A resiliência desempenha um papel fundamental no desenvolvimento de qualquer carga de trabalho e IA generativa as cargas de trabalho não são diferentes. Existem considerações exclusivas ao projetar cargas de trabalho generativas de IA através de lentes de resiliência. Compreender e priorizar a resiliência é crucial para que as cargas de trabalho generativas de IA atendam aos requisitos de disponibilidade organizacional e continuidade dos negócios. Nesta postagem, discutimos as diferentes pilhas de uma carga de trabalho de IA generativa e quais devem ser essas considerações.
IA generativa full stack
Embora grande parte do entusiasmo em torno da IA generativa se concentre nos modelos, uma solução completa envolve pessoas, habilidades e ferramentas de vários domínios. Considere a imagem a seguir, que é uma visão da AWS da pilha de aplicativos emergentes a16z para grandes modelos de linguagem (LLMs).
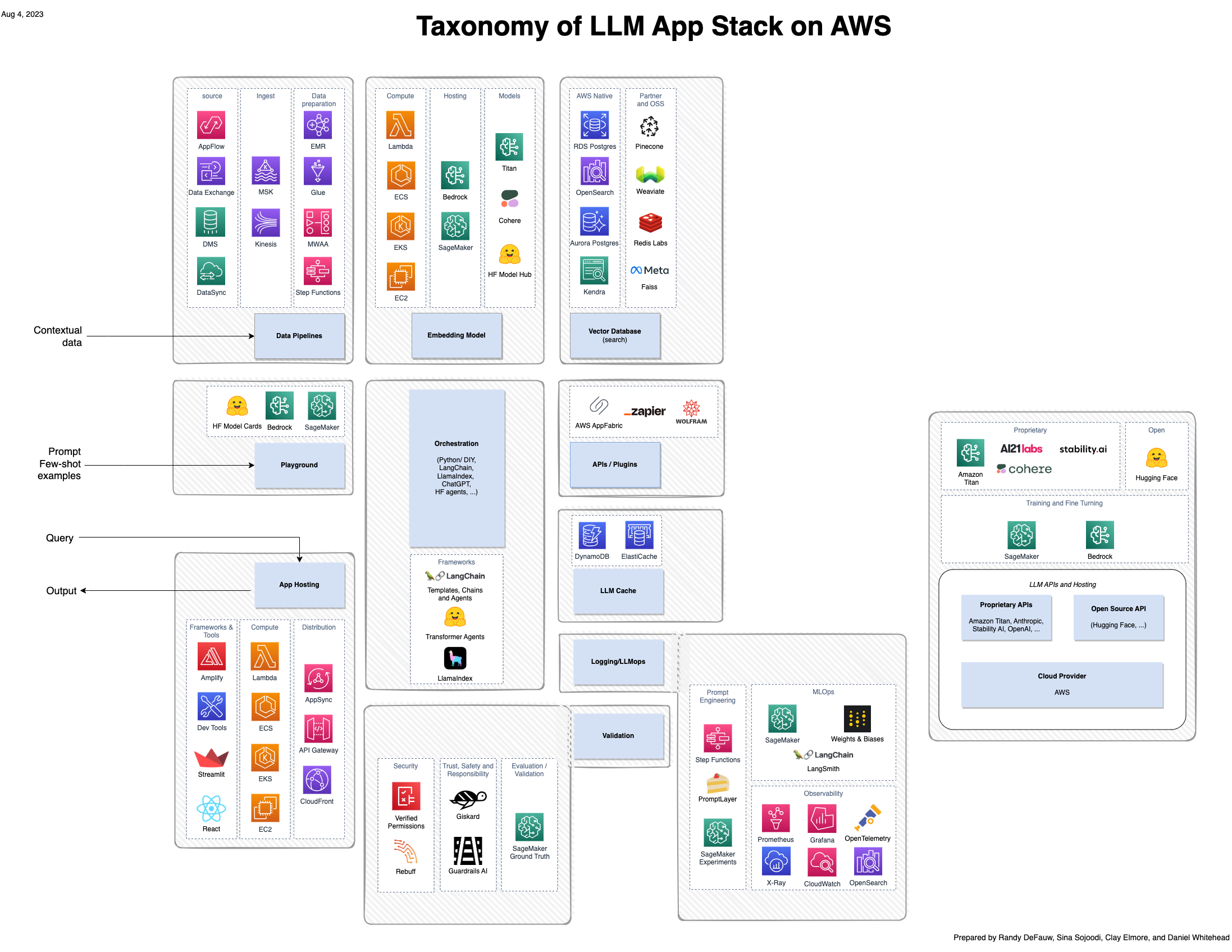
Em comparação com uma solução mais tradicional construída em torno de IA e aprendizado de máquina (ML), uma solução de IA generativa agora envolve o seguinte:
- Novos papéis – Você deve considerar sintonizadores de modelos, bem como construtores e integradores de modelos
- Novas ferramentas – A pilha MLOps tradicional não se estende para cobrir o tipo de rastreamento de experimento ou observabilidade necessária para engenharia imediata ou agentes que invocam ferramentas para interagir com outros sistemas
Raciocínio do agente
Ao contrário dos modelos tradicionais de IA, a Geração Aumentada de Recuperação (RAG) permite respostas mais precisas e contextualmente relevantes, integrando fontes de conhecimento externas. A seguir estão algumas considerações ao usar RAG:
- Definir tempos limite apropriados é importante para a experiência do cliente. Nada representa mais uma experiência ruim para o usuário do que estar no meio de um bate-papo e ser desconectado.
- Certifique-se de validar os dados de entrada do prompt e o tamanho da entrada do prompt para limites de caracteres alocados definidos pelo seu modelo.
- Se você estiver realizando engenharia de prompts, deverá persistir seus prompts em um armazenamento de dados confiável. Isso protegerá seus avisos em caso de perda acidental ou como parte de sua estratégia geral de recuperação de desastres.
Pipelines de dados
