یہ تین حصوں کی سیریز میں دکھایا گیا ہے کہ گراف نیورل نیٹ ورکس (GNNs) کو کیسے استعمال کیا جائے اور ایمیزون نیپچون کا استعمال کرتے ہوئے فلم کی سفارشات تیار کرنے کے لئے IMDb اور Box Office Mojo Movies/TV/OTT قابل لائسنس ڈیٹا پیکج، جو تفریحی میٹا ڈیٹا کی ایک وسیع رینج فراہم کرتا ہے، بشمول 1 بلین سے زیادہ صارف کی درجہ بندی؛ 11 ملین سے زیادہ کاسٹ اور عملے کے ارکان کے لیے کریڈٹ؛ 9 ملین فلم، ٹی وی، اور تفریحی عنوانات؛ اور 60 سے زیادہ ممالک سے عالمی باکس آفس رپورٹنگ ڈیٹا۔ بہت سے AWS میڈیا اور تفریحی صارفین IMDb ڈیٹا کے ذریعے لائسنس دیتے ہیں۔ AWS ڈیٹا ایکسچینج مواد کی دریافت کو بہتر بنانے اور گاہک کی مصروفیت اور برقرار رکھنے میں اضافہ کرنے کے لیے۔
In حصہ 1، ہم نے GNNs کی ایپلی کیشنز پر تبادلہ خیال کیا، اور سوال کرنے کے لیے اپنے IMDb ڈیٹا کو کیسے تبدیل اور تیار کیا جائے۔ اس پوسٹ میں، ہم حصہ 3 میں اپنی کیٹلاگ سے باہر تلاش کرنے کے لیے استعمال ہونے والی سرایت پیدا کرنے کے لیے نیپچون کے استعمال کے عمل پر تبادلہ خیال کرتے ہیں۔ ہم بھی اوپر جاتے ہیں۔ ایمیزون نیپچون ایم ایل، نیپچون کی مشین لرننگ (ML) خصوصیت، اور کوڈ جو ہم اپنے ترقیاتی عمل میں استعمال کرتے ہیں۔ حصہ 3 میں، ہم اپنے علمی گراف ایمبیڈنگز کو کیٹلاگ سے باہر تلاش کے استعمال کے کیس میں لاگو کرنے کے طریقہ پر چلتے ہیں۔
حل جائزہ
بڑے منسلک ڈیٹا سیٹس میں اکثر قیمتی معلومات ہوتی ہیں جنہیں اکیلے انسانی وجدان کی بنیاد پر استفسارات کا استعمال کرتے ہوئے نکالنا مشکل ہو سکتا ہے۔ ML تکنیک اربوں رشتوں کے ساتھ گراف میں پوشیدہ ارتباط کو تلاش کرنے میں مدد کر سکتی ہے۔ یہ ارتباط مصنوعات کی سفارش کرنے، کریڈٹ کی اہلیت کی پیشین گوئی، دھوکہ دہی کی نشاندہی کرنے، اور استعمال کے بہت سے دیگر معاملات میں مددگار ثابت ہو سکتے ہیں۔
نیپچون ایم ایل کارآمد ایم ایل ماڈلز کو بڑے گرافس پر ہفتوں کے بجائے گھنٹوں میں بنانا اور تربیت دینا ممکن بناتا ہے۔ اس کو پورا کرنے کے لیے، نیپچون ایم ایل جی این این ٹیکنالوجی کا استعمال کرتا ہے۔ ایمیزون سیج میکر اور ڈیپ گراف لائبریری (DGL) (کونسا آزاد مصدر)۔ GNNs مصنوعی ذہانت میں ایک ابھرتا ہوا شعبہ ہے (مثال کے طور پر دیکھیں گراف نیورل نیٹ ورکس پر ایک جامع سروے)۔ DGL کے ساتھ GNNs استعمال کرنے کے بارے میں ہینڈ آن ٹیوٹوریل کے لیے، دیکھیں ڈیپ گراف لائبریری کے ساتھ گراف نیورل نیٹ ورک سیکھنا.
