آج، NFL کی طرف سے فراہم کردہ اعدادوشمار کی تعداد میں اضافہ کرنے کے لیے اپنا سفر جاری رکھے ہوئے ہے۔ نیکسٹ جنرل سٹیٹس پلیٹ فارم تمام 32 ٹیموں اور شائقین کو یکساں۔ مشین لرننگ (ML) سے اخذ کردہ جدید تجزیات کے ساتھ، NFL فٹ بال کی مقدار درست کرنے اور شائقین کو فٹ بال کے بارے میں ان کے علم کو بڑھانے کے لیے درکار ٹولز فراہم کرنے کے لیے نئے طریقے تیار کر رہا ہے۔ کھیل کے اندر کھیل فٹ بال کے. 2022 کے سیزن کے لیے، NFL کا مقصد پلیئر ٹریکنگ ڈیٹا اور نئی جدید تجزیاتی تکنیکوں سے فائدہ اٹھانا ہے۔ خصوصی ٹیموں کو بہتر طور پر سمجھنے کے لیے.
اس منصوبے کا مقصد یہ پیشین گوئی کرنا تھا کہ واپس آنے والے کو پنٹ یا کِک آف پلے پر کتنے گز کا فائدہ ہوگا۔ پنٹ اور کِک آف ریٹرن کے لیے پیشین گوئی کرنے والے ماڈلز بناتے وقت ایک چیلنج بہت ہی نایاب واقعات کی دستیابی ہے — جیسے ٹچ ڈاؤن — جو گیم کی حرکیات میں اہم اہمیت رکھتے ہیں۔ حقیقی دنیا کی ایپلی کیشنز میں چربی کی دم کے ساتھ ڈیٹا کی تقسیم عام ہے، جہاں نادر واقعات ماڈلز کی مجموعی کارکردگی پر نمایاں اثر ڈالتے ہیں۔ انتہائی واقعات پر تقسیم کو درست طریقے سے ماڈل بنانے کے لیے ایک مضبوط طریقہ کا استعمال بہتر مجموعی کارکردگی کے لیے بہت ضروری ہے۔
اس پوسٹ میں، ہم دکھاتے ہیں کہ GluonTS میں لاگو کردہ Spliced Binned-Pareto ڈسٹری بیوشن کو کس طرح استعمال کیا جائے تاکہ اس طرح کی چربی والی ڈسٹری بیوشن کو مضبوطی سے ماڈل بنایا جائے۔
ہم پہلے استعمال شدہ ڈیٹا سیٹ کی وضاحت کرتے ہیں۔ اگلا، ہم ڈیٹا سیٹ پر لاگو ڈیٹا پری پروسیسنگ اور دیگر تبدیلی کے طریقے پیش کرتے ہیں۔ اس کے بعد ہم ML طریقہ کار اور ماڈل ٹریننگ کے طریقہ کار کی تفصیلات بیان کرتے ہیں۔ آخر میں، ہم ماڈل کی کارکردگی کے نتائج پیش کرتے ہیں۔
ڈیٹا بیس
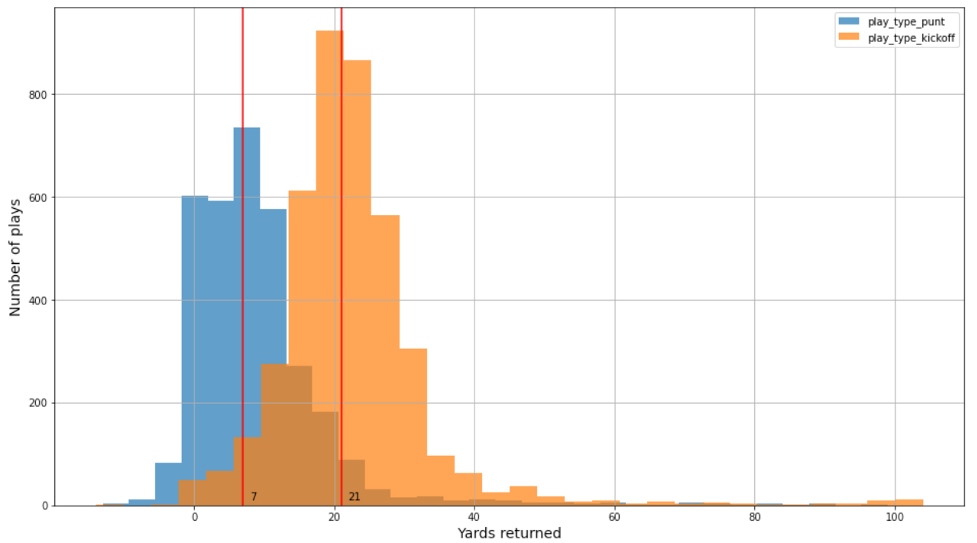
اس پوسٹ میں، ہم نے پنٹ اور کِک آف ریٹرن کے لیے الگ الگ ماڈل بنانے کے لیے دو ڈیٹا سیٹس کا استعمال کیا۔ پلیئر ٹریکنگ ڈیٹا میں کھلاڑی کی پوزیشن، سمت، سرعت اور بہت کچھ شامل ہوتا ہے (x,y کوآرڈینیٹ میں)۔ پنٹ اور کِک آف ڈراموں کے لیے بالترتیب چار NFL سیزن (3,000–4,000) کے لگ بھگ 2018 اور 2021 ڈرامے ہیں۔ اس کے علاوہ، ڈیٹا سیٹس میں بہت کم پنٹ اور کِک آف سے متعلق ٹچ ڈاؤنز ہیں—بالترتیب صرف 0.23% اور 0.8%۔ پنٹ اور کِک آف کے لیے ڈیٹا کی تقسیم مختلف ہے۔ مثال کے طور پر، کِک آف اور پنٹس کے لیے یارڈج کی حقیقی تقسیم یکساں ہے لیکن منتقل کی گئی ہے، جیسا کہ درج ذیل تصویر میں دکھایا گیا ہے۔
ڈیٹا پری پروسیسنگ اور فیچر انجینئرنگ
سب سے پہلے، ٹریکنگ ڈیٹا کو صرف پنٹس اور کِک آف ریٹرن سے متعلق ڈیٹا کے لیے فلٹر کیا گیا تھا۔ پلیئر ڈیٹا کو ماڈل ڈیولپمنٹ کی خصوصیات حاصل کرنے کے لیے استعمال کیا گیا تھا:
- X - میدان کے لمبے محور کے ساتھ کھلاڑی کی پوزیشن
- Y - فیلڈ کے مختصر محور کے ساتھ کھلاڑی کی پوزیشن
- S - گز/سیکنڈ میں رفتار؛ اسے مزید درست بنانے کے لیے Dis*10 سے تبدیل کیا گیا (Dis پچھلے 0.1 سیکنڈ میں فاصلہ ہے)
- دیر - پلیئر موشن کا زاویہ (ڈگری)
پچھلے اعداد و شمار سے، ہر کھیل کو 10 جارحانہ کھلاڑیوں (بال کیریئر کو چھوڑ کر)، 11 محافظوں، اور 14 اخذ کردہ خصوصیات کے ساتھ ڈیٹا کے 10X11X14 میں تبدیل کیا گیا تھا:
- sX - ایک کھلاڑی کی ایکس رفتار
- sY - ایک کھلاڑی کی رفتار
- s - ایک کھلاڑی کی رفتار
- aX - ایک کھلاڑی کی ایکس ایکسلریشن
- aY - ایک کھلاڑی کا ایکسلریشن
- relX - بال کیریئر کے مقابلے میں کھلاڑی کا x فاصلہ
- relY - بال کیریئر کے مقابلے میں کھلاڑی کا y فاصلہ
- relSx - بال کیریئر کے مقابلے میں کھلاڑی کی ایکس رفتار
- relSy - بال کیریئر کے مقابلے میں کھلاڑی کی y رفتار
- relDist - بال کیریئر کے مقابلہ میں کھلاڑی کا یوکلیڈین فاصلہ
- oppX - دفاعی کھلاڑی کے مقابلے میں مجرم کھلاڑی کا x فاصلہ
- oppY - دفاعی کھلاڑی کے مقابلہ میں مجرم کھلاڑی کا y فاصلہ
- oppSx - دفاعی کھلاڑی کے مقابلے میں مجرم کھلاڑی کی ایکس رفتار
- oppSy - دفاعی کھلاڑی کے مقابلہ میں مجرم کھلاڑی کی رفتار
اعداد و شمار کو بڑھانے اور دائیں اور بائیں پوزیشنوں کے حساب سے، X اور Y پوزیشن کی اقدار کو بھی دائیں اور بائیں فیلڈ پوزیشنوں کے حساب سے منعکس کیا گیا تھا۔ ڈیٹا پری پروسیسنگ اور فیچر انجینئرنگ کو جیتنے والے سے اخذ کیا گیا تھا۔ NFL بگ ڈیٹا باؤل Kaggle پر مقابلہ.
