یہ پوسٹ ڈیوک انرجی سے ٹریوس برونسن اور برائن ایل ولکرسن کے ساتھ مل کر لکھی گئی ہے۔
مشین لرننگ (ML) ہر صنعت، عمل اور کاروبار کو تبدیل کر رہی ہے، لیکن کامیابی کا راستہ ہمیشہ سیدھا نہیں ہوتا۔ اس بلاگ پوسٹ میں، ہم یہ ظاہر کرتے ہیں کہ کیسے ڈیوک انرجیایک Fortune 150 کمپنی جس کا صدر دفتر چارلوٹ، NC. میں ہے، اس کے ساتھ تعاون کیا AWS مشین لرننگ سلوشنز لیب (MLSL) لکڑی کے یوٹیلیٹی پولز کے معائنہ کو خودکار بنانے اور بجلی کی بندش، املاک کو پہنچنے والے نقصان اور یہاں تک کہ چوٹوں کو روکنے میں مدد کرنے کے لیے کمپیوٹر ویژن کا استعمال کرنا۔
بجلی کا گرڈ کھمبوں، لائنوں اور پاور پلانٹس پر مشتمل ہوتا ہے تاکہ لاکھوں گھروں اور کاروباروں کو بجلی پیدا کی جا سکے۔ یہ افادیت کے کھمبے بنیادی ڈھانچے کے اہم اجزاء ہیں اور مختلف ماحولیاتی عوامل جیسے ہوا، بارش اور برف کے تابع ہیں، جو اثاثوں کو نقصان پہنچا سکتے ہیں۔ یہ بہت اہم ہے کہ یوٹیلیٹی پولز کا باقاعدگی سے معائنہ کیا جاتا ہے اور ان کی خرابیوں کو روکنے کے لیے ان کی دیکھ بھال کی جاتی ہے جو بجلی کی بندش، املاک کو نقصان پہنچانے اور یہاں تک کہ زخمی ہونے کا باعث بن سکتی ہیں۔ زیادہ تر پاور یوٹیلیٹی کمپنیاں، بشمول ڈیوک انرجی، اپنے ٹرانسمیشن اور ڈسٹری بیوشن نیٹ ورک سے متعلق بے ضابطگیوں کی نشاندہی کرنے کے لیے یوٹیلیٹی پولز کے دستی بصری معائنہ کا استعمال کرتی ہیں۔ لیکن یہ طریقہ مہنگا اور وقت طلب ہوسکتا ہے، اور اس کے لیے ضروری ہے کہ پاور ٹرانسمیشن لائن ورکرز سخت حفاظتی پروٹوکول پر عمل کریں۔
ڈیوک انرجی نے ماضی میں مصنوعی ذہانت کا استعمال کیا ہے تاکہ روزمرہ کے کاموں میں بڑی کامیابی حاصل کی جا سکے۔ کمپنی نے AI کو جنریشن اثاثوں اور اہم انفراسٹرکچر کا معائنہ کرنے کے لیے استعمال کیا ہے اور یوٹیلیٹی پولز کے معائنے کے لیے بھی AI کو لاگو کرنے کے مواقع تلاش کر رہی ہے۔ ڈیوک انرجی کے ساتھ AWS مشین لرننگ سلوشنز لیب کی مصروفیت کے دوران، یوٹیلیٹی نے جدید کمپیوٹر ویژن تکنیکوں کا استعمال کرتے ہوئے لکڑی کے کھمبوں میں بے ضابطگیوں کا پتہ لگانے کے لیے اپنے کام کو آگے بڑھایا۔
اہداف اور استعمال کا معاملہ
ڈیوک انرجی اور مشین لرننگ سلوشنز لیب کے درمیان اس مصروفیت کا مقصد 33,000 میل ٹرانسمیشن لائنوں میں لکڑی کے کھمبے سے متعلق تمام مسائل کی شناخت اور جائزہ کے عمل کو خودکار بنانے کے لیے سیکڑوں ہزاروں ہائی ریزولوشن فضائی تصاویر کا معائنہ کرنے کے لیے مشین لرننگ کا فائدہ اٹھانا ہے۔ . اس مقصد سے ڈیوک انرجی کو گرڈ کی لچک کو بہتر بنانے اور بروقت نقائص کی نشاندہی کرکے حکومتی ضوابط کی تعمیل کرنے میں مزید مدد ملے گی۔ یہ ایندھن اور مزدوری کے اخراجات کو بھی کم کرے گا، ساتھ ہی غیر ضروری ٹرک رولز کو کم سے کم کرکے کاربن کے اخراج کو بھی کم کرے گا۔ آخر میں، یہ خطوں اور موسمی حالات سے سمجھوتہ کرنے والے میلوں، کھمبوں پر چڑھنے اور جسمانی معائنہ کے خطرات کو کم کرکے حفاظت کو بھی بہتر بنائے گا۔
مندرجہ ذیل حصوں میں، ہم لکڑی کی افادیت کے کھمبوں سے متعلق بے ضابطگی کا پتہ لگانے کے لیے مضبوط اور موثر ماڈل تیار کرنے سے وابستہ اہم چیلنجز پیش کرتے ہیں۔ ہم مطلوبہ ماڈل کی کارکردگی کو حاصل کرنے کے لیے استعمال کی جانے والی مختلف ڈیٹا پری پروسیسنگ تکنیکوں سے وابستہ کلیدی چیلنجوں اور قیاسات کو بھی بیان کرتے ہیں۔ اگلا، ہم اپنے حتمی ماڈلز کی تشخیص کے ساتھ ماڈل کی کارکردگی کا جائزہ لینے کے لیے استعمال ہونے والے کلیدی میٹرکس پیش کرتے ہیں۔ اور آخر میں، ہم مختلف جدید ترین زیر نگرانی اور غیر زیر نگرانی ماڈلنگ تکنیکوں کا موازنہ کرتے ہیں۔
چیلنجز
