یہ پوسٹ لائٹ اینڈ ونڈر (L&W) سے ارونا ابیاکون اور ڈینس کولن کے ساتھ مل کر لکھی گئی ہے۔
لاس ویگاس میں ہیڈ کوارٹر، Light & Wonder, Inc. ایک سرکردہ کراس پلیٹ فارم عالمی گیم کمپنی ہے جو جوئے کی مصنوعات اور خدمات فراہم کرتی ہے۔ AWS کے ساتھ کام کرتے ہوئے، لائٹ اینڈ ونڈر نے حال ہی میں انڈسٹری کا پہلا محفوظ حل، لائٹ اینڈ ونڈر کنیکٹ (LnW Connect) تیار کیا ہے، جس سے ٹیلی میٹری اور مشین ہیلتھ ڈیٹا کو اسٹریم کرنے کے لیے تقریباً 500 لاکھ الیکٹرانک گیمنگ مشینوں سے اس کے کیسینو کسٹمر بیس میں عالمی سطح پر تقسیم کیا گیا جب LnW کنیکٹ۔ اپنی پوری صلاحیت تک پہنچ جاتا ہے۔ مشین کے حالات اور ان کے آپریٹنگ ماحول کی مکمل تصویر دینے کے لیے تقریباً حقیقی وقت میں XNUMX سے زیادہ مشین ایونٹس کی نگرانی کی جاتی ہے۔ LnW Connect کے ذریعے سٹریم کیے گئے ڈیٹا کو استعمال کرتے ہوئے، L&W کا مقصد اپنے اختتامی صارفین کے لیے گیمنگ کا بہتر تجربہ پیدا کرنا ہے اور ساتھ ہی ان کے کیسینو کے صارفین کے لیے زیادہ اہمیت لانا ہے۔
لائٹ اینڈ ونڈر کے ساتھ مل کر کام کیا۔ ایمیزون ایم ایل حل لیب سلاٹ مشینوں کے لیے مشین لرننگ (ML) سے چلنے والی پیشن گوئی کی بحالی کو فعال کرنے کے لیے LnW Connect سے سٹریم کیے گئے ایونٹس کے ڈیٹا کو استعمال کرنے کے لیے۔ پیشن گوئی کی دیکھ بھال جسمانی سازوسامان یا مشینری کے اثاثوں والے کاروباروں کے لیے ML کے استعمال کا ایک عام معاملہ ہے۔ پیشن گوئی کی دیکھ بھال کے ساتھ، L&W مشین کے خراب ہونے کی پیشگی وارننگ حاصل کر سکتا ہے اور مسئلہ کا معائنہ کرنے کے لیے ایک سروس ٹیم کو فعال طور پر بھیج سکتا ہے۔ اس سے مشین کا وقت کم ہو جائے گا اور جوئے بازی کے اڈوں کے لیے اہم آمدنی کے نقصان سے بچ جائے گا۔ ریموٹ تشخیصی نظام کے بغیر، کیسینو فلور پر لائٹ اینڈ ونڈر سروس ٹیم کی طرف سے ایشو ریزولیوشن مہنگا اور ناکارہ ہو سکتا ہے، جبکہ صارف کے گیمنگ کے تجربے کو شدید نقصان پہنچا سکتا ہے۔
پروجیکٹ کی نوعیت انتہائی تحقیقی ہے- یہ گیمنگ انڈسٹری میں پیشین گوئی کی دیکھ بھال کی پہلی کوشش ہے۔ ایمیزون ایم ایل سلوشنز لیب اور ایل اینڈ ڈبلیو ٹیم نے ایم ایل مسئلہ کی تشکیل اور تشخیصی میٹرکس کی وضاحت سے لے کر ایک اعلیٰ معیار کے حل کی فراہمی تک ایک اختتام سے آخر تک کا سفر شروع کیا۔ حتمی ML ماڈل CNN اور ٹرانسفارمر کو یکجا کرتا ہے، جو کہ ترتیب وار مشین لاگ ڈیٹا کی ماڈلنگ کے لیے جدید ترین نیورل نیٹ ورک آرکیٹیکچرز ہیں۔ پوسٹ میں اس سفر کی تفصیلی وضاحت پیش کی گئی ہے، اور ہم امید کرتے ہیں کہ آپ اس سے اتنا ہی لطف اندوز ہوں گے جتنا ہم کرتے ہیں!
اس پوسٹ میں، ہم مندرجہ ذیل پر بات کرتے ہیں:
- تشخیص کے لیے مناسب میٹرکس کے سیٹ کے ساتھ ہم نے پیشین گوئی کی دیکھ بھال کے مسئلے کو ML مسئلہ کے طور پر کیسے وضع کیا
- ہم نے تربیت اور جانچ کے لیے ڈیٹا کیسے تیار کیا۔
- ڈیٹا پری پروسیسنگ اور فیچر انجینئرنگ تکنیکوں کو ہم نے پرفارمنس ماڈل حاصل کرنے کے لیے استعمال کیا۔
- کے ساتھ ایک ہائپرپیرامیٹر ٹیوننگ مرحلہ انجام دینا ایمیزون سیج میکر آٹومیٹک ماڈل ٹیوننگ
- بیس لائن ماڈل اور فائنل CNN+ٹرانسفارمر ماڈل کے درمیان موازنہ
- اضافی تکنیک جو ہم نے ماڈل کی کارکردگی کو بہتر بنانے کے لیے استعمال کیں، جیسے کہ جوڑنا
پس منظر
اس سیکشن میں، ہم ان مسائل پر بات کرتے ہیں جو اس حل کی ضرورت تھی۔
ڈیٹا بیس
سلاٹ مشین کے ماحول بہت زیادہ ریگولیٹ ہوتے ہیں اور ان کو ایئر گیپڈ ماحول میں تعینات کیا جاتا ہے۔ LnW Connect میں، ایک انکرپشن کا عمل ڈیزائن کیا گیا تھا تاکہ ڈیٹا کو AWS ڈیٹا لیک میں پیشین گوئی کرنے والی ماڈلنگ کے لیے ایک محفوظ اور قابل اعتماد طریقہ کار فراہم کیا جا سکے۔ مجموعی فائلیں انکرپٹڈ ہیں اور ڈکرپشن کلید صرف اس میں دستیاب ہے۔ AWS کی مینجمنٹ سروس (AWS KMS). AWS میں سیلولر پر مبنی نجی نیٹ ورک قائم کیا گیا ہے جس کے ذریعے فائلیں اپ لوڈ کی گئی تھیں۔ ایمیزون سادہ اسٹوریج سروس (ایمیزون S3).
