Skuteczne zasady kontroli umożliwiają przedsiębiorstwom przemysłowym zwiększanie rentowności poprzez maksymalizację produktywności przy jednoczesnej redukcji nieplanowanych przestojów i zużycia energii. Znalezienie optymalnych zasad kontroli jest złożonym zadaniem, ponieważ systemy fizyczne, takie jak reaktory chemiczne i turbiny wiatrowe, są często trudne do modelowania, a dryf w dynamice procesu może z czasem powodować pogorszenie wydajności. Uczenie się przez wzmacnianie w trybie offline to strategia kontroli, która umożliwia przedsiębiorstwom przemysłowym budowanie polityk kontroli wyłącznie na podstawie danych historycznych, bez potrzeby tworzenia wyraźnego modelu procesu. Podejście to nie wymaga interakcji z procesem bezpośrednio na etapie eksploracji, co usuwa jedną z barier w przyjęciu uczenia się przez wzmacnianie w zastosowaniach krytycznych dla bezpieczeństwa. W tym poście zbudujemy kompleksowe rozwiązanie, aby znaleźć optymalne zasady kontroli, korzystając wyłącznie z danych historycznych Amazon Sage Maker za pomocą Raya RLlib biblioteka. Aby dowiedzieć się więcej na temat uczenia się przez wzmacnianie, zob Korzystaj z uczenia się przez wzmacnianie w Amazon SageMaker.
Przypadków użycia
Sterowanie przemysłowe obejmuje zarządzanie złożonymi systemami, takimi jak linie produkcyjne, sieci energetyczne i zakłady chemiczne, w celu zapewnienia wydajnego i niezawodnego działania. Wiele tradycyjnych strategii sterowania opiera się na predefiniowanych regułach i modelach, które często wymagają ręcznej optymalizacji. W niektórych branżach standardową praktyką jest monitorowanie wydajności i dostosowywanie polityki kontroli, na przykład gdy sprzęt zaczyna się pogarszać lub zmieniają się warunki środowiskowe. Ponowne dostrojenie może zająć tygodnie i może wymagać wprowadzenia zewnętrznych wzbudzeń do systemu w celu zarejestrowania jego reakcji metodą prób i błędów.
Uczenie się przez wzmacnianie wyłoniło się jako nowy paradygmat kontroli procesu, pozwalający na uczenie się optymalnych zasad kontroli poprzez interakcję z otoczeniem. Proces ten wymaga podzielenia danych na trzy kategorie: 1) pomiary dostępne z systemu fizycznego, 2) zestaw działań, które można podjąć w systemie oraz 3) liczbowy miernik (nagroda) wydajności sprzętu. Politykę szkoli się tak, aby w danej obserwacji znaleźć działanie, które prawdopodobnie przyniesie najwyższe przyszłe nagrody.
W trybie uczenia się przez wzmacnianie w trybie offline można wytrenować zasady na danych historycznych przed wdrożeniem ich w środowisku produkcyjnym. Algorytm przeszkolony w tym poście na blogu nazywa się „Konserwatywne uczenie się Q” (CQL). CQL zawiera model „aktora” i model „krytyka” i ma na celu konserwatywne przewidywanie własnych wyników po podjęciu zalecanego działania. W tym poście proces ten został zademonstrowany za pomocą ilustracyjnego problemu sterowania wózkiem i masztem. Celem jest wyszkolenie agenta w balansowaniu drążkiem na wózku i jednoczesnym przesuwaniu wózka w stronę wyznaczonego celu. Procedura uczenia wykorzystuje dane offline, umożliwiając agentowi uczenie się na podstawie istniejących informacji. To studium przypadku z wózkiem demonstruje proces szkoleniowy i jego skuteczność w potencjalnych zastosowaniach w świecie rzeczywistym.
Omówienie rozwiązania
Rozwiązanie zaprezentowane w tym poście automatyzuje wdrożenie kompleksowego przepływu pracy do uczenia się przez wzmacnianie w trybie offline z wykorzystaniem danych historycznych. Poniższy diagram opisuje architekturę używaną w tym przepływie pracy. Dane pomiarowe są generowane na krawędzi przez urządzenie przemysłowe (tutaj symulowane przez AWS Lambda funkcjonować). Dane są umieszczane w pliku Amazonka Kinesis Data Firehose, w którym jest on przechowywany Usługa Amazon Simple Storage (Amazon S3). Amazon S3 to trwałe, wydajne i niedrogie rozwiązanie do przechowywania danych, które umożliwia udostępnianie dużych ilości danych w procesie szkolenia w zakresie uczenia maszynowego.
