کمپیوٹر ویژن (CV) میں، دلچسپی کی اشیاء کی شناخت کے لیے ٹیگ شامل کرنا یا اشیاء کو تلاش کرنے کے لیے بکس کو باؤنڈنگ کرنا کہلاتا ہے۔ لیبل. گہرے سیکھنے کے ماڈل کو تربیت دینے کے لیے تربیتی ڈیٹا تیار کرنا لازمی کاموں میں سے ایک ہے۔ سی وی کے استعمال کے مختلف کیسز کے لیے تصاویر اور ویڈیوز سے اعلیٰ معیار کے لیبل بنانے میں لاکھوں کام کے گھنٹے صرف کیے جاتے ہیں۔ آپ استعمال کر سکتے ہیں ایمیزون سیج میکر ڈیٹا لیبلنگ یہ لیبل بنانے کے دو طریقوں سے:
- ایمیزون سیج میکر گراؤنڈ ٹروتھ پلس - یہ سروس ایک ماہر افرادی قوت فراہم کرتی ہے جو ML کاموں پر تربیت یافتہ ہے اور آپ کے ڈیٹا کی حفاظت، رازداری اور تعمیل کی ضروریات کو پورا کرنے میں مدد کر سکتی ہے۔ آپ اپنا ڈیٹا اپ لوڈ کرتے ہیں، اور گراؤنڈ ٹروتھ پلس ٹیم آپ کی جانب سے ڈیٹا لیبلنگ ورک فلوز اور افرادی قوت کو تخلیق اور ان کا نظم کرتی ہے۔
- ایمیزون سیج میکر گراؤنڈ ٹروتھ - متبادل طور پر، آپ ڈیٹا لیبل لگانے کے لیے اپنے ڈیٹا لیبلنگ ورک فلوز اور ورک فورس کا انتظام کر سکتے ہیں۔
خاص طور پر، گہری سیکھنے پر مبنی خود مختار گاڑی (AV) اور ایڈوانسڈ ڈرائیور اسسٹنس سسٹمز (ADAS) کے لیے، شروع سے پیچیدہ ملٹی موڈل ڈیٹا کو لیبل کرنے کی ضرورت ہے، بشمول مطابقت پذیر LiDAR، RADAR، اور ملٹی کیمرہ اسٹریمز۔ مثال کے طور پر، درج ذیل اعداد و شمار LiDAR ڈیٹا کے لیے پوائنٹ کلاؤڈ ویو میں کار کے ارد گرد ایک 3D باؤنڈنگ باکس دکھاتا ہے، سائیڈ پر آرتھوگونل LiDAR ویوز، اور باؤنڈنگ باکس کے پروجیکٹ شدہ لیبلز کے ساتھ سات مختلف کیمرہ اسٹریمز دکھاتا ہے۔

AV/ADAS ٹیموں کو شروع سے کئی ہزار فریموں پر لیبل لگانے کی ضرورت ہوتی ہے، اور ایک لیبل لگا ڈیٹا سیٹ حاصل کرنے کے لیے لیبل کنسولیڈیشن، خودکار کیلیبریشن، فریم سلیکشن، فریم سیکوینس انٹرپولیشن، اور فعال سیکھنے جیسی تکنیکوں پر انحصار کرنا ہوتا ہے۔ زمینی سچائی ان خصوصیات کی حمایت کرتی ہے۔ خصوصیات کی مکمل فہرست کے لیے، رجوع کریں۔ ایمیزون سیج میکر ڈیٹا لیبلنگ کی خصوصیات. تاہم، ایسی کمپنیوں کے لیے جو AV/ADAS سسٹم بنانے کے کاروبار میں ہیں، دسیوں ہزار میل ریکارڈ شدہ ویڈیو اور LiDAR ڈیٹا پر لیبل لگانا مشکل، مہنگا اور وقت طلب ہو سکتا ہے۔ آج اس مسئلے کو حل کرنے کے لیے استعمال ہونے والی ایک تکنیک آٹو لیبلنگ ہے، جسے مندرجہ ذیل خاکہ میں اجاگر کیا گیا ہے۔ AWS پر ADAS کے لیے ماڈیولر فنکشنز ڈیزائن.