ایم ایل طریقہ کار اور ماڈل ٹریننگ
چونکہ ہم ڈرامے کے تمام ممکنہ نتائج میں دلچسپی رکھتے ہیں، بشمول ٹچ ڈاون کا امکان، ہم محض رجعت کے مسئلے کے طور پر حاصل کردہ اوسط گز کی پیش گوئی نہیں کر سکتے۔ ہمیں یارڈ کے تمام ممکنہ فوائد کی مکمل امکانی تقسیم کی پیشین گوئی کرنے کی ضرورت ہے، اس لیے ہم نے اس مسئلے کو ممکنہ پیشین گوئی کے طور پر تیار کیا۔
امکانی پیشین گوئیوں کو لاگو کرنے کا ایک طریقہ یہ ہے کہ حاصل کردہ گز کو کئی ڈبوں میں تفویض کیا جائے (جیسے 0 سے کم، 0–1 سے، 1–2 سے، …، 14–15 سے، 15 سے زیادہ) اور بِن کی درجہ بندی کے طور پر پیش گوئی کریں۔ مسئلہ اس نقطہ نظر کا منفی پہلو یہ ہے کہ ہم چاہتے ہیں کہ چھوٹے ڈبوں میں تقسیم کی ایک ہائی ڈیفینیشن تصویر ہو، لیکن چھوٹے ڈبوں کا مطلب ہے کم ڈیٹا پوائنٹس فی بِن اور ہماری تقسیم، خاص طور پر دم، کا تخمینہ ناقص اور بے قاعدہ ہو سکتا ہے۔
امکانی پیشین گوئیوں کو لاگو کرنے کا ایک اور طریقہ یہ ہے کہ آؤٹ پٹ کو محدود تعداد میں پیرامیٹرز (مثال کے طور پر گاوسی یا گاما ڈسٹری بیوشن) کے ساتھ ایک مسلسل امکانی تقسیم کے طور پر ماڈل بنایا جائے اور پیرامیٹرز کی پیشن گوئی کی جائے۔ یہ نقطہ نظر تقسیم کی ایک بہت ہی اعلیٰ تعریف اور باقاعدہ تصویر پیش کرتا ہے، لیکن حاصل شدہ گز کی حقیقی تقسیم کے لیے بہت سخت ہے، جو کثیر موڈل اور بھاری دم والا ہے۔
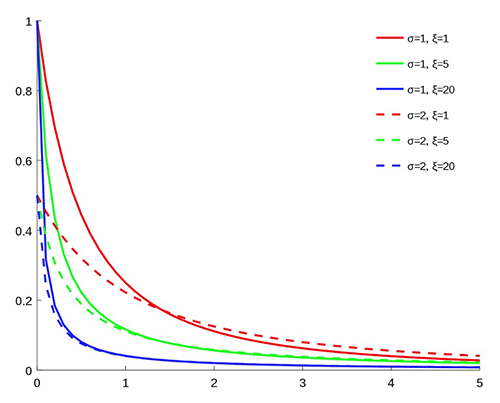
دونوں طریقوں سے بہترین حاصل کرنے کے لیے، ہم استعمال کرتے ہیں۔ کٹے ہوئے بنڈ-پیریٹو کی تقسیم (SBP)، جس میں تقسیم کے مرکز کے لیے ڈبے ہوتے ہیں جہاں بہت سا ڈیٹا دستیاب ہوتا ہے، اور پیریٹو کی عام تقسیم (GPD) دونوں سروں پر، جہاں نایاب لیکن اہم واقعات رونما ہو سکتے ہیں، جیسے ٹچ ڈاؤن۔ GPD کے دو پیرامیٹرز ہیں: ایک پیمانے کے لیے اور دوسرا دم کے بھاری پن کے لیے، جیسا کہ درج ذیل گراف میں دیکھا گیا ہے (ماخذ: ویکیپیڈیا)۔
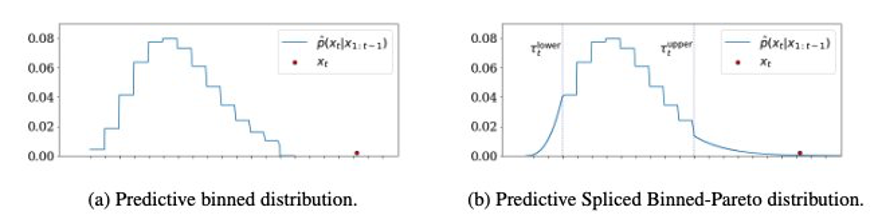
GPD کو بائنڈ ڈسٹری بیوشن (مندرجہ ذیل بائیں گراف کو دیکھیں) کے ساتھ دونوں اطراف میں تقسیم کرنے سے، ہم دائیں جانب درج ذیل SBP حاصل کرتے ہیں۔ نچلی اور اوپری دہلیز جہاں سپلیسنگ کی جاتی ہے وہ ہائپر پیرامیٹر ہیں۔
ایک بیس لائن کے طور پر، ہم نے وہ ماڈل استعمال کیا جس نے ہمارا جیتا تھا۔ NFL بگ ڈیٹا باؤل Kaggle پر مقابلہ. یہ ماڈل تیار کردہ ڈیٹا سے خصوصیات نکالنے کے لیے CNN تہوں کا استعمال کرتا ہے، اور "1 یارڈ فی بن" درجہ بندی کے مسئلے کے طور پر نتائج کی پیشین گوئی کرتا ہے۔ اپنے ماڈل کے لیے، ہم نے فیچر نکالنے کی تہوں کو بیس لائن سے رکھا اور ہر ڈبے کے لیے امکانات کے بجائے صرف آخری پرت کو آؤٹ پٹ کرنے کے لیے ایس بی پی کے پیرامیٹرز میں ترمیم کی، جیسا کہ مندرجہ ذیل تصویر میں دکھایا گیا ہے (پوسٹ سے تصویر میں ترمیم کی گئی پہلی جگہ حل چڑیا گھر).

