میکر ڈومین. ہم بھی استعمال کرتے ہیں a تجربہ سے باخبر رہنے کے لیے منظم TensorBoard مثالاگرچہ یہ اس ٹیوٹوریل کے لیے اختیاری ہے۔
مزید برآں، آپ کو متعلقہ SageMaker Studio KernelGateway ایپس کے لیے سروس کوٹہ میں اضافے کی درخواست کرنے کی ضرورت پڑ سکتی ہے۔ Falcon-40B کو ٹھیک کرنے کے لیے، ہم ایک ml.g5.12xlarge مثال استعمال کرتے ہیں۔
سروس کوٹہ میں اضافے کی درخواست کرنے کے لیے، AWS سروس کوٹاس کنسول پر، تشریف لے جائیں۔ AWS خدمات, ایمیزون سیج میکر، اور منتخب کریں اسٹوڈیو کرنل گیٹ وے ایپس ml.g5.12x بڑی مثالوں پر چل رہی ہیں۔. 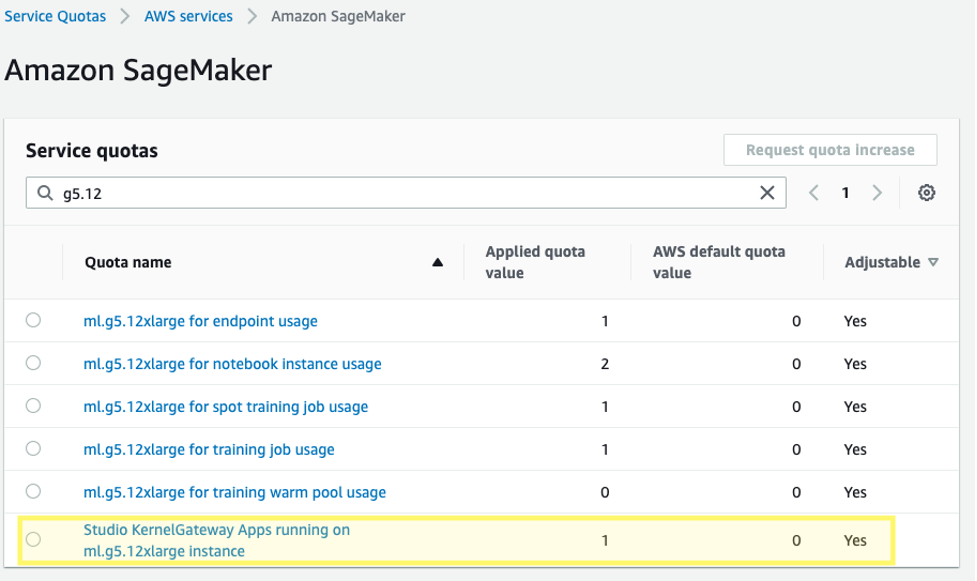
شروع کریں
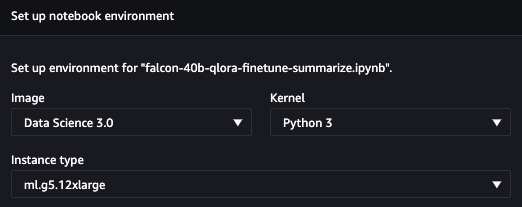
اس پوسٹ کے لیے کوڈ کا نمونہ درج ذیل میں پایا جا سکتا ہے۔ GitHub ذخیرہ. شروع کرنے کے لیے، ہم SageMaker اسٹوڈیو سے ڈیٹا سائنس 3.0 امیج اور Python 3 کرنل کا انتخاب کرتے ہیں تاکہ ہمارے پاس اپنے پیکجز کو انسٹال کرنے کے لیے Python 3.10 کا حالیہ ماحول ہو۔
ہم PyTorch اور مطلوبہ Hugging Face اور bitsandbytes لائبریریاں انسٹال کرتے ہیں:
اگلا، ہم نے نصب شدہ CUDA کا استعمال کرتے ہوئے CUDA ماحول کا راستہ مقرر کیا جو PyTorch کی تنصیب کا انحصار تھا۔ یہ bitsandbytes لائبریری کے لیے درست CUDA مشترکہ آبجیکٹ بائنری کو صحیح طریقے سے ڈھونڈنے اور لوڈ کرنے کے لیے ایک ضروری قدم ہے۔
پہلے سے تربیت یافتہ بنیادی ماڈل لوڈ کریں۔
ہم Falcon-40B ماڈل کو 4-bit precision میں کوانٹائز کرنے کے لیے bitsandbytes کا استعمال کرتے ہیں تاکہ ہم Hugging Face Accelerate کی سادہ پائپ لائن متوازی کا استعمال کرتے ہوئے ماڈل کو 4 A10G GPUs پر میموری میں لوڈ کر سکیں۔ جیسا کہ پہلے ذکر کیا گیا ہے۔ گلے ملتے ہوئے چہرے کی پوسٹ, QLoRA ٹیوننگ کو تجربات کی ایک وسیع رینج میں 16 بٹ فائن ٹیوننگ کے طریقوں سے مماثل دکھایا گیا ہے کیونکہ ماڈل وزن 4 بٹ نارمل فلوٹ کے طور پر محفوظ کیے جاتے ہیں، لیکن ضرورت کے مطابق آگے اور پیچھے والے پاسوں پر حساب کتاب bfloat16 کے لیے کم کر دیے جاتے ہیں۔
پہلے سے تربیت یافتہ وزن لوڈ کرتے وقت، ہم وضاحت کرتے ہیں۔ device_map=”auto" تاکہ Hugging Face Accelerate خود بخود اس بات کا تعین کرے گا کہ ماڈل کی ہر پرت کو کس GPU پر لگانا ہے۔ یہ عمل کے طور پر جانا جاتا ہے ماڈل متوازی.
Hugging Face کی PEFT لائبریری کے ساتھ، آپ زیادہ تر اصل ماڈل کے وزن کو منجمد کر سکتے ہیں اور ایک اضافی، بہت چھوٹے، پیرامیٹرز کے سیٹ کو تربیت دے کر ماڈل کی تہوں کو تبدیل یا بڑھا سکتے ہیں۔ یہ ضروری کمپیوٹ کے لحاظ سے تربیت کو بہت کم مہنگا بناتا ہے۔ ہم Falcon ماڈیولز سیٹ کرتے ہیں جسے ہم ٹھیک ٹیون کرنا چاہتے ہیں۔ target_modules LoRA ترتیب میں:
نوٹ کریں کہ ہم ماڈل کے پیرامیٹرز کا صرف 0.26% ٹھیک کر رہے ہیں، جو اسے مناسب وقت میں ممکن بناتا ہے۔
ڈیٹاسیٹ لوڈ کریں۔
ہم استعمال کرتے ہیں صمسم ہمارے فائن ٹیوننگ کے لیے ڈیٹا سیٹ۔ سیمسم 16,000 میسنجر جیسی گفتگو کا مجموعہ ہے جس میں لیبل لگائے گئے خلاصے ہیں۔ درج ذیل ڈیٹاسیٹ کی ایک مثال ہے:
عملی طور پر، آپ ایک ایسا ڈیٹاسیٹ استعمال کرنا چاہیں گے جس میں اس کام کے لیے مخصوص معلومات ہوں جو آپ اپنے ماڈل کو ٹیون کرنے کی امید کر رہے ہیں۔ اس طرح کے ڈیٹاسیٹ کی تعمیر کے عمل کو استعمال کرکے تیز کیا جاسکتا ہے۔ ایمیزون سیج میکر گراؤنڈ ٹروتھ پلسجیسا کہ میں بیان کیا گیا ہے۔ ایمیزون سیج میکر گراؤنڈ ٹروتھ پلس سے آپ کی تخلیقی AI ایپلیکیشنز کے لیے اعلیٰ معیار کے انسانی تاثرات.