Nos casos em que você precisa fornecer dados contextuais ao modelo básico usando o padrão RAG, você precisa de um pipeline de dados que possa ingerir os dados de origem, convertê-los em vetores incorporados e armazenar os vetores incorporados em um banco de dados vetorial. Esse pipeline pode ser um pipeline em lote se você preparar dados contextuais com antecedência ou um pipeline de baixa latência se estiver incorporando novos dados contextuais dinamicamente. No caso do lote, existem alguns desafios em comparação com os pipelines de dados típicos.
As fontes de dados podem ser documentos PDF em um sistema de arquivos, dados de um sistema de software como serviço (SaaS), como uma ferramenta de CRM, ou dados de um wiki ou base de conhecimento existente. A ingestão dessas fontes é diferente das fontes de dados típicas, como dados de log em um Serviço de armazenamento simples da Amazon (Amazon S3) bucket ou dados estruturados de um banco de dados relacional. O nível de paralelismo que você pode alcançar pode ser limitado pelo sistema de origem, portanto, você precisa levar em conta a limitação e usar técnicas de espera. Alguns dos sistemas de origem podem ser frágeis, então você precisa incorporar o tratamento de erros e a lógica de novas tentativas.
O modelo de incorporação pode ser um gargalo de desempenho, independentemente de você executá-lo localmente no pipeline ou chamar um modelo externo. Modelos de incorporação são modelos básicos executados em GPUs e não possuem capacidade ilimitada. Se o modelo for executado localmente, será necessário atribuir trabalho com base na capacidade da GPU. Se o modelo for executado externamente, você precisará ter certeza de não estar saturando o modelo externo. Em ambos os casos, o nível de paralelismo que você pode alcançar será ditado pelo modelo de incorporação, e não pela quantidade de CPU e RAM disponíveis no sistema de processamento em lote.
No caso de baixa latência, é necessário levar em conta o tempo necessário para gerar os vetores de incorporação. O aplicativo de chamada deve invocar o pipeline de forma assíncrona.
Bancos de dados vetoriais
Um banco de dados vetorial tem duas funções: armazenar vetores incorporados e executar uma pesquisa por similaridade para encontrar o mais próximo. k corresponde a um novo vetor. Existem três tipos gerais de bancos de dados vetoriais:
- Opções de SaaS dedicadas, como Pinecone.
