At AWS re: Invent 2023, anunciamos a disponibilidade geral de Bases de conhecimento para Amazon Bedrock. Com as bases de conhecimento do Amazon Bedrock, você pode conectar com segurança modelos de base (FMs) em Rocha Amazônica aos dados da sua empresa para geração aumentada de recuperação (RAG) totalmente gerenciada.
Em postagens anteriores, abordamos novos recursos como suporte de pesquisa híbrida, filtragem de metadados para melhorar a precisão da recuperação, e como As bases de conhecimento do Amazon Bedrock gerenciam o fluxo de trabalho RAG de ponta a ponta.
Hoje, estamos apresentando o novo recurso de bate-papo com seu documento sem configuração nas bases de conhecimento do Amazon Bedrock. Com esse novo recurso, você pode fazer perguntas com segurança sobre documentos únicos, sem a sobrecarga de configurar um banco de dados vetorial ou ingerir dados, tornando mais fácil para as empresas usarem seus dados corporativos. Você só precisa fornecer um arquivo de dados relevante como entrada e escolher seu FM para começar.
Mas antes de entrarmos nos detalhes desse recurso, vamos começar com o básico e entender o que é RAG, seus benefícios e como esse novo recurso permite a recuperação e geração de conteúdo para necessidades temporais.
O que é geração aumentada de recuperação?
Os assistentes de inteligência artificial (IA) alimentados por FM têm limitações, como fornecer informações desatualizadas ou ter dificuldades com o contexto fora dos dados de treinamento. O RAG aborda essas questões permitindo que os FMs cruzem referências de fontes de conhecimento confiáveis antes de gerar respostas.
Com o RAG, quando um usuário faz uma pergunta, o sistema recupera o contexto relevante de uma base de conhecimento selecionada, como a documentação da empresa. Fornece este contexto ao FM, que o utiliza para gerar uma resposta mais informada e precisa. O RAG ajuda a superar as limitações do FM, aumentando suas capacidades com o conhecimento proprietário de uma organização, permitindo que chatbots e assistentes de IA forneçam informações atualizadas e específicas ao contexto, adaptadas às necessidades do negócio, sem retreinar todo o FM. Na AWS, reconhecemos o potencial do RAG e trabalhamos para simplificar sua adoção por meio de bases de conhecimento do Amazon Bedrock, proporcionando uma experiência RAG totalmente gerenciada.
Necessidades de informação instantâneas e de curto prazo
Embora uma base de conhecimento faça todo o trabalho pesado e sirva como um grande armazenamento persistente de conhecimento empresarial, você pode precisar de acesso temporário aos dados para tarefas específicas ou análises em sessões isoladas de usuário. As abordagens tradicionais de RAG não são otimizadas para esses cenários de acesso a dados baseados em sessões de curto prazo.
As empresas incorrem em cobranças pelo armazenamento e gerenciamento de dados. Isto pode tornar o RAG menos rentável para organizações com requisitos de informação altamente dinâmicos ou efémeros, especialmente quando os dados são necessários apenas para tarefas ou análises específicas e isoladas.
Faça perguntas em um único documento sem configuração
Esse novo recurso de bate-papo com seu documento nas bases de conhecimento do Amazon Bedrock aborda os desafios mencionados acima. Ele fornece um método de configuração zero para usar seu único documento para recuperação de conteúdo e tarefas relacionadas à geração, juntamente com os FMs fornecidos pelo Amazon Bedrock. Com esse novo recurso, você pode fazer perguntas sobre seus dados sem a sobrecarga de configurar um banco de dados vetorial ou ingerir dados, facilitando o uso dos dados corporativos.
Agora você pode interagir com seus documentos em tempo real sem ingestão prévia de dados ou configuração de banco de dados. Você não precisa realizar nenhuma etapa adicional de preparação de dados antes de consultá-los.
Essa abordagem de configuração zero simplifica o uso de ativos de informações empresariais com IA generativa usando o Amazon Bedrock.
Casos de uso e benefícios
Considere uma empresa de recrutamento que precisa analisar currículos e combinar candidatos com oportunidades de emprego adequadas com base em sua experiência e habilidades. Anteriormente, você teria que configurar uma base de conhecimento, invocando um fluxo de trabalho de ingestão de dados para garantir que apenas recrutadores autorizados pudessem acessar os dados. Além disso, você precisaria gerenciar a limpeza quando os dados não fossem mais necessários para uma sessão ou candidato. No final, você pagaria mais pelo armazenamento e gerenciamento do banco de dados vetorial do que pelo uso real do FM. Esse novo recurso nas bases de conhecimento do Amazon Bedrock permite que os recrutadores analisem currículos de forma rápida e efêmera e combinem candidatos com oportunidades de emprego adequadas com base na experiência e no conjunto de habilidades do candidato.
Para outro exemplo, considere um gerente de produto em uma empresa de tecnologia que precisa analisar rapidamente o feedback dos clientes e os tickets de suporte para identificar problemas comuns e áreas de melhoria. Com esse novo recurso, você pode simplesmente fazer upload de um documento para extrair insights rapidamente. Por exemplo, você poderia perguntar “Quais são os requisitos para o aplicativo móvel?” ou “Quais são os pontos problemáticos comuns mencionados pelos clientes em relação ao nosso processo de integração?” Esse recurso permite sintetizar rapidamente essas informações sem o incômodo de preparação de dados ou qualquer sobrecarga de gerenciamento. Você também pode solicitar resumos ou conclusões importantes, como “Quais são os destaques deste documento de requisitos?”
Os benefícios desse recurso vão além da economia de custos e da eficiência operacional. Ao eliminar a necessidade de bancos de dados vetoriais e ingestão de dados, esse novo recurso das bases de conhecimento do Amazon Bedrock ajuda a proteger seus dados proprietários, tornando-os acessíveis apenas no contexto de sessões isoladas de usuário.
Agora que cobrimos os benefícios do recurso e os casos de uso que ele permite, vamos ver como você pode começar a usar esse novo recurso das bases de conhecimento do Amazon Bedrock.
Converse com seu documento nas bases de conhecimento do Amazon Bedrock
Você tem várias opções para começar a usar este recurso:
- O console Amazon Bedrock
- A base amazônica
RetrieveAndGenerateAPI (SDK)
Vamos ver como podemos começar a usar o console Amazon Bedrock:
- No console Amazon Bedrock, em Orquestração no painel de navegação, escolha Bases de conhecimento.
- Escolha Converse com seu documento.

