۔ IMDb اور Box Office Mojo Movies/TV/OTT لائسنس یافتہ ڈیٹا پیکیج تفریحی میٹا ڈیٹا کی ایک وسیع رینج فراہم کرتا ہے، بشمول 1 بلین سے زیادہ صارف کی درجہ بندی؛ 11 ملین سے زیادہ کاسٹ اور عملے کے ارکان کے لیے کریڈٹ؛ 9 ملین فلم، ٹی وی، اور تفریحی عنوانات؛ اور 60 سے زیادہ ممالک سے عالمی باکس آفس رپورٹنگ ڈیٹا۔ بہت سے AWS میڈیا اور تفریحی صارفین IMDb ڈیٹا کے ذریعے لائسنس دیتے ہیں۔ AWS ڈیٹا ایکسچینج مواد کی دریافت کو بہتر بنانے اور گاہک کی مصروفیت اور برقرار رکھنے میں اضافہ کرنے کے لیے۔
اس تین حصوں کی سیریز میں، ہم یہ ظاہر کرتے ہیں کہ آپ کے میڈیا اور تفریحی استعمال کے معاملات کے لیے کیٹلاگ سے باہر تلاش کرنے کے لیے IMDb ڈیٹا کو کیسے تبدیل اور تیار کیا جائے۔ اس پوسٹ میں، ہم IMDb ڈیٹا کو تیار کرنے اور ڈیٹا کو لوڈ کرنے کے طریقہ پر تبادلہ خیال کرتے ہیں۔ ایمیزون نیپچون استفسار کے لیے میں حصہ 2، ہم استعمال کرنے کے طریقہ پر تبادلہ خیال کرتے ہیں۔ ایمیزون نیپچون ایم ایل IMDb گراف سے گراف نیورل نیٹ ورک (GNN) ایمبیڈنگز کو تربیت دینے کے لیے۔ حصہ 3 میں، ہم ایک ڈیمو ایپلیکیشن سے باہر کیٹلاگ تلاش کرتے ہیں جو GNN ایمبیڈنگز کے ذریعے تقویت یافتہ ہے۔
حل جائزہ
اس سلسلے میں، ہم استعمال کرتے ہیں IMDb اور Box Office Mojo Movies/TV/OTT لائسنس یافتہ ڈیٹا پیکج یہ دکھانے کے لیے کہ آپ گرافس کا استعمال کرتے ہوئے اپنی ایپلیکیشنز کیسے بنا سکتے ہیں۔
یہ لائسنس یافتہ ڈیٹا پیکج JSON فائلوں پر مشتمل ہے جس میں IMDb میٹا ڈیٹا کے ساتھ 9 ملین سے زیادہ عنوانات (بشمول فلمیں، TV اور OTT شوز، اور ویڈیو گیمز) اور 11 ملین سے زیادہ کاسٹ، عملہ، اور تفریحی پیشہ ور افراد کے لیے کریڈٹ شامل ہیں۔ IMDb کے میٹا ڈیٹا پیکج میں 1 بلین سے زیادہ صارف کی درجہ بندی کے ساتھ ساتھ پلاٹ، انواع، زمرہ بند مطلوبہ الفاظ، پوسٹرز، کریڈٹس اور زیادہ.
IMDb AWS ڈیٹا ایکسچینج کے ذریعے ڈیٹا فراہم کرتا ہے، جو آپ کے لیے اپنے تفریحی تجربات کو تقویت دینے اور دیگر AWS سروسز کے ساتھ بغیر کسی رکاوٹ کے مربوط ہونے کے لیے ڈیٹا تک رسائی کو ناقابل یقین حد تک آسان بنا دیتا ہے۔ IMDb میڈیا اور تفریحی صارفین کی ایک وسیع رینج کو ڈیٹا لائسنس دیتا ہے، بشمول پے ٹی وی، ڈائریکٹ ٹو کنزیومر، اور اسٹریمنگ آپریٹرز، مواد کی دریافت کو بہتر بنانے اور کسٹمر کی مصروفیت اور برقرار رکھنے میں اضافہ کرنے کے لیے۔ لائسنس دینے والے صارفین ان کیٹلاگ اور آؤٹ آف کیٹلاگ ٹائٹل سرچ اور پاور متعلقہ سفارشات کو بڑھانے کے لیے بھی IMDb ڈیٹا استعمال کرتے ہیں۔
ہم اس حل کے حصے کے طور پر درج ذیل خدمات استعمال کرتے ہیں:
مندرجہ ذیل خاکہ 1 حصوں کی بلاگ سیریز کے حصہ 3 کے لیے ورک فلو کو ظاہر کرتا ہے۔

اس پوسٹ میں، ہم درج ذیل اعلیٰ سطحی مراحل سے گزرتے ہیں:
- نیپچون کے وسائل کی فراہمی AWS کلاؤڈ فارمیشن.
