În managementul activelor, managerii de portofoliu trebuie să monitorizeze îndeaproape companiile din universul lor de investiții pentru a identifica riscurile și oportunitățile și pentru a ghida deciziile de investiții. Urmărirea evenimentelor directe, cum ar fi rapoartele de câștig sau reducerile de credit, este simplă – puteți configura alerte pentru a notifica managerii știri care conțin nume de companii. Cu toate acestea, detectarea impacturilor de ordinul al doilea și al treilea care decurg din evenimente la furnizori, clienți, parteneri sau alte entități din ecosistemul unei companii este o provocare.
De exemplu, o întrerupere a lanțului de aprovizionare la un furnizor-cheie ar avea probabil un impact negativ pe producătorii din aval. Sau pierderea unui client de top pentru un client major prezintă un risc de cerere pentru furnizor. De foarte multe ori, astfel de evenimente nu reușesc să facă titluri în care apar compania afectată în mod direct, dar sunt totuși importante să le acordați atenție. În această postare, demonstrăm o soluție automată care combină grafice de cunoștințe și inteligență artificială generativă (AI) pentru a evidenția astfel de riscuri prin încrucișarea hărților de relații cu știrile în timp real.
În linii mari, aceasta implică doi pași: În primul rând, construirea relațiilor complicate dintre companii (clienți, furnizori, directori) într-un grafic de cunoștințe. În al doilea rând, utilizarea acestei baze de date grafice împreună cu AI generativă pentru a detecta impactul de ordinul al doilea și al treilea din evenimentele de știri. De exemplu, această soluție poate evidenția faptul că întârzierile la un furnizor de piese pot perturba producția pentru producătorii auto din aval dintr-un portofoliu, deși niciunul nu este referit direct.
Cu AWS, puteți implementa această soluție într-o arhitectură fără server, scalabilă și complet bazată pe evenimente. Această postare demonstrează o dovadă de concept construită pe două servicii cheie AWS, potrivite pentru reprezentarea cunoștințelor grafice și procesarea limbajului natural: Amazon Neptun și Amazon Bedrock. Neptune este un serviciu de baze de date grafice rapid, fiabil și complet gestionat, care facilitează construirea și rularea aplicațiilor care funcționează cu seturi de date foarte conectate. Amazon Bedrock este un serviciu complet gestionat care oferă o gamă de modele de fundație (FM) de înaltă performanță de la companii de IA de vârf precum AI21 Labs, Anthropic, Cohere, Meta, Stability AI și Amazon printr-un singur API, împreună cu un set larg de capabilități de a construi aplicații AI generative cu securitate, confidențialitate și AI responsabilă.
În general, acest prototip demonstrează arta posibilității cu grafice de cunoștințe și AI generativă - obținând semnale prin conectarea punctelor disparate. Recomandarea pentru profesioniștii în investiții este capacitatea de a rămâne la curent cu evoluțiile mai aproape de semnal, evitând în același timp zgomotul.
Construiți graficul cunoștințelor
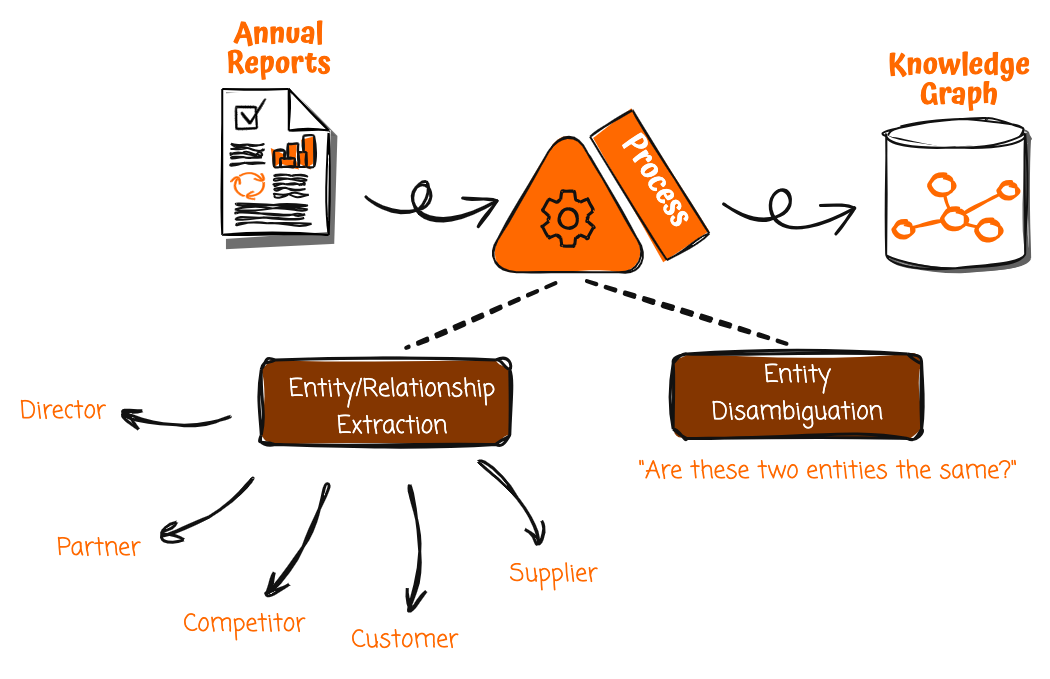