Klej AWS kataloguje dane i udostępnia je przy użyciu zapytań Amazonka Atena. Athena przekształca dane pomiarowe w formę, którą może przyjąć algorytm uczenia się przez wzmacnianie, a następnie ładuje je z powrotem do Amazon S3. Amazon SageMaker ładuje te dane do zadania szkoleniowego i tworzy przeszkolony model. Następnie SageMaker udostępnia ten model w punkcie końcowym SageMaker. Sprzęt przemysłowy może następnie wysłać zapytanie do tego punktu końcowego, aby otrzymać zalecenia dotyczące działań.
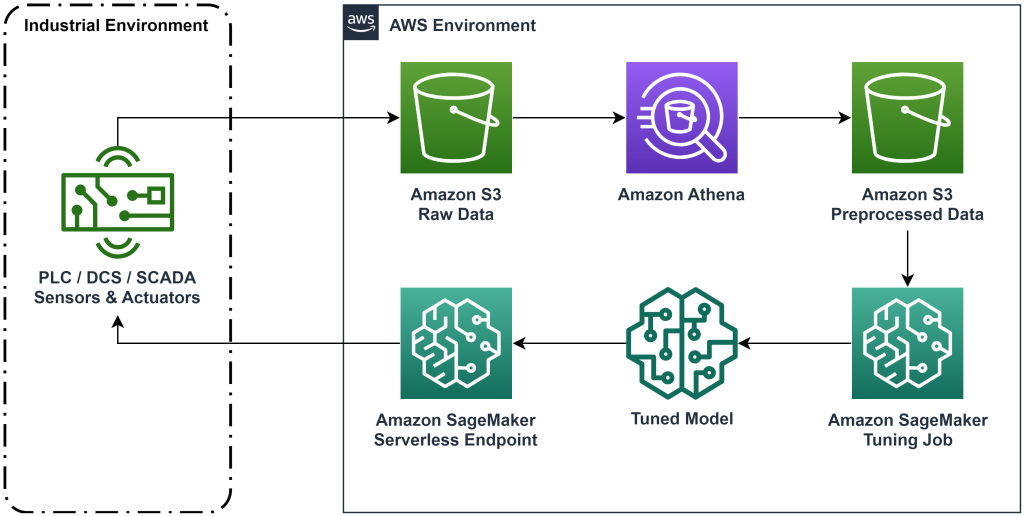
Rysunek 1: Diagram architektury przedstawiający kompleksowy proces uczenia się przez wzmacnianie.
W tym poście podzielimy przepływ pracy na następujące kroki:
- Sformułuj problem. Zdecyduj, jakie działania można podjąć, na jakich pomiarach oprzeć zalecenia i określ liczbowo skuteczność każdego działania.
- Przygotuj dane. Przekształć tabelę pomiarów w format, który może wykorzystać algorytm uczenia maszynowego.
- Trenuj algorytm na tych danych.
- Wybierz najlepszy przebieg treningowy na podstawie wskaźników treningowych.
- Wdróż model w punkcie końcowym SageMaker.
- Oceń wydajność modelu w produkcji.
Wymagania wstępne
Aby ukończyć ten przewodnik, musisz mieć plik Konto AWS oraz interfejs wiersza poleceń z Zainstalowany AWS SAM. Wykonaj poniższe kroki, aby wdrożyć szablon AWS SAM w celu uruchomienia tego przepływu pracy i wygenerowania danych szkoleniowych:
- Pobierz repozytorium kodu za pomocą polecenia
- Zmień katalog na repozytorium:
- Zbuduj repozytorium:
- Wdróż repozytorium
- Użyj poniższych poleceń, aby wywołać skrypt bash, który generuje fałszywe dane przy użyciu funkcji AWS Lambda.
sudo yum install jqcd utilssh generate_mock_data.sh
Przewodnik po rozwiązaniu
Sformułuj problem
Nasz system opisany w tym poście to wózek z wyważonym drążkiem na górze. System działa dobrze, gdy rura jest wyprostowana, a pozycja wózka jest zbliżona do pozycji bramkowej. W etapie wstępnym wygenerowaliśmy dane historyczne z tego systemu.
