Розмовні помічники штучного інтелекту (ШІ) створені для надання точних відповідей у режимі реального часу за допомогою інтелектуальної маршрутизації запитів до найбільш підходящих функцій ШІ. З генеративними службами штучного інтелекту AWS, такими як Amazon Bedrock, розробники можуть створювати системи, які кваліфіковано керують запитами користувачів і відповідають на них. Amazon Bedrock — це повністю керований сервіс, який пропонує вибір високопродуктивних базових моделей (FM) від провідних компаній штучного інтелекту, таких як AI21 Labs, Anthropic, Cohere, Meta, Stability AI і Amazon, використовуючи єдиний API разом із широким набором можливості, необхідні для створення генеративних програм ШІ з безпекою, конфіденційністю та відповідальним ШІ.
У цьому дописі оцінюються два основні підходи до розробки помічників ШІ: використання керованих служб, таких як Агенти Amazon Bedrock, а також використання технологій з відкритим кодом, як-от LangChain. Ми досліджуємо переваги та труднощі кожного з них, щоб ви могли обрати шлях, який найбільше відповідає вашим потребам.
Що таке AI-помічник?
Помічник штучного інтелекту – це інтелектуальна система, яка розуміє запити природною мовою та взаємодіє з різними інструментами, джерелами даних і API для виконання завдань або отримання інформації від імені користувача. Ефективні помічники ШІ володіють такими ключовими можливостями:
- Обробка природної мови (NLP) і розмовний потік
- Інтеграція бази знань і семантичний пошук для розуміння та отримання відповідної інформації на основі нюансів контексту розмови
- Запуск завдань, таких як запити до бази даних і настроювані AWS Lambda Функції
- Обробка спеціалізованих розмов і запитів користувачів
Ми демонструємо переваги помічників ШІ на прикладі керування пристроями Інтернету речей (IoT). У цьому випадку використання ШІ може допомогти технікам ефективно керувати обладнанням за допомогою команд, які отримують дані або автоматизують завдання, оптимізуючи операції на виробництві.
Підхід агентів Amazon Bedrock
Агенти Amazon Bedrock дозволяє створювати генеративні програми штучного інтелекту, які можуть виконувати багатоетапні завдання в системах і джерелах даних компанії. Він пропонує такі ключові можливості:
- Автоматичне створення підказок із інструкцій, деталей API та інформації про джерело даних, заощаджуючи тижні оперативних інженерних зусиль
- Retrieval Augmented Generation (RAG) для безпечного підключення агентів до джерел даних компанії та надання відповідних відповідей
- Оркестровка та виконання багатоетапних завдань шляхом розбиття запитів на логічні послідовності та виклику необхідних API
- Видимість міркувань агента за допомогою трасування ланцюга думок (CoT), що дозволяє виявляти неполадки та керувати поведінкою моделі
- Інженерні можливості підказки для зміни автоматично створеного шаблону підказки для посиленого контролю над агентами
Ви можете використовувати агенти для Amazon Bedrock і Бази знань для Amazon Bedrock створювати та розгортати помічників ШІ для складних випадків використання маршрутизації. Вони забезпечують стратегічну перевагу для розробників і організацій, спрощуючи управління інфраструктурою, покращуючи масштабованість, покращуючи безпеку та зменшуючи недиференційований важкий підйом. Вони також дозволяють спростити код прикладного рівня, оскільки логіка маршрутизації, векторизація та пам’ять повністю керуються.
Огляд рішення
Це рішення представляє розмовний помічник зі штучним інтелектом, призначений для керування пристроями Інтернету речей і операцій під час використання Claude v2.1 від Anthropic на Amazon Bedrock. Основні функції помічника AI регулюються комплексним набором інструкцій, відомих як a системна підказка, яка окреслює його можливості та сфери знань. Ця інструкція гарантує, що помічник зі штучним інтелектом може виконувати широкий спектр завдань, від керування інформацією про пристрій до виконання операційних команд.
Оснащений цими можливостями, як описано в системному запиті, помічник AI дотримується структурованого робочого процесу, щоб відповідати на запитання користувачів. На наступному малюнку показано візуальне представлення цього робочого циклу, ілюструючи кожен крок від початкової взаємодії користувача до остаточної відповіді.

Робочий процес складається з наступних кроків:
- Процес починається, коли користувач просить помічника виконати завдання; наприклад, запит на максимальну кількість точок даних для певного пристрою IoT
device_xxx. Цей введений текст фіксується та надсилається до помічника ШІ. - Помічник AI інтерпретує введений користувачем текст. Він використовує надану історію розмов, групи дій і бази знань, щоб зрозуміти контекст і визначити необхідні завдання.
