Este é um post convidado co-escrito com Tamir Rubinsky e Aviad Aranias da Nielsen Sports.
Nielsen Esportes molda a mídia e o conteúdo mundial como líder global em insights, dados e análises de público. Através da nossa compreensão das pessoas e dos seus comportamentos em todos os canais e plataformas, capacitamos os nossos clientes com inteligência independente e acionável para que possam ligar-se e interagir com os seus públicos – agora e no futuro.
Na Nielsen Sports, nossa missão é fornecer aos nossos clientes – marcas e detentores de direitos – a capacidade de medir o retorno sobre o investimento (ROI) e a eficácia de uma campanha publicitária de patrocínio esportivo em todos os canais, incluindo TV, online, mídia social e até mesmo jornais, e fornecer uma segmentação precisa nos níveis local, nacional e internacional.
Nesta postagem, descrevemos como a Nielsen Sports modernizou um sistema que executa milhares de modelos diferentes de aprendizado de máquina (ML) em produção usando Amazon Sage Maker endpoints multimodelos (MMEs) e reduziu os custos operacionais e financeiros em 75%.
Desafios com segmentação de vídeo de canal
Nossa tecnologia é baseada em inteligência artificial (IA) e especificamente em visão computacional (CV), que nos permite rastrear a exposição da marca e identificar sua localização com precisão. Por exemplo, identificamos se a marca está num banner ou numa camisa. Além disso, identificamos a localização da marca na peça, como no canto superior de uma placa ou na manga. A figura a seguir mostra um exemplo de nosso sistema de etiquetagem.
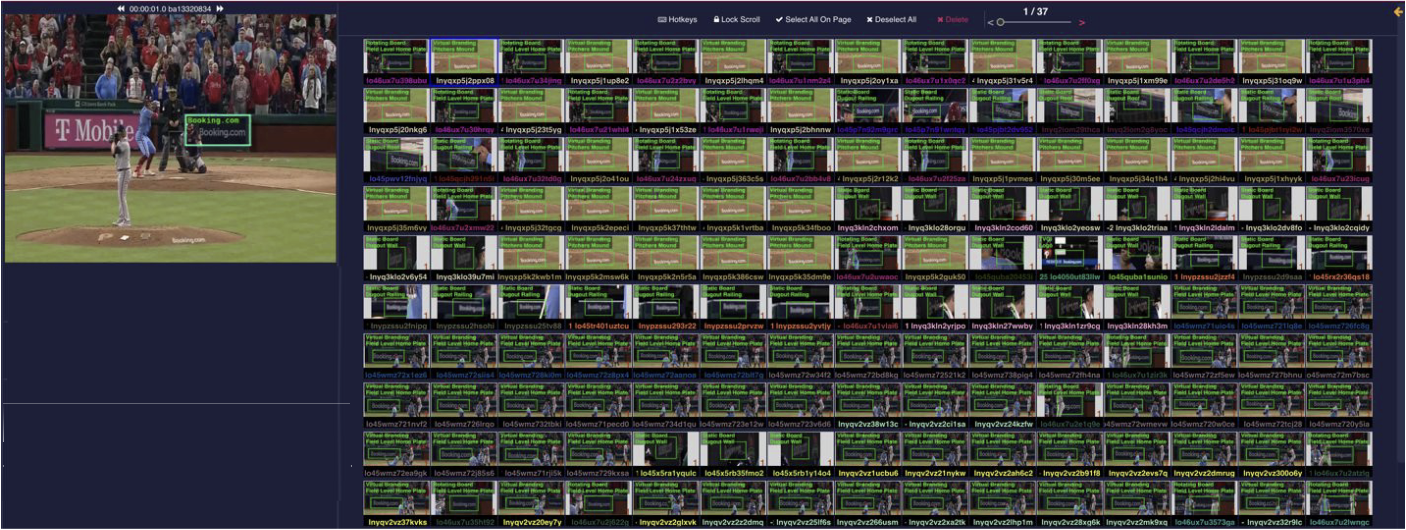
Para entender nossos desafios de escala e custo, vejamos alguns números representativos. Todos os meses, identificamos mais de 120 milhões de impressões de marcas em diferentes canais, e o sistema deve suportar a identificação de mais de 100,000 marcas e variações de diferentes marcas. Construímos um dos maiores bancos de dados de impressões de marcas do mundo, com mais de 6 bilhões de pontos de dados.
