یہ پوسٹ KakaoGames Data Analytics Lab کے جنرل مینیجر Suhyoung Kim کے ساتھ مل کر لکھی گئی ہے۔
سے kakao گیمز ایک اعلی ویڈیو گیم پبلشر اور ڈویلپر ہے جس کا صدر دفتر جنوبی کوریا میں ہے۔ یہ پی سی، موبائل، اور ورچوئل رئیلٹی (VR) پر گیمز تیار کرنے اور شائع کرنے میں مہارت رکھتا ہے جو عالمی سطح پر پیش کرتا ہے۔ اپنے کھلاڑیوں کے تجربے کو زیادہ سے زیادہ بڑھانے اور آپریشنز اور مارکیٹنگ کی کارکردگی کو بہتر بنانے کے لیے، وہ مسلسل نئے گیم آئٹمز شامل کر رہے ہیں اور اپنے کھلاڑیوں کو پروموشنز فراہم کر رہے ہیں۔ ان واقعات کے نتیجے کا اندازہ بعد میں کیا جا سکتا ہے تاکہ وہ مستقبل میں بہتر فیصلے کر سکیں۔
تاہم، یہ نقطہ نظر رد عمل ہے. اگر ہم لائف ٹائم ویلیو (LTV) کی پیشن گوئی کر سکتے ہیں، تو ہم ایک فعال طریقہ اختیار کر سکتے ہیں۔ دوسرے لفظوں میں، ان سرگرمیوں کی منصوبہ بندی کی جا سکتی ہے اور پیش گوئی کی گئی LTV کی بنیاد پر چلائی جا سکتی ہے، جو کھیل میں ان کی زندگی بھر کے دوران کھلاڑیوں کی اقدار کا تعین کرتی ہے۔ اس فعال نقطہ نظر کے ساتھ، کاکاو گیمز صحیح وقت پر صحیح ایونٹس شروع کر سکتے ہیں۔ اگر کچھ کھلاڑیوں کے لیے پیش گوئی کی گئی LTV کم ہو رہی ہے، تو اس کا مطلب ہے کہ کھلاڑیوں کے جلد ہی رخصت ہونے کا امکان ہے۔ Kakao گیمز اس کے بعد گیم کو نہ چھوڑنے کے لیے پروموشنل ایونٹ بنا سکتے ہیں۔ اس سے ان کے کھلاڑیوں کے LTV کی درست پیشن گوئی کرنا اہم ہو جاتا ہے۔ LTV وہ پیمائش ہے جسے نہ صرف گیمنگ کمپنیوں نے اپنایا ہے بلکہ صارفین کی طویل مدتی مصروفیت کے ساتھ کسی بھی قسم کی سروس بھی۔ شماریاتی طریقے اور مشین لرننگ (ML) کے طریقے فعال طور پر تیار کیے جاتے ہیں اور LTV کو زیادہ سے زیادہ کرنے کے لیے اپنایا جاتا ہے۔
اس پوسٹ میں، ہم اشتراک کرتے ہیں کہ کس طرح کاکاو گیمز اور ایمیزون مشین لرننگ سلوشنز لیب AWS ڈیٹا اور ML سروسز جیسے کہ استعمال کر کے قابل توسیع اور قابل اعتماد LTV پیشین گوئی حل تیار کرنے کے لیے مل کر AWS گلو اور ایمیزون سیج میکر.
ہم نے کاکاو گیمز کے سب سے مشہور گیمز میں سے ایک کا انتخاب کیا، اوڈین، منصوبے کے لیے ہدف کے کھیل کے طور پر۔ ODIN PC اور موبائل آلات کے لیے ایک مقبول بڑے پیمانے پر ملٹی پلیئر آن لائن رول پلےنگ گیم (MMORPG) ہے جسے Kakao Games کے ذریعے شائع اور چلایا جاتا ہے۔ اسے جون 2021 میں لانچ کیا گیا تھا اور کوریا میں آمدنی میں اسے ٹاپ تھری میں رکھا گیا ہے۔

چیلنجز
اس سیکشن میں، ہم ڈیٹا کے مختلف ذرائع کے ارد گرد چیلنجوں، اندرونی یا بیرونی واقعات کی وجہ سے ڈیٹا کے بڑھنے، اور دوبارہ استعمال کے قابل حل پر تبادلہ خیال کرتے ہیں۔ ان چیلنجوں کا سامنا عام طور پر اس وقت ہوتا ہے جب ہم ML سلوشنز کو نافذ کرتے ہیں اور انہیں پیداواری ماحول میں تعینات کرتے ہیں۔
اندرونی اور بیرونی واقعات سے متاثر کھلاڑی کا رویہ
LTV کی درست پیشن گوئی کرنا مشکل ہے، کیونکہ کھلاڑی کے رویے کو متاثر کرنے والے بہت سے متحرک عوامل ہیں۔ ان میں گیم پروموشنز، نئی شامل کردہ آئٹمز، چھٹیاں، بدسلوکی یا غیر قانونی کھیل کے لیے اکاؤنٹس پر پابندی، یا غیر متوقع بیرونی واقعات جیسے کھیلوں کے واقعات یا شدید موسمی حالات شامل ہیں۔ اس کا مطلب یہ ہے کہ اس ماہ کام کرنے والا ماڈل اگلے مہینے ٹھیک کام نہیں کر سکتا۔
