No cenário empresarial atual, as organizações procuram constantemente formas de otimizar os seus processos financeiros, aumentar a eficiência e gerar poupanças de custos. Uma área que apresenta um potencial significativo de melhoria é a das contas a pagar. Em alto nível, o processo de contas a pagar inclui recebimento e digitalização de faturas, extração de dados relevantes de faturas digitalizadas, validação, aprovação e arquivamento. A segunda etapa (extração) pode ser complexa. Cada fatura e recibo parecem diferentes. Os rótulos são imperfeitos e inconsistentes. As informações mais importantes, como preço, nome do fornecedor, endereço do fornecedor e condições de pagamento, muitas vezes não são explicitamente rotuladas e precisam ser interpretadas com base no contexto. A abordagem tradicional de usar revisores humanos para extrair os dados é demorada, sujeita a erros e não escalável.
Nesta postagem, mostramos como automatizar o processo de contas a pagar usando amazontext para extração de dados. Também fornecemos uma arquitetura de referência para construir um pipeline de automação de faturas que permite extração, verificação, arquivamento e pesquisa inteligente.
Visão geral da solução
O diagrama de arquitetura a seguir mostra os estágios de um fluxo de trabalho de processamento de recebimento e fatura. Começa com uma etapa de captura de documentos para coletar e armazenar com segurança faturas e recibos digitalizados. A próxima etapa é a fase de extração, onde você repassa as faturas e recibos coletados para o Amazon Textract AnalyzeExpense API para extrair relacionamentos relacionados financeiramente entre textos, como nome do fornecedor, data de recebimento da fatura, data do pedido, valor devido, valor pago e assim por diante. Na próxima etapa, você usa regras de despesas predefinidas para determinar se deve aprovar ou rejeitar automaticamente o recebimento. Os documentos aprovados e rejeitados vão para suas respectivas pastas dentro do Serviço de armazenamento simples da Amazon (Amazon S3) balde. Para documentos aprovados, você pode pesquisar todos os campos e valores extraídos usando Serviço Amazon OpenSearch. Você pode visualizar os metadados indexados usando OpenSearch Dashboards. Os documentos aprovados também são configurados para serem movidos para Camada inteligente do Amazon S3 para retenção e arquivamento de longo prazo usando políticas de ciclo de vida S3.
