Tworzenie skalowalnych i wydajnych potoków uczenia maszynowego (ML) ma kluczowe znaczenie dla usprawnienia opracowywania, wdrażania i zarządzania modelami uczenia maszynowego. W tym poście prezentujemy framework do automatyzacji tworzenia skierowanego grafu acyklicznego (DAG) dla Rurociągi Amazon SageMaker w oparciu o proste pliki konfiguracyjne. The kod frameworka i przykłady przedstawione tutaj obejmują jedynie potoki uczenia modeli, ale można je łatwo rozszerzyć również na potoki wnioskowania wsadowego.
Ta dynamiczna platforma wykorzystuje pliki konfiguracyjne do koordynowania etapów przetwarzania wstępnego, szkolenia, oceny i rejestracji zarówno dla przypadków użycia jednego, jak i wielu modeli, w oparciu o zdefiniowane przez użytkownika skrypty Pythona, potrzeby infrastrukturalne (w tym Wirtualna prywatna chmura Amazon podsieci i grupy zabezpieczeń (Amazon VPC), AWS Zarządzanie tożsamością i dostępem (IAM) role, Usługa zarządzania kluczami AWS (AWS KMS), rejestr kontenerów i typy instancji), dane wejściowe i wyjściowe Usługa Amazon Simple Storage (Amazon S3) ścieżki i znaczniki zasobów. Pliki konfiguracyjne (YAML i JSON) umożliwiają specjalistom ML określenie niezróżnicowanego kodu do organizowania potoków szkoleniowych przy użyciu składni deklaratywnej. Umożliwia to analitykom danych szybkie budowanie i iterację modeli ML, a inżynierom ML szybsze wykonywanie potoków ML ciągłej integracji i ciągłego dostarczania (CI/CD), skracając czas potrzebny do wyprodukowania modeli.
Omówienie rozwiązania
Proponowany kod frameworka rozpoczyna się od odczytania plików konfiguracyjnych. Następnie dynamicznie tworzy DAG SageMaker Pipelines w oparciu o kroki zadeklarowane w plikach konfiguracyjnych oraz interakcje i zależności między krokami. Ta struktura orkiestracji obsługuje zarówno przypadki użycia jednego modelu, jak i wielu modeli oraz zapewnia płynny przepływ danych i procesów. Oto najważniejsze zalety tego rozwiązania:
- Automatyzacja – Cały proces uczenia maszynowego, od wstępnego przetwarzania danych po rejestrację modelu, jest zorganizowany bez ręcznej interwencji. Skraca to czas i wysiłek wymagany do eksperymentowania z modelami i operacjonalizacji.
- Odtwarzalność – Dzięki predefiniowanemu plikowi konfiguracyjnemu badacze danych i inżynierowie ML mogą odtworzyć cały przepływ pracy, uzyskując spójne wyniki w wielu przebiegach i środowiskach.
- Skalowalność - Amazon Sage Maker jest używany w całym procesie, umożliwiając specjalistom ML przetwarzanie dużych zbiorów danych i uczenie złożonych modeli bez problemów związanych z infrastrukturą.
- Elastyczność – Struktura jest elastyczna i może pomieścić szeroką gamę przypadków użycia ML, frameworków ML (takich jak XGBoost i TensorFlow), szkolenia wielomodelowego i szkolenia wieloetapowego. Każdy krok szkolenia DAG można dostosować za pomocą pliku konfiguracyjnego.
- Zarządzanie modelowe - Rejestr modelu Amazon SageMaker integracja pozwala na śledzenie wersji modeli, a co za tym idzie, pewne wprowadzanie ich do produkcji.
Poniższy diagram architektury przedstawia, jak można używać proponowanej struktury podczas eksperymentowania i operacjonalizacji modeli uczenia maszynowego. Podczas eksperymentów możesz sklonować repozytorium kodu frameworka dostarczone w tym poście i repozytoria kodu źródłowego specyficzne dla projektu do Studio Amazon SageMakeri ustaw środowisko wirtualne (szczegóły w dalszej części tego postu). Następnie możesz iterować po skryptach przetwarzania wstępnego, szkolenia i oceny, a także wyborów konfiguracyjnych. Aby utworzyć i uruchomić szkoleniowy DAG SageMaker Pipelines, można wywołać punkt wejścia platformy, który odczyta wszystkie pliki konfiguracyjne, utworzy niezbędne kroki i zorganizuje je w oparciu o określoną kolejność kroków i zależności.