Primul pas în această soluție este construirea unui grafic de cunoștințe, iar o sursă de date valoroasă, dar adesea trecută cu vederea pentru graficele de cunoștințe, sunt rapoartele anuale ale companiei. Deoarece publicațiile oficiale corporative sunt supuse controlului înainte de lansare, informațiile pe care le conțin este probabil să fie exacte și de încredere. Cu toate acestea, rapoartele anuale sunt scrise într-un format nestructurat destinat citirii umane, mai degrabă decât consumului de mașini. Pentru a le debloca potențialul, aveți nevoie de o modalitate de a extrage și structura sistematic bogăția de fapte și relații pe care le conțin.
Cu servicii AI generative precum Amazon Bedrock, acum aveți capacitatea de a automatiza acest proces. Puteți să luați un raport anual și să declanșați o conductă de procesare pentru a asimila raportul, a-l împărți în bucăți mai mici și a aplica înțelegerea limbajului natural pentru a scoate entități și relații importante.
De exemplu, o propoziție care spune că „[Compania A] și-a extins flota europeană de livrare electrică cu o comandă pentru 1,800 de dubițe electrice de la [Compania B]” ar permite Amazon Bedrock să identifice următoarele:
- [Compania A] ca client
- [Compania B] ca furnizor
- O relație de furnizor între [Compania A] și [Compania B]
- Detalii despre relația „furnizorului de furgonete electrice de livrare”
Extragerea unor astfel de date structurate din documente nestructurate necesită furnizarea de solicitări elaborate cu atenție către modele lingvistice mari (LLM), astfel încât acestea să poată analiza text pentru a scoate entități precum companii și oameni, precum și relații precum clienți, furnizori și multe altele. Solicitările conțin instrucțiuni clare despre ce să căutați și structura în care să returnați datele. Repetând acest proces pe întregul raport anual, puteți extrage entitățile și relațiile relevante pentru a construi un grafic bogat de cunoștințe.
Cu toate acestea, înainte de a trimite informațiile extrase în graficul de cunoștințe, trebuie mai întâi să dezambiguizezi entitățile. De exemplu, poate exista deja o altă entitate „[Compania A]” în graficul de cunoștințe, dar ar putea reprezenta o altă organizație cu același nume. Amazon Bedrock poate argumenta și compara atribute cum ar fi domeniul de interes al afacerii, industria și industriile generatoare de venituri și relațiile cu alte entități pentru a determina dacă cele două entități sunt de fapt distincte. Acest lucru previne fuzionarea incorectă a companiilor neafiliate într-o singură entitate.
După ce dezambiguizarea este completă, puteți adăuga în mod fiabil noi entități și relații în graficul de cunoștințe Neptune, îmbogățindu-l cu faptele extrase din rapoartele anuale. De-a lungul timpului, asimilarea de date fiabile și integrarea unor surse de date mai fiabile vor ajuta la construirea unui grafic cuprinzător de cunoștințe care poate sprijini informații revelatoare prin interogări și analize grafice.
Această automatizare activată de AI generativă face posibilă procesarea a mii de rapoarte anuale și deblochează un activ neprețuit pentru curatarea graficelor de cunoștințe care altfel ar rămâne neexploatat din cauza efortului manual prohibitiv de mare necesar.
Următoarea captură de ecran arată un exemplu de explorare vizuală care este posibilă într-o bază de date grafică Neptune folosind Explorator grafic instrument.

