گہری سیکھنے میں غوطہD2L.ai) ایک اوپن سورس درسی کتاب ہے جو گہری سیکھنے کو ہر کسی کے لیے قابل رسائی بناتی ہے۔ اس میں PyTorch، JAX، TensorFlow، اور MXNet میں خود ساختہ کوڈ کے ساتھ انٹرایکٹو Jupyter نوٹ بکس کے ساتھ ساتھ حقیقی دنیا کی مثالیں، نمائشی اعداد و شمار اور ریاضی شامل ہیں۔ اب تک، D2L کو دنیا بھر کی 400 سے زیادہ یونیورسٹیوں نے اپنایا ہے، جیسے یونیورسٹی آف کیمبرج، سٹینفورڈ یونیورسٹی، میساچوسٹس انسٹی ٹیوٹ آف ٹیکنالوجی، کارنیگی میلن یونیورسٹی، اور سنگھوا یونیورسٹی۔ یہ کام چینی، جاپانی، کورین، پرتگالی، ترکی اور ویتنامی زبانوں میں بھی دستیاب کرایا گیا ہے، ہسپانوی اور دیگر زبانوں کو شروع کرنے کے منصوبے کے ساتھ۔
ایک آن لائن کتاب رکھنا ایک چیلنجنگ کوشش ہے جو مسلسل اپ ٹو ڈیٹ رکھی جاتی ہے، متعدد مصنفین کے ذریعہ لکھی جاتی ہے، اور متعدد زبانوں میں دستیاب ہوتی ہے۔ اس پوسٹ میں، ہم ایک حل پیش کرتے ہیں جو D2L.ai استعمال کرکے اس چیلنج سے نمٹنے کے لیے استعمال کیا جاتا ہے۔ ایکٹو کسٹم ٹرانسلیشن (ACT) کی خصوصیت of ایمیزون ترجمہ اور کثیر لسانی خودکار ترجمے کی پائپ لائن کی تعمیر۔
ہم استعمال کرنے کا طریقہ دکھاتے ہیں۔ AWS مینجمنٹ کنسول اور Amazon Translate public API خودکار مشین بیچ ترجمہ فراہم کرنے کے لیے، اور دو زبانوں کے جوڑوں کے درمیان ترجمہ کا تجزیہ کریں: انگریزی اور چینی، اور انگریزی اور ہسپانوی۔ ترجمہ کے معیار اور کارکردگی کو یقینی بنانے کے لیے اس خودکار ترجمے کی پائپ لائن میں Amazon Translate کا استعمال کرتے وقت ہم بہترین طریقوں کی بھی تجویز کرتے ہیں۔
حل جائزہ
ہم نے Amazon Translate میں ACT خصوصیت کا استعمال کرتے ہوئے متعدد زبانوں کے لیے خودکار ترجمے کی پائپ لائنیں بنائی ہیں۔ ACT آپ کو اڑتے وقت ترجمے کی پیداوار کو حسب ضرورت بنانے کی اجازت دیتا ہے۔ متوازی ڈیٹا. متوازی ڈیٹا ایک ماخذ کی زبان میں متنی مثالوں اور ایک یا زیادہ ہدف کی زبانوں میں مطلوبہ ترجمے پر مشتمل ہوتا ہے۔ ترجمہ کے دوران، ACT خودکار طور پر متوازی ڈیٹا سے سب سے زیادہ متعلقہ حصوں کا انتخاب کرتا ہے اور ان سیگمنٹ جوڑوں کی بنیاد پر فلائی پر ترجمہ ماڈل کو اپ ڈیٹ کرتا ہے۔ اس کے نتیجے میں ایسے ترجمہ ہوتے ہیں جو متوازی ڈیٹا کے انداز اور مواد سے بہتر طور پر میل کھاتے ہیں۔