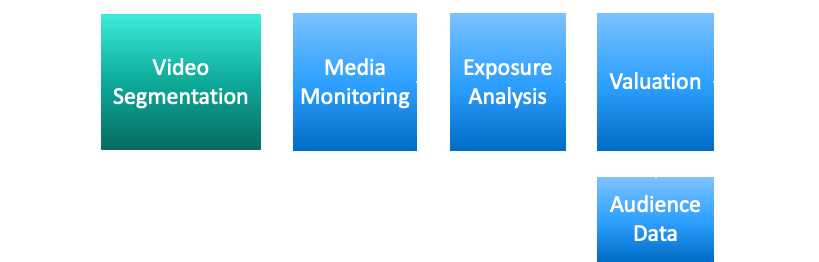
Nosso processo de avaliação de mídia inclui diversas etapas, conforme ilustrado na figura a seguir:
- Primeiro, gravamos milhares de canais em todo o mundo utilizando um sistema de gravação internacional.
- Transmitimos o conteúdo em combinação com a programação de transmissão (Guia Eletrônico de Programação) para a próxima etapa, que é a segmentação e separação entre as próprias transmissões do jogo e outros conteúdos ou propagandas.
- Realizamos monitoramento de mídia, onde adicionamos metadados adicionais a cada segmento, como resultados da liga, times relevantes e jogadores.
- Realizamos uma análise de exposição de visibilidade das marcas e depois combinamos as informações do público para calcular o valor da campanha.
- As informações são entregues ao cliente por meio de um dashboard ou relatórios de analistas. O analista tem acesso direto aos dados brutos ou através do nosso data warehouse.
Como operamos numa escala de mais de mil canais e dezenas de milhares de horas de vídeo por ano, devemos ter um sistema de automação escalável para o processo de análise. Nossa solução segmenta automaticamente a transmissão e sabe como isolar os videoclipes relevantes do restante do conteúdo.
Fazemos isso utilizando algoritmos e modelos dedicados desenvolvidos por nós para analisar as características específicas dos canais.
No total, estamos executando milhares de modelos diferentes em produção para apoiar esta missão, que é cara, gera sobrecarga operacional e é lenta e propensa a erros. Demorou meses para colocar em produção modelos com nova arquitetura de modelo.
É aqui que queríamos inovar e reestruturar nosso sistema.
Dimensionamento econômico para modelos de CV usando MMEs SageMaker
Nosso sistema legado de segmentação de vídeo era difícil de testar, alterar e manter. Alguns dos desafios incluem trabalhar com uma estrutura de ML antiga, interdependências entre componentes e um fluxo de trabalho difícil de otimizar. Isso ocorre porque nos baseamos no RabbitMQ para o pipeline, que era uma solução com estado. Para depurar um componente, como extração de recursos, tivemos que testar todo o pipeline.
O diagrama a seguir ilustra a arquitetura anterior.