- AWS ڈیٹا ایکسچینج سے IMDb ڈیٹا تک رسائی حاصل کریں۔
- کلون GitHub repo.
- نیپچون گریملن فارمیٹ میں ڈیٹا پر کارروائی کریں۔
- ڈیٹا کو نیپچون کلسٹر میں لوڈ کریں۔
- Gremlin Query Language کا استعمال کرتے ہوئے ڈیٹا سے استفسار کریں۔
شرائط
اس پوسٹ میں استعمال ہونے والے IMDb ڈیٹا کے لیے AWS ڈیٹا ایکسچینج میں IMDb اور Box Office Mojo Movies/TV/OTT لائسنسنگ پیکج کے لیے IMDb مواد کا لائسنس اور ادا شدہ سبسکرپشن درکار ہے۔ لائسنس کے بارے میں پوچھ گچھ کرنے اور نمونے کے ڈیٹا تک رسائی کے لیے، ملاحظہ کریں۔ developer.imdb.com.
مزید برآں، اس پوسٹ کے ساتھ پیروی کرنے کے لیے، آپ کے پاس ایک ہونا چاہیے۔ AWS اکاؤنٹ اور نیپچون، گریملن استفسار کی زبان، اور سیج میکر سے واقفیت۔
AWS CloudFormation کے ساتھ نیپچون کے وسائل کی فراہمی
اب جب کہ آپ نے حل کی ساخت دیکھ لی ہے، آپ اسے مثالی ورک فلو چلانے کے لیے اپنے اکاؤنٹ میں تعینات کر سکتے ہیں۔
آپ اسٹیک کو AWS ریجن میں لانچ کر سکتے ہیں۔ us-east-1 منتخب کرکے AWS CloudFormation کنسول پر اسٹیک لانچ کریں۔:
![]()
اسٹیک کو کسی مختلف علاقے میں شروع کرنے کے لیے، رجوع کریں۔ ایک نئے DB کلسٹر میں تیزی سے شروع کرنے کے لیے Neptune ML AWS CloudFormation ٹیمپلیٹ کا استعمال.
درج ذیل اسکرین شاٹ فراہم کرنے کے لیے اسٹیک پیرامیٹرز دکھاتا ہے۔
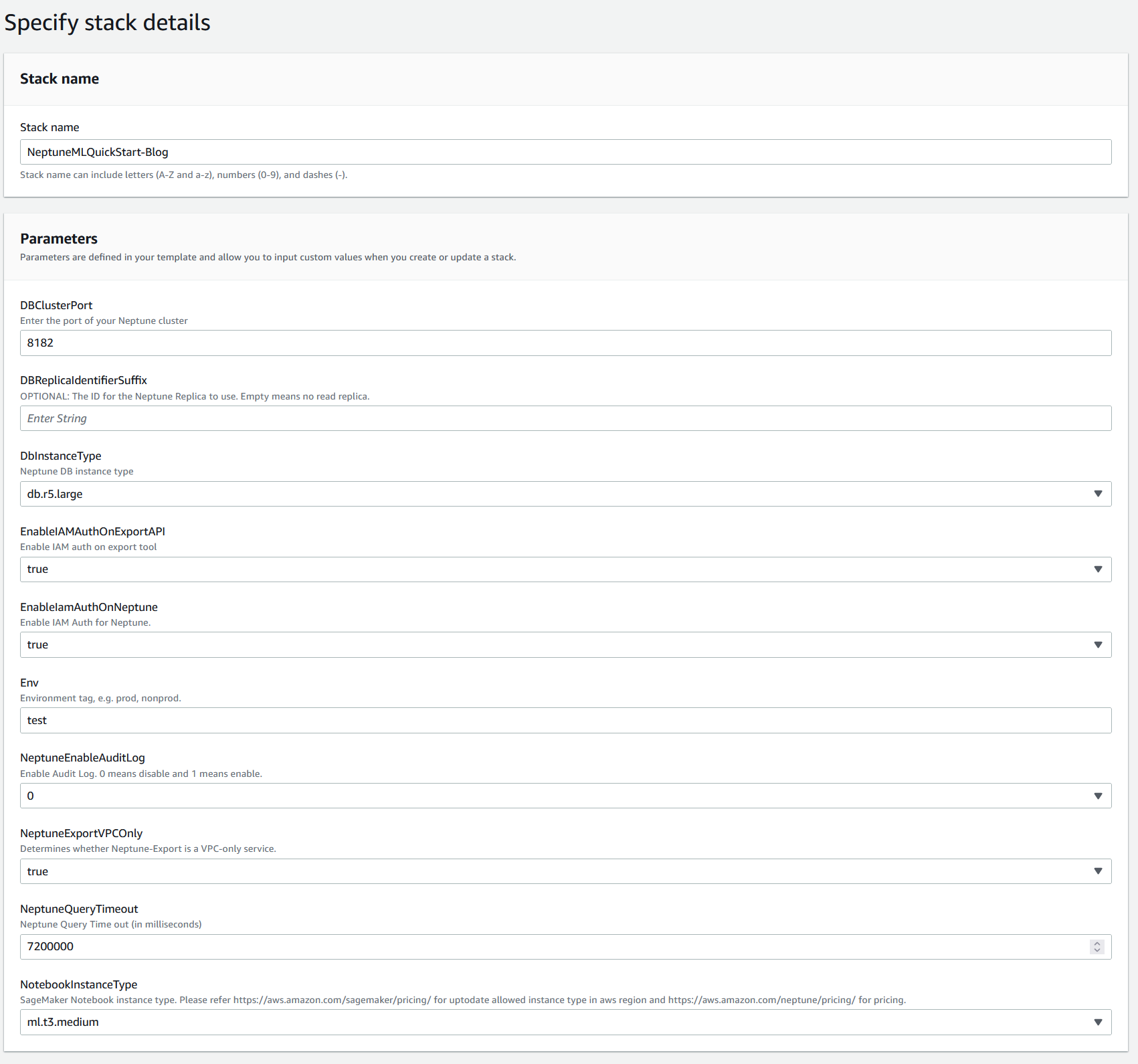
اسٹیک بنانے میں تقریباً 20 منٹ لگتے ہیں۔ آپ AWS CloudFormation کنسول پر پیشرفت کی نگرانی کر سکتے ہیں۔
جب اسٹیک مکمل ہو جائے گا، اب آپ IMDb ڈیٹا پر کارروائی کرنے کے لیے تیار ہیں۔ پر نتائج اسٹیک کے لیے ٹیب، کے لیے اقدار نوٹ کریں۔ NeptuneExportApiUri اور NeptuneLoadFromS3IAMRoleArn. پھر IMDb ڈیٹاسیٹ تک رسائی حاصل کرنے کے لیے درج ذیل مراحل پر جائیں۔