فن تعمیر متعدد ذیلی پائپ لائنوں پر مشتمل ہے۔ ہر ذیلی پائپ لائن ایک زبان کا ترجمہ سنبھالتی ہے جیسے انگریزی سے چینی، انگریزی سے ہسپانوی، وغیرہ۔ متوازی طور پر متعدد ترجمے کی ذیلی پائپ لائنوں پر کارروائی کی جا سکتی ہے۔ ہر ذیلی پائپ لائن میں، ہم سب سے پہلے Amazon Translate میں متوازی ڈیٹا تیار کرتے ہیں جو انسانی ترجمہ شدہ D2L کتابوں سے درج ترجمے کی مثالوں کے اعلیٰ معیار کے ڈیٹاسیٹ کا استعمال کرتے ہیں۔ اس کے بعد ہم رن ٹائم پر اپنی مرضی کے مطابق مشین ٹرانسلیشن آؤٹ پٹ تیار کرتے ہیں، جو بہتر معیار اور درستگی حاصل کرتا ہے۔
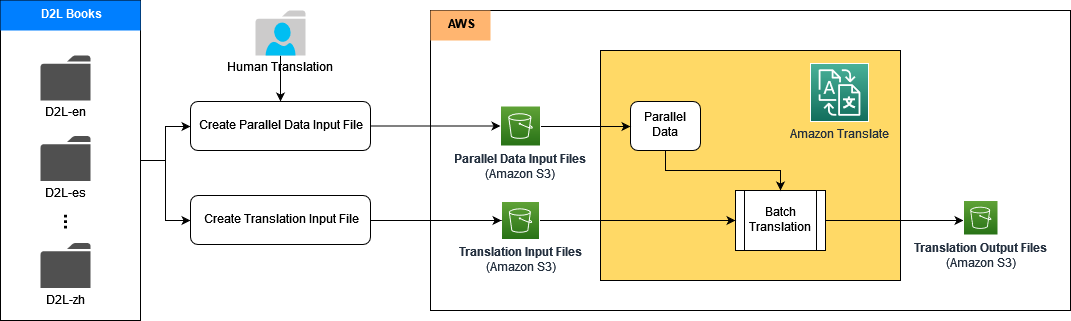
مندرجہ ذیل حصوں میں، ہم یہ ظاہر کرتے ہیں کہ ایمیزون ٹرانسلیٹ کا استعمال کرتے ہوئے ہر ٹرانسلیشن پائپ لائن کو ACT کے ساتھ کیسے بنایا جائے۔ ایمیزون سیج میکر اور ایمیزون سادہ اسٹوریج سروس (ایمیزون S3)۔
سب سے پہلے، ہم سورس دستاویزات، حوالہ جاتی دستاویزات، اور متوازی ڈیٹا ٹریننگ سیٹ کو S3 بالٹی میں ڈالتے ہیں۔ پھر ہم Amazon Translate Public APIs کا استعمال کرتے ہوئے ترجمے کے عمل کو چلانے کے لیے SageMaker میں Jupyter نوٹ بکس بناتے ہیں۔
شرائط
اس پوسٹ میں درج مراحل پر عمل کرنے کے لیے، یقینی بنائیں کہ آپ کے پاس درج ذیل کے ساتھ AWS اکاؤنٹ ہے:
- تک رسائی AWS شناخت اور رسائی کا انتظام (IAM) کردار اور پالیسی کی ترتیب کے لیے
- Amazon Translate، SageMaker، اور Amazon S3 تک رسائی
- ماخذ دستاویزات، حوالہ جاتی دستاویزات، متوازی ڈیٹا ڈیٹاسیٹ، اور ترجمہ کے آؤٹ پٹ کو ذخیرہ کرنے کے لیے ایک S3 بالٹی
ACT کے ساتھ Amazon Translate کے لیے IAM کردار اور پالیسیاں بنائیں
ہمارے IAM کردار کو Amazon Translate کے لیے حسب ضرورت اعتماد کی پالیسی پر مشتمل ہونا ضروری ہے:
اس کردار کے پاس اجازت کی پالیسی بھی ہونی چاہیے جو Amazon S3 میں ان پٹ فولڈر اور ذیلی فولڈرز تک Amazon Translate کو پڑھنے کی رسائی فراہم کرتی ہے جس میں ماخذ کی دستاویزات ہیں، اور آؤٹ پٹ S3 بالٹی اور فولڈر کو پڑھنے/لکھنے تک رسائی فراہم کرتی ہے جس میں ترجمہ شدہ دستاویزات شامل ہیں:
ترجمے کے کاموں کے لیے SageMaker میں Jupyter نوٹ بک چلانے کے لیے، ہمیں SageMaker کے عمل درآمد کے لیے ایک ان لائن اجازت کی پالیسی دینے کی ضرورت ہے۔ یہ کردار ایمیزون ٹرانسلیٹ سروس رول کو SageMaker کو منتقل کرتا ہے جو SageMaker نوٹ بک کو نامزد کردہ S3 بالٹیوں میں ماخذ اور ترجمہ شدہ دستاویزات تک رسائی حاصل کرنے کی اجازت دیتا ہے:
متوازی ڈیٹا ٹریننگ کے نمونے تیار کریں۔
ACT میں متوازی ڈیٹا کو متنی مثال کے جوڑوں کی فہرست پر مشتمل ایک ان پٹ فائل کے ذریعے تربیت دینے کی ضرورت ہے، مثال کے طور پر، ماخذ زبان (انگریزی) اور ہدف کی زبان (چینی) کا ایک جوڑا۔ ان پٹ فائل TMX، CSV، یا TSV فارمیٹ میں ہو سکتی ہے۔ درج ذیل اسکرین شاٹ CSV ان پٹ فائل کی مثال دکھاتا ہے۔ پہلا کالم ماخذ زبان کا ڈیٹا ہے (انگریزی میں)، اور دوسرا کالم ہدف زبان کا ڈیٹا (چینی میں) ہے۔ درج ذیل مثال D2L-en کتاب اور D2L-zh کتاب سے نکالی گئی ہے۔

Amazon Translate میں حسب ضرورت متوازی ڈیٹا ٹریننگ انجام دیں۔
سب سے پہلے، ہم S3 بالٹی اور فولڈرز ترتیب دیتے ہیں جیسا کہ درج ذیل اسکرین شاٹ میں دکھایا گیا ہے۔ دی source_data فولڈر ترجمہ سے پہلے ماخذ دستاویزات پر مشتمل ہے؛ بیچ ترجمے کے بعد تیار کردہ دستاویزات کو آؤٹ پٹ فولڈر میں ڈال دیا جاتا ہے۔ دی ParallelData فولڈر پچھلے مرحلے میں تیار کردہ متوازی ڈیٹا ان پٹ فائل رکھتا ہے۔
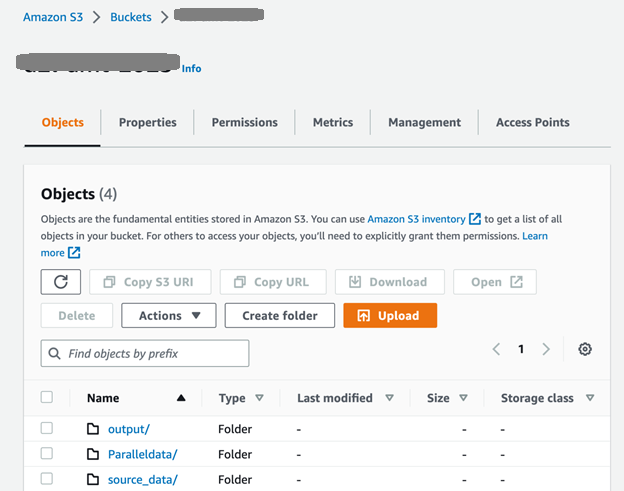
ان پٹ فائلوں کو اپ لوڈ کرنے کے بعد source_data فولڈر، ہم استعمال کر سکتے ہیں ParallelData API بنائیں ایمیزون ٹرانسلیٹ میں ڈیٹا بنانے کا متوازی کام چلانے کے لیے:
نئے تربیتی ڈیٹاسیٹس کے ساتھ موجودہ متوازی ڈیٹا کو اپ ڈیٹ کرنے کے لیے، ہم استعمال کر سکتے ہیں۔ UpdateParallelData API:
S3_BUCKET = “YOUR-S3_BUCKET-NAME”
pd_name = “pd-d2l-short_test_sentence_enzh_all”
pd_description = “Parallel Data for English to Chinese”
pd_fn = “d2l_short_test_sentence_enzh_all.csv”
response_t = translate_client.update_parallel_data( Name=pd_name, # pd_name is the parallel data name Description=pd_description, # pd_description is the parallel data description ParallelDataConfig={ 'S3Uri': 's3://'+S3_BUCKET+'/Paralleldata/'+pd_fn, # S3_BUCKET is the S3 bucket name defined in the previous step 'Format': 'CSV' },
)
print(pd_name, ": ", response_t['Status'], " updated.")