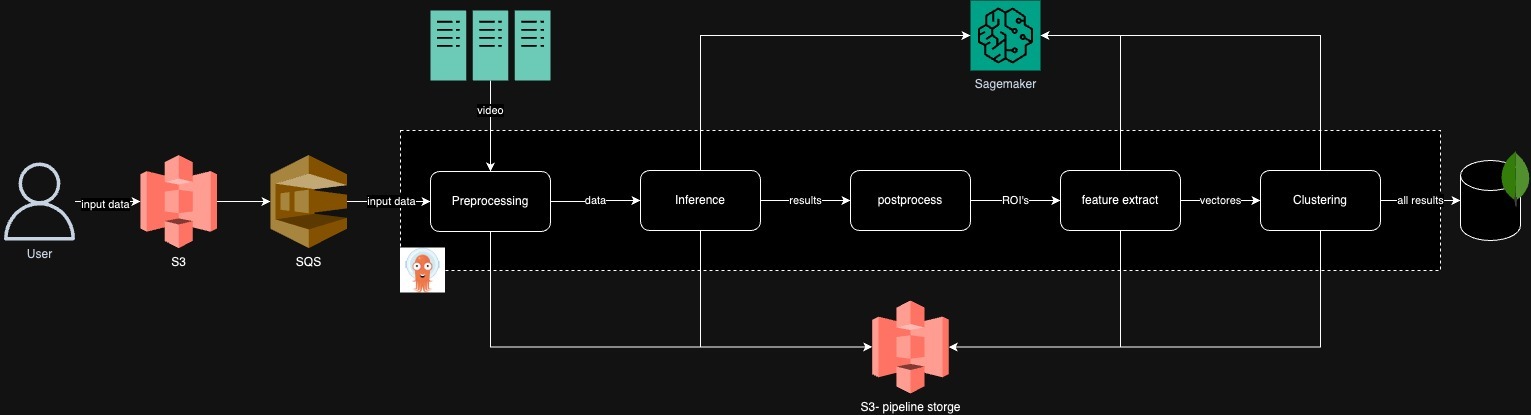
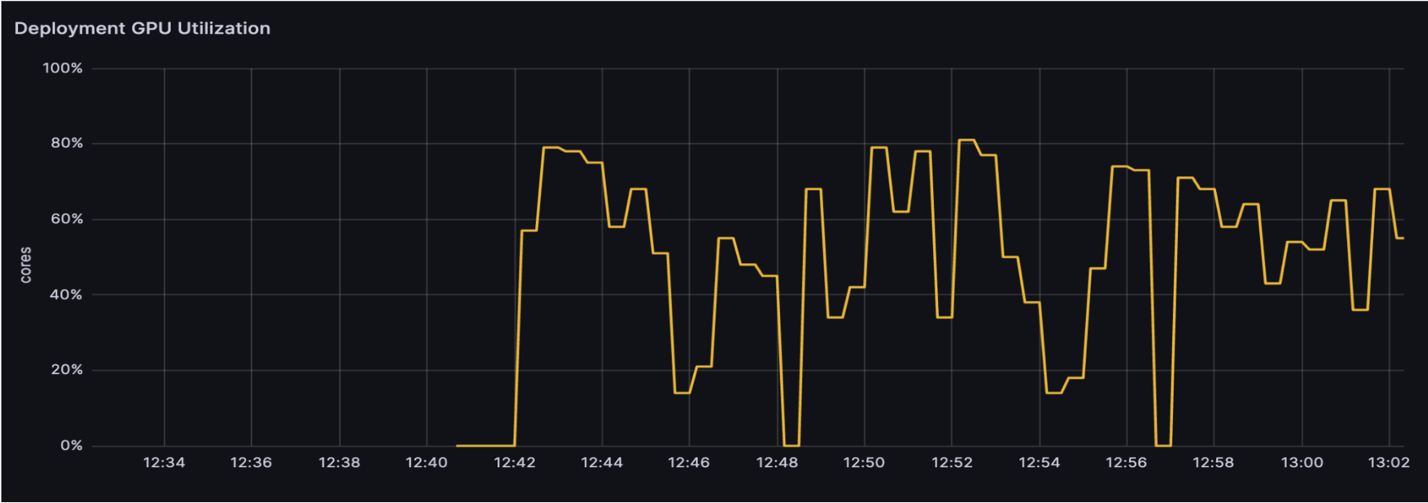
Como parte de nossa análise, identificamos gargalos de desempenho, como a execução de um único modelo em uma máquina, que mostrou uma baixa utilização de GPU de 30 a 40%. Também descobrimos execuções de pipeline e algoritmos de agendamento ineficientes para os modelos.
