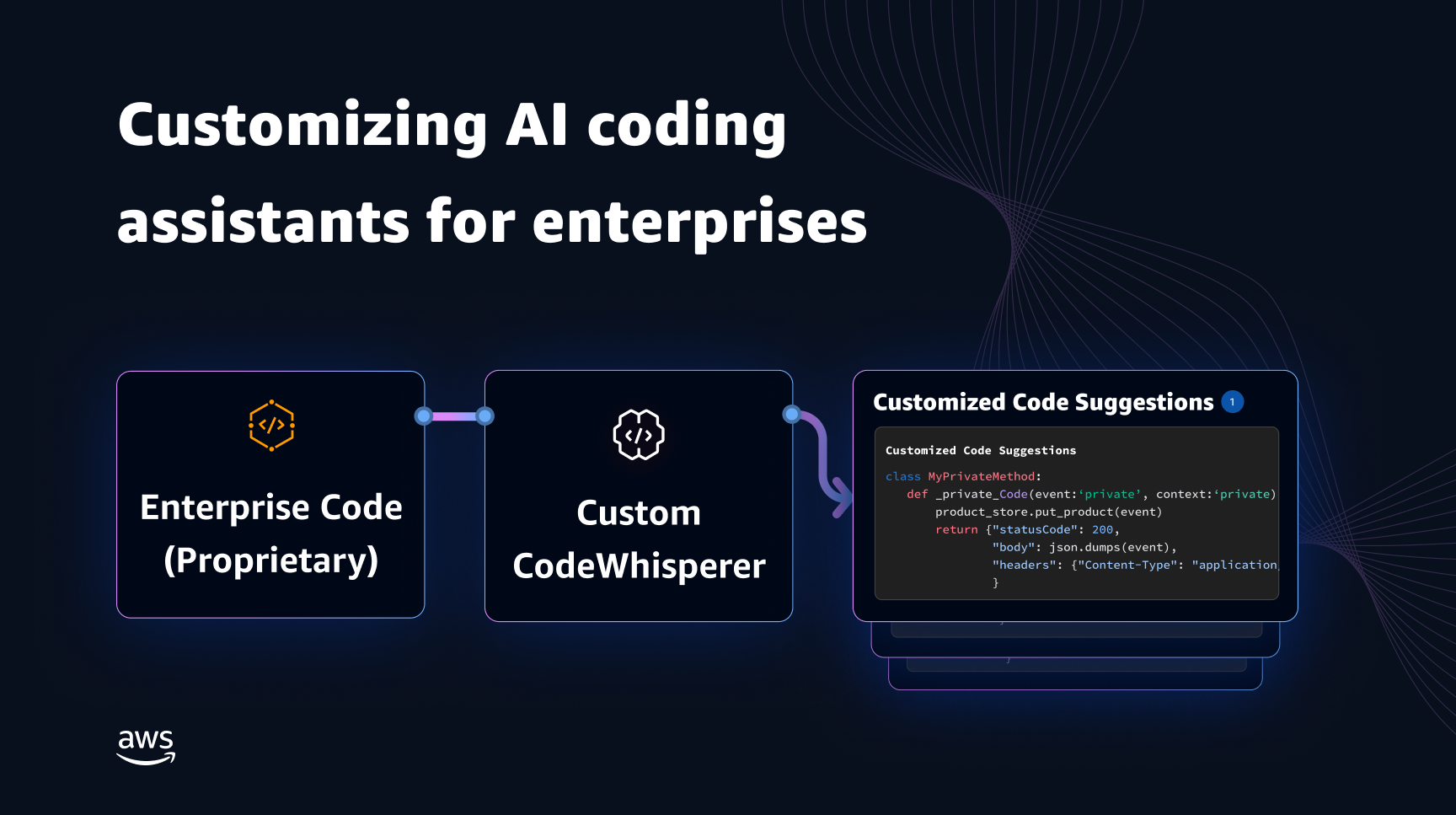
Os modelos generativos de IA para codificação complementar são treinados principalmente em código-fonte disponível publicamente e texto em linguagem natural. Embora o grande tamanho do corpus de treinamento permita que os modelos gerem código para funcionalidades comumente usadas, esses modelos desconhecem o código em repositórios privados e os estilos de codificação associados que são aplicados ao desenvolver com eles. Conseqüentemente, as sugestões geradas podem exigir reescritas antes de serem apropriadas para incorporação em um repositório interno.