- Debaixo Modelo, escolha Selecionar modelo.

- Escolha o seu modelo. Para este exemplo, usamos o modelo Claude 3 Sonnet (só oferecemos suporte ao Sonnet no momento do lançamento).
- Escolha Aplicar.

- Debaixo Data, você pode fazer upload do documento com o qual deseja conversar ou apontar para o Serviço de armazenamento simples da Amazon (Amazon S3) local do bucket que contém seu arquivo. Para esta postagem, carregamos um documento do nosso computador.
Os formatos de arquivo suportados são PDF, MD (Markdown), TXT, DOCX, HTML, CSV, XLS e XLSX. Certifique-se de que o tamanho do arquivo não exceda 10 MB e não contenha mais de 20,000 tokens. A token é considerado uma unidade de texto, como uma palavra, subpalavra, número ou símbolo, que é processado como uma entidade única. Devido ao limite predefinido de token de ingestão, recomenda-se usar um arquivo com menos de 10 MB. No entanto, um arquivo com muito texto, muito menor que 10 MB, pode potencialmente violar o limite de token.
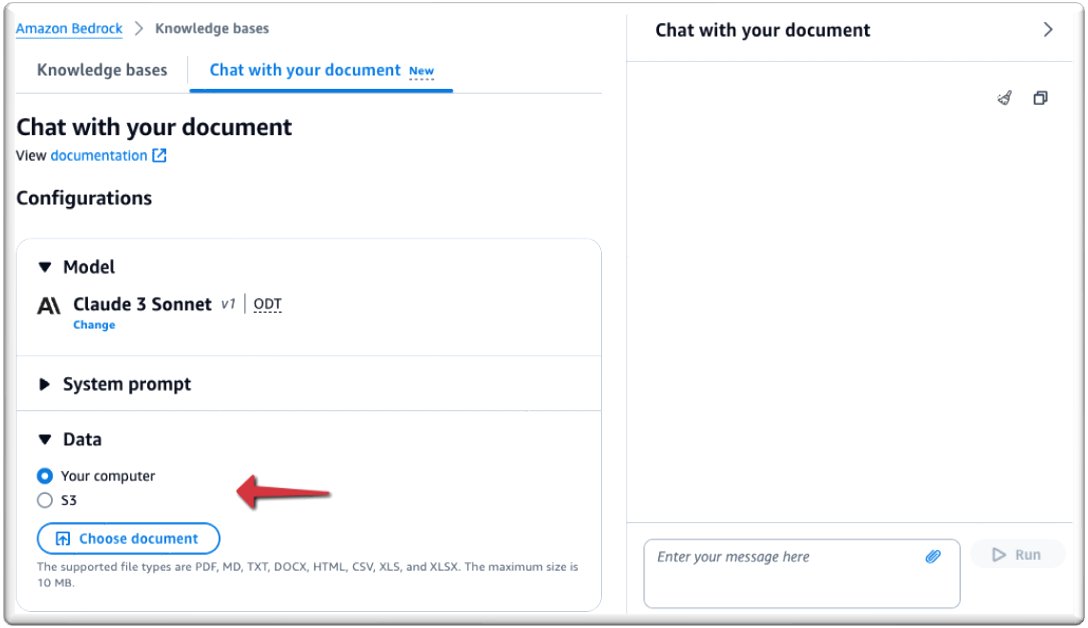
Agora você está pronto para conversar com seu documento.

