Генератор изображений Amazon Titan G1 — это передовая модель преобразования текста в изображение, доступная через Коренная порода Амазонки, который способен понимать подсказки, описывающие несколько объектов в различных контекстах, и фиксировать эти важные детали в генерируемых изображениях. Он доступен в регионах AWS Восток США (Сев. Вирджиния) и Запад США (Орегон) и может выполнять расширенные задачи редактирования изображений, такие как интеллектуальная обрезка, закрашивание и изменение фона. Однако пользователи хотели бы адаптировать модель к уникальным характеристикам пользовательских наборов данных, на которых модель еще не обучена. Пользовательские наборы данных могут включать в себя конфиденциальные данные, соответствующие принципам вашего бренда или конкретным стилям, таким как предыдущая кампания. Чтобы учесть эти варианты использования и создать полностью персонализированные изображения, вы можете настроить Amazon Titan Image Generator на свои собственные данные, используя пользовательские модели для Amazon Bedrock.
Модели преобразования текста в изображение находят широкое применение в различных отраслях: от создания изображений до их редактирования. Они могут повысить творческий потенциал сотрудников и дать им возможность представить новые возможности просто с помощью текстовых описаний. Например, он может помочь архитекторам в проектировании и планировании помещений, а также ускорить внедрение инноваций, предоставляя возможность визуализировать различные проекты без ручного процесса их создания. Точно так же он может помочь в дизайне в различных отраслях, таких как производство, дизайн одежды в розничной торговле и дизайн игр, оптимизируя создание графики и иллюстраций. Модели преобразования текста в изображение также улучшают качество обслуживания клиентов, позволяя использовать персонализированную рекламу, а также интерактивные и захватывающие визуальные чат-боты в сценариях использования в средствах массовой информации и развлечениях.
В этом посте мы покажем вам процесс тонкой настройки модели генератора изображений Amazon Titan, чтобы изучить две новые категории: собака Рон и кошка Смила, наши любимые домашние животные. Мы обсудим, как подготовить данные для задачи точной настройки модели и как создать задание по настройке модели в Amazon Bedrock. Наконец, мы покажем вам, как протестировать и развернуть вашу точно настроенную модель с помощью Обеспеченная пропускная способность.
 |
 |
| Рон, собака | Смила кот |
Оценка возможностей модели перед точной настройкой задания
Базовые модели обучаются на больших объемах данных, поэтому вполне возможно, что ваша модель будет работать достаточно хорошо «из коробки». Вот почему рекомендуется проверить, действительно ли вам нужно точно настроить модель для вашего варианта использования или достаточно быстрого проектирования. Давайте попробуем сгенерировать несколько изображений собаки Рона и кошки Смилы с помощью базовой модели Amazon Titan Image Generator, как показано на следующих снимках экрана.


Как и ожидалось, готовая модель еще не знает Рона и Смилу, а сгенерированные выходные данные показывают разных собак и кошек. Благодаря быстрому проектированию мы можем предоставить более подробную информацию, чтобы приблизиться к внешнему виду наших любимых домашних животных.


Хотя сгенерированные изображения больше похожи на Рона и Смилу, мы видим, что модель не способна воспроизвести их полное сходство. Давайте теперь начнем тонкую настройку фотографий Рона и Смилы, чтобы получить согласованные, персонализированные результаты.
Тонкая настройка генератора изображений Amazon Titan
Amazon Bedrock предоставляет вам бессерверную возможность точной настройки модели генератора изображений Amazon Titan. Вам нужно только подготовить данные и выбрать гиперпараметры, а AWS возьмет на себя всю тяжелую работу за вас.
Когда вы используете модель Amazon Titan Image Generator для точной настройки, в учетной записи разработки модели AWS, принадлежащей и управляемой AWS, создается копия этой модели, а также создается задание по настройке модели. Затем это задание получает доступ к данным тонкой настройки из VPC, и в модели Amazon Titan обновляются веса. Новая модель затем сохраняется в Простой сервис хранения Amazon (Amazon S3) находится в той же учетной записи разработки модели, что и предварительно обученная модель. Теперь его можно использовать для вывода только в вашей учетной записи, и он не будет доступен другим учетным записям AWS. При выполнении вывода вы получаете доступ к этой модели через вычисление выделенной мощности или напрямую, используя пакетный вывод для Amazon Bedrock. Независимо от выбранного метода вывода ваши данные остаются в вашей учетной записи и не копируются в какую-либо учетную запись, принадлежащую AWS, и не используются для улучшения модели Amazon Titan Image Generator.