- Після аналізу та розуміння намірів користувача помічник ШІ визначає завдання. Це базується на інструкціях, які інтерпретуються помічником відповідно до системної підказки та введення користувача.
- Потім завдання запускаються через серію викликів API. Це робиться за допомогою ReAct підказка, яка розбиває завдання на серію кроків, які обробляються послідовно:
- Для перевірки показників пристрою ми використовуємо
check-device-metricsгрупа дій, яка включає виклик API лямбда-функцій, які потім запитують Амазонка Афіна для запитуваних даних. - Для прямих дій пристрою, таких як запуск, зупинка або перезавантаження, ми використовуємо
action-on-deviceгрупа дій, яка викликає лямбда-функцію. Ця функція ініціює процес, який надсилає команди на пристрій IoT. Для цієї публікації функція Lambda надсилає сповіщення за допомогою Простий сервіс електронної пошти Amazon (Amazon SES). - Ми використовуємо бази знань для Amazon Bedrock, щоб отримати історичні дані, які зберігаються як вбудовані в Служба Amazon OpenSearch векторна база даних.
- Для перевірки показників пристрою ми використовуємо
- Після виконання завдань Amazon Bedrock FM генерує остаточну відповідь і повертає її користувачеві.
- Агенти для Amazon Bedrock автоматично зберігають інформацію за допомогою сеансу з відстеженням стану, щоб підтримувати ту саму розмову. Стан видаляється після закінчення настроюваного часу простою.
Технічний огляд
На наступній діаграмі показано архітектуру для розгортання помічника ШІ з агентами для Amazon Bedrock.
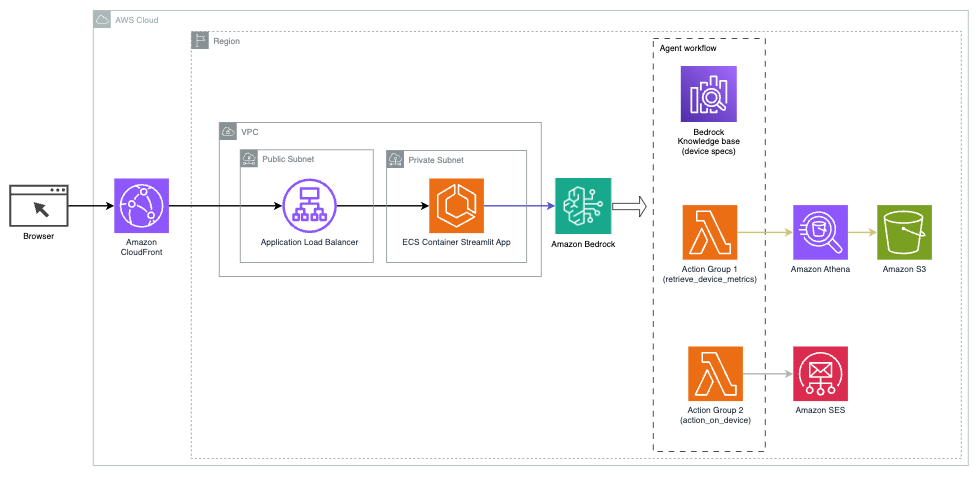
Він складається з таких ключових компонентів:
- Розмовний інтерфейс – Розмовний інтерфейс використовує Streamlit, бібліотеку Python з відкритим вихідним кодом, яка спрощує створення спеціальних, візуально привабливих веб-додатків для машинного навчання (ML) і науки про дані. Він розміщений на Служба еластичних контейнерів Amazon (Amazon ECS) с AWS Fargate, а доступ до нього здійснюється за допомогою балансувальника навантаження програми. Ви можете використовувати Fargate з Amazon ECS для запуску containers без необхідності керувати серверами, кластерами чи віртуальними машинами.
- Агенти Amazon Bedrock – Агенти для Amazon Bedrock завершують запити користувачів за допомогою ряду кроків міркування та відповідних дій на основі Підказка ReAct:
- Бази знань для Amazon Bedrock – Бази знань для Amazon Bedrock забезпечують повне керування КГР щоб надати помічнику ШІ доступ до ваших даних. У нашому випадку використання ми завантажили специфікації пристрою в Служба простого зберігання Amazon (Amazon S3) відро. Він служить джерелом даних для бази знань.
