W dzisiejszym krajobrazie biznesowym organizacje nieustannie poszukują sposobów optymalizacji swoich procesów finansowych, zwiększania wydajności i zwiększania oszczędności. Jednym z obszarów, który ma znaczny potencjał poprawy, są zobowiązania. Na wysokim poziomie proces zobowiązań obejmuje otrzymywanie i skanowanie faktur, wyodrębnianie odpowiednich danych ze zeskanowanych faktur, walidację, zatwierdzanie i archiwizację. Drugi etap (ekstrakcja) może być złożony. Każda faktura i paragon wyglądają inaczej. Etykiety są niedoskonałe i niespójne. Najważniejsze informacje, takie jak cena, nazwa dostawcy, adres dostawcy i warunki płatności często nie są wyraźnie oznaczone i należy je interpretować w oparciu o kontekst. Tradycyjne podejście polegające na wykorzystywaniu weryfikatorów do wyodrębniania danych jest czasochłonne, podatne na błędy i nieskalowalne.
W tym poście pokazujemy, jak zautomatyzować proces rozliczeń z dostawcami za pomocą Ekstrakt z amazonki do ekstrakcji danych. Zapewniamy również architekturę referencyjną do budowy potoku automatyzacji faktur, który umożliwia ekstrakcję, weryfikację, archiwizację i inteligentne wyszukiwanie.
Omówienie rozwiązania
Poniższy diagram architektury przedstawia etapy przepływu pracy przetwarzania paragonów i faktur. Rozpoczyna się od etapu przechwycenia dokumentu, którego celem jest bezpieczne gromadzenie i przechowywanie zeskanowanych faktur i paragonów. Kolejnym etapem jest faza ekstrakcji, podczas której przekazujesz zebrane faktury i rachunki do Amazon Texttract AnalyzeExpense Interfejs API umożliwiający wyodrębnienie relacji finansowych między tekstami, takimi jak nazwa dostawcy, data otrzymania faktury, data zamówienia, należna kwota, zapłacona kwota itd. W kolejnym etapie na podstawie