ہم بیرونی ایونٹس کو ML خصوصیات کے ساتھ ساتھ گیم سے متعلقہ لاگز اور ڈیٹا کے طور پر استعمال کر سکتے ہیں۔ مثال کے طور پر، ایمیزون کی پیشن گوئی اندرونی اور بیرونی متعلقہ واقعات کی عکاسی کرنے کے لیے متعلقہ ٹائم سیریز ڈیٹا جیسے موسم، قیمتیں، اقتصادی اشارے، یا پروموشنز کو سپورٹ کرتا ہے۔ ایک اور نقطہ نظر یہ ہے کہ جب ڈیٹا بڑھنے کا مشاہدہ کیا جائے تو ایم ایل ماڈلز کو باقاعدگی سے ریفریش کیا جائے۔ ہمارے حل کے لیے، ہم نے مؤخر الذکر طریقہ کا انتخاب کیا کیونکہ متعلقہ ایونٹ کا ڈیٹا دستیاب نہیں تھا اور ہمیں یقین نہیں تھا کہ موجودہ ڈیٹا کتنا قابل اعتماد ہے۔
حالیہ اعداد و شمار سے دوبارہ سیکھ کر اس چیلنج پر قابو پانے کے لیے مسلسل ML ماڈل کی دوبارہ تربیت ایک طریقہ ہے۔ اس کے لیے نہ صرف اچھی طرح سے ڈیزائن کردہ خصوصیات اور ML فن تعمیر بلکہ ڈیٹا کی تیاری اور ML پائپ لائنوں کی بھی ضرورت ہے جو دوبارہ تربیت کے عمل کو خودکار کر سکیں۔ بصورت دیگر، ML محلول کو پیداواری ماحول میں پیچیدگی اور ناقص ریپیٹ ایبلٹی کی وجہ سے مؤثر طریقے سے نہیں چلایا جا سکتا۔
جدید ترین تربیتی ڈیٹاسیٹ کا استعمال کرتے ہوئے ماڈل کو دوبارہ تربیت دینا کافی نہیں ہے۔ دوبارہ تربیت یافتہ ماڈل موجودہ ماڈل کے مقابلے میں زیادہ درست پیشن گوئی کا نتیجہ نہیں دے سکتا، لہذا ہم بغیر کسی جانچ کے ماڈل کو نئے ماڈل سے تبدیل نہیں کر سکتے۔ اگر نیا ماڈل کسی وجہ سے کم کارکردگی دکھانا شروع کرتا ہے تو ہمیں پچھلے ماڈل پر واپس جانے کے قابل ہونے کی ضرورت ہے۔
اس مسئلے کو حل کرنے کے لیے، ہمیں خام ڈیٹا اور MLOps سے ایم ایل فیچرز بنانے کے لیے ایک مضبوط ڈیٹا پائپ لائن ڈیزائن کرنا تھی۔
متعدد ڈیٹا ذرائع
ODIN ایک MMORPG ہے جہاں گیم پلیئرز ایک دوسرے کے ساتھ بات چیت کرتے ہیں، اور اس میں مختلف ایونٹس ہوتے ہیں جیسے لیول اپ، آئٹم کی خریداری، اور گولڈ (گیم منی) کا شکار۔ یہ دنیا بھر میں اپنے 300 ملین سے زیادہ پلیئرز سے ہر روز تقریباً 10 GB لاگ تیار کرتا ہے۔ گیمنگ لاگز مختلف قسم کے ہوتے ہیں، جیسے پلیئر لاگ ان، پلیئر کی سرگرمی، پلیئر کی خریداری، اور پلیئر لیول اپ۔ اس قسم کے ڈیٹا ML کے نقطہ نظر سے تاریخی خام ڈیٹا ہیں۔ مثال کے طور پر، ہر لاگ ٹائم اسٹیمپ، یوزر آئی ڈی، اور ایونٹ کی معلومات کی شکل میں لکھا جاتا ہے۔ نوشتہ جات کا وقفہ یکساں نہیں ہے۔ اس کے علاوہ، کھلاڑیوں کی عمر اور رجسٹریشن کی تاریخ جیسے جامد ڈیٹا موجود ہے، جو کہ غیر تاریخی ڈیٹا ہے۔ LTV پیشین گوئی ماڈلنگ کے لیے ان دو قسم کے ڈیٹا کو اس کے ان پٹ کے طور پر درکار ہوتا ہے کیونکہ یہ کھلاڑی کی خصوصیات اور رویے کی نمائندگی کرنے کے لیے ایک دوسرے کی تکمیل کرتے ہیں۔
اس حل کے لیے، ہم نے تاریخی خصوصیات کو یکجا کرنے والے ٹیبلولر ڈیٹاسیٹ کی وضاحت کرنے کا فیصلہ کیا ہے جس میں جامد پلیئر کی خصوصیات کے ساتھ مجموعی اقدامات کی مقررہ تعداد شامل ہے۔ مجموعی تاریخی خصوصیات گیم لاگز کی تعداد سے متعدد مراحل کے ذریعے تیار کی جاتی ہیں، جو ایمیزون ایتینا میزیں ML ماڈل کے لیے فیچرز کی وضاحت کرنے کے چیلنج کے علاوہ، فیچر جنریشن کے عمل کو خودکار بنانا بہت ضروری ہے تاکہ ہم ML انفرنس اور ماڈل ری ٹریننگ کے لیے خام ڈیٹا سے ML فیچرز حاصل کر سکیں۔
