Structured Query Language (SQL) to złożony język, który wymaga zrozumienia baz danych i metadanych. Dzisiaj, generatywna sztuczna inteligencja może pomóc osobom bez znajomości języka SQL. To generatywne zadanie AI nosi nazwę Text-to-SQL i generuje zapytania SQL na podstawie przetwarzania języka naturalnego (NLP) i konwertuje tekst na poprawny semantycznie kod SQL. Rozwiązanie przedstawione w tym poście ma na celu wyniesienie działań analityki korporacyjnej na wyższy poziom poprzez skrócenie ścieżki do danych przy użyciu języka naturalnego.
Wraz z pojawieniem się dużych modeli językowych (LLM), generowanie SQL oparte na NLP przeszło znaczącą transformację. Wykazując wyjątkową wydajność, LLM są teraz w stanie generować dokładne zapytania SQL na podstawie opisów w języku naturalnym. Jednak wyzwania nadal pozostają. Po pierwsze, język ludzki jest z natury niejednoznaczny i zależny od kontekstu, podczas gdy SQL jest precyzyjny, matematyczny i uporządkowany. Ta luka może skutkować niedokładną konwersją potrzeb użytkownika na wygenerowany kod SQL. Po drugie, może być konieczne zbudowanie funkcji zamiany tekstu na SQL dla każdej bazy danych, ponieważ dane często nie są przechowywane w jednym miejscu docelowym. Konieczne może być odtworzenie możliwości każdej bazy danych, aby umożliwić użytkownikom generowanie kodu SQL w oparciu o NLP. Po trzecie, pomimo szerszego zastosowania scentralizowanych rozwiązań analitycznych, takich jak jeziora danych i hurtownie, złożoność wzrasta wraz z różnymi nazwami tabel i innymi metadanymi wymaganymi do utworzenia kodu SQL dla żądanych źródeł. Dlatego też gromadzenie kompleksowych i wysokiej jakości metadanych również pozostaje wyzwaniem. Aby dowiedzieć się więcej o najlepszych praktykach i wzorcach projektowych zamiany tekstu na SQL, zobacz Generowanie wartości z danych przedsiębiorstwa: najlepsze praktyki dotyczące Text2SQL i generatywnej sztucznej inteligencji.
Nasze rozwiązanie ma na celu sprostanie tym wyzwaniom związanym z wykorzystaniem Amazońska skała macierzysta i Usługi analityczne AWS. Używamy Antropiczny Claude v2.1 na Amazon Bedrock jako nasz LLM. Aby sprostać tym wyzwaniom, nasze rozwiązanie najpierw uwzględnia metadane źródeł danych w pliku Katalog danych kleju AWS w celu zwiększenia dokładności generowanego zapytania SQL. Przepływ pracy obejmuje również pętlę końcowej oceny i korekty, na wypadek zidentyfikowania jakichkolwiek problemów SQL Amazonka Atena, który jest używany jako silnik SQL. Atena pozwala nam także korzystać z mnóstwa obsługiwane punkty końcowe i łączniki aby objąć duży zestaw źródeł danych.
Po przejściu przez kolejne etapy budowania rozwiązania przedstawiamy wyniki niektórych scenariuszy testowych o różnym poziomie złożoności SQL. Na koniec omówimy, jak łatwo można włączyć różne źródła danych do zapytań SQL.
Omówienie rozwiązania
Nasza architektura obejmuje trzy krytyczne komponenty: generację rozszerzoną pobierania (RAG) z metadanymi bazy danych, wieloetapową pętlę samokorekty oraz technologię Athena jako nasz silnik SQL.
Używamy metody RAG do pobierania opisów tabel i opisów schematów (kolumn) z metastore AWS Glue, aby mieć pewność, że żądanie jest powiązane z właściwą tabelą i zbiorami danych. W naszym rozwiązaniu zbudowaliśmy poszczególne kroki umożliwiające uruchomienie frameworku RAG z katalogiem danych kleju AWS w celach demonstracyjnych. Można jednak również skorzystać bazy wiedzy w Amazon Bedrock, aby szybko tworzyć rozwiązania RAG.
Komponent wieloetapowy pozwala LLM poprawić wygenerowane zapytanie SQL pod kątem dokładności. Tutaj wygenerowany kod SQL jest wysyłany w przypadku błędów składniowych. Używamy komunikatów o błędach Athena, aby wzbogacić nasze monity o LLM w celu uzyskania dokładniejszych i skuteczniejszych poprawek w wygenerowanym SQL.