predefiniowanych reguł wydatkowych określasz, czy automatycznie zatwierdzić paragon, czy też go odrzucić. Zatwierdzone i odrzucone dokumenty trafiają do odpowiednich folderów w folderze Usługa Amazon Simple Storage Łyżka (Amazon S3). W przypadku zatwierdzonych dokumentów możesz przeszukiwać wszystkie wyodrębnione pola i wartości za pomocą Usługa Amazon OpenSearch. Możesz wizualizować zindeksowane metadane za pomocą pulpitów nawigacyjnych OpenSearch. Zatwierdzone dokumenty są również skonfigurowane do przeniesienia Inteligentne warstwowanie Amazon S3 do długoterminowego przechowywania i archiwizacji przy użyciu zasad cyklu życia S3.
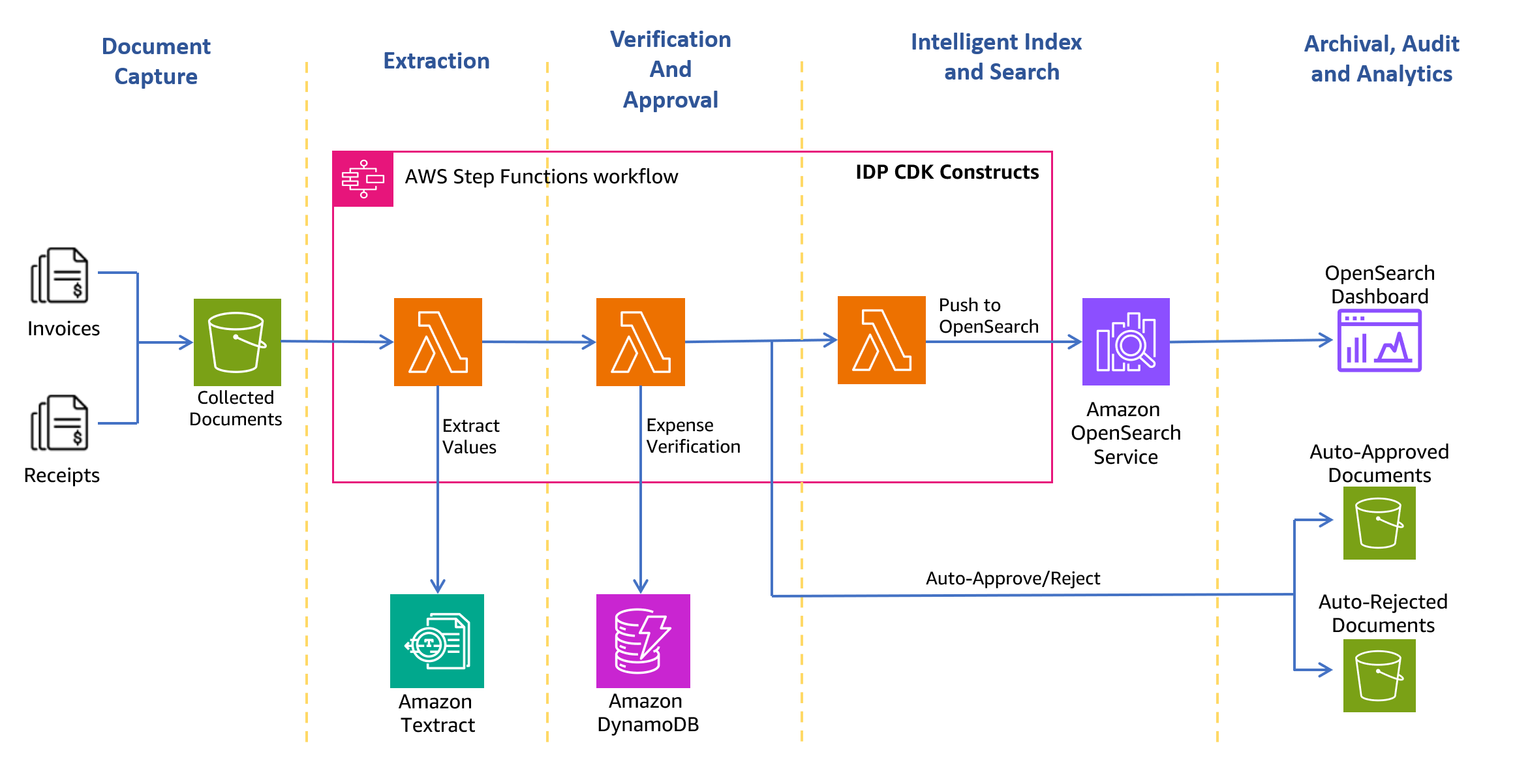
Poniższe sekcje przeprowadzą Cię przez proces tworzenia rozwiązania.
Wymagania wstępne
Aby wdrożyć to rozwiązanie, musisz mieć następujące elementy:
- Konto AWS.
- An Chmura AWS9 środowisko. AWS Cloud9 to zintegrowane środowisko programistyczne (IDE) oparte na chmurze, które umożliwia pisanie, uruchamianie i debugowanie kodu za pomocą samej przeglądarki. Zawiera edytor kodu, debuger i terminal.
Aby utworzyć środowisko AWS Cloud9, podaj nazwę i opis. Zachowaj wszystko inne jako domyślne. Wybierz łącze IDE na konsoli AWS Cloud9, aby przejść do IDE. Możesz teraz korzystać ze środowiska AWS Cloud9.
Wdróż rozwiązanie
Aby skonfigurować rozwiązanie, użyj Zestaw programistyczny AWS Cloud (AWS CDK), aby wdrożyć plik Tworzenie chmury AWS stos.
- W terminalu IDE AWS Cloud9 sklonuj plik Repozytorium GitHub i zainstaluj zależności. Uruchom następujące polecenia, aby wdrożyć
InvoiceProcessorstos:
Wdrożenie zajmuje około 25 minut przy domyślnych ustawieniach konfiguracyjnych z repozytorium GitHub. Dodatkowe informacje wyjściowe są również dostępne w konsoli AWS CloudFormation.
