Inom kapitalförvaltning måste portföljförvaltare noggrant övervaka företag i deras investeringsuniversum för att identifiera risker och möjligheter och vägleda investeringsbeslut. Det är enkelt att spåra direkta händelser som resultatrapporter eller kreditnedgraderingar – du kan ställa in varningar för att meddela chefer om nyheter som innehåller företagsnamn. Det är dock en utmaning att upptäcka andra och tredje ordningens effekter som uppstår från händelser hos leverantörer, kunder, partners eller andra enheter i ett företags ekosystem.
Till exempel skulle en störning i försörjningskedjan hos en nyckelleverantör sannolikt påverka nedströmstillverkare negativt. Eller förlusten av en toppkund för en stor kund innebär en efterfrågerisk för leverantören. Mycket ofta misslyckas sådana händelser att skapa rubriker med det berörda företaget direkt, men är fortfarande viktiga att uppmärksamma. I det här inlägget visar vi en automatiserad lösning som kombinerar kunskapsgrafer och generativ artificiell intelligens (AI) att yttra sådana risker genom att korsrefera relationskartor med nyheter i realtid.
I stora drag innebär detta två steg: För det första att bygga upp de intrikata relationerna mellan företag (kunder, leverantörer, direktörer) till en kunskapsgraf. För det andra, att använda denna grafdatabas tillsammans med generativ AI för att upptäcka andra och tredje ordningens effekter från nyhetshändelser. Till exempel kan den här lösningen markera att förseningar hos en reservdelsleverantör kan störa produktionen för efterföljande biltillverkare i en portfölj, även om ingen är direkt refererad.
Med AWS kan du distribuera den här lösningen i en serverlös, skalbar och helt händelsedriven arkitektur. Det här inlägget visar ett proof of concept som bygger på två viktiga AWS-tjänster som är väl lämpade för grafkunskapsrepresentation och naturlig språkbehandling: Amazon Neptunus och Amazonas berggrund. Neptune är en snabb, pålitlig, fullständigt hanterad grafdatabastjänst som gör det enkelt att bygga och köra applikationer som fungerar med mycket anslutna datauppsättningar. Amazon Bedrock är en helt hanterad tjänst som erbjuder ett urval av högpresterande grundmodeller (FM) från ledande AI-företag som AI21 Labs, Anthropic, Cohere, Meta, Stability AI och Amazon genom ett enda API, tillsammans med en bred uppsättning av förmåga att bygga generativa AI-applikationer med säkerhet, integritet och ansvarsfull AI.
Sammantaget visar den här prototypen konsten att vara möjlig med kunskapsgrafer och generativ AI – härleda signaler genom att koppla samman olika punkter. Nyckeln för investeringsproffs är möjligheten att hålla koll på utvecklingen närmare signalen och samtidigt undvika brus.
Bygg kunskapsgrafen
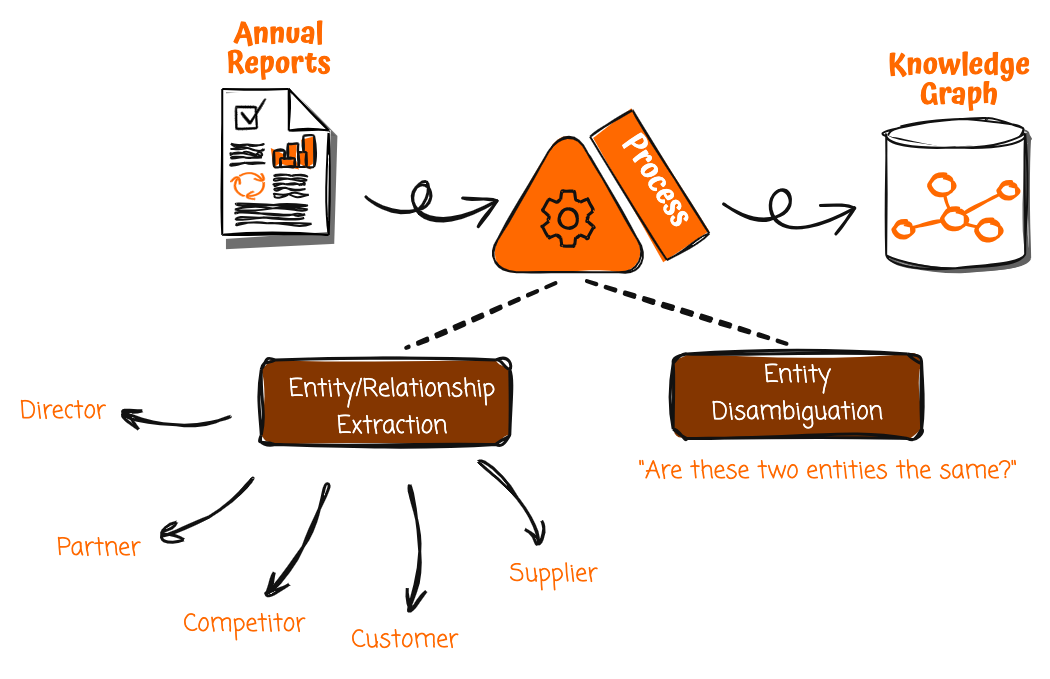
