Когда я начал изучать анализ данных несколько лет назад, первым делом я изучил SQL и Pandas. Для аналитика данных крайне важно иметь прочную основу для работы с SQL и Pandas. Оба являются мощными инструментами, которые помогают аналитикам данных эффективно анализировать данные, хранящиеся в базах данных, и манипулировать ими.
Обзор SQL и Pandas
SQL (язык структурированных запросов) — это язык программирования, используемый для управления реляционными базами данных и управления ими. С другой стороны, Pandas — это библиотека Python, используемая для обработки и анализа данных.
Анализ данных предполагает работу с большими объемами данных, и для хранения этих данных часто используются базы данных. SQL и Pandas предоставляют мощные инструменты для работы с базами данных, позволяя аналитикам данных эффективно извлекать, обрабатывать и анализировать данные. Используя эти инструменты, аналитики данных могут получить ценную информацию из данных, которую иначе было бы трудно получить.
В этой статье мы рассмотрим, как использовать SQL и Pandas для чтения и записи в базу данных.
Подключение к БД
Установка библиотек
Мы должны сначала установить необходимые библиотеки, прежде чем мы сможем подключиться к базе данных SQL с помощью Pandas. Требуются две основные библиотеки: Pandas и SQLAlchemy. Pandas — это популярная библиотека для работы с данными, которая позволяет хранить большие структуры данных, как упоминалось во введении. Напротив, SQLAlchemy предоставляет API для подключения к базе данных SQL и взаимодействия с ней.
Мы можем установить обе библиотеки с помощью диспетчера пакетов Python, pip, выполнив следующие команды в командной строке.
$ pip install pandas
$ pip install sqlalchemy
Создание соединения
После установки библиотек мы можем использовать Pandas для подключения к базе данных SQL.
Для начала мы создадим объект механизма SQLAlchemy с create_engine(), create_engine() Функция подключает код Python к базе данных. Он принимает в качестве аргумента строку подключения, в которой указывается тип базы данных и сведения о подключении. В этом примере мы будем использовать тип базы данных SQLite и путь к файлу базы данных.
Создайте объект механизма для базы данных SQLite, используя приведенный ниже пример:
import pandas as pd
from sqlalchemy import create_engine engine = create_engine('sqlite:///C/SQLite/student.db')
Если файл базы данных SQLite, student.db в нашем случае, находится в том же каталоге, что и скрипт Python, мы можем напрямую использовать имя файла, как показано ниже.
engine = create_engine('sqlite:///student.db')
Чтение файлов SQL с помощью Pandas
Давайте прочитаем данные теперь, когда мы установили соединение. В этом разделе мы рассмотрим read_sql, read_sql_tableкачества read_sql_query функции и как их использовать для работы с базой данных.
Выполнение SQL-запросов с помощью Panda read_sql() Функция
Ассоциация read_sql() — это библиотечная функция Pandas, которая позволяет нам выполнять SQL-запрос и извлекать результаты в кадр данных Pandas. read_sql() Функция связывает SQL и Python, позволяя нам использовать преимущества обоих языков. Функция обертывает read_sql_table() и read_sql_query(), read_sql() функция внутренне маршрутизируется на основе предоставленного ввода, что означает, что если ввод предназначен для выполнения SQL-запроса, он будет перенаправлен на read_sql_query(), и если это таблица базы данных, она будет перенаправлена на read_sql_table().
Ассоциация read_sql() синтаксис следующий:
pandas.read_sql(sql, con, index_col=None, coerce_float=True, params=None, parse_dates=None, columns=None, chunksize=None)
Требуются параметры SQL и con; остальные опциональны. Однако мы можем манипулировать результатом, используя эти необязательные параметры. Рассмотрим подробнее каждый параметр.
sql: SQL-запрос или имя таблицы базы данныхcon: объект подключения или URL-адрес подключения.index_col: этот параметр позволяет нам использовать один или несколько столбцов из результата SQL-запроса в качестве индекса фрейма данных. Он может принимать либо один столбец, либо список столбцов.coerce_float: этот параметр указывает, следует ли преобразовывать нечисловые значения в числа с плавающей запятой или оставлять их в виде строк. По умолчанию установлено значение true. Если возможно, он преобразует нечисловые значения в типы с плавающей запятой.params: параметры обеспечивают безопасный метод передачи динамических значений в SQL-запрос. Мы можем использовать параметр params для передачи словаря, кортежа или списка. В зависимости от базы данных синтаксис параметров различается.parse_dates: это позволяет нам указать, какой столбец в результирующем фрейме данных будет интерпретироваться как дата. Он принимает один столбец, список столбцов или словарь с ключом в качестве имени столбца и значением в качестве формата столбца.columns: Это позволяет нам извлекать только выбранные столбцы из списка.chunksize: при работе с большим набором данных важен размер фрагмента. Он извлекает результат запроса меньшими порциями, повышая производительность.