- Групи дій – Це визначені схеми API, які викликають певні функції Lambda для взаємодії з пристроями IoT та іншими службами AWS.
- Anthropic Claude v2.1 на Amazon Bedrock – Ця модель інтерпретує запити користувачів і організовує потік завдань.
- Amazon Titan Embeddings – Ця модель слугує моделлю вбудовування тексту, перетворюючи текст природною мовою — від окремих слів до складних документів — у числові вектори. Це забезпечує можливості векторного пошуку, дозволяючи системі семантично зіставляти запити користувача з найбільш відповідними записами бази знань для ефективного пошуку.
Рішення інтегровано з такими службами AWS, як Lambda для запуску коду у відповідь на виклики API, Athena для запитів до наборів даних, OpenSearch Service для пошуку в базах знань і Amazon S3 для зберігання. Ці служби працюють разом, щоб забезпечити бездоганний досвід керування операціями пристроїв IoT за допомогою команд природною мовою.
Переваги
Це рішення пропонує такі переваги:
- Складність реалізації:
- Потрібно менше рядків коду, оскільки агенти для Amazon Bedrock абстрагують більшу частину складності, що лежить в основі, зменшуючи зусилля на розробку
- Керування векторними базами даних, такими як OpenSearch Service, спрощено, оскільки бази знань для Amazon Bedrock обробляють векторизацію та зберігання
- Інтеграція з різними службами AWS більш оптимізована за допомогою попередньо визначених груп дій
- Досвід розробника:
- Консоль Amazon Bedrock забезпечує зручний інтерфейс для швидкої розробки, тестування та аналізу першопричин (RCA), покращуючи загальний досвід розробника
- Спритність і гнучкість:
- Агенти для Amazon Bedrock дозволяють безперебійно оновлювати новіші FM (наприклад, Claude 3.0), коли вони стають доступними, тож ваше рішення залишається в курсі останніх досягнень.
- Квотами й обмеженнями послуг керує AWS, що зменшує накладні витрати на моніторинг і масштабування інфраструктури
- Безпека:
- Amazon Bedrock — це повністю керований сервіс, який дотримується суворих стандартів безпеки та відповідності AWS, що потенційно спрощує перевірку організаційної безпеки
Хоча Агенти для Amazon Bedrock пропонують спрощене та кероване рішення для створення розмовних додатків ШІ, деякі організації можуть віддати перевагу підходу з відкритим кодом. У таких випадках ви можете використовувати такі фреймворки, як LangChain, які ми обговоримо в наступному розділі.
Підхід динамічної маршрутизації LangChain
LangChain — це фреймворк з відкритим вихідним кодом, який спрощує створення розмовного ШІ, дозволяючи інтегрувати великі мовні моделі (LLM) і можливості динамічної маршрутизації. За допомогою мови виразів LangChain (LCEL) розробники можуть визначати Маршрутизація, що дозволяє створювати недетерміновані ланцюжки, де вихідні дані попереднього кроку визначають наступний крок. Маршрутизація допомагає забезпечити структуру та послідовність у взаємодії з LLM.
У цій публікації ми використовуємо той самий приклад, що й помічник AI для керування пристроями IoT. Однак основна відмінність полягає в тому, що нам потрібно обробляти системні підказки окремо та розглядати кожен ланцюжок як окрему сутність. Ланцюжок маршрутизації визначає ланцюг призначення на основі введення користувача. Рішення приймається за підтримки LLM шляхом передачі системної підказки, історії чату та запитання користувача.
Огляд рішення
Наступна діаграма ілюструє робочий процес рішення динамічної маршрутизації.

Робочий процес складається з наступних кроків:
- Користувач задає запитання помічнику ШІ. Наприклад, «Які максимальні показники для пристрою 1009?»
- LLM оцінює кожне запитання разом з історією чату з тієї самої сесії, щоб визначити його характер і до якої предметної області воно відноситься (наприклад, SQL, дії, пошук або SME). LLM класифікує вхідні дані, а ланцюжок маршрутизації LCEL приймає ці вхідні дані.
- Ланцюжок маршрутизаторів вибирає ланцюжок призначення на основі вхідних даних, і LLM надає таке системне повідомлення:
LLM оцінює запитання користувача разом із історією чату, щоб визначити природу запиту та до якої теми він відноситься. Потім LLM класифікує вхідні дані та виводить відповідь JSON у такому форматі:
Ланцюг маршрутизаторів використовує цю відповідь JSON для виклику відповідного ланцюга призначення. Є чотири тематичні ланцюжки призначення, кожна з яких має власну системну підказку:
- Запити, пов’язані з SQL, надсилаються до ланцюга призначення SQL для взаємодії з базою даних. Ви можете використовувати LCEL для створення Ланцюжок SQL.