Следующая диаграмма иллюстрирует этот рабочий процесс.

Конфиденциальность данных и сетевая безопасность
Ваши данные, используемые для тонкой настройки, включая подсказки, а также пользовательские модели, остаются конфиденциальными в вашей учетной записи AWS. Они не передаются и не используются для обучения моделей или улучшения обслуживания, а также не передаются сторонним поставщикам моделей. Все данные, используемые для тонкой настройки, шифруются при передаче и хранении. Данные остаются в том же регионе, где обрабатывается вызов API. Вы также можете использовать Приватная ссылка AWS чтобы создать частное соединение между учетной записью AWS, в которой находятся ваши данные, и VPC.
Подготовка данных
Прежде чем вы сможете создать задание по настройке модели, вам необходимо подготовьте набор обучающих данных. Формат вашего набора обучающих данных зависит от типа создаваемого вами задания по настройке (тонкая настройка или продолжение предварительного обучения) и модальности ваших данных (текст-текст, текст-изображение или изображение-изображение). встраивание). Для модели Amazon Titan Image Generator вам необходимо предоставить изображения, которые вы хотите использовать для точной настройки, и подпись к каждому изображению. Amazon Bedrock ожидает, что ваши изображения будут храниться на Amazon S3, а пары изображений и подписей будут предоставляться в формате JSONL с несколькими строками JSON.
Каждая строка JSON представляет собой образец, содержащий ссылку на изображение, URI S3 для изображения и заголовок, включающий текстовую подсказку для изображения. Ваши изображения должны быть в формате JPEG или PNG. В следующем коде показан пример формата:
{"image-ref": "s3://bucket/path/to/image001.png", "caption": ""} {"image-ref": "s3://bucket/path/to/image002.png", "caption": ""} {"image-ref": "s3://bucket/path/to/image003.png", "caption": ""}
Поскольку «Рон» и «Смила» — это имена, которые также можно использовать в других контекстах, например, имя человека, мы добавляем идентификаторы «Собака Рон» и «Кот Смила» при создании подсказки для точной настройки нашей модели. . Хотя это не является обязательным требованием для точной настройки рабочего процесса, эта дополнительная информация обеспечивает большую контекстуальную ясность модели при ее настройке для новых классов и позволяет избежать путаницы между «собакой Роном» и человеком по имени Рон и « Кот Смела» с городом Смела в Украине. Используя эту логику, на следующих изображениях показан образец нашего набора обучающих данных.
 |
 |
 |
| Пес Рон лежит на белой собачьей подстилке | Пес Рон сидит на кафельном полу. | Собака Рон лежит на автокресле |
 |
 |
 |
| Кот Смила лежит на диване | Кот Смила смотрит в камеру, лежа на диване | Кот Смила лежит в переноске для домашних животных |
При преобразовании наших данных в формат, ожидаемый заданием настройки, мы получаем следующую примерную структуру:
{"ссылка на изображение": "/ron_01.jpg", "caption": "Собака Рон лежит на белой собачьей подстилке"} {"image-ref": "/ron_02.jpg", "caption": "Собака Рон сидит на кафельном полу"} {"image-ref": "/ron_03.jpg", "caption": "Собака Рон лежит на автокресле"} {"image-ref": "/smila_01.jpg", "caption": "Кошка Смила лежит на диване"} {"image-ref": "/smila_02.jpg", "caption": "Кошка Смила сидит у окна рядом со статуей кота"} {"image-ref": "/smila_03.jpg", "caption": "Кошка Смила лежит на переноске для животных"}
После того как мы создали файл JSONL, нам нужно сохранить его в корзине S3, чтобы начать работу по настройке. Задания по точной настройке Amazon Titan Image Generator G1 будут работать с 5–10,000 60 изображений. Для примера, обсуждаемого в этом посте, мы используем 30 изображений: 30 собак Рона и XNUMX кошек Смелы. В общем, предоставление большего количества разновидностей стиля или класса, который вы пытаетесь изучить, повысит точность вашей точно настроенной модели. Однако чем больше изображений вы используете для тонкой настройки, тем больше времени потребуется для ее завершения. Количество используемых изображений также влияет на цену вашей точно настроенной работы. Ссылаться на Цены на Amazon Bedrock чтобы получить больше информации.