فضائی امیجز کا استعمال کرتے ہوئے بے ضابطگیوں کا پتہ لگانے کے لیے ماڈل کی تربیت سے منسلک ایک اہم چیلنج تصویر کا غیر یکساں سائز ہے۔ مندرجہ ذیل اعداد و شمار ڈیوک انرجی سے سیٹ کردہ نمونہ ڈیٹا کی تصویر کی اونچائی اور چوڑائی کی تقسیم کو ظاہر کرتا ہے۔ یہ دیکھا جا سکتا ہے کہ تصویروں میں سائز کے لحاظ سے بہت زیادہ فرق ہے۔ اسی طرح، تصاویر کا سائز بھی اہم چیلنجوں کا باعث بنتا ہے۔ ان پٹ امیجز کا سائز ہزاروں پکسلز چوڑا اور ہزاروں پکسلز لمبا ہوتا ہے۔ یہ تصویر میں چھوٹے غیر معمولی علاقوں کی شناخت کے لیے ماڈل کی تربیت کے لیے بھی مثالی نہیں ہے۔
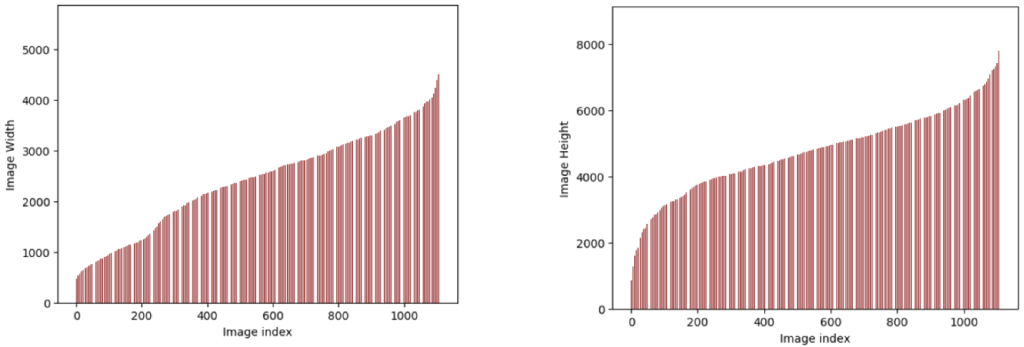
نمونہ ڈیٹا سیٹ کے لیے تصویر کی اونچائی اور چوڑائی کی تقسیم
اس کے علاوہ، ان پٹ امیجز میں پس منظر کی غیر متعلقہ معلومات کی ایک بڑی مقدار ہوتی ہے جیسے کہ پودوں، کاریں، فارم کے جانور وغیرہ۔ پس منظر کی معلومات کے نتیجے میں ماڈل کی بہترین کارکردگی ہو سکتی ہے۔ ہمارے جائزے کی بنیاد پر، تصویر کا صرف 5% لکڑی کے کھمبے پر مشتمل ہے اور بے ضابطگیاں اس سے بھی چھوٹی ہیں۔ یہ ہائی ریزولیوشن امیجز میں بے ضابطگیوں کی شناخت اور مقامی بنانے کے لیے ایک بڑا چیلنج ہے۔ پورے ڈیٹا سیٹ کے مقابلے میں بے ضابطگیوں کی تعداد نمایاں طور پر کم ہے۔ پورے ڈیٹا سیٹ میں صرف 0.12% بے ضابطگیاں ہیں (یعنی 1.2 تصاویر میں سے 1000 بے ضابطگیاں)۔ آخر میں، زیر نگرانی مشین لرننگ ماڈل کی تربیت کے لیے کوئی لیبل لگا ڈیٹا دستیاب نہیں ہے۔ اگلا، ہم بیان کرتے ہیں کہ ہم ان چیلنجوں سے کیسے نمٹتے ہیں اور اپنے مجوزہ طریقہ کی وضاحت کرتے ہیں۔
حل جائزہ
ماڈلنگ کی تکنیک
مندرجہ ذیل تصویر ہماری تصویری کارروائی اور بے ضابطگی کا پتہ لگانے والی پائپ لائن کو ظاہر کرتی ہے۔ ہم نے پہلے ڈیٹا درآمد کیا۔ ایمیزون سادہ اسٹوریج سروس (ایمیزون S3) کا استعمال کرتے ہوئے ایمیزون سیج میکر اسٹوڈیو. ہم نے ماڈل کی کارکردگی کو بہتر بنانے کے لیے اوپر نمایاں کیے گئے کچھ چیلنجوں سے نمٹنے کے لیے ڈیٹا پروسیسنگ کی مختلف تکنیکوں کو مزید استعمال کیا۔ ڈیٹا پری پروسیسنگ کے بعد، ہم نے ایمیزون کو ملازمت دی۔ شناخت حسب ضرورت لیبلز ڈیٹا لیبلنگ کے لیے۔ لیبل شدہ ڈیٹا کو مزید زیر نگرانی ایم ایل ماڈلز کو تربیت دینے کے لیے استعمال کیا جاتا ہے جیسے کہ ویژن ٹرانسفارمر، ایمیزون ویژن کے لئے تلاش، اور آٹو گلوون بے ضابطگی کا پتہ لگانے کے لیے۔
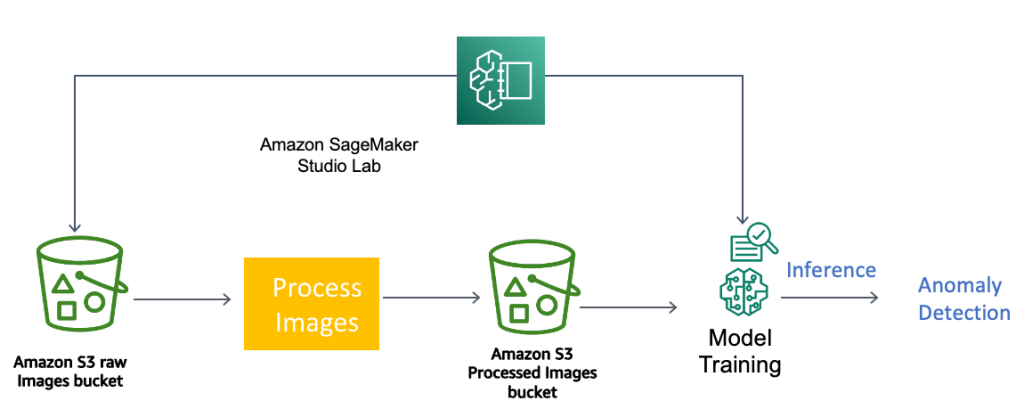
امیج پروسیسنگ اور بے ضابطگی کا پتہ لگانے والی پائپ لائن
مندرجہ ذیل اعداد و شمار ہمارے مجوزہ نقطہ نظر کے تفصیلی جائزہ کو ظاہر کرتا ہے جس میں ڈیٹا پروسیسنگ پائپ لائن اور بے ضابطگی کا پتہ لگانے کے لیے استعمال کیے گئے مختلف ML الگورتھم شامل ہیں۔ سب سے پہلے، ہم ڈیٹا پروسیسنگ پائپ لائن میں شامل اقدامات کی وضاحت کریں گے۔ اس کے بعد، ہم مطلوبہ کارکردگی کے اہداف کو حاصل کرنے کے لیے اس مصروفیت کے دوران استعمال کی جانے والی مختلف ماڈلنگ تکنیکوں سے متعلق تفصیلات اور بصیرت کی وضاحت کریں گے۔

ڈیٹا پروپوزل کی گذارش
مجوزہ ڈیٹا پری پروسیسنگ پائپ لائن میں شامل ہیں۔ ڈیٹا مانکیکرن, دلچسپی کے علاقے کی شناخت (ROI), ڈیٹا میں اضافہ، ڈیٹا کی تقسیم، اور آخر ڈیٹا لیبلنگ. ہر قدم کا مقصد ذیل میں بیان کیا گیا ہے:
ڈیٹا کی معیاری کاری
ہماری ڈیٹا پروسیسنگ پائپ لائن کے پہلے مرحلے میں ڈیٹا کی معیاری کاری شامل ہے۔ اس مرحلے میں، ہر تصویر کو تراش کر 224 X 224 پکسلز کے نان اوورلیپنگ پیچ میں تقسیم کیا جاتا ہے۔ اس قدم کا مقصد یکساں سائز کے پیچ تیار کرنا ہے جو مزید ایک ایم ایل ماڈل کی تربیت اور ہائی ریزولیوشن امیجز میں بے ضابطگیوں کو مقامی بنانے کے لیے استعمال کیا جا سکتا ہے۔
دلچسپی کے علاقے کی شناخت (ROI)