- Запитання, орієнтовані на дії, викликають настроюваний ланцюжок призначення Lambda для виконання операцій. За допомогою LCEL ви можете визначити свій власний спеціальна функція; у нашому випадку це функція для запуску попередньо визначеної функції Lambda для надсилання електронного листа з проаналізованим ідентифікатором пристрою. Прикладом введення користувачем може бути «Вимкнути пристрій 1009».
- Орієнтовані на пошук запити переходять до КГР ланцюг призначення для пошуку інформації.
- Запитання, пов’язані з малим і середнім бізнесом, надсилаються до ланцюга призначення для малого та середнього бізнесу/експертів, щоб отримати спеціалізовану інформацію.
- Кожен ланцюжок призначення приймає вхідні дані та запускає необхідні моделі або функції:
- Ланцюжок SQL використовує Athena для виконання запитів.
- Ланцюжок RAG використовує OpenSearch Service для семантичного пошуку.
- Спеціальний ланцюжок лямбда запускає функції лямбда для дій.
- Мережа SME/expert надає інформацію за допомогою моделі Amazon Bedrock.
- Відповіді кожного ланцюга призначення LLM формулюють у послідовні ідеї. Потім ця інформація доставляється користувачеві, завершуючи цикл запиту.
- Введені користувачем дані та відповіді зберігаються в Amazon DynamoDB щоб надати контекст LLM для поточного сеансу та минулих взаємодій. Тривалість збереження інформації в DynamoDB контролюється програмою.
Технічний огляд
Наступна діаграма ілюструє архітектуру рішення динамічної маршрутизації LangChain.
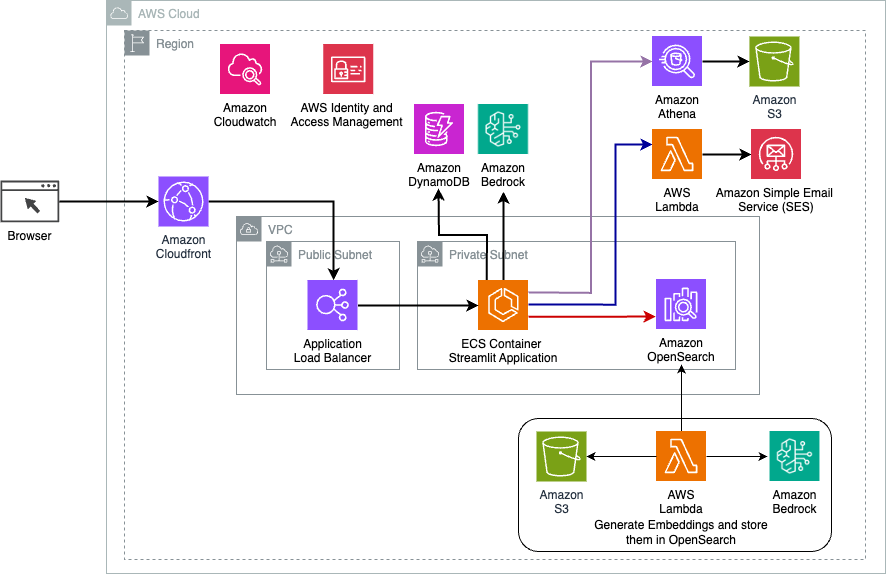
Веб-додаток побудовано на Streamlit, розміщеному на Amazon ECS за допомогою Fargate, і доступ до нього здійснюється за допомогою балансувальника навантаження програми. Ми використовуємо Claude v2.1 від Anthropic на Amazon Bedrock як LLM. Веб-додаток взаємодіє з моделлю за допомогою бібліотек LangChain. Він також взаємодіє з різними іншими сервісами AWS, такими як OpenSearch Service, Athena та DynamoDB, щоб задовольнити потреби кінцевих користувачів.
Переваги
Це рішення пропонує такі переваги:
- Складність реалізації:
- Незважаючи на те, що LangChain вимагає більше коду та спеціальної розробки, він забезпечує більшу гнучкість і контроль над логікою маршрутизації та інтеграцією з різними компонентами.