- Po zakończeniu wdrażania AWS CDK utwórz reguły sprawdzania poprawności wydatków w pliku Amazon DynamoDB tabela. Możesz użyć tego samego terminala AWS Cloud9, aby uruchomić następujące polecenia:
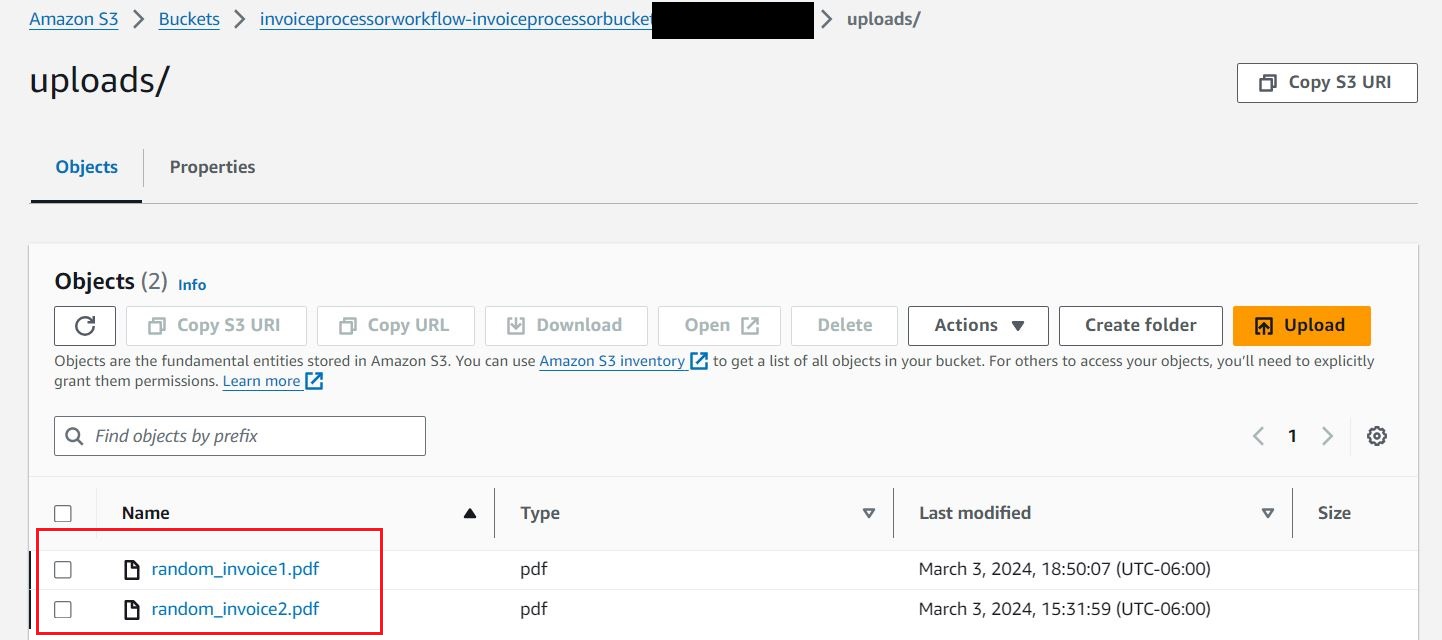
- W wiadrze S3, który zaczyna się od
invoiceprocessorworkflow-invoiceprocessorbucketf1-*, utwórz folder przesyłania.
In Amazon Cognito, powinieneś już mieć istniejącą pulę użytkowników o nazwie OpenSearchResourcesCognitoUserPool*. Używamy tej puli użytkowników do tworzenia nowego użytkownika.
- W konsoli Amazon Cognito przejdź do puli użytkowników
OpenSearchResourcesCognitoUserPool*. - Utwórz nowego użytkownika Amazon Cognito.
- Podaj wybraną nazwę użytkownika i hasło i zapisz je do późniejszego wykorzystania.
- Prześlij dokumenty losowa_faktura1 i losowa_faktura2 do S3
uploadsfolder, aby rozpocząć przepływy pracy.
Przyjrzyjmy się teraz każdemu etapowi przetwarzania dokumentu.
Przechwytywanie dokumentów
Klienci obsługują faktury i paragony w wielu formatach od różnych dostawców. Dokumenty te są odbierane za pośrednictwem takich kanałów, jak kopie papierowe, zeskanowane kopie przesłane do magazynu plików lub udostępnione urządzenia pamięci masowej. Na etapie przechwytywania dokumentów przechowujesz wszystkie zeskanowane kopie paragonów i faktur w wysoce skalowalnym magazynie, takim jak wiadro S3.
