อเมซอน SageMaker เป็นบริการแมชชีนเลิร์นนิง (ML) ที่มีการจัดการเต็มรูปแบบ ด้วย SageMaker นักวิทยาศาสตร์ข้อมูลและนักพัฒนาสามารถสร้างและฝึกโมเดล ML ได้อย่างรวดเร็วและง่ายดาย จากนั้นปรับใช้โดยตรงในสภาพแวดล้อมโฮสต์ที่พร้อมสำหรับการผลิต Sagemaker นำเสนออินสแตนซ์สมุดบันทึกการเขียน Jupyter แบบผสานรวมเพื่อให้เข้าถึงแหล่งข้อมูลของคุณได้ง่ายสำหรับการสำรวจและวิเคราะห์ คุณจึงไม่ต้องจัดการเซิร์ฟเวอร์ นอกจากนี้ยังมีอัลกอริธึม ML ทั่วไปที่ได้รับการปรับให้เหมาะสมเพื่อให้ทำงานได้อย่างมีประสิทธิภาพกับข้อมูลขนาดใหญ่มากในสภาพแวดล้อมแบบกระจาย
SageMaker ต้องการให้ข้อมูลการฝึกอบรมสำหรับโมเดล ML แสดงอยู่ใน Amazon Simple Storage Service (Amazon S3), Amazon Elastic File System (Amazon EFS) หรือ Amazon FSx for Luster (สำหรับข้อมูลเพิ่มเติม โปรดดูที่ Access Training Data). ในการฝึกโมเดลโดยใช้ข้อมูลที่เก็บไว้นอกบริการพื้นที่เก็บข้อมูลที่รองรับสามบริการ ก่อนอื่นต้องนำเข้าข้อมูลในบริการใดบริการหนึ่งเหล่านี้ (โดยทั่วไปคือ Amazon S3) สิ่งนี้จำเป็นต้องสร้างไปป์ไลน์ข้อมูล (โดยใช้เครื่องมือเช่น Amazon SageMaker ข้อมูล Wrangler) เพื่อย้ายข้อมูลไปยัง Amazon S3 อย่างไรก็ตาม แนวทางนี้อาจสร้างความท้าทายในการจัดการข้อมูลในแง่ของการจัดการวงจรชีวิตของสื่อจัดเก็บข้อมูลนี้ การสร้างการควบคุมการเข้าถึง การตรวจสอบข้อมูล และอื่นๆ ทั้งหมดนี้เพื่อจุดประสงค์ในการจัดเตรียมข้อมูลการฝึกอบรมในช่วงระยะเวลาของงานการฝึกอบรม ในสถานการณ์ดังกล่าว อาจเป็นที่ต้องการเพื่อให้ SageMaker สามารถเข้าถึงข้อมูลได้ในสื่อจัดเก็บข้อมูลชั่วคราวที่แนบมากับอินสแตนซ์การฝึกอบรมชั่วคราวโดยไม่ต้องใช้พื้นที่จัดเก็บข้อมูลระดับกลางใน Amazon S3
โพสต์นี้แสดงวิธีการใช้ เกล็ดหิมะ เป็นแหล่งข้อมูลและดาวน์โหลดข้อมูลโดยตรงจาก Snowflake ไปยังอินสแตนซ์งาน SageMaker Training
ภาพรวมโซลูชัน
เราใช้ ชุดข้อมูลที่อยู่อาศัยในแคลิฟอร์เนีย เป็นชุดข้อมูลการฝึกอบรมสำหรับโพสต์นี้ และฝึกโมเดล ML เพื่อทำนายค่าบ้านเฉลี่ยสำหรับแต่ละเขต เราเพิ่มข้อมูลนี้ลงใน Snowflake เป็นตารางใหม่ เราสร้างคอนเทนเนอร์การฝึกอบรมแบบกำหนดเองที่ดาวน์โหลดข้อมูลโดยตรงจากตาราง Snowflake ไปยังอินสแตนซ์การฝึกอบรม แทนที่จะดาวน์โหลดข้อมูลลงในบัคเก็ต S3 ก่อน หลังจากดาวน์โหลดข้อมูลลงในอินสแตนซ์การฝึกแล้ว สคริปต์การฝึกแบบกำหนดเองจะดำเนินการเตรียมข้อมูล จากนั้นฝึกโมเดล ML โดยใช้ ตัวประมาณค่า XGBoost. รหัสทั้งหมดสำหรับโพสต์นี้มีอยู่ใน repo GitHub.