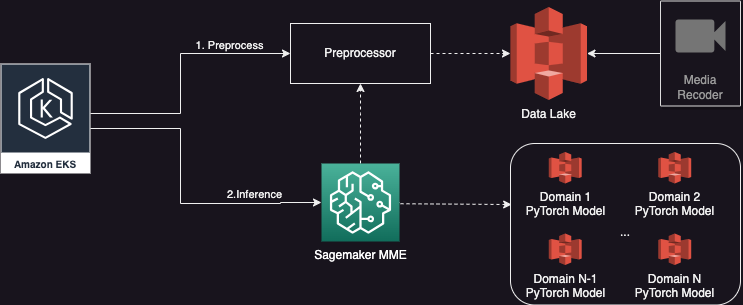
Portanto, decidimos construir uma nova arquitetura multilocatário baseada no SageMaker, que implementaria melhorias de otimização de desempenho, suportaria tamanhos de lote dinâmicos e executaria vários modelos simultaneamente.
Cada execução do fluxo de trabalho tem como alvo um grupo de vídeos. Cada vídeo tem entre 30 e 90 minutos de duração e cada grupo tem mais de cinco modelos para executar.
Vejamos um exemplo: um vídeo pode ter 60 minutos de duração, consistindo em 3,600 imagens, e cada imagem precisa ser inferida por três modelos de ML diferentes durante a primeira etapa. Com os MMEs SageMaker, podemos executar lotes de 12 imagens em paralelo, e o lote completo é concluído em menos de 2 segundos. Num dia normal, temos mais de 20 grupos de vídeos, e num dia de fim de semana movimentado, podemos ter mais de 100 grupos de vídeos.
O diagrama a seguir mostra nossa nova arquitetura simplificada usando um SageMaker MME.
Resultados
Com a nova arquitetura, alcançamos muitos dos resultados desejados e algumas vantagens invisíveis em relação à arquitetura antiga:
- Melhor tempo de execução – Ao aumentar o tamanho dos lotes (12 vídeos em paralelo) e executar vários modelos simultaneamente (cinco modelos em paralelo), reduzimos o tempo de execução geral do pipeline em 33%, de 1 hora para 40 minutos.
- Infraestrutura aprimorada – Com o SageMaker, atualizamos nossa infraestrutura existente e agora estamos usando instâncias AWS mais recentes com GPUs mais recentes, como g5.xlarge. Um dos maiores benefícios da mudança é a melhoria imediata do desempenho com o uso de otimizações TorchScript e CUDA.