اس مسئلے کو حل کرنے کے لیے، ہم ایک ایکسٹریکٹ، ٹرانسفارم، اور لوڈ (ETL) پائپ لائن بناتے ہیں جسے ٹریننگ اور انفرنس ڈیٹا سیٹ بنانے کے لیے خود بخود اور بار بار چلایا جا سکتا ہے۔
دوسرے گیمز کے لیے اسکیل ایبلٹی
Kakao گیمز میں ODIN کی طرح طویل مدتی کھلاڑیوں کی مصروفیات کے ساتھ دیگر گیمز ہیں۔ قدرتی طور پر، LTV کی پیشن گوئی ان گیمز کو بھی فائدہ دیتی ہے۔ چونکہ زیادہ تر گیمز ایک جیسی لاگ کی اقسام کا اشتراک کرتے ہیں، اس لیے وہ اس ML حل کو دوسرے گیمز میں دوبارہ استعمال کرنا چاہتے ہیں۔ جب ہم ML ماڈل ڈیزائن کرتے ہیں تو ہم مختلف گیمز کے درمیان مشترکہ لاگ اور اوصاف کا استعمال کرکے اس ضرورت کو پورا کر سکتے ہیں۔ لیکن پھر بھی انجینئرنگ کا ایک چیلنج باقی ہے۔ ETL پائپ لائن، MLOps پائپ لائن، اور ML تخمینہ کو ایک مختلف AWS اکاؤنٹ میں دوبارہ بنایا جانا چاہیے۔ اس پیچیدہ حل کی دستی تعیناتی قابل توسیع نہیں ہے اور تعینات حل کو برقرار رکھنا مشکل ہے۔
اس مسئلے کو حل کرنے کے لیے، ہم کنفیگریشن کی چند تبدیلیوں کے ساتھ ML سلوشن کو خودکار طور پر قابل استعمال بناتے ہیں۔
حل جائزہ
LTV پیشن گوئی کے لیے ML حل چار اجزاء پر مشتمل ہے: ٹریننگ ڈیٹاسیٹ ETL پائپ لائن، MLOps پائپ لائن، inference dataset ETL پائپ لائن، اور ML بیچ کا اندازہ۔
ٹریننگ اور انفرنس ای ٹی ایل پائپ لائن گیم لاگ اور کھلاڑی کے میٹا ڈیٹا سے ایم ایل فیچرز بناتی ہے جو ایتھینا ٹیبلز میں محفوظ ہوتی ہے، اور نتیجے میں آنے والے فیچر ڈیٹا کو ایمیزون سادہ اسٹوریج سروس (ایمیزون S3) بالٹی۔ ETL کو متعدد تبدیلی کے مراحل کی ضرورت ہوتی ہے، اور ورک فلو کو AWS Glue کا استعمال کرتے ہوئے لاگو کیا جاتا ہے۔ MLOps ML ماڈلز کو تربیت دیتا ہے، موجودہ ماڈل کے مقابلے میں تربیت یافتہ ماڈل کا جائزہ لیتا ہے، اور پھر تربیت یافتہ ماڈل کو ماڈل رجسٹری میں رجسٹر کرتا ہے اگر یہ موجودہ ماڈل سے بہتر کارکردگی کا مظاہرہ کرتا ہے۔ یہ سب ایک واحد ML پائپ لائن کے طور پر لاگو ہوتے ہیں۔ ایمیزون سیج میکر پائپ لائنز، اور تمام ML ٹریننگز کا انتظام بذریعہ کیا جاتا ہے۔ ایمیزون سیج میکر کے تجربات. SageMaker تجربات کے ساتھ، ML انجینئرز تلاش کر سکتے ہیں کہ تربیت کے دوران یا بعد میں ہر ML ماڈل کے لیے کون سے تربیت اور تشخیصی ڈیٹا سیٹس، ہائپر پیرامیٹرس، اور کنفیگریشنز کا استعمال کیا گیا تھا۔ ایم ایل انجینئرز کو اب اس ٹریننگ میٹا ڈیٹا کو الگ سے منظم کرنے کی ضرورت نہیں ہے۔
آخری جزو ML بیچ کا تخمینہ ہے، جو اگلے دو ہفتوں تک LTV کی پیشن گوئی کرنے کے لیے باقاعدگی سے چلایا جاتا ہے۔
مندرجہ ذیل اعداد و شمار سے پتہ چلتا ہے کہ یہ اجزاء ایک واحد ML حل کے طور پر کیسے کام کرتے ہیں۔
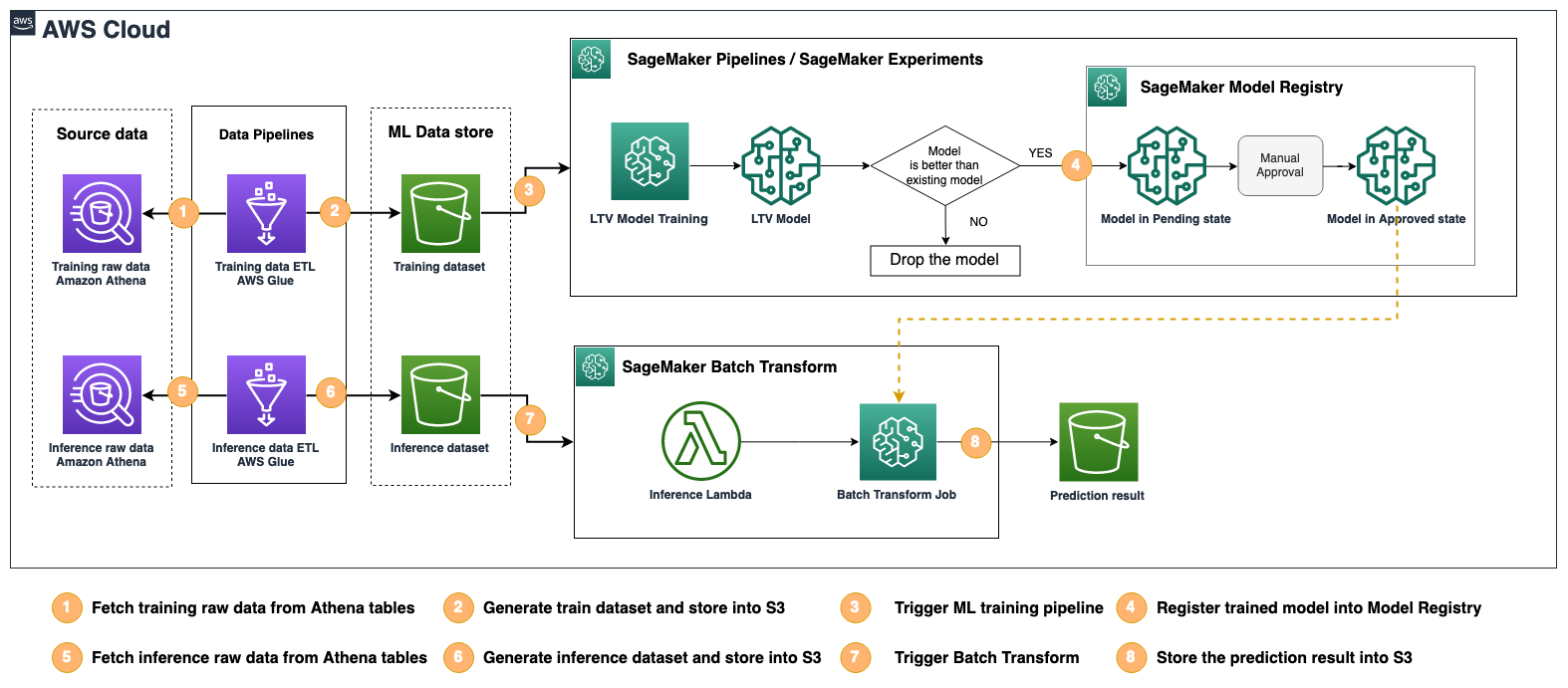
حل فن تعمیر کا استعمال کرتے ہوئے لاگو کیا گیا ہے۔ AWS کلاؤڈ ڈویلپمنٹ کٹ (AWS CDK) بنیادی ڈھانچے کو کوڈ (IaC) کے طور پر فروغ دینے کے لیے، مختلف AWS اکاؤنٹس اور خطوں میں ورژن کنٹرول اور حل کو تعینات کرنا آسان بناتا ہے۔
مندرجہ ذیل حصوں میں، ہم ہر جزو پر مزید تفصیل سے بات کرتے ہیں۔
ایم ایل فیچر جنریشن کے لیے ڈیٹا پائپ لائن