اس پوسٹ میں، ہم یہ ظاہر کرتے ہیں کہ سیج میکر کی خصوصیات کو کیسے استعمال کیا جائے۔ ایمیزون سیج میکر جمپ اسٹارٹ آٹو لیبلنگ کو انجام دینے کے لیے گراؤنڈ ٹروتھ کی فعالیت کے ساتھ ماڈلز اور متضاد تخمینے کی صلاحیتیں۔
خودکار لیبلنگ کا جائزہ
خودکار لیبلنگ (کبھی کبھی کہا جاتا ہے۔ پری لیبلنگ) دستی لیبلنگ کے کاموں سے پہلے یا اس کے ساتھ ہوتا ہے۔ اس ماڈیول میں، کسی خاص کام کے لیے تربیت یافتہ اب تک کا بہترین ماڈل (مثال کے طور پر پیدل چلنے والوں کا پتہ لگانا یا لین سیگمنٹیشن) کو اعلیٰ معیار کے لیبل بنانے کے لیے استعمال کیا جاتا ہے۔ دستی لیبلرز صرف نتیجے میں ڈیٹا سیٹ سے خودکار طور پر بنائے گئے لیبلز کی تصدیق یا ایڈجسٹ کرتے ہیں۔ یہ ان بڑے ڈیٹاسیٹس کو شروع سے لیبل لگانے سے آسان، تیز اور سستا ہے۔ ڈاؤن اسٹریم ماڈیولز جیسے کہ ٹریننگ یا توثیق کے ماڈیول ان لیبلز کو اسی طرح استعمال کر سکتے ہیں۔
فعال سیکھنے ایک اور تصور ہے جو آٹو لیبلنگ سے گہرا تعلق رکھتا ہے۔ یہ ایک مشین لرننگ (ML) تکنیک ہے جو ڈیٹا کی شناخت کرتی ہے جس پر آپ کے کارکنان کو لیبل لگانا چاہیے۔ گراؤنڈ ٹروتھ کی خودکار ڈیٹا لیبلنگ کی فعالیت فعال سیکھنے کی ایک مثال ہے۔ جب گراؤنڈ ٹروتھ ایک خودکار ڈیٹا لیبلنگ کا کام شروع کرتا ہے، تو یہ ان پٹ ڈیٹا آبجیکٹ کا بے ترتیب نمونہ منتخب کرتا ہے اور انہیں انسانی کارکنوں کو بھیجتا ہے۔ جب لیبل لگا ڈیٹا واپس کر دیا جاتا ہے، تو اس کا استعمال ٹریننگ سیٹ اور ایک توثیق سیٹ بنانے کے لیے ہوتا ہے۔ گراؤنڈ ٹروتھ ان ڈیٹاسیٹس کو آٹو لیبلنگ کے لیے استعمال کیے جانے والے ماڈل کی تربیت اور توثیق کرنے کے لیے استعمال کرتا ہے۔ پھر گراؤنڈ ٹروتھ نئے ڈیٹا کے اعتماد کے اسکور کے ساتھ بغیر لیبل والے ڈیٹا کے لیے لیبل بنانے کے لیے ایک بیچ ٹرانسفارم جاب چلاتا ہے۔ کم اعتماد کے اسکور کے ساتھ لیبل لگا ڈیٹا انسانی لیبلرز کو بھیجا جاتا ہے۔ تربیت، توثیق، اور بیچ کی تبدیلی کا یہ عمل اس وقت تک دہرایا جاتا ہے جب تک کہ مکمل ڈیٹا سیٹ پر لیبل نہ لگ جائے۔
اس کے برعکس، آٹو لیبلنگ یہ فرض کرتی ہے کہ ایک اعلیٰ معیار کا، پہلے سے تربیت یافتہ ماڈل موجود ہے (یا تو کمپنی کے اندر نجی طور پر، یا عوامی طور پر کسی مرکز میں)۔ اس ماڈل کا استعمال ایسے لیبلز بنانے کے لیے کیا جاتا ہے جن پر بھروسہ کیا جا سکتا ہے اور نیچے دھارے کے کاموں جیسے کہ لیبل کی توثیق کے کام، تربیت، یا نقلی کاموں کے لیے استعمال کیا جاتا ہے۔ AV/ADAS سسٹمز کے معاملے میں یہ پہلے سے تربیت یافتہ ماڈل کار پر کنارے پر لگایا جاتا ہے، اور اسے اعلیٰ معیار کے لیبل بنانے کے لیے کلاؤڈ پر بڑے پیمانے پر، بیچ انفرنس جابز میں استعمال کیا جا سکتا ہے۔
JumpStart آپ کو مشین لرننگ کے ساتھ شروع کرنے میں مدد کرنے کے لیے پہلے سے تربیت یافتہ، اوپن سورس ماڈل فراہم کرتا ہے۔ آپ جمپ سٹارٹ کو اپنی تنظیم میں ماڈلز کا اشتراک کرنے کے لیے استعمال کر سکتے ہیں۔ آو شروع کریں!