Ekstrakcja
Kolejnym etapem jest faza ekstrakcji, podczas której przekazujesz zebrane faktury i rachunki do Amazon Texttract AnalyzeExpense API umożliwiające wyodrębnienie relacji finansowych pomiędzy tekstami, takimi jak nazwa dostawcy, data otrzymania faktury, data zamówienia, kwota należna/zapłacona itp.
AnalizujWydatki to API dedykowane do przetwarzania dokumentów faktur i paragonów. Jest dostępny zarówno jako synchroniczny, jak i asynchroniczny interfejs API. Synchroniczny interfejs API umożliwia wysyłanie obrazów w formacie bajtowym, a asynchroniczny interfejs API umożliwia wysyłanie plików w formatach JPG, PNG, TIFF i PDF. The AnalyzeExpense Odpowiedź API składa się z trzech odrębnych sekcji:
- Pola podsumowujące – Ta sekcja zawiera zarówno klucze znormalizowane, jak i wyraźnie wymienione klucze wraz z ich wartościami.
AnalyzeExpensenormalizuje klucze dotyczące informacji kontaktowych, takich jak nazwa i adres dostawcy, klucze związane z identyfikatorem podatkowym, takie jak identyfikator podatnika, klucze związane z płatnościami, takie jak kwota należna i rabat, oraz klucze ogólne, takie jak identyfikator faktury, data dostawy i numer konta. Klucze, które nie są znormalizowane, nadal pojawiają się w polach podsumowania jako pary klucz-wartość. Aby zapoznać się z pełną listą obsługiwanych pól wydatków, zobacz Analiza faktur i paragonów. - Elementy zamówienia – Ta sekcja zawiera znormalizowane klucze pozycji pojedynczych, takie jak opis pozycji, cena jednostkowa, ilość i kod produktu.
- Blok OCR – Blok zawiera surowy ekstrakt tekstowy ze strony faktury. Ekstrakt z surowego tekstu można wykorzystać do przetwarzania końcowego i identyfikowania informacji, które nie są uwzględnione w polach podsumowania i pozycji pojedynczej.
Ten post wykorzystuje rozszerzenie Konstrukcje Amazon Text IDP CDK (komponenty AWS CDK do definiowania infrastruktury dla inteligentnych przepływów pracy przetwarzania dokumentów (IDP)), które umożliwiają tworzenie dostosowanych do indywidualnych potrzeb przepływów pracy IDP. Konstrukcje i próbki stanowią zbiór komponentów umożliwiających zdefiniowanie procesów IDP w AWS i publikację GitHub. Głównymi używanymi koncepcjami są konstrukcje AWS CDK, rzeczywiste Stosy AWS CDK, Funkcje kroków AWS.
Poniższy rysunek przedstawia przepływ pracy Funkcje kroku.
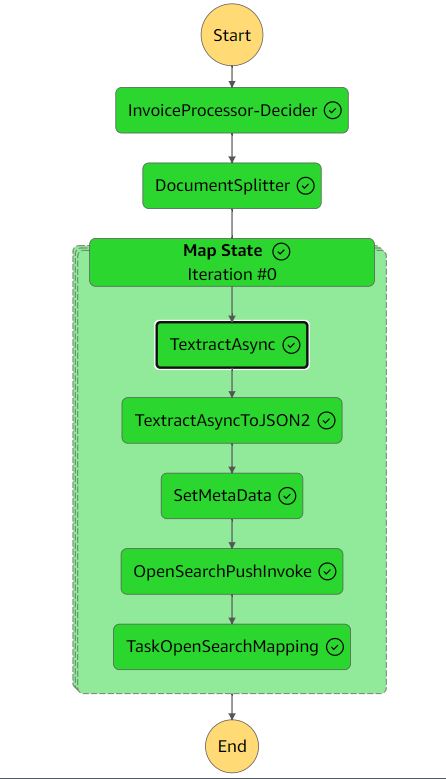
Przepływ pracy wyodrębniania obejmuje następujące kroki:
- Osoba podejmująca decyzję o przetwarzaniu faktur - An AWS Lambda funkcja sprawdzająca, czy format dokumentu wejściowego jest obsługiwany przez Amazon Texttract. Aby uzyskać więcej informacji na temat obsługiwanych formatów, zobacz Dokumenty wejściowe.