ان پٹ ڈیٹا ہائی ریزولیوشن امیجز پر مشتمل ہوتا ہے جس میں بڑی مقدار میں غیر متعلقہ پس منظر کی معلومات ہوتی ہیں (یعنی نباتات، مکانات، کاریں، گھوڑے، گائے وغیرہ)۔ ہمارا مقصد لکڑی کے کھمبوں سے متعلق بے ضابطگیوں کی نشاندہی کرنا ہے۔ ROI (یعنی لکڑی کے کھمبے پر مشتمل پیچ) کی شناخت کرنے کے لیے، ہم نے Amazon Recognition کسٹم لیبلنگ کا استعمال کیا۔ ہم نے ROI اور پس منظر کی تصاویر دونوں پر مشتمل 3k لیبل والی تصاویر کا استعمال کرتے ہوئے ایک Amazon Recognition کسٹم لیبل ماڈل کو تربیت دی۔ ماڈل کا مقصد ROI اور پس منظر کی تصاویر کے درمیان بائنری درجہ بندی کرنا ہے۔ پس منظر کی معلومات کے طور پر شناخت شدہ پیچ کو ضائع کر دیا جاتا ہے جبکہ ROI کے بطور پیش گوئی کی گئی فصلوں کو اگلے مرحلے میں استعمال کیا جاتا ہے۔ مندرجہ ذیل تصویر پائپ لائن کو ظاہر کرتی ہے جو ROI کی شناخت کرتی ہے۔ ہم نے 1,110 لکڑی کی تصویروں کی نان اوور لیپنگ فصلوں کا ایک نمونہ تیار کیا جس سے 244,673 فصلیں پیدا ہوئیں۔ ہم نے ان تصاویر کو ایک Amazon Recognition کسٹم ماڈل میں بطور ان پٹ استعمال کیا جس نے 11,356 فصلوں کو ROI کے طور پر شناخت کیا۔ آخر میں، ہم نے ان 11,356 پیچ میں سے ہر ایک کی دستی طور پر تصدیق کی۔ دستی معائنے کے دوران، ہم نے شناخت کیا کہ ماڈل ROI کے طور پر 10,969 میں سے 11,356 لکڑی کے پیچ کی درست پیش گوئی کرنے کے قابل تھا۔ دوسرے الفاظ میں، ماڈل نے 96 فیصد درستگی حاصل کی۔
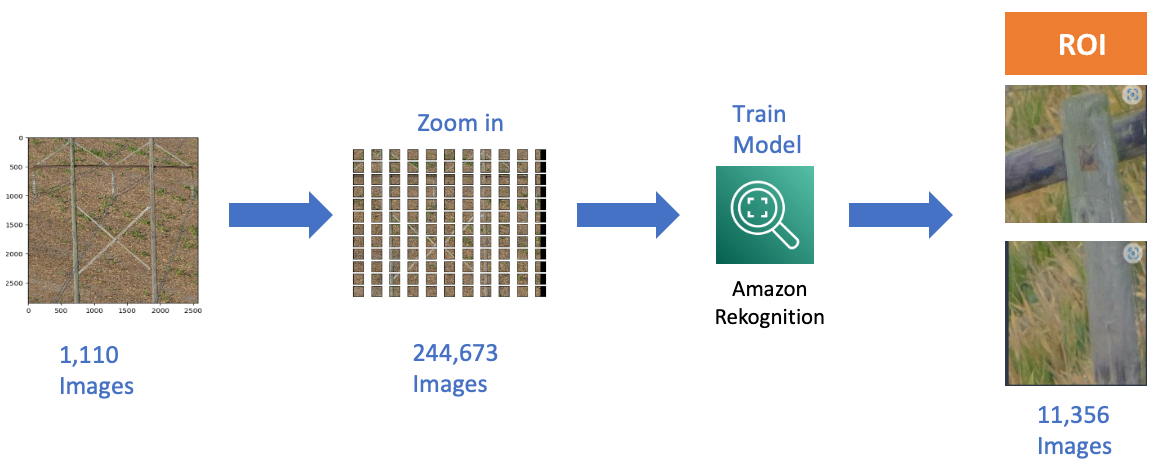
دلچسپی کے علاقے کی شناخت
ڈیٹا لیبلنگ
تصاویر کے دستی معائنہ کے دوران، ہم نے ہر تصویر کو ان کے متعلقہ لیبلز کے ساتھ لیبل بھی کیا۔ امیجز کے متعلقہ لیبلز میں لکڑی کا پیچ، نان ووڈ پیچ، نان اسٹرکچر، نان ووڈ پیچ اور آخر میں لکڑی کے پیچ شامل ہیں جن میں بے ضابطگی ہے۔ مندرجہ ذیل اعداد و شمار Amazon Recognition کسٹم لیبلنگ کا استعمال کرتے ہوئے تصاویر کے نام کو ظاہر کرتا ہے۔

ڈیٹا میں اضافہ
لیبل لگائے گئے ڈیٹا کی محدود مقدار کو دیکھتے ہوئے جو تربیت کے لیے دستیاب تھا، ہم نے تمام پیچ کو افقی پلٹ کر تربیتی ڈیٹا سیٹ کو بڑھایا۔ اس سے ہمارے ڈیٹا سیٹ کے سائز کو دوگنا کرنے کا موثر اثر پڑا۔
قطعہ
ہم نے Amazon Recognition Custom Labels میں باؤنڈنگ باکس آبجیکٹ کا پتہ لگانے کے لیبلنگ ٹول کا استعمال کرتے ہوئے 600 امیجز (کھمبوں، تاروں، اور دھاتی ریلنگ) میں اشیاء کو لیبل کیا اور دلچسپی کی تین اہم چیزوں کا پتہ لگانے کے لیے ایک ماڈل کو تربیت دی۔ ہم نے تربیت یافتہ ماڈل کا استعمال تمام امیجز سے بیک گراؤنڈ کو ہٹانے کے لیے کیا، ہر امیج میں موجود کھمبوں کی شناخت اور نکال کر، جبکہ دیگر تمام اشیاء کے ساتھ ساتھ بیک گراؤنڈ کو بھی ہٹا دیا۔ ان تمام تصاویر کو ہٹانے کے نتیجے میں جن میں لکڑی کے کھمبے شامل نہیں ہیں، نتیجے میں ڈیٹا سیٹ میں اصل ڈیٹا سیٹ سے کم تصاویر تھیں۔ اس کے علاوہ، ایک غلط مثبت تصویر بھی تھی جسے ڈیٹاسیٹ سے ہٹا دیا گیا تھا۔
بے عیب شناخت
اگلا، ہم بے ضابطگی کا پتہ لگانے کے لیے مشین لرننگ ماڈل کی تربیت کے لیے پہلے سے تیار کردہ ڈیٹا کا استعمال کرتے ہیں۔ ہم نے بے ضابطگی کا پتہ لگانے کے لیے تین مختلف طریقے استعمال کیے جن میں AWS مینیجڈ مشین لرننگ سروسز (Amazon Lookout for Vision [L4V]، Amazon Recognition)، AutoGluon، اور Vision Transformer پر مبنی خود کشی کا طریقہ شامل ہے۔
AWS خدمات
Amazon Lookout for Vision (L4V)
Amazon Lookout for Vision ایک منظم AWS سروس ہے جو ایم ایل ماڈلز کی تیز تربیت اور تعیناتی کو قابل بناتی ہے اور بے ضابطگیوں کا پتہ لگانے کی صلاحیتیں فراہم کرتی ہے۔ اس کے لیے مکمل طور پر لیبل لگا ڈیٹا درکار ہے، جو ہم نے Amazon S3 میں تصویری راستوں کی طرف اشارہ کرکے فراہم کیا ہے۔ ماڈل کو تربیت دینا اتنا ہی آسان ہے جتنا کہ سنگل API (ایپلیکیشن پروگرامنگ انٹرفیس) کال یا کنسول بٹن پر کلک اور L4V ماڈل کے انتخاب اور ہائپر پیرامیٹر ٹیوننگ کا خیال رکھتا ہے۔
