یہ NXP SEMICONDUCTORS NV اور AWS مشین لرننگ سولیوشن لیب (MLSL) کی مشترکہ پوسٹ ہے۔
مشین لرننگ (ML) کا استعمال صنعتوں کی ایک وسیع رینج میں ڈیٹا سے قابل عمل بصیرت نکالنے کے لیے عمل کو ہموار کرنے اور محصولات کی پیداوار کو بہتر بنانے کے لیے کیا جا رہا ہے۔ اس پوسٹ میں، ہم یہ ظاہر کرتے ہیں کہ کس طرح NXP، سیمی کنڈکٹر سیکٹر میں ایک صنعتی رہنما، کے ساتھ تعاون کیا AWS مشین لرننگ سلوشنز لیب (MLSL) کے مختص کو بہتر بنانے کے لیے ML تکنیک کا استعمال کرنا NXP ریسرچ اینڈ ڈیولپمنٹ (R&D) بجٹ ان کی سرمایہ کاری پر طویل مدتی منافع (ROI) کو زیادہ سے زیادہ کرنے کے لیے۔
NXP اپنی R&D کوششوں کو بڑے پیمانے پر نئے سیمی کنڈکٹر حلوں کی ترقی کی طرف ہدایت کرتا ہے جہاں وہ ترقی کے اہم مواقع دیکھتے ہیں۔ مارکیٹ کی ترقی کو آگے بڑھانے کے لیے، NXP تیزی سے ترقی کرنے والے، بڑے مارکیٹ کے حصوں پر زور دینے کے ساتھ، مارکیٹ کی اہم پوزیشنوں کو بڑھانے یا تخلیق کرنے کے لیے تحقیق اور ترقی میں سرمایہ کاری کرتا ہے۔ اس مصروفیت کے لیے، انہوں نے مختلف مادی گروپس اور کاروباری خطوط پر نئی اور موجودہ مصنوعات کے لیے ماہانہ فروخت کی پیشن گوئیاں تیار کرنے کی کوشش کی۔ اس پوسٹ میں، ہم یہ ظاہر کرتے ہیں کہ ایم ایل ایس ایل اور این ایکس پی نے کس طرح کام کیا۔ ایمیزون کی پیشن گوئی اور مختلف NXP مصنوعات کے لیے طویل مدتی فروخت کی پیشین گوئیوں کے لیے دیگر حسب ضرورت ماڈلز۔
"ہم نے سائنس دانوں اور ماہرین کی ٹیم کے ساتھ ایمیزون مشین لرننگ سولیوشن لیب کے ساتھ مشغول کیا تاکہ نئی مصنوعات کی فروخت کی پیشن گوئی کے لیے ایک حل تیار کیا جا سکے اور یہ سمجھیں کہ آیا اور کون سی اضافی خصوصیات R&D اخراجات کو بہتر بنانے کے لیے فیصلہ سازی کے عمل کو مطلع کرنے میں مدد کر سکتی ہیں۔ صرف چند ہفتوں کے اندر، ٹیم نے ہماری کچھ کاروباری لائنوں، مادی گروپوں، اور انفرادی مصنوعات کی سطح پر متعدد حل اور تجزیہ پیش کیے۔ ایم ایل ایس ایل نے سیلز کی پیشن گوئی کا ماڈل پیش کیا، جو ہمارے دستی پیشن گوئی کے موجودہ طریقے کی تکمیل کرتا ہے، اور ایمیزون فورکاسٹ اور ایمیزون سیج میکر کا استعمال کرتے ہوئے نوول مشین لرننگ اپروچ کے ساتھ پروڈکٹ لائف سائیکل کو ماڈل بنانے میں ہماری مدد کرتا ہے۔ اپنی ٹیم کے ساتھ ایک مستقل باہمی تعاون پر مبنی ورک اسٹریم کو برقرار رکھتے ہوئے، جب AWS انفراسٹرکچر کا استعمال کرتے ہوئے ایم ایل ڈیولپمنٹ پر سائنسی فضیلت اور بہترین طریقوں کی بات آتی ہے تو ایم ایل ایس ایل نے ہمارے پیشہ ور افراد کو بہتر بنانے میں ہماری مدد کی۔
- بارٹ زیمن، NXP سیمی کنڈکٹرز میں CTO آفس میں حکمت عملی اور تجزیہ کار۔
اہداف اور استعمال کا معاملہ
NXP اور MLSL ٹیم کے درمیان مصروفیت کا مقصد مختلف اختتامی منڈیوں میں NXP کی مجموعی فروخت کی پیش گوئی کرنا ہے۔ عام طور پر، NXP ٹیم میکرو لیول سیلز میں دلچسپی رکھتی ہے جس میں مختلف بزنس لائنز (BLs) کی فروخت شامل ہوتی ہے، جس میں متعدد میٹریل گروپس (MAGs) ہوتے ہیں۔ مزید برآں، NXP ٹیم نئی متعارف کرائی گئی مصنوعات کے لائف سائیکل کی پیشین گوئی کرنے میں بھی دلچسپی رکھتی ہے۔ کسی پروڈکٹ کا لائف سائیکل چار مختلف مراحل (تعارف، نمو، پختگی، اور زوال) میں تقسیم ہوتا ہے۔ پروڈکٹ لائف سائیکل کی پیشن گوئی NXP ٹیم کو اس قابل بناتی ہے کہ وہ ہر پروڈکٹ کے ذریعے حاصل ہونے والی آمدنی کی شناخت کر سکے تاکہ R&D کی فنڈنگ ان مصنوعات کے لیے مختص کی جا سکے جو سب سے زیادہ مقدار میں فروخت یا R&D سرگرمی کے لیے ROI کو زیادہ سے زیادہ کرنے کی اعلیٰ صلاحیت کے ساتھ مصنوعات تیار کر سکیں۔ مزید برآں، وہ مائیکرو لیول پر طویل مدتی فروخت کی پیشین گوئی کر سکتے ہیں، جس سے انہیں نیچے سے اوپر نظر آتا ہے کہ وقت کے ساتھ ان کی آمدنی میں کیسے تبدیلی آتی ہے۔