Komunikaty o błędach pojawiające się czasami od usługi Athena można traktować jako informację zwrotną. Konsekwencje kosztowe etapu korekcji błędów są znikome w porównaniu z dostarczoną wartością. Możesz nawet uwzględnić te kroki naprawcze jako przykłady wzmocnionego uczenia się pod nadzorem, aby dostroić swoje LLM. Jednak dla uproszczenia nie omówiliśmy tego przepływu w naszym poście.
Należy pamiętać, że zawsze istnieje ryzyko wystąpienia niedokładności, które naturalnie wiąże się z generatywnymi rozwiązaniami AI. Nawet jeśli komunikaty o błędach Athena są bardzo skuteczne w ograniczaniu tego ryzyka, możesz dodać więcej kontroli i widoków, takich jak opinie ludzi lub przykładowe zapytania w celu dostrojenia, aby jeszcze bardziej zminimalizować takie ryzyko.
Athena nie tylko pozwala nam korygować zapytania SQL, ale także upraszcza dla nas ogólny problem, ponieważ służy jako hub, w którym szprychy stanowią wiele źródeł danych. Zarządzanie dostępem, składnia SQL i inne funkcje są obsługiwane przez Athenę.
Poniższy schemat ilustruje architekturę rozwiązania.
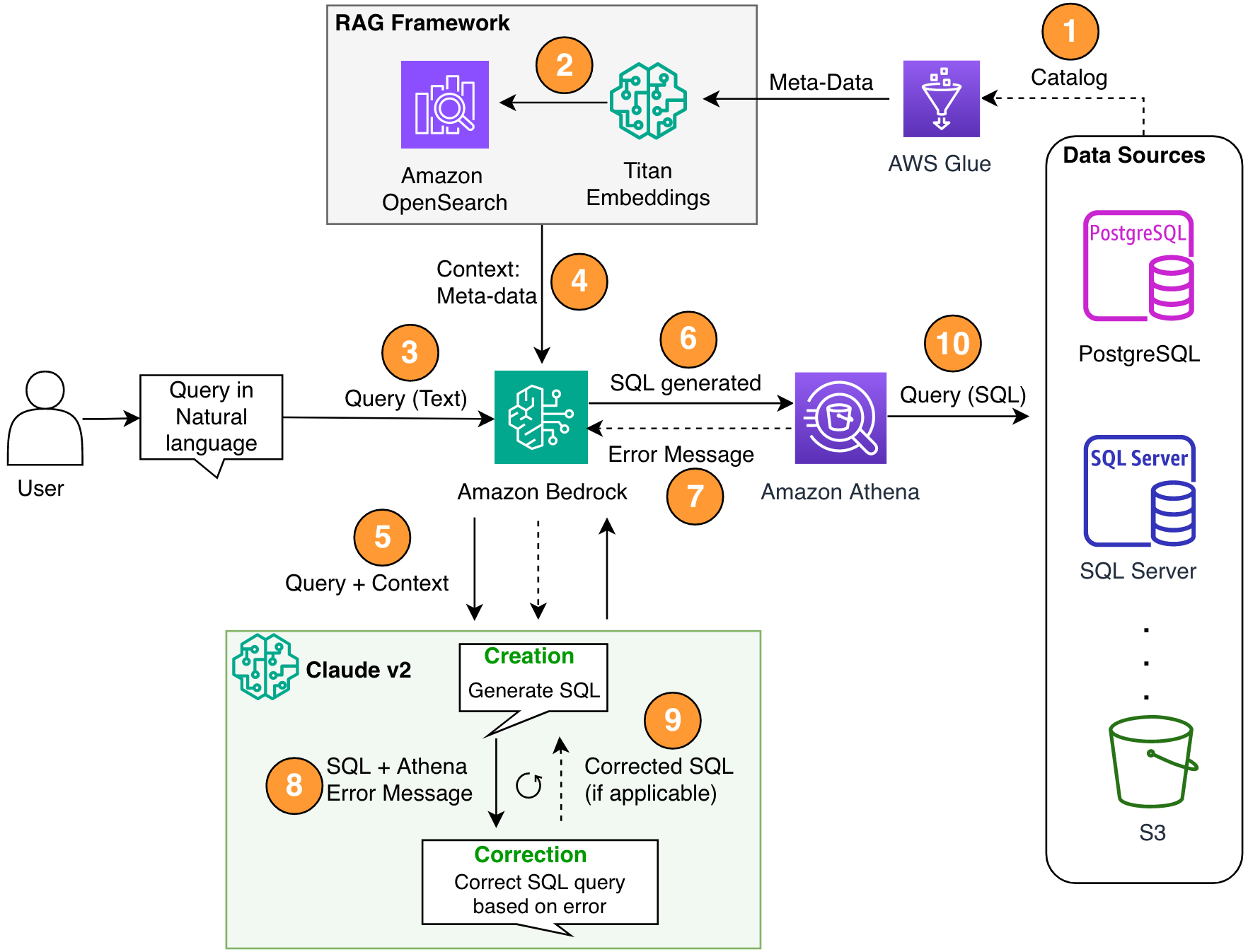
Rysunek 1. Architektura rozwiązania i przebieg procesów.