ہم نے فراہم کردہ SBP کی تقسیم کا استعمال کیا۔ گلوون ٹی ایس. GluonTS ممکنہ ٹائم سیریز ماڈلنگ کے لیے ایک Python پیکج ہے، لیکن SBP کی تقسیم ٹائم سیریز کے لیے مخصوص نہیں ہے، اور ہم اسے رجعت کے لیے دوبارہ استعمال کرنے کے قابل تھے۔ GluonTS SBP استعمال کرنے کے طریقے کے بارے میں مزید معلومات کے لیے، درج ذیل ڈیمو دیکھیں نوٹ بک.
ماڈلز کو 2018، 2019 اور 2020 کے سیزن میں تربیت دی گئی اور ان کی تصدیق کی گئی اور 2021 کے سیزن میں ان کا تجربہ کیا گیا۔ کراس توثیق کے دوران لیکیج سے بچنے کے لیے، ہم نے ایک ہی گیم کے تمام ڈراموں کو ایک ہی فولڈ میں گروپ کیا۔
تشخیص کے لیے، ہم نے Kaggle مقابلے میں استعمال ہونے والے میٹرک کو رکھا، مسلسل درجہ بندی امکانی سکور (CRPS)، جسے لاگ ان امکان کے متبادل کے طور پر دیکھا جا سکتا ہے جو آؤٹ لیرز کے لیے زیادہ مضبوط ہے۔ ہم نے بھی استعمال کیا۔ پیئرسن باہمی ربط کا گتانک اور RMSE عام اور قابل تشریح درستگی میٹرکس کے طور پر۔ مزید برآں، ہم نے انشانکن کا اندازہ کرنے کے لیے ٹچ ڈاؤن کے امکان اور امکانی پلاٹوں کو دیکھا۔
ماڈل کو استعمال کرتے ہوئے CRPS نقصان پر تربیت دی گئی تھی۔ اسٹاکسٹک وزن کا اوسط اور جلدی روکنا.
آؤٹ پٹ ڈسٹری بیوشن کے بائنڈ حصے کی بے قاعدگی سے نمٹنے کے لیے، ہم نے دو تکنیکوں کا استعمال کیا:
- دو لگاتار ڈبوں کے درمیان مربع فرق کے متناسب ہموار پنالٹی
- کراس توثیق کے دوران تربیت یافتہ ماڈلز کو جوڑنا
ماڈل کی کارکردگی کے نتائج
ہر ڈیٹاسیٹ کے لیے، ہم نے درج ذیل اختیارات پر گرڈ تلاش کی:
- امکانی ماڈلز
- بیس لائن فی گز ایک امکان تھا۔
- SBP مرکز میں فی گز ایک امکان تھا، دم میں SBP کو عام کیا گیا۔
- تقسیم کو ہموار کرنا
- کوئی ہموار نہیں (ہموار پنالٹی = 0)