مندرجہ ذیل حصوں میں، ہم طویل مدتی فروخت کی پیشن گوئی کے لیے مضبوط اور موثر ماڈل تیار کرنے سے وابستہ اہم چیلنجز پیش کرتے ہیں۔ ہم مطلوبہ درستگی کو حاصل کرنے کے لیے استعمال کی جانے والی مختلف ماڈلنگ تکنیکوں کے پیچھے وجدان کی مزید وضاحت کرتے ہیں۔ اس کے بعد ہم اپنے حتمی ماڈلز کا جائزہ پیش کرتے ہیں، جہاں ہم NXP کے مارکیٹ ماہرین کے ساتھ فروخت کی پیشین گوئی کے لحاظ سے مجوزہ ماڈلز کی کارکردگی کا موازنہ کرتے ہیں۔ ہم اپنے جدید ترین پوائنٹ کلاؤڈ بیسڈ پروڈکٹ لائف سائیکل پیشین گوئی الگورتھم کی کارکردگی کا بھی مظاہرہ کرتے ہیں۔
چیلنجز
فروخت کی پیشن گوئی کے لیے پروڈکٹ لیول ماڈل جیسے عمدہ یا مائیکرو لیول ماڈلنگ کا استعمال کرتے ہوئے ہمیں درپیش چیلنجز میں سے ایک سیلز ڈیٹا غائب تھا۔ لاپتہ ڈیٹا ہر ماہ کے دوران فروخت کی کمی کا نتیجہ ہے۔ اسی طرح، میکرو لیول سیلز کی پیشین گوئی کے لیے، تاریخی سیلز ڈیٹا کی لمبائی محدود تھی۔ فروخت کے غائب ہونے والے ڈیٹا اور تاریخی فروخت کے اعداد و شمار کی محدود لمبائی دونوں ہی 2026 میں طویل مدتی فروخت کی پیشین گوئی کے لیے ماڈل کی درستگی کے لحاظ سے اہم چیلنجز پیش کرتے ہیں۔ پروڈکٹ لیول) سے میکرو لیول سیلز (BL لیول) تک، لاپتہ اقدار کم اہم ہو جاتی ہیں۔ تاہم، تاریخی فروخت کے اعداد و شمار کی زیادہ سے زیادہ لمبائی (زیادہ سے زیادہ طوالت 140 ماہ) نے ابھی بھی ماڈل کی درستگی کے لحاظ سے اہم چیلنجز کا سامنا کیا ہے۔
ماڈلنگ کی تکنیک
EDA کے بعد، ہم نے BL اور MAG کی سطحوں اور NXP کے لیے سب سے بڑی اینڈ مارکیٹ (آٹو موبائل اینڈ مارکیٹ) میں سے ایک کے لیے مصنوعات کی سطح پر پیشن گوئی پر توجہ مرکوز کی۔ تاہم، ہم نے جو حل تیار کیے ہیں ان کو دوسرے اختتامی بازاروں تک بڑھایا جا سکتا ہے۔ ماڈل کی کارکردگی اور ڈیٹا کی دستیابی کے لحاظ سے BL، MAG، یا پروڈکٹ کی سطح پر ماڈلنگ کے اپنے فوائد اور نقصانات ہیں۔ مندرجہ ذیل جدول ہر سطح کے لیے ایسے فوائد اور نقصانات کا خلاصہ کرتا ہے۔ میکرو لیول سیلز کی پیشین گوئی کے لیے، ہم نے اپنے حتمی حل کے لیے Amazon Forecast AutoPredictor کا استعمال کیا۔ اسی طرح، مائیکرو لیول سیلز کی پیشین گوئی کے لیے، ہم نے کلاؤڈ پر مبنی ایک نوول پوائنٹ تیار کیا۔

میکرو فروخت کی پیشن گوئی (اوپر سے نیچے)
میکرو سطح پر طویل مدتی سیلز ویلیوز (2026) کی پیش گوئی کرنے کے لیے، ہم نے مختلف طریقوں کا تجربہ کیا، بشمول Amazon Forecast، GluonTS، اور N-BEATS (GluonTS اور PyTorch میں لاگو)۔ مجموعی طور پر، پیشن گوئی نے میکرو لیول کی فروخت کی پیشین گوئی کے لیے بیک ٹیسٹنگ اپروچ (بعد میں اس پوسٹ میں ایویلیوایشن میٹرکس سیکشن میں بیان کیا گیا ہے) کی بنیاد پر دیگر تمام طریقوں سے بہتر کارکردگی کا مظاہرہ کیا۔ ہم نے آٹو پریڈیکٹر کی درستگی کا انسانی پیشین گوئیوں کے خلاف بھی موازنہ کیا۔
ہم نے N-BEATS کو اس کی تشریحی خصوصیات کی وجہ سے استعمال کرنے کی تجویز بھی دی۔ N-BEATS ایک بہت ہی سادہ لیکن طاقتور فن تعمیر پر مبنی ہے جو فیڈ فارورڈ نیٹ ورکس کا ایک جوڑا استعمال کرتا ہے جو پیشن گوئی کے لیے اسٹیک شدہ بقایا بلاکس کے ساتھ بقایا کنکشن لگاتا ہے۔ یہ فن تعمیر اپنے فن تعمیر میں آنے والے تعصب کو مزید انکوڈ کرتا ہے تاکہ ٹائم سیریز کے ماڈل کو رجحان اور موسم کو نکالنے کے قابل بنایا جا سکے (مندرجہ ذیل تصویر دیکھیں)۔ یہ تشریحات PyTorch Forecasting کا استعمال کرتے ہوئے تیار کی گئیں۔

مائیکرو فروخت کی پیشن گوئی (نیچے سے اوپر)