ماڈل کو ٹھیک بنائیں
فائن ٹیوننگ سے پہلے، ہم ان ہائپر پیرامیٹرس کی وضاحت کرتے ہیں جو ہم ماڈل کو استعمال اور تربیت دینا چاہتے ہیں۔ ہم پیرامیٹر کی وضاحت کرکے اپنے میٹرکس کو TensorBoard پر بھی لاگ کر سکتے ہیں۔ logging_dir اور ہگنگ فیس ٹرانسفارمر کی درخواست کر رہا ہے۔ report_to="tensorboard":
فائن ٹیوننگ کی نگرانی کریں۔
پچھلے سیٹ اپ کے ساتھ، ہم حقیقی وقت میں اپنی فائن ٹیوننگ کی نگرانی کر سکتے ہیں۔ حقیقی وقت میں GPU کے استعمال کی نگرانی کرنے کے لیے، ہم چلا سکتے ہیں۔ nvidia-smi براہ راست دانا کے کنٹینر سے۔ امیج کنٹینر پر چلنے والے ٹرمینل کو لانچ کرنے کے لیے، اپنی نوٹ بک کے اوپری حصے میں صرف ٹرمینل آئیکن کو منتخب کریں۔

یہاں سے، ہم لینکس استعمال کر سکتے ہیں۔ watch بار بار چلانے کا حکم nvidia-smi ہر آدھے سیکنڈ:
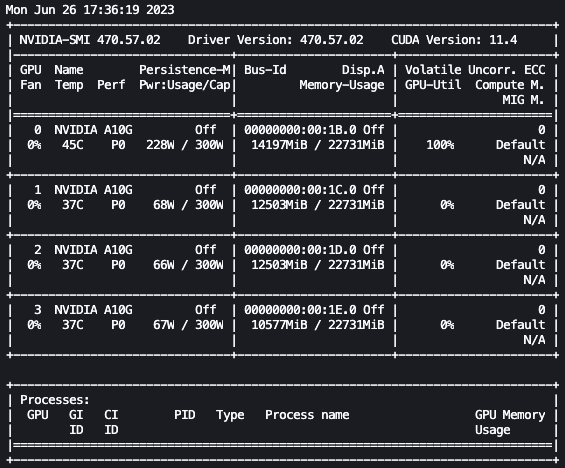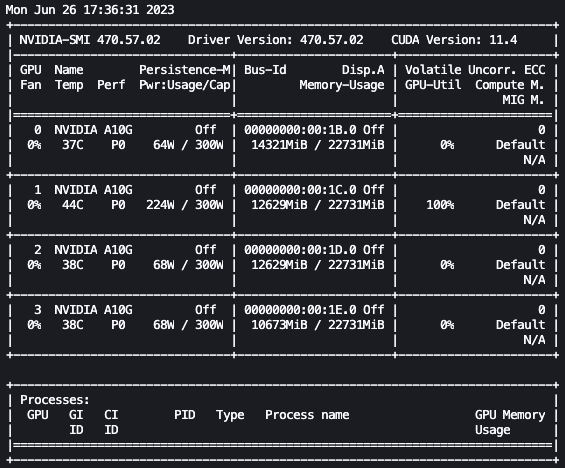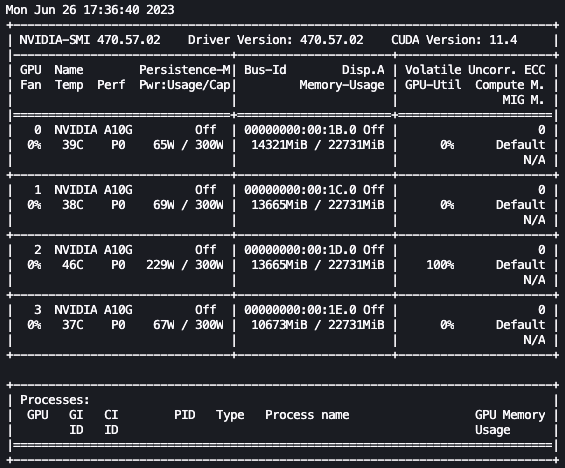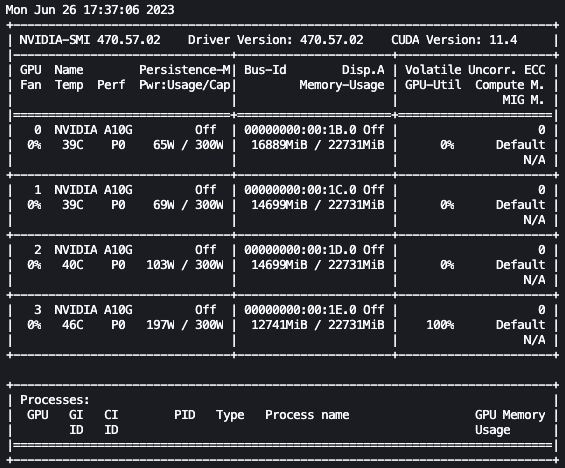