- ہموار پنالٹی = 5
- ہموار پنالٹی = 10
- تربیت اور تخمینہ کا طریقہ کار
- 10 فولڈ کراس توثیق اور جوڑ کا اندازہ (k10)
- 10 عہدوں یا 20 دوروں کے لیے ٹرین اور توثیق کے ڈیٹا پر تربیت
پھر ہم نے CRPS کے لحاظ سے ترتیب دیئے گئے ٹاپ پانچ ماڈلز کے میٹرکس کو دیکھا (کم بہتر ہے)۔
کِک آف ڈیٹا کے لیے، SBP ماڈل CRPS کے لحاظ سے قدرے زیادہ کارکردگی کا مظاہرہ کرتا ہے لیکن اس سے بھی اہم بات یہ ہے کہ یہ ٹچ ڈاؤن امکان کا بہتر اندازہ لگاتا ہے (ٹیسٹ سیٹ میں حقیقی امکان 0.80% ہے)۔ ہم دیکھتے ہیں کہ بہترین ماڈلز 10 فولڈ ensembling (k10) کا استعمال کرتے ہیں اور کوئی نرمی جرمانہ نہیں، جیسا کہ درج ذیل جدول میں دکھایا گیا ہے۔
| ٹریننگ | ماڈل | ہمواری | سی آر پی ایس۔ | RMSE | CORR % | P(ٹچ ڈاؤن)% |
| k10 | ایس بی پی | 0 | 4.071 | 9.641 | 47.15 | 0.78 |
| k10 | بیس لائن | 0 | 4.074 | 9.62 | 47.585 | 0.306 |
| k10 | بیس لائن | 5 | 4.075 | 9.626 | 47.43 | 0.274 |
| k10 | ایس بی پی | 5 | 4.079 | 9.656 | 46.977 | 0.682 |
| k10 | بیس لائن | 10 | 4.08 | 9.621 | 47.519 | 0.265 |
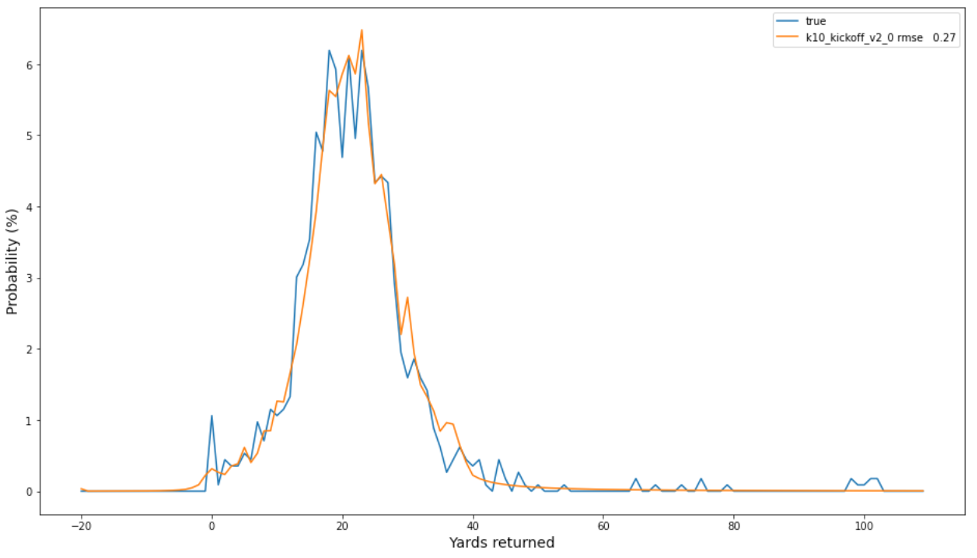
مشاہدہ شدہ تعدد اور پیش گوئی شدہ امکانات کا مندرجہ ذیل پلاٹ ہمارے بہترین ماڈل کی اچھی انشانکن کی نشاندہی کرتا ہے، جس میں دونوں تقسیموں کے درمیان 0.27 کا RMSE ہے۔ ہائی یارڈج (مثال کے طور پر، 100) کے واقعات کو نوٹ کریں جو حقیقی (نیلے) تجرباتی تقسیم کے دم میں واقع ہوتے ہیں، جن کے امکانات بنیادی طریقہ کے مقابلے میں SBP کے ذریعہ زیادہ قابل گرفت ہیں۔
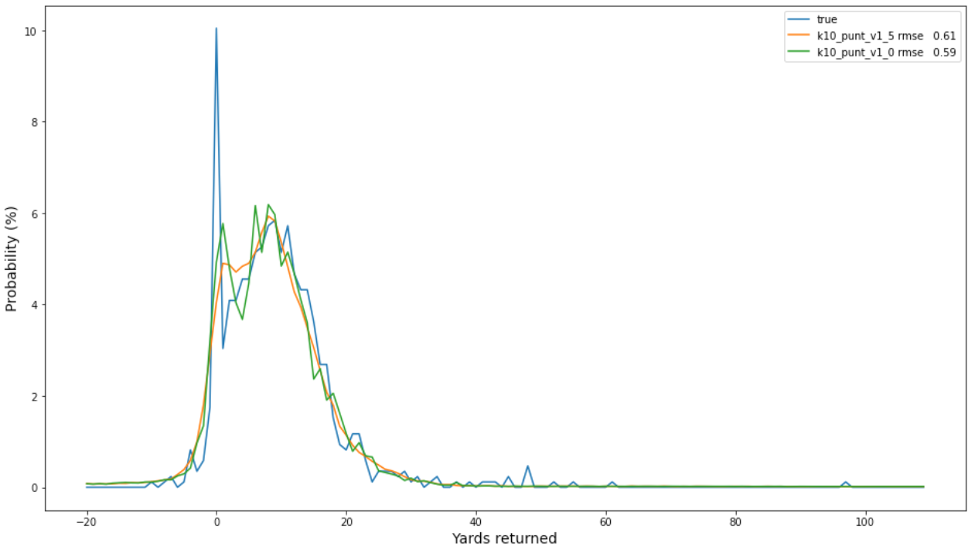
