Os assistentes de inteligência artificial (IA) conversacional são projetados para fornecer respostas precisas e em tempo real por meio do roteamento inteligente de consultas para as funções de IA mais adequadas. Com serviços de IA generativos da AWS, como Rocha Amazônica, os desenvolvedores podem criar sistemas que gerenciam e respondem habilmente às solicitações dos usuários. O Amazon Bedrock é um serviço totalmente gerenciado que oferece uma variedade de modelos básicos (FMs) de alto desempenho de empresas líderes de IA, como AI21 Labs, Anthropic, Cohere, Meta, Stability AI e Amazon, usando uma única API, juntamente com um amplo conjunto de recursos necessários para criar aplicativos generativos de IA com segurança, privacidade e IA responsável.
Esta postagem avalia duas abordagens principais para o desenvolvimento de assistentes de IA: usando serviços gerenciados como Agentes da Amazon Bedrocke empregando tecnologias de código aberto como LangChain. Exploramos as vantagens e desafios de cada um, para que você possa escolher o caminho mais adequado às suas necessidades.
O que é um assistente de IA?
Um assistente de IA é um sistema inteligente que entende consultas em linguagem natural e interage com diversas ferramentas, fontes de dados e APIs para executar tarefas ou recuperar informações em nome do usuário. Assistentes de IA eficazes possuem os seguintes recursos principais:
- Processamento de linguagem natural (PNL) e fluxo de conversação
- Integração da base de conhecimento e pesquisas semânticas para compreender e recuperar informações relevantes com base nas nuances do contexto da conversa
- Execução de tarefas, como consultas de banco de dados e customizações AWS Lambda funções
- Lidar com conversas especializadas e solicitações de usuários
Demonstramos os benefícios dos assistentes de IA usando o gerenciamento de dispositivos da Internet das Coisas (IoT) como exemplo. Neste caso de uso, a IA pode ajudar os técnicos a gerenciar máquinas de forma eficiente com comandos que buscam dados ou automatizam tarefas, agilizando as operações na fabricação.
Abordagem dos agentes para Amazon Bedrock
Agentes da Amazon Bedrock permite que você crie aplicativos generativos de IA que podem executar tarefas de várias etapas nos sistemas e fontes de dados de uma empresa. Ele oferece os seguintes recursos principais:
- Criação automática de prompts a partir de instruções, detalhes de API e informações de fonte de dados, economizando semanas de esforço imediato de engenharia
- Geração Aumentada de Recuperação (RAG) para conectar agentes com segurança às fontes de dados de uma empresa e fornecer respostas relevantes
- Orquestração e execução de tarefas de várias etapas, dividindo as solicitações em sequências lógicas e chamando as APIs necessárias
- Visibilidade do raciocínio do agente por meio de um rastreamento de cadeia de pensamento (CoT), permitindo solução de problemas e orientação do comportamento do modelo
- Habilidades de engenharia de prompt para modificar o modelo de prompt gerado automaticamente para maior controle sobre os agentes
Você pode usar agentes para Amazon Bedrock e Bases de conhecimento para Amazon Bedrock para criar e implantar assistentes de IA para casos de uso de roteamento complexos. Eles oferecem uma vantagem estratégica para desenvolvedores e organizações, simplificando o gerenciamento da infraestrutura, melhorando a escalabilidade, melhorando a segurança e reduzindo o trabalho pesado indiferenciado. Eles também permitem um código da camada de aplicação mais simples porque a lógica de roteamento, a vetorização e a memória são totalmente gerenciadas.
Visão geral da solução
Esta solução apresenta um assistente de IA conversacional adaptado para gerenciamento e operações de dispositivos IoT ao usar o Claude v2.1 da Anthropic no Amazon Bedrock. A funcionalidade principal do assistente de IA é regida por um conjunto abrangente de instruções, conhecido como prompt do sistema, que delineia suas capacidades e áreas de especialização. Esta orientação garante que o assistente de IA possa lidar com uma ampla gama de tarefas, desde o gerenciamento de informações do dispositivo até a execução de comandos operacionais.
Equipado com esses recursos, conforme detalhado no prompt do sistema, o assistente de IA segue um fluxo de trabalho estruturado para responder às dúvidas dos usuários. A figura a seguir fornece uma representação visual desse fluxo de trabalho, ilustrando cada etapa desde a interação inicial do usuário até a resposta final.