Przebieg procesu obejmuje następujące kroki:
- Utwórz katalog danych kleju AWS za pomocą robota AWS Glue (lub inną metodą).
- Korzystanie z Model Titan-Text-Embeddings na Amazon Bedrock, przekonwertuj metadane na elementy osadzone i zapisz je w pliku Amazon OpenSearch bez serwera sklep wektorowy, który służy jako nasza baza wiedzy w ramach naszego RAG.
Na tym etapie proces jest gotowy na przyjęcie zapytania w języku naturalnym. Kroki 7–9 przedstawiają pętlę korekcyjną, jeśli ma to zastosowanie.
- Użytkownik wprowadza zapytanie w języku naturalnym. Interfejs czatu można udostępnić za pomocą dowolnej aplikacji internetowej. Dlatego w naszym poście nie omówiliśmy szczegółów interfejsu użytkownika.
- Rozwiązanie wykorzystuje framework RAG poprzez wyszukiwanie podobieństw, który dodaje dodatkowy kontekst z metadanych z bazy danych wektorów. Ta tabela służy do znajdowania właściwej tabeli, bazy danych i atrybutów.
- Zapytanie jest łączone z kontekstem i wysyłane do Antropiczny Claude v2.1 na Amazon Bedrock.
- Model pobiera wygenerowane zapytanie SQL i łączy się z usługą Athena w celu sprawdzenia poprawności składni.
- Jeśli usługa Athena wyświetli komunikat o błędzie informujący, że składnia jest nieprawidłowa, w modelu zostanie użyty tekst błędu z odpowiedzi Ateny.
- Nowy monit dodaje odpowiedź Ateny.
- Model tworzy poprawiony kod SQL i kontynuuje proces. Iterację tę można wykonać wielokrotnie.
- Na koniec uruchamiamy SQL za pomocą Atheny i generujemy dane wyjściowe. Tutaj dane wyjściowe są prezentowane użytkownikowi. Ze względu na prostotę architektoniczną nie pokazaliśmy tego kroku.
Wymagania wstępne
W przypadku tego stanowiska należy spełnić następujące wymagania wstępne:
- mieć Konto AWS.
- Zainstalować dotychczasowy Interfejs wiersza poleceń AWS (interfejs wiersza poleceń AWS).
- Skonfiguruj SDK dla Pythona (Boto3).
- Utwórz katalog danych kleju AWS za pomocą robota AWS Glue (lub inną metodą).
- Korzystanie z Model Titan-Text-Embeddings na Amazon Bedrock, przekonwertuj metadane na elementy osadzone i przechowuj je w systemie OpenSearch Serverless sklep wektorowy.
Zaimplementuj rozwiązanie
Możesz użyć następujących Notatnik Jupyter, który zawiera wszystkie fragmenty kodu podane w tej sekcji, umożliwiające skompilowanie rozwiązania. Zalecamy użycie Studio Amazon SageMaker aby otworzyć ten notatnik za pomocą instancji ml.t3.medium z jądrem Python 3 (Data Science). Aby uzyskać instrukcje, zobacz Trenuj model uczenia maszynowego. Wykonaj następujące kroki, aby skonfigurować rozwiązanie:
- Utwórz bazę wiedzy w usłudze OpenSearch Service dla frameworka RAG:
- Zbuduj zachętę (
final_question) poprzez połączenie danych wprowadzanych przez użytkownika w języku naturalnym (user_query), odpowiednie metadane z magazynu wektorów (vector_search_match) i nasze instrukcje (details): - Wywołaj Amazon Bedrock dla LLM (Claude v2) i poproś go o wygenerowanie zapytania SQL. W poniższym kodzie podejmuje wiele prób w celu zilustrowania kroku samokorekty:x
- Jeśli pojawią się jakiekolwiek problemy z wygenerowanym zapytaniem SQL (
{sqlgenerated}) z odpowiedzi Ateny ({syntaxcheckmsg}), nowy monit (prompt) jest generowany na podstawie odpowiedzi, a model ponownie próbuje wygenerować nowy kod SQL: - Po wygenerowaniu kodu SQL wywoływany jest klient Athena w celu uruchomienia i wygenerowania danych wyjściowych:
Przetestuj rozwiązanie
W tej sekcji uruchamiamy nasze rozwiązanie z różnymi przykładowymi scenariuszami, aby przetestować różne poziomy złożoności zapytań SQL.