اس پوسٹ میں، ہم دکھاتے ہیں کہ ایمبیڈنگز بنانے کے لیے ہماری پائپ لائن میں نیپچون کو کیسے استعمال کیا جائے۔
درج ذیل خاکہ میں ڈاؤن لوڈ سے ایمبیڈنگ جنریشن تک IMDb ڈیٹا کے مجموعی بہاؤ کو دکھایا گیا ہے۔
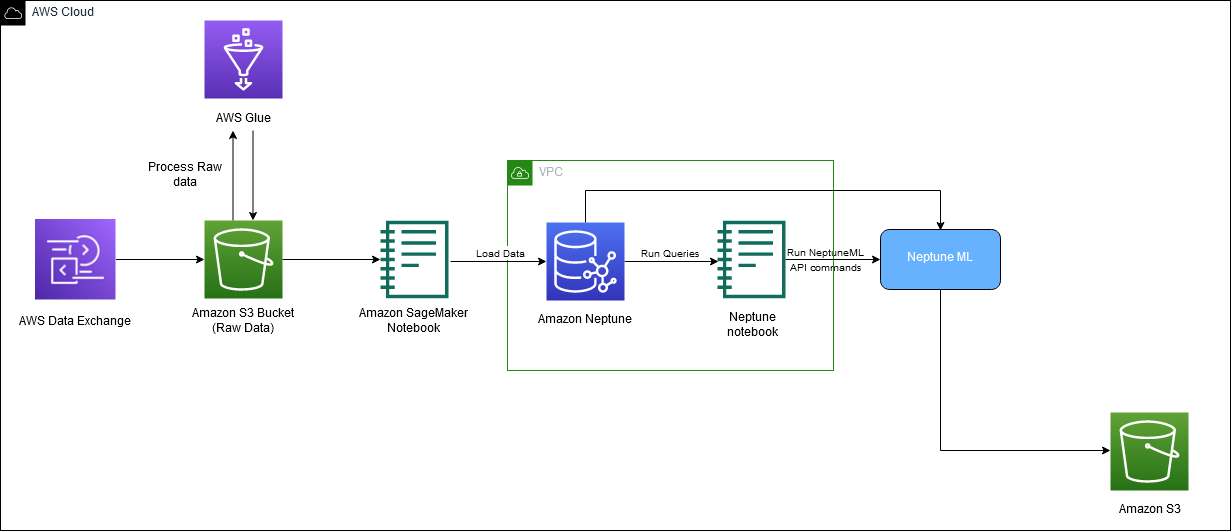
ہم حل کو نافذ کرنے کے لیے درج ذیل AWS خدمات استعمال کرتے ہیں:
اس پوسٹ میں، ہم آپ کو درج ذیل اعلیٰ سطحی مراحل سے گزرتے ہیں:
- ماحولیاتی متغیرات مرتب کریں۔
- ایکسپورٹ جاب بنائیں۔
- ڈیٹا پروسیسنگ کا کام بنائیں۔
- تربیتی کام جمع کروائیں۔
- ایمبیڈنگز ڈاؤن لوڈ کریں۔
نیپچون ایم ایل کمانڈز کے لیے کوڈ
ہم اس حل کو نافذ کرنے کے حصے کے طور پر درج ذیل کمانڈز استعمال کرتے ہیں۔
ہم استعمال کرتے ہیں neptune_ml export اسٹیٹس چیک کرنے یا نیپچون ایم ایل ایکسپورٹ کا عمل شروع کرنے کے لیے، اور neptune_ml training نیپچون ایم ایل ماڈل ٹریننگ جاب شروع کرنے اور اس کی حیثیت کو چیک کرنے کے لیے۔
ان اور دیگر احکامات کے بارے میں مزید معلومات کے لیے، رجوع کریں۔ اپنی نوٹ بک میں نیپچون ورک بینچ کے جادو کا استعمال.