- Rozdzielacz dokumentów – Funkcja Lambda, która generuje fragmenty dokumentów o objętości maksymalnie 2,500 stron i może przetwarzać duże, wielostronicowe dokumenty.
- Stan mapy – Funkcja Lambda, która przetwarza każdą porcję równolegle.
- WyciągAsync – To zadanie wywołuje Amazon Texttract przy użyciu asynchronicznego interfejsu API Najlepsze praktyki w Usługa prostego powiadomienia Amazon Powiadomienia i zastosowania (Amazon SNS).
OutputConfigdo przechowywania danych wyjściowych Amazon Textract JSON w utworzonym wcześniej zasobniku S3. Składa się z dwóch funkcji Lambda: jednej umożliwiającej przesłanie dokumentu do przetworzenia oraz drugiej uruchamianej w momencie powiadomienia SNS. - TexttractAsyncToJSON2 - Ponieważ
TextractAsynczadanie może wygenerować wiele plików wyjściowych podzielonych na strony, npTextractAsyncToJSON2proces łączy je w jeden plik JSON.
Szczegóły kolejnych trzech kroków omówimy w kolejnych sekcjach.
Weryfikacja i zatwierdzenie
Na etapie weryfikacji, SetMetaData Funkcja Lambda sprawdza, czy przesłany plik jest prawidłowym wydatkiem zgodnie z regułami skonfigurowanymi wcześniej w tabeli DynamoDB. W tym poście używasz następujących przykładowych reguł:
- Weryfikacja przebiegła pomyślnie, jeśli
INVOICE_RECEIPT_IDjest obecny i pasuje do wyrażenia regularnego(?i)[0-9]{3}[a-z]{3}[0-9]{3}$i ifPO_NUMBERjest obecny i pasuje do wyrażenia regularnego(?i)[a-z0-9]+$ - Weryfikacja zakończy się niepowodzeniem, jeśli którykolwiek z nich
PO_NUMBERorINVOICE_RECEIPT_IDjest nieprawidłowy lub brakuje go w dokumencie.
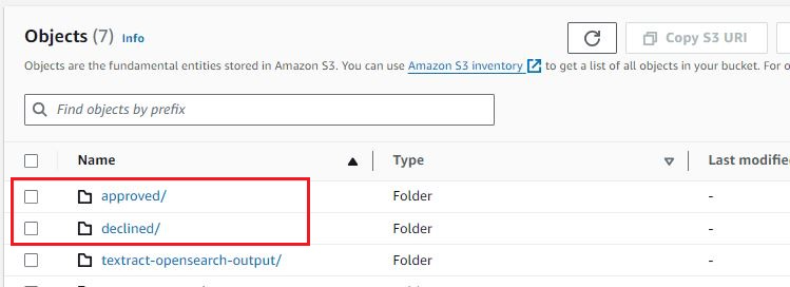
Po przetworzeniu plików funkcja weryfikacji wydatków przenosi pliki wejściowe do któregokolwiek z nich approved or declined foldery w tym samym wiadrze S3.
Na potrzeby tego rozwiązania wykorzystujemy DynamoDB do przechowywania reguł walidacji wydatków. Można jednak zmodyfikować to rozwiązanie, aby zintegrować je z własnymi lub komercyjnymi rozwiązaniami do sprawdzania poprawności wydatków lub zarządzania nimi.
Inteligentne indeksowanie i wyszukiwanie
Z OpenSearchPushInvoke Funkcja Lambda wyodrębnione metadane wydatków są wypychane do indeksu usługi OpenSearch i są dostępne do wyszukiwania.
Finał TaskOpenSearchMapping krok usuwa kontekst, który w przeciwnym razie mógłby przekroczyć Krok Funkcje limitu maksymalnego rozmiaru wejściowego lub wyjściowego dla zadania, stanu lub przebiegu przepływu pracy.
