یہ تین حصوں کی سیریز میں دکھایا گیا ہے کہ گراف نیورل نیٹ ورکس (GNNs) کو کیسے استعمال کیا جائے اور ایمیزون نیپچون کا استعمال کرتے ہوئے فلم کی سفارشات تیار کرنے کے لئے IMDb اور Box Office Mojo Movies/TV/OTT قابل لائسنس ڈیٹا پیکج، جو تفریحی میٹا ڈیٹا کی ایک وسیع رینج فراہم کرتا ہے، بشمول 1 بلین سے زیادہ صارف کی درجہ بندی؛ 11 ملین سے زیادہ کاسٹ اور عملے کے ارکان کے لیے کریڈٹ؛ 9 ملین فلم، ٹی وی، اور تفریحی عنوانات؛ اور 60 سے زیادہ ممالک سے عالمی باکس آفس رپورٹنگ ڈیٹا۔ بہت سے AWS میڈیا اور تفریحی صارفین IMDb ڈیٹا کے ذریعے لائسنس دیتے ہیں۔ AWS ڈیٹا ایکسچینج مواد کی دریافت کو بہتر بنانے اور گاہک کی مصروفیت اور برقرار رکھنے میں اضافہ کرنے کے لیے۔
مندرجہ ذیل خاکہ اس سیریز کے حصے کے طور پر لاگو مکمل فن تعمیر کی وضاحت کرتا ہے۔
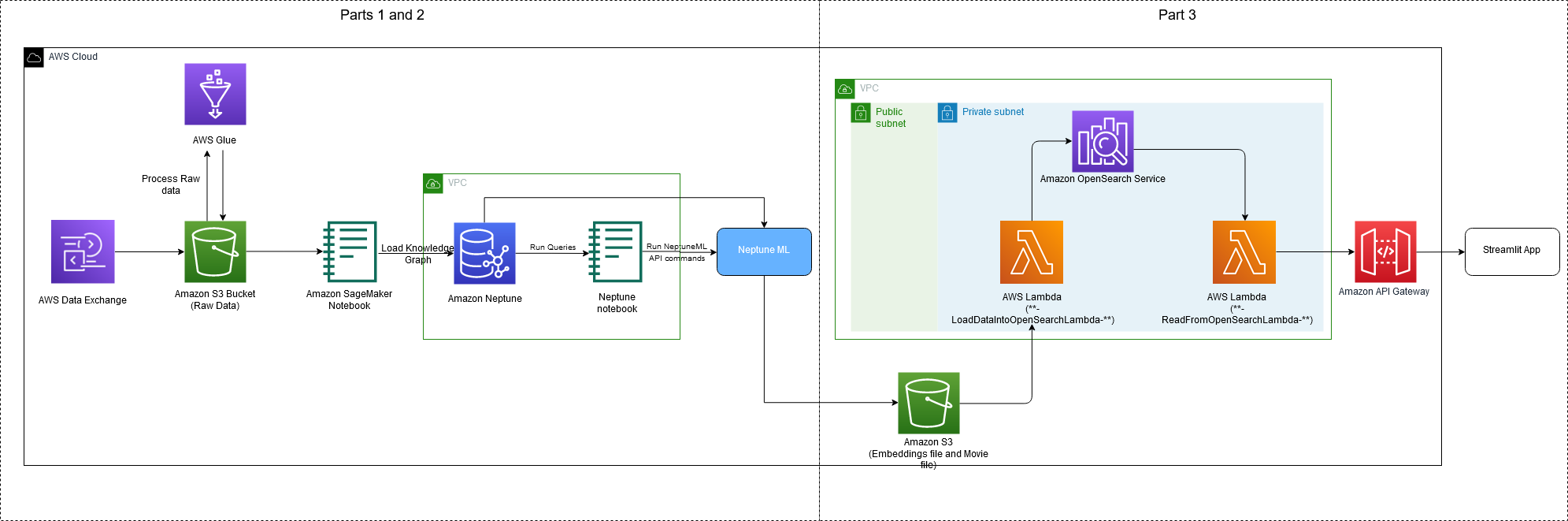
In حصہ 1، ہم نے GNNs کی ایپلی کیشنز اور اپنے IMDb ڈیٹا کو نالج گراف (KG) میں تبدیل کرنے اور تیار کرنے کے طریقہ پر تبادلہ خیال کیا۔ ہم نے AWS ڈیٹا ایکسچینج سے ڈیٹا ڈاؤن لوڈ کیا اور اس پر کارروائی کی۔ AWS گلو KG فائلیں بنانے کے لیے۔ KG فائلیں اس میں محفوظ تھیں۔ ایمیزون سادہ اسٹوریج سروس (ایمیزون S3) اور پھر لوڈ کیا گیا۔ ایمیزون نیپچون.
In حصہ 2، ہم نے استعمال کرنے کا طریقہ دکھایا ایمیزون نیپچون ایم ایل (میں ایمیزون سیج میکر) کے جی کو تربیت دینے اور کے جی ایمبیڈنگز بنانے کے لیے۔
اس پوسٹ میں، ہم آپ کو بتاتے ہیں کہ Amazon S3 میں ہمارے تربیت یافتہ KG ایمبیڈنگز کو کیٹلاگ سے باہر تلاش کے استعمال کے کیسز میں کیسے لاگو کیا جائے۔ ایمیزون اوپن سرچ سروس اور او ڈبلیو ایس لامبڈا۔. آپ انٹرایکٹو تلاش کے تجربے کے لیے ایک مقامی ویب ایپ بھی تعینات کرتے ہیں۔ اس پوسٹ میں استعمال ہونے والے تمام وسائل ایک ہی استعمال کرکے بنائے جاسکتے ہیں۔ AWS کلاؤڈ ڈویلپمنٹ کٹ (AWS CDK) کمانڈ جیسا کہ بعد میں پوسٹ میں بیان کیا گیا ہے۔
پس منظر
کیا آپ نے کبھی نادانستہ طور پر کسی ایسے مواد کا عنوان تلاش کیا ہے جو ویڈیو اسٹریمنگ پلیٹ فارم میں دستیاب نہیں تھا؟ اگر ہاں، تو آپ دیکھیں گے کہ خالی تلاش کے نتائج والے صفحے کا سامنا کرنے کے بجائے، آپ کو کاسٹ یا عملے کے ارکان کے ساتھ ایک ہی صنف کی فلموں کی فہرست ملے گی۔ یہ کیٹلاگ سے باہر تلاش کا تجربہ ہے!