Amazon S3 کی حمایت یافتہ Athena میں محفوظ کردہ گیم لاگز AWS Glue میں Python شیل جابز کے طور پر تخلیق کردہ ETL پائپ لائنوں سے گزرتے ہیں۔ یہ ٹریننگ کے لیے تیار ڈیٹاسیٹ تیار کرنے کے لیے فیچر ایکسیکشن کے لیے AWS Glue کے ساتھ Python اسکرپٹ کو چلانے کے قابل بناتا ہے۔ ایتھینا میں ہر مرحلے میں متعلقہ میزیں بنائی جاتی ہیں۔ ہم ETL پائپ لائن کو چلانے کے لیے AWS Glue کا استعمال کرتے ہیں کیونکہ اس کے بغیر سرور کے فن تعمیر اور ڈیٹاسیٹ کے مختلف ورژن تیار کرنے میں مختلف شروعاتی اور اختتامی تاریخوں کو گزرنے میں لچک ہے۔ کا حوالہ دیتے ہیں getResolvedOptions کا استعمال کرتے ہوئے پیرامیٹرز تک رسائی حاصل کرنا AWS Glue جاب میں پیرامیٹرز کو منتقل کرنے کے بارے میں مزید جاننے کے لیے۔ اس طریقہ کے ساتھ، ڈیٹاسیٹ کو 4 ہفتوں تک مختصر مدت کا احاطہ کرنے کے لیے بنایا جا سکتا ہے، جو اس کے ابتدائی مراحل میں گیم کو سپورٹ کرتا ہے۔ مثال کے طور پر، ڈیٹا سیٹ کے ہر ورژن کے لیے ان پٹ شروع ہونے کی تاریخ اور پیشین گوئی کے آغاز کی تاریخ کو درج ذیل کوڈ کے ذریعے پارس کیا جاتا ہے:
AWS Glue جابز کو ڈیزائن اور مختلف مراحل میں تقسیم کیا جاتا ہے اور ترتیب وار متحرک کیا جاتا ہے۔ اپنی مرضی کے مطابق ETL پائپ لائنوں کو چلانے کے لیے ہر کام کو پوزیشنی اور کلیدی قدر کے جوڑے کے دلائل لینے کے لیے ترتیب دیا گیا ہے۔ ایک اہم پیرامیٹر ڈیٹا کی شروعات اور اختتامی تاریخ ہے جو تربیت میں استعمال ہوتی ہے۔ اس کی وجہ یہ ہے کہ ڈیٹا کی شروعات اور اختتامی تاریخ ممکنہ طور پر مختلف تعطیلات پر محیط ہے، اور ڈیٹا سیٹ کی لمبائی کا تعین کرنے میں براہ راست عنصر کے طور پر کام کرتی ہے۔ ماڈل پرفارمنس پر اس پیرامیٹر کے اثرات کا مشاہدہ کرنے کے لیے، ہم نے نو مختلف ڈیٹاسیٹ ورژن بنائے (مختلف آغاز کی تاریخوں اور تربیت کی مدت کے ساتھ)۔
خاص طور پر، ہم نے ایمیزون S4 کے تعاون سے نو ایتھینا ڈیٹا بیسز میں مختلف شروعاتی تاریخوں (12 ہفتوں سے شفٹ) اور مختلف تربیتی ادوار (16 ہفتے، 20 ہفتے، 24 ہفتے، 28 ہفتے اور 3 ہفتے) کے ساتھ ڈیٹاسیٹ ورژن بنائے۔ ڈیٹاسیٹ کے ہر ورژن میں کھلاڑی کی خصوصیات اور ان گیم پرچیز ایکٹیویٹی ٹائم سیریز ڈیٹا کو بیان کرنے والی خصوصیات شامل ہیں۔
ایم ایل ماڈل
ہم نے منتخب کیا۔ آٹوگلون SageMaker پائپ لائنز کے ساتھ لاگو ماڈل ٹریننگ کے لیے۔ AutoGluon خودکار مشین لرننگ (AutoML) کے لیے ایک ٹول کٹ ہے۔ یہ خودکار اسٹیک انسمبلنگ، ڈیپ لرننگ، اور امیج، ٹیکسٹ، اور ٹیبلولر ڈیٹا پر محیط حقیقی دنیا کی ایپلی کیشنز پر توجہ کے ساتھ استعمال میں آسان اور آسانی سے توسیع کرنے والی AutoML کو قابل بناتا ہے۔
آپ ML ماڈلز کو تربیت دینے کے لیے یا اس کے ساتھ مل کر AutoGluon اسٹینڈ الون استعمال کر سکتے ہیں۔ ایمیزون سیج میکر آٹو پائلٹسیج میکر کی ایک خصوصیت جو ایم ایل ماڈلز کی تربیت اور تعیناتی کے لیے مکمل طور پر منظم ماحول فراہم کرتی ہے۔
عام طور پر، اگر آپ SageMaker کی طرف سے فراہم کردہ مکمل طور پر منظم ماحول سے فائدہ اٹھانا چاہتے ہیں تو آپ کو AutoGluon کے ساتھ آٹو پائلٹ کا استعمال کرنا چاہیے، بشمول آٹومیٹک اسکیلنگ اور ریسورس مینجمنٹ جیسی خصوصیات، نیز تربیت یافتہ ماڈلز کی آسانی سے تعیناتی۔ یہ خاص طور پر مفید ہو سکتا ہے اگر آپ ML میں نئے ہیں اور بنیادی انفراسٹرکچر کی فکر کیے بغیر ماڈلز کی تربیت اور جانچ پر توجہ مرکوز کرنا چاہتے ہیں۔