پچھلے اینیمیشن میں، ہم دیکھ سکتے ہیں کہ ماڈل کے وزن کو 4 GPUs میں تقسیم کیا گیا ہے اور ان میں حساب تقسیم کیا جا رہا ہے کیونکہ تہوں کو سیریل پروسیس کیا جاتا ہے۔
ٹریننگ میٹرکس کی نگرانی کے لیے، ہم TensorBoard لاگز کا استعمال کرتے ہیں جو ہم مخصوص پر لکھتے ہیں۔ ایمیزون سادہ اسٹوریج سروس (ایمیزون S3) بالٹی۔ ہم AWS SageMaker کنسول سے اپنے SageMaker سٹوڈیو ڈومین صارف کا TensorBoard لانچ کر سکتے ہیں:
لوڈ کرنے کے بعد، آپ S3 بالٹی کی وضاحت کر سکتے ہیں جسے آپ نے تربیت اور تشخیصی میٹرکس دیکھنے کے لیے ہگنگ فیس ٹرانسفارمر کو لاگ ان کرنے کی ہدایت کی تھی۔
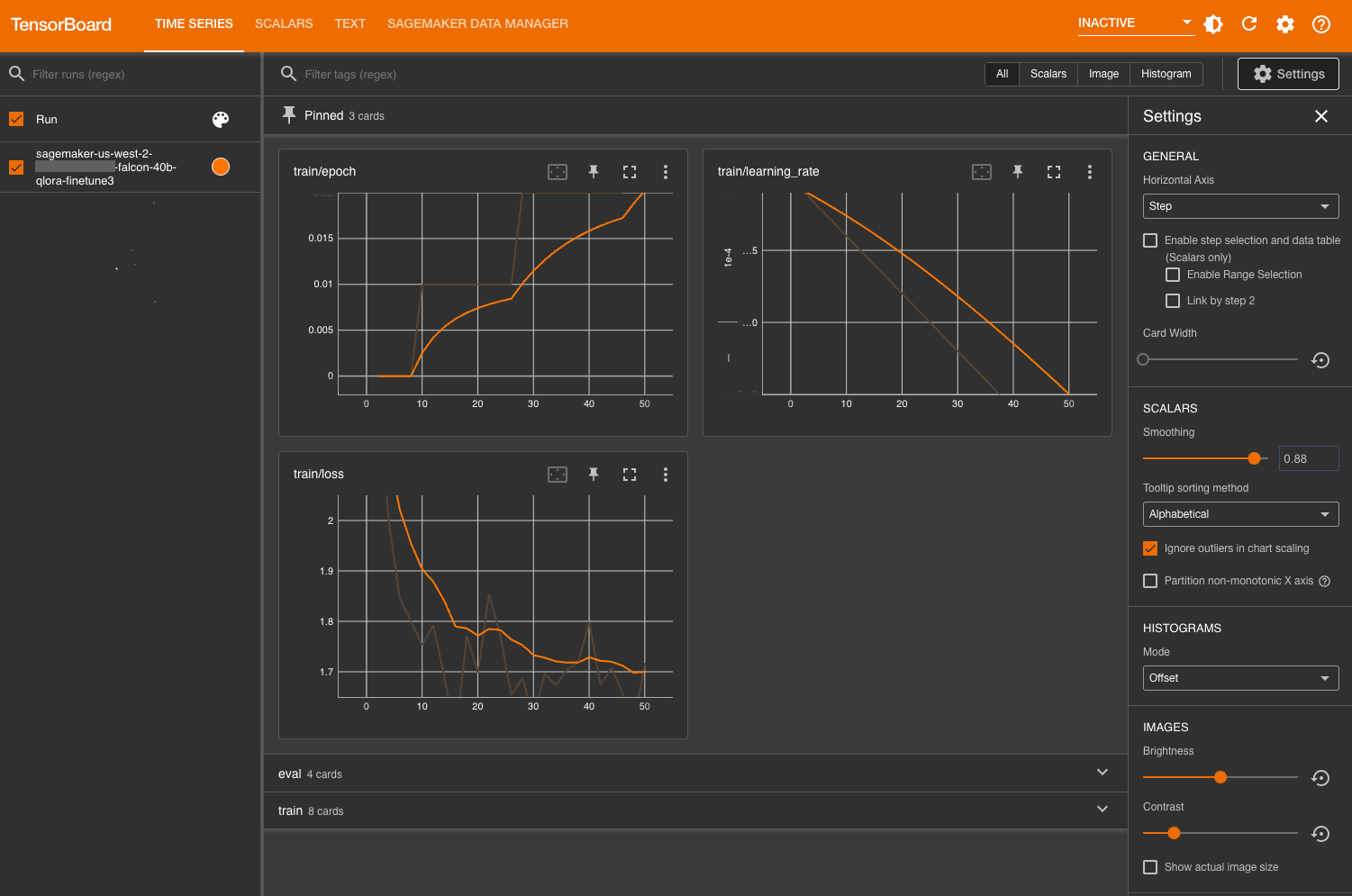
ماڈل کا اندازہ لگائیں۔
ہمارے ماڈل کی تربیت مکمل ہونے کے بعد، ہم منظم تشخیص چلا سکتے ہیں یا صرف جوابات پیدا کر سکتے ہیں:
ماڈل کی کارکردگی سے مطمئن ہونے کے بعد، آپ ماڈل کو محفوظ کر سکتے ہیں:
آپ بھی منتخب کرسکتے ہیں اس کی میزبانی ایک سرشار سیج میکر اینڈ پوائنٹ میں کریں۔.
صاف کرو
اپنے وسائل کو صاف کرنے کے لیے درج ذیل اقدامات کو مکمل کریں:
- سیج میکر اسٹوڈیو مثالوں کو بند کریں۔ اضافی اخراجات سے بچنے کے لیے۔
- اپنی TensorBoard ایپلیکیشن کو بند کریں۔.
- ہگنگ فیس کیش ڈائرکٹری کو صاف کرکے اپنی EFS ڈائرکٹری کو صاف کریں:
نتیجہ
SageMaker نوٹ بک آپ کو ایک انٹرایکٹو ماحول میں تیز اور موثر انداز میں LLMs کو ٹھیک کرنے کی اجازت دیتی ہے۔ اس پوسٹ میں، ہم نے دکھایا کہ کس طرح آپ SageMaker اسٹوڈیو نوٹ بک پر QLoRA کا استعمال کرتے ہوئے Falcon-40B ماڈلز کو ٹھیک کرنے کے لیے bitsandbtyes کے ساتھ Hugging Face PEFT کا استعمال کر سکتے ہیں۔ اسے آزمائیں، اور ہمیں تبصرے کے سیکشن میں اپنے خیالات سے آگاہ کریں!
ہم آپ کو ایمیزون کی تخلیقی AI صلاحیتوں کے بارے میں مزید جاننے کے لیے بھی دریافت کرتے ہیں۔ سیج میکر جمپ اسٹارٹ, ایمیزون ٹائٹن ماڈلز، اور ایمیزون بیڈرک.