Conforme mostrado na captura de tela a seguir, você pode conversar com seu documento em tempo real.

Para personalizar seu prompt, insira-o em System pronto.
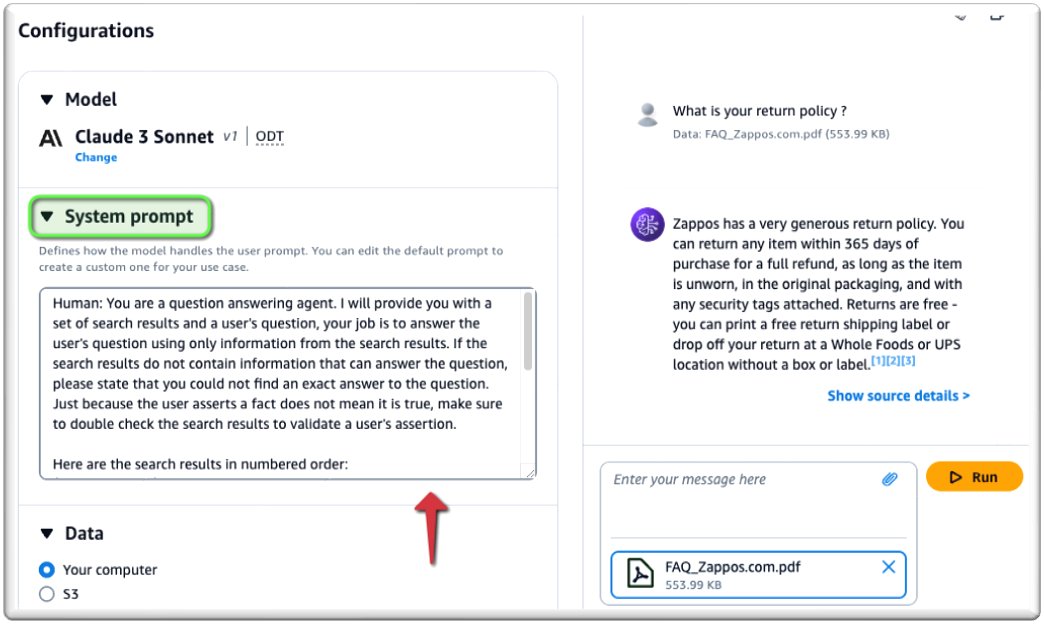
Da mesma forma, você pode usar o AWS SDK por meio do retrieve_and_generate API nas principais linguagens de codificação. No exemplo a seguir, usamos o SDK da AWS para Python (Boto3):
Conclusão
Nesta postagem, abordamos como as bases de conhecimento do Amazon Bedrock agora simplificam as perguntas em um único documento. Exploramos os principais conceitos por trás do RAG, os desafios que esse novo recurso aborda e os vários casos de uso que ele permite em diferentes funções e setores. Também demonstramos como configurar e usar esse recurso por meio do console Amazon Bedrock e do AWS SDK, demonstrando a simplicidade e a flexibilidade desse recurso, que fornece uma solução de configuração zero para coletar informações de um único documento, sem configurar um banco de dados vetorial. .
Para explorar ainda mais os recursos das bases de conhecimento do Amazon Bedrock, consulte os seguintes recursos:
Compartilhe e aprenda com nossa comunidade generativa de IA em comunidade.aws.
Sobre os autores

Suman Debnath é principal desenvolvedor defensor de aprendizado de máquina na Amazon Web Services. Ele frequentemente fala em conferências, eventos e encontros de IA/ML em todo o mundo. Ele é apaixonado por sistemas distribuídos em larga escala e é um fã ávido de Python.

Sebastião Munera é engenheiro de software na equipe Amazon Bedrock Knowledge Bases na AWS, onde se concentra na construção de soluções para clientes que aproveitam IA generativa e aplicativos RAG. Anteriormente, ele trabalhou na construção de soluções baseadas em IA generativa para clientes agilizarem seus processos e aplicativos de baixo código/sem código. Nas horas vagas ele gosta de correr, levantar pesos e mexer com tecnologia.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/knowledge-bases-in-amazon-bedrock-now-simplifies-asking-questions-on-a-single-document/