جب آپ اپنی مرضی کے مطابق ML ماڈلز کو تربیت دینا چاہتے ہیں تو آپ AutoGluon اسٹینڈ اکیلا بھی استعمال کر سکتے ہیں۔ ہمارے معاملے میں، ہم نے SageMaker کے ساتھ AutoGluon کا استعمال دو مراحل کی پیشین گوئی کو پورا کرنے کے لیے کیا، جس میں churn کی درجہ بندی اور تاحیات قدر رجعت شامل ہے۔ اس صورت میں، جن کھلاڑیوں نے گیم آئٹمز کی خریداری روک دی ہے انہیں منتھلی سمجھا جاتا ہے۔
آئیے LTV پیشین گوئی کے لیے ماڈلنگ کے طریقہ کار کے بارے میں بات کرتے ہیں اور ڈیٹا بڑھنے کی علامت کے خلاف ماڈل کی دوبارہ تربیت کی تاثیر کے بارے میں بات کرتے ہیں، جس کا مطلب ہے اندرونی یا بیرونی واقعات جو کھلاڑی کی خریداری کے انداز کو تبدیل کرتے ہیں۔
سب سے پہلے، ماڈلنگ کے عمل کو دو مراحل میں الگ کیا گیا تھا، جس میں ایک بائنری درجہ بندی (کسی کھلاڑی کو منتھلی ہوئی یا نہیں کے طور پر درجہ بندی کرنا) اور ایک ریگریشن ماڈل جسے غیر منحنی کھلاڑیوں کے لیے LTV قدر کی پیشن گوئی کرنے کی تربیت دی گئی تھی:
- اسٹیج 1 - LTV کے لیے ہدف کی قدریں بائنری لیبل میں تبدیل ہو جاتی ہیں،
LTV = 0اورLTV > 0. AutoGluon TabularPredictor F1 سکور کو زیادہ سے زیادہ کرنے کے لیے تربیت یافتہ ہے۔ - اسٹیج 2 - AutoGluon TabularPredictor کا استعمال کرتے ہوئے ایک ریگریشن ماڈل استعمال کیا جاتا ہے جس کے ساتھ صارفین کو ماڈل کی تربیت دی جاتی ہے۔
LTV > 0حقیقی LTV ریگریشن کے لیے۔
ماڈل ٹیسٹنگ کے مرحلے کے دوران، ٹیسٹ کا ڈیٹا ترتیب وار دو ماڈلز سے گزرتا ہے:
- اسٹیج 1 - بائنری درجہ بندی کا ماڈل بائنری پیشن گوئی 0 حاصل کرنے کے لیے ٹیسٹ ڈیٹا پر چلتا ہے (صارف کے پاس
LTV = 0, churned) یا 1 (صارف کے پاسLTV > 0، منتھلی نہیں)۔ - اسٹیج 2 - کھلاڑیوں کے ساتھ پیش گوئی کی گئی۔
LTV > 0حقیقی LTV قدر کی پیشن گوئی حاصل کرنے کے لیے ریگریشن ماڈل سے گزریں۔ ہونے کے طور پر پیشن گوئی صارف کے ساتھ مل کرLTV = 0، حتمی LTV پیشین گوئی کا نتیجہ تیار ہوا ہے۔
ہر تجربے کے لیے اور ڈیٹاسیٹ کے ہر ورژن کے لیے ٹریننگ کنفیگریشنز سے وابستہ ماڈل نمونے ٹریننگ کے بعد S3 بالٹی میں محفوظ کیے جاتے ہیں، اور SageMaker پائپ لائنز کے اندر SageMaker ماڈل رجسٹری میں بھی رجسٹر ہوتے ہیں۔
یہ جانچنے کے لیے کہ آیا ڈیٹاسیٹ v1 (اکتوبر سے شروع ہونے والے 12 ہفتے) پر تربیت یافتہ ایک ہی ماڈل کے استعمال کی وجہ سے ڈیٹا میں کوئی اضافہ ہوا ہے، ہم ڈیٹاسیٹ v1، v2 (شروعاتی وقت 4 ہفتوں سے آگے منتقل کیا گیا)، v3 (آگے منتقل کیا گیا) کا اندازہ لگاتے ہیں۔ 8 ہفتے)، اور اسی طرح v4 اور v5 کے لیے۔ مندرجہ ذیل جدول ماڈل کی کارکردگی کا خلاصہ کرتا ہے۔ موازنہ کے لیے استعمال ہونے والا میٹرک minmax سکور ہے، جس کی حد 0–1 ہے۔ جب LTV کی پیشن گوئی حقیقی LTV قدر کے قریب ہوتی ہے تو یہ زیادہ نمبر دیتا ہے۔
| ڈیٹاسیٹ ورژن | Minmax سکور | v1 کے ساتھ فرق |
| v1 | 0.68756 | - |
| v2 | 0.65283 | 0.03473- |
| v3 | 0.66173 | 0.02584- |
| v4 | 0.69633 | 0.00877 |
| v5 | 0.71533 | 0.02777 |
ڈیٹاسیٹ v2 اور v3 پر کارکردگی میں کمی دیکھی گئی ہے، جو ڈیٹاسیٹ v2 اور v3 پر کارکردگی کو کم کرنے والے مختلف ماڈلنگ طریقوں پر کیے گئے تجزیہ سے مطابقت رکھتی ہے۔ v4 اور v5 کے لیے، ماڈل مساوی کارکردگی دکھاتا ہے، اور یہاں تک کہ ماڈل کی دوبارہ تربیت کے بغیر v5 پر معمولی بہتری بھی دکھاتا ہے۔ تاہم، ڈیٹاسیٹ v1 (5) پر ماڈل v0.71533 کی کارکردگی بمقابلہ ڈیٹاسیٹ v5 (5) پر ماڈل v0.7599 کی کارکردگی کا موازنہ کرتے وقت، ماڈل کی دوبارہ تربیت کارکردگی کو نمایاں طور پر بہتر کر رہی ہے۔