IMDb ڈیٹا تک رسائی حاصل کریں۔
IMDb اپنا ڈیٹا سیٹ دن میں ایک بار AWS ڈیٹا ایکسچینج پر شائع کرتا ہے۔ IMDb ڈیٹا استعمال کرنے کے لیے، آپ پہلے AWS ڈیٹا ایکسچینج میں ڈیٹا کو سبسکرائب کریں، پھر آپ ڈیٹا کو ایکسپورٹ کر سکتے ہیں۔ ایمیزون سادہ اسٹوریج سروس (ایمیزون S3)۔ درج ذیل مراحل کو مکمل کریں:
- AWS ڈیٹا ایکسچینج کنسول پر، منتخب کریں۔ کیٹلاگ کو براؤز کریں۔ نیوی گیشن پین میں.
- تلاش کے میدان میں، درج کریں۔
IMDb. - دونوں میں سے سبسکرائب کریں۔ IMDb اور Box Office Mojo Movie/TV/OTT ڈیٹا (نمونہ) or IMDb اور Box Office Mojo Movie/TV/OTT ڈیٹا.
- درج ذیل مراحل کو مکمل کریں۔ ورکشاپ AWS ڈیٹا ایکسچینج سے Amazon S3 میں IMDb ڈیٹا ایکسپورٹ کرنے کے لیے۔
GitHub ذخیرہ کو کلون کریں۔
درج ذیل مراحل کو مکمل کریں:
- سیج میکر مثال کھولیں جسے آپ نے کلاؤڈ فارمیشن ٹیمپلیٹ سے بنایا ہے۔
- GitHub ذخیرہ کو کلون کریں۔
آئی ایم ڈی بی ڈیٹا کو نیپچون گریملن فارمیٹ میں پروسیس کریں۔
ایمیزون نیپچون میں ڈیٹا شامل کرنے کے لیے، ہم ڈیٹا کو نیپچون گریملن فارمیٹ میں پروسیس کرتے ہیں۔ GitHub ذخیرہ سے، ہم چلاتے ہیں۔ process_imdb_data.py فائلوں پر کارروائی کرنے کے لیے۔ اسکرپٹ ڈیٹا کو نیپچون میں لوڈ کرنے کے لیے CSVs بناتی ہے۔ ڈیٹا کو S3 بالٹی میں اپ لوڈ کریں اور S3 URI مقام کو نوٹ کریں۔
نوٹ کریں کہ اس پوسٹ کے لیے، ہم صرف فلمیں شامل کرنے کے لیے ڈیٹا سیٹ کو فلٹر کرتے ہیں۔ آپ کو یا تو ایک کی ضرورت ہے۔ AWS گلو نوکری یا ایمیزون ای ایم آر مکمل ڈیٹا پر کارروائی کرنے کے لیے۔
AWS Glue کا استعمال کرتے ہوئے IMDb ڈیٹا پر کارروائی کرنے کے لیے، درج ذیل مراحل کو مکمل کریں:
- AWS Glue کنسول پر، نیویگیشن پین میں، منتخب کریں۔ نوکریاں.