پنٹ ڈیٹا کے لیے، بیس لائن ایس بی پی سے بہتر کارکردگی کا مظاہرہ کرتی ہے، شاید اس لیے کہ انتہائی یارڈج کی دُموں میں کم احساس ہوتا ہے۔ اس لیے، 0-10 گز کی چوٹیوں کے درمیان موڈالٹی کو پکڑنا بہتر تجارت ہے۔ اور کِک آف ڈیٹا کے برعکس، بہترین ماڈل ہموار پنالٹی کا استعمال کرتا ہے۔ مندرجہ ذیل جدول ہمارے نتائج کا خلاصہ کرتا ہے۔
| ٹریننگ | ماڈل | ہمواری | سی آر پی ایس۔ | RMSE | CORR % | P(ٹچ ڈاؤن)% |
| k10 | بیس لائن | 5 | 3.961 | 8.313 | 35.227 | 0.547 |
| k10 | بیس لائن | 0 | 3.972 | 8.346 | 34.227 | 0.579 |
| k10 | بیس لائن | 10 | 3.978 | 8.351 | 34.079 | 0.555 |
| k10 | ایس بی پی | 5 | 3.981 | 8.342 | 34.971 | 0.723 |
| k10 | ایس بی پی | 0 | 3.991 | 8.378 | 33.437 | 0.677 |
مشاہدہ شدہ تعدد (نیلے رنگ میں) اور دو بہترین پنٹ ماڈلز کے لیے پیش گوئی شدہ امکانات کا درج ذیل پلاٹ اس بات کی نشاندہی کرتا ہے کہ غیر ہموار ماڈل (نارنجی رنگ میں) ہموار ماڈل (سبز رنگ میں) سے قدرے بہتر کیلیبریٹ کیا گیا ہے اور مجموعی طور پر ایک بہتر انتخاب ہو سکتا ہے۔
نتیجہ
اس پوسٹ میں، ہم نے دکھایا کہ موٹی پونچھ والے ڈیٹا کی تقسیم کے ساتھ پیشین گوئی کرنے والے ماڈل کیسے بنائے جائیں۔ ہم نے GluonTS میں لاگو کردہ Spliced Binned-Pareto ڈسٹری بیوشن کا استعمال کیا، جو اس طرح کی چربی والی تقسیم کو مضبوطی سے ماڈل بنا سکتا ہے۔ ہم نے اس تکنیک کو پنٹ اور کِک آف ریٹرن کے لیے ماڈل بنانے کے لیے استعمال کیا۔ ہم اس حل کو اسی طرح کے استعمال کے معاملات میں لاگو کر سکتے ہیں جہاں ڈیٹا میں بہت کم واقعات ہوتے ہیں، لیکن ان واقعات کا ماڈلز کی مجموعی کارکردگی پر نمایاں اثر پڑتا ہے۔
اگر آپ اپنی مصنوعات اور خدمات میں ایم ایل کے استعمال کو تیز کرنے میں مدد چاہتے ہیں، تو براہ کرم رابطہ کریں۔ ایمیزون ایم ایل حل لیب پروگرام.