ایمیزون پہچان۔
Amazon Recognition L4V کی طرح ایک منظم AI/ML سروس ہے، جو ماڈلنگ کی تفصیلات کو چھپاتی ہے اور بہت سی صلاحیتیں فراہم کرتی ہے جیسے کہ تصویر کی درجہ بندی، آبجیکٹ کا پتہ لگانے، حسب ضرورت لیبلنگ، اور بہت کچھ۔ یہ تصاویر میں پہلے سے معلوم اداروں پر لاگو کرنے کے لیے بلٹ ان ماڈلز کو استعمال کرنے کی صلاحیت فراہم کرتا ہے (مثال کے طور پر، ImageNet یا دیگر بڑے کھلے ڈیٹا سیٹس سے)۔ تاہم، ہم نے ROI ڈیٹیکٹر کو تربیت دینے کے لیے Amazon Recognition کے کسٹم لیبلز کی فعالیت کا استعمال کیا، نیز ڈیوک انرجی کے پاس موجود مخصوص تصاویر پر ایک بے ضابطگی کا پتہ لگانے والا۔ ہم نے ہر تصویر میں لکڑی کے کھمبوں کے گرد باؤنڈنگ بکس لگانے کے لیے ایک ماڈل کو تربیت دینے کے لیے Amazon Recognition کے کسٹم لیبلز کا بھی استعمال کیا۔
آٹو گلوون
AutoGluon ایک اوپن سورس مشین لرننگ تکنیک ہے جسے Amazon نے تیار کیا ہے۔ AutoGluon میں ایک ملٹی موڈل جزو شامل ہے جو امیج ڈیٹا پر آسان تربیت کی اجازت دیتا ہے۔ ہم نے آٹوگلون ملٹی موڈل کو لیبل والے تصویری پیچ پر ماڈلز کو تربیت دینے کے لیے استعمال کیا تاکہ بے ضابطگیوں کی شناخت کے لیے ایک بنیادی لائن قائم کی جا سکے۔
وژن ٹرانسفارمر
AI کی بہت سی دلچسپ کامیابیاں دو حالیہ اختراعات سے آئی ہیں: خود زیر نگرانی سیکھنے، جو مشینوں کو بے ترتیب، بغیر لیبل والی مثالوں سے سیکھنے کی اجازت دیتی ہے۔ اور ٹرانسفارمرز، جو AI ماڈلز کو اپنے ان پٹ کے کچھ حصوں پر انتخابی توجہ مرکوز کرنے کے قابل بناتے ہیں اور اس طرح زیادہ مؤثر طریقے سے استدلال کرتے ہیں۔ دونوں طریقے مشین لرننگ کمیونٹی کے لیے مستقل توجہ کا مرکز رہے ہیں، اور ہمیں یہ بتاتے ہوئے خوشی ہو رہی ہے کہ ہم نے انہیں اس مصروفیت میں استعمال کیا۔
خاص طور پر، ڈیوک انرجی کے محققین کے ساتھ مل کر کام کرتے ہوئے، ہم نے Amazon Sagemaker کا استعمال کرتے ہوئے ڈاؤن اسٹریم بے ضابطگی کا پتہ لگانے والی ایپلی کیشن کے لیے فیچر ایکسٹریکٹر کے طور پر پہلے سے تربیت یافتہ سیلف ڈسٹلیشن ViT (وژن ٹرانسفارمر) ماڈلز کا استعمال کیا۔ پہلے سے تربیت یافتہ سیلف ڈسٹلیشن وژن ٹرانسفارمر ماڈلز کو Amazon S3 پر محفوظ کردہ بڑی مقدار میں تربیتی ڈیٹا پر Amazon SageMaker کا استعمال کرتے ہوئے خود نگرانی میں تربیت دی جاتی ہے۔ ہم بڑے پیمانے پر ڈیٹا سیٹس (جیسے امیج نیٹ) پر پہلے سے تربیت یافتہ ViT ماڈلز کی منتقلی سیکھنے کی صلاحیتوں کا فائدہ اٹھاتے ہیں۔ اس سے ہمیں تربیت کے لیے صرف چند ہزار لیبل والی تصاویر کا استعمال کرتے ہوئے تشخیصی سیٹ پر 83% کی واپسی حاصل کرنے میں مدد ملی۔
تشخیصی میٹرکس
مندرجہ ذیل اعداد و شمار ماڈل کی کارکردگی اور اس کے اثرات کا جائزہ لینے کے لیے استعمال ہونے والے کلیدی میٹرکس کو دکھاتا ہے۔ ماڈل کا کلیدی مقصد بے ضابطگیوں کی کھوج کو زیادہ سے زیادہ کرنا ہے (یعنی حقیقی مثبتات) اور جھوٹے منفی کی تعداد کو کم سے کم کرنا، یا ایسے اوقات جب ان بے ضابطگیوں کی جو بندش کا باعث بن سکتی ہیں غلط درجہ بندی کی جا رہی ہیں۔
ایک بار بے ضابطگیوں کی نشاندہی ہو جانے کے بعد، تکنیکی ماہرین ان کا ازالہ کر سکتے ہیں، مستقبل کی بندش کو روک سکتے ہیں اور حکومتی ضوابط کی تعمیل کو یقینی بنا سکتے ہیں۔ جھوٹے مثبت کو کم کرنے کا ایک اور فائدہ ہے: آپ دوبارہ تصاویر کے ذریعے جانے کی غیر ضروری کوشش سے بچتے ہیں۔

ان میٹرکس کو ذہن میں رکھتے ہوئے، ہم مندرجہ ذیل میٹرکس کے لحاظ سے ماڈل کی کارکردگی کو ٹریک کرتے ہیں، جو اوپر بیان کردہ چاروں میٹرکس کو سمیٹتا ہے۔