- پر نوکریاں صفحہ، منتخب کریں اسپارک اسکرپٹ ایڈیٹر.
- کے تحت آپشنز کے بھیمنتخب کریں موجودہ اسکرپٹ کو اپ لوڈ اور ترمیم کریں۔ اور اپ لوڈ کریں
1_process_imdb_data.pyفائل. - میں سے انتخاب کریں بنانا.
- ایڈیٹر صفحہ پر، منتخب کریں۔ کام کی تفصیلات.
- پر کام کی تفصیلات صفحہ، درج ذیل اختیارات شامل کریں:
- کے لئے نام، داخل کریں
imdb-graph-processor. - کے لئے Description، داخل کریں
processing IMDb dataset and convert to Neptune Gremlin Format. - کے لئے IAM کا کردار، موجودہ AWS گلو رول استعمال کریں یا AWS Glue کے لیے IAM رول بنائیں. یقینی بنائیں کہ آپ خام ڈیٹا اور آؤٹ پٹ ڈیٹا پاتھ کے لیے اپنے Amazon S3 مقام کو اجازت دیتے ہیں۔
- کے لئے ورکر کی قسممنتخب کریں جی 2 ایکس۔.
- کے لئے کارکنوں کی تعداد طلب کی۔، 20 درج کریں۔
- کے لئے نام، داخل کریں
- توسیع اعلی درجے کی خصوصیات.
- کے تحت ملازمت کے پیرامیٹرزمنتخب کریں نیا پیرامیٹر شامل کریں۔ اور درج ذیل کلیدی قدر کا جوڑا درج کریں:
- کلید کے لیے، درج کریں۔
--output_bucket_path. - قدر کے لیے، S3 کا راستہ داخل کریں جہاں آپ فائلوں کو محفوظ کرنا چاہتے ہیں۔ یہ راستہ ڈیٹا کو نیپچون کلسٹر میں لوڈ کرنے کے لیے بھی استعمال ہوتا ہے۔
- کلید کے لیے، درج کریں۔
- دوسرا پیرامیٹر شامل کرنے کے لیے، منتخب کریں۔ نیا پیرامیٹر شامل کریں۔ اور درج ذیل کلیدی قدر کا جوڑا درج کریں:
- کلید کے لیے، درج کریں۔
--raw_data_path. - قدر کے لیے، S3 کا راستہ داخل کریں جہاں خام ڈیٹا محفوظ ہے۔
- کلید کے لیے، درج کریں۔
- میں سے انتخاب کریں محفوظ کریں اور پھر منتخب کریں رن.