اس سیکشن میں، ہم کولڈ اسٹارٹ پروڈکٹ کو مدنظر رکھتے ہوئے مندرجہ ذیل تصویر میں دکھائے گئے پروڈکٹ لائف سائیکل کی پیشین گوئی کرنے کے لیے تیار کیے گئے ایک نئے طریقہ پر تبادلہ خیال کرتے ہیں۔ ہم نے PyTorch on کا استعمال کرتے ہوئے اس طریقہ کو نافذ کیا۔ ایمیزون سیج میکر اسٹوڈیو. سب سے پہلے، ہم نے ایک نقطہ کلاؤڈ پر مبنی طریقہ متعارف کرایا۔ یہ طریقہ پہلے سیلز ڈیٹا کو پوائنٹ کلاؤڈ میں تبدیل کرتا ہے، جہاں ہر پوائنٹ پروڈکٹ کی ایک مخصوص عمر میں سیلز ڈیٹا کی نمائندگی کرتا ہے۔ پوائنٹ کلاؤڈ بیسڈ نیورل نیٹ ورک ماڈل کو اس ڈیٹا کا استعمال کرتے ہوئے پروڈکٹ لائف سائیکل وکر کے پیرامیٹرز کو جاننے کے لیے مزید تربیت دی جاتی ہے (مندرجہ ذیل تصویر دیکھیں)۔ اس نقطہ نظر میں، ہم نے اضافی خصوصیات بھی شامل کیں، بشمول پروڈکٹ کی تفصیل کو الفاظ کے ایک تھیلے کے طور پر پروڈکٹ لائف سائیکل وکر کی پیش گوئی کرنے کے لیے کولڈ اسٹارٹ کے مسئلے سے نمٹنے کے لیے۔

پوائنٹ کلاؤڈ بیسڈ پروڈکٹ لائف سائیکل پیشین گوئی کے طور پر ٹائم سیریز
ہم نے پروڈکٹ لائف سائیکل اور مائیکرو لیول سیلز کی پیشین گوئی کرنے کے لیے ایک نوول پوائنٹ کلاؤڈ بیسڈ اپروچ تیار کیا۔ ہم نے کولڈ اسٹارٹ پروڈکٹ لائف سائیکل کی پیشین گوئیوں کے لیے ماڈل کی درستگی کو مزید بہتر بنانے کے لیے اضافی خصوصیات بھی شامل کیں۔ ان خصوصیات میں پروڈکٹ فیبریکیشن تکنیک اور پروڈکٹس سے متعلق دیگر متعلقہ واضح معلومات شامل ہیں۔ اس طرح کے اضافی اعداد و شمار سے ماڈل کو نئی مصنوعات کی فروخت کی پیش گوئی کرنے میں مدد مل سکتی ہے یہاں تک کہ پروڈکٹ کو مارکیٹ میں ریلیز کیا جائے (کولڈ اسٹارٹ)۔ درج ذیل اعداد و شمار کلاؤڈ پر مبنی نقطہ نظر کو ظاہر کرتا ہے۔ ماڈل ان پٹ کے طور پر پروڈکٹ کی عام فروخت اور عمر (پروڈکٹ لانچ ہونے کے بعد سے مہینوں کی تعداد) لیتا ہے۔ ان ان پٹس کی بنیاد پر، ماڈل ٹریننگ کے دوران گریڈینٹ ڈیسنٹ کا استعمال کرتے ہوئے پیرامیٹرز سیکھتا ہے۔ پیشن گوئی کے مرحلے کے دوران، پیرامیٹرز کے ساتھ ساتھ کولڈ اسٹارٹ پروڈکٹ کی خصوصیات لائف سائیکل کی پیشن گوئی کے لیے استعمال کی جاتی ہیں۔ پروڈکٹ کی سطح پر ڈیٹا میں گمشدہ اقدار کی بڑی تعداد موجودہ ٹائم سیریز کے تقریباً سبھی ماڈلز پر منفی اثر ڈالتی ہے۔ یہ نیا حل لائف سائیکل ماڈلنگ کے خیالات پر مبنی ہے اور گمشدہ اقدار کو کم کرنے کے لیے ٹائم سیریز کے ڈیٹا کو پوائنٹ کلاؤڈ کے طور پر استعمال کرنا ہے۔
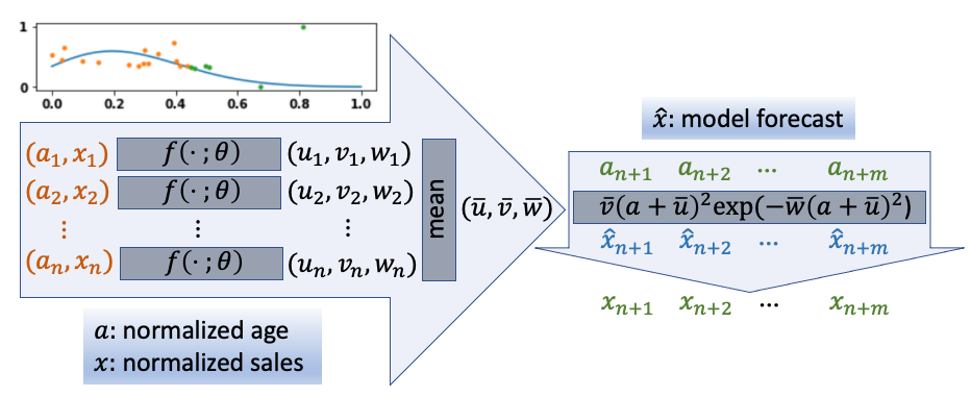
مندرجہ ذیل اعداد و شمار یہ ظاہر کرتا ہے کہ ہمارا نقطہ کلاؤڈ بیسڈ لائف سائیکل طریقہ ڈیٹا کی گمشدہ اقدار کو کیسے حل کرتا ہے اور بہت کم تربیتی نمونوں کے ساتھ پروڈکٹ لائف سائیکل کی پیش گوئی کرنے کے قابل ہے۔ X-axis وقت میں عمر کی نمائندگی کرتا ہے، اور Y-axis کسی پروڈکٹ کی فروخت کی نمائندگی کرتا ہے۔ نارنجی نقطے تربیتی نمونوں کی نمائندگی کرتے ہیں، سبز نقطے جانچ کے نمونوں کی نمائندگی کرتے ہیں، اور نیلی لکیر ماڈل کے ذریعہ کسی مصنوع کی پیش گوئی شدہ لائف سائیکل کو ظاہر کرتی ہے۔

طریقہ کار
میکرو لیول سیلز کی پیشن گوئی کرنے کے لیے، ہم نے دیگر تکنیکوں کے ساتھ Amazon Forecast کا استعمال کیا۔ اسی طرح، مائیکرو سیلز کے لیے، ہم نے ایک جدید ترین پوائنٹ کلاؤڈ بیسڈ کسٹم ماڈل تیار کیا۔ پیشن گوئی نے ماڈل کی کارکردگی کے لحاظ سے دیگر تمام طریقوں کو پیچھے چھوڑ دیا۔ ہم نے ڈیٹا پروسیسنگ پائپ لائن بنانے کے لیے Amazon SageMaker نوٹ بک مثالوں کا استعمال کیا جس نے Amazon Simple Storage Service (Amazon S3) سے تربیتی مثالیں نکالیں۔ ٹریننگ ڈیٹا کو مزید پیشن گوئی کے لیے بطور ان پٹ استعمال کیا گیا تاکہ ماڈل کو تربیت دی جا سکے اور طویل مدتی فروخت کی پیشن گوئی کی جا سکے۔