Вот пример того, как использовать read_sql():
Код:
import pandas as pd
from sqlalchemy import create_engine engine = create_engine('sqlite:///C/SQLite/student.db') df = pd.read_sql("SELECT * FROM Student", engine, index_col='Roll Number', parse_dates='dateOfBirth')
print(df)
print("The Data type of dateOfBirth: ", df.dateOfBirth.dtype) engine.dispose()
Вывод:
firstName lastName email dateOfBirth
rollNumber
1 Mark Simson [email protected] 2000-02-23
2 Peter Griffen [email protected] 2001-04-15
3 Meg Aniston [email protected] 2001-09-20
Date type of dateOfBirth: datetime64[ns]
После подключения к базе данных мы выполняем запрос, который возвращает все записи из базы данных. Student таблицу и сохраняет их в DataFrame df. Столбец «Roll Number» преобразуется в индекс с помощью index_col параметр, а тип данных «dateOfBirth» — «datetime64[ns]» из-за parse_dates. Мы можем использовать read_sql() не только для извлечения данных, но и для выполнения других операций, таких как вставка, удаление и обновление. read_sql() является универсальной функцией.
Загрузка определенных таблиц или представлений из БД
Загрузка определенной таблицы или представления с помощью Pandas read_sql_table() — это еще один метод чтения данных из базы данных в фрейм данных Pandas.
Что такое read_sql_table?
Библиотека Pandas предоставляет read_sql_table функция, которая специально разработана для чтения всей таблицы SQL без выполнения каких-либо запросов и возврата результата в виде кадра данных Pandas.
Синтаксис read_sql_table() как показано ниже:
pandas.read_sql_table(table_name, con, schema=None, index_col=None, coerce_float=True, parse_dates=None, columns=None, chunksize=None)
За исключением table_name и схеме параметры объясняются так же, как read_sql().
table_name: Параметрtable_nameимя таблицы SQL в базе данных.schema: этот необязательный параметр является именем схемы, содержащей имя таблицы.
После создания подключения к базе данных мы будем использовать read_sql_table функция для загрузки Student таблицу в Pandas DataFrame.
import pandas as pd
from sqlalchemy import create_engine engine = create_engine('sqlite:///C/SQLite/student.db') df = pd.read_sql_table('Student', engine)
print(df.head()) engine.dispose()
Вывод:
rollNumber firstName lastName email dateOfBirth
0 1 Mark Simson [email protected] 2000-02-23
1 2 Peter Griffen [email protected] 2001-04-15
2 3 Meg Aniston [email protected] 2001-09-20
Предположим, что это большая таблица, которая может интенсивно использовать память. Давайте рассмотрим, как мы можем использовать chunksize параметр для решения этой проблемы.
Ознакомьтесь с нашим практическим руководством по изучению Git с рекомендациями, принятыми в отрасли стандартами и прилагаемой памяткой. Перестаньте гуглить команды Git и на самом деле изучить это!
Код:
import pandas as pd
from sqlalchemy import create_engine engine = create_engine('sqlite:///C/SQLite/student.db') df_iterator = pd.read_sql_table('Student', engine, chunksize = 1) for df in df_iterator: print(df.head()) engine.dispose()
Вывод:
rollNumber firstName lastName email dateOfBirth
0 1 Mark Simson [email protected] 2000-02-23
0 2 Peter Griffen [email protected] 2001-04-15
0 3 Meg Aniston [email protected] 2001-09-20
Имейте в виду, что chunksize Я использую здесь 1, потому что в моей таблице всего 3 записи.
Запрос к БД напрямую с синтаксисом SQL Pandas
Извлечение информации из базы данных является важной частью для аналитиков данных и ученых. Для этого мы будем использовать read_sql_query() функции.
Что такое read_sql_query()?
Использование панд read_sql_query() мы можем запускать SQL-запросы и получать результаты непосредственно в DataFrame. read_sql_query() функция создана специально для SELECT заявления. Его нельзя использовать для каких-либо других операций, таких как DELETE or UPDATE.