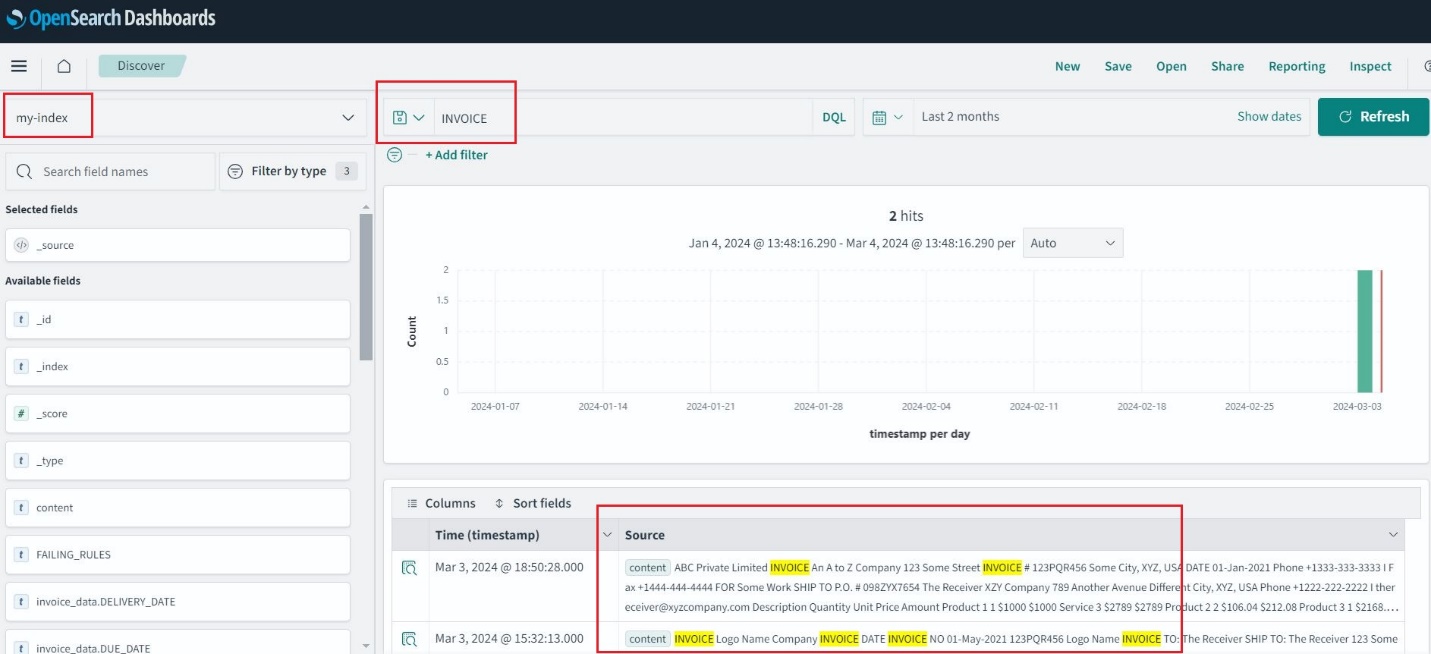
Po utworzeniu indeksu usługi OpenSearch można wyszukiwać słowa kluczowe z wyodrębnionego tekstu za pośrednictwem pulpitów nawigacyjnych OpenSearch.
Archiwizacja, audyt i analityka
Aby zarządzać cyklem życia i archiwizacją faktur i paragonów, możesz skonfigurować reguły cyklu życia S3 w celu przenoszenia obiektów S3 z klas pamięci Standard do klas Intelligent-Tiering. S3 Intelligent-Tiering monitoruje wzorce dostępu i automatycznie przenosi obiekty do warstwy dostępu rzadkiego, jeśli nie były one dostępne przez 30 kolejnych dni. Po 90 dniach braku dostępu obiekty są przenoszone do warstwy Natychmiastowy dostęp do archiwum bez wpływu na wydajność i koszty operacyjne.
Do celów audytu i analiz rozwiązanie to wykorzystuje usługę OpenSearch do przeprowadzania analiz żądań faktur. Usługa OpenSearch umożliwia bezproblemowe pozyskiwanie, zabezpieczanie, przeszukiwanie, agregowanie, przeglądanie i analizowanie danych do wielu zastosowań, takich jak analiza logów, wyszukiwanie aplikacji, wyszukiwanie korporacyjne i nie tylko.