LnW Connect مشین ایونٹس کی ایک وسیع رینج کو چلاتا ہے، جیسے گیم کا آغاز، گیم کا اختتام، اور بہت کچھ۔ یہ نظام 500 سے زیادہ مختلف قسم کے واقعات کو اکٹھا کرتا ہے۔ جیسا کہ درج ذیل میں دکھایا گیا ہے۔
، ہر واقعہ کو اس کے ٹائم اسٹیمپ کے ساتھ ریکارڈ کیا جاتا ہے کہ یہ کب ہوا اور اس واقعہ کو ریکارڈ کرنے والی مشین کی ID۔ LnW کنیکٹ اس وقت بھی ریکارڈ کرتا ہے جب کوئی مشین ناقابل پلے حالت میں داخل ہوتی ہے، اور اگر یہ کافی کم وقت کے اندر اندر چلانے کے قابل حالت میں بحال نہیں ہوتی ہے تو اسے مشین کی خرابی یا خرابی کے طور پر نشان زد کیا جائے گا۔
| مشین کی شناخت | ایونٹ کی قسم ID | ٹائمسٹیمپ |
|---|---|---|
| 0 | E1 | 2022-01-01 00:17:24 |
| 0 | E3 | 2022-01-01 00:17:29 |
| 1000 | E4 | 2022-01-01 00:17:33 |
| 114 | E234 | 2022-01-01 00:17:34 |
| 222 | E100 | 2022-01-01 00:17:37 |
متحرک مشین کے واقعات کے علاوہ، ہر مشین کے بارے میں جامد میٹا ڈیٹا بھی دستیاب ہے۔ اس میں مشین کا منفرد شناخت کنندہ، کابینہ کی قسم، مقام، آپریٹنگ سسٹم، سافٹ ویئر ورژن، گیم تھیم، اور مزید جیسی معلومات شامل ہیں، جیسا کہ درج ذیل جدول میں دکھایا گیا ہے۔ (کسٹمر کی معلومات کی حفاظت کے لیے ٹیبل میں موجود تمام نام گمنام ہیں۔)
| مشین کی شناخت | کابینہ کی قسم | OS | جگہ | کھیل تھیم |
|---|---|---|---|---|
| 276 | A | OS_Ver0 | AA ریزورٹ اور کیسینو | StormMaiden |
| 167 | B | OS_Ver1 | بی بی کیسینو، ریزورٹ اور سپا | یو ایچ ایم ایل انڈیا |
| 13 | C | OS_Ver0 | CC کیسینو اور ہوٹل | زبردست ٹائیگر |
| 307 | D | OS_Ver0 | ڈی ڈی کیسینو ریسارٹ | NeptunesRealm |
| 70 | E | OS_Ver0 | EE ریزورٹ اور کیسینو | RLPMealTicket |
مسلے کی تعریف
ہم سلاٹ مشینوں کے لیے پیشین گوئی کی دیکھ بھال کے مسئلے کو بائنری درجہ بندی کے مسئلے کے طور پر دیکھتے ہیں۔ ML ماڈل مشین کے واقعات اور دیگر میٹا ڈیٹا کی تاریخی ترتیب میں لیتا ہے اور پیش گوئی کرتا ہے کہ آیا 6 گھنٹے کے مستقبل کے ٹائم ونڈو میں مشین کو ناکامی کا سامنا کرنا پڑے گا۔ اگر کوئی مشین 6 گھنٹے کے اندر ٹوٹ جاتی ہے، تو اسے دیکھ بھال کے لیے اعلیٰ ترجیح والی مشین سمجھا جاتا ہے۔ دوسری صورت میں، یہ کم ترجیح ہے. مندرجہ ذیل اعداد و شمار کم ترجیح (اوپر) اور اعلی ترجیح (نیچے) نمونوں کی مثالیں دیتا ہے۔ ہم پیشین گوئی کے لیے تاریخی مشین ایونٹ کا ڈیٹا اکٹھا کرنے کے لیے ایک فکسڈ لینتھ لُک بیک ٹائم ونڈو کا استعمال کرتے ہیں۔ تجربات سے پتہ چلتا ہے کہ زیادہ دیر تک دیکھنے کے وقت کی ونڈوز ماڈل کی کارکردگی کو نمایاں طور پر بہتر کرتی ہے (مزید تفصیلات بعد میں اس پوسٹ میں)۔

ماڈلنگ کے چیلنجز
ہمیں اس مسئلے کو حل کرنے کے لیے چند چیلنجوں کا سامنا کرنا پڑا:
- ہمارے پاس ایک بہت بڑی رقم کے ایونٹ لاگ ہیں جن میں ایک ماہ میں تقریباً 50 ملین ایونٹس ہوتے ہیں (تقریباً 1,000 گیم کے نمونوں سے)۔ ڈیٹا نکالنے اور پری پروسیسنگ کے مرحلے میں محتاط اصلاح کی ضرورت ہے۔