Amazon Forecast کا استعمال کرتے ہوئے ٹائم سیریز ماڈل کی تربیت تین اہم مراحل پر مشتمل ہے۔ پہلے مرحلے میں، ہم نے تاریخی ڈیٹا Amazon S3 میں درآمد کیا۔ دوسرا، ایک پیشن گوئی کرنے والے کو تاریخی اعداد و شمار کا استعمال کرتے ہوئے تربیت دی گئی تھی۔ آخر میں، ہم نے پیشن گوئی پیدا کرنے کے لیے تربیت یافتہ پیشن گو کو تعینات کیا۔ اس سیکشن میں، ہم ہر قدم کے کوڈ کے ٹکڑوں کے ساتھ ایک تفصیلی وضاحت فراہم کرتے ہیں۔
ہم نے سیلز کا تازہ ترین ڈیٹا نکال کر شروع کیا۔ اس قدم میں ڈیٹا سیٹ کو Amazon S3 پر درست فارمیٹ میں اپ لوڈ کرنا شامل ہے۔ Amazon Forecast تین کالموں کو ان پٹ کے طور پر لیتا ہے: ٹائم اسٹیمپ، آئٹم_آئی ڈی، اور ٹارگٹ_ویلیو (سیلز ڈیٹا)۔ ٹائم اسٹیمپ کالم میں فروخت کا وقت ہوتا ہے، جسے فی گھنٹہ، روزانہ، اور اسی طرح فارمیٹ کیا جا سکتا ہے۔ آئٹم_آئی ڈی کالم میں فروخت شدہ آئٹمز کا نام ہوتا ہے، اور ٹارگٹ_ویلیو کالم سیلز ویلیوز پر مشتمل ہوتا ہے۔ اس کے بعد، ہم نے ایمیزون S3 میں واقع تربیتی ڈیٹا کا راستہ استعمال کیا، ٹائم سیریز ڈیٹاسیٹ فریکوئنسی (H, D, W, M, Y) کی وضاحت کی، ڈیٹاسیٹ کے نام کی وضاحت کی، اور ڈیٹاسیٹ کی صفات کی نشاندہی کی (متعلقہ کالموں کو ڈیٹاسیٹ اور ان کے ڈیٹا کی اقسام)۔ اس کے بعد، ہم نے Boto3 API سے Create_dataset فنکشن کا نام دیا تاکہ ڈومین، DatasetType، DatasetName، DatasetFrequency، اور Schema جیسی خصوصیات کے ساتھ ڈیٹاسیٹ بنایا جائے۔ اس فنکشن نے ایک JSON آبجیکٹ واپس کیا جس میں Amazon Resource Name (ARN) تھا۔ اس ARN کو بعد میں درج ذیل مراحل میں استعمال کیا گیا۔ درج ذیل کوڈ دیکھیں:
dataset_path = "PATH_OF_DATASET_IN_S3"
DATASET_FREQUENCY = "M" # Frequency of dataset (H, D, W, M, Y) TS_DATASET_NAME = "NAME_OF_THE_DATASET"
TS_SCHEMA = { "Attributes":[ { "AttributeName":"item_id", "AttributeType":"string" }, { "AttributeName":"timestamp", "AttributeType":"timestamp" }, { "AttributeName":"target_value", "AttributeType":"float" } ]
} create_dataset_response = forecast.create_dataset(Domain="CUSTOM", DatasetType='TARGET_TIME_SERIES', DatasetName=TS_DATASET_NAME, DataFrequency=DATASET_FREQUENCY, Schema=TS_SCHEMA) ts_dataset_arn = create_dataset_response['DatasetArn']ڈیٹاسیٹ بنانے کے بعد، اسے Boto3 کا استعمال کرتے ہوئے Amazon Forecast میں درآمد کیا گیا۔ تخلیق_ڈیٹا سیٹ_امپورٹ_نوکری۔ تقریب تخلیق_ڈیٹا سیٹ_امپورٹ_نوکری۔ فنکشن نوکری کا نام (سٹرنگ ویلیو)، پچھلے مرحلے سے ڈیٹاسیٹ کا ARN، پچھلے مرحلے سے Amazon S3 میں ٹریننگ ڈیٹا کا مقام، اور ٹائم اسٹیمپ فارمیٹ کو بطور دلیل لیتا ہے۔ یہ ایک JSON آبجیکٹ لوٹاتا ہے جس میں امپورٹ جاب ARN ہے۔ درج ذیل کوڈ دیکھیں:
TIMESTAMP_FORMAT = "yyyy-MM-dd"
TS_IMPORT_JOB_NAME = "SALES_DATA_IMPORT_JOB_NAME" ts_dataset_import_job_response = forecast.create_dataset_import_job(DatasetImportJobName=TS_IMPORT_JOB_NAME, DatasetArn=ts_dataset_arn, DataSource= { "S3Config" : { "Path": ts_s3_path, "RoleArn": role_arn } }, TimestampFormat=TIMESTAMP_FORMAT, TimeZone = TIMEZONE) ts_dataset_import_job_arn = ts_dataset_import_job_response['DatasetImportJobArn']درآمد شدہ ڈیٹاسیٹ کو پھر create_dataset_group فنکشن کا استعمال کرتے ہوئے ڈیٹاسیٹ گروپ بنانے کے لیے استعمال کیا گیا۔ یہ فنکشن ڈومین (اسٹرنگ ویلیوز جو پیشن گوئی کے ڈومین کی وضاحت کرتا ہے)، ڈیٹاسیٹ گروپ کا نام، اور ڈیٹاسیٹ ARN کو بطور ان پٹ لیتا ہے:
DATASET_GROUP_NAME = "SALES_DATA_GROUP_NAME"
