موثر کنٹرول پالیسیاں صنعتی کمپنیوں کو پیداواری صلاحیت کو زیادہ سے زیادہ کرنے کے ساتھ ساتھ غیر طے شدہ ڈاؤن ٹائم اور توانائی کی کھپت کو کم کر کے اپنے منافع میں اضافہ کرنے کے قابل بناتی ہیں۔ زیادہ سے زیادہ کنٹرول کی پالیسیاں تلاش کرنا ایک پیچیدہ کام ہے کیونکہ جسمانی نظام، جیسے کیمیکل ری ایکٹر اور ونڈ ٹربائنز کا ماڈل بنانا اکثر مشکل ہوتا ہے اور کیونکہ عمل کی حرکیات میں اضافہ وقت کے ساتھ ساتھ کارکردگی کو خراب کرنے کا سبب بن سکتا ہے۔ آف لائن ری انفورسمنٹ لرننگ ایک کنٹرول حکمت عملی ہے جو صنعتی کمپنیوں کو کسی واضح پروسیس ماڈل کی ضرورت کے بغیر مکمل طور پر تاریخی ڈیٹا سے کنٹرول پالیسیاں بنانے کی اجازت دیتی ہے۔ اس نقطہ نظر کو تلاش کے مرحلے میں براہ راست عمل کے ساتھ تعامل کی ضرورت نہیں ہے، جو حفاظتی اہم ایپلی کیشنز میں کمک سیکھنے کو اپنانے کے لیے رکاوٹوں میں سے ایک کو دور کرتا ہے۔ اس پوسٹ میں، ہم صرف تاریخی ڈیٹا کا استعمال کرتے ہوئے بہترین کنٹرول پالیسیاں تلاش کرنے کے لیے ایک آخر سے آخر تک حل تیار کریں گے۔ ایمیزون سیج میکر رے کا استعمال کرتے ہوئے RLlib کتب خانہ. کمک سیکھنے کے بارے میں مزید جاننے کے لیے، دیکھیں ایمیزون سیج میکر کے ساتھ کمک سیکھنے کا استعمال کریں۔
استعمال کے مقدمات
صنعتی کنٹرول میں پیچیدہ نظاموں کا انتظام شامل ہوتا ہے، جیسے کہ مینوفیکچرنگ لائنز، انرجی گرڈز، اور کیمیائی پلانٹس، تاکہ موثر اور قابل اعتماد آپریشن کو یقینی بنایا جا سکے۔ بہت سی روایتی کنٹرول حکمت عملی پہلے سے طے شدہ اصولوں اور ماڈلز پر مبنی ہوتی ہے، جن کے لیے اکثر دستی اصلاح کی ضرورت ہوتی ہے۔ کچھ صنعتوں میں کارکردگی کی نگرانی کرنا اور کنٹرول پالیسی کو ایڈجسٹ کرنا معیاری عمل ہے، مثال کے طور پر، جب آلات خراب ہونے لگتے ہیں یا ماحولیاتی حالات تبدیل ہوتے ہیں۔ ری ٹیوننگ میں ہفتے لگ سکتے ہیں اور اس کے ردعمل کو آزمائشی اور غلطی کے نقطہ نظر میں ریکارڈ کرنے کے لیے سسٹم میں بیرونی جوشوں کو انجیکشن لگانے کی ضرورت پڑ سکتی ہے۔
ماحول کے ساتھ تعامل کے ذریعے کنٹرول کی بہترین پالیسیوں کو سیکھنے کے لیے عمل کے کنٹرول میں کمک سیکھنے کی ایک نئی مثال کے طور پر ابھرا ہے۔ اس عمل کے لیے ڈیٹا کو تین قسموں میں تقسیم کرنے کی ضرورت ہے: 1) جسمانی نظام سے دستیاب پیمائش، 2) کارروائیوں کا مجموعہ جو سسٹم پر لیا جا سکتا ہے، اور 3) سامان کی کارکردگی کا عددی میٹرک (انعام)۔ ایک پالیسی کو ایک دیئے گئے مشاہدے پر عمل تلاش کرنے کے لیے تربیت دی جاتی ہے، جس سے مستقبل میں سب سے زیادہ انعامات حاصل ہونے کا امکان ہوتا ہے۔