صحت سے متعلق
پائی جانے والی بے ضابطگیوں کا فیصد جو دلچسپی کی اشیاء کے لیے حقیقی بے ضابطگیاں ہیں۔ درستگی پیمائش کرتی ہے کہ ہمارا الگورتھم صرف بے ضابطگیوں کی کتنی اچھی طرح شناخت کرتا ہے۔ اس استعمال کے معاملے کے لیے، اعلی درستگی کا مطلب ہے کم جھوٹے الارم (یعنی الگورتھم غلط طریقے سے لکڑی کے سوراخ کی شناخت کرتا ہے جب کہ تصویر میں کوئی نہیں ہے)۔
![]()
یاد رکھیں
ان تمام بے ضابطگیوں کا فیصد جو ہر دلچسپی کے شے کے لیے بازیافت ہوتے ہیں۔ پیمائشوں کو یاد کریں کہ ہم تمام بے ضابطگیوں کی کتنی اچھی طرح شناخت کرتے ہیں۔ یہ سیٹ بے ضابطگیوں کے مکمل سیٹ کے کچھ فیصد پر قبضہ کرتا ہے، اور وہ فیصد واپسی ہے۔ اس استعمال کے معاملے میں، زیادہ یاد کرنے کا مطلب یہ ہے کہ ہم لکڑی کے سوراخ ہونے پر اسے پکڑنے میں اچھے ہیں۔ اس لیے اس POC پر توجہ مرکوز کرنے کے لیے یاد کرنا صحیح میٹرک ہے کیونکہ جھوٹے الارم سب سے زیادہ پریشان کن ہوتے ہیں جب کہ یاد نہ ہونے والی بے ضابطگیوں کو اگر توجہ نہ دی گئی تو سنگین نتائج کا باعث بن سکتے ہیں۔
![]()
کم یاد کرنے سے بندش اور حکومتی ضابطوں کی خلاف ورزی ہو سکتی ہے۔ جبکہ کم درستگی انسانی کوششوں کو ضائع کرنے کا باعث بنتی ہے۔ اس مصروفیت کا بنیادی مقصد حکومتی ضابطوں کی تعمیل کرنے کے لیے تمام بے ضابطگیوں کی نشاندہی کرنا اور کسی بھی بندش سے بچنا ہے، اس لیے ہم درستگی سے زیادہ یادداشت کو بہتر بنانے کو ترجیح دیتے ہیں۔
تشخیص اور ماڈل کا موازنہ
مندرجہ ذیل حصے میں، ہم اس مصروفیت کے دوران استعمال کی گئی مختلف ماڈلنگ تکنیکوں کے موازنہ کا مظاہرہ کرتے ہیں۔ ہم نے دو AWS سروسز Amazon Recognition اور Amazon Lookout for Vision کی کارکردگی کا جائزہ لیا۔ ہم نے AutoGluon کا استعمال کرتے ہوئے ماڈلنگ کی مختلف تکنیکوں کا بھی جائزہ لیا۔ آخر میں، ہم کارکردگی کا موازنہ جدید ترین ViT پر مبنی خود کشی کے طریقہ سے کرتے ہیں۔
مندرجہ ذیل اعداد و شمار اس مصروفیت کی مدت کے دوران مختلف ڈیٹا پروسیسنگ تکنیکوں کا استعمال کرتے ہوئے AutoGluon کے ماڈل میں بہتری کو ظاہر کرتا ہے۔ اہم مشاہدہ یہ ہے کہ جب ہم ڈیٹا کے معیار اور مقدار کو بہتر بناتے ہیں تو یاد کرنے کے لحاظ سے ماڈل کی کارکردگی 30% سے نیچے سے 78% تک بہتر ہوتی ہے۔
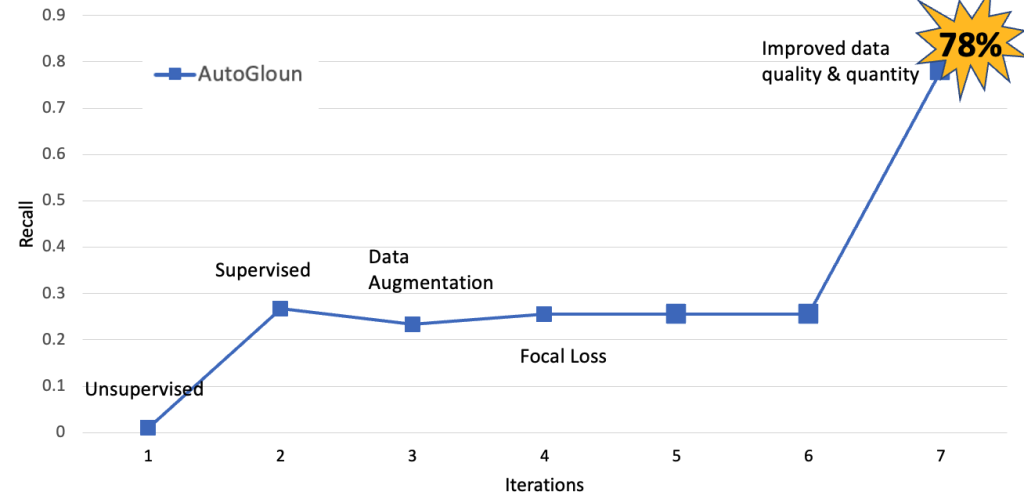
اگلا، ہم آٹوگلون کی کارکردگی کا AWS خدمات سے موازنہ کرتے ہیں۔ ہم نے مختلف ڈیٹا پروسیسنگ تکنیکوں کو بھی استعمال کیا جس نے کارکردگی کو بہتر بنانے میں مدد کی۔ تاہم، بڑی بہتری ڈیٹا کی مقدار اور معیار میں اضافے سے آئی ہے۔ ہم ڈیٹاسیٹ کا سائز 11 K تصاویر سے بڑھا کر 60 K تصاویر کر دیتے ہیں۔

اگلا، ہم AutoGluon اور AWS سروسز کی کارکردگی کا ViT پر مبنی طریقہ سے موازنہ کرتے ہیں۔ درج ذیل اعداد و شمار سے پتہ چلتا ہے کہ ViT پر مبنی طریقہ کار، AutoGluon اور AWS خدمات نے یاد کرنے کے معاملے میں برابری کی کارکردگی کا مظاہرہ کیا۔ ایک اہم مشاہدہ ہے، ایک خاص نقطہ سے آگے، ڈیٹا کے معیار اور مقدار میں اضافہ یاد کرنے کے معاملے میں کارکردگی کو بڑھانے میں مدد نہیں کرتا ہے۔ تاہم، ہم درستگی کے لحاظ سے بہتری کا مشاہدہ کرتے ہیں۔

صحت سے متعلق بمقابلہ یاد کرنے کا موازنہ
| ایمیزون آٹو گلوون | پیشن گوئی بے ضابطگیوں | معمول کی پیشن گوئی کی۔ |
| بدقسمتی | 15600 | 4400 |
| عمومی | 3659 | 38341 |