- وقت کے ساتھ واقعات کی انتہائی غیر مساوی تقسیم کی وجہ سے ایونٹ کی ترتیب ماڈلنگ چیلنجنگ تھی۔ 3 گھنٹے کی ونڈو دسیوں سے لے کر ہزاروں واقعات پر مشتمل ہو سکتی ہے۔
- مشینیں زیادہ تر وقت اچھی حالت میں ہوتی ہیں اور اعلیٰ ترجیحی دیکھ بھال ایک نایاب طبقہ ہے، جس نے طبقاتی عدم توازن کا مسئلہ پیش کیا۔
- سسٹم میں نئی مشینیں لگاتار شامل کی جاتی ہیں، اس لیے ہمیں یہ یقینی بنانا تھا کہ ہمارا ماڈل نئی مشینوں کے بارے میں پیشین گوئی کو سنبھال سکتا ہے جو کبھی تربیت میں نہیں دیکھی گئیں۔
ڈیٹا پری پروسیسنگ اور فیچر انجینئرنگ
اس سیکشن میں، ہم ڈیٹا کی تیاری اور فیچر انجینئرنگ کے اپنے طریقوں پر تبادلہ خیال کرتے ہیں۔
فیچر انجینئرنگ
سلاٹ مشین فیڈ غیر مساوی فاصلہ والے ٹائم سیریز کے واقعات کی ندیاں ہیں۔ مثال کے طور پر، 3 گھنٹے کی ونڈو میں واقعات کی تعداد دسیوں سے ہزاروں تک ہو سکتی ہے۔ اس عدم توازن کو سنبھالنے کے لیے، ہم نے خام ترتیب والے ڈیٹا کے بجائے ایونٹ کی فریکوئنسی استعمال کی۔ ایک سیدھا سادا نقطہ نظر پوری لُک بیک ونڈو کے لیے ایونٹ کی فریکوئنسی کو جمع کرنا اور اسے ماڈل میں فیڈ کرنا ہے۔ تاہم، اس نمائندگی کو استعمال کرتے وقت، وقتی معلومات ضائع ہو جاتی ہیں، اور واقعات کی ترتیب محفوظ نہیں رہتی ہے۔ اس کے بجائے ہم نے ٹائم ونڈو کو N مساوی ذیلی ونڈوز میں تقسیم کرکے اور ہر ایک میں ایونٹ کی فریکوئنسی کا حساب لگا کر وقتی بائننگ کا استعمال کیا۔ ٹائم ونڈو کی آخری خصوصیات اس کی تمام ذیلی ونڈو خصوصیات کا مجموعہ ہیں۔ ڈبوں کی تعداد میں اضافہ زیادہ وقتی معلومات کو محفوظ رکھتا ہے۔ مندرجہ ذیل تصویر نمونے کی کھڑکی پر عارضی بائننگ کو واضح کرتی ہے۔
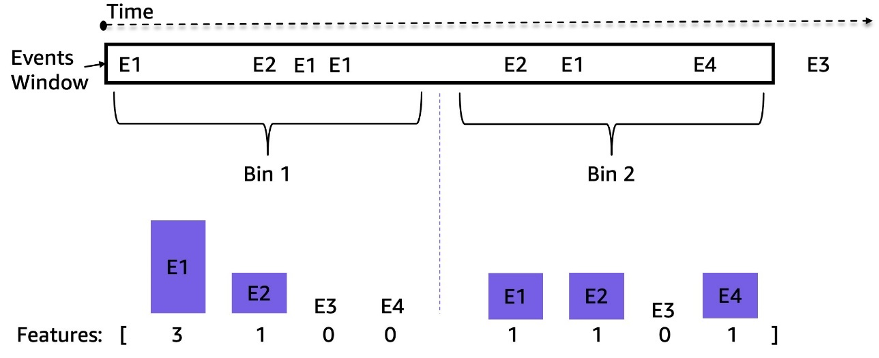
سب سے پہلے، نمونہ ٹائم ونڈو کو دو مساوی ذیلی کھڑکیوں (بِنز) میں تقسیم کیا جاتا ہے؛ مثال کے لیے ہم نے یہاں صرف دو ڈبے استعمال کیے ہیں۔ پھر، واقعات E1، E2، E3، اور E4 کی گنتی ہر ایک بن میں شمار کی جاتی ہے۔ آخر میں، وہ مربوط اور خصوصیات کے طور پر استعمال ہوتے ہیں۔
ایونٹ کی فریکوئنسی پر مبنی خصوصیات کے ساتھ، ہم نے مشین کے لیے مخصوص خصوصیات جیسے سافٹ ویئر ورژن، کابینہ کی قسم، گیم تھیم، اور گیم ورژن کا استعمال کیا۔ مزید برآں، ہم نے ٹائم اسٹیمپ سے متعلق خصوصیات شامل کیں تاکہ موسمی کیفیت کو پکڑا جا سکے، جیسے دن کا گھنٹہ اور ہفتے کا دن۔
ڈیٹا کی تیاری
تربیت اور جانچ کے لیے ڈیٹا کو مؤثر طریقے سے نکالنے کے لیے، ہم Amazon Athena اور AWS Glue Data Catalog کا استعمال کرتے ہیں۔ واقعات کا ڈیٹا Amazon S3 میں Parquet فارمیٹ میں محفوظ کیا جاتا ہے اور دن/مہینہ/گھنٹہ کے مطابق تقسیم کیا جاتا ہے۔ یہ ایک مخصوص ٹائم ونڈو کے اندر ڈیٹا کے نمونوں کے موثر نکالنے میں سہولت فراہم کرتا ہے۔ ہم تازہ ترین مہینے میں تمام مشینوں کا ڈیٹا ٹیسٹنگ کے لیے استعمال کرتے ہیں اور بقیہ ڈیٹا کو تربیت کے لیے استعمال کرتے ہیں، جس سے ڈیٹا کے ممکنہ رساو سے بچنے میں مدد ملتی ہے۔
ایم ایل طریقہ کار اور ماڈل ٹریننگ