- Керування векторними базами даних, такими як OpenSearch Service, потребує додаткових зусиль з налаштування та налаштування. Процес векторизації реалізований у коді.
- Інтеграція зі службами AWS може включати більше спеціального коду та конфігурації.
- Досвід розробника:
- Підхід LangChain на основі Python і обширна документація можуть бути привабливими для розробників, які вже знайомі з Python і інструментами з відкритим кодом.
- Швидка розробка та налагодження може вимагати більше ручних зусиль порівняно з використанням консолі Amazon Bedrock.
- Спритність і гнучкість:
- LangChain підтримує широкий спектр LLM, дозволяючи вам перемикатися між різними моделями або постачальниками, сприяючи гнучкості.
- Природа LangChain з відкритим вихідним кодом дає змогу створювати покращення та налаштування, керовані спільнотою.
- Безпека:
- Як фреймворк із відкритим вихідним кодом, LangChain може вимагати більш ретельного аналізу безпеки та перевірки в організаціях, що потенційно може збільшити витрати.
Висновок
Розмовні помічники штучного інтелекту – це трансформаційні інструменти для оптимізації операцій і покращення взаємодії з користувачем. У цьому дописі досліджено два потужні підходи до використання служб AWS: керовані агенти для Amazon Bedrock і гнучка динамічна маршрутизація LangChain з відкритим кодом. Вибір між цими підходами залежить від вимог вашої організації, уподобань щодо розробки та бажаного рівня налаштування. Незалежно від обраного шляху, AWS дає вам змогу створювати інтелектуальних помічників AI, які революціонізують бізнес і взаємодію з клієнтами
Знайдіть код рішення та активи розгортання в нашому GitHub сховище, де ви можете виконати детальні кроки для кожного розмовного підходу ШІ.
Про авторів
 Амір Хакме є архітектором рішень AWS у Пенсільванії. Він співпрацює з незалежними постачальниками програмного забезпечення (ISV) у північно-східному регіоні, допомагаючи їм у розробці та створенні масштабованих і сучасних платформ у хмарі AWS. Експерт із ШІ/ML та генеративного ШІ, Амір допомагає клієнтам розкрити потенціал цих передових технологій. У вільний час він любить кататися на мотоциклі та проводити час із сім’єю.
Амір Хакме є архітектором рішень AWS у Пенсільванії. Він співпрацює з незалежними постачальниками програмного забезпечення (ISV) у північно-східному регіоні, допомагаючи їм у розробці та створенні масштабованих і сучасних платформ у хмарі AWS. Експерт із ШІ/ML та генеративного ШІ, Амір допомагає клієнтам розкрити потенціал цих передових технологій. У вільний час він любить кататися на мотоциклі та проводити час із сім’єю.
 Шерон Лі є архітектором рішень AI/ML в Amazon Web Services, що базується в Бостоні, і захоплюється розробкою та створенням програм Generative AI на AWS. Вона співпрацює з клієнтами, щоб використовувати сервіси AWS AI/ML для інноваційних рішень.
Шерон Лі є архітектором рішень AI/ML в Amazon Web Services, що базується в Бостоні, і захоплюється розробкою та створенням програм Generative AI на AWS. Вона співпрацює з клієнтами, щоб використовувати сервіси AWS AI/ML для інноваційних рішень.
 Кавсар Камал є старшим архітектором рішень Amazon Web Services із понад 15-річним досвідом роботи в сфері автоматизації інфраструктури та безпеки. Він допомагає клієнтам проектувати та створювати масштабовані рішення DevSecOps і AI/ML у хмарі.
Кавсар Камал є старшим архітектором рішень Amazon Web Services із понад 15-річним досвідом роботи в сфері автоматизації інфраструктури та безпеки. Він допомагає клієнтам проектувати та створювати масштабовані рішення DevSecOps і AI/ML у хмарі.
- Розповсюдження контенту та PR на основі SEO. Отримайте посилення сьогодні.
- PlatoData.Network Vertical Generative Ai. Додайте собі сили. Доступ тут.
- PlatoAiStream. Web3 Intelligence. Розширення знань. Доступ тут.
- ПлатонЕСГ. вуглець, CleanTech, Енергія, Навколишнє середовище, Сонячна, Поводження з відходами. Доступ тут.
- PlatoHealth. Розвідка про біотехнології та клінічні випробування. Доступ тут.
- джерело: https://aws.amazon.com/blogs/machine-learning/enhance-conversational-ai-with-advanced-routing-techniques-with-amazon-bedrock/