Podemos resolver essa lacuna e minimizar a edição manual adicional incorporando conhecimento de código de repositórios privados em um modelo de linguagem treinado em código público. É por isso que desenvolvemos uma capacidade de personalização para Sussurrador de Código da Amazon. Nesta postagem, mostramos duas maneiras possíveis de personalizar companheiros de codificação usando geração aumentada de recuperação e ajuste fino.
Nosso objetivo com o recurso de personalização do CodeWhisperer é permitir que as organizações adaptem o modelo CodeWhisperer usando seus repositórios e bibliotecas privadas para gerar recomendações de código específicas da organização que economizem tempo, sigam o estilo e as convenções organizacionais e evitem bugs ou vulnerabilidades de segurança. Isso beneficia o desenvolvimento de software empresarial e ajuda a superar os seguintes desafios:
- Documentação ou informações esparsas para bibliotecas internas e APIs que forçam os desenvolvedores a gastar tempo examinando códigos previamente escritos para replicar o uso.
- Falta de consciência e consistência na implementação de práticas, estilos e padrões de codificação específicos da empresa.
- Uso inadvertido de código e APIs obsoletos por desenvolvedores.
Ao usar repositórios de código interno para treinamento adicional que já passaram por revisões de código, o modelo de linguagem pode revelar o uso de APIs internas e blocos de código que superam a lista de problemas anterior. Como o código de referência já foi revisado e atende aos padrões elevados do cliente, a probabilidade de introdução de bugs ou vulnerabilidades de segurança também é minimizada. E, ao selecionar cuidadosamente os arquivos de origem usados para personalização, as organizações podem reduzir o uso de código obsoleto.
Desafios de design
A personalização de sugestões de código com base nos repositórios privados de uma organização apresenta muitos desafios de design interessantes. A implantação de grandes modelos de linguagem (LLMs) para apresentar sugestões de código tem custos fixos de disponibilidade e custos variáveis devido à inferência baseada no número de tokens gerados. Portanto, ter personalizações separadas para cada cliente e hospedá-las individualmente, incorrendo assim em custos fixos adicionais, pode ser proibitivamente caro. Por outro lado, ter múltiplas personalizações simultaneamente no mesmo sistema exige uma infraestrutura multilocatária para isolar o código proprietário de cada cliente. Além disso, a capacidade de personalização deve exibir botões para permitir a seleção do subconjunto de treinamento apropriado do repositório interno usando diferentes métricas (por exemplo, arquivos com histórico de menos bugs ou código que foi recentemente confirmado no repositório). Ao selecionar o código com base nessas métricas, a customização pode ser treinada usando código de maior qualidade, o que pode melhorar a qualidade das sugestões de código. Finalmente, mesmo com repositórios de código em constante evolução, o custo associado à personalização deve ser mínimo para ajudar as empresas a obterem economias de custos decorrentes do aumento da produtividade do desenvolvedor.
Uma abordagem básica para a personalização da construção poderia ser pré-treinar o modelo em um único corpus de treinamento composto pelo conjunto de dados de pré-treinamento (público) existente junto com o código empresarial (privado). Embora esta abordagem funcione na prática, requer pré-formação individual (redundante) utilizando o conjunto de dados públicos de cada empresa. Também requer custos de implantação redundantes associados à hospedagem de um modelo personalizado para cada cliente que atenda apenas às solicitações dos clientes originadas desse cliente. Ao dissociar o treinamento de código público e privado e implantar a customização em um sistema multilocatário, esses custos redundantes podem ser evitados.
Como personalizar
Em alto nível, existem dois tipos de técnicas de customização possíveis: geração aumentada de recuperação (RAG) e ajuste fino (FT).