شرائط
اس پوسٹ کے ساتھ پیروی کرنے کے لیے، آپ کے پاس درج ذیل چیزیں ہونی چاہئیں:
- An AWS اکاؤنٹ
- SageMaker، Amazon S3، اور AWS CloudFormation سے واقفیت
- نیپچون کلسٹر میں بھرا ہوا گراف ڈیٹا (دیکھیں۔ حصہ 1 مزید معلومات کے لیے)
ماحولیاتی متغیرات مرتب کریں۔
اس سے پہلے کہ ہم شروع کریں، آپ کو درج ذیل متغیرات کو ترتیب دے کر اپنے ماحول کو ترتیب دینے کی ضرورت ہوگی: s3_bucket_uri اور processed_folder. s3_bucket_uri حصہ 1 اور میں استعمال ہونے والی بالٹی کا نام ہے۔ processed_folder ایکسپورٹ جاب سے آؤٹ پٹ کے لیے ایمیزون S3 کا مقام ہے۔
ایکسپورٹ جاب بنائیں
حصہ 1 میں، ہم نے اپنا ڈیٹا Neptune DB کلسٹر سے Amazon S3 کو مطلوبہ فارمیٹ میں ایکسپورٹ کرنے کے لیے SageMaker نوٹ بک اور ایکسپورٹ سروس بنائی ہے۔
اب چونکہ ہمارا ڈیٹا لوڈ ہو چکا ہے اور ایکسپورٹ سروس بن گئی ہے، ہمیں ایکسپورٹ جاب بنانے کی ضرورت ہے اسے شروع کریں۔ ایسا کرنے کے لئے، ہم استعمال کرتے ہیں NeptuneExportApiUri اور برآمدی کام کے لیے پیرامیٹرز بنائیں۔ درج ذیل کوڈ میں، ہم متغیرات استعمال کرتے ہیں۔ expo اور export_params. سیٹ کریں expo آپ کے لئے NeptuneExportApiUri قدر، جسے آپ پر تلاش کر سکتے ہیں۔ نتائج آپ کے CloudFormation اسٹیک کا ٹیب۔ کے لیے export_params، ہم آپ کے نیپچون کلسٹر کا اختتامی نقطہ استعمال کرتے ہیں اور اس کی قدر فراہم کرتے ہیں۔ outputS3path، جو برآمدی کام سے آؤٹ پٹ کے لیے Amazon S3 کا مقام ہے۔
ایکسپورٹ جاب جمع کرانے کے لیے درج ذیل کمانڈ کا استعمال کریں:
ایکسپورٹ جاب کی حیثیت کو چیک کرنے کے لیے درج ذیل کمانڈ کا استعمال کریں:
آپ کا کام مکمل ہونے کے بعد، سیٹ کریں۔ processed_folder پروسیسر شدہ نتائج کا ایمیزون S3 مقام فراہم کرنے کے لیے متغیر:
ڈیٹا پروسیسنگ کا کام بنائیں
اب جبکہ ایکسپورٹ ہو چکا ہے، ہم نیپچون ایم ایل ٹریننگ کے عمل کے لیے ڈیٹا تیار کرنے کے لیے ڈیٹا پروسیسنگ کا کام بناتے ہیں۔ یہ کچھ مختلف طریقوں سے کیا جا سکتا ہے۔ اس قدم کے لیے، آپ کو تبدیل کر سکتے ہیں۔ job_name اور modelType متغیرات، لیکن دیگر تمام پیرامیٹرز کو ایک جیسا رہنا چاہیے۔ اس کوڈ کا بنیادی حصہ ہے modelType پیرامیٹر، جو یا تو متضاد گراف ماڈل ہو سکتا ہے (heterogeneous) یا علمی گراف (kge).