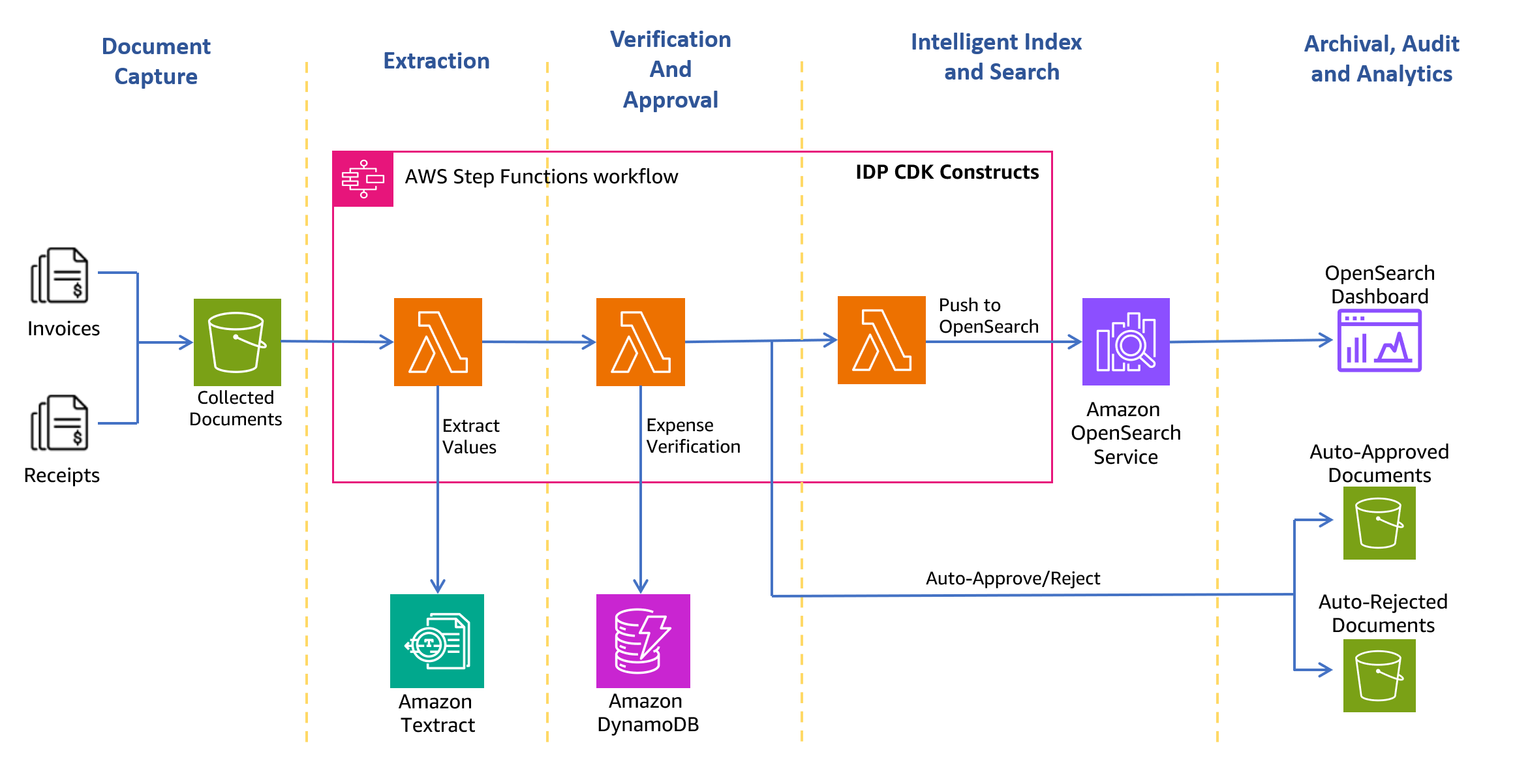
As seções a seguir orientam você no processo de criação da solução.
Pré-requisitos
Para implantar esta solução, você deve ter o seguinte:
- Uma conta da AWS.
- An Nuvem AWS9 ambiente. O AWS Cloud9 é um ambiente de desenvolvimento integrado (IDE) baseado em nuvem que permite escrever, executar e depurar seu código com apenas um navegador. Inclui um editor de código, depurador e terminal.
Para criar o ambiente AWS Cloud9, forneça um nome e uma descrição. Mantenha todo o resto como padrão. Escolha o link do IDE no console do AWS Cloud9 para navegar até o IDE. Agora você está pronto para usar o ambiente AWS Cloud9.
Implante a solução
Para configurar a solução, você usa o Kit de desenvolvimento em nuvem da AWS (AWS CDK) para implantar um Formação da Nuvem AWS pilha.
- No terminal IDE do AWS Cloud9, clone o Repositório GitHub e instale as dependências. Execute os seguintes comandos para implantar o
InvoiceProcessorpilha:
A implantação leva cerca de 25 minutos com as configurações padrão do repositório GitHub. Informações adicionais de saída também estão disponíveis no console do AWS CloudFormation.
- Após a conclusão da implantação do AWS CDK, crie regras de validação de despesas em um Amazon DynamoDB mesa. Você pode usar o mesmo terminal AWS Cloud9 para executar os seguintes comandos:
- No bucket S3 que começa com
invoiceprocessorworkflow-invoiceprocessorbucketf1-*, crie uma pasta de uploads.
In Amazon Cognito, você já deve ter um grupo de usuários existente chamado OpenSearchResourcesCognitoUserPool*. Usamos esse grupo de usuários para criar um novo usuário.
- No console do Amazon Cognito, navegue até o grupo de usuários
OpenSearchResourcesCognitoUserPool*. - Crie um novo usuário do Amazon Cognito.
- Forneça um nome de usuário e uma senha de sua escolha e anote-os para uso posterior.
- Carregue os documentos fatura_aleatória1 e fatura_aleatória2 para o S3
uploadspasta para iniciar os fluxos de trabalho.