حل جائزہ
اس پوسٹ کے لیے، ہم اپنی مثال کے نوٹ بک میں ہر سیل پر جانے کے بغیر اہم اقدامات کا خاکہ پیش کرتے ہیں۔ اس کی پیروی کرنے یا اسے خود آزمانے کے لیے، آپ چلا سکتے ہیں۔ Jupyter نوٹ بک in ایمیزون سیج میکر اسٹوڈیو.
درج ذیل خاکہ حل کا جائزہ فراہم کرتا ہے۔
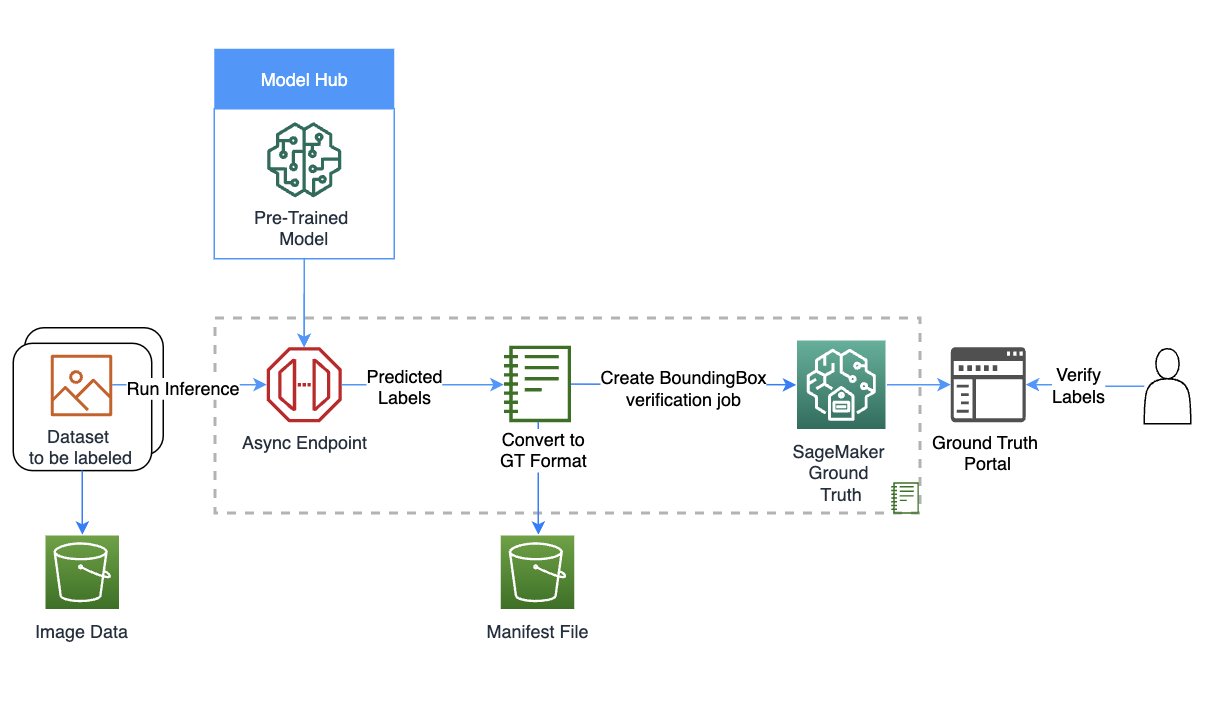
کردار اور سیشن مرتب کریں۔
اس مثال کے لیے، ہم نے سٹوڈیو میں ml.m3.0.large مثال کی قسم پر ڈیٹا سائنس 5 کرنل استعمال کیا۔ سب سے پہلے، ہم کچھ بنیادی درآمدات کرتے ہیں اور بعد میں نوٹ بک میں استعمال کے لیے کردار اور سیشن ترتیب دیتے ہیں:
SageMaker کا استعمال کرتے ہوئے اپنا ماڈل بنائیں
اس مرحلے میں، ہم آٹو لیبلنگ کے کام کے لیے ایک ماڈل بناتے ہیں۔ آپ ماڈل بنانے کے لیے تین اختیارات میں سے انتخاب کر سکتے ہیں:
- JumpStart سے ایک ماڈل بنائیں - جمپ سٹارٹ کے ساتھ، ہم پہلے سے تربیت یافتہ ماڈل کا اندازہ لگا سکتے ہیں، یہاں تک کہ اسے نئے ڈیٹاسیٹ پر پہلے ٹھیک ٹیوننگ کیے بغیر۔
- اپنی ٹیم یا تنظیم کے ساتھ JumpStart کے ذریعے اشتراک کردہ ماڈل کا استعمال کریں۔ - اگر آپ اپنی تنظیم کے اندر کسی ایک ٹیم کے تیار کردہ ماڈل کو استعمال کرنا چاہتے ہیں تو آپ یہ اختیار استعمال کر سکتے ہیں۔
- ایک موجودہ اختتامی نقطہ استعمال کریں۔ - اگر آپ کے اکاؤنٹ میں پہلے سے موجود ماڈل موجود ہے تو آپ یہ اختیار استعمال کر سکتے ہیں۔
پہلا آپشن استعمال کرنے کے لیے، ہم جمپ اسٹارٹ سے ایک ماڈل منتخب کرتے ہیں (یہاں، ہم استعمال کرتے ہیں۔ mxnet-is-mask-rcnn-fpn-resnet101-v1d-coco. ماڈلز کی فہرست میں دستیاب ہے۔ models_manifest.json JumpStart کی طرف سے فراہم کردہ فائل۔
ہم اس جمپ اسٹارٹ ماڈل کا استعمال کرتے ہیں جو عوامی طور پر دستیاب ہے اور مثال کے طور پر سیگمنٹیشن ٹاسک پر تربیت یافتہ ہے، لیکن آپ نجی ماڈل کو بھی استعمال کرنے کے لیے آزاد ہیں۔ درج ذیل کوڈ میں، ہم استعمال کرتے ہیں۔ image_uris, model_uris، اور script_uris میں اس MXNet ماڈل کو استعمال کرنے کے لیے صحیح پیرامیٹر کی اقدار کو بازیافت کرنے کے لیے sagemaker.model.Model ماڈل بنانے کے لیے API:
غیر مطابقت پذیر تخمینہ اور پیمانہ ترتیب دیں۔