اگلا، ہم اپنے ڈیٹاسیٹ کا استعمال کرتے ہوئے AutoGluon اور Amazon Recognition اور ViT پر مبنی طریقہ کے لیے کنفیوژن میٹرکس پیش کرتے ہیں جس میں 62 K نمونے ہیں۔ 62K نمونوں میں سے 20 K نمونے غیر معمولی ہیں جبکہ باقی 42 K تصاویر نارمل ہیں۔ یہ دیکھا جا سکتا ہے کہ ViT پر مبنی طریقے سب سے زیادہ بے ضابطگیوں (16,600) کو پکڑتے ہیں جس کے بعد Amazon Rekognition (16,000) اور Amazon AutoGluon (15600) آتے ہیں۔ اسی طرح، Amazon AutoGluon میں جھوٹے مثبت (3659 امیجز) کی سب سے کم تعداد ہے جس کے بعد Amazon Recognition (5918) اور ViT (15323) ہیں۔ یہ نتائج ظاہر کرتے ہیں کہ Amazon Recognition سب سے زیادہ AUC (وکر کے نیچے کا علاقہ) حاصل کرتا ہے۔
| ایمیزون پہچان۔ | پیشن گوئی بے ضابطگیوں | معمول کی پیشن گوئی کی۔ |
| بدقسمتی | 16,000 | 4000 |
| عمومی | 5918 | 36082 |
| ViT | پیشن گوئی بے ضابطگیوں | معمول کی پیشن گوئی کی۔ |
| بدقسمتی | 16,600 | 3400 |
| عمومی | 15,323 | 26,677 |
نتیجہ
اس پوسٹ میں، ہم نے آپ کو دکھایا کہ کس طرح MLSL اور Duke Energy ٹیموں نے کمپیوٹر وژن پر مبنی حل تیار کرنے کے لیے مل کر کام کیا تاکہ ہیلی کاپٹر کی پروازوں کے ذریعے جمع کی گئی ہائی ریزولیوشن امیجز کا استعمال کرتے ہوئے لکڑی کے کھمبوں میں خود کار طریقے سے بے ضابطگی کا پتہ لگایا جا سکے۔ مجوزہ حل میں ڈیٹا پروسیسنگ پائپ لائن کا استعمال کیا گیا تاکہ سائز کی معیاری کاری کے لیے ہائی ریزولوشن امیج کو تراش سکے۔ تراشی گئی تصاویر پر مزید کارروائی ایمیزون ریکگنیشن کسٹم لیبلز کا استعمال کرتے ہوئے کی جاتی ہے تاکہ دلچسپی کے علاقے کی شناخت کی جا سکے (یعنی کھمبوں کے ساتھ پیچ پر مشتمل فصلیں)۔ Amazon Recognition نے کھمبوں کے ساتھ پیچ کی درست شناخت کرنے کے معاملے میں 96% درستگی حاصل کی۔ ROI فصلوں کو مزید بے ضابطگی کا پتہ لگانے کے لیے ViT پر مبنی سیلف ڈسٹلیشن mdoel AutoGluon اور AWS سروسز کا استعمال کرتے ہوئے استعمال کیا جاتا ہے۔ ہم نے تینوں طریقوں کی کارکردگی کو جانچنے کے لیے ایک معیاری ڈیٹا سیٹ استعمال کیا۔ ViT پر مبنی ماڈل نے 83% واپسی اور 52% درستگی حاصل کی۔ AutoGluon نے 78% ریکال اور 81% درستگی حاصل کی۔ آخر میں، Amazon Recognition 80% recall اور 73% precision حاصل کرتا ہے۔ تین مختلف طریقے استعمال کرنے کا مقصد ہر طریقہ کی کارکردگی کا مختلف تعداد میں تربیتی نمونوں، تربیت کے وقت، اور تعیناتی کے وقت کے ساتھ موازنہ کرنا ہے۔ ان تمام طریقوں کو ایک A2 GPU مثال یا Amazon AWS پر منظم خدمات کا استعمال کرتے ہوئے تربیت دینے اور تعینات کرنے میں 100 گھنٹے سے بھی کم وقت لگتا ہے۔ اگلا، ماڈل کی کارکردگی میں مزید بہتری کے اقدامات میں ماڈل کی درستگی کو بہتر بنانے کے لیے مزید تربیتی ڈیٹا شامل کرنا شامل ہے۔
مجموعی طور پر، اس پوسٹ میں تجویز کردہ اختتام سے آخر تک پائپ لائن آپریشن کی لاگت، حفاظتی واقعات، ریگولیٹری خطرات، کاربن کے اخراج، اور ممکنہ بجلی کی بندش کو کم کرتے ہوئے بے ضابطگیوں کا پتہ لگانے میں نمایاں بہتری حاصل کرنے میں مدد کرتی ہے۔
تیار کردہ حل کو ٹرانسمیشن اور ڈسٹری بیوشن نیٹ ورکس میں دیگر بے ضابطگیوں کا پتہ لگانے اور اثاثہ صحت سے متعلق استعمال کے معاملات کے لیے استعمال کیا جا سکتا ہے، بشمول انسولیٹروں اور دیگر آلات میں نقائص۔ اس حل کو تیار کرنے اور اپنی مرضی کے مطابق بنانے میں مزید مدد کے لیے، براہ کرم MLSL ٹیم سے بلا جھجھک رابطہ کریں۔
مصنفین کے بارے میں
 ٹریوس برونسن ٹکنالوجی میں 15 سال کے تجربے کے ساتھ ایک لیڈ مصنوعی ذہانت کے ماہر ہیں اور 8 سال خاص طور پر مصنوعی ذہانت کے لیے وقف ہیں۔ ڈیوک انرجی میں اپنے 5 سالہ دور میں، ٹریوس نے اپنی کمپنی کے اہم کنارے پر منفرد بصیرت اور تخلیقی سوچ کی قیادت لا کر ڈیجیٹل تبدیلی کے لیے AI کے اطلاق کو آگے بڑھایا ہے۔ ٹریوس فی الحال AI کور ٹیم کی قیادت کر رہا ہے، AI پریکٹیشنرز، پرجوشوں، اور کاروباری شراکت داروں کی ایک کمیونٹی جو AI کے نتائج اور گورننس کو آگے بڑھانے پر مرکوز ہے۔ ٹریوس نے متعدد تکنیکی شعبوں میں اپنی مہارتیں حاصل کیں اور ان کو بہتر بنایا، جس کا آغاز امریکی بحریہ اور امریکی حکومت میں ہوا، پھر ایک دہائی سے زیادہ سروس کے بعد نجی شعبے میں منتقل ہوا۔