Podczas operacjonalizacji potok CI klonuje repozytorium kodu platformy i repozytoria szkoleń specyficznych dla projektu do pliku Tworzenie kodu AWS zadanie, w którym wywoływany jest skrypt punktu wejścia platformy w celu utworzenia lub zaktualizowania szkoleniowego DAG SageMaker Pipelines, a następnie jego uruchomienia.

Struktura repozytorium
Połączenia Repozytorium GitHub zawiera następujące katalogi i pliki:
- /framework/conf/ – Ten katalog zawiera plik konfiguracyjny, który służy do ustawiania wspólnych zmiennych we wszystkich jednostkach modelowania, takich jak podsieci, grupy zabezpieczeń i rola IAM w czasie wykonywania. Jednostka modelowania to sekwencja maksymalnie sześciu kroków służących do szkolenia modelu ML.
- /framework/utwórzmodel/ – Ten katalog zawiera skrypt Pythona, który tworzy plik Model SageMakera obiekt oparty na artefaktach modelu z a Etap szkolenia SageMaker Pipelines. Obiekt modelu jest później używany w a Transformacja wsadowa SageMaker zadanie polegające na ocenie wydajności modelu na zestawie testowym.
- /framework/modelmetryka/ – Ten katalog zawiera skrypt Pythona, który tworzy plik Przetwarzanie Amazon SageMaker zadanie służące do generowania raportu JSON dotyczącego metryk modelu dla przeszkolonego modelu na podstawie wyników zadania transformacji wsadowej programu SageMaker wykonanego na danych testowych.
- /framework/potok/ – Ten katalog zawiera skrypty Pythona, które wykorzystują klasy Pythona zdefiniowane w innych katalogach frameworka do tworzenia lub aktualizowania DAG SageMaker Pipelines w oparciu o określone konfiguracje. Skrypt model_unit.py jest używany przez potok_service.py do tworzenia jednej lub większej liczby jednostek modelowania. Każda jednostka modelowania to sekwencja maksymalnie sześciu kroków służących do uczenia modelu uczenia maszynowego: przetwarzanie, uczenie, tworzenie modelu, przekształcanie, metryki i rejestrowanie modelu. Konfiguracje dla każdej jednostki modelującej należy określić w odpowiednim repozytorium modelu. Plik potokowy_service.py ustawia również zależności między krokami SageMaker Pipelines (w jaki sposób kroki w obrębie i między jednostkami modelowania są sekwencjonowane lub łączone) w oparciu o sekcję sagemakerPipeline, która powinna być zdefiniowana w pliku konfiguracyjnym jednego z repozytoriów modeli (model kotwicy). Pozwala to zastąpić domyślne zależności wywnioskowane przez SageMaker Pipelines. Strukturę pliku konfiguracyjnego omówimy w dalszej części tego wpisu.
- /framework/przetwarzanie/ – Ten katalog zawiera skrypt Pythona, który tworzy zadanie SageMaker Processing w oparciu o określony obraz Dockera i skrypt punktu wejścia.
- /framework/registermodel/ – Ten katalog zawiera skrypt Pythona służący do rejestrowania przeszkolonego modelu wraz z obliczonymi metrykami w rejestrze modelu SageMaker.
- /framework/szkolenia/ – Ten katalog zawiera skrypt Pythona, który tworzy zadanie szkoleniowe SageMaker.
- /framework/transformacja/ – Ten katalog zawiera skrypt Pythona, który tworzy zadanie transformacji wsadowej SageMaker. W kontekście uczenia modeli służy to do obliczania metryki wydajności wyszkolonego modelu na danych testowych.
- /framework/narzędzia/ – Ten katalog zawiera skrypty narzędziowe do odczytu i łączenia plików konfiguracyjnych, a także logowania.