آف لائن کمک سیکھنے میں، کوئی بھی تاریخی ڈیٹا کو پروڈکشن میں تعینات کرنے سے پہلے اس پر پالیسی کی تربیت دے سکتا ہے۔ اس بلاگ پوسٹ میں تربیت یافتہ الگورتھم کہلاتا ہے "قدامت پسند Q لرننگ(CQL)۔ CQL ایک "اداکار" ماڈل اور ایک "نقد" ماڈل پر مشتمل ہے اور اسے تجویز کردہ کارروائی کرنے کے بعد قدامت پسندی سے اپنی کارکردگی کا اندازہ لگانے کے لیے ڈیزائن کیا گیا ہے۔ اس پوسٹ میں، عمل کو ایک مثالی کارٹ پول کنٹرول مسئلہ کے ساتھ دکھایا گیا ہے۔ مقصد ایک ایجنٹ کو تربیت دینا ہے کہ وہ ایک کارٹ پر ایک کھمبے کو متوازن بنائے اور ساتھ ہی ساتھ کارٹ کو ایک مقررہ ہدف کے مقام کی طرف لے جائے۔ تربیت کا طریقہ کار آف لائن ڈیٹا کا استعمال کرتا ہے، جس سے ایجنٹ کو پہلے سے موجود معلومات سے سیکھنے کی اجازت ملتی ہے۔ یہ کارٹ پول کیس اسٹڈی تربیتی عمل اور ممکنہ حقیقی دنیا کی ایپلی کیشنز میں اس کی تاثیر کو ظاہر کرتا ہے۔
حل جائزہ
اس پوسٹ میں پیش کردہ حل تاریخی ڈیٹا کے ساتھ آف لائن کمک سیکھنے کے لیے آخر سے آخر تک ورک فلو کی تعیناتی کو خودکار بناتا ہے۔ مندرجہ ذیل خاکہ اس ورک فلو میں استعمال ہونے والے فن تعمیر کو بیان کرتا ہے۔ پیمائش کا ڈیٹا صنعتی آلات کے ایک ٹکڑے کے ذریعہ کنارے پر تیار کیا جاتا ہے (یہاں ایک او ڈبلیو ایس لامبڈا۔ فنکشن)۔ ڈیٹا کو ایک میں ڈال دیا جاتا ہے۔ ایمیزون کنیسیس ڈیٹا فائر ہوز، جو اسے اسٹور کرتا ہے۔ ایمیزون سادہ اسٹوریج سروس (ایمیزون S3)۔ Amazon S3 ایک پائیدار، پرفارمنٹ، اور کم لاگت اسٹوریج حل ہے جو آپ کو مشین لرننگ ٹریننگ کے عمل میں ڈیٹا کی بڑی مقدار فراہم کرنے کی اجازت دیتا ہے۔
AWS گلو ڈیٹا کو کیٹلاگ کرتا ہے اور اسے استعمال کرنے کے قابل بناتا ہے۔ ایمیزون ایتینا. ایتھینا پیمائش کے ڈیٹا کو اس شکل میں تبدیل کرتی ہے جسے ایک کمک سیکھنے والا الگورتھم کھا سکتا ہے اور پھر اسے واپس Amazon S3 میں اتار دیتا ہے۔ Amazon SageMaker اس ڈیٹا کو تربیتی کام میں لوڈ کرتا ہے اور ایک تربیت یافتہ ماڈل تیار کرتا ہے۔ سیج میکر پھر اس ماڈل کو سیج میکر اینڈ پوائنٹ میں پیش کرتا ہے۔ اس کے بعد صنعتی آلات کارروائی کی سفارشات حاصل کرنے کے لیے اس اختتامی نقطہ سے استفسار کر سکتے ہیں۔
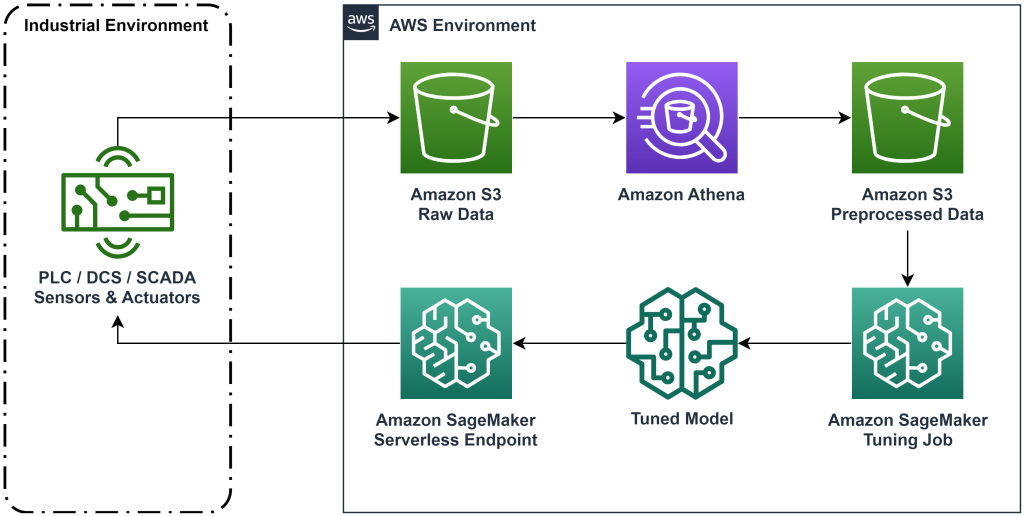
شکل 1: فن تعمیر کا خاکہ جو آخر سے آخر تک کمک سیکھنے کے ورک فلو کو دکھا رہا ہے۔