DATASET_ARNS = [ts_dataset_arn] create_dataset_group_response = forecast.create_dataset_group(Domain="CUSTOM", DatasetGroupName=DATASET_GROUP_NAME, DatasetArns=DATASET_ARNS) dataset_group_arn = create_dataset_group_response['DatasetGroupArn']
اگلا، ہم نے ڈیٹاسیٹ گروپ کو پیشن گوئی کے ماڈلز کی تربیت کے لیے استعمال کیا۔ Amazon Forecast مختلف جدید ترین ماڈل پیش کرتا ہے۔ ان میں سے کسی بھی ماڈل کو تربیت کے لیے استعمال کیا جا سکتا ہے۔ ہم نے اپنے ڈیفالٹ ماڈل کے طور پر AutoPredictor کا استعمال کیا۔ AutoPredictor استعمال کرنے کا بنیادی فائدہ یہ ہے کہ یہ ان پٹ ڈیٹاسیٹ کی بنیاد پر چھ جدید ترین ماڈلز کے جوڑ سے بہترین ماڈل کا استعمال کرتے ہوئے خود بخود آئٹم لیول کی پیشن گوئی پیدا کرتا ہے۔ Boto3 API فراہم کرتا ہے۔ تخلیق_آٹو_پیش گوئی کرنے والا ایک آٹو پیشن گوئی ماڈل کی تربیت کے لیے فنکشن۔ اس فنکشن کے ان پٹ پیرامیٹرز ہیں۔ پیش گوئی کرنے والے کا نام, ForecastHorizon، اور پیشن گوئی کی تعدد. صارفین پیشن گوئی کے افق اور تعدد کو منتخب کرنے کے بھی ذمہ دار ہیں۔ پیشن گوئی کا افق مستقبل کی پیشین گوئی کی کھڑکی کے سائز کی نمائندگی کرتا ہے، جسے گھنٹے، دن، ہفتے، مہینوں اور اسی طرح فارمیٹ کیا جا سکتا ہے۔ اسی طرح، پیشن گوئی کی فریکوئنسی پیشن گوئی کی قدروں کی گرینولریٹی کی نمائندگی کرتی ہے، جیسے فی گھنٹہ، روزانہ، ہفتہ وار، ماہانہ، یا سالانہ۔ ہم نے بنیادی طور پر مختلف BLs پر NXP کی ماہانہ فروخت کی پیش گوئی کرنے پر توجہ مرکوز کی۔ درج ذیل کوڈ دیکھیں:
PREDICTOR_NAME = "SALES_PREDICTOR"
FORECAST_HORIZON = 24
FORECAST_FREQUENCY = "M" create_auto_predictor_response = forecast.create_auto_predictor(PredictorName = PREDICTOR_NAME, ForecastHorizon = FORECAST_HORIZON, ForecastFrequency = FORECAST_FREQUENCY, DataConfig = { 'DatasetGroupArn': dataset_group_arn }) predictor_arn = create_auto_predictor_response['PredictorArn']تربیت یافتہ پیشن گوئی کرنے والے کو پھر پیشن گوئی کی قدریں پیدا کرنے کے لیے استعمال کیا گیا۔ کا استعمال کرتے ہوئے پیشن گوئیاں تیار کی گئیں۔ بنائیں_پیش گوئی پہلے سے تربیت یافتہ پیشن گو سے فنکشن۔ یہ فنکشن پیشن گوئی کا نام اور پیشین گوئی کرنے والے کے ARN کو بطور ان پٹ لیتا ہے اور پیشین گوئی کرنے والے میں بیان کردہ افق اور تعدد کے لیے پیشن گوئی کی قدریں تیار کرتا ہے:
FORECAST_NAME = "SALES_FORECAST" create_forecast_response = forecast.create_forecast(ForecastName=FORECAST_NAME, PredictorArn=predictor_arn)Amazon Forecast ایک مکمل طور پر منظم سروس ہے جو خود بخود ٹریننگ اور ٹیسٹ ڈیٹاسیٹ تیار کرتی ہے اور ماڈل کے ذریعے تیار کردہ پیشن گوئی کی وشوسنییتا کا جائزہ لینے کے لیے مختلف درستگی کے میٹرکس فراہم کرتی ہے۔ تاہم، پیش گوئی کردہ ڈیٹا پر اتفاق رائے پیدا کرنے اور پیشین گوئی شدہ اقدار کا انسانی پیشین گوئیوں کے ساتھ موازنہ کرنے کے لیے، ہم نے اپنے تاریخی ڈیٹا کو تربیتی ڈیٹا اور تصدیقی ڈیٹا میں دستی طور پر تقسیم کیا۔ ہم نے ماڈل کو توثیق کے اعداد و شمار کے سامنے لائے بغیر ٹریننگ ڈیٹا کا استعمال کرتے ہوئے ماڈل کو تربیت دی اور توثیق کے ڈیٹا کی لمبائی کے لیے پیشین گوئی پیدا کی۔ ماڈل کی کارکردگی کا جائزہ لینے کے لیے توثیق کے اعداد و شمار کا موازنہ پیش گوئی شدہ اقدار سے کیا گیا۔ توثیق کے میٹرکس میں دیگر کے درمیان اوسط فیصد غلطی (MAPE) اور وزنی مطلق فیصد غلطی (WAPE) شامل ہو سکتی ہے۔ ہم نے WAPE کو اپنی درستگی کے میٹرک کے طور پر استعمال کیا، جیسا کہ اگلے حصے میں زیر بحث آیا ہے۔
تشخیصی میٹرکس