Poniższa tabela przedstawia dane historyczne zebrane z systemu.
| Pozycja wózka | Prędkość wózka | Kąt bieguna | Prędkość kątowa bieguna | Pozycja bramkowa | Siła zewnętrzna | Nagradzać | Czas |
| 0.53 | -0.79 | -0.08 | 0.16 | 0.50 | -0.04 | 11.5 | 5: 37: 54 PM |
| 0.51 | -0.82 | -0.07 | 0.17 | 0.50 | -0.04 | 11.9 | 5: 37: 55 PM |
| 0.50 | -0.84 | -0.07 | 0.18 | 0.50 | -0.03 | 12.2 | 5: 37: 56 PM |
| 0.48 | -0.85 | -0.07 | 0.18 | 0.50 | -0.03 | 10.5 | 5: 37: 57 PM |
| 0.46 | -0.87 | -0.06 | 0.19 | 0.50 | -0.03 | 10.3 | 5: 37: 58 PM |
Możesz zapytać o historyczne informacje o systemie za pomocą Amazon Athena za pomocą następującego zapytania:
Stan tego układu jest definiowany przez położenie wózka, prędkość wózka, kąt bieguna, prędkość kątową bieguna i położenie bramki. Działaniem podejmowanym w każdym kroku jest siła zewnętrzna przyłożona do wózka. Symulowane środowisko generuje nagrodę, która jest wyższa, gdy wózek znajduje się bliżej pozycji docelowej, a rura jest bardziej wyprostowana.
Przygotuj dane
Aby przedstawić informacje o systemie modelowi uczenia się przez wzmacnianie, przekształć je w obiekty JSON z kluczami kategoryzującymi wartości na kategorie stanu (zwanego także obserwacją), działania i nagrody. Przechowuj te obiekty w Amazon S3. Oto przykład obiektów JSON utworzonych na podstawie kroków czasowych z poprzedniej tabeli.
|
{“obs”:[[0.53,-0.79,-0.08,0.16,0.5]], “action”:[[-0.04]], “reward”:[11.5] ,”next_obs”:[[0.51,-0.82,-0.07,0.17,0.5]]} |
|
{“obs”:[[0.51,-0.82,-0.07,0.17,0.5]], “action”:[[-0.04]], “reward”:[11.9], “next_obs”:[[0.50,-0.84,-0.07,0.18,0.5]]} |
|
{“obs”:[[0.50,-0.84,-0.07,0.18,0.5]], “action”:[[-0.03]], “reward”:[12.2], “next_obs”:[[0.48,-0.85,-0.07,0.18,0.5]]} |
Stos AWS CloudFormation zawiera dane wyjściowe o nazwie AthenaQueryToCreateJsonFormatedData. Uruchom to zapytanie w Amazon Athena, aby przeprowadzić transformację i zapisać obiekty JSON w Amazon S3. Algorytm uczenia się przez wzmacnianie wykorzystuje strukturę tych obiektów JSON, aby zrozumieć, na jakich wartościach opierać się rekomendacje i wynik podejmowania działań w danych historycznych.
Agent pociągowy
Teraz możemy rozpocząć zadanie szkoleniowe, aby wygenerować przeszkolony model rekomendacji działań. Amazon SageMaker pozwala szybko uruchomić wiele zadań szkoleniowych, aby zobaczyć, jak różne konfiguracje wpływają na wynikowy wytrenowany model. Wywołaj funkcję Lambda o nazwie TuningJobLauncherFunction aby rozpocząć zadanie dostrajania hiperparametrów, które podczas uczenia algorytmu eksperymentuje z czterema różnymi zestawami hiperparametrów.
Wybierz najlepszy bieg treningowy
Aby dowiedzieć się, które z zadań szkoleniowych stworzyło najlepszy model, przeanalizuj krzywe strat utworzone podczas szkolenia. Model krytyka CQL szacuje wydajność aktora (zwaną wartością Q) po wykonaniu zalecanego działania. Część funkcji straty krytyka obejmuje błąd różnicy czasowej. Ta metryka mierzy dokładność wartości Q krytyka. Szukaj przebiegów treningowych z wysoką średnią wartością Q i niskim błędem różnicy czasowej. Ten papier, Proces uczenia się w trybie offline, bez użycia modeli, przy użyciu robota, szczegółowo opisano, jak wybrać najlepszy bieg treningowy. Repozytorium kodu zawiera plik, /utils/investigate_training.py, co tworzy fascynującą figurę HTML opisującą najnowsze zadanie szkoleniowe. Uruchom ten plik i użyj wyników, aby wybrać najlepszy przebieg treningowy.
Możemy użyć średniej wartości Q, aby przewidzieć wydajność wyszkolonego modelu. Wartości Q są szkolone w celu konserwatywnego przewidywania sumy zdyskontowanych przyszłych wartości nagród. W przypadku procesów długotrwałych możemy przeliczyć tę liczbę na wykładniczą średnią ważoną, mnożąc wartość Q przez (1 – „stopę dyskontową”). Najlepszy przebieg treningowy w tym zestawie osiągnął średnią wartość Q wynoszącą 539. Nasza stopa dyskontowa wynosi 0.99, więc model przewiduje co najmniej 5.39 średniej nagrody na krok czasowy. Można porównać tę wartość z historyczną wydajnością systemu, aby określić, czy nowy model będzie działał lepiej niż historyczna polityka kontroli. W tym eksperymencie średnia nagroda na krok czasowy wynikająca z danych historycznych wyniosła 4.3, zatem model CQL przewiduje o 25 procent lepszą wydajność niż system osiągany w przeszłości.