Agora vamos nos aprofundar em cada uma das etapas de processamento de documentos.
Captura de documentos
Os clientes lidam com faturas e recibos em diversos formatos de diferentes fornecedores. Esses documentos são recebidos por meio de canais como cópias impressas, cópias digitalizadas enviadas para armazenamento de arquivos ou dispositivos de armazenamento compartilhados. Na fase de captura de documentos, você armazena todas as cópias digitalizadas de recibos e faturas em um armazenamento altamente escalável, como um bucket S3.
Processo de
A próxima etapa é a fase de extração, onde você repassa as faturas e recibos coletados para o Amazon Textract AnalyzeExpense API para extrair relacionamentos relacionados financeiramente entre textos, como nome do fornecedor, data de recebimento da fatura, data do pedido, valor devido/pago, etc.
Analisar Despesa é uma API dedicada ao processamento de documentos de faturas e recebimentos. Está disponível como API síncrona ou assíncrona. A API síncrona permite enviar imagens em formato de bytes, e a API assíncrona permite enviar arquivos nos formatos JPG, PNG, TIFF e PDF. O AnalyzeExpense A resposta da API consiste em três seções distintas:
- Campos de resumo – Esta seção inclui chaves normalizadas e as chaves mencionadas explicitamente junto com seus valores.
AnalyzeExpensenormaliza as chaves para informações relacionadas ao contato, como nome e endereço do fornecedor, chaves relacionadas ao ID fiscal, como ID do contribuinte, chaves relacionadas ao pagamento, como valor devido e desconto, e chaves gerais, como ID da fatura, data de entrega e número de conta. As chaves que não são normalizadas ainda aparecem nos campos de resumo como pares de valores-chave. Para obter uma lista completa dos campos de despesas suportados, consulte Análise de Faturas e Recibos. - Itens de linha – Esta seção inclui chaves de item de linha normalizadas, como descrição do item, preço unitário, quantidade e código do produto.
- Bloco de OCR – O bloco contém o extrato de texto bruto da página da fatura. A extração de texto bruto pode ser usada para pós-processamento e identificação de informações que não são cobertas como parte dos campos de resumo e item de linha.
Esta postagem usa o Construções do Amazon Textract IDP CDK (componentes do AWS CDK para definir a infraestrutura para fluxos de trabalho de processamento inteligente de documentos (IDP)), que permite criar fluxos de trabalho de IDP personalizáveis e específicos para casos de uso. As construções e amostras são uma coleção de componentes para permitir a definição de processos de IDP na AWS e publicados no GitHub. Os principais conceitos utilizados são as construções do AWS CDK, o próprio Pilhas AWS CDK e Funções de etapa da AWS.
A figura a seguir mostra o fluxo de trabalho do Step Functions.
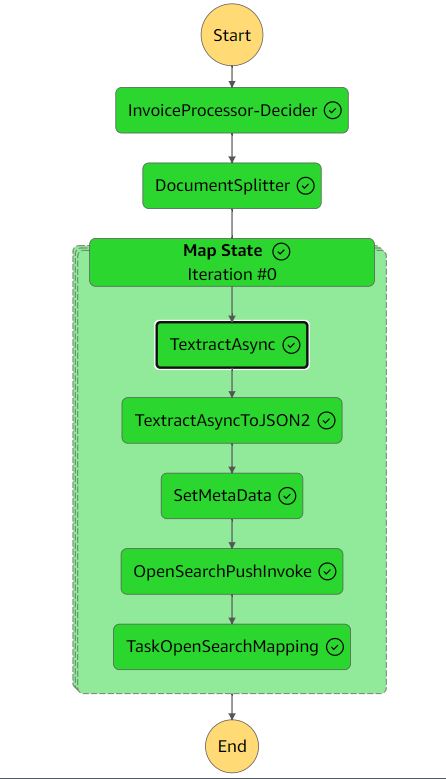
O fluxo de trabalho de extração inclui as seguintes etapas:
- InvoiceProcessor-Decider - A AWS Lambda função que verifica se o formato do documento de entrada é compatível com o Amazon Textract. Para obter mais detalhes sobre os formatos suportados, consulte Documentos de entrada.