برآمدی کام بھی شامل ہے۔ training-data-configuration.json. اس فائل کو کسی ایسے نوڈس یا کناروں کو شامل کرنے یا ہٹانے کے لیے استعمال کریں جو آپ تربیت کے لیے فراہم نہیں کرنا چاہتے ہیں (مثال کے طور پر، اگر آپ دو نوڈس کے درمیان لنک کی پیش گوئی کرنا چاہتے ہیں، تو آپ اس کنفیگریشن فائل میں اس لنک کو ہٹا سکتے ہیں)۔ اس بلاگ پوسٹ کے لیے ہم اصل کنفیگریشن فائل استعمال کرتے ہیں۔ مزید معلومات کے لیے، دیکھیں ٹریننگ کنفیگریشن فائل میں ترمیم کرنا.
درج ذیل کوڈ کے ساتھ اپنی ڈیٹا پروسیسنگ جاب بنائیں:
ایکسپورٹ جاب کی حیثیت کو چیک کرنے کے لیے درج ذیل کمانڈ کا استعمال کریں:
تربیتی کام جمع کروائیں۔
پروسیسنگ کا کام مکمل ہونے کے بعد، ہم اپنا تربیتی کام شروع کر سکتے ہیں، جہاں ہم اپنی ایمبیڈنگز بناتے ہیں۔ ہم مثال کے طور پر ml.m5.24xlarge کی تجویز کرتے ہیں، لیکن آپ اسے اپنی کمپیوٹنگ کی ضروریات کے مطابق تبدیل کر سکتے ہیں۔ درج ذیل کوڈ دیکھیں:
ہم تربیتی کام کے لیے ID حاصل کرنے کے لیے training_results متغیر پرنٹ کرتے ہیں۔ اپنے کام کی حیثیت کو چیک کرنے کے لیے درج ذیل کمانڈ کا استعمال کریں:
%neptune_ml training status --job-id {training_results['id']} --store-to training_status_results
ایمبیڈنگز ڈاؤن لوڈ کریں۔
آپ کا تربیتی کام مکمل ہونے کے بعد، آخری مرحلہ اپنی خام ایمبیڈنگز کو ڈاؤن لوڈ کرنا ہے۔ مندرجہ ذیل اقدامات آپ کو دکھاتے ہیں کہ KGE استعمال کرکے بنائی گئی ایمبیڈنگز کو کیسے ڈاؤن لوڈ کیا جائے (آپ اسی عمل کو RGCN کے لیے استعمال کر سکتے ہیں)۔
درج ذیل کوڈ میں، ہم استعمال کرتے ہیں۔ neptune_ml.get_mapping() اور get_embeddings() میپنگ فائل کو ڈاؤن لوڈ کرنے کے لیے (mapping.info) اور خام ایمبیڈنگ فائل (entity.npy)۔ پھر ہمیں مناسب ایمبیڈنگز کو ان کے متعلقہ IDs پر نقشہ بنانے کی ضرورت ہے۔
RGCNs کو ڈاؤن لوڈ کرنے کے لیے، ماڈل ٹائپ پیرامیٹر کے ساتھ ڈیٹا پر کارروائی کرکے نئے تربیتی جاب کے نام کے ساتھ اسی عمل کو فالو کریں heterogeneous، پھر اپنے ماڈل کو ماڈل نام کے پیرامیٹر کے ساتھ تربیت دیں۔ rgcn دیکھنا یہاں مزید تفصیلات کے لیے. ایک بار جب یہ ختم ہوجائے تو کال کریں۔ get_mapping اور get_embeddings آپ کے نئے ڈاؤن لوڈ کرنے کے فنکشنز mapping.info اور entity.npy فائلوں. آپ کے پاس ہستی اور نقشہ سازی کی فائلیں ہونے کے بعد، CSV فائل بنانے کا عمل یکساں ہے۔