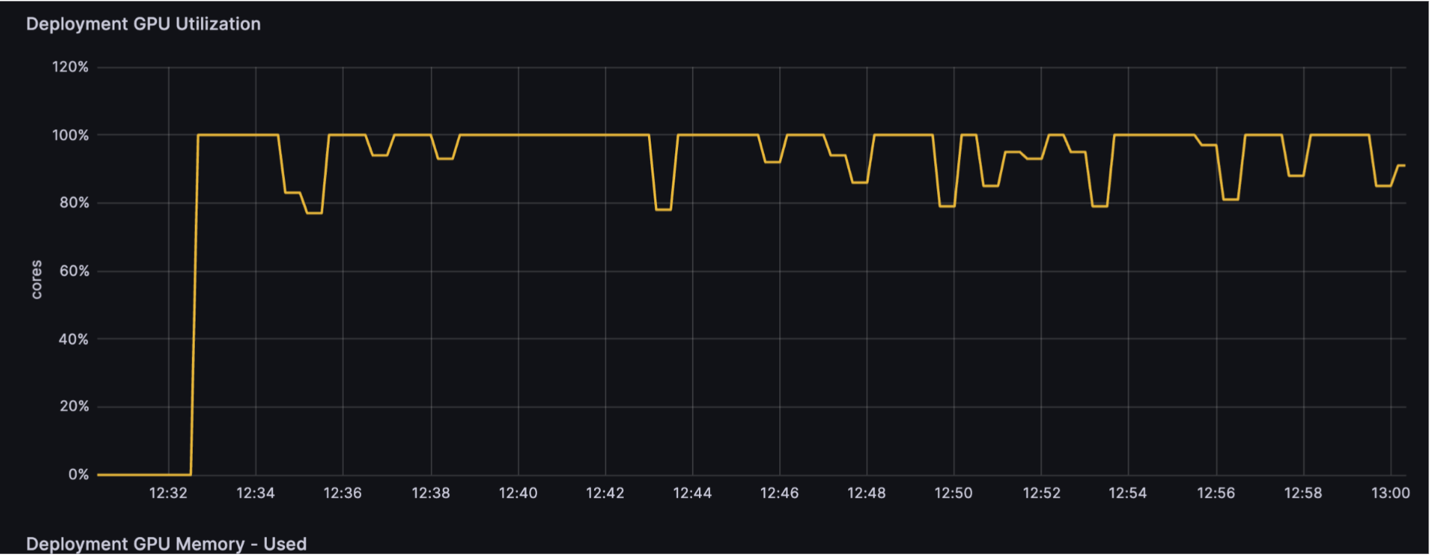
- Uso otimizado da infraestrutura – Ao ter um único endpoint que pode hospedar vários modelos, podemos reduzir o número de endpoints e o número de máquinas que precisamos manter, e também aumentar a utilização de uma única máquina e sua GPU. Para uma tarefa específica com cinco vídeos, passamos a utilizar apenas cinco máquinas de instâncias g5, o que nos dá 75% de custo benefício em relação à solução anterior. Para uma carga de trabalho típica durante o dia, usamos um único endpoint com uma única máquina g5.xlarge com utilização de GPU superior a 80%. Para efeito de comparação, a solução anterior tinha menos de 40% de utilização.
- Maior agilidade e produtividade – O uso do SageMaker nos permitiu gastar menos tempo migrando modelos e mais tempo melhorando nossos algoritmos e modelos principais. Isso aumentou a produtividade de nossas equipes de engenharia e ciência de dados. Agora podemos pesquisar e implantar um novo modelo de ML em menos de 7 dias, em vez de 1 mês anteriormente. Esta é uma melhoria de 75% na velocidade e no planejamento.
- Melhor qualidade e confiança – Com os recursos de teste A/B do SageMaker, podemos implantar nossos modelos de forma gradual e reverter com segurança. O ciclo de vida mais rápido até a produção também aumentou a precisão e os resultados dos nossos modelos de ML.
A figura a seguir mostra nossa utilização de GPU com a arquitetura anterior (30-40% de utilização da GPU).
A figura a seguir mostra nossa utilização de GPU com a nova arquitetura simplificada (90% de utilização de GPU).
Conclusão
Nesta postagem, compartilhamos como a Nielsen Sports modernizou um sistema que executa milhares de modelos diferentes em produção usando MMEs SageMaker e reduziu seus custos operacionais e financeiros em 75%.
Para leitura adicional, consulte o seguinte:
Sobre os autores
 Eitan Sela é arquiteto de soluções especialista em IA generativa e aprendizado de máquina na Amazon Web Services. Ele trabalha com clientes da AWS para fornecer orientação e assistência técnica, ajudando-os a criar e operar soluções de IA generativa e aprendizado de máquina na AWS. Em seu tempo livre, Eitan gosta de correr e ler os artigos mais recentes sobre aprendizado de máquina.
