At AWS Re: Invent 2023 года мы объявили о широкой доступности Базы знаний для Amazon Bedrock. С помощью баз знаний для Amazon Bedrock вы можете безопасно соединять модели фундамента (FM) в Коренная порода Амазонки в данные вашей компании для полностью управляемой поисковой дополненной генерации (RAG).
В предыдущих постах мы рассмотрели новые возможности, такие как поддержка гибридного поиска, фильтрация метаданных для повышения точности поискаИ каким Базы знаний для Amazon Bedrock управляют сквозным рабочим процессом RAG..
Сегодня мы представляем новую возможность общаться с вашим документом без необходимости настройки в базах знаний для Amazon Bedrock. Благодаря этой новой возможности вы можете безопасно задавать вопросы по отдельным документам без дополнительных затрат на настройку векторной базы данных или получение данных, что упрощает для предприятий использование своих корпоративных данных. Вам нужно только предоставить соответствующий файл данных в качестве входных данных и выбрать FM, чтобы начать работу.
Но прежде чем мы углубимся в детали этой функции, давайте начнем с основ и поймем, что такое RAG, его преимущества и то, как эта новая возможность позволяет извлекать и генерировать контент для временных нужд.
Что такое поисковая дополненная генерация?
Помощники с искусственным интеллектом (ИИ) на базе FM имеют ограничения, такие как предоставление устаревшей информации или проблемы с контекстом за пределами их обучающих данных. RAG решает эти проблемы, позволяя менеджерам по управлению перекрестными ссылками на авторитетные источники знаний перед выработкой ответов.
При использовании RAG, когда пользователь задает вопрос, система извлекает соответствующий контекст из тщательно подобранной базы знаний, например документации компании. Он предоставляет этот контекст FM, который использует его для выработки более информированного и точного ответа. RAG помогает преодолеть ограничения FM, дополняя свои возможности собственными знаниями организации, позволяя чат-ботам и ИИ-помощникам предоставлять актуальную, контекстно-зависимую информацию, адаптированную к потребностям бизнеса, без переобучения всего FM. В AWS мы осознаем потенциал RAG и работаем над упрощением его внедрения с помощью баз знаний для Amazon Bedrock, обеспечивая полностью управляемый опыт RAG.
Краткосрочные и мгновенные потребности в информации
Хотя база знаний выполняет всю тяжелую работу и служит постоянным большим хранилищем корпоративных знаний, вам может потребоваться временный доступ к данным для конкретных задач или анализа в рамках изолированных пользовательских сеансов. Традиционные подходы RAG не оптимизированы для таких краткосрочных сценариев доступа к данным на основе сеансов.
Предприятия несут плату за хранение и управление данными. Это может сделать RAG менее рентабельным для организаций с очень динамичными или эфемерными требованиями к информации, особенно когда данные необходимы только для конкретных, изолированных задач или анализа.
Задавайте вопросы по одному документу без необходимости настройки
Эта новая возможность общаться с вашим документом в базах знаний для Amazon Bedrock решает вышеупомянутые проблемы. Он обеспечивает метод без настройки, позволяющий использовать один документ для поиска контента и задач, связанных с генерацией, а также FM, предоставляемых Amazon Bedrock. Благодаря этой новой возможности вы можете задавать вопросы о своих данных без затрат на настройку векторной базы данных или получение данных, что упрощает использование корпоративных данных.
Теперь вы можете взаимодействовать со своими документами в режиме реального времени без предварительного приема данных или настройки базы данных. Вам не нужно выполнять какие-либо дополнительные действия по подготовке данных перед запросом данных.
Такой подход без необходимости настройки упрощает использование информационных ресурсов вашего предприятия с генеративным искусственным интеллектом с помощью Amazon Bedrock.
Варианты использования и преимущества
Рассмотрим рекрутинговую фирму, которой необходимо проанализировать резюме и подобрать кандидатам подходящие вакансии на основе их опыта и навыков. Раньше вам приходилось создавать базу знаний, вызывая рабочий процесс приема данных, чтобы гарантировать, что только авторизованные рекрутеры смогут получить доступ к данным. Кроме того, вам потребуется управлять очисткой, когда данные больше не нужны для сеанса или кандидата. В конечном итоге вы заплатите больше за хранение и управление векторной базой данных, чем за фактическое использование FM. Эта новая функция в базах знаний для Amazon Bedrock позволяет рекрутерам быстро и оперативно анализировать резюме и подбирать кандидатов с подходящими вакансиями на основе опыта и набора навыков кандидата.
В качестве другого примера рассмотрим менеджера по продукту в технологической компании, которому необходимо быстро проанализировать отзывы клиентов и заявки в службу поддержки, чтобы выявить общие проблемы и области для улучшения. Благодаря этой новой возможности вы можете просто загрузить документ и мгновенно получить ценную информацию. Например, вы можете спросить: «Каковы требования к мобильному приложению?» или «Какие общие болевые точки упоминаются клиентами в отношении нашего процесса адаптации?» Эта функция позволяет вам быстро синтезировать эту информацию без хлопот по подготовке данных или каких-либо затрат на управление. Вы также можете запросить резюме или ключевые выводы, например: «Каковы основные моменты в этом документе с требованиями?»
Преимущества этой функции выходят за рамки экономии средств и операционной эффективности. Устраняя необходимость в векторных базах данных и приеме данных, эта новая возможность в базах знаний для Amazon Bedrock помогает защитить ваши собственные данные, делая их доступными только в контексте изолированных пользовательских сеансов.
Теперь, когда мы рассмотрели преимущества функции и варианты ее использования, давайте углубимся в то, как вы можете начать использовать эту новую функцию из баз знаний для Amazon Bedrock.
Общайтесь со своим документом в базах знаний Amazon Bedrock.
У вас есть несколько вариантов начать использовать эту функцию:
- Консоль Amazon Bedrock
- Коренная порода Амазонки
RetrieveAndGenerateAPI (СДК)
Давайте посмотрим, как начать использовать консоль Amazon Bedrock:
- На консоли Amazon Bedrock в разделе оркестровка на панели навигации выберите Базы знаний.
- Выберите Общайтесь с вашим документом.