کیٹلاگ سے باہر کی تلاش (OOC) اس وقت ہوتا ہے جب آپ ایک تلاش کا استفسار درج کرتے ہیں جس کا کیٹلاگ میں کوئی براہ راست مماثلت نہیں ہے۔ یہ واقعہ اکثر ویڈیو اسٹریمنگ پلیٹ فارمز میں ہوتا ہے جو ایک محدود وقت کے لیے متعدد وینڈرز اور پروڈکشن کمپنیوں سے مختلف قسم کے مواد کو مسلسل خریدتے ہیں۔ سٹریمنگ کمپنی کے کیٹلاگ سے فلموں اور شوز کے بڑے علمی اڈوں سے مطابقت یا نقشہ سازی کی عدم موجودگی کے نتیجے میں صارفین کے لیے ایک ذیلی برابر تلاش کا تجربہ ہو سکتا ہے جو OOC مواد سے استفسار کرتے ہیں، اس طرح پلیٹ فارم کے ساتھ تعامل کا وقت کم ہو جاتا ہے۔ یہ نقشہ سازی دستی طور پر کیٹلاگ کے مواد میں بار بار OOC سوالات کی نقشہ سازی کے ذریعے کی جا سکتی ہے یا مشین لرننگ (ML) کا استعمال کرتے ہوئے خودکار کیا جا سکتا ہے۔
اس پوسٹ میں، ہم IMDb ڈیٹاسیٹ (عالمی تفریحی میٹا ڈیٹا کا سب سے بڑا ذریعہ) اور نالج گرافس کی طاقت کو استعمال کرتے ہوئے OOC کو ہینڈل کرنے کا طریقہ بتاتے ہیں۔
اوپن سرچ سروس ایک مکمل طور پر منظم سروس ہے جو آپ کے لیے انٹرایکٹو لاگ اینالیٹکس، ریئل ٹائم ایپلیکیشن مانیٹرنگ، ویب سائٹ کی تلاش اور مزید بہت کچھ کرنا آسان بناتی ہے۔ OpenSearch ایک کھلا ذریعہ ہے، تقسیم شدہ تلاش اور تجزیاتی سوٹ Elasticsearch سے اخذ کیا گیا ہے۔ OpenSearch سروس OpenSearch کے تازہ ترین ورژن پیش کرتی ہے، Elasticsearch کے 19 ورژنز (1.5 سے 7.10 ورژنز) کے ساتھ ساتھ OpenSearch ڈیش بورڈز اور Kibana (1.5 سے 7.10 ورژن) کے ذریعے چلنے والی ویژولائزیشن کی صلاحیتیں بھی پیش کرتی ہیں۔ OpenSearch سروس کے پاس فی الحال ہزاروں کی تعداد میں فعال صارفین ہیں جن کے ہزاروں کلسٹرز مینجمنٹ کے تحت ہر ماہ کھربوں درخواستوں پر کارروائی کرتے ہیں۔ OpenSearch سروس kNN تلاش پیش کرتی ہے، جو استعمال کے معاملات میں تلاش کو بڑھا سکتی ہے جیسے پروڈکٹ کی سفارشات، دھوکہ دہی کا پتہ لگانے، اور تصویر، ویڈیو، اور دستاویز اور استفسار کی مماثلت جیسے کچھ مخصوص معنیاتی منظرنامے۔ OpenSearch سروس کی فطری زبان کی تفہیم سے چلنے والی تلاش کی خصوصیات کے بارے میں مزید معلومات کے لیے، رجوع کریں۔ Amazon SageMaker اور Amazon OpenSearch Service KNN فیچر کے ساتھ NLU سے چلنے والی سرچ ایپلی کیشن بنانا.