ہم نے طویل مدتی فروخت کی پیشن گوئی (2026 سیلز) کے لیے اپنے پیشن گوئی کے ماڈل کی پیشن گوئی کو درست کرنے کے لیے پہلے بیک ٹیسٹنگ کا استعمال کرتے ہوئے ماڈل کی کارکردگی کی تصدیق کی۔ ہم نے WAPE کا استعمال کرتے ہوئے ماڈل کی کارکردگی کا جائزہ لیا۔ WAPE قدر جتنی کم ہوگی، ماڈل اتنا ہی بہتر ہوگا۔ MAPE جیسے دیگر ایرر میٹرکس پر WAPE استعمال کرنے کا اہم فائدہ یہ ہے کہ WAPE ہر آئٹم کی فروخت کے انفرادی اثر کو وزن کرتا ہے۔ لہذا، مجموعی خرابی کا حساب لگاتے ہوئے یہ کل فروخت میں ہر پروڈکٹ کی شراکت کا حساب رکھتا ہے۔ مثال کے طور پر، اگر آپ $2 ملین پیدا کرنے والے پروڈکٹ میں 30% کی غلطی کرتے ہیں اور $10 پیدا کرنے والے پروڈکٹ میں 50,000% کی غلطی کرتے ہیں، تو آپ کا MAPE پوری کہانی نہیں بتائے گا۔ 2% کی خرابی دراصل 10% غلطی سے زیادہ مہنگی ہے، ایسی چیز جسے آپ MAPE استعمال کرکے نہیں بتا سکتے۔ تقابلی طور پر، WAPE ان فرقوں کا حساب دے گا۔ ہم نے ماڈل کی پیشن گوئی کے اوپری اور نچلے حدود کو ظاہر کرنے کے لیے سیلز کے لیے مختلف پرسنٹائل اقدار کی بھی پیش گوئی کی۔
میکرو لیول سیلز پیشن گوئی ماڈل کی توثیق
اگلا، ہم نے WAPE اقدار کے لحاظ سے ماڈل کی کارکردگی کی توثیق کی۔ ہم نے ڈیٹا کو ٹیسٹ اور توثیق کے سیٹ میں تقسیم کرکے ماڈل کی WAPE قدر کا حساب لگایا۔ مثال کے طور پر، 2019 WAPE قدر میں، ہم نے 2011-2018 کے درمیان سیلز ڈیٹا کا استعمال کرتے ہوئے اپنے ماڈل کو تربیت دی اور اگلے 12 مہینوں (2019 سیل) کے لیے سیلز ویلیوز کی پیش گوئی کی۔ اگلا، ہم نے درج ذیل فارمولے کا استعمال کرتے ہوئے WAPE قدر کا حساب لگایا:

ہم نے 2020 اور 2021 کے لیے WAPE کی قیمت کا حساب لگانے کے لیے اسی طریقہ کار کو دہرایا۔ ہم نے 2019، 2020 اور 2021 کے لیے آٹو اینڈ مارکیٹ میں تمام BLs کے لیے WAPE کا جائزہ لیا۔ 0.33 کا سال (COVID-2020 وبائی امراض کے دوران)۔ 19 اور 2019 میں، ہمارے ماڈل نے اعلی درستگی کا مظاہرہ کرتے ہوئے 2020 سے کم WAPE قدریں حاصل کیں۔
میکرو لیول سیلز کی پیشن گوئی بیس لائن موازنہ
ہم نے 2019، 2020 اور 2021 کے لیے WAPE قدر کے لحاظ سے Amazon Forecast کا استعمال کرتے ہوئے تیار کیے گئے میکرو سیلز پیشن گوئی ماڈلز کی کارکردگی کا موازنہ کیا (مندرجہ ذیل تصویر دیکھیں)۔ Amazon Forecast نے یا تو دیگر بیس لائن ماڈلز کو نمایاں طور پر پیچھے چھوڑ دیا یا تمام 3 سالوں کے لیے برابری پر کارکردگی کا مظاہرہ کیا۔ یہ نتائج ہماری حتمی ماڈل پیشین گوئیوں کی تاثیر کو مزید توثیق کرتے ہیں۔

میکرو لیول سیلز پیشین گوئی ماڈل بمقابلہ انسانی پیشین گوئیاں
اپنے میکرو لیول ماڈل کے اعتماد کو مزید توثیق کرنے کے لیے، ہم نے اگلا اپنے ماڈل کی کارکردگی کا انسانی پیشن گوئی کی فروخت کی اقدار سے موازنہ کیا۔ ہر سال چوتھی سہ ماہی کے آغاز میں، NXP کے مارکیٹ ماہرین عالمی مارکیٹ کے رجحانات کے ساتھ ساتھ دیگر عالمی اشارے جو ممکنہ طور پر NXP مصنوعات کی فروخت کو متاثر کر سکتے ہیں، کو مدنظر رکھتے ہوئے، ہر BL کی فروخت کی قیمت کی پیش گوئی کرتے ہیں۔ ہم 2019، 2020 اور 2021 میں حقیقی فروخت کی قدروں کے ساتھ ماڈل کی پیشن گوئی بمقابلہ انسانی پیشین گوئی کی فیصد غلطی کا موازنہ کرتے ہیں۔ ہم نے 2011-2018 کے ڈیٹا کا استعمال کرتے ہوئے تین ماڈلز کو تربیت دی اور 2021 تک فروخت کی قدروں کی پیش گوئی کی۔ ہم نے اگلا MAPE کا حساب لگایا فروخت کی اصل قیمتیں اس کے بعد ہم نے 2018 کے آخر تک انسانی پیش گوئی کی اقدار کا استعمال کیا (ماڈل کی پیشن گوئی 1Y آگے سے 3Y آگے کی پیشن گوئی کی جانچ کریں)۔ ہم نے 2019 میں قدروں کی پیشن گوئی کرنے کے لیے اس عمل کو دہرایا (1Y آگے کی پیشن گوئی سے 2Y آگے کی پیشن گوئی) اور 2020 (1Y آگے کی پیشن گوئی کے لیے)۔ مجموعی طور پر، ماڈل نے انسانی پیش گوئوں کے برابر یا کچھ معاملات میں بہتر کارکردگی کا مظاہرہ کیا۔ یہ نتائج ہمارے ماڈل کی تاثیر اور وشوسنییتا کو ظاہر کرتے ہیں۔