اس کام کو مکمل ہونے میں تقریباً 2.5 گھنٹے لگتے ہیں۔
درج ذیل جدول گراف ڈیٹا ماڈل کے لیے نوڈس کے بارے میں تفصیلات فراہم کرتا ہے۔
| Description | لیبل |
| پرنسپل کاسٹ ممبران | شخص |
| لمبی شکل والی فلم | مووی |
| فلموں کی صنف | قسم |
| فلموں کی کلیدی الفاظ کی تفصیل | مطلوبہ الفاظ کی |
| فلموں کی شوٹنگ کے مقامات | مقام |
| فلموں کی درجہ بندی۔ | درجہ بندی |
| ایوارڈ ایونٹ جہاں فلم کو ایوارڈ ملا | ایوارڈ |
اسی طرح، درج ذیل جدول گراف میں شامل کچھ کناروں کو دکھاتا ہے۔ کل 24 ایج قسمیں ہوں گی۔
| Description | لیبل | سے | کرنے کے لئے |
| وہ فلمیں جن میں ایک اداکارہ نے کام کیا ہے۔ | کاسٹ کی طرف سے اداکارہ | مووی | شخص |
| وہ فلمیں جن میں ایک اداکار نے کام کیا ہے۔ | کاسٹ بہ اداکار | مووی | شخص |
| کردار کے لحاظ سے فلم میں مطلوبہ الفاظ | بیان کردہ بذریعہ حرف کلیدی لفظ | مووی | مطلوبہ الفاظ |
| فلم کی صنف | is-genre | مووی | قسم |
| وہ جگہ جہاں فلم کی شوٹنگ ہوئی تھی۔ | پر فلمایا | مووی | مقام |
| ایک فلم کا کمپوزر | کمپوزر کے ذریعے تیار کردہ | مووی | شخص |
| ایوارڈ نامزدگی | نامزد_کے لیے | مووی | ایوارڈ |
| ایوارڈ فاتح | جیت گیا ہے | مووی | ایوارڈ |
ڈیٹا کو نیپچون کلسٹر میں لوڈ کریں۔
ریپو میں، پر تشریف لے جائیں۔ graph_creation فولڈر اور چلائیں 2_load.ipynb. ڈیٹا کو نیپچون میں لوڈ کرنے کے لیے، نوٹ بک میں %load کمانڈ استعمال کریں، اور فراہم کریں۔ AWS شناخت اور رسائی کا انتظام (IAM) آپ کے پروسیس شدہ ڈیٹا کا ARN اور Amazon S3 مقام۔
درج ذیل اسکرین شاٹ کمانڈ کی آؤٹ پٹ کو ظاہر کرتا ہے۔

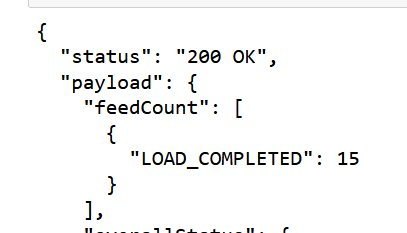
نوٹ کریں کہ ڈیٹا لوڈ مکمل ہونے میں تقریباً 1.5 گھنٹے لگتے ہیں۔ لوڈ کی حیثیت کو چیک کرنے کے لئے، درج ذیل کمانڈ کا استعمال کریں:
جب لوڈ مکمل ہو جاتا ہے، اسٹیٹس ظاہر ہوتا ہے۔ LOAD_COMPLETED، جیسا کہ مندرجہ ذیل اسکرین شاٹ میں دکھایا گیا ہے۔
تمام ڈیٹا اب گراف میں بھرا ہوا ہے، اور آپ گراف سے استفسار کرنا شروع کر سکتے ہیں۔
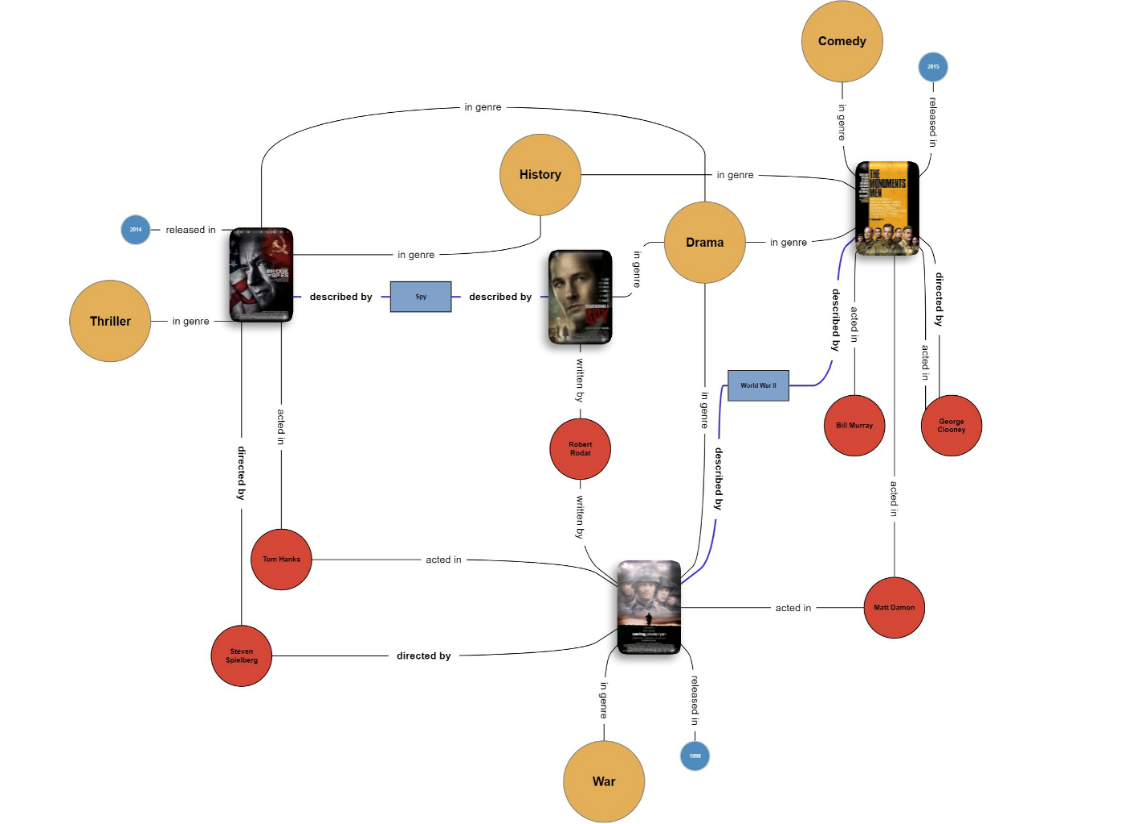