حل جائزہ
اس پوسٹ میں، ہم اوپن سرچ سروس کی k-nearest پڑوسی (kNN) تلاش کی صلاحیتوں کا استعمال کرتے ہوئے نالج گراف پر مبنی ایمبیڈنگ سرچ کے ذریعے OOC حالات کو سنبھالنے کا حل پیش کرتے ہیں۔ اس حل کو نافذ کرنے کے لیے استعمال ہونے والی کلیدی AWS سروسز ہیں OpenSearch Service، SageMaker، Lambda، اور Amazon S3۔
باہر چیک کریں حصہ 1 اور حصہ 2 Amazon Neptune ML کا استعمال کرتے ہوئے نالج گرافس بنانے اور GNN ایمبیڈنگ کے بارے میں مزید جاننے کے لیے اس سیریز کا۔
ہمارا OOC حل مانتا ہے کہ آپ کے پاس ایک مشترکہ KG ہے جو ایک سٹریمنگ کمپنی KG اور IMDb KG کو ملا کر حاصل کیا گیا ہے۔ یہ سادہ ٹیکسٹ پروسیسنگ تکنیکوں کے ذریعے کیا جا سکتا ہے جو ٹائٹل کی قسم (فلم، سیریز، دستاویزی فلم)، کاسٹ اور عملے کے ساتھ ٹائٹلز سے میل کھاتی ہیں۔ مزید برآں، اس مشترکہ نالج گراف کو اس میں مذکور پائپ لائنوں کے ذریعے نالج گراف ایمبیڈنگس پیدا کرنے کی تربیت دی جانی ہوگی۔ حصہ 1 اور حصہ 2. مندرجہ ذیل خاکہ مشترکہ KG کا ایک آسان منظر پیش کرتا ہے۔
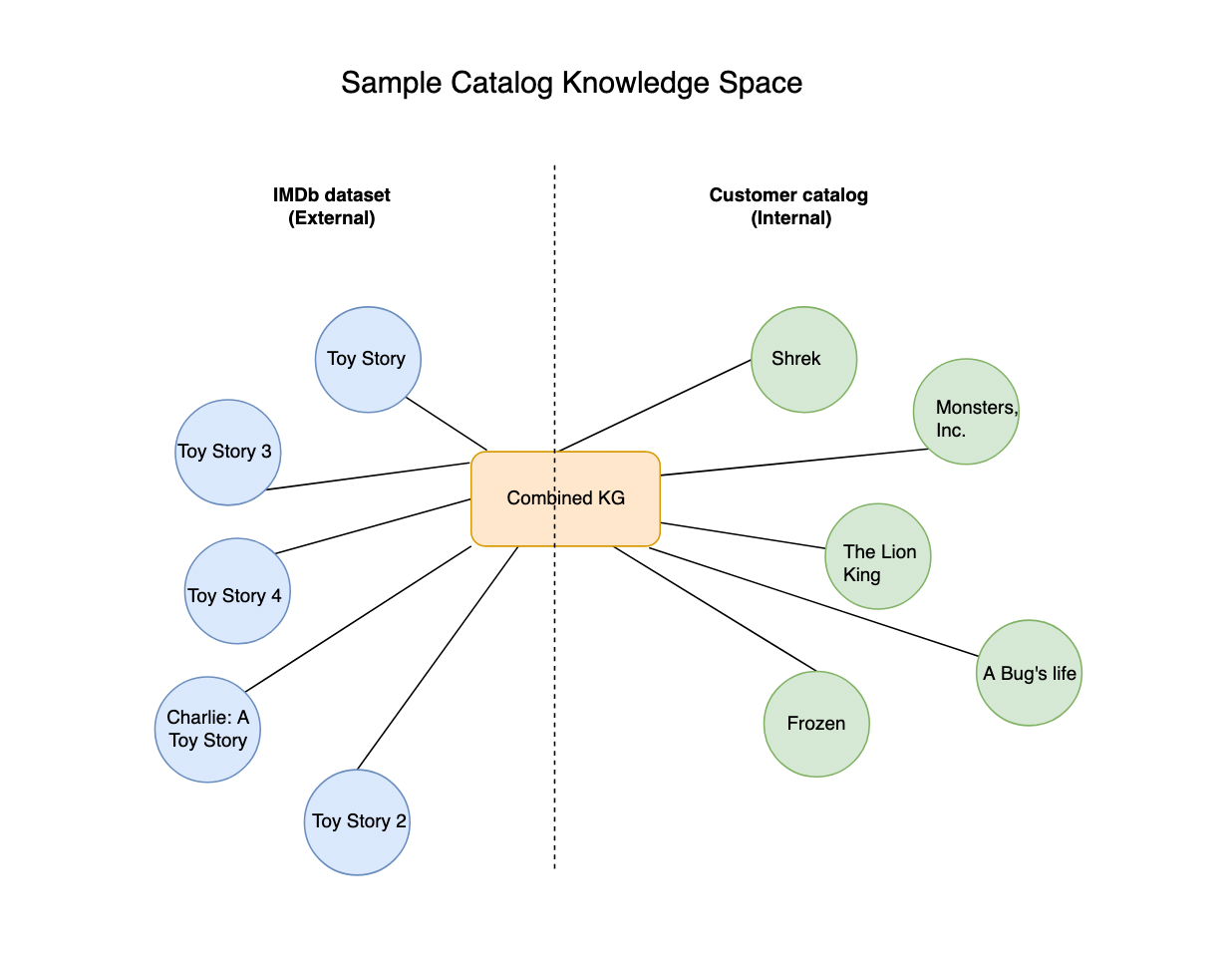
ایک سادہ مثال کے ساتھ OOC تلاش کی فعالیت کو ظاہر کرنے کے لیے، ہم نے IMDb نالج گراف کو کسٹمر-کیٹلاگ اور آؤٹ-آف-کسٹمر-کیٹلاگ میں تقسیم کیا ہے۔ ہم ان عنوانات کو نشان زد کرتے ہیں جن میں "Toy Story" کو کسٹمر کیٹلاگ سے باہر کے وسائل کے طور پر اور بقیہ IMDb نالج گراف کو کسٹمر کیٹلاگ کے بطور نشان زد کیا جاتا ہے۔ ایک ایسے منظر نامے میں جہاں کسٹمر کیٹلاگ کو بڑھایا نہیں گیا ہے یا بیرونی ڈیٹا بیس کے ساتھ ضم نہیں کیا گیا ہے، "کھلونے کی کہانی" کی تلاش کسی بھی عنوان کو لوٹائے گی جس کے میٹا ڈیٹا میں "کھلونا" یا "کہانی" کے الفاظ ہوں، اوپن سرچ ٹیکسٹ سرچ کے ساتھ۔ اگر کسٹمر کیٹلاگ کو IMDb میں میپ کیا گیا تھا، تو یہ سمجھنا آسان ہوگا کہ کیٹلاگ میں سوال "کھلونے کی کہانی" موجود نہیں ہے اور یہ کہ IMDb میں سب سے زیادہ میچز "Toy Story" "Toy Story 2," "Toy" ہیں۔ کہانی 3، "کھلونے کی کہانی 4،" اور "چارلی: کھلونا کہانی" متن کی مطابقت کے ساتھ کم ہوتی ہوئی ترتیب میں۔ ان میں سے ہر ایک میچ کے اندر اندر کیٹلاگ کے نتائج حاصل کرنے کے لیے، ہم OpenSearch سروس کے ذریعے کسٹمر کیٹلاگ پر مبنی kNN ایمبیڈنگ (مشترکہ KG کی) مماثلت میں پانچ قریب ترین فلمیں بنا سکتے ہیں۔
ایک عام OOC تجربہ مندرجہ ذیل تصویر میں بیان کردہ بہاؤ کی پیروی کرتا ہے۔
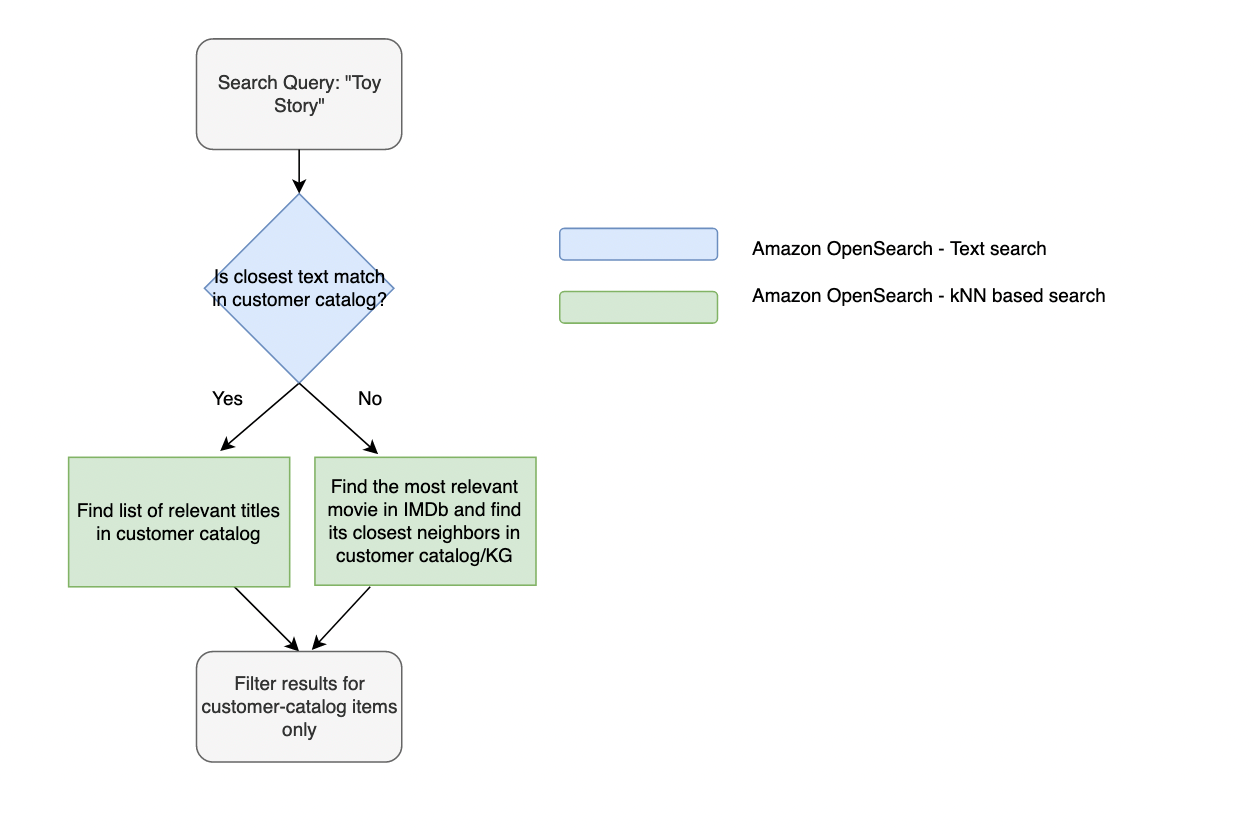
مندرجہ ذیل ویڈیو سوال "کھلونے کی کہانی" اور کسٹمر کیٹلاگ میں متعلقہ میچز (سفارشات کی تعداد) کے لیے سب سے اوپر پانچ (ہٹ کی تعداد) OOC نتائج دکھاتی ہے۔
یہاں، سوال کو اوپن سرچ سروس میں ٹیکسٹ سرچ کا استعمال کرتے ہوئے نالج گراف سے ملایا جاتا ہے۔ اس کے بعد ہم اوپن سرچ سروس کے این این انڈیکس کا استعمال کرتے ہوئے ٹیکسٹ میچ کی ایمبیڈنگز کو کسٹمر کیٹلاگ کے عنوانات میں نقشہ بناتے ہیں۔ چونکہ صارف کے استفسار کو علمی گراف کے اداروں سے براہ راست نقشہ نہیں بنایا جا سکتا، اس لیے ہم پہلے عنوان پر مبنی استفسار کی مماثلتیں تلاش کرنے کے لیے دو قدمی طریقہ استعمال کرتے ہیں اور پھر نالج گراف ایمبیڈنگز کا استعمال کرتے ہوئے عنوان سے ملتے جلتے آئٹمز کا استعمال کرتے ہیں۔ مندرجہ ذیل حصوں میں، ہم اوپن سرچ سروس کلسٹر قائم کرنے، نالج گراف انڈیکس بنانے اور اپ لوڈ کرنے، اور حل کو ویب ایپلیکیشن کے طور پر تعینات کرنے کے عمل سے گزرتے ہیں۔
شرائط