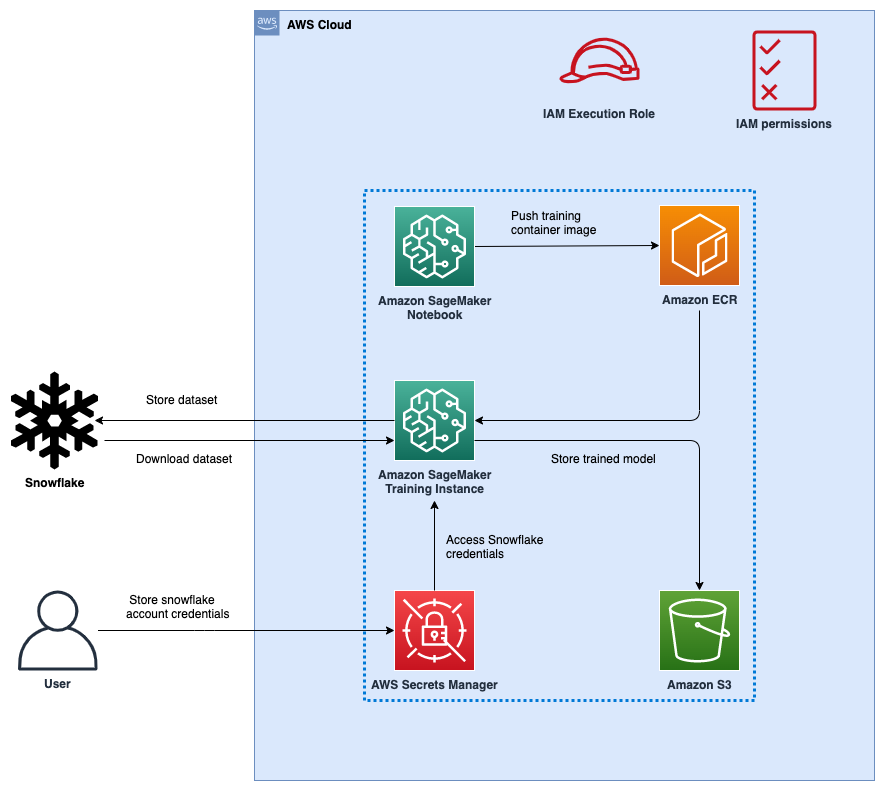
รูปที่ 1: สถาปัตยกรรม
รูปต่อไปนี้แสดงถึงสถาปัตยกรรมระดับสูงของโซลูชันที่เสนอเพื่อใช้ Snowflake เป็นแหล่งข้อมูลในการฝึกโมเดล ML ด้วย SageMaker
ขั้นตอนเวิร์กโฟลว์มีดังนี้:
- ตั้งค่าสมุดบันทึก SageMaker และ AWS Identity และการจัดการการเข้าถึง บทบาท (IAM) พร้อมการอนุญาตที่เหมาะสมเพื่อให้ SageMaker เข้าถึงได้ การลงทะเบียน Amazon Elastic Container (Amazon ECR), Secrets Manager และบริการอื่นๆ ภายในบัญชี AWS ของคุณ
- จัดเก็บข้อมูลรับรองบัญชี Snowflake ของคุณใน AWS Secrets Manager
- นำเข้าข้อมูลในตารางในบัญชี Snowflake ของคุณ
- สร้างอิมเมจคอนเทนเนอร์แบบกำหนดเองสำหรับการฝึกโมเดล ML และส่งไปยัง Amazon ECR
- เริ่มงาน SageMaker Training เพื่อฝึกอบรมโมเดล ML อินสแตนซ์การฝึกอบรมดึงข้อมูลประจำตัวของ Snowflake จาก Secrets Manager จากนั้นใช้ข้อมูลประจำตัวเหล่านี้เพื่อดาวน์โหลดชุดข้อมูลจาก Snowflake โดยตรง นี่เป็นขั้นตอนที่ขจัดความจำเป็นในการดาวน์โหลดข้อมูลลงในบัคเก็ต S3 ก่อน
- โมเดล ML ที่ผ่านการฝึกอบรมจะถูกจัดเก็บไว้ในบัคเก็ต S3
เบื้องต้น
ในการใช้โซลูชันที่ให้ไว้ในโพสต์นี้ คุณควรมี บัญชี AWSที่ บัญชีเกล็ดหิมะ และความคุ้นเคยกับ SageMaker
ตั้งค่า SageMaker Notebook และบทบาท IAM
เราใช้ AWS CloudFormation เพื่อสร้างสมุดบันทึก SageMaker ที่ชื่อว่า aws-aiml-blogpost-sagemaker-snowflake-example และบทบาท IAM ที่เรียกว่า SageMakerSnowFlakeExample. เลือก เรียกใช้ Stack สำหรับภูมิภาคที่คุณต้องการปรับใช้ทรัพยากร
จัดเก็บข้อมูลประจำตัวของ Snowflake ใน Secrets Manager