تصویر: آئی ایم ڈی بی ڈیٹاسیٹ میں فلموں کا نمونہ علمی گراف۔ فلمیں "سیونگ پرائیویٹ ریان" اور "برج آف سپائز" میں اداکار اور ہدایت کار کی طرح مشترکہ رابطے ہیں اور گراف نیٹ ورک میں "دی کیچر ایک جاسوس" جیسی فلموں کے ذریعے بالواسطہ رابطے ہیں۔
Gremlin کا استعمال کرتے ہوئے ڈیٹا سے استفسار کریں۔
نیپچون میں گراف تک رسائی کے لیے، ہم Gremlin استفسار کی زبان استعمال کرتے ہیں۔ مزید معلومات کے لیے رجوع کریں۔ نیپچون گراف سے استفسار کرنا.
گراف معلومات کے ایک بھرپور سیٹ پر مشتمل ہے جس سے براہ راست Gremlin کا استعمال کرتے ہوئے استفسار کیا جا سکتا ہے۔ اس سیکشن میں، ہم سوالات کی چند مثالیں دکھاتے ہیں جن کا جواب آپ گراف ڈیٹا کے ساتھ دے سکتے ہیں۔ ریپو میں، پر تشریف لے جائیں۔ graph_creation فولڈر اور چلائیں 3_queries.ipynb کاپی. مندرجہ ذیل سیکشن نوٹ بک سے تمام سوالات پر جاتا ہے۔
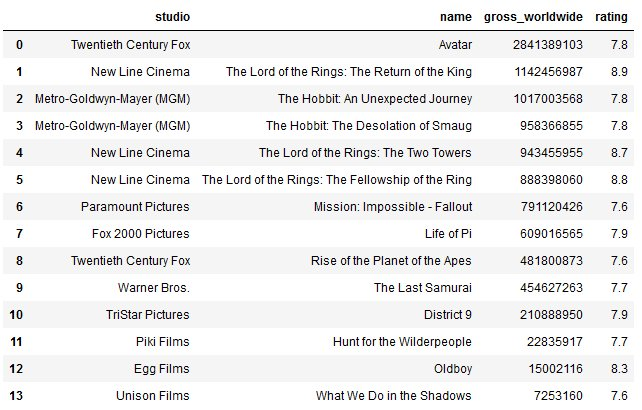
کم از کم 7.5 ریٹنگ کے ساتھ نیوزی لینڈ میں شوٹ کی گئی فلموں کی دنیا بھر میں مجموعی
مندرجہ ذیل استفسار نیوزی لینڈ میں فلمائی گئی دنیا بھر میں فلموں کی مجموعی رقم واپس کرتا ہے، جس کی کم از کم درجہ بندی 7.5 ہے:
درج ذیل اسکرین شاٹ استفسار کے نتائج کو ظاہر کرتا ہے۔
سرفہرست 50 فلمیں جو ایکشن اور ڈرامہ کی صنفوں سے تعلق رکھتی ہیں اور جن میں آسکر ایوارڈ یافتہ اداکار ہیں۔
درج ذیل مثال میں، ہم آسکر ایوارڈ یافتہ اداکاروں کے ساتھ دو مختلف انواع (ایکشن اور ڈرامہ) میں سرفہرست 50 فلمیں تلاش کرنا چاہتے ہیں۔ ہم تین مختلف سوالات کا استعمال کرتے ہوئے اور پانڈوں کا استعمال کرتے ہوئے معلومات کو ملا کر ایسا کر سکتے ہیں:
درج ذیل اسکرین شاٹ ہمارے نتائج کو ظاہر کرتا ہے۔

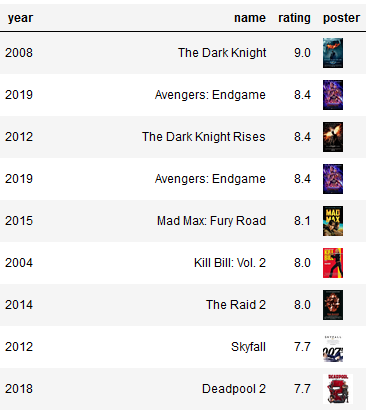
سرفہرست فلمیں جن میں کلیدی الفاظ "ٹیٹو" اور "قاتل" ہیں
درج ذیل استفسار فلموں کو مطلوبہ الفاظ "ٹیٹو" اور "قاتل" کے ساتھ لوٹاتا ہے:
درج ذیل اسکرین شاٹ ہمارے نتائج کو ظاہر کرتا ہے۔
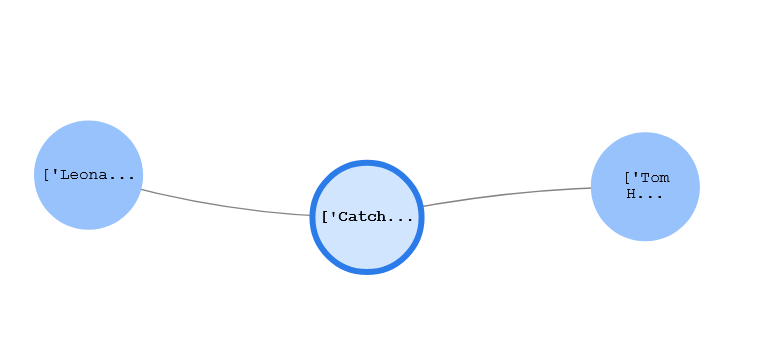
وہ فلمیں جن میں عام اداکار ہوں۔
درج ذیل استفسار میں، ہمیں لیونارڈو ڈی کیپریو اور ٹام ہینکس والی فلمیں ملتی ہیں:
ہمیں درج ذیل نتائج ملتے ہیں۔
نتیجہ