Тонкая настройка генератора изображений Amazon Titan
Теперь, когда у нас есть готовые данные для обучения, мы можем начать новую работу по настройке. Этот процесс можно выполнить как через консоль Amazon Bedrock, так и через API. Чтобы использовать консоль Amazon Bedrock, выполните следующие действия:
- На консоли Amazon Bedrock выберите Пользовательские модели в навигационной панели.
- На Настроить модель Меню, выберите Создать задание по тонкой настройке.
- Что касается Точно настроенное название модели, введите имя новой модели.
- Что касается Конфигурация задания, введите имя задания обучения.
- Что касается Входные данные, введите путь S3 входных данных.

- В гиперпараметры раздел укажите значения для следующих параметров:
- Количество ступеней – Сколько раз модель подвергалась воздействию каждой партии.
- Размер партии – Количество образцов, обработанных перед обновлением параметров модели.
- Скорость обучения – Скорость обновления параметров модели после каждого пакета. Выбор этих параметров зависит от конкретного набора данных. В качестве общего руководства мы рекомендуем начать с фиксации размера пакета на уровне 8, скорости обучения на уровне 1e-5 и установки количества шагов в соответствии с количеством используемых изображений, как подробно описано в следующей таблице.
| Количество предоставленных изображений | 8 | 32 | 64 | 1,000 | 10,000 |
| Рекомендуемое количество шагов | 1,000 | 4,000 | 8,000 | 10,000 | 12,000 |
Если результаты вашей работы по тонкой настройке неудовлетворительны, рассмотрите возможность увеличения количества шагов, если вы не наблюдаете никаких признаков стиля в сгенерированных изображениях, и уменьшения количества шагов, если вы наблюдаете стиль в сгенерированных изображениях, но с артефактами или размытостью. Если точно настроенной модели не удается запомнить уникальный стиль вашего набора данных даже после 40,000 XNUMX шагов, рассмотрите возможность увеличения размера пакета или скорости обучения.
- В Выходные данные В разделе введите выходной путь S3, где хранятся выходные данные проверки, включая периодически записываемые показатели потерь и точности проверки.
- В Доступ к сервису раздел, создайте новый Управление идентификацией и доступом AWS (IAM) или выберите существующую роль IAM с необходимыми разрешениями для доступа к вашим корзинам S3.
Эта авторизация позволяет Amazon Bedrock извлекать входные и проверочные наборы данных из назначенной корзины и беспрепятственно сохранять результаты проверки в корзине S3.
- Выберите Точная настройка модели.

Если установлены правильные конфигурации, Amazon Bedrock теперь будет обучать вашу пользовательскую модель.
Разверните точно настроенный генератор изображений Amazon Titan с выделенной пропускной способностью.
После создания пользовательской модели функция Provisioned Throughput позволяет выделить заранее определенную фиксированную скорость обработки для пользовательской модели. Такое распределение обеспечивает постоянный уровень производительности и мощности для обработки рабочих нагрузок, что приводит к повышению производительности производственных рабочих нагрузок. Вторым преимуществом Provisioned Throughput является контроль затрат, поскольку стандартное ценообразование на основе токенов с режимом вывода по требованию может быть трудно предсказать в больших масштабах.
Когда точная настройка вашей модели будет завершена, эта модель появится на Пользовательские модели' странице на консоли Amazon Bedrock.
Чтобы приобрести Provisioned Throughput, выберите пользовательскую модель, которую вы только что настроили, и выберите Приобретение предоставленной пропускной способности.
