Processamento de linguagem natural (NLP) é o campo do aprendizado de máquina (ML) preocupado em dar aos computadores a capacidade de entender texto e palavras faladas da mesma forma que os seres humanos. Recentemente, arquiteturas de ponta como a arquitetura do transformador são usados para obter desempenho quase humano em tarefas downstream de NLP, como resumo de texto, classificação de texto, reconhecimento de entidade e muito mais.
Modelos de linguagem grande (LLMs) são modelos baseados em transformadores treinados em uma grande quantidade de texto não rotulado com centenas de milhões (BERT) para mais de um trilhão de parâmetros (MiCS) e cujo tamanho torna impraticável o treinamento com uma única GPU. Devido à sua complexidade inerente, treinar um LLM do zero é uma tarefa muito desafiadora que poucas organizações podem pagar. Uma prática comum para tarefas downstream de NLP é pegar um LLM pré-treinado e ajustá-lo. Para obter mais informações sobre o ajuste fino, consulte Adaptação de domínio Ajuste fino de modelos de fundação no Amazon SageMaker JumpStart em dados financeiros e Ajuste os modelos de linguagem do transformador para diversidade linguística com o Hugging Face no Amazon SageMaker.
O aprendizado zero-shot em PNL permite uma LLM pré-treinado para gerar respostas a tarefas para as quais não foi explicitamente treinado (mesmo sem ajuste fino). Especificamente falando sobre classificação de texto, classificação de texto zero-shot é uma tarefa no processamento de linguagem natural em que um modelo NLP é usado para classificar o texto de classes invisíveis, em contraste com classificação supervisionada, onde os modelos NLP só podem classificar o texto que pertence a classes nos dados de treinamento.
Lançamos recentemente o suporte ao modelo de classificação zero-shot em JumpStart do Amazon SageMaker. O SageMaker JumpStart é o centro de ML de Amazon Sage Maker que fornece acesso a modelos de fundação (FMs) pré-treinados, LLMs, algoritmos integrados e modelos de solução para ajudá-lo a começar a usar o ML rapidamente. Nesta postagem, mostramos como você pode executar a classificação zero-shot usando modelos pré-treinados no SageMaker Jumpstart. Você aprenderá como usar a IU do SageMaker Jumpstart e o SageMaker Python SDK para implantar a solução e executar a inferência usando os modelos disponíveis.
Aprendizagem Zero-shot
A classificação zero-shot é um paradigma em que um modelo pode classificar novos exemplos não vistos que pertencem a classes que não estavam presentes nos dados de treinamento. Por exemplo, um modelo de linguagem que foi treinado para entender a linguagem humana pode ser usado para classificar os tweets de resoluções de ano novo em várias classes, como career, health e finance, sem que o modelo de linguagem seja explicitamente treinado na tarefa de classificação de texto. Isso contrasta com o ajuste fino do modelo, uma vez que o último implica o retreinamento do modelo (através do aprendizado por transferência), enquanto o aprendizado zero-shot não requer treinamento adicional.
O diagrama a seguir ilustra as diferenças entre o aprendizado por transferência (esquerda) e o aprendizado zero-shot (direita).

Yin et al. propôs uma estrutura para criar classificadores zero-shot usando inferência de linguagem natural (NLI). A estrutura funciona colocando a sequência a ser classificada como uma premissa NLI e constrói uma hipótese de cada rótulo candidato. Por exemplo, se quisermos avaliar se uma sequência pertence à classe politics, poderíamos construir uma hipótese de “Este texto é sobre política”. As probabilidades de implicação e contradição são então convertidas em probabilidades de rótulo. Como uma revisão rápida, NLI considera duas sentenças: uma premissa e uma hipótese. A tarefa é determinar se a hipótese é verdadeira (implicação) ou falsa (contradição) dada a premissa. A tabela a seguir fornece alguns exemplos.