Eitan Sela é arquiteto de soluções especialista em IA generativa e aprendizado de máquina na Amazon Web Services. Ele trabalha com clientes da AWS para fornecer orientação e assistência técnica, ajudando-os a criar e operar soluções de IA generativa e aprendizado de máquina na AWS. Em seu tempo livre, Eitan gosta de correr e ler os artigos mais recentes sobre aprendizado de máquina.
 Gal Goldman é engenheiro de software sênior e arquiteto de soluções corporativo sênior na AWS, apaixonado por soluções de ponta. Ele é especialista e desenvolveu muitos serviços e soluções distribuídas de aprendizado de máquina. Gal também se concentra em ajudar os clientes da AWS a acelerar e superar seus desafios de engenharia e IA generativa.
Gal Goldman é engenheiro de software sênior e arquiteto de soluções corporativo sênior na AWS, apaixonado por soluções de ponta. Ele é especialista e desenvolveu muitos serviços e soluções distribuídas de aprendizado de máquina. Gal também se concentra em ajudar os clientes da AWS a acelerar e superar seus desafios de engenharia e IA generativa.
 Tal Panchek é gerente sênior de desenvolvimento de negócios para inteligência artificial e aprendizado de máquina na Amazon Web Services. Como especialista em BD, ele é responsável pelo aumento da adoção, utilização e receita dos serviços da AWS. Ele reúne as necessidades dos clientes e do setor e faz parceria com equipes de produtos da AWS para inovar, desenvolver e fornecer soluções da AWS.
Tal Panchek é gerente sênior de desenvolvimento de negócios para inteligência artificial e aprendizado de máquina na Amazon Web Services. Como especialista em BD, ele é responsável pelo aumento da adoção, utilização e receita dos serviços da AWS. Ele reúne as necessidades dos clientes e do setor e faz parceria com equipes de produtos da AWS para inovar, desenvolver e fornecer soluções da AWS.
 Tamir Rubinsky lidera a Engenharia Global de P&D na Nielsen Sports, trazendo vasta experiência na construção de produtos inovadores e no gerenciamento de equipes de alto desempenho. Seu trabalho transformou a avaliação de mídia de patrocínio esportivo por meio de soluções inovadoras baseadas em IA.
Tamir Rubinsky lidera a Engenharia Global de P&D na Nielsen Sports, trazendo vasta experiência na construção de produtos inovadores e no gerenciamento de equipes de alto desempenho. Seu trabalho transformou a avaliação de mídia de patrocínio esportivo por meio de soluções inovadoras baseadas em IA.
 Aviad Aranias é líder de equipe MLOps e arquiteto de análise esportiva da Nielsen, especializado na criação de pipelines complexos para análise de vídeos de eventos esportivos em vários canais. Ele se destaca na construção e implantação de modelos de aprendizagem profunda para lidar com dados em grande escala com eficiência. Nas horas vagas, ele gosta de preparar deliciosas pizzas napolitanas.
Aviad Aranias é líder de equipe MLOps e arquiteto de análise esportiva da Nielsen, especializado na criação de pipelines complexos para análise de vídeos de eventos esportivos em vários canais. Ele se destaca na construção e implantação de modelos de aprendizagem profunda para lidar com dados em grande escala com eficiência. Nas horas vagas, ele gosta de preparar deliciosas pizzas napolitanas.
- Conteúdo com tecnologia de SEO e distribuição de relações públicas. Seja amplificado hoje.
- PlatoData.Network Gerativa Vertical Ai. Capacite-se. Acesse aqui.
- PlatoAiStream. Inteligência Web3. Conhecimento Amplificado. Acesse aqui.
- PlatãoESG. Carbono Tecnologia Limpa, Energia, Ambiente, Solar, Gestão de resíduos. Acesse aqui.
- PlatoHealth. Inteligência em Biotecnologia e Ensaios Clínicos. Acesse aqui.
- Fonte: https://aws.amazon.com/blogs/machine-learning/nielsen-sports-sees-75-cost-reduction-in-video-analysis-with-amazon-sagemaker-multi-model-endpoints/