Wdróż model
Punkty końcowe Amazon SageMaker umożliwiają obsługę modeli uczenia maszynowego na kilka różnych sposobów, aby sprostać różnorodnym przypadkom użycia. W tym poście użyjemy typu punktu końcowego bezserwerowego, aby nasz punkt końcowy automatycznie skalował się w zależności od zapotrzebowania i płacimy za wykorzystanie mocy obliczeniowej tylko wtedy, gdy punkt końcowy generuje wnioskowanie. Aby wdrożyć bezserwerowy punkt końcowy, dołącz plik Wariant produkcyjnyKonfiguracja bezserwerowa wariant produkcyjny z SageMakera konfiguracja punktu końcowego. Poniższy fragment kodu pokazuje, jak bezserwerowy punkt końcowy w tym przykładzie jest wdrażany przy użyciu zestawu programistycznego Amazon SageMaker dla języka Python. Znajdź przykładowy kod używany do wdrożenia modelu w witrynie sagemaker-offline-wzmocnienie-learning-ray-cql.
Przeszkolone pliki modelu znajdują się w artefaktach modelu S3 dla każdego przebiegu szkoleniowego. Aby wdrożyć model uczenia maszynowego, zlokalizuj pliki modelu najlepszego przebiegu szkoleniowego i wywołaj funkcję Lambda o nazwie „ModelDeployerFunction” ze zdarzeniem zawierającym dane tego modelu. Funkcja Lambda uruchomi bezserwerowy punkt końcowy SageMaker w celu obsługi przeszkolonego modelu. Przykładowe zdarzenie do wykorzystania przy wywoływaniu metody „ModelDeployerFunction"
Oceń wydajność przeszkolonego modelu
Czas sprawdzić jak nasz wytrenowany model radzi sobie w produkcji! Aby sprawdzić wydajność nowego modelu, wywołaj funkcję Lambda o nazwie „RunPhysicsSimulationFunction” z nazwą punktu końcowego SageMaker w zdarzeniu. Spowoduje to uruchomienie symulacji przy użyciu działań zalecanych przez punkt końcowy. Przykładowe zdarzenie do użycia podczas wywoływania metody RunPhysicsSimulatorFunction:
Użyj następującego zapytania Athena, aby porównać wydajność przeszkolonego modelu z historyczną wydajnością systemu.
| Źródło akcji | Średnia nagroda za krok czasowy |
trained_model |
10.8 |
historic_data |
4.3 |
Poniższe animacje pokazują różnicę między przykładowym odcinkiem z danych szkoleniowych a odcinkiem, w którym przeszkolony model został użyty do wybrania akcji, którą należy wykonać. W animacjach niebieskie pole to wózek, niebieska linia to słup, a zielony prostokąt to lokalizacja celu. Czerwona strzałka pokazuje siłę przyłożoną do wózka w każdym kroku czasowym. Czerwona strzałka w danych szkoleniowych często przeskakuje w tę i z powrotem, ponieważ dane zostały wygenerowane przy użyciu 50% działań eksperckich i 50% działań losowych. Wyszkolony model nauczył się polityki kontroli, która szybko przesuwa wózek do pozycji docelowej, zachowując jednocześnie stabilność, wyłącznie poprzez obserwację demonstracji nieekspertów.
 |
 |
Sprzątać
Aby usunąć zasoby używane w tym przepływie pracy, przejdź do sekcji zasobów stosu Amazon CloudFormation i usuń zasobniki S3 oraz role IAM. Następnie usuń sam stos CloudFormation.
Wnioski
Uczenie się przez wzmacnianie w trybie offline może pomóc firmom przemysłowym zautomatyzować wyszukiwanie optymalnych polityk bez narażania bezpieczeństwa dzięki wykorzystaniu danych historycznych. Aby wdrożyć to podejście w swoich operacjach, zacznij od zidentyfikowania pomiarów składających się na system zdeterminowany stanem, działań, którymi możesz sterować, oraz metryk wskazujących pożądaną wydajność. Następnie dostęp to repozytorium GitHub za wdrożenie automatycznego, kompleksowego rozwiązania z wykorzystaniem Ray i Amazon SageMaker.