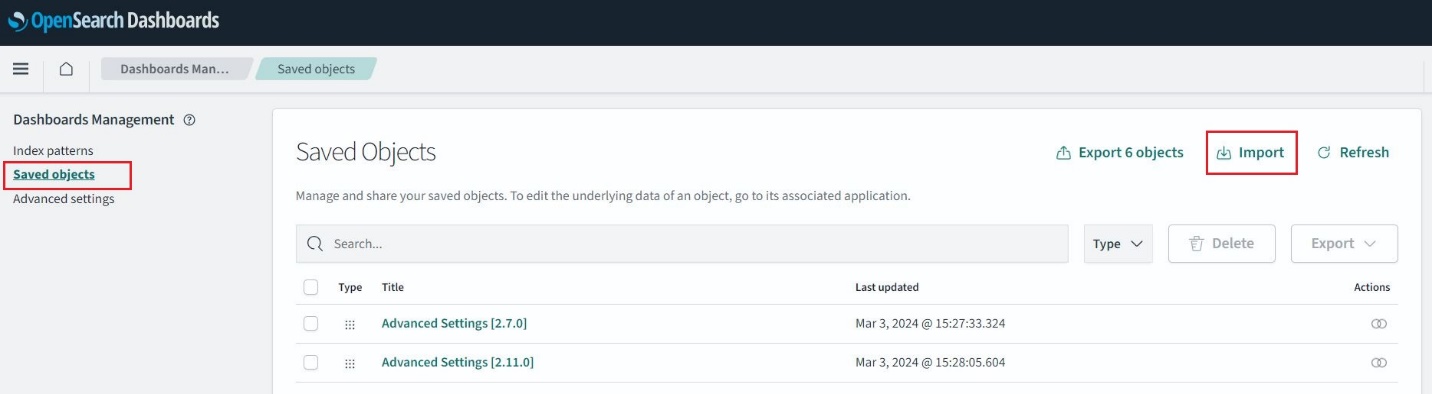
Zaloguj się do pulpitów OpenSearch i przejdź do Zarządzanie stosem, Zapisane obiekty, A następnie wybierz import. Wybierz faktury.ndjson plik ze sklonowanego repozytorium i wybierz import. Spowoduje to wstępne wypełnienie indeksów i utworzenie wizualizacji.
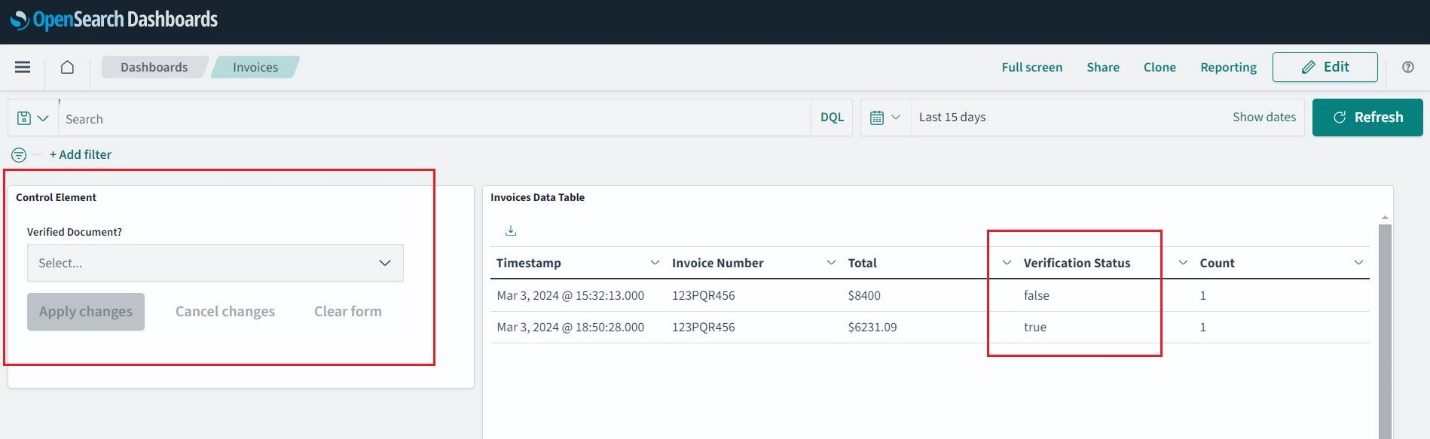
Odśwież stronę i przejdź do Strona główna, Panel Użytkownikai otwarte Faktury. Możesz teraz wybierać i stosować filtry oraz rozszerzać okno czasowe, aby przeglądać przeszłe faktury.