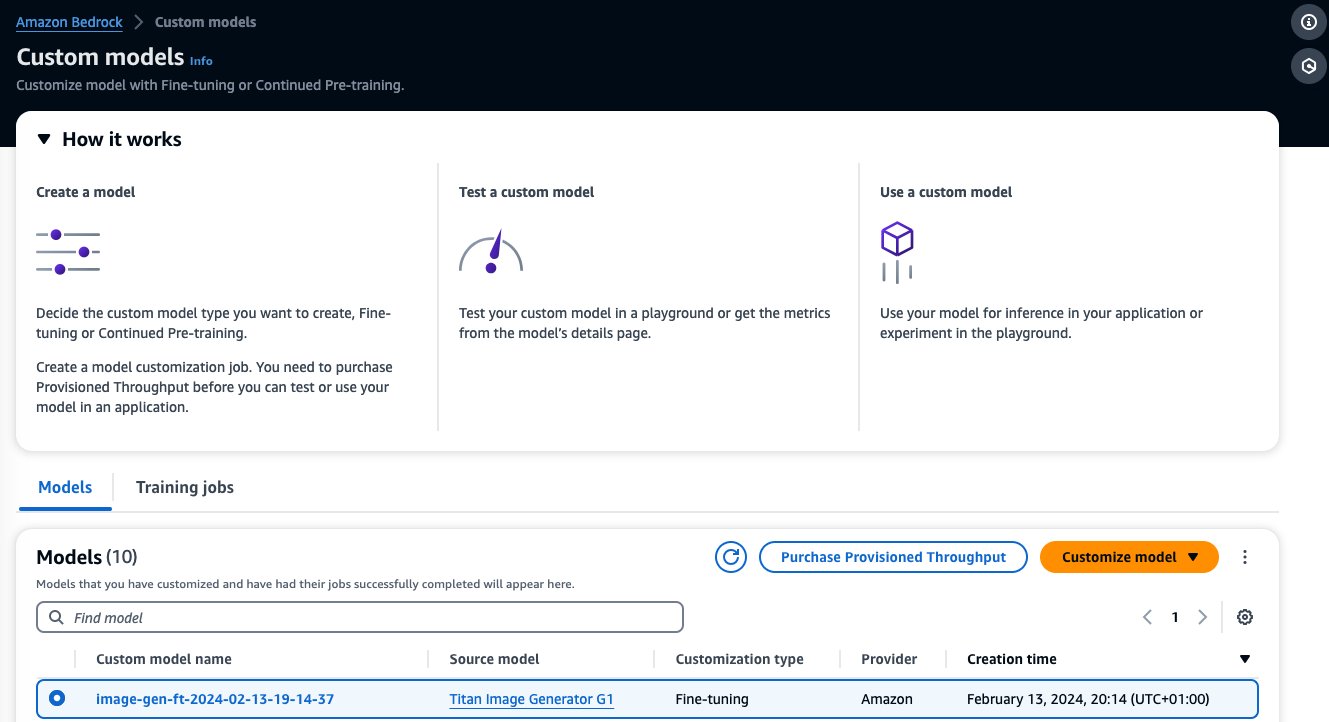
При этом будет предварительно заполнена выбранная модель, для которой вы хотите приобрести Provisioned Throughput. Для тестирования точно настроенной модели перед развертыванием установите для единиц модели значение 1 и установите срок действия обязательства на Без обязательств. Это позволит вам быстро начать тестирование моделей с помощью собственных подсказок и проверить адекватность обучения. Более того, когда доступны новые точно настроенные модели и новые версии, вы можете обновлять предоставленную пропускную способность при условии, что вы обновляете ее другими версиями той же модели.

Результаты точной настройки
Для нашей задачи по настройке модели на собаке Роне и кошке Смиле эксперименты показали, что лучшими гиперпараметрами были 5,000 шагов с размером пакета 8 и скоростью обучения 1e-5.