Det första steget i denna lösning är att bygga en kunskapsgraf, och en värdefull men ofta förbisedd datakälla för kunskapsgrafer är företagets årsredovisningar. Eftersom officiella företagspublikationer genomgår granskning innan de släpps, är informationen de innehåller sannolikt korrekt och tillförlitlig. Årsrapporter är dock skrivna i ett ostrukturerat format avsett för mänsklig läsning snarare än för maskinkonsumtion. För att frigöra deras potential behöver du ett sätt att systematiskt extrahera och strukturera den mängd fakta och relationer de innehåller.
Med generativa AI-tjänster som Amazon Bedrock har du nu möjlighet att automatisera denna process. Du kan ta en årsrapport och utlösa en bearbetningspipeline för att få in rapporten, dela upp den i mindre bitar och använda naturlig språkförståelse för att dra ut framträdande enheter och relationer.
Till exempel, en mening som säger att "[Företag A] utökade sin europeiska elleveransflotta med en beställning på 1,800 XNUMX elektriska skåpbilar från [Företag B]" skulle göra det möjligt för Amazon Bedrock att identifiera följande:
- [Företag A] som kund
- [Företag B] som leverantör
- Ett leverantörsförhållande mellan [Företag A] och [Företag B]
- Relationsinformation för "leverantör av elektriska leveransbilar"
Att extrahera sådana strukturerade data från ostrukturerade dokument kräver att man tillhandahåller noggrant utformade uppmaningar till stora språkmodeller (LLM) så att de kan analysera text för att dra ut enheter som företag och människor, såväl som relationer som kunder, leverantörer och mer. Uppmaningarna innehåller tydliga instruktioner om vad du ska hålla utkik efter och strukturen att returnera data i. Genom att upprepa denna process över hela årsredovisningen kan du extrahera relevanta enheter och relationer för att konstruera en rik kunskapsgraf.
Men innan du överför den extraherade informationen till kunskapsgrafen måste du först disambiguera enheterna. Det kan till exempel redan finnas en annan "[Företag A]"-enhet i kunskapsdiagrammet, men den kan representera en annan organisation med samma namn. Amazon Bedrock kan resonera och jämföra attribut som affärsfokusområde, industri och intäktsgenererande industrier och relationer till andra enheter för att avgöra om de två enheterna faktiskt är åtskilda. Detta förhindrar felaktigt sammanslagningar av icke-närstående företag till en enda enhet.
När disambigueringen är klar kan du på ett tillförlitligt sätt lägga till nya enheter och relationer i din Neptune-kunskapsgraf, och berika den med fakta extraherade från årsrapporter. Med tiden kommer intag av tillförlitliga data och integrering av mer tillförlitliga datakällor att hjälpa till att bygga en omfattande kunskapsgraf som kan stödja avslöjande insikter genom graffrågor och analyser.
Denna automatisering som möjliggörs av generativ AI gör det möjligt att bearbeta tusentals årsrapporter och låser upp en ovärderlig tillgång för kunskapsgrafkurering som annars skulle förbli outnyttjad på grund av den oöverkomligt höga manuella ansträngning som krävs.