مصنفین کے بارے میں
 تصفغبیر مہریزی ۔ میں ڈیٹا سائنٹسٹ ہے۔ ایمیزون ایم ایل حل لیب جہاں وہ صحت کی دیکھ بھال اور لائف سائنسز، مینوفیکچرنگ، آٹوموٹیو، اور کھیلوں اور میڈیا جیسی مختلف صنعتوں میں AWS صارفین کی مدد کرتا ہے، ان کے کاروباری چیلنجوں کو حل کرنے کے لیے مشین لرننگ اور AWS کلاؤڈ سروسز کے استعمال کو تیز کرتا ہے۔
تصفغبیر مہریزی ۔ میں ڈیٹا سائنٹسٹ ہے۔ ایمیزون ایم ایل حل لیب جہاں وہ صحت کی دیکھ بھال اور لائف سائنسز، مینوفیکچرنگ، آٹوموٹیو، اور کھیلوں اور میڈیا جیسی مختلف صنعتوں میں AWS صارفین کی مدد کرتا ہے، ان کے کاروباری چیلنجوں کو حل کرنے کے لیے مشین لرننگ اور AWS کلاؤڈ سروسز کے استعمال کو تیز کرتا ہے۔
 مارک وین اوڈیوسڈن Amazon Web Services میں Amazon ML Solutions Lab ٹیم کے ساتھ ایک سینئر ڈیٹا سائنٹسٹ ہے۔ وہ مصنوعی ذہانت اور مشین لرننگ کے ساتھ کاروباری مسائل حل کرنے کے لیے AWS صارفین کے ساتھ کام کرتا ہے۔ کام سے باہر آپ اسے ساحل سمندر پر، اپنے بچوں کے ساتھ کھیلتے، سرفنگ یا پتنگ سرفنگ کرتے ہوئے پا سکتے ہیں۔
مارک وین اوڈیوسڈن Amazon Web Services میں Amazon ML Solutions Lab ٹیم کے ساتھ ایک سینئر ڈیٹا سائنٹسٹ ہے۔ وہ مصنوعی ذہانت اور مشین لرننگ کے ساتھ کاروباری مسائل حل کرنے کے لیے AWS صارفین کے ساتھ کام کرتا ہے۔ کام سے باہر آپ اسے ساحل سمندر پر، اپنے بچوں کے ساتھ کھیلتے، سرفنگ یا پتنگ سرفنگ کرتے ہوئے پا سکتے ہیں۔
 پانپن سو AWS میں Amazon ML Solutions Lab کے ساتھ ایک سینئر اپلائیڈ سائنٹسٹ اور مینیجر ہیں۔ وہ مشین لرننگ الگورتھم کی تحقیق اور ترقی پر کام کر رہی ہے تاکہ ان کے AI اور کلاؤڈ کو اپنانے کو تیز کرنے کے لیے صنعتی عمودی کی ایک قسم میں اعلیٰ اثر والے کسٹمر ایپلی کیشنز کے لیے۔ اس کی تحقیقی دلچسپی میں ماڈل کی تشریح، وجہ تجزیہ، ہیومن ان دی لوپ AI اور انٹرایکٹو ڈیٹا ویژولائزیشن شامل ہے۔
پانپن سو AWS میں Amazon ML Solutions Lab کے ساتھ ایک سینئر اپلائیڈ سائنٹسٹ اور مینیجر ہیں۔ وہ مشین لرننگ الگورتھم کی تحقیق اور ترقی پر کام کر رہی ہے تاکہ ان کے AI اور کلاؤڈ کو اپنانے کو تیز کرنے کے لیے صنعتی عمودی کی ایک قسم میں اعلیٰ اثر والے کسٹمر ایپلی کیشنز کے لیے۔ اس کی تحقیقی دلچسپی میں ماڈل کی تشریح، وجہ تجزیہ، ہیومن ان دی لوپ AI اور انٹرایکٹو ڈیٹا ویژولائزیشن شامل ہے۔
 کیونگ ہون (جوناتھن) جنگ نیشنل فٹ بال لیگ میں ایک سینئر سافٹ ویئر انجینئر ہے۔ وہ پچھلے سات سالوں سے نیکسٹ جنرل سٹیٹس ٹیم کے ساتھ رہا ہے جس نے خام ڈیٹا کو سٹریم کرنے، ڈیٹا پر کارروائی کرنے کے لیے مائیکرو سروسز بنانے، پراسیس شدہ ڈیٹا کو بے نقاب کرنے والے API کی تعمیر تک پلیٹ فارم بنانے میں مدد کی۔ اس نے ایمیزون مشین لرننگ سلوشنز لیب کے ساتھ کام کرنے کے لیے صاف ڈیٹا فراہم کرنے کے ساتھ ساتھ ڈیٹا کے بارے میں ڈومین کی معلومات فراہم کرنے میں تعاون کیا ہے۔ کام سے باہر، وہ لاس اینجلس میں سائیکلنگ اور سیراس میں پیدل سفر سے لطف اندوز ہوتا ہے۔