Синтаксис:
pandas.read_sql_query(sql, con, index_col=None, coerce_float=True, params=None, parse_dates=None, chunksize=None, dtype=None, dtype_backend=_NoDefault.no_default)
Все описания параметров совпадают с read_sql() функция. Вот пример read_sql_query():
Код:
import pandas as pd
from sqlalchemy import create_engine engine = create_engine('sqlite:///C/SQLite/student.db') df = pd.read_sql_query('Select firstName, lastName From Student Where rollNumber = 1', engine)
print(df) engine.dispose()
Вывод:
firstName lastName
0 Mark Simson
Написание файлов SQL с помощью Pandas
Предположим, при анализе данных мы обнаружили, что необходимо изменить несколько записей или требуется новая таблица или представление с данными. Чтобы обновить или вставить новую запись, одним из способов является использование read_sql() и написать запрос. Однако этот метод может быть длительным. Панды предоставляют отличный метод под названием to_sql() для подобных ситуаций.
В этом разделе мы сначала создадим новую таблицу в базе данных, а затем отредактируем существующую.
Создание новой таблицы в базе данных SQL
Прежде чем мы создадим новую таблицу, давайте сначала обсудим to_sql() в деталях.
Что такое to_sql()?
Ассоциация to_sql() Функция библиотеки Pandas позволяет нам записывать или обновлять базу данных. to_sql() Функция может сохранять данные DataFrame в базу данных SQL.
Синтаксис для to_sql():
DataFrame.to_sql(name, con, schema=None, if_exists='fail', index=True, index_label=None, chunksize=None, dtype=None, method=None)
Только name и con параметры обязательны для запуска to_sql(); однако другие параметры обеспечивают дополнительную гибкость и возможности настройки. Рассмотрим подробно каждый параметр:
name: имя создаваемой или изменяемой таблицы SQL.con: объект подключения к базе данных.schema: Схема таблицы (необязательно).if_exists: Значение по умолчанию для этого параметра — «сбой». Этот параметр позволяет нам решить, какое действие следует предпринять, если таблица уже существует. Варианты включают «сбой», «заменить» и «добавить».index: параметр index принимает логическое значение. По умолчанию установлено значение True, что означает, что индекс DataFrame будет записан в таблицу SQL.index_label: этот необязательный параметр позволяет указать метку столбца для столбцов индекса. По умолчанию индекс записывается в таблицу, но с помощью этого параметра можно указать конкретное имя.chunksize: количество строк, записываемых за раз в базу данных SQL.dtype: этот параметр принимает словарь с ключами в качестве имен столбцов и значениями в качестве их типов данных.method: Параметр метода позволяет указать метод, используемый для вставки данных в SQL. По умолчанию установлено значение «Нет», что означает, что панды найдут наиболее эффективный способ на основе базы данных. Существует два основных варианта параметров метода:multi: позволяет вставлять несколько строк в один SQL-запрос. Однако не все базы данных поддерживают многострочную вставку.- Вызываемая функция: Здесь мы можем написать пользовательскую функцию для вставки и вызвать ее, используя параметры метода.
Вот пример использования to_sql():
import pandas as pd
from sqlalchemy import create_engine engine = create_engine('sqlite:///C/SQLite/student.db') data = {'Name': ['Paul', 'Tom', 'Jerry'], 'Age': [9, 8, 7]}
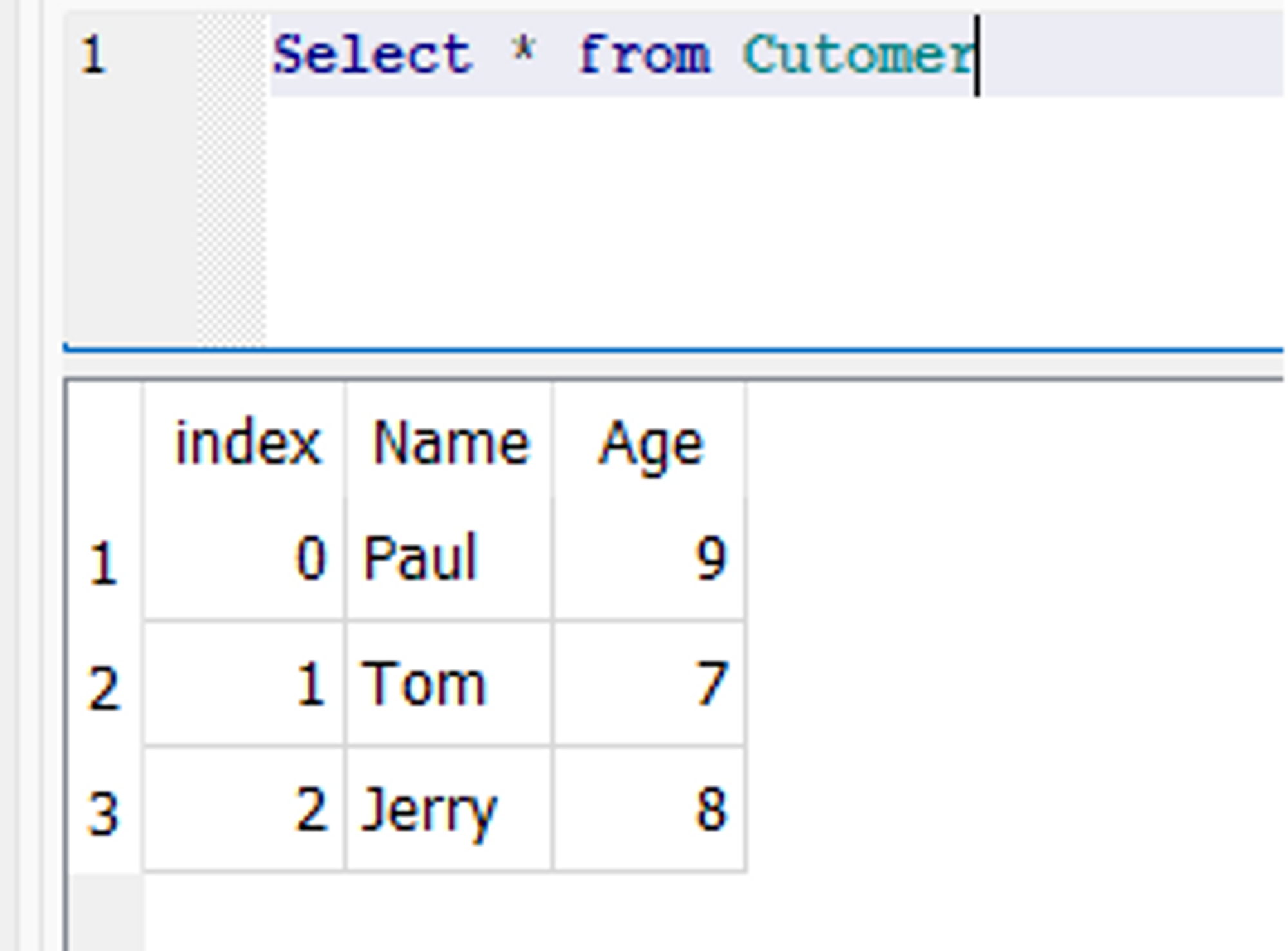
df = pd.DataFrame(data) df.to_sql('Customer', con=engine, if_exists='fail') engine.dispose()
В базе данных создается новая таблица «Клиент» с двумя полями «Имя» и «Возраст».
Снимок базы данных:
Обновление существующих таблиц с помощью фреймов данных Pandas
Обновление данных в базе данных — сложная задача, особенно при работе с большими данными. Однако, используя to_sql() Функция в Pandas может значительно упростить эту задачу. Чтобы обновить существующую таблицу в базе данных, to_sql() можно использовать с функцией if_exists параметр установлен на «заменить». Это перезапишет существующую таблицу новыми данными.
