Amazon-erkännande gör det enkelt att lägga till bild- och videoanalys i dina applikationer. Den är baserad på samma beprövade, mycket skalbara, djupinlärningsteknologi som utvecklats av Amazons forskare om datorseende för att analysera miljarder bilder och videor dagligen. Det kräver ingen maskininlärning (ML) expertis att använda och vi lägger ständigt till nya datorseende funktioner till tjänsten. Amazon Rekognition inkluderar ett enkelt, lättanvänt API som snabbt kan analysera alla bilder eller videofiler som lagras i Amazon enkel lagringstjänst (Amazon S3).
Kunder över branscher som reklam- och marknadsföringsteknik, spel, media och detaljhandel och e-handel förlitar sig på bilder som laddas upp av sina slutanvändare (användargenererat innehåll eller UGC) som en kritisk komponent för att driva engagemang på deras plattform. De använder Amazon Rekognition innehåll moderering för att upptäcka olämpligt, oönskat och stötande innehåll för att skydda deras varumärkesrykte och främja säkra användargemenskaper.
I det här inlägget kommer vi att diskutera följande:
- Content Moderering modell version 7.0 och funktioner
- Hur fungerar Amazon Rekognition Bulk Analysis för innehållsmoderering
- Hur man förbättrar förutsägelsen av innehållsmoderering med massanalys och anpassad moderering
Innehållsmodereringsmodell version 7.0 och funktioner
Amazon Rekognition Content Moderering version 7.0 lägger till 26 nya modereringsetiketter och utökar modereringsetikettsklassificeringen från en två-nivå till en tre-nivå etikettkategori. Dessa nya etiketter och den utökade taxonomin gör det möjligt för kunder att upptäcka finkorniga koncept på innehållet de vill moderera. Dessutom introducerar den uppdaterade modellen en ny förmåga att identifiera två nya innehållstyper, animerat och illustrerat innehåll. Detta tillåter kunder att skapa detaljerade regler för att inkludera eller exkludera sådana innehållstyper från deras modereringsarbetsflöde. Med dessa nya uppdateringar kan kunder moderera innehåll i enlighet med deras innehållspolicy med högre noggrannhet.
Låt oss titta på ett exempel på upptäckt av modereringsetiketter för följande bild.

Följande tabell visar modereringsetiketter, innehållstyp och konfidenspoäng som returneras i API-svaret.
| Modereringsetiketter | Taxonominivå | Förtroendepoäng |
| Våld | L1 | 92.6% |
| Grafiskt våld | L2 | 92.6% |
| Explosioner och sprängningar | L3 | 92.6% |
| Innehållstyper | Förtroendepoäng |
| illustrerad | 93.9% |