اس سیکشن میں، ہم AutoGluon کے ساتھ اپنے بیس لائن ماڈل پر بات کرتے ہیں اور کس طرح ہم نے SageMaker آٹومیٹک ماڈل ٹیوننگ کے ساتھ حسب ضرورت نیورل نیٹ ورک بنایا۔
AutoGluon کے ساتھ ایک بیس لائن ماڈل بنانا
کسی بھی ML استعمال کے معاملے کے ساتھ، موازنہ اور تکرار کے لیے استعمال کیے جانے والے بنیادی ماڈل کو قائم کرنا ضروری ہے۔ ہم نے استعمال کیا آٹوگلون کئی کلاسک ML الگورتھم کو دریافت کرنے کے لیے۔ AutoGluon استعمال میں آسان AutoML ٹول ہے جو خودکار ڈیٹا پروسیسنگ، ہائپر پیرامیٹر ٹیوننگ، اور ماڈل کا جوڑا استعمال کرتا ہے۔ بہترین بیس لائن گریڈینٹ بوسٹڈ ڈیسیسن ٹری ماڈلز کے وزنی جوڑ کے ساتھ حاصل کی گئی۔ AutoGluon کے استعمال میں آسانی نے ہمیں دریافت کے مرحلے میں ممکنہ ڈیٹا اور ML ماڈلنگ ڈائریکشنز کی ایک وسیع رینج کے ذریعے تیزی سے اور مؤثر طریقے سے تشریف لے جانے میں مدد کی۔
سیج میکر آٹومیٹک ماڈل ٹیوننگ کے ساتھ حسب ضرورت نیورل نیٹ ورک ماڈل کی تعمیر اور ٹیوننگ
مختلف نیورل نیٹ ورکس کے فن تعمیر کے ساتھ تجربہ کرنے کے بعد، ہم نے پیشن گوئی کی دیکھ بھال کے لیے ایک حسب ضرورت ڈیپ لرننگ ماڈل بنایا۔ ہمارے ماڈل نے AutoGluon بیس لائن ماڈل کو 121% درستگی پر ریکال میں 80% سے پیچھے چھوڑ دیا۔ حتمی ماڈل میں تاریخی مشین ایونٹ کی ترتیب کا ڈیٹا، وقت کی خصوصیات جیسے دن کا گھنٹہ، اور جامد مشین میٹا ڈیٹا شامل ہوتا ہے۔ ہم استعمال کرتے ہیں۔ سیج میکر خودکار ماڈل ٹیوننگ بہترین ہائپرپیرامیٹر اور ماڈل آرکیٹیکچرز تلاش کرنے کے لیے نوکریاں۔
مندرجہ ذیل تصویر ماڈل فن تعمیر کو ظاہر کرتی ہے۔ ہم سب سے پہلے ٹریننگ سیٹ میں ہر ایونٹ کی اوسط فریکوئنسی کے حساب سے بائنڈ ایونٹ سیکوینس ڈیٹا کو نارملائز کرتے ہیں تاکہ ہائی فریکونسی ایونٹس (گیم کا آغاز، گیم کا اختتام، اور اسی طرح) کے زبردست اثر کو دور کیا جا سکے۔ انفرادی واقعات کے لیے ایمبیڈنگز سیکھنے کے قابل ہیں، جبکہ عارضی فیچر ایمبیڈنگز (ہفتے کا دن، دن کا گھنٹہ) پیکج کا استعمال کرتے ہوئے نکالا جاتا ہے۔ گلوون ٹی ایس. اس کے بعد ہم ماڈل میں ان پٹ کے طور پر وقتی فیچر ایمبیڈنگ کے ساتھ ایونٹ کی ترتیب کے ڈیٹا کو جوڑتے ہیں۔ ماڈل مندرجہ ذیل تہوں پر مشتمل ہے:
- Convolutional Layers (CNN) - ہر CNN پرت بقایا کنکشن کے ساتھ دو 1 جہتی convolutional آپریشنز پر مشتمل ہے۔ ہر CNN پرت کے آؤٹ پٹ میں دوسرے ماڈیولز کے ساتھ آسانی سے اسٹیکنگ کی اجازت دینے کے لیے ان پٹ کے برابر لمبائی ہوتی ہے۔ CNN تہوں کی کل تعداد ایک ٹیون ایبل ہائپر پیرامیٹر ہے۔
- ٹرانسفارمر انکوڈر لیئرز (TRANS) - CNN تہوں کے آؤٹ پٹ کو ملٹی ہیڈ سیلف اٹینشن سٹرکچر میں پوزیشنل انکوڈنگ کے ساتھ فیڈ کیا جاتا ہے۔ ہم بار بار چلنے والے نیورل نیٹ ورکس کو استعمال کرنے کے بجائے عارضی انحصار کو براہ راست حاصل کرنے کے لیے TRANS کا استعمال کرتے ہیں۔ یہاں، خام ترتیب کے اعداد و شمار کو بائننگ کرنے سے (لمبائی کو ہزاروں سے سینکڑوں تک کم کرنا) GPU میموری کی رکاوٹوں کو دور کرنے میں مدد کرتا ہے، جبکہ تاریخی معلومات کو ٹیون ایبل حد تک رکھتے ہوئے (بِنز کی تعداد ایک ٹیون ایبل ہائپر پیرامیٹر ہے)۔