ٹریوس برونسن ٹکنالوجی میں 15 سال کے تجربے کے ساتھ ایک لیڈ مصنوعی ذہانت کے ماہر ہیں اور 8 سال خاص طور پر مصنوعی ذہانت کے لیے وقف ہیں۔ ڈیوک انرجی میں اپنے 5 سالہ دور میں، ٹریوس نے اپنی کمپنی کے اہم کنارے پر منفرد بصیرت اور تخلیقی سوچ کی قیادت لا کر ڈیجیٹل تبدیلی کے لیے AI کے اطلاق کو آگے بڑھایا ہے۔ ٹریوس فی الحال AI کور ٹیم کی قیادت کر رہا ہے، AI پریکٹیشنرز، پرجوشوں، اور کاروباری شراکت داروں کی ایک کمیونٹی جو AI کے نتائج اور گورننس کو آگے بڑھانے پر مرکوز ہے۔ ٹریوس نے متعدد تکنیکی شعبوں میں اپنی مہارتیں حاصل کیں اور ان کو بہتر بنایا، جس کا آغاز امریکی بحریہ اور امریکی حکومت میں ہوا، پھر ایک دہائی سے زیادہ سروس کے بعد نجی شعبے میں منتقل ہوا۔
 برائن ولکرسن ڈیوک انرجی میں دو دہائیوں کے تجربے کے ساتھ ایک ماہر پیشہ ور ہے۔ کمپیوٹر سائنس میں ڈگری کے ساتھ، اس نے پچھلے 7 سال مصنوعی ذہانت کے شعبے میں شاندار کارکردگی کا مظاہرہ کرتے ہوئے گزارے ہیں۔ برائن ڈیوک انرجی کی MADlab (مشین لرننگ، AI اور ڈیپ لرننگ ٹیم) کے شریک بانی ہیں۔ وہ فی الحال ڈیوک انرجی میں آرٹیفیشل انٹیلی جنس اینڈ ٹرانسفارمیشن کے ڈائریکٹر کے عہدے پر فائز ہیں، جہاں وہ AI کے نفاذ کے ذریعے کاروباری قدر کی فراہمی کے لیے پرجوش ہیں۔
برائن ولکرسن ڈیوک انرجی میں دو دہائیوں کے تجربے کے ساتھ ایک ماہر پیشہ ور ہے۔ کمپیوٹر سائنس میں ڈگری کے ساتھ، اس نے پچھلے 7 سال مصنوعی ذہانت کے شعبے میں شاندار کارکردگی کا مظاہرہ کرتے ہوئے گزارے ہیں۔ برائن ڈیوک انرجی کی MADlab (مشین لرننگ، AI اور ڈیپ لرننگ ٹیم) کے شریک بانی ہیں۔ وہ فی الحال ڈیوک انرجی میں آرٹیفیشل انٹیلی جنس اینڈ ٹرانسفارمیشن کے ڈائریکٹر کے عہدے پر فائز ہیں، جہاں وہ AI کے نفاذ کے ذریعے کاروباری قدر کی فراہمی کے لیے پرجوش ہیں۔
 احسن علی ایمیزون جنریٹو اے آئی انوویشن سینٹر میں ایک اپلائیڈ سائنٹسٹ ہے، جہاں وہ مختلف ڈومینز کے صارفین کے ساتھ جنریٹیو اے آئی کا استعمال کرتے ہوئے ان کے فوری اور مہنگے مسائل کو حل کرنے کے لیے کام کرتا ہے۔
احسن علی ایمیزون جنریٹو اے آئی انوویشن سینٹر میں ایک اپلائیڈ سائنٹسٹ ہے، جہاں وہ مختلف ڈومینز کے صارفین کے ساتھ جنریٹیو اے آئی کا استعمال کرتے ہوئے ان کے فوری اور مہنگے مسائل کو حل کرنے کے لیے کام کرتا ہے۔
 طہین سید ایمیزون جنریٹو AI انوویشن سینٹر کے ساتھ ایک اپلائیڈ سائنٹسٹ ہے، جہاں وہ تخلیقی AI حل کے ساتھ کاروباری نتائج کو محسوس کرنے میں مدد کے لیے صارفین کے ساتھ کام کرتا ہے۔ کام سے باہر، وہ نیا کھانا آزمانے، سفر کرنے اور تائیکوانڈو سکھانے میں لطف اندوز ہوتا ہے۔
طہین سید ایمیزون جنریٹو AI انوویشن سینٹر کے ساتھ ایک اپلائیڈ سائنٹسٹ ہے، جہاں وہ تخلیقی AI حل کے ساتھ کاروباری نتائج کو محسوس کرنے میں مدد کے لیے صارفین کے ساتھ کام کرتا ہے۔ کام سے باہر، وہ نیا کھانا آزمانے، سفر کرنے اور تائیکوانڈو سکھانے میں لطف اندوز ہوتا ہے۔
 ڈاکٹر Nkechinyere N. Agu AWS میں جنریٹو AI انوویشن سینٹر میں ایک اپلائیڈ سائنٹسٹ ہے۔ اس کی مہارت کمپیوٹر وژن AI/ML طریقوں، صحت کی دیکھ بھال کے لیے AI/ML کی ایپلی کیشنز کے ساتھ ساتھ ML سلوشنز میں سیمنٹک ٹیکنالوجیز (نالج گرافس) کے انضمام میں ہے۔ اس نے کمپیوٹر سائنس میں ماسٹرز اور ڈاکٹریٹ کی ہے۔
ڈاکٹر Nkechinyere N. Agu AWS میں جنریٹو AI انوویشن سینٹر میں ایک اپلائیڈ سائنٹسٹ ہے۔ اس کی مہارت کمپیوٹر وژن AI/ML طریقوں، صحت کی دیکھ بھال کے لیے AI/ML کی ایپلی کیشنز کے ساتھ ساتھ ML سلوشنز میں سیمنٹک ٹیکنالوجیز (نالج گرافس) کے انضمام میں ہے۔ اس نے کمپیوٹر سائنس میں ماسٹرز اور ڈاکٹریٹ کی ہے۔