เก็บข้อมูลรับรอง Snowflake ของคุณเป็นความลับใน Secrets Manager สำหรับคำแนะนำเกี่ยวกับวิธีสร้างความลับ โปรดดูที่ Create an AWS Secrets Manager secret.
- บอกชื่อความลับ
snowflake_credentials. สิ่งนี้จำเป็นเนื่องจากรหัสในsnowflake-load-dataset.ipynbคาดว่าความลับจะเรียกว่า - สร้างความลับเป็นคู่คีย์-ค่าด้วยสองคีย์:
- ชื่อผู้ใช้ – ชื่อผู้ใช้ Snowflake ของคุณ
- รหัสผ่าน – รหัสผ่านที่เชื่อมโยงกับชื่อผู้ใช้ Snowflake ของคุณ
นำเข้าข้อมูลในตารางในบัญชี Snowflake ของคุณ
ในการรับข้อมูล ให้ทำตามขั้นตอนต่อไปนี้:
- บนคอนโซล SageMaker ให้เลือก โน๊ตบุ๊ค ในบานหน้าต่างนำทาง
- เลือกสมุดบันทึก aws-aiml-blogpost-sagemaker-snowflake-example และเลือก เปิด JupyterLab.

รูปที่ 2: เปิด JupyterLab
- Choose
snowflake-load-dataset.ipynbเพื่อเปิดใน JupyterLab สมุดบันทึกนี้จะนำเข้า ชุดข้อมูลที่อยู่อาศัยในแคลิฟอร์เนีย ไปที่โต๊ะเกล็ดหิมะ - ในสมุดบันทึก แก้ไขเนื้อหาของเซลล์ต่อไปนี้เพื่อแทนที่ค่าตัวยึดด้วยค่าที่ตรงกับบัญชีเกล็ดหิมะของคุณ:
- บนเมนูเรียกใช้ เลือก เรียกใช้ทุกเซลล์ เพื่อเรียกใช้รหัสในสมุดบันทึกนี้ การดำเนินการนี้จะดาวน์โหลดชุดข้อมูลภายในเครื่องลงในโน้ตบุ๊ก จากนั้นนำเข้าไปยังตาราง Snowflake
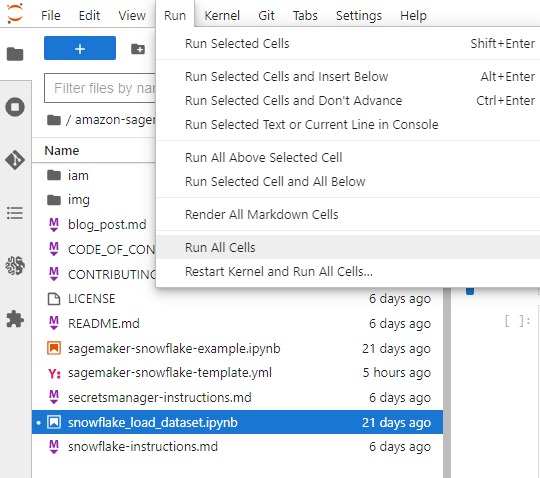
รูปที่ 3: โน้ตบุ๊กเรียกใช้เซลล์ทั้งหมด
ข้อมูลโค้ดต่อไปนี้ในสมุดบันทึกจะนำชุดข้อมูลเข้าสู่ Snowflake ดู snowflake-load-dataset.ipynb สมุดบันทึกสำหรับรหัสเต็ม
- ปิดสมุดบันทึกหลังจากที่เซลล์ทั้งหมดทำงานโดยไม่มีข้อผิดพลาดใดๆ ข้อมูลของคุณพร้อมใช้งานแล้วใน Snowflake ภาพหน้าจอต่อไปนี้แสดง