اس پوسٹ میں، ہم مندرجہ ذیل مراحل میں ورک فلو کو توڑ دیں گے۔
- مسئلہ وضع کریں۔ فیصلہ کریں کہ کون سے اقدامات کیے جاسکتے ہیں، کن پیمائشوں کی بنیاد پر سفارشات کی جائیں، اور عددی طور پر تعین کریں کہ ہر عمل نے کتنی اچھی کارکردگی کا مظاہرہ کیا۔
- ڈیٹا تیار کریں۔ پیمائش کے جدول کو اس فارمیٹ میں تبدیل کریں جو مشین لرننگ الگورتھم استعمال کر سکتا ہے۔
- اس ڈیٹا پر الگورتھم کو تربیت دیں۔
- ٹریننگ میٹرکس پر مبنی بہترین ٹریننگ کا انتخاب کریں۔
- ماڈل کو سیج میکر اینڈ پوائنٹ پر تعینات کریں۔
- پیداوار میں ماڈل کی کارکردگی کا اندازہ کریں.
شرائط
اس واک تھرو کو مکمل کرنے کے لیے، آپ کے پاس ایک ہونا ضروری ہے۔ AWS اکاؤنٹ اور کمانڈ لائن انٹرفیس کے ساتھ AWS SAM انسٹال ہوا۔. اس ورک فلو کو چلانے اور تربیتی ڈیٹا تیار کرنے کے لیے AWS SAM ٹیمپلیٹ کو تعینات کرنے کے لیے ان اقدامات پر عمل کریں:
- کمانڈ کے ساتھ کوڈ ریپوزٹری ڈاؤن لوڈ کریں۔
- ڈائرکٹری کو ریپو میں تبدیل کریں:
- ریپو بنائیں:
- ریپو تعینات کریں۔
- bash اسکرپٹ کو کال کرنے کے لیے درج ذیل کمانڈز کا استعمال کریں، جو AWS Lambda فنکشن کا استعمال کرتے ہوئے فرضی ڈیٹا تیار کرتا ہے۔
sudo yum install jqcd utilssh generate_mock_data.sh
حل واک تھرو
مسئلہ وضع کریں۔
اس بلاگ پوسٹ میں ہمارا سسٹم ایک ٹوکری ہے جس کے اوپر ایک قطب متوازن ہے۔ نظام اس وقت اچھی کارکردگی کا مظاہرہ کرتا ہے جب قطب سیدھا ہوتا ہے، اور کارٹ کی پوزیشن گول پوزیشن کے قریب ہوتی ہے۔ پیشگی مرحلے میں، ہم نے اس سسٹم سے تاریخی ڈیٹا تیار کیا۔
مندرجہ ذیل جدول سسٹم سے جمع کیے گئے تاریخی ڈیٹا کو دکھاتا ہے۔
| ٹوکری کی پوزیشن | ٹوکری کی رفتار | قطب زاویہ | قطب کونیی رفتار | گول پوزیشن | بیرونی قوت | انعام | وقت |
| 0.53 | 0.79- | 0.08- | 0.16 | 0.50 | 0.04- | 11.5 | 5:37:54 شام |
| 0.51 | 0.82- | 0.07- | 0.17 | 0.50 | 0.04- | 11.9 | 5:37:55 شام |
| 0.50 | 0.84- | 0.07- | 0.18 | 0.50 | 0.03- | 12.2 | 5:37:56 شام |
| 0.48 | 0.85- | 0.07- | 0.18 | 0.50 | 0.03- | 10.5 | 5:37:57 شام |
| 0.46 | 0.87- | 0.06- | 0.19 | 0.50 | 0.03- | 10.3 | 5:37:58 شام |
آپ مندرجہ ذیل استفسار کے ساتھ Amazon Athena کا استعمال کرتے ہوئے تاریخی نظام کی معلومات سے استفسار کر سکتے ہیں:
اس نظام کی حالت کارٹ کی پوزیشن، کارٹ کی رفتار، قطب زاویہ، قطب کونیی رفتار، اور ہدف کی پوزیشن سے بیان کی جاتی ہے۔ ہر بار قدم پر کی جانے والی کارروائی کارٹ پر لگائی جانے والی بیرونی قوت ہے۔ نقلی ماحول ایک انعامی قدر پیدا کرتا ہے جو اس وقت زیادہ ہوتا ہے جب کارٹ گول پوزیشن کے قریب ہوتا ہے اور قطب زیادہ سیدھا ہوتا ہے۔
ڈیٹا تیار کریں
نظام کی معلومات کو کمک سیکھنے کے ماڈل میں پیش کرنے کے لیے، اسے کلیدوں کے ساتھ JSON آبجیکٹ میں تبدیل کریں جو اقدار کو ریاست (جسے مشاہدہ بھی کہا جاتا ہے)، عمل اور انعام کے زمرے میں درجہ بندی کرتے ہیں۔ ان اشیاء کو Amazon S3 میں اسٹور کریں۔ یہاں پچھلے جدول میں وقت کے مراحل سے تیار کردہ JSON آبجیکٹ کی ایک مثال ہے۔
|
{“obs”:[[0.53,-0.79,-0.08,0.16,0.5]], “action”:[[-0.04]], “reward”:[11.5] ,”next_obs”:[[0.51,-0.82,-0.07,0.17,0.5]]} |
|
{“obs”:[[0.51,-0.82,-0.07,0.17,0.5]], “action”:[[-0.04]], “reward”:[11.9], “next_obs”:[[0.50,-0.84,-0.07,0.18,0.5]]} |
|
{“obs”:[[0.50,-0.84,-0.07,0.18,0.5]], “action”:[[-0.03]], “reward”:[12.2], “next_obs”:[[0.48,-0.85,-0.07,0.18,0.5]]} |
AWS CloudFormation اسٹیک میں ایک آؤٹ پٹ ہوتا ہے جسے کہا جاتا ہے۔ AthenaQueryToCreateJsonFormatedData. تبدیلی کو انجام دینے اور JSON اشیاء کو Amazon S3 میں ذخیرہ کرنے کے لیے اس استفسار کو Amazon Athena میں چلائیں۔ کمک سیکھنے کا الگورتھم ان JSON آبجیکٹ کی ساخت کو یہ سمجھنے کے لیے استعمال کرتا ہے کہ سفارشات کی بنیاد کن اقدار اور تاریخی اعداد و شمار میں کارروائی کرنے کے نتائج پر ہے۔
ٹرین ایجنٹ
اب ہم ایک تربیتی کام شروع کر سکتے ہیں تاکہ ایک تربیت یافتہ عمل کی سفارش کا ماڈل تیار کیا جا سکے۔ Amazon SageMaker آپ کو یہ دیکھنے کے لیے کہ کس طرح مختلف کنفیگریشنز نتیجے میں تربیت یافتہ ماڈل کو متاثر کرتی ہیں، آپ کو فوری طور پر متعدد تربیتی جابز شروع کرنے دیتا ہے۔ لیمبڈا فنکشن کو کال کریں۔ TuningJobLauncherFunction ایک ہائپر پیرامیٹر ٹیوننگ کام شروع کرنے کے لیے جو الگورتھم کو تربیت دیتے وقت ہائپر پیرامیٹر کے چار مختلف سیٹوں کے ساتھ تجربہ کرتا ہے۔
بہترین ٹریننگ رن کا انتخاب کریں۔
یہ جاننے کے لیے کہ کون سی تربیتی ملازمتوں نے بہترین ماڈل تیار کیا، تربیت کے دوران پیدا ہونے والے نقصان کے منحنی خطوط کا جائزہ لیں۔ CQL کا نقاد ماڈل تجویز کردہ کارروائی کرنے کے بعد اداکار کی کارکردگی (جسے Q ویلیو کہا جاتا ہے) کا تخمینہ لگاتا ہے۔ نقاد کے نقصان کے فنکشن کے ایک حصے میں وقتی فرق کی خرابی شامل ہے۔ یہ میٹرک نقاد کی Q قدر کی درستگی کی پیمائش کرتا ہے۔ اعلی اوسط Q قدر اور کم وقتی فرق کی خرابی کے ساتھ ٹریننگ رن تلاش کریں۔ یہ کاغذ، آف لائن ماڈل سے پاک روبوٹک کمک سیکھنے کے لیے ایک ورک فلو، بہترین ٹریننگ رن کو منتخب کرنے کے طریقہ کی تفصیلات۔ کوڈ کے ذخیرے میں ایک فائل ہے، /utils/investigate_training.py، جو جدید ترین تربیتی کام کو بیان کرنے والا ایک پلاٹلی HTML شکل بناتا ہے۔ اس فائل کو چلائیں اور بہترین ٹریننگ رن لینے کے لیے آؤٹ پٹ کا استعمال کریں۔
تربیت یافتہ ماڈل کی کارکردگی کا اندازہ لگانے کے لیے ہم اوسط Q قدر کا استعمال کر سکتے ہیں۔ Q اقدار کو مستقبل میں رعایتی انعامی قدروں کے مجموعے کی قدامت پسندی سے پیش گوئی کرنے کی تربیت دی جاتی ہے۔ طویل عرصے تک چلنے والے عمل کے لیے، ہم Q قدر کو (1-"رعایت کی شرح") سے ضرب دے کر اس نمبر کو تیزی سے وزنی اوسط میں تبدیل کر سکتے ہیں۔ اس سیٹ میں چلائی جانے والی بہترین تربیت نے 539 کی اوسط Q قیمت حاصل کی۔ ہماری رعایت کی شرح 0.99 ہے، اس لیے ماڈل فی وقت کم از کم 5.39 اوسط انعام کی پیش گوئی کر رہا ہے۔ آپ اس قدر کا موازنہ تاریخی نظام کی کارکردگی سے کر سکتے ہیں تاکہ یہ معلوم ہو سکے کہ آیا نیا ماڈل تاریخی کنٹرول پالیسی سے بہتر کارکردگی کا مظاہرہ کرے گا۔ اس تجربے میں، تاریخی اعداد و شمار کا اوسط انعام فی وقت 4.3 تھا، لہذا CQL ماڈل تاریخی طور پر حاصل کردہ نظام کے مقابلے میں 25 فیصد بہتر کارکردگی کی پیش گوئی کر رہا ہے۔
ماڈل تعینات کریں۔
Amazon SageMaker اینڈ پوائنٹس آپ کو مختلف طریقوں سے مشین لرننگ ماڈلز پیش کرنے دیتے ہیں تاکہ استعمال کے مختلف معاملات کو پورا کیا جا سکے۔ اس پوسٹ میں، ہم سرور لیس اینڈ پوائنٹ کی قسم استعمال کریں گے تاکہ ہمارا اینڈ پوائنٹ خود بخود ڈیمانڈ کے ساتھ پیمانہ ہو جائے، اور ہم کمپیوٹ کے استعمال کے لیے صرف اس وقت ادائیگی کرتے ہیں جب اختتامی نقطہ ایک تخمینہ پیدا کر رہا ہو۔ بغیر سرور کے اختتامی نقطہ کو تعینات کرنے کے لیے، شامل کریں a ProductionVariantServerlessConfig میں پیداوار کی مختلف قسم سیج میکر کے اختتامی نقطہ کی ترتیب. مندرجہ ذیل کوڈ کا ٹکڑا دکھاتا ہے کہ اس مثال میں سرور لیس اینڈ پوائنٹ کو Python کے لیے Amazon SageMaker سافٹ ویئر ڈویلپمنٹ کٹ کا استعمال کرتے ہوئے کیسے لگایا گیا ہے۔ پر ماڈل کو تعینات کرنے کے لیے استعمال ہونے والا نمونہ کوڈ تلاش کریں۔ sagemaker-offline-reinforcement-learning-ray-cql.