اس حل کو نافذ کرنے کے لیے، آپ کے پاس ایک ہونا چاہیے۔ AWS اکاؤنٹاوپن سرچ سروس، سیج میکر، لیمبڈا، اور سے واقفیت AWS کلاؤڈ فارمیشن، اور اندر کے مراحل مکمل کر لیے ہیں۔ حصہ 1 اور حصہ 2 اس سیریز کا
حل کے وسائل شروع کریں۔
مندرجہ ذیل آرکیٹیکچر ڈایاگرام آؤٹ آف کیٹلاگ ورک فلو کو ظاہر کرتا ہے۔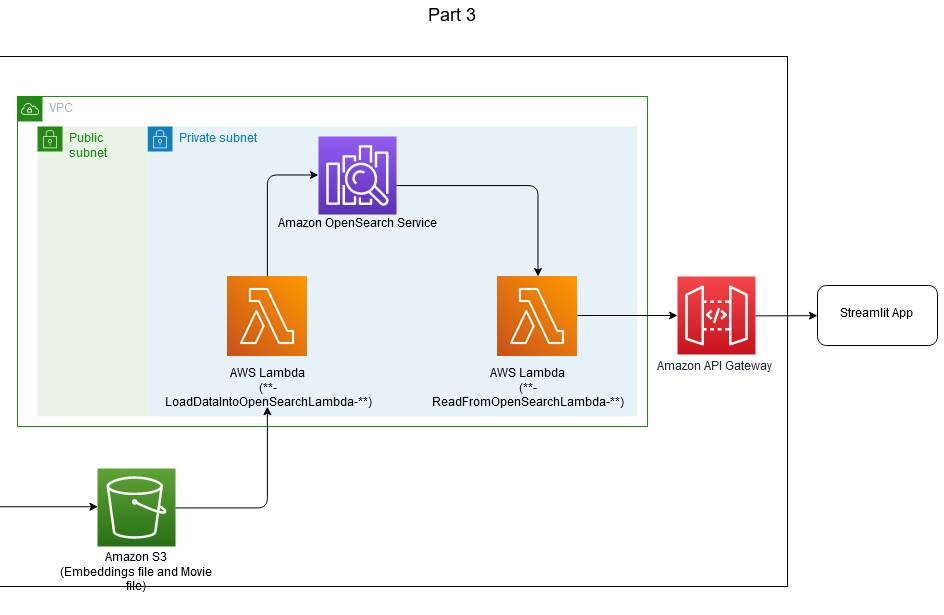
آپ OOC تلاش ایپلی کیشنز کے لیے درکار وسائل کی فراہمی کے لیے AWS Cloud Development Kit (CDK) استعمال کریں گے۔ ان وسائل کو شروع کرنے کا کوڈ درج ذیل کام کرتا ہے:
- وسائل کے لیے ایک VPC بناتا ہے۔
- تلاش کی درخواست کے لیے ایک OpenSearch Service ڈومین بناتا ہے۔
- مووی میٹا ڈیٹا کو پروسیس کرنے اور لوڈ کرنے کے لیے ایک لیمبڈا فنکشن بناتا ہے اور اوپن سرچ سروس انڈیکس میں ایمبیڈنگز (
**-ReadFromOpenSearchLambda-**). - ایک لیمبڈا فنکشن بناتا ہے جو کسی ویب ایپ سے صارف کے سوال کو ان پٹ کے طور پر لیتا ہے اور OpenSearch سے متعلقہ عنوانات واپس کرتا ہے (
**-LoadDataIntoOpenSearchLambda-**). - ایک API گیٹ وے بناتا ہے جو ویب ایپ یوزر انٹرفیس اور لیمبڈا کے درمیان سیکیورٹی کی ایک اضافی پرت کا اضافہ کرتا ہے۔
شروع کرنے کے لیے، درج ذیل مراحل کو مکمل کریں:
- سے کوڈ اور نوٹ بک چلائیں۔ حصہ 1 اور حصہ 2.
- پر تشریف لے جائیں
part3-out-of-catalogکوڈ ریپوزٹری میں فولڈر۔
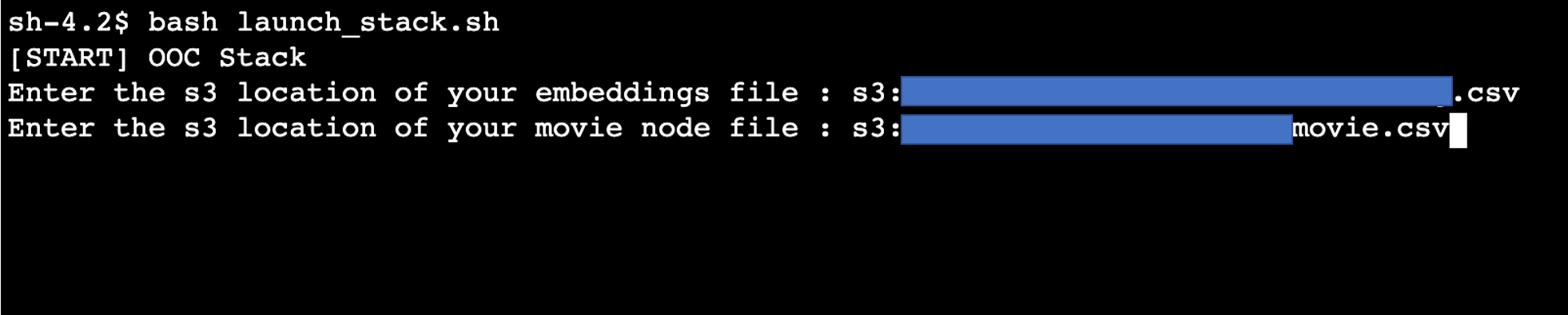
- کمانڈ کے ساتھ ٹرمینل سے AWS CDK لانچ کریں۔
bash launch_stack.sh. - حصہ 3 میں بنائے گئے S2 فائل کے دو راستے بطور ان پٹ فراہم کریں:
- مووی ایمبیڈنگز CSV فائل کا S3 راستہ۔
- مووی نوڈ فائل کا S3 راستہ۔
- اسکرپٹ میں تمام مطلوبہ وسائل کی فراہمی اور چلنا ختم ہونے تک انتظار کریں۔