یہاں ہم ماڈل کو تعینات کرنے سے پہلے ایک غیر مطابقت پذیر انفرنس کنفیگریشن ترتیب دیتے ہیں۔ ہم نے غیر مطابقت پذیر تخمینہ کا انتخاب کیا کیونکہ یہ بڑے پے لوڈ سائز کو سنبھال سکتا ہے اور قریب قریب حقیقی وقت میں تاخیر کی ضروریات کو پورا کر سکتا ہے۔ اس کے علاوہ، آپ اینڈ پوائنٹ کو آٹو اسکیل پر کنفیگر کر سکتے ہیں اور اسکیلنگ کی پالیسی لاگو کر سکتے ہیں تاکہ مثال کی گنتی کو صفر پر سیٹ کیا جا سکے جب کارروائی کی کوئی درخواست نہ ہو۔ درج ذیل کوڈ میں، ہم سیٹ کرتے ہیں۔ max_concurrent_invocations_per_instance ہم آٹو اسکیلنگ بھی ترتیب دیتے ہیں کہ ضرورت پڑنے پر اینڈ پوائنٹ اسکیل ہوجاتا ہے اور آٹو لیبلنگ کا کام مکمل ہونے کے بعد صفر تک اسکیل ہوجاتا ہے۔
ڈیٹا ڈاؤن لوڈ کریں اور اندازہ لگائیں۔
ہم استعمال کرتے ہیں فورڈ ملٹی اے وی سیزنل ڈیٹاسیٹ AWS اوپن ڈیٹا کیٹلاگ سے۔
سب سے پہلے، ہم قیاس کے لیے تاریخ ڈاؤن لوڈ اور تیار کرتے ہیں۔ ہم نے نوٹ بک میں ڈیٹاسیٹ کو پروسیس کرنے کے لیے پری پروسیسنگ کے اقدامات فراہم کیے ہیں۔ آپ اسے اپنے ڈیٹا سیٹ پر کارروائی کرنے کے لیے تبدیل کر سکتے ہیں۔ اس کے بعد، SageMaker API کا استعمال کرتے ہوئے، ہم مندرجہ ذیل طور پر غیر مطابقت پذیر انفرنس کا کام شروع کر سکتے ہیں:
اس میں 30 منٹ یا اس سے زیادہ وقت لگ سکتا ہے اس پر منحصر ہے کہ آپ نے غیر مطابقت پذیر تخمینہ کے لیے کتنا ڈیٹا اپ لوڈ کیا ہے۔ آپ ان قیاس آرائیوں میں سے ایک کو حسب ذیل تصور کر سکتے ہیں:

غیر مطابقت پذیر انفرنس آؤٹ پٹ کو گراؤنڈ ٹروتھ ان پٹ مینی فیسٹ میں تبدیل کریں۔
اس مرحلے میں، ہم زمینی سچائی پر باؤنڈنگ باکس کی تصدیق کے کام کے لیے ایک ان پٹ مینی فیسٹ بناتے ہیں۔ ہم گراؤنڈ ٹروتھ UI ٹیمپلیٹ اور لیبل زمرہ جات فائل کو اپ لوڈ کرتے ہیں، اور تصدیق کا کام بناتے ہیں۔ اس پوسٹ سے منسلک نوٹ بک لیبلنگ کو انجام دینے کے لیے نجی افرادی قوت کا استعمال کرتی ہے۔ اگر آپ دوسری قسم کے افرادی قوت استعمال کر رہے ہیں تو آپ اسے تبدیل کر سکتے ہیں۔ مزید تفصیلات کے لیے، نوٹ بک میں مکمل کوڈ دیکھیں۔
گراؤنڈ ٹروتھ میں آٹو لیبلنگ کے عمل سے لیبلز کی تصدیق کریں۔