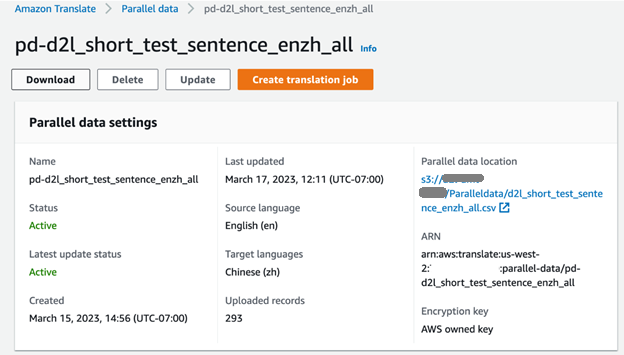
ہم Amazon Translate کنسول پر تربیتی ملازمت کی پیشرفت چیک کر سکتے ہیں۔ جب کام مکمل ہوجاتا ہے، متوازی ڈیٹا کی حیثیت اس طرح ظاہر ہوتی ہے۔ ایکٹو اور استعمال کے لیے تیار ہے۔
متوازی ڈیٹا کا استعمال کرتے ہوئے غیر مطابقت پذیر بیچ ترجمہ چلائیں۔
بیچ کا ترجمہ ایک ایسے عمل میں کیا جا سکتا ہے جہاں متعدد ماخذ دستاویزات کا خود بخود ٹارگٹ زبانوں میں دستاویزات میں ترجمہ ہو جاتا ہے۔ اس عمل میں سورس دستاویزات کو S3 بالٹی کے ان پٹ فولڈر میں اپ لوڈ کرنا، پھر لاگو کرنا شامل ہے۔ StartTextTranslationJob API Amazon Translate کا ایک غیر مطابقت پذیر ترجمہ کا کام شروع کرنے کے لیے:
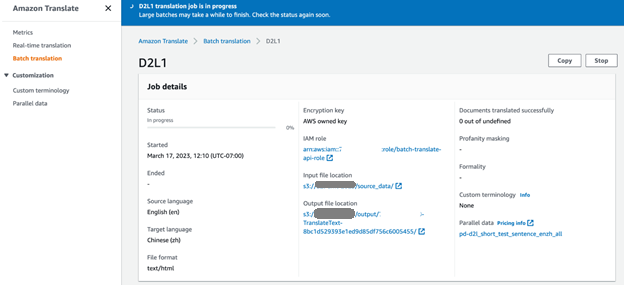
ہم نے بڑے پیمانے پر ترجمہ کے لیے D2L کتاب (D2L-en) سے انگریزی میں پانچ ماخذ دستاویزات کا انتخاب کیا۔ Amazon Translate کنسول پر، ہم ترجمے کے کام کی پیشرفت کی نگرانی کر سکتے ہیں۔ جب ملازمت کی حیثیت میں بدل جاتی ہے۔ مکمل، ہم S2 بالٹی آؤٹ پٹ فولڈر میں چینی (D3L-zh) میں ترجمہ شدہ دستاویزات تلاش کر سکتے ہیں۔
ترجمہ کے معیار کا اندازہ کریں۔
Amazon Translate میں ACT کی خصوصیت کی تاثیر کو ظاہر کرنے کے لیے، ہم نے Amazon Translate کے روایتی طریقے کو بھی متوازی ڈیٹا کے بغیر ایک ہی دستاویزات پر کارروائی کرنے کے لیے لاگو کیا، اور ACT کے ساتھ بیچ ترجمہ آؤٹ پٹ کے ساتھ آؤٹ پٹ کا موازنہ کیا۔ ہم نے دو طریقوں کے درمیان ترجمے کے معیار کو بینچ مارک کرنے کے لیے BLEU (BiLingual Evaluation Understudy) اسکور کا استعمال کیا۔ مشین ٹرانسلیشن آؤٹ پٹ کے معیار کو درست طریقے سے ماپنے کا واحد طریقہ یہ ہے کہ ماہر کا جائزہ لیا جائے اور معیار کو درجہ دیا جائے۔ تاہم، BLEU دو آؤٹ پٹ کے درمیان رشتہ دار معیار کی بہتری کا تخمینہ فراہم کرتا ہے۔ BLEU سکور عام طور پر 0-1 کے درمیان ایک نمبر ہوتا ہے۔ یہ حوالہ انسانی ترجمے سے مشینی ترجمہ کی مماثلت کا حساب لگاتا ہے۔ زیادہ اسکور قدرتی زبان کی سمجھ بوجھ (NLU) میں بہتر معیار کی نمائندگی کرتا ہے۔