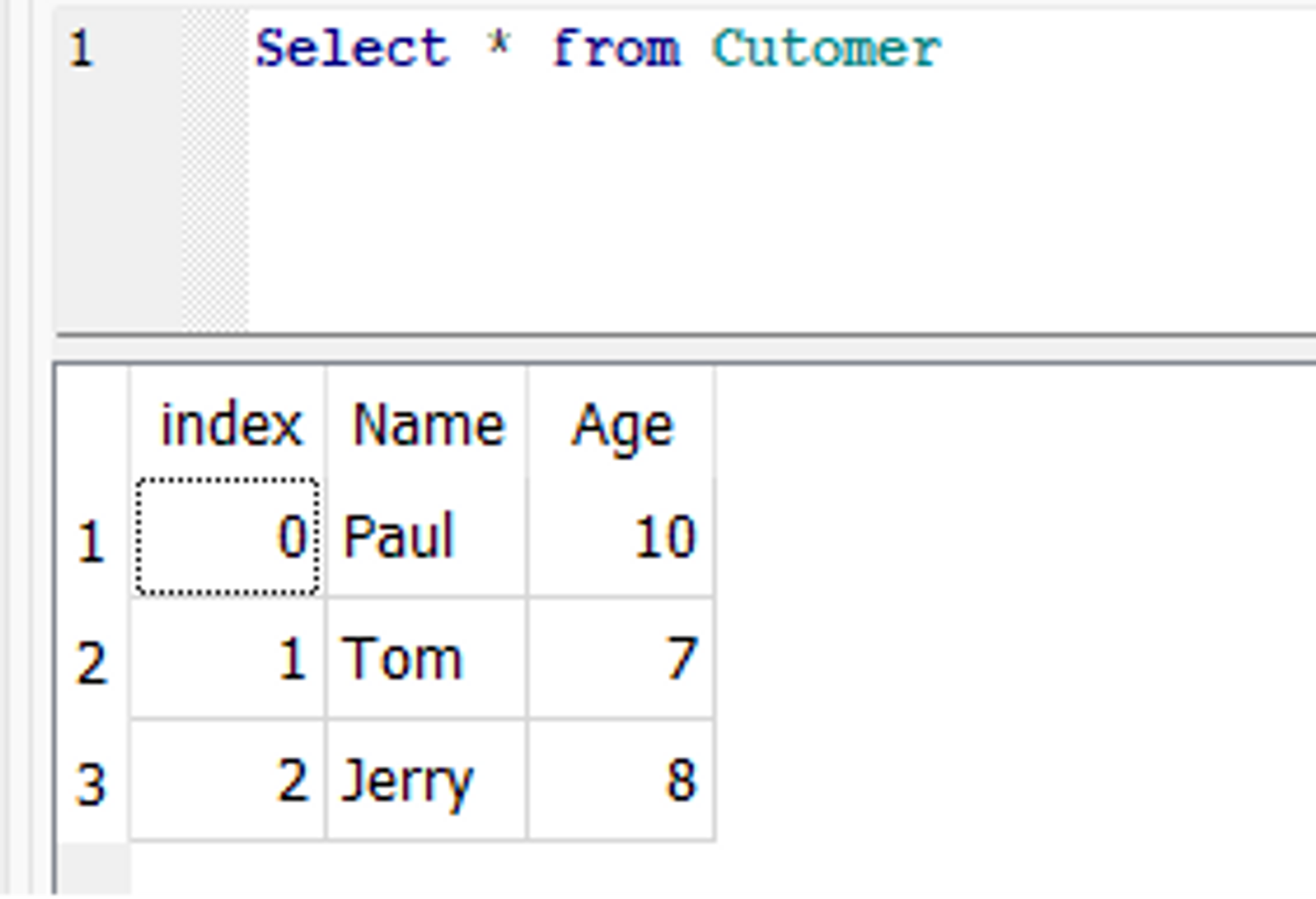
Вот пример to_sql() который обновляет ранее созданный Customer стол. Предположим, в Customer мы хотим обновить возраст клиента по имени Пол с 9 до 10 лет. Для этого сначала мы можем изменить соответствующую строку в DataFrame, а затем использовать to_sql() Функция обновления базы данных.
Код:
import pandas as pd
from sqlalchemy import create_engine engine = create_engine('sqlite:///C/SQLite/student.db') df = pd.read_sql_table('Customer', engine) df.loc[df['Name'] == 'Paul', 'Age'] = 10 df.to_sql('Customer', con=engine, if_exists='replace') engine.dispose()
В базе обновляется возраст Павла:
Заключение
В заключение, Pandas и SQL являются мощными инструментами для задач анализа данных, таких как чтение и запись данных в базу данных SQL. Pandas предоставляет простой способ подключения к базе данных SQL, чтения данных из базы данных в фрейм данных Pandas и записи данных фрейма данных обратно в базу данных.
Библиотека Pandas позволяет легко манипулировать данными в кадре данных, тогда как SQL предоставляет мощный язык для запроса данных в базе данных. Использование Pandas и SQL для чтения и записи данных может сэкономить время и усилия в задачах анализа данных, особенно когда данные очень большие. В целом, совместное использование SQL и Pandas может помочь аналитикам данных и ученым оптимизировать рабочий процесс.
- SEO-контент и PR-распределение. Получите усиление сегодня.
- ПлатонАйСтрим. Анализ данных Web3. Расширение знаний. Доступ здесь.
- Чеканка будущего с Эдриенн Эшли. Доступ здесь.
- Покупайте и продавайте акции компаний PREIPO® с помощью PREIPO®. Доступ здесь.
- Источник: https://stackabuse.com/reading-and-writing-sql-files-in-pandas/