اس مرحلے میں، ہم لیبلنگ پورٹل تک رسائی حاصل کرکے تصدیق مکمل کرتے ہیں۔ مزید تفصیلات کے لیے رجوع کریں۔ یہاں.
جب آپ ورک فورس ممبر کے طور پر پورٹل تک رسائی حاصل کرتے ہیں، تو آپ جمپ سٹارٹ ماڈل کے ذریعے بنائے گئے باؤنڈنگ باکسز کو دیکھ سکیں گے اور ضرورت کے مطابق ایڈجسٹمنٹ کر سکیں گے۔

آپ اس ٹیمپلیٹ کو بہت سے ٹاسک مخصوص ماڈلز کے ساتھ آٹو لیبلنگ کو دہرانے، ممکنہ طور پر لیبلز کو ضم کرنے، اور نتیجے میں لیبل والے ڈیٹاسیٹ کو بہاوی کاموں میں استعمال کرنے کے لیے استعمال کر سکتے ہیں۔
صاف کرو
اس مرحلے میں، ہم اختتامی نقطہ اور پچھلے مراحل میں بنائے گئے ماڈل کو حذف کر کے صاف کرتے ہیں:
نتیجہ
اس پوسٹ میں، ہم نے جمپ اسٹارٹ اور غیر مطابقت پذیر تخمینہ پر مشتمل آٹو لیبلنگ کے عمل سے گزرا۔ ہم نے خودکار لیبلنگ کے عمل کے نتائج کو حقیقی دنیا کے ڈیٹاسیٹ پر لیبل والے ڈیٹا کو تبدیل کرنے اور دیکھنے کے لیے استعمال کیا۔ آپ بہت سے ٹاسک مخصوص ماڈلز کے ساتھ آٹو لیبلنگ کرنے کے لیے حل استعمال کر سکتے ہیں، ممکنہ طور پر لیبلز کو ضم کر سکتے ہیں، اور نتیجے میں لیبل والے ڈیٹاسیٹ کو ڈاؤن اسٹریم ٹاسک میں استعمال کر سکتے ہیں۔ آپ جیسے ٹولز کا استعمال کرکے بھی دریافت کرسکتے ہیں۔ کسی بھی چیز کے ماڈل کو سیگمنٹ کریں۔ آٹو لیبلنگ کے عمل کے حصے کے طور پر سیگمنٹ ماسک تیار کرنے کے لیے۔ اس سلسلے کی آئندہ پوسٹس میں، ہم پرسیپشن ماڈیول اور سیگمنٹیشن کا احاطہ کریں گے۔ جمپ سٹارٹ اور غیر مطابقت پذیر تخمینہ کے بارے میں مزید معلومات کے لیے، رجوع کریں۔ سیج میکر جمپ اسٹارٹ اور غیر مطابقت پذیر تخمینہبالترتیب ہم آپ کی حوصلہ افزائی کرتے ہیں کہ AV/ADAS سے آگے کے استعمال کے معاملات کے لیے اس مواد کو دوبارہ استعمال کریں، اور کسی بھی مدد کے لیے AWS سے رابطہ کریں۔
مصنفین کے بارے میں
 گوپی کرشنامورتی۔ نیویارک شہر میں واقع Amazon ویب سروسز میں ایک سینئر AI/ML سلوشنز آرکیٹیکٹ ہیں۔ وہ بڑے آٹوموٹیو صارفین کے ساتھ ان کے مشین لرننگ کے کام کے بوجھ کو تبدیل کرنے اور کلاؤڈ پر منتقل کرنے کے لیے ان کے قابل اعتماد مشیر کے طور پر کام کرتا ہے۔ اس کی بنیادی دلچسپیوں میں گہری سیکھنے اور سرور کے بغیر ٹیکنالوجیز شامل ہیں۔ کام سے باہر، وہ اپنے خاندان کے ساتھ وقت گزارنا اور موسیقی کی وسیع رینج کو تلاش کرنا پسند کرتا ہے۔