O fluxo de trabalho é composto pelas seguintes etapas:
- O processo começa quando um usuário solicita ao assistente a execução de uma tarefa; por exemplo, solicitando o máximo de pontos de dados para um dispositivo IoT específico
device_xxx. Esta entrada de texto é capturada e enviada ao assistente de IA. - O assistente de IA interpreta a entrada de texto do usuário. Ele usa o histórico de conversas, grupos de ação e bases de conhecimento fornecidos para compreender o contexto e determinar as tarefas necessárias.
- Depois que a intenção do usuário é analisada e compreendida, o assistente de IA define as tarefas. Isso se baseia nas instruções que são interpretadas pelo assistente de acordo com o prompt do sistema e a entrada do usuário.
- As tarefas são então executadas por meio de uma série de chamadas de API. Isso é feito usando Reagir solicitação, que divide a tarefa em uma série de etapas que são processadas sequencialmente:
- Para verificações de métricas de dispositivos, usamos o
check-device-metricsgrupo de ação, que envolve uma chamada de API para funções do Lambda que consultam Amazona atena para os dados solicitados. - Para ações diretas do dispositivo, como iniciar, parar ou reinicializar, usamos o
action-on-devicegrupo de ação, que invoca uma função Lambda. Esta função inicia um processo que envia comandos para o dispositivo IoT. Para esta postagem, a função Lambda envia notificações usando Serviço de e-mail simples da Amazon (Amazônia SES). - Usamos bases de conhecimento do Amazon Bedrock para buscar dados históricos armazenados como embeddings no Serviço Amazon OpenSearch banco de dados de vetores.
- Para verificações de métricas de dispositivos, usamos o
- Após a conclusão das tarefas, a resposta final é gerada pelo Amazon Bedrock FM e devolvida ao usuário.
- Os agentes do Amazon Bedrock armazenam informações automaticamente usando uma sessão com estado para manter a mesma conversa. O estado é excluído depois de decorrido um tempo limite de inatividade configurável.
Visão geral técnica
O diagrama a seguir ilustra a arquitetura para implantar um assistente de IA com agentes para Amazon Bedrock.
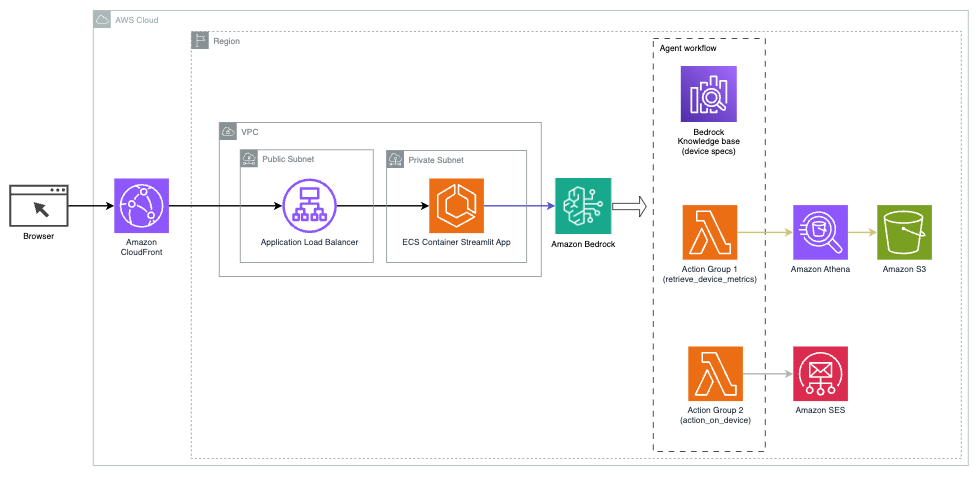
Consiste nos seguintes componentes principais:
- Interface conversacional – A interface conversacional usa Streamlit, uma biblioteca Python de código aberto que simplifica a criação de aplicativos web personalizados e visualmente atraentes para aprendizado de máquina (ML) e ciência de dados. Está hospedado em Serviço Amazon Elastic Container (Amazon ECS) com AWS Fargate, e ele é acessado usando um Application Load Balancer. Você pode usar o Fargate com o Amazon ECS para executar containers sem precisar gerenciar servidores, clusters ou máquinas virtuais.