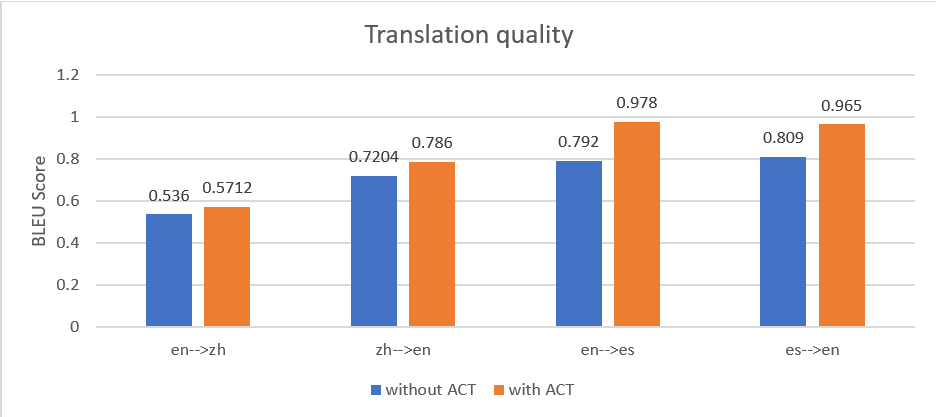
ہم نے چار پائپ لائنوں میں دستاویزات کے ایک سیٹ کا تجربہ کیا ہے: انگریزی میں چینی (en سے zh)، چینی میں انگریزی (zh to en)، انگریزی میں ہسپانوی (en سے es)، اور ہسپانوی سے انگریزی (es to en)۔ مندرجہ ذیل اعداد و شمار سے پتہ چلتا ہے کہ ACT کے ساتھ ترجمہ نے تمام ترجمے کی پائپ لائنوں میں ایک اعلی اوسط BLEU سکور پیدا کیا۔
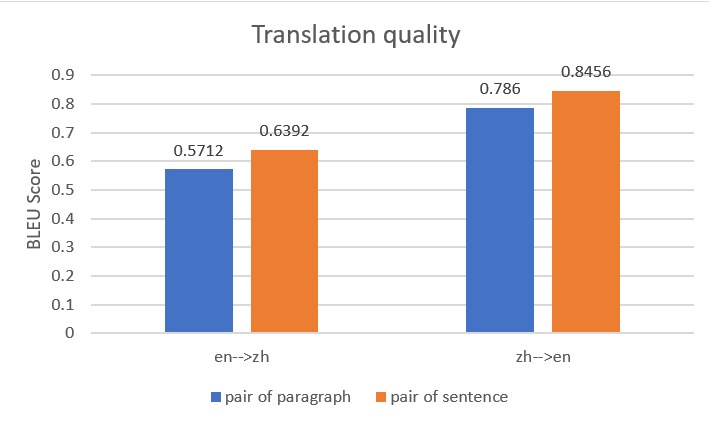
ہم نے یہ بھی مشاہدہ کیا کہ، متوازی ڈیٹا کے جوڑے جتنے زیادہ دانے دار ہوں گے، ترجمے کی کارکردگی اتنی ہی بہتر ہوگی۔ مثال کے طور پر، ہم پیراگراف کے جوڑے کے ساتھ درج ذیل متوازی ڈیٹا ان پٹ فائل کا استعمال کرتے ہیں، جس میں 10 اندراجات ہیں۔

اسی مواد کے لیے، ہم جملے کے جوڑے اور 16 اندراجات کے ساتھ درج ذیل متوازی ڈیٹا ان پٹ فائل کا استعمال کرتے ہیں۔

ہم نے Amazon Translate میں دو متوازی ڈیٹا انٹیٹیز بنانے کے لیے دونوں متوازی ڈیٹا ان پٹ فائلوں کا استعمال کیا، پھر ایک ہی ماخذ دستاویز کے ساتھ دو بیچ ٹرانسلیشن جابز تخلیق کیں۔ مندرجہ ذیل اعداد و شمار آؤٹ پٹ ترجمہ کا موازنہ کرتا ہے۔ یہ ظاہر کرتا ہے کہ جملے کے جوڑے کے ساتھ متوازی ڈیٹا کا استعمال کرنے والے آؤٹ پٹ نے پیراگراف کے جوڑے کے ساتھ متوازی ڈیٹا کا استعمال کرتے ہوئے انگریزی سے چینی ترجمہ اور چینی سے انگریزی ترجمہ دونوں کے لیے بہتر کارکردگی کا مظاہرہ کیا۔
اگر آپ ان بینچ مارک تجزیوں کے بارے میں مزید جاننے میں دلچسپی رکھتے ہیں، تو رجوع کریں۔ "ڈیپ انٹ لرننگ" کے لیے آٹو مشین ٹرانسلیشن اور سنکرونائزیشن۔
صاف کرو
مستقبل میں بار بار آنے والے اخراجات سے بچنے کے لیے، ہم تجویز کرتے ہیں کہ آپ اپنے بنائے ہوئے وسائل کو صاف کریں:
- Amazon Translate کنسول پر، اپنے بنائے ہوئے متوازی ڈیٹا کو منتخب کریں اور منتخب کریں۔ خارج کر دیں. متبادل کے طور پر ، آپ استعمال کر سکتے ہیں DeleteParallelData API یا AWS کمانڈ لائن انٹرفیس (AWS CLI) ڈیلیٹ-متوازی-ڈیٹا متوازی ڈیٹا کو حذف کرنے کا حکم۔