- API گیٹ وے یو آر ایل کاپی کریں جسے AWS CDK اسکرپٹ پرنٹ کرتا ہے اور اسے محفوظ کرتا ہے۔ (ہم اسے بعد میں Streamlit ایپ کے لیے استعمال کرتے ہیں)۔

اوپن سرچ سروس ڈومین بنائیں
مثال کے مقاصد کے لیے، آپ ایک محفوظ VPC اور سب نیٹ کے اندر r6g.large.search مثال میں ایک Availability Zone پر سرچ ڈومین بناتے ہیں۔ نوٹ کریں کہ ایک پرائمری اور دو ریپلیکا مثالوں کے ساتھ تین دستیابی زونز پر سیٹ اپ کرنے کا بہترین عمل ہوگا۔
اوپن سرچ سروس انڈیکس بنائیں اور ڈیٹا اپ لوڈ کریں۔
آپ اوپن سرچ سروس انڈیکس بنانے کے لیے لیمبڈا فنکشنز (AWS CDK لانچ اسٹیک کمانڈ کا استعمال کرتے ہوئے تخلیق کردہ) استعمال کرتے ہیں۔ انڈیکس بنانا شروع کرنے کے لیے، درج ذیل مراحل کو مکمل کریں:
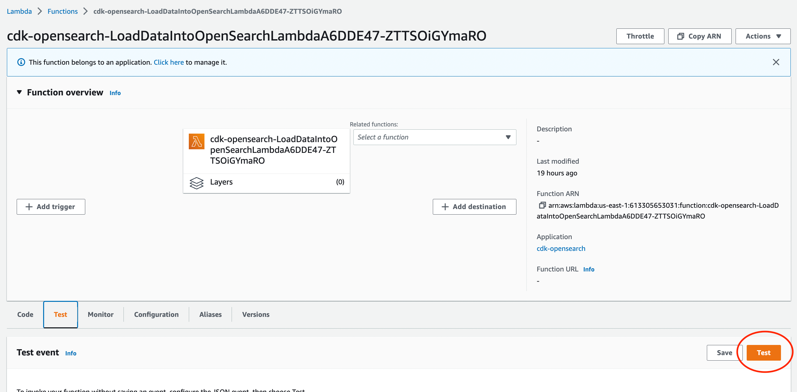
- لیمبڈا کنسول پر، کھولیں۔
LoadDataIntoOpenSearchLambdaلیمبڈا فنکشن۔
- پر ٹیسٹ ٹیب، منتخب کریں ٹیسٹ OpenSearch سروس انڈیکس میں ڈیٹا بنانے اور داخل کرنے کے لیے۔
اس لیمبڈا فنکشن کا درج ذیل کوڈ اس میں پایا جا سکتا ہے۔ part3-out-of-catalog/cdk/ooc/lambdas/LoadDataIntoOpenSearchLambda/lambda_handler.py:
فنکشن مندرجہ ذیل کام انجام دیتا ہے:
- آئی ایم ڈی بی کے جی مووی نوڈ فائل کو لوڈ کرتا ہے جس میں مووی میٹا ڈیٹا اور اس سے منسلک ایمبیڈنگز S3 فائل پاتھز سے ہوتی ہیں جو اسٹیک تخلیق فائل میں منتقل کیے گئے تھے۔
launch_stack.sh. - انڈیکس بنانے کے لیے ایک ہی ڈیٹا فریم بنانے کے لیے دو ان پٹ فائلوں کو ضم کرتا ہے۔
- Boto3 Python لائبریری کا استعمال کرتے ہوئے OpenSearch سروس کلائنٹ کو شروع کرتا ہے۔
- متن کے لیے دو اشاریہ جات بناتا ہے (
ooc_text) اور کے این این ایمبیڈنگ سرچ (ooc_knn) اور بڑے پیمانے پر مشترکہ ڈیٹا فریم سے ڈیٹا اپ لوڈ کرتا ہے۔ingest_data_into_opsتقریب.