Procesați articole de știri

Următorul pas al soluției este îmbogățirea automată a fluxurilor de știri ale managerilor de portofoliu și evidențierea articolelor relevante pentru interesele și investițiile acestora. Pentru fluxul de știri, managerii de portofoliu se pot abona la orice furnizor de știri terță parte prin intermediul Schimb de date AWS sau un alt API de știri la alegerea lor.
Când un articol de știri intră în sistem, este invocată o conductă de asimilare pentru a procesa conținutul. Folosind tehnici similare procesării rapoartelor anuale, Amazon Bedrock este folosit pentru a extrage entități, atribute și relații din articolul de știri, care sunt apoi folosite pentru a dezambiguiza graficul de cunoștințe pentru a identifica entitatea corespunzătoare în graficul de cunoștințe.
Graficul de cunoștințe conține conexiuni între companii și oameni, iar prin conectarea entităților articol la nodurile existente, puteți identifica dacă vreun subiect se află la două ori de la companiile în care managerul de portofoliu a investit sau în care este interesat. Găsirea unei astfel de conexiuni indică faptul că articolul poate fi relevant pentru managerul de portofoliu și, deoarece datele de bază sunt reprezentate într-un grafic de cunoștințe, ele pot fi vizualizate pentru a ajuta managerul de portofoliu să înțeleagă de ce și cum este relevant acest context. Pe lângă identificarea conexiunilor la portofoliu, puteți utiliza și Amazon Bedrock pentru a efectua analize de sentiment asupra entităților la care se face referire.
Rezultatul final este un flux de știri îmbogățit care afișează articole care ar putea avea un impact asupra domeniilor de interes și investiții ale managerului de portofoliu.
Prezentare generală a soluțiilor
Arhitectura generală a soluției arată ca următoarea diagramă.
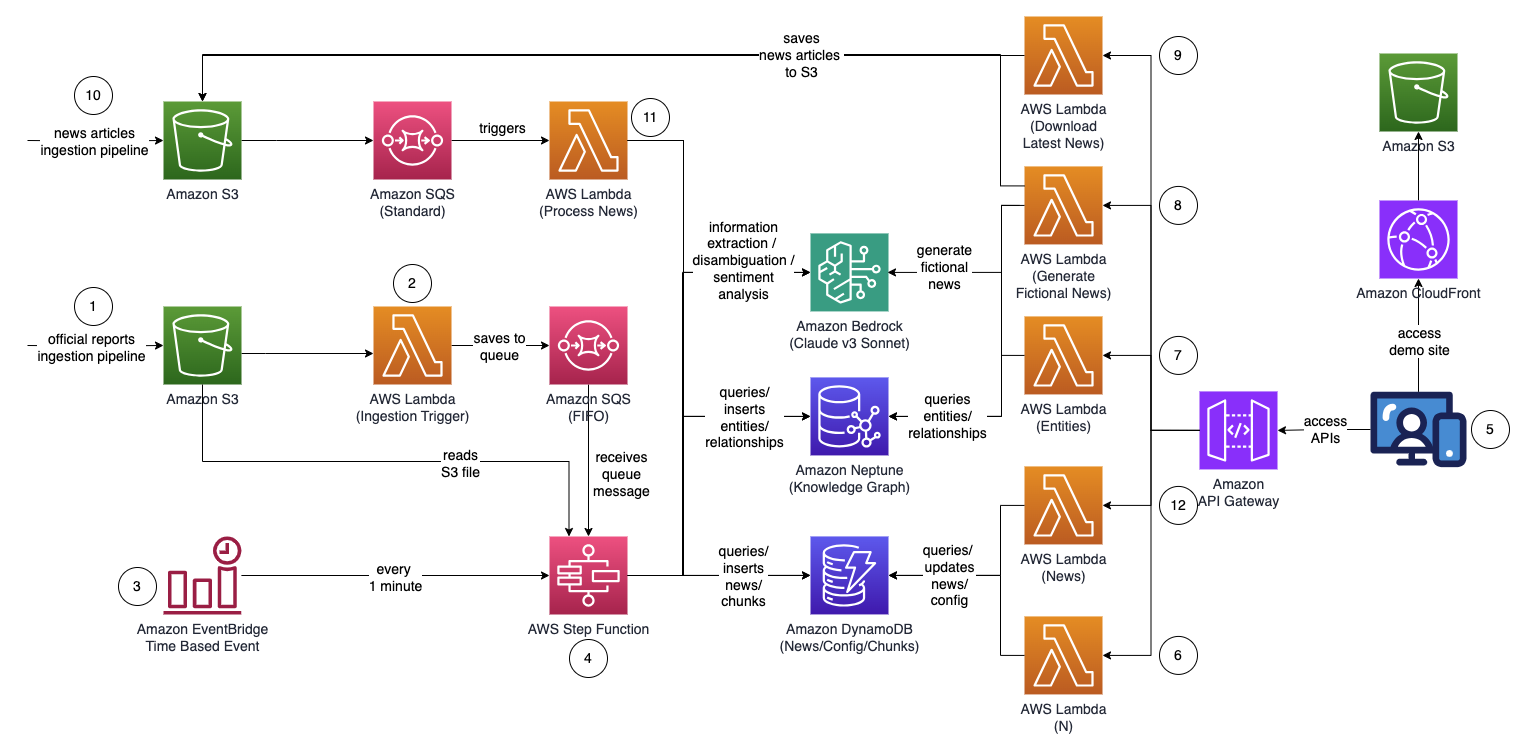
Fluxul de lucru constă din următorii pași:
- Un utilizator încarcă rapoarte oficiale (în format PDF) într-un Serviciul Amazon de stocare simplă (Amazon S3) găleată. Rapoartele ar trebui să fie rapoarte publicate oficial pentru a minimiza includerea datelor inexacte în graficul dvs. de cunoștințe (spre deosebire de știri și tabloide).
- Notificarea evenimentului S3 invocă un AWS Lambdas funcția, care trimite găleata S3 și numele fișierului la un Serviciul de coadă simplă Amazon coadă (Amazon SQS). Coada First-In-First-Out (FIFO) se asigură că procesul de asimilare a raportului este efectuat secvenţial pentru a reduce probabilitatea de a introduce date duplicat în graficul dvs. de cunoştinţe.