تربیت یافتہ ماڈل فائلیں ہر ٹریننگ رن کے لیے S3 ماڈل کے نمونے پر واقع ہوتی ہیں۔ مشین لرننگ ماڈل کو تعینات کرنے کے لیے، بہترین ٹریننگ رن کی ماڈل فائلوں کو تلاش کریں، اور Lambda فنکشن کو کال کریں جس کا نام ہے "ModelDeployerFunctionایک ایونٹ کے ساتھ جس میں یہ ماڈل ڈیٹا شامل ہے۔ Lambda فنکشن تربیت یافتہ ماڈل کی خدمت کے لیے SageMaker سرور لیس اینڈ پوائنٹ کا آغاز کرے گا۔ کال کرتے وقت استعمال کرنے کے لیے نمونہ واقعہModelDeployerFunction"
تربیت یافتہ ماڈل کی کارکردگی کا اندازہ کریں۔
یہ دیکھنے کا وقت ہے کہ ہمارا تربیت یافتہ ماڈل پیداوار میں کیسا کر رہا ہے! نئے ماڈل کی کارکردگی کو چیک کرنے کے لیے، لیمبڈا فنکشن کو کال کریں جس کا نام "RunPhysicsSimulationFunctionایونٹ میں سیج میکر اینڈ پوائنٹ کے نام کے ساتھ۔ یہ اختتامی نقطہ کے ذریعہ تجویز کردہ اعمال کا استعمال کرتے ہوئے تخروپن کو چلائے گا۔ کو کال کرتے وقت استعمال کرنے کے لیے نمونہ واقعہ RunPhysicsSimulatorFunction:
تربیت یافتہ ماڈل کی کارکردگی کا تاریخی نظام کی کارکردگی سے موازنہ کرنے کے لیے درج ذیل ایتھینا استفسار کا استعمال کریں۔
| عمل کا ذریعہ | فی ٹائم مرحلہ اوسط انعام |
trained_model |
10.8 |
historic_data |
4.3 |
مندرجہ ذیل اینیمیشنز ٹریننگ ڈیٹا سے نمونے کے ایپی سوڈ اور ایک ایپی سوڈ کے درمیان فرق ظاہر کرتی ہیں جہاں تربیت یافتہ ماڈل کو یہ چننے کے لیے استعمال کیا گیا تھا کہ کون سی کارروائی کرنی ہے۔ اینیمیشنز میں، نیلا باکس کارٹ ہے، نیلی لائن قطب ہے، اور سبز مستطیل گول مقام ہے۔ سرخ تیر ہر بار قدم پر کارٹ پر لگائی جانے والی قوت کو ظاہر کرتا ہے۔ ٹریننگ ڈیٹا میں سرخ تیر تھوڑا سا آگے پیچھے چھلانگ لگاتا ہے کیونکہ ڈیٹا 50 فیصد ماہرانہ کارروائیوں اور 50 فیصد بے ترتیب کارروائیوں کا استعمال کرتے ہوئے تیار کیا گیا تھا۔ تربیت یافتہ ماڈل نے ایک کنٹرول پالیسی سیکھی جو کارٹ کو تیزی سے ہدف کی پوزیشن پر لے جاتی ہے، استحکام کو برقرار رکھتے ہوئے، مکمل طور پر غیر ماہرانہ مظاہروں کا مشاہدہ کرنے سے۔
 |
 |
صاف کرو
اس ورک فلو میں استعمال ہونے والے وسائل کو حذف کرنے کے لیے، Amazon CloudFormation اسٹیک کے وسائل کے سیکشن پر جائیں اور S3 بالٹی اور IAM رولز کو حذف کریں۔ پھر کلاؤڈ فارمیشن اسٹیک کو ہی حذف کریں۔
نتیجہ