| Premissa | O rótulo | Hipótese |
| Um homem inspeciona o uniforme de uma figura em algum país do Leste Asiático. | Contradição | O homem está dormindo. |
| Um homem mais velho e mais jovem sorrindo. | Neutro | Dois homens estão sorrindo e rindo dos gatos brincando no chão. |
| Um jogo de futebol com vários homens jogando. | vinculação | Alguns homens estão praticando um esporte. |
Visão geral da solução
Nesta postagem, discutimos o seguinte:
- Como implantar modelos de classificação de texto zero-shot pré-treinados usando a IU JumpStart do SageMaker e executar inferência no modelo implantado usando dados de texto curtos
- Como usar o SageMaker Python SDK para acessar os modelos de classificação de texto zero-shot pré-treinados no SageMaker JumpStart e usar o script de inferência para implantar o modelo em um endpoint do SageMaker para um caso de uso de classificação de texto em tempo real
- Como usar o SageMaker Python SDK para acessar modelos de classificação de texto zero-shot pré-treinados e usar a transformação em lote do SageMaker para um caso de uso de classificação de texto em lote
O SageMaker JumpStart fornece ajuste fino e implantação com um clique para uma ampla variedade de modelos pré-treinados em tarefas populares de ML, bem como uma seleção de soluções completas que resolvem problemas comerciais comuns. Esses recursos removem o trabalho pesado de cada etapa do processo de ML, simplificando o desenvolvimento de modelos de alta qualidade e reduzindo o tempo de implantação. O APIs JumpStart permitem que você implante e ajuste programaticamente uma vasta seleção de modelos pré-treinados em seus próprios conjuntos de dados.
O hub de modelo JumpStart fornece acesso a um grande número de modelos NLP que permitem aprendizado de transferência e ajuste fino em conjuntos de dados personalizados. Até o momento, o hub de modelos JumpStart contém mais de 300 modelos de texto em uma variedade de modelos populares, como Stable Diffusion, Flan T5, Alexa TM, Bloom e muito mais.
Observe que, seguindo as etapas desta seção, você implantará uma infraestrutura em sua conta da AWS que pode incorrer em custos.
Implante um modelo autônomo de classificação de texto zero-shot
Nesta seção, demonstramos como implantar um modelo de classificação zero-shot usando o SageMaker JumpStart. Você pode acessar modelos pré-treinados por meio da página inicial do JumpStart em Estúdio Amazon SageMaker. Conclua as seguintes etapas:
- No SageMaker Studio, abra a página inicial do JumpStart.
Consulte Abra e use o JumpStart para obter mais detalhes sobre como navegar para o SageMaker JumpStart. - No Modelos de Texto carrossel, localize o cartão do modelo “Zero-Shot Text Classification”.
- Escolha Ver modelo para acessar o
facebook-bart-large-mnlimodelo.
Como alternativa, você pode pesquisar o modelo de classificação zero-shot na barra de pesquisa e acessar o modelo no SageMaker JumpStart. - Especifique uma configuração de implantação, tipo de instância de hospedagem do SageMaker, nome do endpoint, Serviço de armazenamento simples da Amazon (Amazon S3) nome do bucket e outros parâmetros necessários.
- Opcionalmente, você pode especificar configurações de segurança como Gerenciamento de acesso e identidade da AWS função (IAM), configurações de VPC e Serviço de gerenciamento de chaves AWS (AWS KMS) chaves de criptografia.
- Escolha Implantação para criar um terminal SageMaker.
Esta etapa leva alguns minutos para ser concluída. Quando estiver concluído, você pode executar a inferência no ponto de extremidade do SageMaker que hospeda o modelo de classificação zero-shot.
No vídeo a seguir, mostramos um passo a passo das etapas nesta seção.