- Recursos de banco de dados vetorial integrados a outros serviços. Isso inclui serviços nativos da AWS como Serviço Amazon OpenSearch e Aurora Amazônica.
- Opções na memória que podem ser usadas para dados transitórios em cenários de baixa latência.
Não abordamos detalhadamente os recursos de pesquisa de similaridade nesta postagem. Embora sejam importantes, são um aspecto funcional do sistema e não afetam diretamente a resiliência. Em vez disso, nos concentramos nos aspectos de resiliência de um banco de dados vetorial como sistema de armazenamento:
- Latência – O banco de dados vetorial consegue ter um bom desempenho contra uma carga alta ou imprevisível? Caso contrário, o aplicativo de chamada precisará lidar com a limitação de taxa e a espera e tentar novamente.
- AMPLIAR – Quantos vetores o sistema pode conter? Se você exceder a capacidade do banco de dados vetorial, precisará analisar a fragmentação ou outras soluções.
- Alta disponibilidade e recuperação de desastres – A incorporação de vetores é um dado valioso e recriá-los pode ser caro. Seu banco de dados de vetores está altamente disponível em uma única região da AWS? Tem a capacidade de replicar dados para outra região para fins de recuperação de desastres?
Camada de aplicativo
Existem três considerações exclusivas para a camada de aplicação ao integrar soluções generativas de IA:
- Latência potencialmente alta – Os modelos básicos geralmente são executados em grandes instâncias de GPU e podem ter capacidade finita. Certifique-se de usar as práticas recomendadas para limitação de taxa, espera e nova tentativa e redução de carga. Use designs assíncronos para que a alta latência não interfira na interface principal do aplicativo.
- Postura de segurança – Se você estiver usando agentes, ferramentas, plug-ins ou outros métodos de conexão de um modelo a outros sistemas, preste atenção extra à sua postura de segurança. Os modelos podem tentar interagir com esses sistemas de maneiras inesperadas. Siga a prática normal de acesso com privilégios mínimos, por exemplo, restringindo prompts recebidos de outros sistemas.
- Estruturas em rápida evolução – Estruturas de código aberto como LangChain estão evoluindo rapidamente. Use uma abordagem de microsserviços para isolar outros componentes dessas estruturas menos maduras.
Capacidade
Podemos pensar em capacidade em dois contextos: pipelines de dados de modelos de inferência e treinamento. A capacidade é uma consideração quando as organizações estão construindo seus próprios pipelines. Os requisitos de CPU e memória são dois dos maiores requisitos ao escolher instâncias para executar suas cargas de trabalho.
As instâncias que podem suportar cargas de trabalho generativas de IA podem ser mais difíceis de obter do que o tipo médio de instância de uso geral. A flexibilidade da instância pode ajudar na capacidade e no planejamento da capacidade. Dependendo da região da AWS em que você está executando sua carga de trabalho, diferentes tipos de instância estarão disponíveis.
Para as jornadas do usuário que são críticas, as organizações deverão considerar a reserva ou o pré-provisionamento de tipos de instância para garantir a disponibilidade quando necessário. Esse padrão atinge uma arquitetura estaticamente estável, que é uma prática recomendada de resiliência. Para saber mais sobre a estabilidade estática no pilar de confiabilidade do AWS Well-Architected Framework, consulte Use estabilidade estática para evitar comportamento bimodal.
Observabilidade
Além das métricas de recursos que você normalmente coleta, como utilização de CPU e RAM, você precisa monitorar de perto a utilização de GPU se hospedar um modelo em Amazon Sage Maker or Amazon Elastic Compute Nuvem (Amazon EC2). A utilização da GPU pode mudar inesperadamente se o modelo básico ou os dados de entrada mudarem, e ficar sem memória da GPU pode colocar o sistema em um estado instável.