Sprzątać
Kiedy skończysz oceniać Amazon Texttract pod kątem przetwarzania paragonów i faktur, zalecamy wyczyszczenie wszelkich zasobów, które mogłeś utworzyć. Wykonaj następujące kroki:
- Usuń całą zawartość z segmentu S3
invoiceprocessorworkflow-invoiceprocessorbucketf1-*. - W AWS Cloud9 uruchom następujące polecenia, aby usunąć zasoby Amazon Cognito i stosy CloudFormation:
- Usuń środowisko AWS Cloud9 utworzone z konsoli AWS Cloud9.
Wnioski
W tym poście omówiliśmy, w jaki sposób możemy zbudować potok automatyzacji faktur za pomocą Amazon Texttract do ekstrakcji danych i stworzyć przepływ pracy do sprawdzania poprawności, archiwizacji i wyszukiwania. Udostępniliśmy próbki kodu dotyczące korzystania z AnalyzeExpense API do ekstrakcji krytycznych pól z faktury.
Aby rozpocząć, zaloguj się do konsoli Amazon Textract i wypróbuj tę funkcję. Aby dowiedzieć się więcej o możliwościach Amazon Texttract, zapoznaj się z sekcją Przewodnik dla programistów Amazon Textract or Zasoby tekstowe. Aby dowiedzieć się więcej o IDP, zapoznaj się z sekcją IDP z usługami AWS AI Część 1 i Część 2 posty.
O autorach
 Sushanta Pradhana jest starszym architektem rozwiązań w Amazon Web Services i pomaga klientom korporacyjnym. Jego zainteresowania i doświadczenie obejmują kontenery, technologię bezserwerową i DevOps. W wolnym czasie Sushant lubi spędzać czas na świeżym powietrzu z rodziną.
Sushanta Pradhana jest starszym architektem rozwiązań w Amazon Web Services i pomaga klientom korporacyjnym. Jego zainteresowania i doświadczenie obejmują kontenery, technologię bezserwerową i DevOps. W wolnym czasie Sushant lubi spędzać czas na świeżym powietrzu z rodziną.
 Shibin Michaelraj jest Starszym Product Managerem w zespole AWS Texttract. Koncentruje się na budowaniu produktów opartych na AI/ML dla klientów AWS.
Shibin Michaelraj jest Starszym Product Managerem w zespole AWS Texttract. Koncentruje się na budowaniu produktów opartych na AI/ML dla klientów AWS.
 Suprakasz Dutta jest starszym architektem rozwiązań w Amazon Web Services. Koncentruje się na strategii transformacji cyfrowej, modernizacji i migracji aplikacji, analityce danych i uczeniu maszynowym. Jest członkiem społeczności AI/ML w AWS i projektuje inteligentne rozwiązania do przetwarzania dokumentów.
Suprakasz Dutta jest starszym architektem rozwiązań w Amazon Web Services. Koncentruje się na strategii transformacji cyfrowej, modernizacji i migracji aplikacji, analityce danych i uczeniu maszynowym. Jest członkiem społeczności AI/ML w AWS i projektuje inteligentne rozwiązania do przetwarzania dokumentów.
 Marana Chandrasekarana jest starszym architektem rozwiązań w Amazon Web Services, pracując z naszymi klientami korporacyjnymi. Poza pracą uwielbia podróżować i jeździć na motocyklu po Texas Hill Country.
Marana Chandrasekarana jest starszym architektem rozwiązań w Amazon Web Services, pracując z naszymi klientami korporacyjnymi. Poza pracą uwielbia podróżować i jeździć na motocyklu po Texas Hill Country.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- PlatoData.Network Pionowe generatywne AI. Wzmocnij się. Dostęp tutaj.
- PlatoAiStream. Inteligencja Web3. Wiedza wzmocniona. Dostęp tutaj.
- PlatonESG. Węgiel Czysta technologia, Energia, Środowisko, Słoneczny, Gospodarowanie odpadami. Dostęp tutaj.
- Platon Zdrowie. Inteligencja w zakresie biotechnologii i badań klinicznych. Dostęp tutaj.
- Źródło: https://aws.amazon.com/blogs/machine-learning/build-a-receipt-and-invoice-processing-pipeline-with-amazon-textract/