- Agentes da Amazon Bedrock – Os agentes do Amazon Bedrock completam as consultas do usuário por meio de uma série de etapas de raciocínio e ações correspondentes com base em Solicitação do ReAct:
- Bases de conhecimento para Amazon Bedrock – As bases de conhecimento do Amazon Bedrock fornecem recursos totalmente gerenciados RAG para fornecer ao assistente de IA acesso aos seus dados. Em nosso caso de uso, carregamos as especificações do dispositivo em um Serviço de armazenamento simples da Amazon (Amazon S3) balde. Ele serve como fonte de dados para a base de conhecimento.
- Grupos de ação – Esses são esquemas de API definidos que invocam funções específicas do Lambda para interagir com dispositivos IoT e outros serviços da AWS.
- Claude antrópico v2.1 no Amazon Bedrock – Este modelo interpreta as consultas dos usuários e orquestra o fluxo de tarefas.
- Incorporações Amazon Titan – Este modelo serve como um modelo de incorporação de texto, transformando texto em linguagem natural – de palavras isoladas a documentos complexos – em vetores numéricos. Isso habilita recursos de pesquisa vetorial, permitindo que o sistema combine semanticamente as consultas do usuário com as entradas mais relevantes da base de conhecimento para uma pesquisa eficaz.
A solução é integrada a serviços da AWS, como Lambda para execução de código em resposta a chamadas de API, Athena para consulta de conjuntos de dados, OpenSearch Service para pesquisa em bases de conhecimento e Amazon S3 para armazenamento. Esses serviços trabalham juntos para fornecer uma experiência perfeita para o gerenciamento de operações de dispositivos IoT por meio de comandos de linguagem natural.
Benefícios
Esta solução oferece os seguintes benefícios:
- Complexidade de implementação:
- São necessárias menos linhas de código, porque o Agents for Amazon Bedrock abstrai grande parte da complexidade subjacente, reduzindo o esforço de desenvolvimento
- O gerenciamento de bancos de dados vetoriais como o OpenSearch Service é simplificado, porque as bases de conhecimento do Amazon Bedrock lidam com vetorização e armazenamento
- A integração com vários serviços da AWS é mais simplificada por meio de grupos de ação predefinidos
- Experiência do desenvolvedor:
- O console do Amazon Bedrock fornece uma interface amigável para desenvolvimento imediato, testes e análise de causa raiz (RCA), melhorando a experiência geral do desenvolvedor
- Agilidade e flexibilidade:
- Os agentes para Amazon Bedrock permitem atualizações contínuas para FMs mais recentes (como Claude 3.0) quando estiverem disponíveis, para que sua solução permaneça atualizada com os avanços mais recentes
- As cotas e limitações de serviço são gerenciadas pela AWS, reduzindo a sobrecarga de monitoramento e dimensionamento da infraestrutura
- Segurança:
- O Amazon Bedrock é um serviço totalmente gerenciado que adere aos rigorosos padrões de segurança e conformidade da AWS, simplificando potencialmente as análises de segurança organizacional
Embora o Agents for Amazon Bedrock ofereça uma solução simplificada e gerenciada para a criação de aplicativos de IA conversacional, algumas organizações podem preferir uma abordagem de código aberto. Nesses casos, você pode usar estruturas como LangChain, que discutiremos na próxima seção.
Abordagem de roteamento dinâmico LangChain
LangChain é uma estrutura de código aberto que simplifica a construção de IA conversacional, permitindo a integração de grandes modelos de linguagem (LLMs) e recursos de roteamento dinâmico. Com LangChain Expression Language (LCEL), os desenvolvedores podem definir o roteamento, que permite criar cadeias não determinísticas onde a saída de uma etapa anterior define a próxima etapa. O roteamento ajuda a fornecer estrutura e consistência nas interações com LLMs.
Para esta postagem, usamos o mesmo exemplo do assistente de IA para gerenciamento de dispositivos IoT. No entanto, a principal diferença é que precisamos lidar com os prompts do sistema separadamente e tratar cada cadeia como uma entidade separada. A cadeia de roteamento decide a cadeia de destino com base na entrada do usuário. A decisão é tomada com o apoio de um LLM, passando pelo prompt do sistema, histórico de chat e dúvida do usuário.
Visão geral da solução
O diagrama a seguir ilustra o fluxo de trabalho da solução de roteamento dinâmico.

O fluxo de trabalho consiste nas seguintes etapas:
- O usuário apresenta uma pergunta ao assistente de IA. Por exemplo, “Quais são as métricas máximas para o dispositivo 1009?”