- Geração aumentada de recuperação: O RAG encontra trechos de código correspondentes em um repositório que é semelhante a um determinado fragmento de código (por exemplo, código que precede imediatamente o cursor no IDE) e aumenta o prompt usado para consultar o LLM com esses trechos de código correspondentes. Isso enriquece o prompt para ajudar a estimular o modelo a gerar um código mais relevante. Existem algumas técnicas exploradas na literatura nesse sentido. Ver Geração aumentada de recuperação para tarefas de PNL intensivas em conhecimento, REINO, kNN-LM e RETRO.

- Afinação: FT pega um LLM pré-treinado e o treina ainda mais em uma base de código específica e menor (em comparação com o conjunto de dados de pré-treinamento) para adaptá-lo ao repositório apropriado. O ajuste fino ajusta os pesos do LLM com base nesse treinamento, tornando-o mais adaptado às necessidades exclusivas da organização.
Tanto o RAG quanto o ajuste fino são ferramentas poderosas para melhorar o desempenho da personalização baseada em LLM. O RAG pode se adaptar rapidamente a bibliotecas privadas ou APIs com menor complexidade e custo de treinamento. No entanto, pesquisar e aumentar trechos de código recuperados para o prompt aumenta a latência em tempo de execução. Em vez disso, o ajuste fino não requer nenhum aumento do contexto porque o modelo já está treinado em bibliotecas e APIs privadas. No entanto, isso leva a custos de treinamento mais elevados e a complexidades no atendimento do modelo, quando vários modelos personalizados precisam ser suportados por vários clientes corporativos. Como discutiremos mais adiante, essas preocupações podem ser solucionadas otimizando ainda mais a abordagem.
Geração aumentada de recuperação
Existem algumas etapas envolvidas no RAG:
Indexação
Dado um repositório privado como entrada do administrador, um índice é criado dividindo os arquivos de código-fonte em partes. Simplificando, o chunking transforma os trechos de código em partes digeríveis que provavelmente serão mais informativas para o modelo e fáceis de recuperar, dado o contexto. O tamanho de um pedaço e como ele é extraído de um arquivo são escolhas de design que afetam o resultado final. Por exemplo, pedaços podem ser divididos com base em linhas de código ou em blocos sintáticos e assim por diante.
Fluxo de trabalho do administrador

Pesquisa contextual
Pesquise um conjunto de trechos de código indexados com base em algumas linhas de código acima do cursor e recupere trechos de código relevantes. Essa recuperação pode acontecer usando diferentes algoritmos. Essas opções podem incluir:
- Saco de palavras (BM25) - Uma função de recuperação de conjunto de palavras que classifica um conjunto de trechos de código com base nas frequências dos termos de consulta e nos comprimentos dos trechos de código.
Recuperação baseada em BM25

A figura a seguir ilustra como o BM25 funciona. Para usar o BM25, primeiro é construído um índice invertido. Esta é uma estrutura de dados que mapeia diferentes termos para os trechos de código em que esses termos ocorrem. No momento da pesquisa, procuramos trechos de código com base nos termos presentes na consulta e os pontuamos com base na frequência.
Recuperação semântica

O BM25 concentra-se na correspondência lexical. Portanto, substituir “adicionar” por “excluir” pode não alterar a pontuação do BM25 com base nos termos da consulta, mas a funcionalidade recuperada pode ser o oposto do que é necessário. Por outro lado, a recuperação semântica concentra-se na funcionalidade do trecho de código, mesmo que os nomes das variáveis e da API possam ser diferentes. Normalmente, uma combinação de BM25 e recuperações semânticas pode funcionar bem juntas para fornecer melhores resultados.
Inferência aumentada
Quando os desenvolvedores escrevem código, seu programa existente é usado para formular uma consulta que é enviada ao índice de recuperação. Depois de recuperar vários trechos de código usando uma das técnicas discutidas acima, nós os acrescentamos ao prompt original. Existem muitas opções de design aqui, incluindo o número de trechos a serem recuperados, o posicionamento relativo dos trechos no prompt e o tamanho do trecho. A escolha final do design é impulsionada principalmente pela observação empírica, explorando várias abordagens com o modelo de linguagem subjacente e desempenha um papel fundamental na determinação da precisão da abordagem. O conteúdo dos pedaços retornados e o código original são combinados e enviados ao modelo para obter sugestões de código customizadas.