ڈیٹا کے ادخال کے اس عمل میں 5-10 منٹ لگتے ہیں اور اس کے ذریعے نگرانی کی جا سکتی ہے۔ ایمیزون کلاؤڈ واچ پر لاگ ان باخبر رہنا لیمبڈا فنکشن کا ٹیب۔
آپ متن پر مبنی تلاش اور kNN ایمبیڈنگ پر مبنی تلاش کو فعال کرنے کے لیے دو اشاریہ جات بناتے ہیں۔ ٹیکسٹ سرچ اس فری فارم سوال کا نقشہ بناتی ہے جو صارف فلم کے عنوانات میں داخل کرتا ہے۔ kNN ایمبیڈنگ سرچ KG لیٹنٹ اسپیس سے بہترین ٹیکسٹ میچ کے قریب ترین فلموں کو آؤٹ پٹ کے طور پر واپس کرنے کے لیے تلاش کرتی ہے۔
حل کو مقامی ویب ایپلیکیشن کے طور پر تعینات کریں۔
اب جب کہ آپ کے پاس اوپن سرچ سروس پر ورکنگ ٹیکسٹ سرچ اور kNN انڈیکس ہے، آپ ML سے چلنے والی ویب ایپ بنانے کے لیے تیار ہیں۔
ہم استعمال کرتے ہیں streamlit اس ایپلیکیشن کے لیے سامنے کی تصویر بنانے کے لیے Python پیکیج۔ دی IMDb-Knowledge-Graph-Blog/part3-out-of-catalog/run_imdb_demo.py Python فائل ہماری GitHub repo اس قابلیت کو دریافت کرنے کے لیے مقامی ویب ایپ لانچ کرنے کے لیے مطلوبہ کوڈ ہے۔
کوڈ کو چلانے کے لیے، درج ذیل مراحل کو مکمل کریں:
- انسٹال کریں
streamlitاورaws_requests_authاپنے ٹرمینل میں درج ذیل کمانڈز کے ذریعے اپنے مقامی ورچوئل ازگر ماحول میں ازگر کا پیکیج:
- کوڈ میں API گیٹ وے یو آر ایل کے لیے پلیس ہولڈر کو AWS CDK کے تخلیق کردہ کے ساتھ تبدیل کریں:
api = '<ENTER URL OF THE API GATEWAY HERE>/opensearch-lambda?q={query_text}&numMovies={num_movies}&numRecs={num_recs}'
- کمانڈ کے ساتھ ویب ایپ لانچ کریں۔
streamlit run run_imdb_demo.pyآپ کے ٹرمینل سے۔
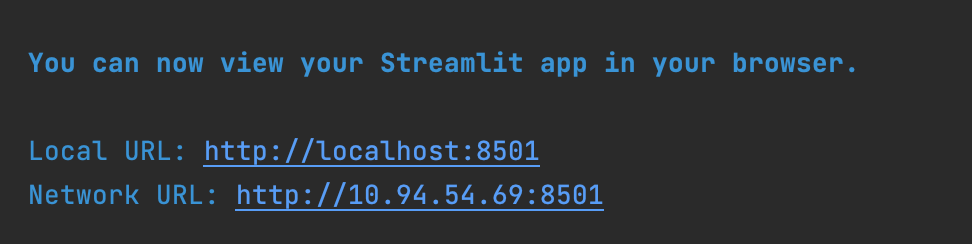
یہ اسکرپٹ ایک Streamlit ویب ایپ لانچ کرتی ہے جسے آپ کے ویب براؤزر میں حاصل کیا جا سکتا ہے۔ ویب ایپ کا URL اسکرپٹ آؤٹ پٹ سے حاصل کیا جا سکتا ہے، جیسا کہ درج ذیل اسکرین شاٹ میں دکھایا گیا ہے۔
ایپ نئے سرچ سٹرنگز، ہٹس کی تعداد، اور سفارشات کی تعداد کو قبول کرتی ہے۔ ہٹس کی تعداد اس کے مساوی ہے کہ ہمیں بیرونی (IMDb) کیٹلاگ سے کتنے مماثل OOC عنوانات حاصل کرنے چاہئیں۔ سفارشات کی تعداد اس کے مساوی ہے کہ ہمیں kNN ایمبیڈنگ تلاش کی بنیاد پر کسٹمر کیٹلاگ سے کتنے قریبی پڑوسیوں کو بازیافت کرنا چاہیے۔ درج ذیل کوڈ دیکھیں:
یہ ان پٹ (استفسار، کامیابیوں کی تعداد اور سفارشات) کو پاس کیا جاتا ہے۔ **-ReadFromOpenSearchLambda-** AWS CDK کی طرف سے API گیٹ وے کی درخواست کے ذریعے تخلیق کردہ Lambda فنکشن۔ یہ مندرجہ ذیل فنکشن میں کیا جاتا ہے:
اوپن سرچ سروس سے لیمبڈا فنکشن کے آؤٹ پٹ نتائج API گیٹ وے کو بھیجے جاتے ہیں اور Streamlit ایپ میں دکھائے جاتے ہیں۔
صاف کرو
آپ کمانڈ کے ذریعے AWS CDK کے تخلیق کردہ تمام وسائل کو حذف کر سکتے ہیں۔ npx cdk destroy –app “python3 appy.py” --all اسی مثال میں (اندر cdk فولڈر) جو اسٹیک لانچ کرنے کے لیے استعمال کیا گیا تھا (مندرجہ ذیل اسکرین شاٹ دیکھیں)۔
نتیجہ
اس پوسٹ میں، ہم نے آپ کو دکھایا کہ سیج میکر اور اوپن سرچ سروس کا استعمال کرتے ہوئے ٹیکسٹ اور kNN پر مبنی تلاش کا استعمال کرتے ہوئے OOC تلاش کے لیے حل کیسے بنایا جائے۔ آپ نے اپنے کیٹلاگ میں IMDb ٹائٹلز کے قریب ترین پڑوسیوں کو تلاش کرنے کے لیے حسب ضرورت نالج گراف ماڈل ایمبیڈنگز کا استعمال کیا۔ اب آپ، مثال کے طور پر، "The Rings of Power" کو تلاش کر سکتے ہیں، جسے Amazon Prime Video نے تیار کیا ہے، دوسرے سٹریمنگ پلیٹ فارمز پر اور اس وجہ سے کہ وہ تلاش کے نتائج کو کیسے بہتر بنا سکتے تھے۔
اس پوسٹ میں کوڈ کے نمونے کے بارے میں مزید معلومات کے لیے، دیکھیں GitHub repo. اسی طرح کی جدید ترین ML ایپلیکیشنز بنانے کے لیے Amazon ML Solutions Lab کے ساتھ تعاون کرنے کے بارے میں مزید جاننے کے لیے، دیکھیں ایمیزون مشین لرننگ سلوشنز لیب. IMDb ڈیٹاسیٹس کو لائسنس دینے کے بارے میں مزید معلومات کے لیے، ملاحظہ کریں۔ developer.imdb.com.