- S3 بالٹی کو حذف کریں۔ ماخذ اور حوالہ دستاویزات، ترجمہ شدہ دستاویزات، اور متوازی ڈیٹا ان پٹ فائلوں کی میزبانی کے لیے استعمال کیا جاتا ہے۔
- IAM کردار اور پالیسی کو حذف کریں۔ ہدایات کے لیے، رجوع کریں۔ کرداروں یا مثال کے پروفائلز کو حذف کرنا اور IAM پالیسیوں کو حذف کرنا.
نتیجہ
اس حل کے ساتھ، ہم ترجمے کے معیار کو برقرار رکھتے ہوئے اور متعدد زبانوں کو سپورٹ کرتے ہوئے انسانی مترجمین کے کام کے بوجھ کو 80% تک کم کرنا چاہتے ہیں۔ آپ اس حل کو اپنے ترجمے کے معیار اور کارکردگی کو بہتر بنانے کے لیے استعمال کر سکتے ہیں۔ ہم دیگر زبانوں کے لیے حل کے فن تعمیر اور ترجمے کے معیار کو مزید بہتر بنانے پر کام کر رہے ہیں۔
آپ کی رائے ہمیشہ خوش آئند ہے۔ براہ کرم تبصرے کے سیکشن میں اپنے خیالات اور سوالات چھوڑیں۔
مصنفین کے بارے میں
 یونفی بائی AWS میں ایک سینئر سولیوشن آرکیٹیکٹ ہے۔ AI/ML، ڈیٹا سائنس اور تجزیات میں پس منظر کے ساتھ، Yunfei صارفین کو کاروباری نتائج فراہم کرنے کے لیے AWS سروسز کو اپنانے میں مدد کرتا ہے۔ وہ AI/ML اور ڈیٹا اینالیٹکس سلوشنز ڈیزائن کرتا ہے جو پیچیدہ تکنیکی چیلنجوں پر قابو پاتے ہیں اور اسٹریٹجک مقاصد کو آگے بڑھاتے ہیں۔ Yunfei نے الیکٹرانک اور الیکٹریکل انجینئرنگ میں پی ایچ ڈی کی ہے۔ کام سے باہر، یونفی کو پڑھنے اور موسیقی کا شوق ہے۔
یونفی بائی AWS میں ایک سینئر سولیوشن آرکیٹیکٹ ہے۔ AI/ML، ڈیٹا سائنس اور تجزیات میں پس منظر کے ساتھ، Yunfei صارفین کو کاروباری نتائج فراہم کرنے کے لیے AWS سروسز کو اپنانے میں مدد کرتا ہے۔ وہ AI/ML اور ڈیٹا اینالیٹکس سلوشنز ڈیزائن کرتا ہے جو پیچیدہ تکنیکی چیلنجوں پر قابو پاتے ہیں اور اسٹریٹجک مقاصد کو آگے بڑھاتے ہیں۔ Yunfei نے الیکٹرانک اور الیکٹریکل انجینئرنگ میں پی ایچ ڈی کی ہے۔ کام سے باہر، یونفی کو پڑھنے اور موسیقی کا شوق ہے۔