- ایگریگیشن لیئرز (AGG) - آخری پرت میٹا ڈیٹا کی معلومات (گیم تھیم کی قسم، کابینہ کی قسم، مقامات) کو یکجا کرتی ہے تاکہ ترجیحی سطح کے امکانات کی پیشن گوئی تیار کی جا سکے۔ یہ کئی پولنگ پرتوں پر مشتمل ہے اور جہت میں اضافہ میں کمی کے لیے مکمل طور پر منسلک تہوں پر مشتمل ہے۔ میٹا ڈیٹا کے ملٹی ہاٹ ایمبیڈنگز بھی سیکھنے کے قابل ہیں، اور CNN اور TRANS کی تہوں سے نہیں گزرتے ہیں کیونکہ ان میں ترتیب وار معلومات نہیں ہوتی ہیں۔
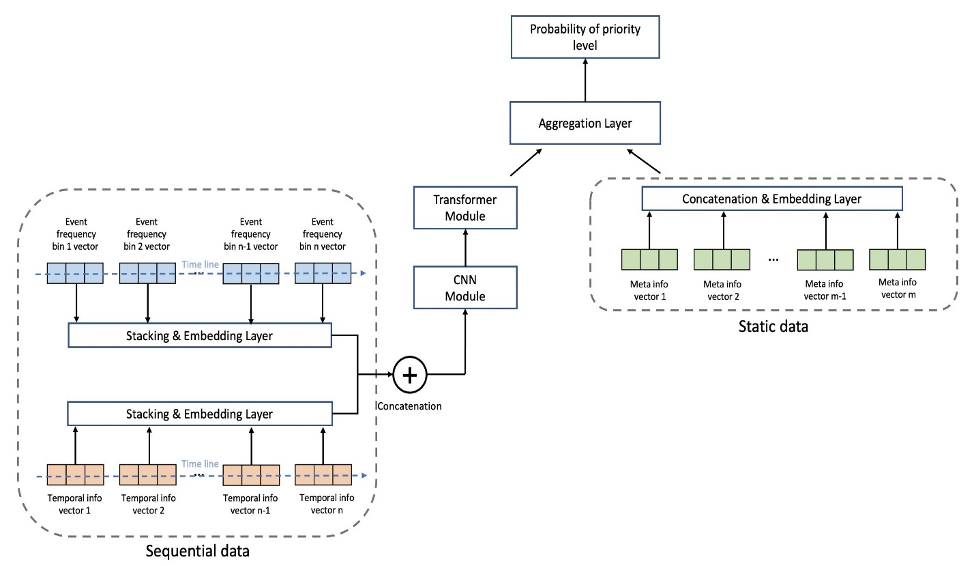
ہم طبقاتی عدم توازن کے مسئلے کو ایڈجسٹ کرنے کے لیے کلاس وزن کے ساتھ کراس اینٹروپی نقصان کو ٹیون ایبل ہائپر پیرامیٹر کے طور پر استعمال کرتے ہیں۔ اس کے علاوہ، CNN اور TRANS تہوں کی تعداد 0 کی ممکنہ قدروں کے ساتھ اہم ہائپر پیرامیٹر ہیں، جس کا مطلب ہے کہ ماڈل فن تعمیر میں مخصوص پرتیں ہمیشہ موجود نہیں ہوسکتی ہیں۔ اس طرح، ہمارے پاس ایک متحد فریم ورک ہے جہاں ماڈل آرکیٹیکچرز کو دوسرے معمول کے ہائپر پیرامیٹر کے ساتھ تلاش کیا جاتا ہے۔
ہم SageMaker آٹومیٹک ماڈل ٹیوننگ کا استعمال کرتے ہیں، جسے ہائپر پیرامیٹر آپٹیمائزیشن (HPO) بھی کہا جاتا ہے، تاکہ ماڈل کی مختلف حالتوں اور تمام ہائپر پیرامیٹر کی بڑی تلاش کی جگہ کو مؤثر طریقے سے دریافت کیا جا سکے۔ خودکار ماڈل ٹیوننگ حسب ضرورت الگورتھم، ٹریننگ ڈیٹا، اور ہائپر پیرامیٹر سرچ اسپیس کنفیگریشنز حاصل کرتی ہے، اور متوازی طور پر متعدد GPU مثالوں کے ساتھ مختلف حکمت عملیوں جیسے Bayesian، Hyperband، اور مزید کا استعمال کرتے ہوئے بہترین ہائپر پیرامیٹر کی تلاش کرتی ہے۔ ہولڈ آؤٹ توثیق سیٹ پر جائزہ لینے کے بعد، ہم نے CNN کی دو پرتوں کے ساتھ بہترین ماڈل فن تعمیر، چار ہیڈز کے ساتھ TRANS کی ایک پرت، اور ایک AGG پرت حاصل کی۔
ہم نے بہترین ماڈل فن تعمیر کی تلاش کے لیے درج ذیل ہائپرپیرامیٹر رینجز کا استعمال کیا:
ماڈل کی درستگی کو مزید بہتر بنانے اور ماڈل کے تغیر کو کم کرنے کے لیے، ہم نے ماڈل کو متعدد آزاد بے ترتیب وزن کی ابتدا کے ساتھ تربیت دی، اور حتمی امکانی پیشین گوئی کے طور پر اوسط قدروں کے ساتھ نتیجہ کو جمع کیا۔ کمپیوٹنگ کے مزید وسائل اور ماڈل کی بہتر کارکردگی کے درمیان تجارت ہے، اور ہم نے مشاہدہ کیا کہ موجودہ استعمال کے معاملے میں 5–10 کو ایک مناسب نمبر ہونا چاہیے (نتائج بعد میں اس پوسٹ میں دکھائے گئے ہیں)۔
ماڈل کی کارکردگی کے نتائج
اس سیکشن میں، ہم ماڈل کی کارکردگی کی جانچ کے میٹرکس اور نتائج پیش کرتے ہیں۔
تشخیصی میٹرکس
اس پیشن گوئی کی بحالی کے استعمال کے کیس کے لئے صحت سے متعلق بہت اہم ہے. کم درستگی کا مطلب ہے زیادہ غلط دیکھ بھال کی کالوں کی اطلاع دینا، جو غیر ضروری دیکھ بھال کے ذریعے اخراجات کو بڑھاتی ہے۔ چونکہ اوسط درستگی (AP) اعلی درستگی کے مقصد کے ساتھ مکمل طور پر ہم آہنگ نہیں ہوتی ہے، اس لیے ہم نے ایک نیا میٹرک متعارف کرایا ہے جس کا نام ایوریج ریکال ایٹ ہائی پریسیئنز (ARHP) ہے۔ ARHP 60%، 70%، اور 80% درستگی پوائنٹس پر یاد کرنے کی اوسط کے برابر ہے۔ ہم نے اوپری K% (K=1, 10)، AUPR، اور AUROC کو اضافی میٹرکس کے طور پر بھی استعمال کیا۔