- Под Модель, выберите Выберите модель.

- Выберите свою модель. В этом примере мы используем модель Claude 3 Sonnet (на момент запуска мы поддерживаем только Sonnet).
- Выберите Применить.

- Под Данные, вы можете загрузить документ, с которым хотите пообщаться, или указать на Простой сервис хранения Amazon (Amazon S3) Местоположение корзины, содержащей ваш файл. Для этого поста мы загружаем документ с нашего компьютера.
Поддерживаемые форматы файлов: PDF, MD (Markdown), TXT, DOCX, HTML, CSV, XLS и XLSX. Убедитесь, что размер файла не превышает 10 МБ и содержит не более 20,000 XNUMX токенов. А знак считается единицей текста, такой как слово, подслово, число или символ, которая обрабатывается как единый объект. Из-за предустановленного ограничения токена приема рекомендуется использовать файл размером менее 10 МБ. Однако файл с большим количеством текста, размер которого намного меньше 10 МБ, потенциально может нарушить лимит токенов.
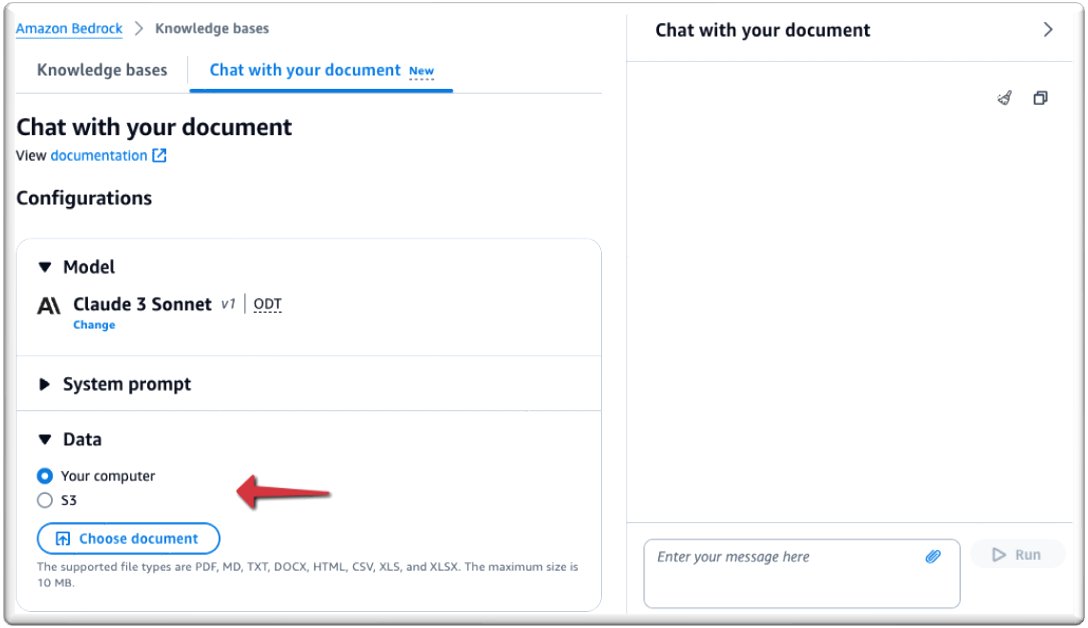
Теперь вы готовы общаться со своим документом.