Ниже приведены некоторые примеры изображений, созданных настроенной моделью.
 |
 |
 |
| Пес Рон в плаще супергероя | Пес Рон на Луне | Пес Рон в бассейне в солнечных очках |
 |
 |
 |
| Кот Смила на снегу | Кот Смила в черно-белом цвете смотрит в камеру | Кот Смила в рождественской шапке |
Заключение
В этом посте мы обсудили, когда следует использовать тонкую настройку вместо разработки подсказок для создания изображений более высокого качества. Мы показали, как точно настроить модель Amazon Titan Image Generator и развернуть пользовательскую модель на Amazon Bedrock. Мы также предоставили общие рекомендации о том, как подготовить данные для тонкой настройки и установить оптимальные гиперпараметры для более точной настройки модели.
В качестве следующего шага вы можете адаптировать следующее пример в соответствии с вашим вариантом использования для создания гиперперсонализированных изображений с помощью генератора изображений Amazon Titan.
Об авторах
 Майра Ладейра Танке — старший специалист по данным генеративного искусственного интеллекта в AWS. Имея опыт работы в области машинного обучения, она имеет более чем 10-летний опыт проектирования и создания приложений искусственного интеллекта с клиентами из разных отраслей. В качестве технического руководителя она помогает клиентам ускорить достижение ими бизнес-ценности с помощью генеративных решений искусственного интеллекта на Amazon Bedrock. В свободное время Майра любит путешествовать, играть со своей кошкой Смилой и проводить время с семьей в теплом месте.
Майра Ладейра Танке — старший специалист по данным генеративного искусственного интеллекта в AWS. Имея опыт работы в области машинного обучения, она имеет более чем 10-летний опыт проектирования и создания приложений искусственного интеллекта с клиентами из разных отраслей. В качестве технического руководителя она помогает клиентам ускорить достижение ими бизнес-ценности с помощью генеративных решений искусственного интеллекта на Amazon Bedrock. В свободное время Майра любит путешествовать, играть со своей кошкой Смилой и проводить время с семьей в теплом месте.
 Дэни Митчелл — специалист по архитектуре решений искусственного интеллекта и машинного обучения в Amazon Web Services. Он занимается сценариями использования компьютерного зрения и помогает клиентам в регионе EMEA ускорить внедрение машинного обучения.
Дэни Митчелл — специалист по архитектуре решений искусственного интеллекта и машинного обучения в Amazon Web Services. Он занимается сценариями использования компьютерного зрения и помогает клиентам в регионе EMEA ускорить внедрение машинного обучения.
 Бхарати Шринивасан работает специалистом по данным в AWS Professional Services, где ей нравится создавать интересные вещи на Amazon Bedrock. Она увлечена повышением эффективности бизнеса с помощью приложений машинного обучения, уделяя особое внимание ответственному искусственному интеллекту. Помимо создания новых возможностей искусственного интеллекта для клиентов, Бхарати любит писать научную фантастику и заниматься спортом на выносливость.
Бхарати Шринивасан работает специалистом по данным в AWS Professional Services, где ей нравится создавать интересные вещи на Amazon Bedrock. Она увлечена повышением эффективности бизнеса с помощью приложений машинного обучения, уделяя особое внимание ответственному искусственному интеллекту. Помимо создания новых возможностей искусственного интеллекта для клиентов, Бхарати любит писать научную фантастику и заниматься спортом на выносливость.
 Ачин Джайн — учёный-прикладник в команде Amazon по искусственному интеллекту (AGI). Он имеет опыт работы с моделями преобразования текста в изображение и занимается созданием генератора изображений Amazon Titan.
Ачин Джайн — учёный-прикладник в команде Amazon по искусственному интеллекту (AGI). Он имеет опыт работы с моделями преобразования текста в изображение и занимается созданием генератора изображений Amazon Titan.
- SEO-контент и PR-распределение. Получите усиление сегодня.
- PlatoData.Network Вертикальный генеративный ИИ. Расширьте возможности себя. Доступ здесь.
- ПлатонАйСтрим. Интеллект Web3. Расширение знаний. Доступ здесь.
- ПлатонЭСГ. Углерод, чистые технологии, Энергия, Окружающая среда, Солнечная, Управление отходами. Доступ здесь.
- ПлатонЗдоровье. Биотехнологии и клинические исследования. Доступ здесь.
- Источник: https://aws.amazon.com/blogs/machine-learning/fine-tune-your-amazon-titan-image-generator-g1-model-using-amazon-bedrock-model-customization/