Post jedynie zarysowuje powierzchnię tego, co możesz zrobić z Amazon SageMaker RL. Spróbuj i prześlij nam swoją opinię w formacie Forum dyskusyjne Amazon SageMaker lub przez zwykłe kontakty AWS.
O autorach
 Walta Mayfielda jest architektem rozwiązań w AWS i pomaga firmom energetycznym działać bezpieczniej i wydajniej. Przed dołączeniem do AWS Walt pracował jako inżynier operacyjny w Hilcorp Energy Company. W wolnym czasie lubi pracować w ogrodzie i łowić ryby.
Walta Mayfielda jest architektem rozwiązań w AWS i pomaga firmom energetycznym działać bezpieczniej i wydajniej. Przed dołączeniem do AWS Walt pracował jako inżynier operacyjny w Hilcorp Energy Company. W wolnym czasie lubi pracować w ogrodzie i łowić ryby.
 Filip Lopez jest starszym architektem rozwiązań w AWS, specjalizującym się w operacjach związanych z produkcją ropy i gazu. Przed dołączeniem do AWS Felipe współpracował z GE Digital i Schlumberger, gdzie skupiał się na modelowaniu i optymalizacji produktów do zastosowań przemysłowych.
Filip Lopez jest starszym architektem rozwiązań w AWS, specjalizującym się w operacjach związanych z produkcją ropy i gazu. Przed dołączeniem do AWS Felipe współpracował z GE Digital i Schlumberger, gdzie skupiał się na modelowaniu i optymalizacji produktów do zastosowań przemysłowych.
 Yingwei Yu jest naukowcem stosowanym w Inkubatorze Generative AI w AWS. Ma doświadczenie w pracy z kilkoma organizacjami z różnych branż nad różnymi weryfikacjami koncepcji uczenia maszynowego, w tym przetwarzania języka naturalnego, analizy szeregów czasowych i konserwacji predykcyjnej. W wolnym czasie lubi pływać, malować, wędrować i spędzać czas z rodziną i przyjaciółmi.
Yingwei Yu jest naukowcem stosowanym w Inkubatorze Generative AI w AWS. Ma doświadczenie w pracy z kilkoma organizacjami z różnych branż nad różnymi weryfikacjami koncepcji uczenia maszynowego, w tym przetwarzania języka naturalnego, analizy szeregów czasowych i konserwacji predykcyjnej. W wolnym czasie lubi pływać, malować, wędrować i spędzać czas z rodziną i przyjaciółmi.
 Haozhu Wang jest pracownikiem naukowym w Amazon Bedrock, zajmującym się budowaniem modeli fundamentów Titan firmy Amazon. Wcześniej pracował w Amazon ML Solutions Lab jako współkierownik działu Reinforcement Learning Vertical i pomagał klientom budować zaawansowane rozwiązania ML w oparciu o najnowsze badania dotyczące uczenia się przez wzmacnianie, przetwarzania języka naturalnego i uczenia się za pomocą grafów. Haozhu uzyskał stopień doktora inżynierii elektrycznej i komputerowej na Uniwersytecie Michigan.
Haozhu Wang jest pracownikiem naukowym w Amazon Bedrock, zajmującym się budowaniem modeli fundamentów Titan firmy Amazon. Wcześniej pracował w Amazon ML Solutions Lab jako współkierownik działu Reinforcement Learning Vertical i pomagał klientom budować zaawansowane rozwiązania ML w oparciu o najnowsze badania dotyczące uczenia się przez wzmacnianie, przetwarzania języka naturalnego i uczenia się za pomocą grafów. Haozhu uzyskał stopień doktora inżynierii elektrycznej i komputerowej na Uniwersytecie Michigan.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- PlatoData.Network Pionowe generatywne AI. Wzmocnij się. Dostęp tutaj.
- PlatoAiStream. Inteligencja Web3. Wiedza wzmocniona. Dostęp tutaj.
- PlatonESG. Motoryzacja / pojazdy elektryczne, Węgiel Czysta technologia, Energia, Środowisko, Słoneczny, Gospodarowanie odpadami. Dostęp tutaj.
- Platon Zdrowie. Inteligencja w zakresie biotechnologii i badań klinicznych. Dostęp tutaj.
- ChartPrime. Podnieś poziom swojej gry handlowej dzięki ChartPrime. Dostęp tutaj.
- Przesunięcia bloków. Modernizacja własności offsetu środowiskowego. Dostęp tutaj.
- Źródło: https://aws.amazon.com/blogs/machine-learning/optimize-equipment-performance-with-historical-data-ray-and-amazon-sagemaker/