Fluxo de trabalho do desenvolvedor

Afinação:
Afinação um modelo de linguagem é feito para transferir aprendizado em que os pesos de um modelo pré-treinado são treinados em novos dados. O objetivo é reter o conhecimento apropriado de um modelo já treinado em um grande corpus e refinar, substituir ou adicionar novo conhecimento do novo corpus — no nosso caso, uma nova base de código. Simplesmente treinar em uma nova base de código leva a esquecimento catastrófico. Por exemplo, o modelo de linguagem pode “esquecer” seu conhecimento de segurança ou as APIs que são pouco usadas na base de código empresarial até o momento. Existem diversas técnicas como experiência de repetição, GEM e PP-TF que são empregados para enfrentar esse desafio.
Afinação

Existem duas maneiras de fazer o ajuste fino. Uma abordagem é usar os dados adicionais sem aumentar o prompt para ajustar o modelo. Outra abordagem é aumentar o prompt durante o ajuste fino, recuperando sugestões de código relevantes. Isso ajuda a melhorar a capacidade do modelo de fornecer sugestões melhores na presença de trechos de código recuperados. O modelo é então avaliado em um conjunto de exemplos após ser treinado. Posteriormente, o modelo customizado é implantado e utilizado para gerar as sugestões de código.
Apesar das vantagens de usar LLMs dedicados para gerar código em repositórios privados, os custos podem ser proibitivos para organizações de pequeno e médio porte. Isso ocorre porque recursos computacionais dedicados são necessários, mesmo que possam ser subutilizados devido ao tamanho das equipes. Uma maneira de obter eficiência de custos é servir vários modelos na mesma computação (por exemplo, Multilocação do SageMaker). No entanto, os modelos de linguagem exigem uma ou mais GPUs dedicadas em diversas zonas para lidar com restrições de latência e taxa de transferência. Conseqüentemente, a multilocação de hospedagem de modelo completo em cada GPU é inviável.
Podemos superar esse problema atendendo vários clientes na mesma computação usando pequenas Adaptadores para o LLM. Técnicas de ajuste fino com eficiência de parâmetros (PEFT), como ajuste rápido, ajuste de prefixoe adaptação de baixa classificação (LoRA) são usados para reduzir custos de treinamento sem qualquer perda de precisão. LoRA, especialmente, obteve grande sucesso em alcançar precisão semelhante (ou melhor) do que o ajuste fino do modelo completo. A ideia básica é projetar uma matriz de classificação baixa que é então adicionada às matrizes com o peso da matriz original das camadas alvo do modelo. Normalmente, esses adaptadores são mesclados com os pesos do modelo original para veiculação. Isso leva ao mesmo tamanho e arquitetura da rede neural original. Mantendo os adaptadores separados, podemos servir o mesmo modelo básico com vários modelos de adaptadores. Isto traz de volta as economias de escala aos nossos clientes de pequeno e médio porte.
Adaptação de baixo escalão (LoRA)

Medindo a eficácia da personalização
Precisamos de métricas de avaliação para avaliar a eficácia da solução customizada. As métricas de avaliação off-line atuam como proteção contra personalizações de envio que estão abaixo da média em comparação com o modelo padrão. Ao construir conjuntos de dados a partir de um conjunto de dados mantido no repositório fornecido, a abordagem de personalização pode ser aplicada a esse conjunto de dados para medir a eficácia. Comparar o código-fonte existente com a sugestão de código customizado quantifica a utilidade da customização. Medidas comuns usadas para esta quantificação incluem métricas como editar semelhança, correspondência exata e CódigoBLEU.