Mais acima na pilha, você também desejará rastrear o fluxo de chamadas no sistema, capturando as interações entre agentes e ferramentas. Como a interface entre agentes e ferramentas é definida de forma menos formal do que um contrato de API, você deve monitorar esses rastreamentos não apenas para desempenho, mas também para capturar novos cenários de erro. Para monitorar o modelo ou agente em busca de riscos e ameaças à segurança, você pode usar ferramentas como Dever de guarda da Amazônia.
Você também deve capturar linhas de base de vetores incorporados, prompts, contexto e saída, e as interações entre eles. Se estes mudarem ao longo do tempo, poderá indicar que os utilizadores estão a utilizar o sistema de novas formas, que os dados de referência não estão a cobrir o espaço de perguntas da mesma forma, ou que o resultado do modelo é subitamente diferente.
A recuperação de desastres
Ter um plano de continuidade de negócios com uma estratégia de recuperação de desastres é essencial para qualquer carga de trabalho. As cargas de trabalho de IA generativa não são diferentes. Compreender os modos de falha aplicáveis à sua carga de trabalho ajudará a orientar sua estratégia. Se você estiver usando serviços gerenciados pela AWS para sua carga de trabalho, como Rocha Amazônica e SageMaker, verifique se o serviço está disponível na sua região de recuperação da AWS. No momento em que este livro foi escrito, esses serviços da AWS não oferecem suporte nativo à replicação de dados entre regiões da AWS, portanto, você precisa pensar em suas estratégias de gerenciamento de dados para recuperação de desastres e também pode precisar fazer ajustes em várias regiões da AWS.
Conclusão
Esta postagem descreveu como levar em consideração a resiliência ao construir soluções generativas de IA. Embora as aplicações de IA generativa tenham algumas nuances interessantes, os padrões de resiliência e as melhores práticas existentes ainda se aplicam. É apenas uma questão de avaliar cada parte de uma aplicação generativa de IA e aplicar as melhores práticas relevantes.
Para obter mais informações sobre IA generativa e seu uso com serviços da AWS, consulte os seguintes recursos:
Sobre os autores
 Jennifer Moran é arquiteto de soluções especialista em resiliência sênior da AWS e mora na cidade de Nova York. Ela tem uma formação diversificada, tendo trabalhado em diversas disciplinas técnicas, incluindo desenvolvimento de software, liderança ágil e DevOps, e é uma defensora das mulheres na tecnologia. Ela gosta de ajudar os clientes a projetar soluções resilientes para melhorar a postura de resiliência e fala publicamente sobre todos os tópicos relacionados à resiliência.
Jennifer Moran é arquiteto de soluções especialista em resiliência sênior da AWS e mora na cidade de Nova York. Ela tem uma formação diversificada, tendo trabalhado em diversas disciplinas técnicas, incluindo desenvolvimento de software, liderança ágil e DevOps, e é uma defensora das mulheres na tecnologia. Ela gosta de ajudar os clientes a projetar soluções resilientes para melhorar a postura de resiliência e fala publicamente sobre todos os tópicos relacionados à resiliência.
 Randy De Fauw é arquiteto de soluções principal sênior na AWS. Ele possui um MSEE pela Universidade de Michigan, onde trabalhou em visão computacional para veículos autônomos. Ele também possui MBA pela Colorado State University. Randy ocupou diversos cargos na área de tecnologia, desde engenharia de software até gerenciamento de produtos. Ele entrou no espaço de big data em 2013 e continua a explorar essa área. Ele está trabalhando ativamente em projetos na área de ML e fez apresentações em diversas conferências, incluindo Strata e GlueCon.
Randy De Fauw é arquiteto de soluções principal sênior na AWS. Ele possui um MSEE pela Universidade de Michigan, onde trabalhou em visão computacional para veículos autônomos. Ele também possui MBA pela Colorado State University. Randy ocupou diversos cargos na área de tecnologia, desde engenharia de software até gerenciamento de produtos. Ele entrou no espaço de big data em 2013 e continua a explorar essa área. Ele está trabalhando ativamente em projetos na área de ML e fez apresentações em diversas conferências, incluindo Strata e GlueCon.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/designing-generative-ai-workloads-for-resilience/