اس پوسٹ میں، ہم نے آپ کو IMDb اور Box Office Mojo Movies/TV/OTT ڈیٹاسیٹ کی طاقت دکھائی ہے اور یہ کہ آپ اسے مختلف استعمال کے معاملات میں کیسے استعمال کر سکتے ہیں ڈیٹا کو گریملن کے سوالات کا استعمال کرتے ہوئے گراف میں تبدیل کر سکتے ہیں۔ میں حصہ 2 اس سلسلے میں، ہم آپ کو دکھاتے ہیں کہ کس طرح اس ڈیٹا پر گراف نیورل نیٹ ورک ماڈلز بنائے جائیں جو کہ بہاو کے کاموں کے لیے استعمال کیے جا سکیں۔
نیپچون اور گریملن کے بارے میں مزید معلومات کے لیے رجوع کریں۔ ایمیزون نیپچون وسائل اضافی بلاگ پوسٹس اور ویڈیوز کے لیے۔
مصنفین کے بارے میں
 گورو ریلی ایمیزون ایم ایل سلوشن لیب میں ڈیٹا سائنٹسٹ ہے، جہاں وہ مختلف عمودی حصوں میں AWS صارفین کے ساتھ کام کرتا ہے تاکہ ان کے کاروباری چیلنجوں کو حل کرنے کے لیے مشین لرننگ اور AWS کلاؤڈ سروسز کے استعمال کو تیز کیا جا سکے۔
گورو ریلی ایمیزون ایم ایل سلوشن لیب میں ڈیٹا سائنٹسٹ ہے، جہاں وہ مختلف عمودی حصوں میں AWS صارفین کے ساتھ کام کرتا ہے تاکہ ان کے کاروباری چیلنجوں کو حل کرنے کے لیے مشین لرننگ اور AWS کلاؤڈ سروسز کے استعمال کو تیز کیا جا سکے۔
 میتھیو روڈس ایک ڈیٹا سائنٹسٹ ہے جو میں Amazon ML Solutions Lab میں کام کر رہا ہوں۔ وہ مشین لرننگ پائپ لائنز بنانے میں مہارت رکھتا ہے جس میں نیچرل لینگویج پروسیسنگ اور کمپیوٹر ویژن جیسے تصورات شامل ہیں۔
میتھیو روڈس ایک ڈیٹا سائنٹسٹ ہے جو میں Amazon ML Solutions Lab میں کام کر رہا ہوں۔ وہ مشین لرننگ پائپ لائنز بنانے میں مہارت رکھتا ہے جس میں نیچرل لینگویج پروسیسنگ اور کمپیوٹر ویژن جیسے تصورات شامل ہیں۔
 دیویا بھارگوی ایمیزون ایم ایل سلوشنز لیب میں ڈیٹا سائنٹسٹ اور میڈیا اینڈ انٹرٹینمنٹ ورٹیکل لیڈ ہے، جہاں وہ مشین لرننگ کا استعمال کرتے ہوئے AWS صارفین کے لیے اعلیٰ قدر کے کاروباری مسائل حل کرتی ہے۔ وہ تصویر/ویڈیو کی تفہیم، علمی گراف کی سفارش کے نظام، پیشن گوئی اشتہارات کے استعمال کے معاملات پر کام کرتی ہے۔
دیویا بھارگوی ایمیزون ایم ایل سلوشنز لیب میں ڈیٹا سائنٹسٹ اور میڈیا اینڈ انٹرٹینمنٹ ورٹیکل لیڈ ہے، جہاں وہ مشین لرننگ کا استعمال کرتے ہوئے AWS صارفین کے لیے اعلیٰ قدر کے کاروباری مسائل حل کرتی ہے۔ وہ تصویر/ویڈیو کی تفہیم، علمی گراف کی سفارش کے نظام، پیشن گوئی اشتہارات کے استعمال کے معاملات پر کام کرتی ہے۔