Aby przetestować naszą zamianę tekstu na SQL, używamy dwóch zbiory danych dostępne w IMDB. Podzbiory danych IMDb są dostępne do użytku osobistego i niekomercyjnego. Możesz pobrać zbiory danych i przechowywać je Usługa Amazon Simple Storage (Amazon S3). Możesz użyć następującego fragmentu kodu Spark SQL, aby utworzyć tabele w AWS Glue. W tym przykładzie używamy title_ratings i title:
Przechowuj dane w Amazon S3 i metadane w AWS Glue
W tym scenariuszu nasz zbiór danych jest przechowywany w zasobniku S3. Athena posiada złącze S3, które umożliwia wykorzystanie Amazon S3 jako źródła danych, z którego można odpytywać.
W przypadku naszego pierwszego zapytania podajemy dane wejściowe „Jestem w tym nowy. Czy możesz mi pomóc zobaczyć wszystkie tabele i kolumny w schemacie imdb?”
Poniżej znajduje się wygenerowane zapytanie:
Poniższy zrzut ekranu i kod przedstawiają nasze dane wyjściowe.

W przypadku drugiego zapytania prosimy „Pokaż mi cały tytuł i szczegóły w regionie USA, którego ocena jest większa niż 9.5”.
Oto nasze wygenerowane zapytanie:
Odpowiedź jest następująca.

W trzecim zapytaniu wpisujemy „Świetna odpowiedź! Teraz pokaż mi wszystkie tytuły typu oryginalnego, które mają ocenę wyższą niż 7.5 i nie pochodzą z regionu USA.
Generowane jest następujące zapytanie:
Otrzymujemy następujące wyniki.

Wygeneruj samodzielnie poprawiony kod SQL
Ten scenariusz symuluje zapytanie SQL, które ma problemy ze składnią. W tym przypadku wygenerowany kod SQL zostanie automatycznie poprawiony na podstawie odpowiedzi z usługi Athena. W poniższej odpowiedzi Atena dała COLUMN_NOT_FOUND błąd i wspomniałem o tym table_description nie można rozwiązać:
Korzystanie z rozwiązania z innymi źródłami danych
Aby móc korzystać z rozwiązania z innymi źródłami danych, Athena wykona to zadanie za Ciebie. Aby to zrobić, Atena używa złącza źródła danych z którymi można korzystać zapytania sfederowane. Konektor można uznać za rozszerzenie silnika zapytań Athena. Istnieją gotowe łączniki źródeł danych Athena dla źródeł danych takich jak Dzienniki Amazon CloudWatch, Amazon DynamoDB, Amazon DocumentDB (z kompatybilnością MongoDB), Usługa relacyjnych baz danych Amazon (Amazon RDS) oraz relacyjne źródła danych zgodne z JDBC, takie jak MySQL i PostgreSQL na licencji Apache 2.0. Po skonfigurowaniu połączenia z dowolnym źródłem danych możesz użyć powyższej bazy kodu, aby rozszerzyć rozwiązanie. Aby uzyskać więcej informacji, zobacz Wysyłaj zapytania do dowolnego źródła danych za pomocą nowego, stowarzyszonego zapytania Amazon Athena.
Sprzątać
Aby oczyścić zasoby, możesz zacząć od sprzątanie wiadra S3 gdzie znajdują się dane. Jeśli Twoja aplikacja nie odwołuje się do Amazon Bedrock, nie poniesie żadnych kosztów. Ze względu na najlepsze praktyki w zakresie zarządzania infrastrukturą zalecamy usunięcie zasobów utworzonych w ramach tej demonstracji.