california_housingตารางที่สร้างขึ้นใน Snowflake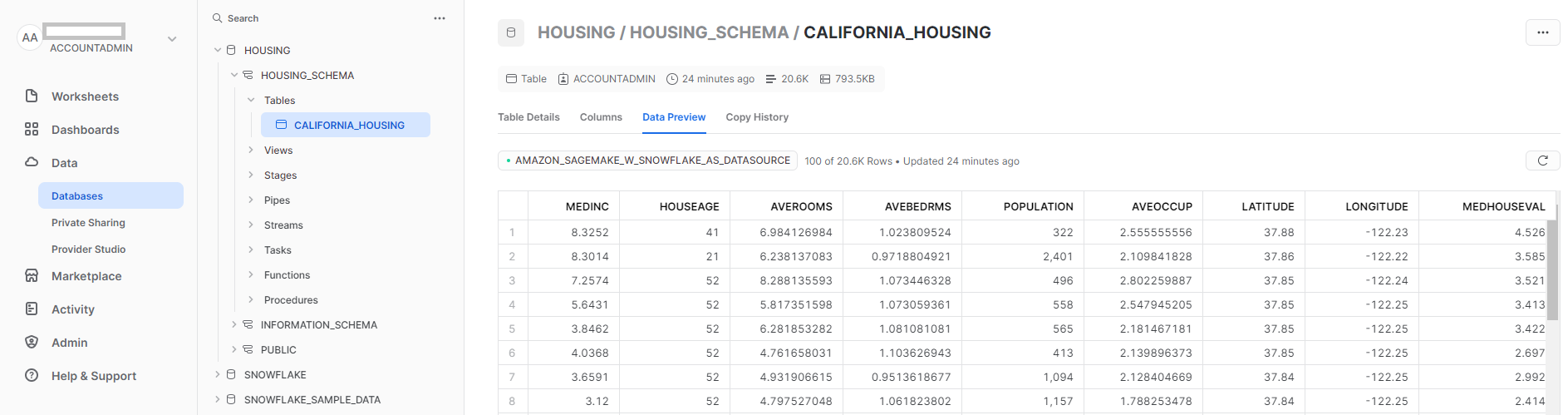
รูปที่ 4: ตารางเกล็ดหิมะ
เรียกใช้ sagemaker-snowflake-example.ipynb สมุดบันทึก
สมุดบันทึกนี้สร้างคอนเทนเนอร์การฝึกอบรมแบบกำหนดเองด้วยการเชื่อมต่อ Snowflake ดึงข้อมูลจาก Snowflake ไปยังพื้นที่จัดเก็บชั่วคราวของอินสแตนซ์การฝึกอบรมโดยไม่ต้องจัดเตรียมใน Amazon S3 และดำเนินการฝึกอบรมโมเดล XGBoost แบบกระจายข้อมูล (DDP) กับข้อมูล การฝึกอบรม DDP ไม่จำเป็นสำหรับการฝึกอบรมแบบจำลองในชุดข้อมูลขนาดเล็กดังกล่าว รวมไว้ที่นี่เพื่อเป็นภาพประกอบของคุณลักษณะ SageMaker ที่เพิ่งเปิดตัวเมื่อเร็วๆ นี้
รูปที่ 5: เปิดสมุดบันทึกตัวอย่าง SageMaker Snowflake
สร้างคอนเทนเนอร์แบบกำหนดเองสำหรับการฝึกอบรม
ตอนนี้เราสร้างคอนเทนเนอร์แบบกำหนดเองสำหรับงานฝึกอบรมโมเดล ML โปรดทราบว่าจำเป็นต้องมีการเข้าถึงรูทเพื่อสร้างคอนเทนเนอร์ Docker โน้ตบุ๊ก SageMaker นี้ถูกปรับใช้โดยเปิดใช้งานการเข้าถึงระดับรูท หากนโยบายองค์กรขององค์กรไม่อนุญาตให้เข้าถึงทรัพยากรระบบคลาวด์ในระดับราก คุณอาจต้องการใช้ไฟล์ Docker และเชลล์สคริปต์ต่อไปนี้เพื่อสร้างคอนเทนเนอร์ Docker ที่อื่น (เช่น แล็ปท็อปของคุณ) แล้วส่งไปยัง Amazon ECR เราใช้คอนเทนเนอร์ตามอิมเมจคอนเทนเนอร์ SageMaker XGBoost 246618743249.dkr.ecr.us-west-2.amazonaws.com/sagemaker-xgboost:1.5-1 ด้วยการเพิ่มเติมดังต่อไปนี้:
- พื้นที่ ตัวเชื่อมต่อเกล็ดหิมะสำหรับ Python เพื่อดาวน์โหลดข้อมูลจากตาราง Snowflake ไปยังอินสแตนซ์การฝึก
- สคริปต์ Python เพื่อเชื่อมต่อกับ Secrets Manager เพื่อดึงข้อมูลประจำตัวของ Snowflake