 کرن سندھوانی Amazon ML Solutions Lab میں ڈیٹا سائنٹسٹ ہے، جہاں وہ گہرے سیکھنے کے ماڈل بناتا اور تعینات کرتا ہے۔ وہ کمپیوٹر ویژن کے شعبے میں مہارت رکھتا ہے۔ اپنے فارغ وقت میں وہ پیدل سفر سے لطف اندوز ہوتا ہے۔
کرن سندھوانی Amazon ML Solutions Lab میں ڈیٹا سائنٹسٹ ہے، جہاں وہ گہرے سیکھنے کے ماڈل بناتا اور تعینات کرتا ہے۔ وہ کمپیوٹر ویژن کے شعبے میں مہارت رکھتا ہے۔ اپنے فارغ وقت میں وہ پیدل سفر سے لطف اندوز ہوتا ہے۔
 سوجی ادیشینہ AWS میں ایک اپلائیڈ سائنٹسٹ ہے جہاں وہ گرافس کے کاموں پر مشین لرننگ کے لیے گراف نیورل نیٹ ورک پر مبنی ماڈل تیار کرتا ہے جس میں فراڈ اور غلط استعمال کی ایپلی کیشنز، نالج گرافس، تجویز کنندہ سسٹمز، اور لائف سائنسز شامل ہیں۔ اپنے فارغ وقت میں، وہ پڑھنا اور کھانا پکانا پسند کرتا ہے۔
سوجی ادیشینہ AWS میں ایک اپلائیڈ سائنٹسٹ ہے جہاں وہ گرافس کے کاموں پر مشین لرننگ کے لیے گراف نیورل نیٹ ورک پر مبنی ماڈل تیار کرتا ہے جس میں فراڈ اور غلط استعمال کی ایپلی کیشنز، نالج گرافس، تجویز کنندہ سسٹمز، اور لائف سائنسز شامل ہیں۔ اپنے فارغ وقت میں، وہ پڑھنا اور کھانا پکانا پسند کرتا ہے۔
 ودیا ساگر روی پتی۔ Amazon ML Solutions Lab میں ایک مینیجر ہے، جہاں وہ بڑے پیمانے پر تقسیم شدہ نظاموں میں اپنے وسیع تجربے اور مشین لرننگ کے اپنے جذبے سے فائدہ اٹھاتا ہے تاکہ صنعت کے مختلف حصوں میں AWS صارفین کو ان کے AI اور کلاؤڈ کو اپنانے میں تیزی لا سکے۔
ودیا ساگر روی پتی۔ Amazon ML Solutions Lab میں ایک مینیجر ہے، جہاں وہ بڑے پیمانے پر تقسیم شدہ نظاموں میں اپنے وسیع تجربے اور مشین لرننگ کے اپنے جذبے سے فائدہ اٹھاتا ہے تاکہ صنعت کے مختلف حصوں میں AWS صارفین کو ان کے AI اور کلاؤڈ کو اپنانے میں تیزی لا سکے۔
- SEO سے چلنے والا مواد اور PR کی تقسیم۔ آج ہی بڑھا دیں۔
- پلیٹو بلاک چین۔ Web3 Metaverse Intelligence. علم میں اضافہ۔ یہاں تک رسائی حاصل کریں۔
- ماخذ: https://aws.amazon.com/blogs/machine-learning/part-1-power-recommendation-and-search-using-an-imdb-knowledge-graph/