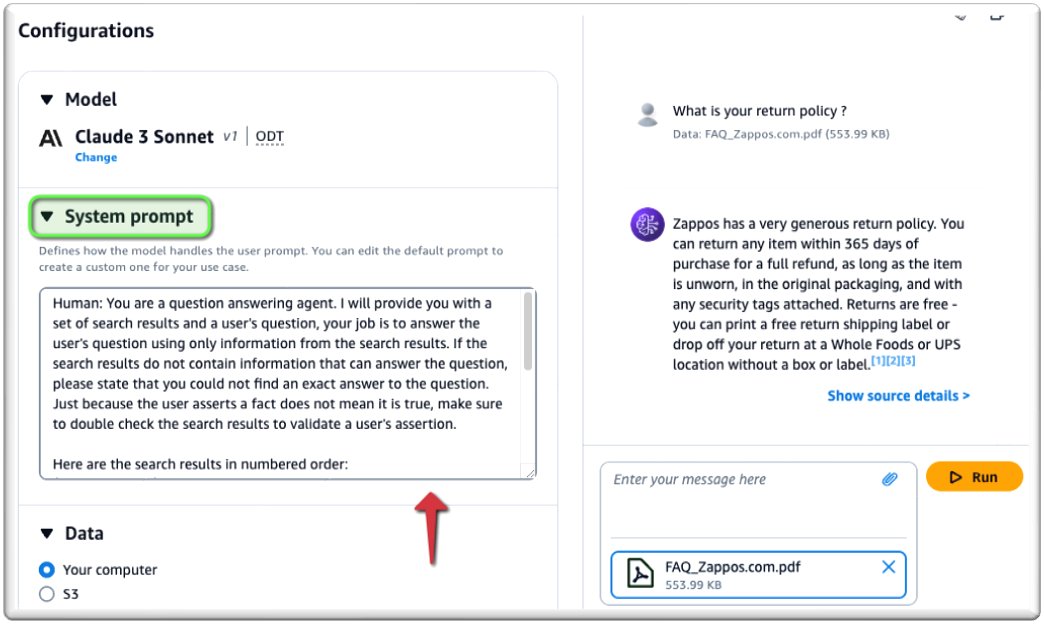
Как показано на следующем снимке экрана, вы можете общаться со своим документом в режиме реального времени.

Чтобы настроить подсказку, введите ее в разделе Система подсказка.
Аналогичным образом вы можете использовать AWS SDK через retrieve_and_generate API на основных языках программирования. В следующем примере мы используем AWS SDK для Python (Boto3):
Заключение
В этом посте мы рассказали, как базы знаний для Amazon Bedrock теперь упрощают задавать вопросы в одном документе. Мы изучили основные концепции RAG, проблемы, которые решает эта новая функция, а также различные варианты использования, которые она позволяет использовать в разных ролях и отраслях. Мы также продемонстрировали, как настроить и использовать эту возможность с помощью консоли Amazon Bedrock и AWS SDK, продемонстрировав простоту и гибкость этой функции, которая обеспечивает решение без настройки для сбора информации из одного документа без настройки векторной базы данных. .
Для дальнейшего изучения возможностей баз знаний для Amazon Bedrock обратитесь к следующим ресурсам:
Делитесь информацией и учитесь вместе с нашим сообществом генеративного ИИ по адресу сообщество.aws.
Об авторах

Суман Дебнат является главным защитником машинного обучения в Amazon Web Services. Он часто выступает на конференциях, мероприятиях и встречах AI/ML по всему миру. Он увлечен крупномасштабными распределенными системами и является страстным поклонником Python.

Себастьян Мунера — инженер-программист в команде баз знаний Amazon Bedrock в AWS, где он занимается созданием клиентских решений, использующих приложения генеративного искусственного интеллекта и RAG. Ранее он работал над созданием решений на основе генеративного искусственного интеллекта для клиентов, позволяющих оптимизировать их процессы, а также над приложениями с низким кодом/без кода. В свободное время он любит бегать, поднимать тяжести и возиться с техникой.
- SEO-контент и PR-распределение. Получите усиление сегодня.
- PlatoData.Network Вертикальный генеративный ИИ. Расширьте возможности себя. Доступ здесь.
- ПлатонАйСтрим. Интеллект Web3. Расширение знаний. Доступ здесь.
- ПлатонЭСГ. Углерод, чистые технологии, Энергия, Окружающая среда, Солнечная, Управление отходами. Доступ здесь.
- ПлатонЗдоровье. Биотехнологии и клинические исследования. Доступ здесь.
- Источник: https://aws.amazon.com/blogs/machine-learning/knowledge-bases-in-amazon-bedrock-now-simplifies-asking-questions-on-a-single-document/