- An Amazon EventBridge evenimentul bazat pe timp rulează în fiecare minut pentru a începe rularea unui Funcții pas AWS mașina de stare asincronă.
- Mașina de stare Step Functions rulează o serie de sarcini pentru a procesa documentul încărcat, extragând informații cheie și inserându-le în graficul de cunoștințe:
- Primiți mesajul în coadă de la Amazon SQS.
- Descărcați fișierul raport PDF de pe Amazon S3, împărțiți-l în mai multe bucăți de text mai mici (aproximativ 1,000 de cuvinte) pentru procesare și stocați fragmentele de text în Amazon DynamoDB.
- Utilizați Sonnetul Claude v3 de la Anthropic pe Amazon Bedrock pentru a procesa primele câteva fragmente de text pentru a determina entitatea principală la care se referă raportul, împreună cu atributele relevante (cum ar fi industria).
- Preluați fragmentele de text din DynamoDB și pentru fiecare fragment de text, invocați o funcție Lambda pentru a extrage entitățile (cum ar fi compania sau persoana) și relația acesteia (client, furnizor, partener, concurent sau director) cu entitatea principală folosind Amazon Bedrock .
- Consolidați toate informațiile extrase.
- Filtrați zgomotul și entitățile irelevante (de exemplu, termeni generici precum „consumatori”) folosind Amazon Bedrock.
- Utilizați Amazon Bedrock pentru a efectua dezambiguizarea prin raționament folosind informațiile extrase în raport cu lista de entități similare din graficul de cunoștințe. Dacă entitatea nu există, introduceți-o. În caz contrar, utilizați entitatea care există deja în graficul de cunoștințe. Inserați toate relațiile extrase.
- Curățați prin ștergerea mesajului de coadă SQS și a fișierului S3.
- Un utilizator accesează o aplicație web bazată pe React pentru a vedea articolele de știri care sunt completate cu informații despre entitate, sentiment și calea conexiunii.
- Folosind aplicația web, utilizatorul specifică numărul de hopuri (implicit N=2) pe calea conexiunii de monitorizat.
- Folosind aplicația web, utilizatorul specifică lista de entități de urmărit.
- Pentru a genera știri fictive, utilizatorul alege Generați exemple de știri pentru a genera 10 mostre de articole de știri financiare cu conținut aleatoriu pentru a fi introduse în procesul de asimilare a știrilor. Conținutul este generat folosind Amazon Bedrock și este pur fictiv.
- Pentru a descărca știri reale, utilizatorul alege Descărcați cele mai recente știri pentru a descărca știrile de top care se întâmplă astăzi (produs de NewsAPI.org).