- /framework_entrypoint.py – Ten plik jest punktem wejścia kodu frameworka. Wywołuje funkcję zdefiniowaną w katalogu /framework/pipeline/ w celu utworzenia lub aktualizacji DAG SageMaker Pipelines i uruchomienia go.
- /przykłady/ – Ten katalog zawiera kilka przykładów wykorzystania tego frameworka automatyzacji do tworzenia prostych i złożonych szkoleniowych DAG-ów.
- /środ.środ – Ten plik umożliwia ustawienie typowych zmiennych, takich jak podsieci, grupy zabezpieczeń i rola IAM, jako zmiennych środowiskowych.
- /wymagania.txt – Ten plik określa biblioteki Pythona wymagane dla kodu frameworka.
Wymagania wstępne
Przed wdrożeniem tego rozwiązania należy spełnić następujące wymagania wstępne:
- Konto AWS
- Studio SageMaker
- Rola SageMaker z uprawnieniami do odczytu/zapisu Amazon S3 i szyfrowania/odszyfrowywania AWS KMS
- Wiadro S3 do przechowywania danych, skryptów i artefaktów modeli
- Opcjonalnie Interfejs wiersza poleceń AWS (CLI AWS)
- Python3 (Python 3.7 lub nowszy) i następujące pakiety Pythona:
- boto3
- sagemaker
- PyYAML
- Dodatkowe pakiety Pythona używane w niestandardowych skryptach
Wdróż rozwiązanie
Wykonaj następujące kroki, aby wdrożyć rozwiązanie:
- Zorganizuj repozytorium uczenia modeli zgodnie z następującą strukturą:
- Sklonuj kod frameworka i kod źródłowy modelu z repozytoriów Git:
-
- Clone
dynamic-sagemaker-pipelines-frameworkrepo do katalogu szkoleniowego. W poniższym kodzie zakładamy, że katalog szkoleniowy nosi nazwęaws-train: - Sklonuj kod źródłowy modelu w tym samym katalogu. W przypadku uczenia wielu modeli powtórz ten krok dla dowolnej liczby modeli, których potrzebujesz do trenowania.
- Clone
W przypadku uczenia pojedynczego modelu katalog powinien wyglądać następująco:
W przypadku szkolenia wielomodelowego katalog powinien wyglądać następująco:
- Skonfiguruj następujące zmienne środowiskowe. Gwiazdki wskazują wymagane zmienne środowiskowe; reszta jest opcjonalna.
| Zmienna środowiskowa | Opis |
SMP_ACCOUNTID* |
Konto AWS, na którym uruchamiany jest potok SageMaker |
SMP_REGION* |
Region AWS, w którym działa potok SageMaker |
SMP_S3BUCKETNAME* |
Nazwa zasobnika S3 |
SMP_ROLE* |
Rola SageMakera |
SMP_MODEL_CONFIGPATH* |
Ścieżka względna plików konfiguracyjnych jednego lub wielu modeli |
SMP_SUBNETS |
Identyfikatory podsieci dla konfiguracji sieci SageMaker |
SMP_SECURITYGROUPS |
Identyfikatory grup zabezpieczeń dla konfiguracji sieci SageMaker |
W przypadku przypadków użycia pojedynczego modelu, SMP_MODEL_CONFIGPATH będzie <MODEL-DIR>/conf/conf.yaml. W przypadku zastosowań obejmujących wiele modeli SMP_MODEL_CONFIGPATH będzie */conf/conf.yaml, co pozwala znaleźć wszystko conf.yaml pliki przy użyciu modułu glob Pythona i połącz je, tworząc globalny plik konfiguracyjny. Podczas eksperymentów (testowanie lokalne) możesz określić zmienne środowiskowe w pliku env.env, a następnie wyeksportować je, uruchamiając następującą komendę w terminalu:
Należy pamiętać, że wartości zmiennych środowiskowych w env.env należy umieścić w cudzysłowie (np. SMP_REGION="us-east-1"). Podczas operacjonalizacji te zmienne środowiskowe powinny zostać ustawione przez potok CI.