Use o JumpStart programaticamente com o SDK do SageMaker
Na seção SageMaker JumpStart do SageMaker Studio, em Soluções de início rápido, você pode encontrar o modelos de solução. Os modelos de solução SageMaker JumpStart são soluções completas de um clique para muitos casos de uso comuns de ML. Até o momento, mais de 20 soluções estão disponíveis para vários casos de uso, como previsão de demanda, detecção de fraude e recomendações personalizadas, para citar alguns.
A solução “Zero Shot Text Classification with Hugging Face” fornece uma maneira de classificar texto sem a necessidade de treinar um modelo para rótulos específicos (classificação de tiro zero) usando um classificador de texto pré-treinado. O modelo de classificação zero-shot padrão para esta solução é o facebook-bart-grande-mnli (BART). Para esta solução, utilizamos o Conjunto de dados de resoluções de ano novo de 2015 para classificar resoluções. Um subconjunto do conjunto de dados original contendo apenas o Resolution_Category (rótulo da verdade fundamental) e o text colunas está incluída nos ativos da solução.
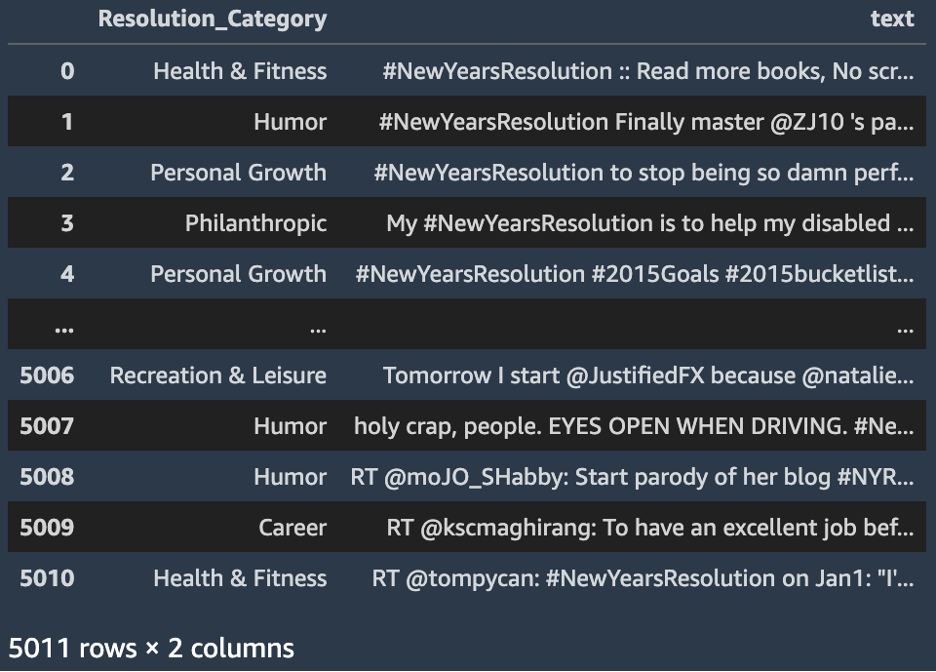
Os dados de entrada incluem strings de texto, uma lista de categorias desejadas para classificação e se a classificação é multi-rótulo ou não para inferência síncrona (em tempo real). Para inferência assíncrona (lote), fornecemos uma lista de strings de texto, a lista de categorias para cada string e se a classificação é multi-rótulo ou não em um arquivo de texto formatado de linhas JSON.

O resultado da inferência é um objeto JSON semelhante à captura de tela a seguir.

Temos o texto original no sequence campo, os rótulos utilizados para a classificação do texto no campo labels campo e a probabilidade atribuída a cada rótulo (na mesma ordem de aparecimento) no campo scores.
Para implantar a solução Zero Shot Text Classification with Hugging Face, conclua as seguintes etapas:
- Na página inicial do SageMaker JumpStart, escolha Modelos, notebooks, soluções no painel de navegação.
- No Soluções seção, escolha Explorar todas as soluções.