- Divisor de documentos – Uma função Lambda que gera blocos de documentos de no máximo 2,500 páginas e pode processar documentos grandes de várias páginas.
- Estado do mapa – Uma função Lambda que processa cada pedaço em paralelo.
- TextractAsync – Esta tarefa chama o Amazon Textract usando a API assíncrona a seguir melhores práticas de Serviço de notificação simples da Amazon (Amazon SNS) notificações e usos
OutputConfigpara armazenar a saída JSON do Amazon Textract no bucket S3 criado anteriormente. É composto por duas funções Lambda: uma para submeter o documento para processamento e outra que é acionada na notificação do SNS. - TextractAsyncToJSON2 - Porque o
TextractAsynctarefa pode produzir vários arquivos de saída paginados, oTextractAsyncToJSON2o processo os combina em um arquivo JSON.
Discutiremos os detalhes das próximas três etapas nas seções a seguir.
Verificação e aprovação
Para a fase de verificação, o SetMetaData Função Lambda verifica se o arquivo enviado é uma despesa válida conforme regras configuradas anteriormente na tabela DynamoDB. Para esta postagem, você usa os seguintes exemplos de regras:
- A verificação será bem-sucedida se
INVOICE_RECEIPT_IDestá presente e corresponde ao regex(?i)[0-9]{3}[a-z]{3}[0-9]{3}$e ifPO_NUMBERestá presente e corresponde ao regex(?i)[a-z0-9]+$ - A verificação não será bem-sucedida se
PO_NUMBERorINVOICE_RECEIPT_IDestá incorreto ou faltando no documento.
Após os arquivos serem processados, a função de verificação de despesas move os arquivos de entrada para approved or declined pastas no mesmo bucket S3.
Para efeitos desta solução, usamos DynamoDB para armazenar as regras de validação de despesas. No entanto, você pode modificar esta solução para integrá-la às suas próprias soluções comerciais ou de validação ou gerenciamento de despesas.
Índice e pesquisa inteligentes