گوپی کرشنامورتی۔ نیویارک شہر میں واقع Amazon ویب سروسز میں ایک سینئر AI/ML سلوشنز آرکیٹیکٹ ہیں۔ وہ بڑے آٹوموٹیو صارفین کے ساتھ ان کے مشین لرننگ کے کام کے بوجھ کو تبدیل کرنے اور کلاؤڈ پر منتقل کرنے کے لیے ان کے قابل اعتماد مشیر کے طور پر کام کرتا ہے۔ اس کی بنیادی دلچسپیوں میں گہری سیکھنے اور سرور کے بغیر ٹیکنالوجیز شامل ہیں۔ کام سے باہر، وہ اپنے خاندان کے ساتھ وقت گزارنا اور موسیقی کی وسیع رینج کو تلاش کرنا پسند کرتا ہے۔
 شریاس سبرامنیم ایک پرنسپل AI/ML ماہر سولیوشن آرکیٹیکٹ ہے، اور AWS پلیٹ فارم کا استعمال کرتے ہوئے اپنے کاروباری چیلنجوں کو حل کرنے کے لیے مشین لرننگ کا استعمال کر کے صارفین کی مدد کرتا ہے۔ شریاس کا پس منظر بڑے پیمانے پر آپٹیمائزیشن اور مشین لرننگ، اور مشین لرننگ اور ری انفورسمنٹ لرننگ کے استعمال میں ہے تاکہ آپٹیمائزیشن کے کاموں کو تیز کیا جا سکے۔
شریاس سبرامنیم ایک پرنسپل AI/ML ماہر سولیوشن آرکیٹیکٹ ہے، اور AWS پلیٹ فارم کا استعمال کرتے ہوئے اپنے کاروباری چیلنجوں کو حل کرنے کے لیے مشین لرننگ کا استعمال کر کے صارفین کی مدد کرتا ہے۔ شریاس کا پس منظر بڑے پیمانے پر آپٹیمائزیشن اور مشین لرننگ، اور مشین لرننگ اور ری انفورسمنٹ لرننگ کے استعمال میں ہے تاکہ آپٹیمائزیشن کے کاموں کو تیز کیا جا سکے۔
- SEO سے چلنے والا مواد اور PR کی تقسیم۔ آج ہی بڑھا دیں۔
- پلیٹو ڈیٹا ڈاٹ نیٹ ورک ورٹیکل جنریٹو اے آئی۔ اپنے آپ کو بااختیار بنائیں۔ یہاں تک رسائی حاصل کریں۔
- پلیٹوآئ اسٹریم۔ ویب 3 انٹیلی جنس۔ علم میں اضافہ۔ یہاں تک رسائی حاصل کریں۔
- پلیٹو ای ایس جی۔ آٹوموٹو / ای وی، کاربن، کلین ٹیک، توانائی ، ماحولیات، شمسی، ویسٹ مینجمنٹ یہاں تک رسائی حاصل کریں۔
- بلاک آفسیٹس۔ ماحولیاتی آفسیٹ ملکیت کو جدید بنانا۔ یہاں تک رسائی حاصل کریں۔
- ماخذ: https://aws.amazon.com/blogs/machine-learning/auto-labeling-module-for-deep-learning-based-advanced-driver-assistance-systems-on-aws/