 الڈو ایرزمندی آسٹن، ٹیکساس میں واقع AWS جنریٹیو AI انوویشن سینٹر میں جنریٹو AI اسٹریٹجسٹ ہے۔ یونیورسٹی آف نیبراسکا-لنکن سے کمپیوٹر انجینئرنگ میں بی ایس حاصل کرنے کے بعد، مسٹر ایرزمندی نے گزشتہ 12 سالوں کے دوران سینکڑوں فارچیون 500 کمپنیوں اور اسٹارٹ اپس کو جدید تجزیات، مشین لرننگ، اور جنریٹیو AI کا استعمال کرتے ہوئے اپنے کاروبار کو تبدیل کرنے میں مدد کی ہے۔
الڈو ایرزمندی آسٹن، ٹیکساس میں واقع AWS جنریٹیو AI انوویشن سینٹر میں جنریٹو AI اسٹریٹجسٹ ہے۔ یونیورسٹی آف نیبراسکا-لنکن سے کمپیوٹر انجینئرنگ میں بی ایس حاصل کرنے کے بعد، مسٹر ایرزمندی نے گزشتہ 12 سالوں کے دوران سینکڑوں فارچیون 500 کمپنیوں اور اسٹارٹ اپس کو جدید تجزیات، مشین لرننگ، اور جنریٹیو AI کا استعمال کرتے ہوئے اپنے کاروبار کو تبدیل کرنے میں مدد کی ہے۔
 سٹیسی جینکس تجزیات اور AI/ML میں دو دہائیوں سے زیادہ کے تجربے کے ساتھ AWS میں پرنسپل تجزیات سیلز اسپیشلسٹ ہیں۔ Stacey کسٹمر کے اقدامات پر گہرا غوطہ لگانے اور ڈیٹا کے ساتھ تبدیلی کے قابل، قابل پیمائش کاروباری نتائج کو چلانے کے بارے میں پرجوش ہے۔ وہ خاص طور پر اس نشان کے بارے میں پرجوش ہے جو افادیت معاشرے پر، سستی، قابل اعتماد، صاف توانائی کے ساتھ ایک سبز سیارے تک پہنچنے کے اپنے راستے کے ذریعے بنائے گی۔
سٹیسی جینکس تجزیات اور AI/ML میں دو دہائیوں سے زیادہ کے تجربے کے ساتھ AWS میں پرنسپل تجزیات سیلز اسپیشلسٹ ہیں۔ Stacey کسٹمر کے اقدامات پر گہرا غوطہ لگانے اور ڈیٹا کے ساتھ تبدیلی کے قابل، قابل پیمائش کاروباری نتائج کو چلانے کے بارے میں پرجوش ہے۔ وہ خاص طور پر اس نشان کے بارے میں پرجوش ہے جو افادیت معاشرے پر، سستی، قابل اعتماد، صاف توانائی کے ساتھ ایک سبز سیارے تک پہنچنے کے اپنے راستے کے ذریعے بنائے گی۔
 مہدی نور جنریٹو ائی انوویشن سینٹر میں اپلائیڈ سائنس مینیجر ہے۔ ٹکنالوجی اور جدت طرازی کے جذبے کے ساتھ، وہ AWS کے صارفین کو جنریٹو AI کی صلاحیت کو کھولنے میں مدد کرتا ہے، جدید AI ٹیکنالوجیز کے توسیع پذیر، قابل پیمائش، اور اثر انگیز استعمال پر توجہ مرکوز کرتے ہوئے، ممکنہ چیلنجوں کو تیزی سے تجربہ اور اختراع کے مواقع میں تبدیل کرتا ہے، اور راستے کو ہموار کرتا ہے۔ پیداوار کے لئے.
مہدی نور جنریٹو ائی انوویشن سینٹر میں اپلائیڈ سائنس مینیجر ہے۔ ٹکنالوجی اور جدت طرازی کے جذبے کے ساتھ، وہ AWS کے صارفین کو جنریٹو AI کی صلاحیت کو کھولنے میں مدد کرتا ہے، جدید AI ٹیکنالوجیز کے توسیع پذیر، قابل پیمائش، اور اثر انگیز استعمال پر توجہ مرکوز کرتے ہوئے، ممکنہ چیلنجوں کو تیزی سے تجربہ اور اختراع کے مواقع میں تبدیل کرتا ہے، اور راستے کو ہموار کرتا ہے۔ پیداوار کے لئے.
- SEO سے چلنے والا مواد اور PR کی تقسیم۔ آج ہی بڑھا دیں۔
- پلیٹو ڈیٹا ڈاٹ نیٹ ورک ورٹیکل جنریٹو اے آئی۔ اپنے آپ کو بااختیار بنائیں۔ یہاں تک رسائی حاصل کریں۔
- پلیٹوآئ اسٹریم۔ ویب 3 انٹیلی جنس۔ علم میں اضافہ۔ یہاں تک رسائی حاصل کریں۔
- پلیٹو ای ایس جی۔ آٹوموٹو / ای وی، کاربن، کلین ٹیک، توانائی ، ماحولیات، شمسی، ویسٹ مینجمنٹ یہاں تک رسائی حاصل کریں۔
- پلیٹو ہیلتھ۔ بائیوٹیک اینڈ کلینیکل ٹرائلز انٹیلی جنس۔ یہاں تک رسائی حاصل کریں۔
- چارٹ پرائم۔ ChartPrime کے ساتھ اپنے ٹریڈنگ گیم کو بلند کریں۔ یہاں تک رسائی حاصل کریں۔
- بلاک آفسیٹس۔ ماحولیاتی آفسیٹ ملکیت کو جدید بنانا۔ یہاں تک رسائی حاصل کریں۔
- ماخذ: https://aws.amazon.com/blogs/machine-learning/improving-asset-health-and-grid-resilience-using-machine-learning/