การใช้ตัวเชื่อมต่อ Snowflake และสคริปต์ Python ทำให้มั่นใจได้ว่าผู้ใช้ที่ใช้อิมเมจคอนเทนเนอร์นี้สำหรับการฝึกโมเดล ML ไม่จำเป็นต้องเขียนโค้ดนี้เป็นส่วนหนึ่งของสคริปต์การฝึก และสามารถใช้ฟังก์ชันนี้ที่มีอยู่แล้วได้
ต่อไปนี้คือ Dockerfile สำหรับคอนเทนเนอร์การฝึกอบรม:
อิมเมจคอนเทนเนอร์ถูกสร้างขึ้นและส่งไปยัง Amazon ECR ภาพนี้ใช้สำหรับการฝึกโมเดล ML
ฝึกโมเดล ML โดยใช้งาน SageMaker Training
หลังจากที่เราสร้างอิมเมจคอนเทนเนอร์และส่งไปยัง Amazon ECR เรียบร้อยแล้ว เราก็สามารถเริ่มใช้งานอิมเมจคอนเทนเนอร์สำหรับการฝึกโมเดลได้
- เราสร้างชุดสคริปต์ Python เพื่อดาวน์โหลดข้อมูลจาก Snowflake โดยใช้ ตัวเชื่อมต่อเกล็ดหิมะสำหรับ Pythonให้เตรียมข้อมูลแล้วใช้
XGBoost Regressorเพื่อฝึกโมเดล ML เป็นขั้นตอนการดาวน์โหลดข้อมูลโดยตรงไปยังอินสแตนซ์การฝึกอบรมเพื่อหลีกเลี่ยงการใช้ Amazon S3 เป็นที่จัดเก็บข้อมูลกลางสำหรับข้อมูลการฝึกอบรม - เราอำนวยความสะดวกในการฝึกอบรมแบบขนานข้อมูลแบบกระจายโดยให้รหัสการฝึกอบรมดาวน์โหลดชุดย่อยแบบสุ่มของข้อมูล เพื่อให้แต่ละอินสแตนซ์การฝึกอบรมดาวน์โหลดข้อมูลจาก Snowflake ในจำนวนที่เท่ากัน ตัวอย่างเช่น หากมีโหนดการฝึกสองโหนด แต่ละโหนดจะดาวน์โหลดตัวอย่างสุ่ม 50% ของแถวในตาราง Snowflake ดูรหัสต่อไปนี้:
- จากนั้นเราจะจัดเตรียมสคริปต์การฝึกอบรมให้กับ SageMaker SDK
Estimatorพร้อมกับไดเร็กทอรีต้นทางเพื่อให้สคริปต์ทั้งหมดที่เราสร้างสามารถจัดเตรียมให้กับคอนเทนเนอร์การฝึกอบรมได้ เมื่อรันงานการฝึกอบรมโดยใช้Estimator.fitวิธี:สำหรับข้อมูลเพิ่มเติมโปรดดูที่ เตรียมสคริปต์การฝึกอบรม Scikit-Learn.