نتائج کی نمائش
مندرجہ ذیل جدول 7/1/2022 کو ٹرین/ٹیسٹ اسپلٹ پوائنٹ کے طور پر بیس لائن اور حسب ضرورت نیورل نیٹ ورک ماڈلز کا استعمال کرتے ہوئے نتائج کا خلاصہ کرتا ہے۔ تجربات سے پتہ چلتا ہے کہ کھڑکی کی لمبائی اور نمونے کے ڈیٹا کے سائز میں اضافہ دونوں ہی ماڈل کی کارکردگی کو بہتر بناتے ہیں، کیونکہ ان میں پیشین گوئی میں مدد کے لیے مزید تاریخی معلومات ہوتی ہیں۔ ڈیٹا سیٹنگز سے قطع نظر، نیورل نیٹ ورک ماڈل تمام میٹرکس میں آٹو گلوون سے بہتر کارکردگی کا مظاہرہ کرتا ہے۔ مثال کے طور پر، فکسڈ 80% درستگی پر یاد کرنے میں 121% اضافہ ہوتا ہے، جو آپ کو نیورل نیٹ ورک ماڈل استعمال کرنے پر مزید خراب مشینوں کی فوری شناخت کرنے کے قابل بناتا ہے۔
| ماڈل | کھڑکی کی لمبائی/ڈیٹا کا سائز | AUROC | اے پی آر | اے آر ایچ پی | [ای میل محفوظ] | [ای میل محفوظ] | [ای میل محفوظ] | Prec@top1% | Prec@top10% |
|---|---|---|---|---|---|---|---|---|---|
| آٹوگلون بیس لائن | 12H/500k | 66.5 | 36.1 | 9.5 | 12.7 | 9.3 | 6.5 | 85 | 42 |
| نیورل نیٹ ورک | 12H/500k | 74.7 | 46.5 | 18.5 | 25 | 18.1 | 12.3 | 89 | 55 |
| آٹوگلون بیس لائن | 48H/1mm | 70.2 | 44.9 | 18.8 | 26.5 | 18.4 | 11.5 | 92 | 55 |
| نیورل نیٹ ورک | 48H/1mm | 75.2 | 53.1 | 32.4 | 39.3 | 32.6 | 25.4 | 94 | 65 |
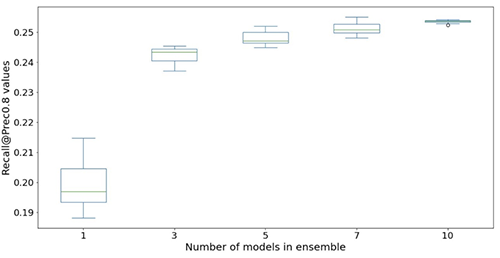
مندرجہ ذیل اعداد و شمار نیورل نیٹ ورک ماڈل کی کارکردگی کو بڑھانے کے لیے جوڑ کے استعمال کے اثر کو واضح کرتے ہیں۔ x-axis پر دکھائے گئے تمام تشخیصی میٹرکس کو بہتر بنایا گیا ہے، اعلی اوسط (زیادہ درست) اور کم تغیر (زیادہ مستحکم) کے ساتھ۔ ہر باکس پلاٹ 12 بار بار کیے گئے تجربات سے ہوتا ہے، بغیر کسی جوڑ کے 10 ماڈلز تک جوڑ (x-axis)۔ اسی طرح کے رجحانات دکھائے گئے Prec@top1% اور Recall@Prec80% کے علاوہ تمام میٹرکس میں برقرار ہیں۔
کمپیوٹیشنل لاگت میں فیکٹرنگ کرنے کے بعد، ہم مشاہدہ کرتے ہیں کہ 5-10 ماڈلز کا استعمال لائٹ اینڈ ونڈر ڈیٹاسیٹس کے لیے موزوں ہے۔

نتیجہ
ہمارے تعاون کے نتیجے میں گیمنگ انڈسٹری کے لیے ایک اہم پیشین گوئی کی دیکھ بھال کے حل کے ساتھ ساتھ دوبارہ استعمال کے قابل فریم ورک کی تخلیق ہوئی ہے جسے مختلف قسم کے پیش گوئی کرنے والے دیکھ بھال کے منظرناموں میں استعمال کیا جا سکتا ہے۔ AWS ٹیکنالوجیز جیسا کہ SageMaker آٹومیٹک ماڈل ٹیوننگ کو اپنانا لائٹ اینڈ ونڈر کو قریب قریب ریئل ٹائم ڈیٹا اسٹریمز کا استعمال کرتے ہوئے نئے مواقع پر نیویگیٹ کرنے کی سہولت فراہم کرتا ہے۔ لائٹ اینڈ ونڈر AWS پر تعیناتی شروع کر رہا ہے۔
اگر آپ اپنی مصنوعات اور خدمات میں ایم ایل کے استعمال کو تیز کرنے میں مدد چاہتے ہیں، تو براہ کرم رابطہ کریں۔ ایمیزون ایم ایل حل لیب پروگرام.