Também é possível medir a utilidade quantificando a frequência com que APIs internas são invocadas pela customização e comparando-as com as invocações na fonte pré-existente. É claro que acertar ambos os aspectos é importante para uma conclusão bem-sucedida. Para nossa abordagem de customização, projetamos uma métrica personalizada conhecida como Índice de Qualidade de Customização (CQI), uma medida única e fácil de usar que varia entre 1 e 10. A métrica CQI mostra a utilidade das sugestões do modelo customizado em comparação com o código sugestões com um modelo público genérico.
Resumo
Construímos o recurso de personalização do Amazon CodeWhisperer com base em uma combinação das principais técnicas técnicas discutidas nesta postagem do blog e avaliamos isso com estudos de usuários sobre produtividade do desenvolvedor, conduzidos pela Persistent Systems. Nestes dois estudos, encomendados pela AWS, os desenvolvedores foram solicitados a criar um aplicativo de software médico em Java que exigisse o uso de suas bibliotecas internas. No primeiro estudo, os desenvolvedores sem acesso ao CodeWhisperer levaram (em média) aproximadamente 8.2 horas para concluir a tarefa, enquanto aqueles que usaram o CodeWhisperer (sem personalização) concluíram a tarefa 62% mais rápido em (em média) aproximadamente 3.1 horas.
No segundo estudo com um conjunto diferente de coortes de desenvolvedores, os desenvolvedores que usaram o CodeWhisperer que foi personalizado usando sua base de código privada concluíram a tarefa em média 2.5 horas, 28% mais rápido do que aqueles que usaram o CodeWhisperer sem personalização e concluíram a tarefa em aproximadamente 3.5 horas. horas em média. Acreditamos fortemente que ferramentas como o CodeWhisperer, que são personalizadas para sua base de código, têm um papel fundamental a desempenhar para aumentar ainda mais a produtividade do desenvolvedor e recomendamos que você experimente. Para mais informações e para começar, visite o Página do Amazon CodeWhisperer.
Sobre os autores
 Sol Qing é cientista aplicado sênior no AWS AI Labs e trabalha no AWS CodeWhisperer, um assistente de codificação generativo baseado em IA. Os seus interesses de investigação residem em Processamento de Linguagem Natural, AI4Code e IA generativa. No passado, ela trabalhou em vários serviços baseados em PNL, como Comprehend Medical, um sistema de diagnóstico médico da Amazon Health AI e sistema de tradução automática da Meta AI. Ela recebeu seu doutorado pela Virginia Tech em 2017.
Sol Qing é cientista aplicado sênior no AWS AI Labs e trabalha no AWS CodeWhisperer, um assistente de codificação generativo baseado em IA. Os seus interesses de investigação residem em Processamento de Linguagem Natural, AI4Code e IA generativa. No passado, ela trabalhou em vários serviços baseados em PNL, como Comprehend Medical, um sistema de diagnóstico médico da Amazon Health AI e sistema de tradução automática da Meta AI. Ela recebeu seu doutorado pela Virginia Tech em 2017.
 Arash Farahani é cientista aplicado do Amazon CodeWhisperer. Seus interesses atuais são IA generativa, pesquisa e personalização. Arash é apaixonado por criar soluções que resolvam os problemas dos desenvolvedores. Ele trabalhou em vários recursos do CodeWhisperer e introduziu soluções de PNL em vários fluxos de trabalho internos que afetam todos os desenvolvedores da Amazon. Ele recebeu seu PhD pela Universidade de Illinois em Urbana-Champaign em 2017.
Arash Farahani é cientista aplicado do Amazon CodeWhisperer. Seus interesses atuais são IA generativa, pesquisa e personalização. Arash é apaixonado por criar soluções que resolvam os problemas dos desenvolvedores. Ele trabalhou em vários recursos do CodeWhisperer e introduziu soluções de PNL em vários fluxos de trabalho internos que afetam todos os desenvolvedores da Amazon. Ele recebeu seu PhD pela Universidade de Illinois em Urbana-Champaign em 2017.