- Fișierul de știri (format TXT) este încărcat într-un bucket S3. Pașii 8 și 9 încarcă automat știri în compartimentul S3, dar puteți, de asemenea, să creați integrări la furnizorul dvs. de știri preferat, cum ar fi AWS Data Exchange sau orice furnizor de știri terță parte, pentru a trimite articole de știri ca fișiere în compartimentul S3. Conținutul fișierului de date de știri trebuie formatat ca
<date>{dd mmm yyyy}</date><title>{title}</title><text>{news content}</text>. - Notificarea evenimentului S3 trimite găleata S3 sau numele fișierului către Amazon SQS (standard), care invocă mai multe funcții Lambda pentru a procesa datele de știri în paralel:
- Utilizați Amazon Bedrock pentru a extrage entitățile menționate în știri, împreună cu orice informații, relații și sentimente conexe ale entității menționate.
- Verificați cu ajutorul graficului de cunoștințe și utilizați Amazon Bedrock pentru a efectua dezambiguizarea prin raționament folosind informațiile disponibile din știri și din cadrul graficului de cunoștințe pentru a identifica entitatea corespunzătoare.
- După ce entitatea a fost localizată, căutați și returnați toate căile de conectare care se conectează la entitățile marcate cu
INTERESTED=YESîn graficul de cunoștințe care sunt la N=2 hop distanță.
- Aplicația web se reîmprospătează automat la fiecare secundă pentru a scoate cel mai recent set de știri procesate pentru a fi afișat în aplicația web.
Implementați prototipul
Puteți implementa soluția prototip și puteți începe să experimentați singur. Prototipul este disponibil de la GitHub și include detalii despre următoarele:
- Cerințe preliminare de implementare
- Etape de implementare
- Pași de curățare
Rezumat
Această postare a demonstrat o soluție de dovadă a conceptului pentru a ajuta managerii de portofoliu să detecteze riscurile de ordinul doi și al treilea din evenimentele de știri, fără referințe directe la companiile pe care le urmăresc. Prin combinarea unui grafic de cunoștințe al relațiilor complicate ale companiei cu analiza în timp real a știrilor folosind AI generativă, pot fi evidențiate efectele din aval, cum ar fi întârzierile de producție din cauza sughițurilor furnizorilor.
Deși este doar un prototip, această soluție arată promisiunea graficelor de cunoștințe și modelelor de limbaj pentru a conecta puncte și a deriva semnale din zgomot. Aceste tehnologii pot ajuta profesioniștii în investiții prin dezvăluirea mai rapidă a riscurilor prin maparea relațiilor și raționament. În general, aceasta este o aplicație promițătoare a bazelor de date grafice și a IA, care justifică explorarea pentru a spori analiza investițiilor și luarea deciziilor.
Dacă acest exemplu de IA generativă în serviciile financiare este de interes pentru afacerea dvs. sau aveți o idee similară, contactați managerul de cont AWS și vom fi încântați să explorăm în continuare împreună cu dvs.
Despre autor
 Xan Huang este arhitect senior de soluții cu AWS și are sediul în Singapore. El lucrează cu instituții financiare importante pentru a proiecta și a construi soluții sigure, scalabile și foarte disponibile în cloud. În afara serviciului, Xan își petrece cea mai mare parte a timpului liber cu familia și fiind stăpânit de fiica lui de 3 ani. Îl poți găsi pe Xan LinkedIn.
Xan Huang este arhitect senior de soluții cu AWS și are sediul în Singapore. El lucrează cu instituții financiare importante pentru a proiecta și a construi soluții sigure, scalabile și foarte disponibile în cloud. În afara serviciului, Xan își petrece cea mai mare parte a timpului liber cu familia și fiind stăpânit de fiica lui de 3 ani. Îl poți găsi pe Xan LinkedIn.
- Distribuție de conținut bazat pe SEO și PR. Amplifică-te astăzi.
- PlatoData.Network Vertical Generative Ai. Împuterniciți-vă. Accesați Aici.
- PlatoAiStream. Web3 Intelligence. Cunoștințe amplificate. Accesați Aici.
- PlatoESG. carbon, CleanTech, Energie, Mediu inconjurator, Solar, Managementul deșeurilor. Accesați Aici.
- PlatoHealth. Biotehnologie și Inteligență pentru studii clinice. Accesați Aici.
- Sursa: https://aws.amazon.com/blogs/machine-learning/uncover-hidden-connections-in-unstructured-financial-data-with-amazon-bedrock-and-amazon-neptune/