ٹریننگ پائپ لائن
سیج میکر پائپ لائنز ایم ایل ورک فلوز کو کمپوز کرنے، ان کا نظم کرنے اور دوبارہ استعمال کرنے کے آسان طریقے فراہم کرتی ہے۔ پیداوار میں تعیناتی کے لیے بہترین ماڈلز کا انتخاب کریں؛ ماڈلز کو خود بخود ٹریک کریں؛ اور CI/CD کو ML پائپ لائنوں میں ضم کریں۔
تربیتی مرحلے میں، مندرجہ ذیل کوڈ کے ساتھ سیج میکر تخمینہ کنندہ بنایا گیا ہے۔ تربیتی جاب بنانے کے لیے عام سیج میکر تخمینہ لگانے والے کے برعکس، ہم سیج میکر پائپ لائن سیشن کو پاس کرتے ہیں SageMaker_session سیج میکر سیشن کے بجائے:
بنیادی تصویر کو درج ذیل کوڈ کے ذریعے بازیافت کیا گیا ہے۔
تربیت یافتہ ماڈل تشخیصی عمل سے گزرتا ہے، جہاں ہدف میٹرک کم از کم ہے۔ موجودہ بہترین LTV minmax سکور سے بڑا سکور ماڈل رجسٹر سٹیپ کی طرف لے جائے گا، جب کہ کم LTV minmax سکور موجودہ رجسٹرڈ ماڈل ورژن کو اپ ڈیٹ کرنے کا باعث نہیں بنے گا۔ ہولڈ آؤٹ ٹیسٹ ڈیٹاسیٹ پر ماڈل کی تشخیص کو SageMaker پروسیسنگ جاب کے طور پر لاگو کیا جاتا ہے۔
تشخیص کے مرحلے کی وضاحت درج ذیل کوڈ سے ہوتی ہے:
جب ماڈل کی تشخیص مکمل ہو جاتی ہے، تو ہمیں موجودہ ماڈل کی کارکردگی کے ساتھ تشخیص کے نتائج (minmax) کا موازنہ کرنے کی ضرورت ہوتی ہے۔ ہم ایک اور پائپ لائن قدم کی وضاحت کرتے ہیں، step_cond.
تمام ضروری اقدامات کی وضاحت کے ساتھ، ایم ایل پائپ لائن کو درج ذیل کوڈ کے ساتھ بنایا اور چلایا جا سکتا ہے:
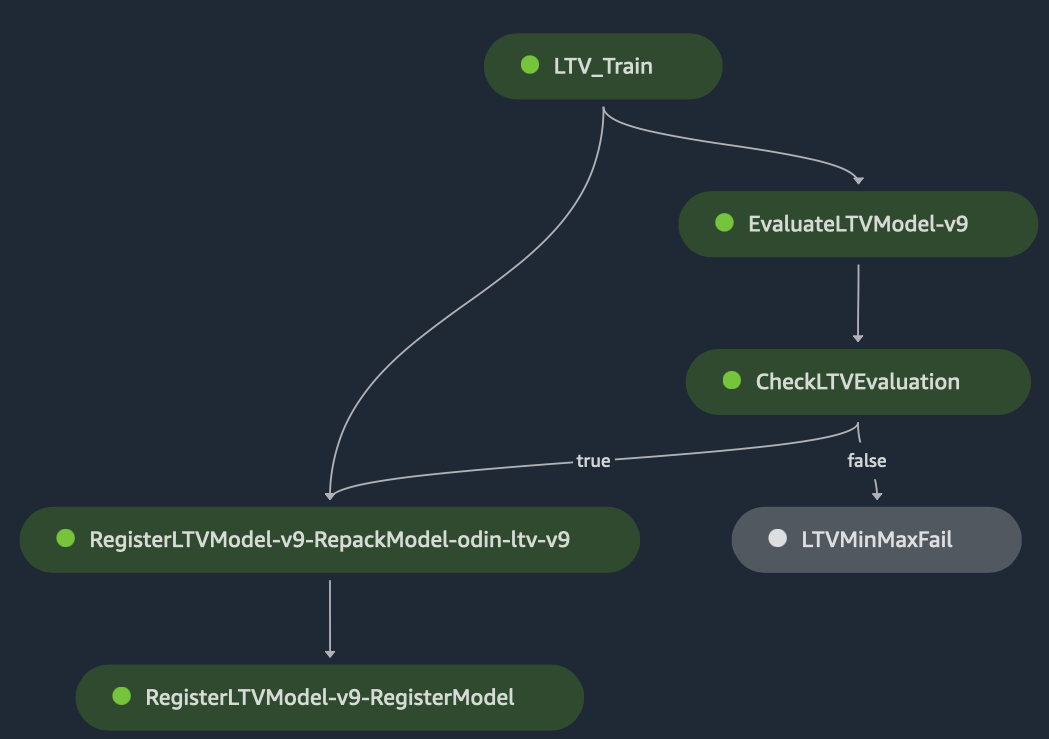
پورے ورک فلو کو ٹریک کیا جا سکتا ہے اور اس میں تصور کیا جا سکتا ہے۔ ایمیزون سیج میکر اسٹوڈیوجیسا کہ مندرجہ ذیل گراف میں دکھایا گیا ہے۔ ML ٹریننگ جابز کو SageMaker Experiment کے ذریعے خود بخود ٹریک کیا جاتا ہے تاکہ آپ ML ٹریننگ کنفیگریشن، ہائپر پیرامیٹر، ڈیٹاسیٹ، اور ہر تربیتی جاب کا تربیت یافتہ ماڈل تلاش کر سکیں۔ ان میں سے ہر ایک ماڈیول، لاگز، پیرامیٹرز، آؤٹ پٹ وغیرہ کو تفصیل سے جانچنے کے لیے منتخب کریں۔
خودکار بیچ کا اندازہ
LTV پیشین گوئی کے معاملے میں، بیچ کے تخمینے کو حقیقی وقت کے تخمینے پر ترجیح دی جاتی ہے کیونکہ پیش گوئی شدہ LTV کو عام طور پر آف لائن بہاو کے کاموں کے لیے استعمال کیا جاتا ہے۔ جس طرح ملٹی سٹیپ ای ٹی ایل کے ذریعے ٹریننگ ڈیٹاسیٹ سے ایم ایل فیچرز بنانا، ہمیں ایل ٹی وی پیشین گوئی ماڈل کے ان پٹ کے طور پر ایم ایل فیچرز بنانا ہوں گے۔ ہم پلیئرز کے ڈیٹا کو ML خصوصیات میں تبدیل کرنے کے لیے AWS Glue کے اسی ورک فلو کو دوبارہ استعمال کرتے ہیں، لیکن ڈیٹا کی تقسیم اور لیبل جنریشن کو انجام نہیں دیا جاتا ہے۔ نتیجے میں آنے والی ML خصوصیت کو نامزد S3 بالٹی میں محفوظ کیا جاتا ہے، جس کی نگرانی ایک کے ذریعے کی جاتی ہے۔ او ڈبلیو ایس لامبڈا۔ محرک جب ML فیچر فائل کو S3 بالٹی میں ڈالا جاتا ہے، تو Lambda فنکشن خود بخود چلتا ہے، جو SageMaker ماڈل رجسٹری میں پائے جانے والے تازہ ترین اور منظور شدہ LTV ماڈل کا استعمال کرتے ہوئے SageMaker بیچ ٹرانسفارم جاب شروع کرتا ہے۔ جب بیچ ٹرانسفارم مکمل ہو جاتا ہے، تو ہر کھلاڑی کے لیے آؤٹ پٹ یا پیشین گوئی شدہ LTV ویلیوز S3 بالٹی میں محفوظ کر دی جاتی ہیں تاکہ کوئی بھی بہاو کام نتیجہ حاصل کر سکے۔ اس فن تعمیر کو درج ذیل خاکہ میں بیان کیا گیا ہے۔