- No Soluções página, escolha o cartão de modelo Zero Shot Text Classification with Hugging Face.
- Revise os detalhes da implantação e, se concordar, escolha Apresentação livro.


A implantação fornecerá um endpoint em tempo real do SageMaker para inferência em tempo real e um bucket S3 para armazenar os resultados da transformação em lote.
O diagrama a seguir ilustra a arquitetura desse método.

Realize inferência em tempo real usando um modelo de classificação zero-shot
Nesta seção, revisamos como usar o Python SDK para executar a classificação de texto zero-shot (usando qualquer um dos modelos disponíveis) em tempo real usando um terminal SageMaker.
- Primeiro, configuramos a solicitação de carga de inferência para o modelo. Isso depende do modelo, mas para o modelo BART, a entrada é um objeto JSON com a seguinte estrutura:
- Observe que o modelo BART não é explicitamente treinado no
candidate_labels. Usaremos a técnica de classificação zero-shot para classificar a sequência de texto para classes não vistas. O código a seguir é um exemplo usando texto do conjunto de dados de resoluções de ano novo e as classes definidas: - Em seguida, você pode invocar um endpoint do SageMaker com a carga zero-shot. O endpoint SageMaker é implantado como parte da solução SageMaker JumpStart.
- O objeto de resposta de inferência contém a sequência original, os rótulos classificados por pontuação de máximo a mínimo e as pontuações por rótulo:
Executar um trabalho de transformação em lote do SageMaker usando o Python SDK
Esta seção descreve como executar a inferência de transformação em lote com a classificação zero-shot facebook-bart-large-mnli modelo usando o SDK Python do SageMaker. Conclua as seguintes etapas:
- Formate os dados de entrada no formato de linhas JSON e carregue o arquivo no Amazon S3.
A transformação em lote do SageMaker executará inferência nos pontos de dados carregados no arquivo S3. - Configure os artefatos de implementação de modelo com os seguintes parâmetros:
- id_modelo - Usar
huggingface-zstc-facebook-bart-large-mnli. - implantar_image_uri - Use o
image_urisFunção do Python SDK para obter a imagem pré-criada do SageMaker Docker para omodel_id. A função retorna o Registro do Amazon Elastic Container (Amazon ECR) URI. - implantar_source_uri – Use o
script_urisAPI de utilitário para recuperar o URI do S3 que contém scripts para executar inferência de modelo pré-treinado. Nós especificamos oscript_scopeasinference. - modelo_uri - Usar
model_uripara obter os artefatos de modelo do Amazon S3 para o especificadomodel_id.
- id_modelo - Usar
- Use
HF_TASKpara definir a tarefa para o pipeline de transformadores Hugging Face eHF_MODEL_IDpara definir o modelo usado para classificar o texto:Para obter uma lista completa de tarefas, consulte Dutos na documentação do Hugging Face.
- Crie um objeto de modelo Hugging Face para ser implantado com o trabalho de transformação em lote do SageMaker:
- Crie uma transformação para executar um trabalho em lote:
- Inicie um trabalho de transformação em lote e use os dados do S3 como entrada:
Você pode monitorar seu trabalho de processamento em lote no console do SageMaker (escolha Tarefas de transformação em lote para Inferência no painel de navegação). Quando o trabalho estiver concluído, você poderá verificar a saída de previsão do modelo no arquivo S3 especificado em output_path.
Para obter uma lista de todos os modelos pré-treinados disponíveis no SageMaker JumpStart, consulte Algoritmos integrados com tabela de modelo pré-treinada. Use a palavra-chave “zstc” (abreviação de classificação de texto zero-shot) na barra de pesquisa para localizar todos os modelos capazes de fazer classificação de texto zero-shot.
limpar
Após concluir a execução do notebook, certifique-se de excluir todos os recursos criados no processo para garantir que os custos incorridos pelos ativos implantados neste guia sejam interrompidos. O código para limpar os recursos implantados é fornecido nos notebooks associados à solução e ao modelo de classificação de texto zero-shot.