Följande skärmdump visar ett exempel på den visuella utforskningen som är möjlig i en Neptunus grafdatabas med hjälp av Graph Explorer verktyg.

Bearbeta nyhetsartiklar

Nästa steg i lösningen är att automatiskt berika portföljförvaltarnas nyhetsflöden och lyfta fram artiklar som är relevanta för deras intressen och investeringar. För nyhetsflödet kan portföljförvaltare prenumerera på vilken tredjepartsnyhetsleverantör som helst AWS datautbyte eller annat valfritt nyhets-API.
När en nyhetsartikel kommer in i systemet anropas en inmatningspipeline för att bearbeta innehållet. Genom att använda tekniker som liknar bearbetningen av årsrapporter används Amazon Bedrock för att extrahera enheter, attribut och relationer från nyhetsartikeln, som sedan används för att disambiguera mot kunskapsgrafen för att identifiera motsvarande enhet i kunskapsgrafen.
Kunskapsgrafen innehåller kopplingar mellan företag och människor, och genom att länka artikelenheter till befintliga noder kan du identifiera om några ämnen ligger inom två hopp från de företag som portföljförvaltaren har investerat i eller är intresserad av. Att hitta en sådan koppling indikerar artikeln kan vara relevant för portföljförvaltaren, och eftersom den underliggande informationen är representerad i en kunskapsgraf kan den visualiseras för att hjälpa portföljförvaltaren att förstå varför och hur detta sammanhang är relevant. Förutom att identifiera kopplingar till portföljen kan du också använda Amazon Bedrock för att utföra sentimentanalyser på de enheter som hänvisas till.
Slutresultatet är ett berikat nyhetsflöde som visar artiklar som sannolikt kommer att påverka portföljförvaltarens intresseområden och investeringar.
Lösningsöversikt
Den övergripande arkitekturen för lösningen ser ut som följande diagram.
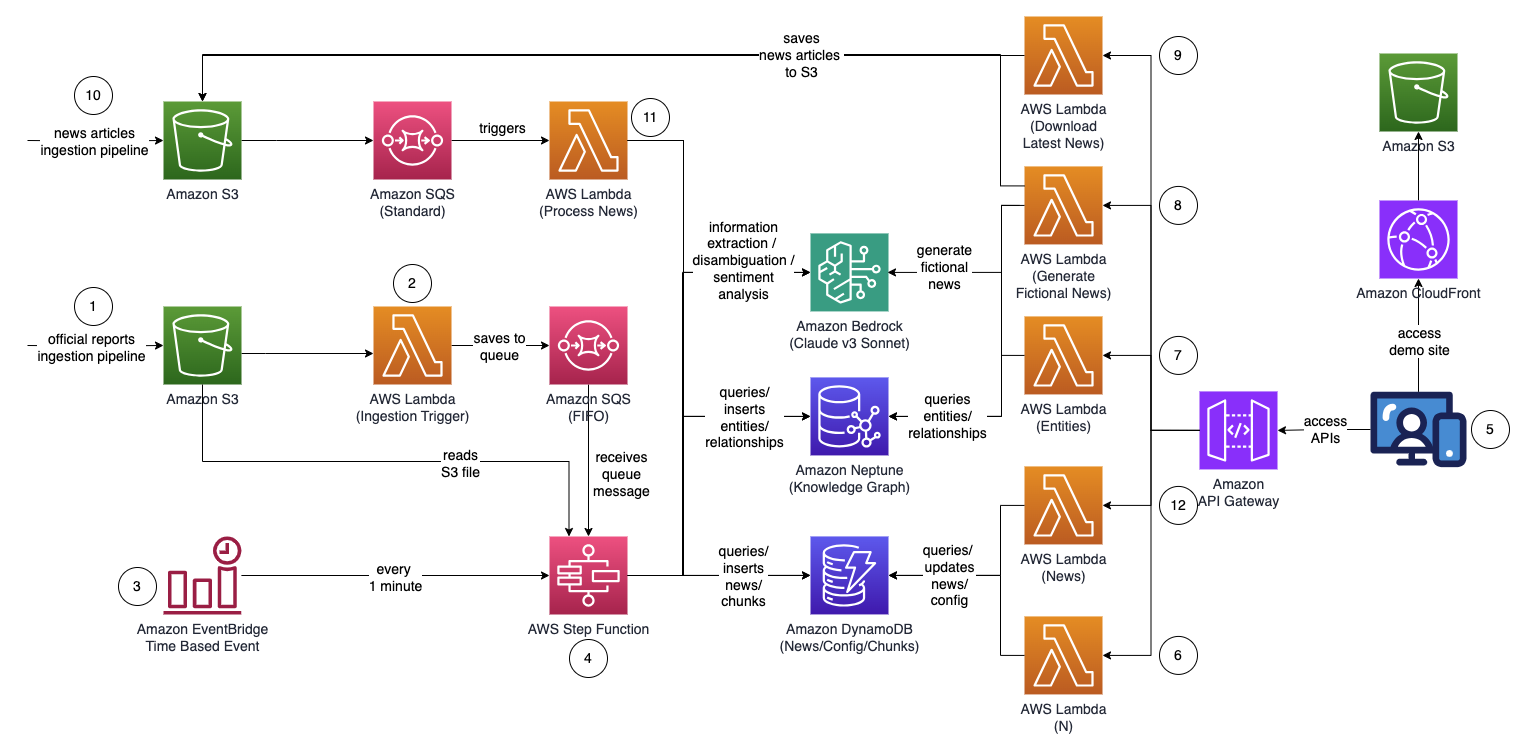
Arbetsflödet består av följande steg:
- En användare laddar upp officiella rapporter (i PDF-format) till en Amazon enkel lagringstjänst (Amazon S3) hink. Rapporterna bör vara officiellt publicerade rapporter för att minimera inkluderingen av felaktiga data i din kunskapsgraf (i motsats till nyheter och tabloider).