اس پائپ لائن میں ETL ٹاسک اور بیچ کے تخمینے کے امتزاج کے ساتھ، LTV کی پیشن گوئی صرف AWS Glue ETL ورک فلو کو باقاعدگی سے چلاتے ہوئے کی جاتی ہے، جیسے ہفتے میں ایک بار یا مہینے میں ایک بار۔ AWS Glue اور SageMaker اپنے بنیادی وسائل کا نظم کرتے ہیں، جس کا مطلب ہے کہ اس پائپ لائن کے لیے آپ کو کسی بھی وسائل کو ہر وقت چلانے کی ضرورت نہیں ہے۔ لہذا، منظم خدمات کا استعمال کرتے ہوئے یہ فن تعمیر بیچ کے کاموں کے لیے لاگت سے موثر ہے۔
AWS CDK کا استعمال کرتے ہوئے قابل تعیناتی حل
ایم ایل پائپ لائن خود پائپ لائنز کا استعمال کرتے ہوئے بیان کی جاتی ہے اور چلائی جاتی ہے، لیکن ڈیٹا پائپ لائن اور ایم ایل ماڈل انفرنس کوڈ بشمول لیمبڈا فنکشن پائپ لائنز کے دائرہ کار سے باہر ہیں۔ اس حل کو قابل استعمال بنانے کے لیے تاکہ ہم اسے دوسرے گیمز پر لاگو کر سکیں، ہم نے AWS CDK کا استعمال کرتے ہوئے ڈیٹا پائپ لائن اور ML ماڈل کا اندازہ لگایا۔ اس طرح، انجینئرنگ ٹیم اور ڈیٹا سائنس ٹیم کے پاس بنیادی ڈھانچے کو دستی طور پر استعمال کیے بغیر پورے ایم ایل حل کو منظم کرنے، اپ ڈیٹ کرنے اور کنٹرول کرنے کی لچک ہوتی ہے۔ AWS مینجمنٹ کنسول.
نتیجہ
اس پوسٹ میں، ہم نے اس بات پر تبادلہ خیال کیا کہ ہم AWS Glue اور SageMaker جیسی منظم خدمات کا استعمال کرتے ہوئے ایک خودکار ڈیٹا پائپ لائن اور ML پائپ لائن بنا کر ڈیٹا ڈرفٹ اور پیچیدہ ETL چیلنجوں کو کیسے حل کر سکتے ہیں، اور اسے کس طرح ایک قابل توسیع اور دوبارہ قابل ML حل بنایا جا سکتا ہے۔ AWS CDK کا استعمال کرتے ہوئے دیگر گیمز۔
"اس دور میں، کھیل صرف مواد سے زیادہ ہیں. جب ہماری زندگیوں سے لطف اندوز ہونے کی بات آتی ہے تو وہ لوگوں کو اکٹھا کرتے ہیں اور ان کے پاس لامحدود صلاحیت اور قدر ہوتی ہے۔ کاکاو گیمز میں، ہم ایک ایسی دنیا کا خواب دیکھتے ہیں جو گیمز سے بھری ہو جس سے کوئی بھی آسانی سے لطف اندوز ہو سکے۔ ہم ایسے تجربات پیدا کرنے کی کوشش کرتے ہیں جہاں کھلاڑی کھیلتے رہنا چاہتے ہیں اور کمیونٹی کے ذریعے بانڈز بنانا چاہتے ہیں۔ MLSL ٹیم نے AutoML کے لیے AutoGluon، MLOps کے لیے Amazon SageMaker، اور ڈیٹا پائپ لائن کے لیے AWS Glue کا استعمال کرتے ہوئے ایک قابل توسیع LTV پیشن گوئی ML حل بنانے میں ہماری مدد کی۔ یہ حل ڈیٹا یا گیم کی تبدیلیوں کے لیے ماڈل کی دوبارہ تربیت کو خودکار کرتا ہے، اور آسانی سے AWS CDK کے ذریعے دوسرے گیمز میں تعینات کیا جا سکتا ہے۔ یہ حل ہمیں اپنے کاروباری عمل کو بہتر بنانے میں مدد کرتا ہے، جس کے نتیجے میں ہمیں کھیل میں آگے رہنے میں مدد ملتی ہے۔
- SuHyung کم، ڈیٹا اینالیٹکس لیب کے سربراہ، کاکاو گیمز۔
SageMaker اور AWS CDK کی متعلقہ خصوصیات کے بارے میں مزید جاننے کے لیے، درج ذیل کو چیک کریں:
ایمیزون ایم ایل حل لیب
۔ ایمیزون ایم ایل حل لیب اپنی ٹیم کو ML ماہرین کے ساتھ جوڑیں تاکہ آپ کو اپنی تنظیم کے اعلیٰ ترین ML مواقع کی شناخت اور ان پر عمل درآمد کرنے میں مدد ملے۔ اگر آپ اپنی مصنوعات اور عمل میں ML کے استعمال کو تیز کرنا چاہتے ہیں، تو براہ کرم Amazon ML Solutions Lab سے رابطہ کریں۔
مصنفین کے بارے میں