Wnioski
W tym poście przedstawiliśmy rozwiązanie, które pozwala wykorzystać NLP do generowania złożonych zapytań SQL przy użyciu różnorodnych zasobów udostępnianych przez Athenę. Zwiększyliśmy także dokładność generowanych zapytań SQL poprzez wieloetapową pętlę oceny opartą na komunikatach o błędach z dalszych procesów. Dodatkowo wykorzystaliśmy metadane z katalogu danych kleju AWS, aby uwzględnić nazwy tabel zadawane w zapytaniu za pośrednictwem platformy RAG. Następnie przetestowaliśmy rozwiązanie w różnych realistycznych scenariuszach o różnych poziomach złożoności zapytań. Na koniec omówiliśmy, jak zastosować to rozwiązanie do różnych źródeł danych obsługiwanych przez Athenę.
Amazon Bedrock znajduje się w centrum tego rozwiązania. Amazon Bedrock może pomóc w tworzeniu wielu generatywnych aplikacji AI. Aby rozpocząć korzystanie z Amazon Bedrock, zalecamy wykonanie poniższej krótkiej instrukcji GitHub repo i zapoznanie się z tworzeniem generatywnych aplikacji AI. Możesz też spróbować bazy wiedzy w Amazon Bedrock, aby szybko budować takie rozwiązania RAG.
O autorach
 Panda Sanjeeba jest inżynierem danych i uczenia maszynowego w Amazon. Mając doświadczenie w AI/ML, Data Science i Big Data, Sanjeeb projektuje i rozwija innowacyjne rozwiązania w zakresie danych i ML, które rozwiązują złożone wyzwania techniczne i osiągają strategiczne cele dla globalnych sprzedawców 3P zarządzających swoimi biznesami na Amazon. Poza pracą jako inżynier danych i uczenia maszynowego w Amazon Sanjeeb Panda jest zapalonym entuzjastą jedzenia i muzyki.
Panda Sanjeeba jest inżynierem danych i uczenia maszynowego w Amazon. Mając doświadczenie w AI/ML, Data Science i Big Data, Sanjeeb projektuje i rozwija innowacyjne rozwiązania w zakresie danych i ML, które rozwiązują złożone wyzwania techniczne i osiągają strategiczne cele dla globalnych sprzedawców 3P zarządzających swoimi biznesami na Amazon. Poza pracą jako inżynier danych i uczenia maszynowego w Amazon Sanjeeb Panda jest zapalonym entuzjastą jedzenia i muzyki.
 Burak Gozluklu jest głównym architektem rozwiązań specjalistycznych AI/ML z siedzibą w Bostonie, MA. Pomaga klientom strategicznym w wdrażaniu technologii AWS, a w szczególności rozwiązań generatywnej AI, aby osiągnąć ich cele biznesowe. Burak posiada tytuł doktora inżynierii lotniczej i kosmicznej uzyskany na METU, tytuł magistra inżynierii systemów oraz post-doc z dynamiki systemów na MIT w Cambridge w stanie Massachusetts. Burak nadal jest pracownikiem naukowym w MIT. Burak jest pasjonatem jogi i medytacji.
Burak Gozluklu jest głównym architektem rozwiązań specjalistycznych AI/ML z siedzibą w Bostonie, MA. Pomaga klientom strategicznym w wdrażaniu technologii AWS, a w szczególności rozwiązań generatywnej AI, aby osiągnąć ich cele biznesowe. Burak posiada tytuł doktora inżynierii lotniczej i kosmicznej uzyskany na METU, tytuł magistra inżynierii systemów oraz post-doc z dynamiki systemów na MIT w Cambridge w stanie Massachusetts. Burak nadal jest pracownikiem naukowym w MIT. Burak jest pasjonatem jogi i medytacji.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- PlatoData.Network Pionowe generatywne AI. Wzmocnij się. Dostęp tutaj.
- PlatoAiStream. Inteligencja Web3. Wiedza wzmocniona. Dostęp tutaj.
- PlatonESG. Węgiel Czysta technologia, Energia, Środowisko, Słoneczny, Gospodarowanie odpadami. Dostęp tutaj.
- Platon Zdrowie. Inteligencja w zakresie biotechnologii i badań klinicznych. Dostęp tutaj.
- Źródło: https://aws.amazon.com/blogs/machine-learning/build-a-robust-text-to-sql-solution-generating-complex-queries-self-correcting-and-querying-diverse-data-sources/