آف لائن کمک سیکھنے سے صنعتی کمپنیوں کو تاریخی ڈیٹا کا استعمال کرتے ہوئے حفاظت سے سمجھوتہ کیے بغیر بہترین پالیسیوں کی تلاش کو خودکار بنانے میں مدد مل سکتی ہے۔ اپنے کاموں میں اس نقطہ نظر کو لاگو کرنے کے لیے، ان پیمائشوں کی نشاندہی کرکے شروع کریں جو ریاست کے ذریعے طے شدہ نظام کو تشکیل دیتے ہیں، جن اعمال کو آپ کنٹرول کرسکتے ہیں، اور میٹرکس جو مطلوبہ کارکردگی کی نشاندہی کرتے ہیں۔ پھر، رسائی یہ GitHub ذخیرہ رے اور ایمیزون سیج میکر کا استعمال کرتے ہوئے ایک خودکار اینڈ ٹو اینڈ حل کے نفاذ کے لیے۔
پوسٹ صرف اس کی سطح کو کھرچتی ہے کہ آپ Amazon SageMaker RL کے ساتھ کیا کرسکتے ہیں۔ اسے آزمائیں، اور براہ کرم ہمیں فیڈ بیک بھیجیں، یا تو میں ایمیزون سیج میکر ڈسکشن فورم یا آپ کے معمول کے AWS رابطوں کے ذریعے۔
مصنفین کے بارے میں
 والٹ مے فیلڈ AWS میں ایک سولیوشن آرکیٹیکٹ ہے اور توانائی کمپنیوں کو زیادہ محفوظ اور موثر طریقے سے کام کرنے میں مدد کرتا ہے۔ AWS میں شامل ہونے سے پہلے، والٹ نے Hilcorp Energy Company میں آپریشن انجینئر کے طور پر کام کیا۔ وہ اپنے فارغ وقت میں باغبانی اور مچھلیاں اڑانا پسند کرتا ہے۔
والٹ مے فیلڈ AWS میں ایک سولیوشن آرکیٹیکٹ ہے اور توانائی کمپنیوں کو زیادہ محفوظ اور موثر طریقے سے کام کرنے میں مدد کرتا ہے۔ AWS میں شامل ہونے سے پہلے، والٹ نے Hilcorp Energy Company میں آپریشن انجینئر کے طور پر کام کیا۔ وہ اپنے فارغ وقت میں باغبانی اور مچھلیاں اڑانا پسند کرتا ہے۔
 فیلیپ لوپیز تیل اور گیس کی پیداوار کے کاموں میں توجہ کے ساتھ AWS میں ایک سینئر سولیوشن آرکیٹیکٹ ہے۔ AWS میں شامل ہونے سے پہلے، Felipe نے GE Digital اور Schlumberger کے ساتھ کام کیا، جہاں اس نے صنعتی ایپلی کیشنز کے لیے ماڈلنگ اور اصلاحی مصنوعات پر توجہ دی۔
فیلیپ لوپیز تیل اور گیس کی پیداوار کے کاموں میں توجہ کے ساتھ AWS میں ایک سینئر سولیوشن آرکیٹیکٹ ہے۔ AWS میں شامل ہونے سے پہلے، Felipe نے GE Digital اور Schlumberger کے ساتھ کام کیا، جہاں اس نے صنعتی ایپلی کیشنز کے لیے ماڈلنگ اور اصلاحی مصنوعات پر توجہ دی۔
 ینگ وی یو جنریٹو AI انکیوبیٹر، AWS میں ایک اپلائیڈ سائنٹسٹ ہے۔ اسے مشین لرننگ میں تصور کے مختلف ثبوتوں پر صنعتوں کی متعدد تنظیموں کے ساتھ کام کرنے کا تجربہ ہے، بشمول قدرتی زبان کی پروسیسنگ، ٹائم سیریز کا تجزیہ، اور پیشین گوئی کی دیکھ بھال۔ اپنے فارغ وقت میں، وہ تیراکی، پینٹنگ، پیدل سفر، اور خاندان اور دوستوں کے ساتھ وقت گزارنے سے لطف اندوز ہوتا ہے۔