مائیکرو لیول سیلز کی پیشن گوئی اور پروڈکٹ لائف سائیکل
مندرجہ ذیل اعداد و شمار میں دکھایا گیا ہے کہ ماڈل پروڈکٹ ڈیٹا کا استعمال کرتے ہوئے کیسا برتاؤ کرتا ہے جب کہ ہر پروڈکٹ کے لیے بہت کم مشاہدات تک رسائی ہوتی ہے (یعنی پروڈکٹ لائف سائیکل کی پیشن گوئی کے لیے ان پٹ پر ایک یا دو مشاہدات)۔ نارنجی نقطے تربیتی اعداد و شمار کی نمائندگی کرتے ہیں، سبز نقطے جانچ کے اعداد و شمار کی نمائندگی کرتے ہیں، اور نیلی لکیر ماڈل کی پیش گوئی شدہ مصنوعات کی لائف سائیکل کی نمائندگی کرتی ہے۔



نئے سیلز ڈیٹا کے دستیاب ہونے پر ماڈل کو دوبارہ تربیت کی ضرورت کے بغیر سیاق و سباق کے لیے مزید مشاہدات فراہم کیے جا سکتے ہیں۔ مندرجہ ذیل اعداد و شمار سے پتہ چلتا ہے کہ ماڈل کیسا برتاؤ کرتا ہے اگر اسے مزید سیاق و سباق دیا جائے۔ بالآخر، زیادہ سیاق و سباق WAPE کی قدروں کو کم کرنے کا باعث بنتے ہیں۔
اس کے علاوہ، ہم ہر پروڈکٹ کے لیے اضافی خصوصیات شامل کرنے میں کامیاب ہو گئے، بشمول من گھڑت تکنیک اور دیگر واضح معلومات۔ اس سلسلے میں، بیرونی خصوصیات نے کم سیاق و سباق کے نظام میں WAPE کی قدر کو کم کرنے میں مدد کی (مندرجہ ذیل تصویر دیکھیں)۔ اس رویے کی دو وضاحتیں ہیں۔ سب سے پہلے، ہمیں اعلیٰ سیاق و سباق کی حکومتوں میں ڈیٹا کو اپنے لیے بولنے کی ضرورت ہے۔ اضافی خصوصیات اس عمل میں مداخلت کر سکتی ہیں۔ دوسرا، ہمیں بہتر خصوصیات کی ضرورت ہے۔ ہم نے 1,000 جہتی ایک گرم انکوڈ شدہ خصوصیات (الفاظ کا تھیلا) استعمال کیا۔ قیاس یہ ہے کہ بہتر فیچر انجینئرنگ تکنیک WAPE کو مزید کم کرنے میں مدد کر سکتی ہے۔
اس طرح کے اضافی ڈیٹا سے ماڈل کو نئی مصنوعات کی فروخت کی پیشن گوئی کرنے میں مدد مل سکتی ہے یہاں تک کہ پروڈکٹ کو مارکیٹ میں ریلیز کیا جائے۔ مثال کے طور پر، مندرجہ ذیل تصویر میں، ہم منصوبہ بناتے ہیں کہ ہم صرف بیرونی خصوصیات سے کتنا مائلیج حاصل کر سکتے ہیں۔

نتیجہ
اس پوسٹ میں، ہم نے دکھایا کہ کس طرح MLSL اور NXP ٹیموں نے NXP کے لیے میکرو اور مائیکرو لیول کی طویل مدتی فروخت کی پیش گوئی کرنے کے لیے مل کر کام کیا۔ NXP ٹیم اب سیکھے گی کہ ان فروخت کی پیشین گوئیوں کو اپنے عمل میں کیسے استعمال کیا جائے — مثال کے طور پر، اسے R&D فنڈنگ کے فیصلوں کے لیے بطور ان پٹ استعمال کرنا اور ROI کو بڑھانا۔ ہم نے Amazon Forecast کا استعمال بزنس لائنز (میکرو سیلز) کی فروخت کی پیشین گوئی کرنے کے لیے کیا، جسے ہم نے اوپر سے نیچے کے نقطہ نظر سے تعبیر کیا۔ ہم نے پروڈکٹ کی سطح (مائیکرو لیول) پر گمشدہ اقدار اور کولڈ اسٹارٹ کے چیلنجوں سے نمٹنے کے لیے ٹائم سیریز کو پوائنٹ کلاؤڈ کے طور پر استعمال کرتے ہوئے ایک نیا طریقہ بھی تجویز کیا۔ ہم نے اس نقطہ نظر کو نیچے سے اوپر کہا، جہاں ہم نے ہر پروڈکٹ کی ماہانہ فروخت کی پیش گوئی کی۔ ہم نے ہر پروڈکٹ کی بیرونی خصوصیات کو مزید شامل کیا تاکہ کولڈ اسٹارٹ کے لیے ماڈل کی کارکردگی کو بہتر بنایا جا سکے۔
مجموعی طور پر، اس مصروفیت کے دوران تیار کردہ ماڈلز نے انسانی پیشین گوئی کے مقابلے میں برابری کی کارکردگی کا مظاہرہ کیا۔ کچھ معاملات میں، ماڈلز نے طویل مدت میں انسانی پیشین گوئیوں سے بہتر کارکردگی کا مظاہرہ کیا۔ یہ نتائج ہمارے ماڈلز کی تاثیر اور وشوسنییتا کو ظاہر کرتے ہیں۔
یہ حل پیشن گوئی کے کسی بھی مسئلے کے لیے استعمال کیا جا سکتا ہے۔ ایم ایل سلوشنز کو ڈیزائن کرنے اور تیار کرنے کے سلسلے میں مزید مدد کے لیے، براہ کرم بلا جھجھک رابطہ کریں۔ ایم ایل ایس ایل ٹیم.