- Um LLM avalia cada pergunta junto com o histórico de bate-papo da mesma sessão para determinar sua natureza e em qual área de assunto ela se enquadra (como SQL, ação, pesquisa ou SME). O LLM classifica a entrada e a cadeia de roteamento LCEL recebe essa entrada.
- A cadeia do roteador seleciona a cadeia de destino com base na entrada, e o LLM é fornecido com o seguinte prompt do sistema:
O LLM avalia a pergunta do usuário junto com o histórico do chat para determinar a natureza da consulta e em qual área de assunto ela se enquadra. O LLM então classifica a entrada e gera uma resposta JSON no seguinte formato:
A cadeia de roteadores usa essa resposta JSON para invocar a cadeia de destino correspondente. Existem quatro cadeias de destino específicas por assunto, cada uma com seu próprio prompt de sistema:
- As consultas relacionadas ao SQL são enviadas à cadeia de destino SQL para interações com o banco de dados. Você pode usar LCEL para construir o Cadeia SQL.
- Perguntas orientadas para a ação invocam a cadeia de destino personalizada do Lambda para executar operações. Com LCEL, você pode definir seu próprio função personalizada; no nosso caso, é uma função para executar uma função Lambda predefinida para enviar um e-mail com um ID de dispositivo analisado. Um exemplo de entrada do usuário pode ser “Desligar dispositivo 1009”.
- Consultas focadas em pesquisa seguem para o RAG cadeia de destino para recuperação de informações.
- Perguntas relacionadas às PME vão para a cadeia de destino de PME/especialistas para obter insights especializados.
- Cada cadeia de destino recebe a entrada e executa os modelos ou funções necessários:
- A cadeia SQL usa Athena para executar consultas.
- A cadeia RAG usa o OpenSearch Service para pesquisa semântica.
- A cadeia Lambda personalizada executa funções Lambda para ações.
- A cadeia de PME/especialistas fornece insights usando o modelo Amazon Bedrock.
- As respostas de cada cadeia de destino são formuladas em insights coerentes pelo LLM. Esses insights são então entregues ao usuário, completando o ciclo de consulta.
- A entrada e as respostas do usuário são armazenadas em Amazon DynamoDB para fornecer contexto ao LLM para a sessão atual e de interações anteriores. A duração das informações persistentes no DynamoDB é controlada pelo aplicativo.
Visão geral técnica
O diagrama a seguir ilustra a arquitetura da solução de roteamento dinâmico LangChain.
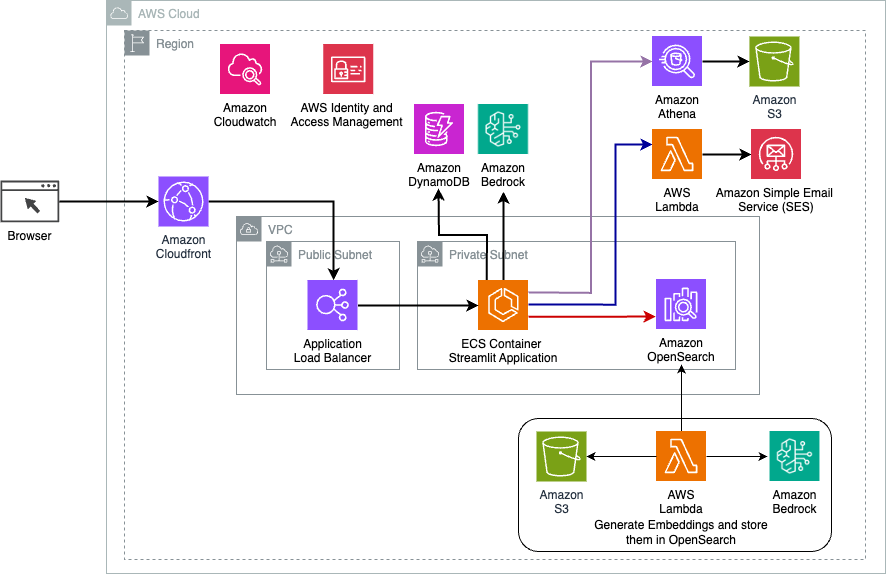
O aplicativo web é construído em Streamlit hospedado no Amazon ECS com Fargate e é acessado usando um Application Load Balancer. Usamos Claude v2.1 da Anthropic no Amazon Bedrock como nosso LLM. A aplicação web interage com o modelo usando bibliotecas LangChain. Ele também interage com vários outros serviços da AWS, como OpenSearch Service, Athena e DynamoDB para atender às necessidades dos usuários finais.