- หลังจากการฝึกโมเดลเสร็จสิ้น โมเดลที่ผ่านการฝึกอบรมจะพร้อมใช้งานในรูปแบบ a
model.tar.gzไฟล์ในบัคเก็ตเริ่มต้นของ SageMaker สำหรับภูมิภาค:
ตอนนี้คุณสามารถใช้โมเดลที่ผ่านการฝึกอบรมเพื่อรับการอนุมานข้อมูลใหม่ได้แล้ว! สำหรับคำแนะนำ โปรดดูที่ สร้างจุดสิ้นสุดของคุณและปรับใช้โมเดลของคุณ
ทำความสะอาด
เพื่อหลีกเลี่ยงค่าใช้จ่ายในอนาคต ให้ลบทรัพยากร คุณสามารถทำได้โดยการลบเทมเพลต CloudFormation ที่ใช้สร้างบทบาท IAM และโน้ตบุ๊ก SageMaker

รูปที่ 6: การทำความสะอาด
คุณจะต้องลบทรัพยากร Snowflake ด้วยตนเองจากคอนโซล Snowflake
สรุป
ในโพสต์นี้ เราแสดงวิธีดาวน์โหลดข้อมูลที่จัดเก็บไว้ในตาราง Snowflake ไปยังอินสแตนซ์งาน SageMaker Training และฝึกโมเดล XGBoost โดยใช้คอนเทนเนอร์การฝึกแบบกำหนดเอง วิธีการนี้ช่วยให้เราผสานรวม Snowflake เป็นแหล่งข้อมูลโดยตรงกับโน้ตบุ๊ก SageMaker โดยไม่ต้องจัดฉากข้อมูลใน Amazon S3
เราขอแนะนำให้คุณเรียนรู้เพิ่มเติมโดยการสำรวจ Amazon SageMaker Python SDK และสร้างโซลูชันโดยใช้ตัวอย่างการใช้งานที่ให้ไว้ในโพสต์นี้และชุดข้อมูลที่เกี่ยวข้องกับธุรกิจของคุณ หากคุณมีคำถามหรือข้อเสนอแนะแสดงความคิดเห็น
เกี่ยวกับผู้แต่ง
 อมิตร อโรรา เป็นสถาปนิกผู้เชี่ยวชาญด้าน AI และ ML ที่ Amazon Web Services ช่วยให้ลูกค้าองค์กรใช้บริการแมชชีนเลิร์นนิงบนคลาวด์เพื่อปรับขนาดนวัตกรรมของตนได้อย่างรวดเร็ว เขายังเป็นอาจารย์เสริมในโปรแกรมวิทยาศาสตร์ข้อมูลและการวิเคราะห์ MS ที่มหาวิทยาลัยจอร์จทาวน์ในวอชิงตัน ดี.ซี
อมิตร อโรรา เป็นสถาปนิกผู้เชี่ยวชาญด้าน AI และ ML ที่ Amazon Web Services ช่วยให้ลูกค้าองค์กรใช้บริการแมชชีนเลิร์นนิงบนคลาวด์เพื่อปรับขนาดนวัตกรรมของตนได้อย่างรวดเร็ว เขายังเป็นอาจารย์เสริมในโปรแกรมวิทยาศาสตร์ข้อมูลและการวิเคราะห์ MS ที่มหาวิทยาลัยจอร์จทาวน์ในวอชิงตัน ดี.ซี
 ดิวิยา มูราลิดฮาราน เป็นสถาปนิกโซลูชันที่ Amazon Web Services เธอมีความกระตือรือร้นในการช่วยลูกค้าระดับองค์กรในการแก้ปัญหาทางธุรกิจด้วยเทคโนโลยี เธอสำเร็จการศึกษาระดับปริญญาโทด้านวิทยาการคอมพิวเตอร์จาก Rochester Institute of Technology นอกที่ทำงาน เธอใช้เวลาทำอาหาร ร้องเพลง และปลูกต้นไม้