- S3-händelsemeddelandet anropar en AWS Lambda funktion, som skickar S3-hinken och filnamnet till en Amazon enkel kötjänst (Amazon SQS) kö. First-In-First-Out (FIFO)-kön ser till att rapportinmatningsprocessen utförs sekventiellt för att minska sannolikheten för att dubbletter av data introduceras i din kunskapsgraf.
- An Amazon EventBridge tidsbaserad händelse körs varje minut för att starta körningen av en AWS stegfunktioner tillståndsmaskin asynkront.
- Step Functions-tillståndsmaskinen kör igenom en serie uppgifter för att bearbeta det uppladdade dokumentet genom att extrahera nyckelinformation och infoga den i din kunskapsgraf:
- Ta emot kömeddelandet från Amazon SQS.
- Ladda ner PDF-rapportfilen från Amazon S3, dela upp den i flera mindre textbitar (cirka 1,000 XNUMX ord) för bearbetning och lagra textbitarna i Amazon DynamoDB.
- Använd Anthropics Claude v3 Sonnet på Amazon Bedrock för att bearbeta de första få textbitarna för att bestämma huvudenheten som rapporten hänvisar till, tillsammans med relevanta attribut (som industri).
- Hämta textbitarna från DynamoDB och anropa en Lambda-funktion för varje textbit för att extrahera entiteter (som företag eller person) och dess relation (kund, leverantör, partner, konkurrent eller direktör) till huvudenheten med Amazon Bedrock .
- Konsolidera all extraherad information.
- Filtrera bort brus och irrelevanta enheter (till exempel generiska termer som "konsumenter") med Amazon Bedrock.
- Använd Amazon Bedrock för att göra disambiguering genom att resonera med hjälp av den extraherade informationen mot listan över liknande enheter från kunskapsdiagrammet. Om enheten inte finns, infoga den. Annars använder du den entitet som redan finns i kunskapsdiagrammet. Infoga alla utdragna relationer.
- Rensa genom att ta bort SQS-kömeddelandet och S3-filen.
- En användare kommer åt en React-baserad webbapplikation för att se nyhetsartiklar som kompletteras med information om entitet, sentiment och anslutningsväg.
- Med hjälp av webbapplikationen anger användaren antalet hopp (standard N=2) på anslutningsvägen som ska övervakas.
- Med hjälp av webbapplikationen anger användaren listan över enheter som ska spåras.