مصنفین کے بارے میں
 شان مورگن AWS میں ایک سینئر ML Solutions آرکیٹیکٹ ہیں۔ اس کے پاس سیمی کنڈکٹر اور تعلیمی تحقیقی شعبوں میں تجربہ ہے، اور وہ اپنے تجربے کا استعمال صارفین کو AWS پر اپنے مقاصد تک پہنچنے میں مدد کرنے کے لیے کرتا ہے۔ اپنے فارغ وقت میں، شان ایک فعال اوپن سورس شراکت دار اور دیکھ بھال کرنے والا ہے، اور TensorFlow Addons کے لیے خصوصی دلچسپی والے گروپ کی قیادت ہے۔
شان مورگن AWS میں ایک سینئر ML Solutions آرکیٹیکٹ ہیں۔ اس کے پاس سیمی کنڈکٹر اور تعلیمی تحقیقی شعبوں میں تجربہ ہے، اور وہ اپنے تجربے کا استعمال صارفین کو AWS پر اپنے مقاصد تک پہنچنے میں مدد کرنے کے لیے کرتا ہے۔ اپنے فارغ وقت میں، شان ایک فعال اوپن سورس شراکت دار اور دیکھ بھال کرنے والا ہے، اور TensorFlow Addons کے لیے خصوصی دلچسپی والے گروپ کی قیادت ہے۔
 لارین مولینیکس AWS میں ایک سینئر AI/ML ماہر حل آرکیٹیکٹ ہے۔ اسے DevOps، انفراسٹرکچر، اور ML میں ایک دہائی کا تجربہ ہے۔ وہ کمپیوٹر ویژن پر ایک کتاب کی مصنفہ بھی ہیں۔ اس کی توجہ کے دیگر شعبوں میں MLOps اور جنریٹیو AI شامل ہیں۔
لارین مولینیکس AWS میں ایک سینئر AI/ML ماہر حل آرکیٹیکٹ ہے۔ اسے DevOps، انفراسٹرکچر، اور ML میں ایک دہائی کا تجربہ ہے۔ وہ کمپیوٹر ویژن پر ایک کتاب کی مصنفہ بھی ہیں۔ اس کی توجہ کے دیگر شعبوں میں MLOps اور جنریٹیو AI شامل ہیں۔
 فلپ شمڈ اوپن سورس اور اوپن سائنس کے ذریعے اچھی مشین لرننگ کو جمہوری بنانے کے مشن کے ساتھ ہیگنگ فیس میں ایک تکنیکی رہنما ہے۔ Philipp جدید ترین اور جنریٹیو AI مشین لرننگ ماڈلز کی تیاری کے بارے میں پرجوش ہے۔ وہ AI اور NLP پر اپنے علم کو مختلف میٹنگز جیسے کہ AWS پر ڈیٹا سائنس، اور اپنی تکنیکی پر شیئر کرنا پسند کرتا ہے۔ کے بلاگ.
فلپ شمڈ اوپن سورس اور اوپن سائنس کے ذریعے اچھی مشین لرننگ کو جمہوری بنانے کے مشن کے ساتھ ہیگنگ فیس میں ایک تکنیکی رہنما ہے۔ Philipp جدید ترین اور جنریٹیو AI مشین لرننگ ماڈلز کی تیاری کے بارے میں پرجوش ہے۔ وہ AI اور NLP پر اپنے علم کو مختلف میٹنگز جیسے کہ AWS پر ڈیٹا سائنس، اور اپنی تکنیکی پر شیئر کرنا پسند کرتا ہے۔ کے بلاگ.
- SEO سے چلنے والا مواد اور PR کی تقسیم۔ آج ہی بڑھا دیں۔
- پلیٹو ڈیٹا ڈاٹ نیٹ ورک ورٹیکل جنریٹو اے آئی۔ اپنے آپ کو بااختیار بنائیں۔ یہاں تک رسائی حاصل کریں۔
- پلیٹوآئ اسٹریم۔ ویب 3 انٹیلی جنس۔ علم میں اضافہ۔ یہاں تک رسائی حاصل کریں۔
- پلیٹو ای ایس جی۔ آٹوموٹو / ای وی، کاربن، کلین ٹیک، توانائی ، ماحولیات، شمسی، ویسٹ مینجمنٹ یہاں تک رسائی حاصل کریں۔
- بلاک آفسیٹس۔ ماحولیاتی آفسیٹ ملکیت کو جدید بنانا۔ یہاں تک رسائی حاصل کریں۔
- ماخذ: https://aws.amazon.com/blogs/machine-learning/interactively-fine-tune-falcon-40b-and-other-llms-on-amazon-sagemaker-studio-notebooks-using-qlora/