ดิวิยา มูราลิดฮาราน เป็นสถาปนิกโซลูชันที่ Amazon Web Services เธอมีความกระตือรือร้นในการช่วยลูกค้าระดับองค์กรในการแก้ปัญหาทางธุรกิจด้วยเทคโนโลยี เธอสำเร็จการศึกษาระดับปริญญาโทด้านวิทยาการคอมพิวเตอร์จาก Rochester Institute of Technology นอกที่ทำงาน เธอใช้เวลาทำอาหาร ร้องเพลง และปลูกต้นไม้
 เซอร์เกย์ เออร์โมลิน เป็นสถาปนิกหลัก AIML Solutions ที่ AWS ก่อนหน้านี้ เขาเป็นสถาปนิกโซลูชันซอฟต์แวร์สำหรับการเรียนรู้เชิงลึก การวิเคราะห์ และเทคโนโลยีบิ๊กดาต้าที่ Intel ผู้คร่ำหวอดใน Silicon Valley ที่มีความหลงใหลในแมชชีนเลิร์นนิงและปัญญาประดิษฐ์ Sergey สนใจโครงข่ายประสาทเทียมมาตั้งแต่สมัยก่อนมี GPU เมื่อเขาใช้มันเพื่อทำนายพฤติกรรมการเสื่อมสภาพของผลึกควอตซ์และนาฬิกาอะตอมซีเซียมที่ Hewlett-Packard Sergey สำเร็จการศึกษาระดับ MSEE และ CS จาก Stanford และปริญญาตรีสาขาฟิสิกส์และวิศวกรรมเครื่องกลจาก California State University, Sacramento นอกเวลางาน เซอร์เกย์ชอบทำไวน์ เล่นสกี ขี่จักรยาน แล่นเรือใบ และดำน้ำลึก เซอร์เกย์ยังเป็นนักบินอาสาสมัครของ เที่ยวบินแองเจิล.
เซอร์เกย์ เออร์โมลิน เป็นสถาปนิกหลัก AIML Solutions ที่ AWS ก่อนหน้านี้ เขาเป็นสถาปนิกโซลูชันซอฟต์แวร์สำหรับการเรียนรู้เชิงลึก การวิเคราะห์ และเทคโนโลยีบิ๊กดาต้าที่ Intel ผู้คร่ำหวอดใน Silicon Valley ที่มีความหลงใหลในแมชชีนเลิร์นนิงและปัญญาประดิษฐ์ Sergey สนใจโครงข่ายประสาทเทียมมาตั้งแต่สมัยก่อนมี GPU เมื่อเขาใช้มันเพื่อทำนายพฤติกรรมการเสื่อมสภาพของผลึกควอตซ์และนาฬิกาอะตอมซีเซียมที่ Hewlett-Packard Sergey สำเร็จการศึกษาระดับ MSEE และ CS จาก Stanford และปริญญาตรีสาขาฟิสิกส์และวิศวกรรมเครื่องกลจาก California State University, Sacramento นอกเวลางาน เซอร์เกย์ชอบทำไวน์ เล่นสกี ขี่จักรยาน แล่นเรือใบ และดำน้ำลึก เซอร์เกย์ยังเป็นนักบินอาสาสมัครของ เที่ยวบินแองเจิล.
- เนื้อหาที่ขับเคลื่อนด้วย SEO และการเผยแพร่ประชาสัมพันธ์ รับการขยายวันนี้
- เพลโตบล็อคเชน Web3 Metaverse ข่าวกรอง ขยายความรู้. เข้าถึงได้ที่นี่.
- ที่มา: https://aws.amazon.com/blogs/machine-learning/use-snowflake-as-a-data-source-to-train-ml-models-with-amazon-sagemaker/