کیونگ ہون (جوناتھن) جنگ نیشنل فٹ بال لیگ میں ایک سینئر سافٹ ویئر انجینئر ہے۔ وہ پچھلے سات سالوں سے نیکسٹ جنرل سٹیٹس ٹیم کے ساتھ رہا ہے جس نے خام ڈیٹا کو سٹریم کرنے، ڈیٹا پر کارروائی کرنے کے لیے مائیکرو سروسز بنانے، پراسیس شدہ ڈیٹا کو بے نقاب کرنے والے API کی تعمیر تک پلیٹ فارم بنانے میں مدد کی۔ اس نے ایمیزون مشین لرننگ سلوشنز لیب کے ساتھ کام کرنے کے لیے صاف ڈیٹا فراہم کرنے کے ساتھ ساتھ ڈیٹا کے بارے میں ڈومین کی معلومات فراہم کرنے میں تعاون کیا ہے۔ کام سے باہر، وہ لاس اینجلس میں سائیکلنگ اور سیراس میں پیدل سفر سے لطف اندوز ہوتا ہے۔
 مائیکل چی نیشنل فٹ بال لیگ میں نیکسٹ جنرل سٹیٹس اور ڈیٹا انجینئرنگ کی نگرانی کرنے والے ٹیکنالوجی کے سینئر ڈائریکٹر ہیں۔ انہوں نے Urbana Champaign میں یونیورسٹی آف الینوائے سے ریاضی اور کمپیوٹر سائنس میں ڈگری حاصل کی ہے۔ مائیکل نے پہلی بار 2007 میں NFL میں شمولیت اختیار کی اور بنیادی طور پر فٹ بال کے اعدادوشمار کے لیے ٹیکنالوجی اور پلیٹ فارمز پر توجہ مرکوز کی۔ اپنے فارغ وقت میں، وہ اپنے خاندان کے ساتھ باہر وقت گزارنے میں لطف اندوز ہوتا ہے۔
مائیکل چی نیشنل فٹ بال لیگ میں نیکسٹ جنرل سٹیٹس اور ڈیٹا انجینئرنگ کی نگرانی کرنے والے ٹیکنالوجی کے سینئر ڈائریکٹر ہیں۔ انہوں نے Urbana Champaign میں یونیورسٹی آف الینوائے سے ریاضی اور کمپیوٹر سائنس میں ڈگری حاصل کی ہے۔ مائیکل نے پہلی بار 2007 میں NFL میں شمولیت اختیار کی اور بنیادی طور پر فٹ بال کے اعدادوشمار کے لیے ٹیکنالوجی اور پلیٹ فارمز پر توجہ مرکوز کی۔ اپنے فارغ وقت میں، وہ اپنے خاندان کے ساتھ باہر وقت گزارنے میں لطف اندوز ہوتا ہے۔
 مائیک بینڈ نیشنل فٹ بال لیگ میں نیکسٹ جنرل سٹیٹس کے لیے ریسرچ اینڈ اینالیٹکس کے سینئر مینیجر ہیں۔ 2018 میں ٹیم میں شامل ہونے کے بعد سے، وہ شائقین، NFL براڈکاسٹ پارٹنرز، اور 32 کلبوں کے لیے پلیئر ٹریکنگ ڈیٹا سے اخذ کردہ کلیدی اعدادوشمار اور بصیرت کے آئیڈییشن، ڈیولپمنٹ، اور مواصلات کے لیے ذمہ دار ہیں۔ مائیک شکاگو یونیورسٹی سے تجزیات میں ماسٹر ڈگری، فلوریڈا یونیورسٹی سے کھیلوں کے نظم و نسق میں بیچلر کی ڈگری، اور مینیسوٹا وائکنگز کے اسکاؤٹنگ ڈیپارٹمنٹ اور ریکروٹنگ ڈیپارٹمنٹ دونوں میں تجربہ کے ساتھ ٹیم کے لیے علم اور تجربہ کا خزانہ لاتا ہے۔ فلوریڈا گیٹر فٹ بال کا۔
مائیک بینڈ نیشنل فٹ بال لیگ میں نیکسٹ جنرل سٹیٹس کے لیے ریسرچ اینڈ اینالیٹکس کے سینئر مینیجر ہیں۔ 2018 میں ٹیم میں شامل ہونے کے بعد سے، وہ شائقین، NFL براڈکاسٹ پارٹنرز، اور 32 کلبوں کے لیے پلیئر ٹریکنگ ڈیٹا سے اخذ کردہ کلیدی اعدادوشمار اور بصیرت کے آئیڈییشن، ڈیولپمنٹ، اور مواصلات کے لیے ذمہ دار ہیں۔ مائیک شکاگو یونیورسٹی سے تجزیات میں ماسٹر ڈگری، فلوریڈا یونیورسٹی سے کھیلوں کے نظم و نسق میں بیچلر کی ڈگری، اور مینیسوٹا وائکنگز کے اسکاؤٹنگ ڈیپارٹمنٹ اور ریکروٹنگ ڈیپارٹمنٹ دونوں میں تجربہ کے ساتھ ٹیم کے لیے علم اور تجربہ کا خزانہ لاتا ہے۔ فلوریڈا گیٹر فٹ بال کا۔
- SEO سے چلنے والا مواد اور PR کی تقسیم۔ آج ہی بڑھا دیں۔
- پلیٹو بلاک چین۔ Web3 Metaverse Intelligence. علم میں اضافہ۔ یہاں تک رسائی حاصل کریں۔
- ماخذ: https://aws.amazon.com/blogs/machine-learning/predict-football-punt-and-kickoff-return-yards-with-fat-tailed-distribution-using-gluonts/