- För att generera fiktiva nyheter väljer användaren Generera exempelnyheter att generera 10 exempel på finansiella nyhetsartiklar med slumpmässigt innehåll som ska matas in i nyhetsintagsprocessen. Innehåll genereras med Amazon Bedrock och är rent fiktivt.
- För att ladda ner faktiska nyheter väljer användaren Ladda ner de senaste nyheterna för att ladda ner de bästa nyheterna som händer idag (driven av NewsAPI.org).
- Nyhetsfilen (TXT-format) laddas upp till en S3-bucket. Steg 8 och 9 laddar upp nyheter till S3-bucketen automatiskt, men du kan också bygga integrationer till din föredragna nyhetsleverantör som AWS Data Exchange eller någon tredjepartsnyhetsleverantör för att släppa nyhetsartiklar som filer i S3-bucket. Nyhetsdatafilens innehåll bör formateras som
<date>{dd mmm yyyy}</date><title>{title}</title><text>{news content}</text>. - S3-händelsemeddelandet skickar S3-hinken eller filnamnet till Amazon SQS (standard), som anropar flera Lambda-funktioner för att behandla nyhetsdata parallellt:
- Använd Amazon Bedrock för att extrahera enheter som nämns i nyheterna tillsammans med all relaterad information, relationer och känslor för den nämnda enheten.
- Kontrollera mot kunskapsgrafen och använd Amazon Bedrock för att göra disambiguering genom att resonera med hjälp av tillgänglig information från nyheterna och inifrån kunskapsgrafen för att identifiera motsvarande enhet.
- Efter att enheten har hittats söker du efter och returnerar alla anslutningsvägar som ansluter till enheter markerade med
INTERESTED=YESi kunskapsgrafen som är inom N=2 hopp bort.
- Webbapplikationen uppdateras automatiskt var 1:e sekund för att ta fram den senaste uppsättningen bearbetade nyheter som ska visas i webbapplikationen.
Distribuera prototypen
Du kan distribuera prototyplösningen och börja experimentera själv. Prototypen finns tillgänglig från GitHub och innehåller information om följande:
- Förutsättningar för distribution
- Distributionssteg
- Rengöringssteg
Sammanfattning
Det här inlägget demonstrerade en proof of concept-lösning för att hjälpa portföljförvaltare att upptäcka andra och tredje ordningens risker från nyhetshändelser, utan direkta referenser till företag som de spårar. Genom att kombinera en kunskapsgraf över komplicerade företagsrelationer med nyhetsanalys i realtid med hjälp av generativ AI, kan nedströmseffekter belysas, såsom produktionsförseningar från leverantörshicka.
Även om det bara är en prototyp, visar den här lösningen löftet om kunskapsgrafer och språkmodeller för att koppla ihop punkter och härleda signaler från brus. Dessa tekniker kan hjälpa investeringsproffs genom att avslöja risker snabbare genom relationskartläggningar och resonemang. Sammantaget är detta en lovande tillämpning av grafdatabaser och AI som motiverar utforskning för att utöka investeringsanalys och beslutsfattande.
Om det här exemplet på generativ AI i finansiella tjänster är av intresse för ditt företag, eller om du har en liknande idé, kontakta din AWS-kontoansvarig, så utforskar vi gärna vidare tillsammans med dig.
Om författaren
 Xan Huang är Senior Solutions Architect med AWS och är baserad i Singapore. Han arbetar med stora finansiella institutioner för att designa och bygga säkra, skalbara och högt tillgängliga lösningar i molnet. Utanför jobbet tillbringar Xan det mesta av sin lediga tid med sin familj och att få styras av sin 3-åriga dotter. Du kan hitta Xan på LinkedIn.
Xan Huang är Senior Solutions Architect med AWS och är baserad i Singapore. Han arbetar med stora finansiella institutioner för att designa och bygga säkra, skalbara och högt tillgängliga lösningar i molnet. Utanför jobbet tillbringar Xan det mesta av sin lediga tid med sin familj och att få styras av sin 3-åriga dotter. Du kan hitta Xan på LinkedIn.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://aws.amazon.com/blogs/machine-learning/uncover-hidden-connections-in-unstructured-financial-data-with-amazon-bedrock-and-amazon-neptune/