För att få den fullständiga taxonomin för Content Moderation version 7.0, besök vår utvecklarguide.
Massanalys för innehållsmoderering
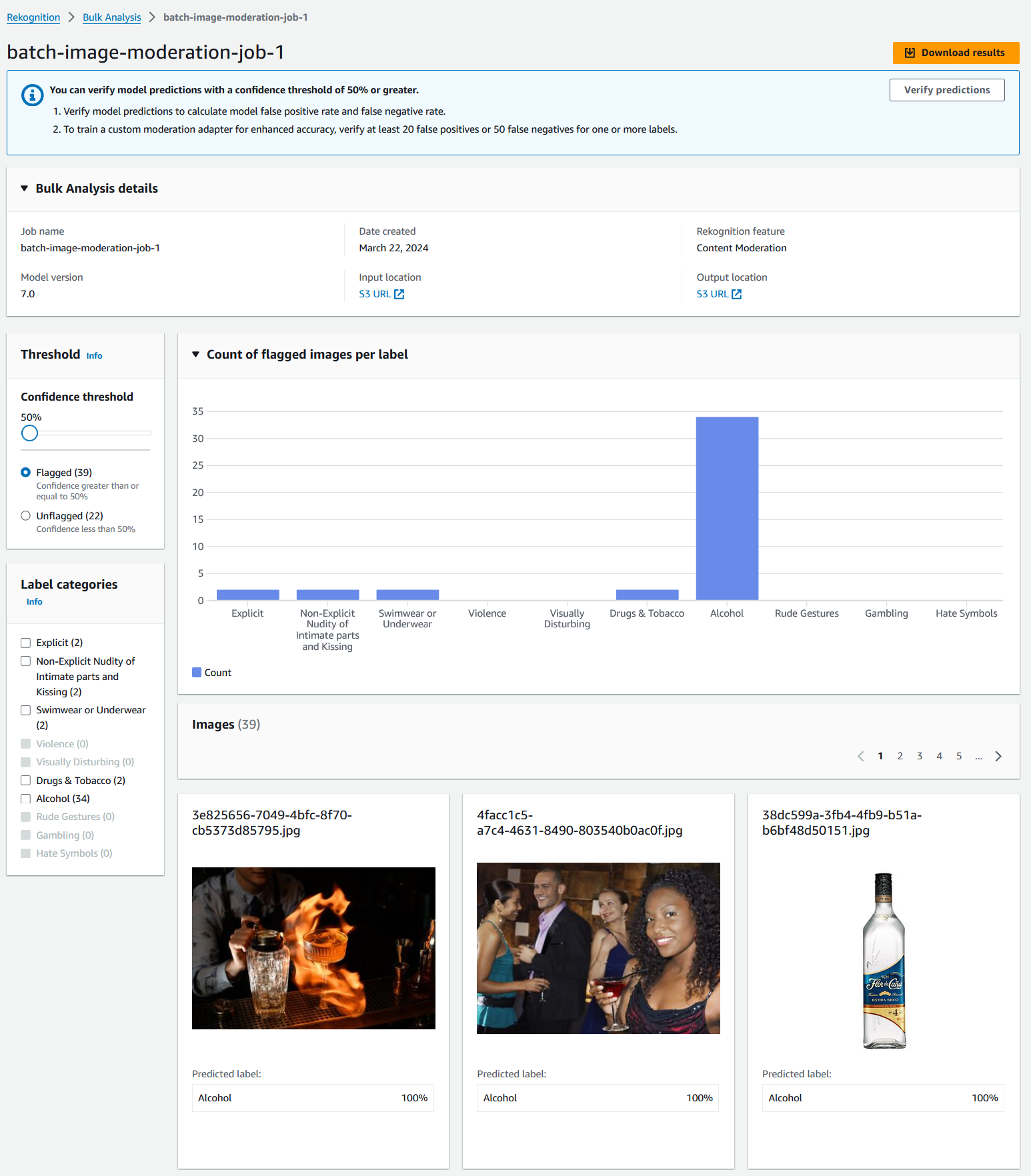
Amazon Rekognition Content Moderering ger också batchbildmoderering utöver realtidsmoderering med hjälp av Amazon erkännande Bulk Analys. Det gör att du kan analysera stora bildsamlingar asynkront för att upptäcka olämpligt innehåll och få insikter i modereringskategorierna som tilldelats bilderna. Det eliminerar också behovet av att bygga en lösning för batchbildmoderering för kunder.
Du kan komma åt bulkanalysfunktionen antingen via Amazon Rekognition-konsolen eller genom att anropa API:erna direkt med hjälp av AWS CLI och AWS SDK:er. På Amazon Rekognition-konsolen kan du ladda upp bilderna du vill analysera och få resultat med några få klick. När bulkanalysjobbet är klart kan du identifiera och se förutsägelser av modereringsetiketter, som Explicit, Non-Explicit nakenhet av intima delar och Kyssar, Våld, Droger & Tobak och mer. Du får också ett förtroendepoäng för varje etikettkategori.
Skapa ett massanalysjobb på Amazon Rekognition-konsolen
Slutför följande steg för att prova Amazon Rekognition Bulk Analysis:
- Välj på Amazon Rekognition-konsolen Bulkanalys i navigeringsfönstret.
- Välja Starta bulkanalys.
- Ange ett jobbnamn och ange bilderna som ska analyseras, antingen genom att ange en S3-skopplats eller genom att ladda upp bilder från din dator.
- Alternativt kan du välja en adapter för att analysera bilder med den anpassade adaptern som du har tränat med att använda anpassad moderering.
- Välja Börja analysen att köra jobbet.

När processen är klar kan du se resultaten på Amazon Rekognition-konsolen. Dessutom kommer en JSON-kopia av analysresultaten att lagras i Amazon S3-utdataplatsen.
Amazon Rekognition Bulk Analysis API-begäran
I det här avsnittet guidar vi dig genom att skapa ett bulkanalysjobb för bildmoderering med hjälp av programmeringsgränssnitt. Om dina bildfiler inte redan finns i en S3-hink, ladda upp dem för att säkerställa åtkomst av Amazon Rekognition. Liknar att skapa ett bulkanalysjobb på Amazon Rekognition-konsolen när du anropar Starta MediaAnalysisJob API måste du ange följande parametrar:
- OperationsConfig – Det här är konfigurationsalternativen för medieanalysjobbet som ska skapas:
- MinConfidence – Minsta konfidensnivå med det giltiga intervallet 0–100 för att modereringsetiketterna ska returneras. Amazon Rekognition returnerar inga etiketter med en konfidensnivå som är lägre än detta angivna värde.