مصنفین کے بارے میں
 ارونا ابیاکون لائٹ اینڈ ونڈر لینڈ پر مبنی گیمنگ ڈویژن میں ڈیٹا سائنس اور تجزیات کے سینئر ڈائریکٹر ہیں۔ ارونا انڈسٹری کے پہلے لائٹ اینڈ ونڈر کنیکٹ اقدام کی قیادت کرتی ہے اور صارفین کے رویے اور مصنوعات کی بصیرت کے ساتھ کیسینو پارٹنرز اور اندرونی اسٹیک ہولڈرز دونوں کو بہتر گیمز بنانے، مصنوعات کی پیشکشوں کو بہتر بنانے، اثاثوں کا نظم کرنے، اور صحت کی نگرانی اور پیشن گوئی کی دیکھ بھال کے لیے معاونت کرتی ہے۔
ارونا ابیاکون لائٹ اینڈ ونڈر لینڈ پر مبنی گیمنگ ڈویژن میں ڈیٹا سائنس اور تجزیات کے سینئر ڈائریکٹر ہیں۔ ارونا انڈسٹری کے پہلے لائٹ اینڈ ونڈر کنیکٹ اقدام کی قیادت کرتی ہے اور صارفین کے رویے اور مصنوعات کی بصیرت کے ساتھ کیسینو پارٹنرز اور اندرونی اسٹیک ہولڈرز دونوں کو بہتر گیمز بنانے، مصنوعات کی پیشکشوں کو بہتر بنانے، اثاثوں کا نظم کرنے، اور صحت کی نگرانی اور پیشن گوئی کی دیکھ بھال کے لیے معاونت کرتی ہے۔
 ڈینس کولن لائٹ اینڈ ونڈر میں ایک سینئر ڈیٹا سائنس مینیجر ہے، جو کہ ایک معروف کراس پلیٹ فارم گلوبل گیم کمپنی ہے۔ وہ گیمنگ ڈیٹا اور تجزیات کی ٹیم کی رکن ہے جو لائٹ اینڈ ونڈر کنیکٹ کے ذریعے مصنوعات کی کارکردگی اور صارفین کے تجربات کو بہتر بنانے کے لیے جدید حل تیار کرنے میں مدد کرتی ہے۔
ڈینس کولن لائٹ اینڈ ونڈر میں ایک سینئر ڈیٹا سائنس مینیجر ہے، جو کہ ایک معروف کراس پلیٹ فارم گلوبل گیم کمپنی ہے۔ وہ گیمنگ ڈیٹا اور تجزیات کی ٹیم کی رکن ہے جو لائٹ اینڈ ونڈر کنیکٹ کے ذریعے مصنوعات کی کارکردگی اور صارفین کے تجربات کو بہتر بنانے کے لیے جدید حل تیار کرنے میں مدد کرتی ہے۔
 تصفغبیر مہریزی ۔ ایمیزون ایم ایل سلوشنز لیب میں ڈیٹا سائنٹسٹ ہے جہاں وہ مختلف صنعتوں جیسے گیمنگ، ہیلتھ کیئر اور لائف سائنسز، مینوفیکچرنگ، آٹوموٹیو، اور کھیل اور میڈیا میں AWS صارفین کی مدد کرتا ہے، اپنے کاروبار کو حل کرنے کے لیے مشین لرننگ اور AWS کلاؤڈ سروسز کے استعمال کو تیز کرتا ہے۔ چیلنجز
تصفغبیر مہریزی ۔ ایمیزون ایم ایل سلوشنز لیب میں ڈیٹا سائنٹسٹ ہے جہاں وہ مختلف صنعتوں جیسے گیمنگ، ہیلتھ کیئر اور لائف سائنسز، مینوفیکچرنگ، آٹوموٹیو، اور کھیل اور میڈیا میں AWS صارفین کی مدد کرتا ہے، اپنے کاروبار کو حل کرنے کے لیے مشین لرننگ اور AWS کلاؤڈ سروسز کے استعمال کو تیز کرتا ہے۔ چیلنجز
 محمد الجزائری۔ Amazon ML Solutions Lab میں ایک اپلائیڈ سائنسدان ہے۔ وہ AWS کے صارفین کو لاجسٹکس، پرسنلائزیشن اور سفارشات، کمپیوٹر ویژن، فراڈ کی روک تھام، پیشن گوئی اور سپلائی چین آپٹیمائزیشن جیسے شعبوں میں اپنے کاروباری چیلنجوں سے نمٹنے کے لیے ML سلوشنز کی شناخت اور تعمیر کرنے میں مدد کرتا ہے۔
محمد الجزائری۔ Amazon ML Solutions Lab میں ایک اپلائیڈ سائنسدان ہے۔ وہ AWS کے صارفین کو لاجسٹکس، پرسنلائزیشن اور سفارشات، کمپیوٹر ویژن، فراڈ کی روک تھام، پیشن گوئی اور سپلائی چین آپٹیمائزیشن جیسے شعبوں میں اپنے کاروباری چیلنجوں سے نمٹنے کے لیے ML سلوشنز کی شناخت اور تعمیر کرنے میں مدد کرتا ہے۔
 یاوی وانگ ایمیزون ایم ایل سلوشن لیب میں ایک اپلائیڈ سائنٹسٹ ہے۔ وہ AWS کے کاروباری شراکت داروں کو حقیقی دنیا کے منظر نامے میں اپنی تنظیم کے کاروباری چیلنجوں سے نمٹنے کے لیے ML حل کی شناخت اور تعمیر کرنے میں مدد کرتا ہے۔
یاوی وانگ ایمیزون ایم ایل سلوشن لیب میں ایک اپلائیڈ سائنٹسٹ ہے۔ وہ AWS کے کاروباری شراکت داروں کو حقیقی دنیا کے منظر نامے میں اپنی تنظیم کے کاروباری چیلنجوں سے نمٹنے کے لیے ML حل کی شناخت اور تعمیر کرنے میں مدد کرتا ہے۔