 سوہیونگ کم KakaoGames Data Analytics Lab میں جنرل منیجر ہیں۔ وہ ڈیٹا اکٹھا کرنے اور تجزیہ کرنے کا ذمہ دار ہے، اور خاص طور پر آن لائن گیمز کی معیشت کے لیے فکر مند ہے۔
سوہیونگ کم KakaoGames Data Analytics Lab میں جنرل منیجر ہیں۔ وہ ڈیٹا اکٹھا کرنے اور تجزیہ کرنے کا ذمہ دار ہے، اور خاص طور پر آن لائن گیمز کی معیشت کے لیے فکر مند ہے۔
 موہیون کم ایمیزون مشین لرننگ سلوشنز لیب میں ڈیٹا سائنٹسٹ ہے۔ وہ مشین لرننگ اور ڈیپ لرننگ کا استعمال کرکے صارفین کے مختلف کاروباری مسائل کو حل کرتا ہے، اور انہیں ہنر مند بننے میں بھی مدد کرتا ہے۔
موہیون کم ایمیزون مشین لرننگ سلوشنز لیب میں ڈیٹا سائنٹسٹ ہے۔ وہ مشین لرننگ اور ڈیپ لرننگ کا استعمال کرکے صارفین کے مختلف کاروباری مسائل کو حل کرتا ہے، اور انہیں ہنر مند بننے میں بھی مدد کرتا ہے۔
 شیلڈن لیو ایمیزون مشین لرننگ سلوشنز لیب میں ڈیٹا سائنٹسٹ ہے۔ ایک تجربہ کار مشین لرننگ پروفیشنل کے طور پر جو توسیع پذیر اور قابل بھروسہ حلوں کی تعمیر میں مہارت رکھتا ہے، وہ انٹرپرائز صارفین کے ساتھ ان کے کاروباری مسائل کو حل کرنے اور مؤثر ML حل فراہم کرنے کے لیے کام کرتا ہے۔
شیلڈن لیو ایمیزون مشین لرننگ سلوشنز لیب میں ڈیٹا سائنٹسٹ ہے۔ ایک تجربہ کار مشین لرننگ پروفیشنل کے طور پر جو توسیع پذیر اور قابل بھروسہ حلوں کی تعمیر میں مہارت رکھتا ہے، وہ انٹرپرائز صارفین کے ساتھ ان کے کاروباری مسائل کو حل کرنے اور مؤثر ML حل فراہم کرنے کے لیے کام کرتا ہے۔
 ایلکس چیراتھ ایمیزون ایم ایل سلوشنز لیب میں ایک سینئر مشین لرننگ انجینئر ہے۔ وہ کاروباری ضروریات کو پورا کرنے کے لیے AI ایپلی کیشنز بنانے کے لیے ڈیٹا سائنسدانوں اور انجینئرز کی ٹیموں کی رہنمائی کرتا ہے۔
ایلکس چیراتھ ایمیزون ایم ایل سلوشنز لیب میں ایک سینئر مشین لرننگ انجینئر ہے۔ وہ کاروباری ضروریات کو پورا کرنے کے لیے AI ایپلی کیشنز بنانے کے لیے ڈیٹا سائنسدانوں اور انجینئرز کی ٹیموں کی رہنمائی کرتا ہے۔
 گونسو مونAWS میں AI/ML سپیشلسٹ سولیوشنز آرکیٹیکٹ نے AWS AI/ML سروسز کا استعمال کرتے ہوئے اپنے ML مسائل کو حل کرنے کے لیے صارفین کے ساتھ مل کر کام کیا ہے۔ ماضی میں، انہیں مینوفیکچرنگ انڈسٹری میں مشین لرننگ سروسز کے ساتھ ساتھ پورٹل اور گیمنگ انڈسٹری میں بڑے پیمانے پر سروس ڈیولپمنٹ، ڈیٹا کے تجزیہ اور سسٹم کی ترقی کا تجربہ تھا۔ اپنے فارغ وقت میں، گونسو سیر کرتا ہے اور بچوں کے ساتھ کھیلتا ہے۔
گونسو مونAWS میں AI/ML سپیشلسٹ سولیوشنز آرکیٹیکٹ نے AWS AI/ML سروسز کا استعمال کرتے ہوئے اپنے ML مسائل کو حل کرنے کے لیے صارفین کے ساتھ مل کر کام کیا ہے۔ ماضی میں، انہیں مینوفیکچرنگ انڈسٹری میں مشین لرننگ سروسز کے ساتھ ساتھ پورٹل اور گیمنگ انڈسٹری میں بڑے پیمانے پر سروس ڈیولپمنٹ، ڈیٹا کے تجزیہ اور سسٹم کی ترقی کا تجربہ تھا۔ اپنے فارغ وقت میں، گونسو سیر کرتا ہے اور بچوں کے ساتھ کھیلتا ہے۔
- SEO سے چلنے والا مواد اور PR کی تقسیم۔ آج ہی بڑھا دیں۔
- پلیٹو بلاک چین۔ Web3 Metaverse Intelligence. علم میں اضافہ۔ یہاں تک رسائی حاصل کریں۔
- ماخذ: https://aws.amazon.com/blogs/machine-learning/how-kakao-games-automates-lifetime-value-prediction-from-game-data-using-amazon-sagemaker-and-aws-glue/