 Xiao Fei Ma é gerente de ciências aplicadas no AWS AI Labs. Ele ingressou na Amazon em 2016 como cientista aplicado na organização SCOT e, posteriormente, no AWS AI Labs em 2018, trabalhando no Amazon Kendra. Xiaofei atua como gerente científico de vários serviços, incluindo Kendra, Contact Lens e, mais recentemente, CodeWhisperer e CodeGuru Security. Os seus interesses de investigação situam-se na área de AI4Code e Processamento de Linguagem Natural. Ele recebeu seu PhD pela Universidade de Maryland, College Park em 2010.
Xiao Fei Ma é gerente de ciências aplicadas no AWS AI Labs. Ele ingressou na Amazon em 2016 como cientista aplicado na organização SCOT e, posteriormente, no AWS AI Labs em 2018, trabalhando no Amazon Kendra. Xiaofei atua como gerente científico de vários serviços, incluindo Kendra, Contact Lens e, mais recentemente, CodeWhisperer e CodeGuru Security. Os seus interesses de investigação situam-se na área de AI4Code e Processamento de Linguagem Natural. Ele recebeu seu PhD pela Universidade de Maryland, College Park em 2010.
 Murali Krishna Ramanathan é cientista aplicado principal no AWS AI Labs e co-líder do AWS CodeWhisperer, um companheiro de codificação generativo baseado em IA. Ele é apaixonado por criar ferramentas de software e fluxos de trabalho que ajudam a melhorar a produtividade do desenvolvedor. No passado, ele construiu a Piranha, uma ferramenta de refatoração automatizada para excluir código devido a sinalizadores de recursos obsoletos e liderou iniciativas de qualidade de código na engenharia da Uber. Ele recebeu o prêmio Google Docente (2015), o prêmio ACM SIGSOFT Distinguished paper (ISSTA 2016) e o prêmio Maurice Halstead (Purdue 2006). Ele recebeu seu PhD em Ciência da Computação pela Purdue University em 2008.
Murali Krishna Ramanathan é cientista aplicado principal no AWS AI Labs e co-líder do AWS CodeWhisperer, um companheiro de codificação generativo baseado em IA. Ele é apaixonado por criar ferramentas de software e fluxos de trabalho que ajudam a melhorar a produtividade do desenvolvedor. No passado, ele construiu a Piranha, uma ferramenta de refatoração automatizada para excluir código devido a sinalizadores de recursos obsoletos e liderou iniciativas de qualidade de código na engenharia da Uber. Ele recebeu o prêmio Google Docente (2015), o prêmio ACM SIGSOFT Distinguished paper (ISSTA 2016) e o prêmio Maurice Halstead (Purdue 2006). Ele recebeu seu PhD em Ciência da Computação pela Purdue University em 2008.
 Ramesh Nallapati é Cientista Aplicado Principal Sênior no AWS AI Labs e co-líder do CodeWhisperer, um companheiro de codificação generativo baseado em IA, e Titan Large Language Models na AWS. Os seus interesses centram-se principalmente nas áreas de Processamento de Linguagem Natural e IA Generativa. No passado, Ramesh forneceu liderança científica no fornecimento de muitos produtos AWS baseados em PNL, como Kendra, Quicksight Q e Contact Lens. Ele ocupou cargos de pesquisa em Stanford, CMU e IBM Research, e recebeu seu Ph.D. em Ciência da Computação pela Universidade de Massachusetts Amherst em 2006.
Ramesh Nallapati é Cientista Aplicado Principal Sênior no AWS AI Labs e co-líder do CodeWhisperer, um companheiro de codificação generativo baseado em IA, e Titan Large Language Models na AWS. Os seus interesses centram-se principalmente nas áreas de Processamento de Linguagem Natural e IA Generativa. No passado, Ramesh forneceu liderança científica no fornecimento de muitos produtos AWS baseados em PNL, como Kendra, Quicksight Q e Contact Lens. Ele ocupou cargos de pesquisa em Stanford, CMU e IBM Research, e recebeu seu Ph.D. em Ciência da Computação pela Universidade de Massachusetts Amherst em 2006.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/customizing-coding-companions-for-organizations/