 یون چاؤ Amazon ML Solutions Lab میں ایک اپلائیڈ سائنٹسٹ ہے، جہاں وہ AWS صارفین کی کامیابی کو یقینی بنانے کے لیے تحقیق اور ترقی میں مدد کرتا ہے۔ وہ شماریاتی ماڈلنگ اور مشین لرننگ تکنیکوں کا استعمال کرتے ہوئے مختلف صنعتوں کے لیے اہم حل پر کام کرتا ہے۔ اس کی دلچسپی میں جنریٹو ماڈل اور ترتیب وار ڈیٹا ماڈلنگ شامل ہے۔
یون چاؤ Amazon ML Solutions Lab میں ایک اپلائیڈ سائنٹسٹ ہے، جہاں وہ AWS صارفین کی کامیابی کو یقینی بنانے کے لیے تحقیق اور ترقی میں مدد کرتا ہے۔ وہ شماریاتی ماڈلنگ اور مشین لرننگ تکنیکوں کا استعمال کرتے ہوئے مختلف صنعتوں کے لیے اہم حل پر کام کرتا ہے۔ اس کی دلچسپی میں جنریٹو ماڈل اور ترتیب وار ڈیٹا ماڈلنگ شامل ہے۔
 پانپن سو AWS میں Amazon ML Solutions Lab کے ساتھ اپلائیڈ سائنس مینیجر ہے۔ وہ مشین لرننگ الگورتھم کی تحقیق اور ترقی پر کام کر رہی ہے تاکہ ان کے AI اور کلاؤڈ کو اپنانے کو تیز کرنے کے لیے صنعتی عمودی کی ایک قسم میں اعلیٰ اثر والے کسٹمر ایپلی کیشنز کے لیے۔ اس کی تحقیقی دلچسپی میں ماڈل کی تشریح، وجہ تجزیہ، ہیومن ان دی لوپ AI اور انٹرایکٹو ڈیٹا ویژولائزیشن شامل ہے۔
پانپن سو AWS میں Amazon ML Solutions Lab کے ساتھ اپلائیڈ سائنس مینیجر ہے۔ وہ مشین لرننگ الگورتھم کی تحقیق اور ترقی پر کام کر رہی ہے تاکہ ان کے AI اور کلاؤڈ کو اپنانے کو تیز کرنے کے لیے صنعتی عمودی کی ایک قسم میں اعلیٰ اثر والے کسٹمر ایپلی کیشنز کے لیے۔ اس کی تحقیقی دلچسپی میں ماڈل کی تشریح، وجہ تجزیہ، ہیومن ان دی لوپ AI اور انٹرایکٹو ڈیٹا ویژولائزیشن شامل ہے۔
 راج سلواجی۔ AWS میں ہاسپٹلٹی سیگمنٹ میں سولیوشنز آرکیٹیکچر کی قیادت کرتا ہے۔ وہ پیچیدہ کاروباری چیلنجوں کے حل کے لیے تزویراتی رہنمائی، تکنیکی مہارت فراہم کرکے مہمان نوازی کے صارفین کے ساتھ کام کرتا ہے۔ وہ ہاسپیٹلٹی، فنانس اور آٹوموٹیو انڈسٹریز میں انجینئرنگ کے متعدد کرداروں میں 25 سال کا تجربہ حاصل کرتا ہے۔
راج سلواجی۔ AWS میں ہاسپٹلٹی سیگمنٹ میں سولیوشنز آرکیٹیکچر کی قیادت کرتا ہے۔ وہ پیچیدہ کاروباری چیلنجوں کے حل کے لیے تزویراتی رہنمائی، تکنیکی مہارت فراہم کرکے مہمان نوازی کے صارفین کے ساتھ کام کرتا ہے۔ وہ ہاسپیٹلٹی، فنانس اور آٹوموٹیو انڈسٹریز میں انجینئرنگ کے متعدد کرداروں میں 25 سال کا تجربہ حاصل کرتا ہے۔
 شان رائے AWS میں Amazon ML Solutions Lab کے ساتھ ایک پرنسپل ML سٹریٹجسٹ ہے۔ وہ AWS کی کلاؤڈ بیسڈ AI/ML خدمات کا استعمال کرتے ہوئے صنعتوں کے متنوع سپیکٹرم میں صارفین کے ساتھ کام کرتا ہے تاکہ ان کی انتہائی اہم اور جدید کاروباری ضروریات کو حل کیا جا سکے۔
شان رائے AWS میں Amazon ML Solutions Lab کے ساتھ ایک پرنسپل ML سٹریٹجسٹ ہے۔ وہ AWS کی کلاؤڈ بیسڈ AI/ML خدمات کا استعمال کرتے ہوئے صنعتوں کے متنوع سپیکٹرم میں صارفین کے ساتھ کام کرتا ہے تاکہ ان کی انتہائی اہم اور جدید کاروباری ضروریات کو حل کیا جا سکے۔
- SEO سے چلنے والا مواد اور PR کی تقسیم۔ آج ہی بڑھا دیں۔
- ای وی ایم فنانس۔ وکندریقرت مالیات کے لیے متحد انٹرفیس۔ یہاں تک رسائی حاصل کریں۔
- کوانٹم میڈیا گروپ۔ آئی آر/پی آر ایمپلیفائیڈ۔ یہاں تک رسائی حاصل کریں۔
- پلیٹوآئ اسٹریم۔ ویب 3 ڈیٹا انٹیلی جنس۔ علم میں اضافہ۔ یہاں تک رسائی حاصل کریں۔
- ماخذ: https://aws.amazon.com/blogs/machine-learning/how-light-wonder-built-a-predictive-maintenance-solution-for-gaming-machines-on-aws/