ینگ وی یو جنریٹو AI انکیوبیٹر، AWS میں ایک اپلائیڈ سائنٹسٹ ہے۔ اسے مشین لرننگ میں تصور کے مختلف ثبوتوں پر صنعتوں کی متعدد تنظیموں کے ساتھ کام کرنے کا تجربہ ہے، بشمول قدرتی زبان کی پروسیسنگ، ٹائم سیریز کا تجزیہ، اور پیشین گوئی کی دیکھ بھال۔ اپنے فارغ وقت میں، وہ تیراکی، پینٹنگ، پیدل سفر، اور خاندان اور دوستوں کے ساتھ وقت گزارنے سے لطف اندوز ہوتا ہے۔
 ہاؤزو وانگ ایمیزون بیڈرک میں ایک تحقیقی سائنسدان ہے جو ایمیزون کے ٹائٹن فاؤنڈیشن ماڈلز کی تعمیر پر توجہ مرکوز کرتا ہے۔ اس سے پہلے اس نے ایمیزون ایم ایل سلوشنز لیب میں ریانفورسمنٹ لرننگ ورٹیکل کے شریک لیڈ کے طور پر کام کیا تھا اور صارفین کو ری انفورسمنٹ لرننگ، نیچرل لینگویج پروسیسنگ، اور گراف لرننگ پر تازہ ترین تحقیق کے ساتھ جدید ترین ایم ایل سلوشنز بنانے میں مدد کی تھی۔ Haozhu نے مشی گن یونیورسٹی سے الیکٹریکل اور کمپیوٹر انجینئرنگ میں پی ایچ ڈی کی ڈگری حاصل کی۔
ہاؤزو وانگ ایمیزون بیڈرک میں ایک تحقیقی سائنسدان ہے جو ایمیزون کے ٹائٹن فاؤنڈیشن ماڈلز کی تعمیر پر توجہ مرکوز کرتا ہے۔ اس سے پہلے اس نے ایمیزون ایم ایل سلوشنز لیب میں ریانفورسمنٹ لرننگ ورٹیکل کے شریک لیڈ کے طور پر کام کیا تھا اور صارفین کو ری انفورسمنٹ لرننگ، نیچرل لینگویج پروسیسنگ، اور گراف لرننگ پر تازہ ترین تحقیق کے ساتھ جدید ترین ایم ایل سلوشنز بنانے میں مدد کی تھی۔ Haozhu نے مشی گن یونیورسٹی سے الیکٹریکل اور کمپیوٹر انجینئرنگ میں پی ایچ ڈی کی ڈگری حاصل کی۔
- SEO سے چلنے والا مواد اور PR کی تقسیم۔ آج ہی بڑھا دیں۔
- پلیٹو ڈیٹا ڈاٹ نیٹ ورک ورٹیکل جنریٹو اے آئی۔ اپنے آپ کو بااختیار بنائیں۔ یہاں تک رسائی حاصل کریں۔
- پلیٹوآئ اسٹریم۔ ویب 3 انٹیلی جنس۔ علم میں اضافہ۔ یہاں تک رسائی حاصل کریں۔
- پلیٹو ای ایس جی۔ آٹوموٹو / ای وی، کاربن، کلین ٹیک، توانائی ، ماحولیات، شمسی، ویسٹ مینجمنٹ یہاں تک رسائی حاصل کریں۔
- پلیٹو ہیلتھ۔ بائیوٹیک اینڈ کلینیکل ٹرائلز انٹیلی جنس۔ یہاں تک رسائی حاصل کریں۔
- چارٹ پرائم۔ ChartPrime کے ساتھ اپنے ٹریڈنگ گیم کو بلند کریں۔ یہاں تک رسائی حاصل کریں۔
- بلاک آفسیٹس۔ ماحولیاتی آفسیٹ ملکیت کو جدید بنانا۔ یہاں تک رسائی حاصل کریں۔
- ماخذ: https://aws.amazon.com/blogs/machine-learning/optimize-equipment-performance-with-historical-data-ray-and-amazon-sagemaker/