Com o OpenSearchPushInvoke Função Lambda, os metadados de despesas extraídos são enviados para um índice do OpenSearch Service e ficam disponíveis para pesquisa.
A final TaskOpenSearchMapping passo limpa o contexto, que de outra forma poderia exceder o Cota do Step Functions do tamanho máximo de entrada ou saída para uma execução de tarefa, estado ou fluxo de trabalho.
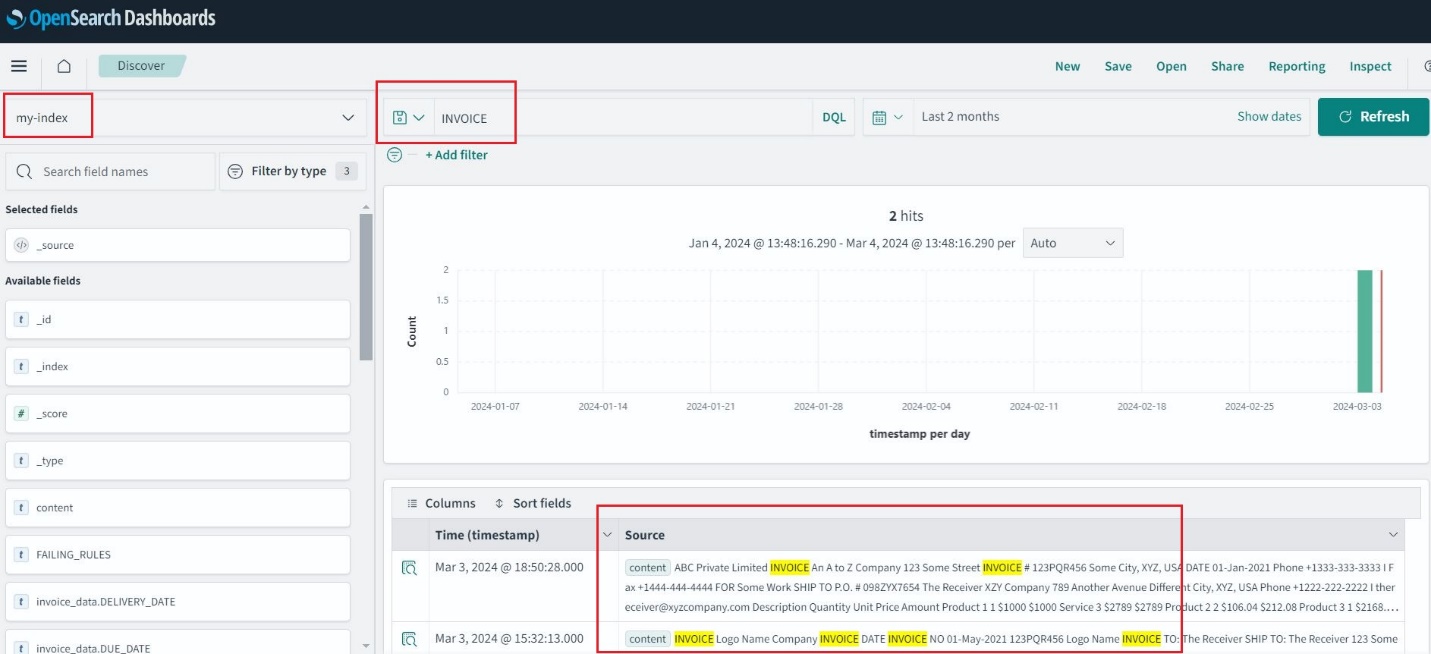
Depois que o índice do OpenSearch Service for criado, você poderá pesquisar palavras-chave do texto extraído por meio do OpenSearch Dashboards.
Arquivamento, auditoria e análise
Para gerenciar o ciclo de vida e o arquivamento de faturas e recibos, você pode configurar regras de ciclo de vida do S3 para fazer a transição de objetos do S3 das classes de armazenamento Standard para Intelligent-Tiering. O S3 Intelligent-Tiering monitora padrões de acesso e move automaticamente objetos para o nível de acesso infrequente quando eles não são acessados por 30 dias consecutivos. Após 90 dias sem acesso, os objetos são movidos para a camada Archive Instant Access sem impacto no desempenho ou sobrecarga operacional.
Para auditoria e análise, esta solução usa o OpenSearch Service para executar análises em solicitações de fatura. O OpenSearch Service permite que você ingira, proteja, pesquise, agregue, visualize e analise dados sem esforço para vários casos de uso, como análise de log, pesquisa de aplicativos, pesquisa corporativa e muito mais.
Faça login no OpenSearch Dashboards e navegue até Gerenciamento de pilha, Objetos salvos, Em seguida, escolha importação. Escolha o faturas.ndjson arquivo do repositório clonado e escolha importação. Isso preenche previamente os índices e cria a visualização.
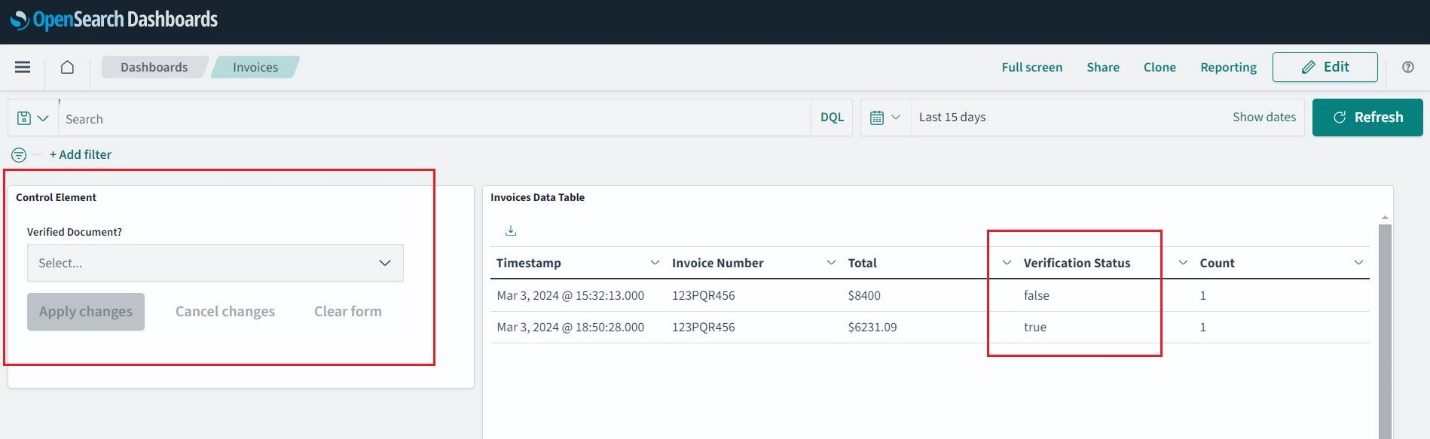
Atualize a página e navegue até Início, Painele aberto Faturas. Agora você pode selecionar e aplicar filtros e expandir a janela de tempo para explorar faturas anteriores.