Benefícios
Esta solução oferece os seguintes benefícios:
- Complexidade de implementação:
- Embora exija mais código e desenvolvimento customizado, LangChain oferece maior flexibilidade e controle sobre a lógica de roteamento e integração com diversos componentes.
- O gerenciamento de bancos de dados vetoriais como o OpenSearch Service requer esforços adicionais de instalação e configuração. O processo de vetorização é implementado em código.
- A integração com serviços da AWS pode envolver mais código e configuração personalizados.
- Experiência do desenvolvedor:
- A abordagem baseada em Python do LangChain e a extensa documentação podem ser atraentes para desenvolvedores já familiarizados com Python e ferramentas de código aberto.
- O desenvolvimento e a depuração imediatos podem exigir mais esforço manual em comparação ao uso do console Amazon Bedrock.
- Agilidade e flexibilidade:
- LangChain suporta uma ampla gama de LLMs, permitindo alternar entre diferentes modelos ou fornecedores, promovendo flexibilidade.
- A natureza de código aberto do LangChain permite melhorias e personalizações orientadas pela comunidade.
- Segurança:
- Como uma estrutura de código aberto, o LangChain pode exigir análises e verificações de segurança mais rigorosas dentro das organizações, potencialmente aumentando a sobrecarga.
Conclusão
Os assistentes de IA conversacional são ferramentas transformadoras para agilizar as operações e aprimorar as experiências do usuário. Esta postagem explorou duas abordagens poderosas usando serviços AWS: os agentes gerenciados para Amazon Bedrock e o roteamento dinâmico flexível e de código aberto LangChain. A escolha entre essas abordagens depende dos requisitos da sua organização, das preferências de desenvolvimento e do nível de personalização desejado. Independentemente do caminho percorrido, a AWS permite que você crie assistentes inteligentes de IA que revolucionam as interações comerciais e com os clientes
Encontre o código da solução e os ativos de implantação em nosso Repositório GitHub, onde você pode seguir as etapas detalhadas para cada abordagem de IA conversacional.
Sobre os autores
 Ameer Hakme é arquiteto de soluções da AWS baseado na Pensilvânia. Ele colabora com Fornecedores Independentes de Software (ISVs) na região Nordeste, auxiliando-os no projeto e construção de plataformas escaláveis e modernas na Nuvem AWS. Especialista em IA/ML e IA generativa, Ameer ajuda os clientes a desbloquear o potencial dessas tecnologias de ponta. Nas horas de lazer, gosta de andar de moto e passar bons momentos com a família.
Ameer Hakme é arquiteto de soluções da AWS baseado na Pensilvânia. Ele colabora com Fornecedores Independentes de Software (ISVs) na região Nordeste, auxiliando-os no projeto e construção de plataformas escaláveis e modernas na Nuvem AWS. Especialista em IA/ML e IA generativa, Ameer ajuda os clientes a desbloquear o potencial dessas tecnologias de ponta. Nas horas de lazer, gosta de andar de moto e passar bons momentos com a família.
 Sharon Lic é arquiteto de soluções de IA/ML na Amazon Web Services com sede em Boston, com paixão por projetar e construir aplicativos de IA generativos na AWS. Ela colabora com os clientes para aproveitar os serviços de IA/ML da AWS para soluções inovadoras.
Sharon Lic é arquiteto de soluções de IA/ML na Amazon Web Services com sede em Boston, com paixão por projetar e construir aplicativos de IA generativos na AWS. Ela colabora com os clientes para aproveitar os serviços de IA/ML da AWS para soluções inovadoras.
 Kawsar Kamal é arquiteto de soluções sênior na Amazon Web Services com mais de 15 anos de experiência em automação de infraestrutura e segurança. Ele ajuda os clientes a projetar e construir soluções escalonáveis de DevSecOps e AI/ML na nuvem.
Kawsar Kamal é arquiteto de soluções sênior na Amazon Web Services com mais de 15 anos de experiência em automação de infraestrutura e segurança. Ele ajuda os clientes a projetar e construir soluções escalonáveis de DevSecOps e AI/ML na nuvem.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/enhance-conversational-ai-with-advanced-routing-techniques-with-amazon-bedrock/