مصنفین کے بارے میں
 سعود بوتان NXP-CTO میں ڈیٹا سائنٹسٹ ہے، جہاں وہ جدید ٹولز اور تکنیکوں کا استعمال کرتے ہوئے کاروباری فیصلے کی حمایت کرنے کے لیے مختلف ڈیٹا کو بامعنی بصیرت میں تبدیل کر رہی ہے۔
سعود بوتان NXP-CTO میں ڈیٹا سائنٹسٹ ہے، جہاں وہ جدید ٹولز اور تکنیکوں کا استعمال کرتے ہوئے کاروباری فیصلے کی حمایت کرنے کے لیے مختلف ڈیٹا کو بامعنی بصیرت میں تبدیل کر رہی ہے۔
 بین فریڈولن NXP-CTO میں ڈیٹا سائنٹسٹ ہے، جہاں وہ AI اور کلاؤڈ کو اپنانے کو تیز کرنے پر کوآرڈینیٹ کرتا ہے۔ وہ مشین لرننگ، ڈیپ لرننگ اور اینڈ ٹو اینڈ ایم ایل سلوشنز پر فوکس کرتا ہے۔
بین فریڈولن NXP-CTO میں ڈیٹا سائنٹسٹ ہے، جہاں وہ AI اور کلاؤڈ کو اپنانے کو تیز کرنے پر کوآرڈینیٹ کرتا ہے۔ وہ مشین لرننگ، ڈیپ لرننگ اور اینڈ ٹو اینڈ ایم ایل سلوشنز پر فوکس کرتا ہے۔
 کارنی جینن NXP کے ڈیٹا پورٹ فولیو میں ایک پروجیکٹ لیڈ ہے جو ڈیٹا سینٹرک بننے کی طرف اس کی ڈیجیٹل تبدیلی میں تنظیم کی مدد کرتا ہے۔
کارنی جینن NXP کے ڈیٹا پورٹ فولیو میں ایک پروجیکٹ لیڈ ہے جو ڈیٹا سینٹرک بننے کی طرف اس کی ڈیجیٹل تبدیلی میں تنظیم کی مدد کرتا ہے۔
 بارٹ زیمن NXP-CTO میں ڈیٹا اور تجزیات کا شوق رکھنے والا ایک حکمت عملی ہے جہاں وہ مزید ترقی اور جدت کے لیے بہتر ڈیٹا پر مبنی فیصلوں کے لیے گاڑی چلا رہا ہے۔
بارٹ زیمن NXP-CTO میں ڈیٹا اور تجزیات کا شوق رکھنے والا ایک حکمت عملی ہے جہاں وہ مزید ترقی اور جدت کے لیے بہتر ڈیٹا پر مبنی فیصلوں کے لیے گاڑی چلا رہا ہے۔
 احسن علی ایمیزون مشین لرننگ سلوشنز لیب میں ایک اپلائیڈ سائنٹسٹ ہے، جہاں وہ جدید ترین AI/ML تکنیکوں کا استعمال کرتے ہوئے ان کے فوری اور مہنگے مسائل کو حل کرنے کے لیے مختلف ڈومینز کے صارفین کے ساتھ کام کرتا ہے۔
احسن علی ایمیزون مشین لرننگ سلوشنز لیب میں ایک اپلائیڈ سائنٹسٹ ہے، جہاں وہ جدید ترین AI/ML تکنیکوں کا استعمال کرتے ہوئے ان کے فوری اور مہنگے مسائل کو حل کرنے کے لیے مختلف ڈومینز کے صارفین کے ساتھ کام کرتا ہے۔
 Yifu Hu ایمیزون مشین لرننگ سلوشنز لیب میں ایک اپلائیڈ سائنٹسٹ ہے، جہاں وہ مختلف صنعتوں میں صارفین کے کاروباری مسائل کو حل کرنے کے لیے تخلیقی ایم ایل حل تیار کرنے میں مدد کرتا ہے۔
Yifu Hu ایمیزون مشین لرننگ سلوشنز لیب میں ایک اپلائیڈ سائنٹسٹ ہے، جہاں وہ مختلف صنعتوں میں صارفین کے کاروباری مسائل کو حل کرنے کے لیے تخلیقی ایم ایل حل تیار کرنے میں مدد کرتا ہے۔
 مہدی نوری۔ ایمیزون ایم ایل سلوشنز لیب میں ایک اپلائیڈ سائنس مینیجر ہے، جہاں وہ مختلف صنعتوں میں بڑی تنظیموں کے لیے ایم ایل سلوشنز تیار کرنے میں مدد کرتا ہے اور انرجی ورٹیکل کی رہنمائی کرتا ہے۔ وہ صارفین کو ان کے پائیداری کے اہداف حاصل کرنے میں مدد کرنے کے لیے AI/ML استعمال کرنے کے بارے میں پرجوش ہے۔
مہدی نوری۔ ایمیزون ایم ایل سلوشنز لیب میں ایک اپلائیڈ سائنس مینیجر ہے، جہاں وہ مختلف صنعتوں میں بڑی تنظیموں کے لیے ایم ایل سلوشنز تیار کرنے میں مدد کرتا ہے اور انرجی ورٹیکل کی رہنمائی کرتا ہے۔ وہ صارفین کو ان کے پائیداری کے اہداف حاصل کرنے میں مدد کرنے کے لیے AI/ML استعمال کرنے کے بارے میں پرجوش ہے۔
 حذیفہ رنگ والا AIRE، AWS میں ایک سینئر اپلائیڈ سائنس مینیجر ہے۔ وہ سائنس دانوں اور انجینئروں کی ایک ٹیم کی رہنمائی کرتا ہے تاکہ ڈیٹا اثاثوں کی مشین لرننگ پر مبنی دریافت کو قابل بنایا جاسکے۔ اس کی تحقیقی دلچسپیاں ذمہ دار اے آئی، فیڈریٹڈ لرننگ اور ہیلتھ کیئر اور لائف سائنسز میں ایم ایل کی ایپلی کیشنز میں ہیں۔
حذیفہ رنگ والا AIRE، AWS میں ایک سینئر اپلائیڈ سائنس مینیجر ہے۔ وہ سائنس دانوں اور انجینئروں کی ایک ٹیم کی رہنمائی کرتا ہے تاکہ ڈیٹا اثاثوں کی مشین لرننگ پر مبنی دریافت کو قابل بنایا جاسکے۔ اس کی تحقیقی دلچسپیاں ذمہ دار اے آئی، فیڈریٹڈ لرننگ اور ہیلتھ کیئر اور لائف سائنسز میں ایم ایل کی ایپلی کیشنز میں ہیں۔
- SEO سے چلنے والا مواد اور PR کی تقسیم۔ آج ہی بڑھا دیں۔
- پلیٹو بلاک چین۔ Web3 Metaverse Intelligence. علم میں اضافہ۔ یہاں تک رسائی حاصل کریں۔
- ماخذ: https://aws.amazon.com/blogs/machine-learning/predicting-new-and-existing-product-sales-in-semiconductors-using-amazon-forecast/