مصنفین کے بارے میں
 دیویا بھارگوی ایمیزون ایم ایل سلوشنز لیب میں ڈیٹا سائنٹسٹ اور میڈیا اینڈ انٹرٹینمنٹ ورٹیکل لیڈ ہے، جہاں وہ مشین لرننگ کا استعمال کرتے ہوئے AWS صارفین کے لیے اعلیٰ قدر کے کاروباری مسائل حل کرتی ہے۔ وہ تصویر/ویڈیو کی تفہیم، علمی گراف کی سفارش کے نظام، پیشن گوئی اشتہارات کے استعمال کے معاملات پر کام کرتی ہے۔
دیویا بھارگوی ایمیزون ایم ایل سلوشنز لیب میں ڈیٹا سائنٹسٹ اور میڈیا اینڈ انٹرٹینمنٹ ورٹیکل لیڈ ہے، جہاں وہ مشین لرننگ کا استعمال کرتے ہوئے AWS صارفین کے لیے اعلیٰ قدر کے کاروباری مسائل حل کرتی ہے۔ وہ تصویر/ویڈیو کی تفہیم، علمی گراف کی سفارش کے نظام، پیشن گوئی اشتہارات کے استعمال کے معاملات پر کام کرتی ہے۔
 گورو ریلی ایمیزون ایم ایل سلوشن لیب میں ڈیٹا سائنٹسٹ ہے، جہاں وہ مختلف عمودی حصوں میں AWS صارفین کے ساتھ کام کرتا ہے تاکہ ان کے کاروباری چیلنجوں کو حل کرنے کے لیے مشین لرننگ اور AWS کلاؤڈ سروسز کے استعمال کو تیز کیا جا سکے۔
گورو ریلی ایمیزون ایم ایل سلوشن لیب میں ڈیٹا سائنٹسٹ ہے، جہاں وہ مختلف عمودی حصوں میں AWS صارفین کے ساتھ کام کرتا ہے تاکہ ان کے کاروباری چیلنجوں کو حل کرنے کے لیے مشین لرننگ اور AWS کلاؤڈ سروسز کے استعمال کو تیز کیا جا سکے۔
 میتھیو روڈس ایک ڈیٹا سائنٹسٹ ہے جو میں Amazon ML Solutions Lab میں کام کر رہا ہوں۔ وہ مشین لرننگ پائپ لائنز بنانے میں مہارت رکھتا ہے جس میں نیچرل لینگویج پروسیسنگ اور کمپیوٹر ویژن جیسے تصورات شامل ہیں۔
میتھیو روڈس ایک ڈیٹا سائنٹسٹ ہے جو میں Amazon ML Solutions Lab میں کام کر رہا ہوں۔ وہ مشین لرننگ پائپ لائنز بنانے میں مہارت رکھتا ہے جس میں نیچرل لینگویج پروسیسنگ اور کمپیوٹر ویژن جیسے تصورات شامل ہیں۔
 کرن سندھوانی Amazon ML Solutions Lab میں ڈیٹا سائنٹسٹ ہے، جہاں وہ گہرے سیکھنے کے ماڈل بناتا اور تعینات کرتا ہے۔ وہ کمپیوٹر ویژن کے شعبے میں مہارت رکھتا ہے۔ اپنے فارغ وقت میں وہ پیدل سفر سے لطف اندوز ہوتا ہے۔
کرن سندھوانی Amazon ML Solutions Lab میں ڈیٹا سائنٹسٹ ہے، جہاں وہ گہرے سیکھنے کے ماڈل بناتا اور تعینات کرتا ہے۔ وہ کمپیوٹر ویژن کے شعبے میں مہارت رکھتا ہے۔ اپنے فارغ وقت میں وہ پیدل سفر سے لطف اندوز ہوتا ہے۔
 سوجی ادیشینہ AWS میں ایک اپلائیڈ سائنٹسٹ ہے جہاں وہ گرافس کے کاموں پر مشین لرننگ کے لیے گراف نیورل نیٹ ورک پر مبنی ماڈل تیار کرتا ہے جس میں فراڈ اور غلط استعمال کی ایپلی کیشنز، نالج گرافس، تجویز کنندہ سسٹمز، اور لائف سائنسز شامل ہیں۔ اپنے فارغ وقت میں، وہ پڑھنا اور کھانا پکانا پسند کرتا ہے۔
سوجی ادیشینہ AWS میں ایک اپلائیڈ سائنٹسٹ ہے جہاں وہ گرافس کے کاموں پر مشین لرننگ کے لیے گراف نیورل نیٹ ورک پر مبنی ماڈل تیار کرتا ہے جس میں فراڈ اور غلط استعمال کی ایپلی کیشنز، نالج گرافس، تجویز کنندہ سسٹمز، اور لائف سائنسز شامل ہیں۔ اپنے فارغ وقت میں، وہ پڑھنا اور کھانا پکانا پسند کرتا ہے۔
 ودیا ساگر روی پتی۔ Amazon ML Solutions Lab میں ایک مینیجر ہے، جہاں وہ بڑے پیمانے پر تقسیم شدہ نظاموں میں اپنے وسیع تجربے اور مشین لرننگ کے اپنے جذبے سے فائدہ اٹھاتا ہے تاکہ صنعت کے مختلف حصوں میں AWS صارفین کو ان کے AI اور کلاؤڈ کو اپنانے میں تیزی لا سکے۔
ودیا ساگر روی پتی۔ Amazon ML Solutions Lab میں ایک مینیجر ہے، جہاں وہ بڑے پیمانے پر تقسیم شدہ نظاموں میں اپنے وسیع تجربے اور مشین لرننگ کے اپنے جذبے سے فائدہ اٹھاتا ہے تاکہ صنعت کے مختلف حصوں میں AWS صارفین کو ان کے AI اور کلاؤڈ کو اپنانے میں تیزی لا سکے۔
- SEO سے چلنے والا مواد اور PR کی تقسیم۔ آج ہی بڑھا دیں۔
- پلیٹو بلاک چین۔ Web3 Metaverse Intelligence. علم میں اضافہ۔ یہاں تک رسائی حاصل کریں۔
- ماخذ: https://aws.amazon.com/blogs/machine-learning/power-recommendations-and-search-using-an-imdb-knowledge-graph-part-3/