آخر میں، اپنے ایمبیڈنگز کو اپنے مطلوبہ ایمیزون S3 مقام پر اپ لوڈ کریں:
یقینی بنائیں کہ آپ کو یہ S3 مقام یاد ہے، آپ کو اسے حصہ 3 میں استعمال کرنے کی ضرورت ہوگی۔
صاف کرو
حل استعمال کرنے کے بعد، جاری چارجز سے بچنے کے لیے کسی بھی وسائل کو صاف کرنا یقینی بنائیں۔
نتیجہ
اس پوسٹ میں، ہم نے آئی ایم ڈی بی ڈیٹا سے جی این این ایمبیڈنگز کو تربیت دینے کے لیے نیپچون ایم ایل کا استعمال کرنے کے طریقہ پر تبادلہ خیال کیا۔
نالج گراف ایمبیڈنگز کی کچھ متعلقہ ایپلی کیشنز تصورات ہیں جیسے کیٹلاگ سے باہر کی تلاش، مواد کی سفارشات، ٹارگٹڈ ایڈورٹائزنگ، گمشدہ لنکس کی پیشین گوئی، عمومی تلاش، اور ہمہ گیر تجزیہ۔ کیٹلاگ سے باہر تلاش ایسے مواد کو تلاش کرنے کا عمل ہے جو آپ کے پاس نہیں ہے، اور آپ کے کیٹلاگ میں موجود مواد کو تلاش کرنے یا تجویز کرنے کا عمل ہے جو صارف کے ممکنہ حد تک قریب ہے۔ ہم حصہ 3 میں کیٹلاگ سے باہر کی تلاش میں گہرائی میں ڈوبتے ہیں۔
مصنفین کے بارے میں
 میتھیو روڈس ایک ڈیٹا سائنٹسٹ ہے جو میں Amazon ML Solutions Lab میں کام کر رہا ہوں۔ وہ مشین لرننگ پائپ لائنز بنانے میں مہارت رکھتا ہے جس میں نیچرل لینگویج پروسیسنگ اور کمپیوٹر ویژن جیسے تصورات شامل ہیں۔
میتھیو روڈس ایک ڈیٹا سائنٹسٹ ہے جو میں Amazon ML Solutions Lab میں کام کر رہا ہوں۔ وہ مشین لرننگ پائپ لائنز بنانے میں مہارت رکھتا ہے جس میں نیچرل لینگویج پروسیسنگ اور کمپیوٹر ویژن جیسے تصورات شامل ہیں۔
 دیویا بھارگوی ایمیزون ایم ایل سلوشنز لیب میں ڈیٹا سائنٹسٹ اور میڈیا اینڈ انٹرٹینمنٹ ورٹیکل لیڈ ہے، جہاں وہ مشین لرننگ کا استعمال کرتے ہوئے AWS صارفین کے لیے اعلیٰ قدر کے کاروباری مسائل حل کرتی ہے۔ وہ تصویر/ویڈیو کی تفہیم، علمی گراف کی سفارش کے نظام، پیشن گوئی اشتہارات کے استعمال کے معاملات پر کام کرتی ہے۔
دیویا بھارگوی ایمیزون ایم ایل سلوشنز لیب میں ڈیٹا سائنٹسٹ اور میڈیا اینڈ انٹرٹینمنٹ ورٹیکل لیڈ ہے، جہاں وہ مشین لرننگ کا استعمال کرتے ہوئے AWS صارفین کے لیے اعلیٰ قدر کے کاروباری مسائل حل کرتی ہے۔ وہ تصویر/ویڈیو کی تفہیم، علمی گراف کی سفارش کے نظام، پیشن گوئی اشتہارات کے استعمال کے معاملات پر کام کرتی ہے۔
 گورو ریلی ایمیزون ایم ایل سلوشن لیب میں ڈیٹا سائنٹسٹ ہے، جہاں وہ مختلف عمودی حصوں میں AWS صارفین کے ساتھ کام کرتا ہے تاکہ ان کے کاروباری چیلنجوں کو حل کرنے کے لیے مشین لرننگ اور AWS کلاؤڈ سروسز کے استعمال کو تیز کیا جا سکے۔