Configurações de segurança padrão
Os modelos SageMaker JumpStart são implantados usando as seguintes configurações de segurança padrão:
Para saber mais sobre os tópicos relacionados à segurança do SageMaker, confira Configurar a segurança no Amazon SageMaker.
Conclusão
Nesta postagem, mostramos como implantar um modelo de classificação zero-shot usando a IU JumpStart do SageMaker e realizar inferência usando o endpoint implantado. Usamos a solução de resoluções de ano novo SageMaker JumpStart para mostrar como você pode usar o SageMaker Python SDK para criar uma solução de ponta a ponta e implementar o aplicativo de classificação zero-shot. O SageMaker JumpStart fornece acesso a centenas de modelos e soluções pré-treinados para tarefas como visão computacional, processamento de linguagem natural, sistemas de recomendação e muito mais. Experimente a solução por conta própria e deixe-nos saber seus pensamentos.
Sobre os autores
 David Laredo é arquiteto de prototipagem na AWS Envision Engineering na LATAM, onde ajudou a desenvolver vários protótipos de aprendizado de máquina. Anteriormente, ele trabalhou como engenheiro de aprendizado de máquina e faz aprendizado de máquina há mais de 5 anos. Suas áreas de interesse são NLP, séries temporais e ML de ponta a ponta.
David Laredo é arquiteto de prototipagem na AWS Envision Engineering na LATAM, onde ajudou a desenvolver vários protótipos de aprendizado de máquina. Anteriormente, ele trabalhou como engenheiro de aprendizado de máquina e faz aprendizado de máquina há mais de 5 anos. Suas áreas de interesse são NLP, séries temporais e ML de ponta a ponta.
 Vikram Elango é arquiteto de soluções especialista em IA/ML da Amazon Web Services, com sede na Virgínia, EUA. A Vikram ajuda os clientes do setor financeiro e de seguros com design e liderança de pensamento para criar e implantar aplicativos de aprendizado de máquina em escala. Atualmente, ele está focado em processamento de linguagem natural, IA responsável, otimização de inferência e escalonamento de ML em toda a empresa. Em seu tempo livre, ele gosta de viajar, caminhar, cozinhar e acampar com sua família.
Vikram Elango é arquiteto de soluções especialista em IA/ML da Amazon Web Services, com sede na Virgínia, EUA. A Vikram ajuda os clientes do setor financeiro e de seguros com design e liderança de pensamento para criar e implantar aplicativos de aprendizado de máquina em escala. Atualmente, ele está focado em processamento de linguagem natural, IA responsável, otimização de inferência e escalonamento de ML em toda a empresa. Em seu tempo livre, ele gosta de viajar, caminhar, cozinhar e acampar com sua família.
 Vivek Madan é um cientista aplicado da equipe Amazon SageMaker JumpStart. Ele obteve seu doutorado na Universidade de Illinois em Urbana-Champaign e foi pesquisador de pós-doutorado na Georgia Tech. Ele é um pesquisador ativo em aprendizado de máquina e design de algoritmos e publicou artigos em conferências EMNLP, ICLR, COLT, FOCS e SODA.
Vivek Madan é um cientista aplicado da equipe Amazon SageMaker JumpStart. Ele obteve seu doutorado na Universidade de Illinois em Urbana-Champaign e foi pesquisador de pós-doutorado na Georgia Tech. Ele é um pesquisador ativo em aprendizado de máquina e design de algoritmos e publicou artigos em conferências EMNLP, ICLR, COLT, FOCS e SODA.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Automotivo / EVs, Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- ChartPrime. Eleve seu jogo de negociação com ChartPrime. Acesse aqui.
- BlockOffsets. Modernizando a Propriedade de Compensação Ambiental. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/zero-shot-text-classification-with-amazon-sagemaker-jumpstart/