limpar
Quando terminar de avaliar o Amazon Textract para processamento de recibos e faturas, recomendamos limpar todos os recursos que você possa ter criado. Conclua as seguintes etapas:
- Exclua todo o conteúdo do bucket S3
invoiceprocessorworkflow-invoiceprocessorbucketf1-*. - No AWS Cloud9, execute os seguintes comandos para excluir recursos do Amazon Cognito e pilhas do CloudFormation:
- Exclua o ambiente do AWS Cloud9 que você criou no console do AWS Cloud9.
Conclusão
Nesta postagem, fornecemos uma visão geral de como podemos construir um pipeline de automação de faturas usando Amazon Textract para extração de dados e criar um fluxo de trabalho para validação, arquivamento e pesquisa. Fornecemos exemplos de código sobre como usar o AnalyzeExpense API para extração de campos críticos de uma fatura.
Para começar, faça login no console do Amazon Textract para experimentar esse recurso. Para saber mais sobre os recursos do Amazon Textract, consulte o Guia do desenvolvedor Amazon Textract or Recursos de texto. Para saber mais sobre o IDP, consulte IDP com serviços de IA da AWS Parte 1 e Parte 2 mensagens.
Sobre os autores
 Sushant Pradhan é arquiteto de soluções sênior na Amazon Web Services, ajudando clientes corporativos. Seus interesses e experiência incluem contêineres, tecnologia sem servidor e DevOps. Nas horas vagas, Sushant gosta de passar o tempo ao ar livre com sua família.
Sushant Pradhan é arquiteto de soluções sênior na Amazon Web Services, ajudando clientes corporativos. Seus interesses e experiência incluem contêineres, tecnologia sem servidor e DevOps. Nas horas vagas, Sushant gosta de passar o tempo ao ar livre com sua família.
 Shibin Michaelraj é gerente sênior de produtos da equipe do AWS Textract. Ele está focado na criação de produtos baseados em IA/ML para clientes da AWS.
Shibin Michaelraj é gerente sênior de produtos da equipe do AWS Textract. Ele está focado na criação de produtos baseados em IA/ML para clientes da AWS.
 Suprakash Dutta é Arquiteto de Soluções Sênior na Amazon Web Services. Ele se concentra na estratégia de transformação digital, modernização e migração de aplicativos, análise de dados e aprendizado de máquina. Ele faz parte da comunidade AI/ML da AWS e projeta soluções inteligentes de processamento de documentos.
Suprakash Dutta é Arquiteto de Soluções Sênior na Amazon Web Services. Ele se concentra na estratégia de transformação digital, modernização e migração de aplicativos, análise de dados e aprendizado de máquina. Ele faz parte da comunidade AI/ML da AWS e projeta soluções inteligentes de processamento de documentos.
 Maran Chandrasekaran é Arquiteto de Soluções Sênior na Amazon Web Services, trabalhando com nossos clientes corporativos. Fora do trabalho, ele adora viajar e andar de moto no Texas Hill Country.
Maran Chandrasekaran é Arquiteto de Soluções Sênior na Amazon Web Services, trabalhando com nossos clientes corporativos. Fora do trabalho, ele adora viajar e andar de moto no Texas Hill Country.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/build-a-receipt-and-invoice-processing-pipeline-with-amazon-textract/