گورو ریلی ایمیزون ایم ایل سلوشن لیب میں ڈیٹا سائنٹسٹ ہے، جہاں وہ مختلف عمودی حصوں میں AWS صارفین کے ساتھ کام کرتا ہے تاکہ ان کے کاروباری چیلنجوں کو حل کرنے کے لیے مشین لرننگ اور AWS کلاؤڈ سروسز کے استعمال کو تیز کیا جا سکے۔
 کرن سندھوانی Amazon ML Solutions Lab میں ڈیٹا سائنٹسٹ ہے، جہاں وہ گہرے سیکھنے کے ماڈل بناتا اور تعینات کرتا ہے۔ وہ کمپیوٹر ویژن کے شعبے میں مہارت رکھتا ہے۔ اپنے فارغ وقت میں وہ پیدل سفر سے لطف اندوز ہوتا ہے۔
کرن سندھوانی Amazon ML Solutions Lab میں ڈیٹا سائنٹسٹ ہے، جہاں وہ گہرے سیکھنے کے ماڈل بناتا اور تعینات کرتا ہے۔ وہ کمپیوٹر ویژن کے شعبے میں مہارت رکھتا ہے۔ اپنے فارغ وقت میں وہ پیدل سفر سے لطف اندوز ہوتا ہے۔
 سوجی ادیشینہ AWS میں ایک اپلائیڈ سائنٹسٹ ہے جہاں وہ گرافس کے کاموں پر مشین لرننگ کے لیے گراف نیورل نیٹ ورک پر مبنی ماڈل تیار کرتا ہے جس میں فراڈ اور غلط استعمال کی ایپلی کیشنز، نالج گرافس، تجویز کنندہ سسٹمز، اور لائف سائنسز شامل ہیں۔ اپنے فارغ وقت میں، وہ پڑھنا اور کھانا پکانا پسند کرتا ہے۔
سوجی ادیشینہ AWS میں ایک اپلائیڈ سائنٹسٹ ہے جہاں وہ گرافس کے کاموں پر مشین لرننگ کے لیے گراف نیورل نیٹ ورک پر مبنی ماڈل تیار کرتا ہے جس میں فراڈ اور غلط استعمال کی ایپلی کیشنز، نالج گرافس، تجویز کنندہ سسٹمز، اور لائف سائنسز شامل ہیں۔ اپنے فارغ وقت میں، وہ پڑھنا اور کھانا پکانا پسند کرتا ہے۔
 ودیا ساگر روی پتی۔ Amazon ML Solutions Lab میں ایک مینیجر ہے، جہاں وہ بڑے پیمانے پر تقسیم شدہ نظاموں میں اپنے وسیع تجربے اور مشین لرننگ کے اپنے جذبے سے فائدہ اٹھاتا ہے تاکہ صنعت کے مختلف حصوں میں AWS صارفین کو ان کے AI اور کلاؤڈ کو اپنانے میں تیزی لا سکے۔
ودیا ساگر روی پتی۔ Amazon ML Solutions Lab میں ایک مینیجر ہے، جہاں وہ بڑے پیمانے پر تقسیم شدہ نظاموں میں اپنے وسیع تجربے اور مشین لرننگ کے اپنے جذبے سے فائدہ اٹھاتا ہے تاکہ صنعت کے مختلف حصوں میں AWS صارفین کو ان کے AI اور کلاؤڈ کو اپنانے میں تیزی لا سکے۔
- SEO سے چلنے والا مواد اور PR کی تقسیم۔ آج ہی بڑھا دیں۔
- پلیٹو بلاک چین۔ Web3 Metaverse Intelligence. علم میں اضافہ۔ یہاں تک رسائی حاصل کریں۔
- ماخذ: https://aws.amazon.com/blogs/machine-learning/part-2-power-recommendations-and-search-using-an-imdb-knowledge-graph/