- Ingång – Detta inkluderar följande:
- S3Objekt – S3-objektinformationen för inmatningsmanifestfilen, inklusive bucket och namnet på filen. indatafilen innehåller JSON-rader för varje bild som lagras på S3-hinken. till exempel:
{"source-ref": "s3://MY-INPUT-BUCKET/1.jpg"}
- S3Objekt – S3-objektinformationen för inmatningsmanifestfilen, inklusive bucket och namnet på filen. indatafilen innehåller JSON-rader för varje bild som lagras på S3-hinken. till exempel:
- OutputConfig – Detta inkluderar följande:
- S3Bucket – S3-hinknamnet för utdatafilerna.
- S3KeyPrefix – Nyckelprefixet för utdatafilerna.
Se följande kod:
Du kan åberopa samma medieanalys med följande AWS CLI-kommando:
Amazon Rekognition Bulk Analysis API-resultat
För att få en lista över bulkanalysjobb kan du använda ListMediaAnalysisJobs. Svaret innehåller alla detaljer om in- och utdatafilerna för analysjobbet och jobbets status:
Du kan också åberopa list-media-analysis-jobs kommando via AWS CLI:
Amazon Rekognition Bulk Analysis genererar två utdatafiler i output-bucket. Den första filen är manifest-summary.json, som inkluderar bulkanalysjobbstatistik och en lista över fel:
Den andra filen är results.json, som inkluderar en JSON-rad per varje analyserad bild i följande format. Varje resultat inkluderar kategori på högsta nivå (L1) för en detekterad etikett och kategorin på andra nivån av etiketten (L2), med en konfidenspoäng mellan 1–100. Vissa Taxonomy Level 2-etiketter kan ha Taxonomy Level 3-etiketter (L3). Detta möjliggör en hierarkisk klassificering av innehållet.

Du kan använda Adaptrar för anpassad moderering senare för att analysera dina bilder genom att helt enkelt välja den anpassade adaptern samtidigt som du skapar ett nytt massanalysjobb eller via API genom att skicka den anpassade adapterns unika adapter-ID.
Sammanfattning
I det här inlägget gav vi en översikt över Content Moderation version 7.0, Bulk Analysis for Content Moderation, och hur man förbättrar förutsägelser om Content Moderering med hjälp av Bulk Analysis och Custom Moderation. För att prova de nya modereringsetiketterna och bulkanalysen, logga in på ditt AWS-konto och kolla in Amazon Rekognition-konsolen för Bildmoderering och Bulkanalys.
Om författarna
 Mehdy Haghy är Senior Solutions Architect på AWS WWCS-teamet, specialiserat på AI och ML på AWS. Han arbetar med företagskunder och hjälper dem att migrera, modernisera och optimera sina arbetsbelastningar för AWS-molnet. På fritiden tycker han om att laga persisk mat och att mixtra med elektronik.
Mehdy Haghy är Senior Solutions Architect på AWS WWCS-teamet, specialiserat på AI och ML på AWS. Han arbetar med företagskunder och hjälper dem att migrera, modernisera och optimera sina arbetsbelastningar för AWS-molnet. På fritiden tycker han om att laga persisk mat och att mixtra med elektronik.
 Shipra Kanoria är huvudproduktchef på AWS. Hon brinner för att hjälpa kunder att lösa sina mest komplexa problem med kraften i maskininlärning och artificiell intelligens. Innan Shipra började på AWS tillbringade hon över fyra år på Amazon Alexa, där hon lanserade många produktivitetsrelaterade funktioner på Alexa röstassistent.
Shipra Kanoria är huvudproduktchef på AWS. Hon brinner för att hjälpa kunder att lösa sina mest komplexa problem med kraften i maskininlärning och artificiell intelligens. Innan Shipra började på AWS tillbringade hon över fyra år på Amazon Alexa, där hon lanserade många produktivitetsrelaterade funktioner på Alexa röstassistent.
 Maria Handoko är Senior Product Manager på AWS. Hon fokuserar på att hjälpa kunder att lösa sina affärsutmaningar genom maskininlärning och datorseende. På fritiden tycker hon om att vandra, lyssna på poddar och utforska olika kök.
Maria Handoko är Senior Product Manager på AWS. Hon fokuserar på att hjälpa kunder att lösa sina affärsutmaningar genom maskininlärning och datorseende. På fritiden tycker hon om att vandra, lyssna på poddar och utforska olika kök.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://aws.amazon.com/blogs/machine-learning/improving-content-moderation-with-amazon-rekognition-bulk-analysis-and-custom-moderation/