 ریچل ہو AWS مشین لرننگ یونیورسٹی (MLU) میں ایک اپلائیڈ سائنسدان ہے۔ وہ ML آپریشنز (MLOps) اور Accelerator Computer Vision سمیت کچھ کورس ڈیزائنز کی رہنمائی کرتی رہی ہیں۔ ریچل ایک AWS سینئر اسپیکر ہے اور اس نے AWS re:Invent، NVIDIA GTC، KDD، اور MLOps سمٹ سمیت اعلیٰ کانفرنسوں میں بات کی ہے۔ AWS میں شامل ہونے سے پہلے، Rachel ایک مشین لرننگ انجینئر کے طور پر کام کرتی تھی جو قدرتی لینگویج پروسیسنگ ماڈل بناتی تھی۔ کام سے باہر، وہ یوگا، الٹی فریسبی، پڑھنے اور سفر سے لطف اندوز ہوتی ہے۔
ریچل ہو AWS مشین لرننگ یونیورسٹی (MLU) میں ایک اپلائیڈ سائنسدان ہے۔ وہ ML آپریشنز (MLOps) اور Accelerator Computer Vision سمیت کچھ کورس ڈیزائنز کی رہنمائی کرتی رہی ہیں۔ ریچل ایک AWS سینئر اسپیکر ہے اور اس نے AWS re:Invent، NVIDIA GTC، KDD، اور MLOps سمٹ سمیت اعلیٰ کانفرنسوں میں بات کی ہے۔ AWS میں شامل ہونے سے پہلے، Rachel ایک مشین لرننگ انجینئر کے طور پر کام کرتی تھی جو قدرتی لینگویج پروسیسنگ ماڈل بناتی تھی۔ کام سے باہر، وہ یوگا، الٹی فریسبی، پڑھنے اور سفر سے لطف اندوز ہوتی ہے۔
 واٹسن سریواتھسن AWS کی قدرتی زبان کی پروسیسنگ سروس، Amazon Translate کے پرنسپل پروڈکٹ مینیجر ہیں۔ اختتام ہفتہ پر، آپ اسے بحر الکاہل کے شمال مغرب میں باہر تلاش کرتے ہوئے پائیں گے۔
واٹسن سریواتھسن AWS کی قدرتی زبان کی پروسیسنگ سروس، Amazon Translate کے پرنسپل پروڈکٹ مینیجر ہیں۔ اختتام ہفتہ پر، آپ اسے بحر الکاہل کے شمال مغرب میں باہر تلاش کرتے ہوئے پائیں گے۔
- SEO سے چلنے والا مواد اور PR کی تقسیم۔ آج ہی بڑھا دیں۔
- ای وی ایم فنانس۔ وکندریقرت مالیات کے لیے متحد انٹرفیس۔ یہاں تک رسائی حاصل کریں۔
- کوانٹم میڈیا گروپ۔ آئی آر/پی آر ایمپلیفائیڈ۔ یہاں تک رسائی حاصل کریں۔
- پلیٹوآئ اسٹریم۔ ویب 3 ڈیٹا انٹیلی جنس۔ علم میں اضافہ۔ یہاں تک رسائی حاصل کریں۔
- ماخذ: https://aws.amazon.com/blogs/machine-learning/build-a-multilingual-automatic-translation-pipeline-with-amazon-translate-active-custom-translation/