- Utwórz i aktywuj środowisko wirtualne, uruchamiając następujące polecenia:
- Zainstaluj wymagane pakiety Pythona, uruchamiając następujące polecenie:
- Edytuj trening modelu
conf.yamlakta. Strukturę pliku konfiguracyjnego omówimy w następnej sekcji. - Z terminala wywołaj punkt wejścia frameworka, aby utworzyć lub zaktualizować i uruchomić szkoleniowy DAG SageMaker Pipeline:
- Przeglądaj i debuguj potoki SageMaker działające na platformie Rurociągi zakładka interfejsu użytkownika SageMaker Studio.
Struktura pliku konfiguracyjnego
W proponowanym rozwiązaniu występują dwa typy plików konfiguracyjnych: konfiguracja frameworka i konfiguracja modelu. W tej sekcji szczegółowo opisujemy każdy z nich.
Konfiguracja frameworka
Połączenia /framework/conf/conf.yaml plik ustawia zmienne, które są wspólne dla wszystkich jednostek modelowania. To zawiera SMP_S3BUCKETNAME, SMP_ROLE, SMP_MODEL_CONFIGPATH, SMP_SUBNETS, SMP_SECURITYGROUPS, SMP_MODELNAME. Opisy tych zmiennych i sposobu ich ustawiania za pomocą zmiennych środowiskowych można znaleźć w kroku 3 instrukcji wdrażania.
Konfiguracja modelu
Dla każdego modelu w projekcie musimy określić w pliku <MODEL-DIR>/conf/conf.yaml plik (gwiazdki wskazują wymagane sekcje; reszta jest opcjonalna):
- /conf/modele* – W tej sekcji możesz skonfigurować jedną lub więcej jednostek modelujących. Kiedy kod frameworka zostanie uruchomiony, automatycznie odczyta wszystkie pliki konfiguracyjne w czasie wykonywania i dołączy je do drzewa konfiguracyjnego. Teoretycznie można określić wszystkie jednostki modelowania w ten sam sposób
conf.yamlplik, ale zaleca się określenie konfiguracji każdej jednostki modelującej w jej odpowiednim katalogu lub repozytorium Git, aby zminimalizować błędy. Jednostki są następujące:- {Nazwa modelu}* – Nazwa modelu.
- katalog_źródłowy* - Powszechny
source_dirścieżka do użycia we wszystkich krokach w jednostce modelowania. - wstępne przetwarzanie – Ta sekcja określa parametry przetwarzania wstępnego.
- pociąg* – Ta sekcja określa parametry zadania szkoleniowego.
- przekształcać* – Ta sekcja określa parametry zadania SageMaker Transform służące do przewidywania danych testowych.
- oceniać – Ta sekcja określa parametry zadania SageMaker Processing służące do generowania raportu JSON dotyczącego metryk modelu dla przeszkolonego modelu.
- rejestr* – W tej sekcji określono parametry rejestrowania przeszkolonego modelu w rejestrze modeli SageMaker.
- /conf/sagemakerPipeline* – Ta sekcja definiuje przepływ potoków SageMaker, w tym zależności między krokami. W przypadku użycia pojedynczego modelu ta sekcja jest zdefiniowana na końcu pliku konfiguracyjnego. W przypadku użycia wielu modeli,
sagemakerPipelineSekcję należy zdefiniować jedynie w pliku konfiguracyjnym jednego z modeli (dowolnego z modeli). Model ten nazywamy tzw model kotwicy. Parametry są następujące:- Nazwa rurociągu* – Nazwa potoku SageMaker.
- modele* – Zagnieżdżona lista jednostek modelowania:
- {Nazwa modelu}* – Identyfikator modelu, który powinien pasować do identyfikatora {model-name} w sekcji /conf/models.
- kroki* -
- nazwa_kroku* – Nazwa kroku wyświetlana w DAG SageMaker Pipelines.
- klasa_kroku* – (Unia [Przetwarzanie, Szkolenie, TworzenieModelu, Transformacja, Metryki, RejestrModel])
- typ_kroku* – Ten parametr jest wymagany tylko w przypadku etapów przetwarzania wstępnego, dla których powinien być ustawiony na przetwarzanie wstępne. Jest to konieczne, aby rozróżnić etapy przetwarzania wstępnego i oceny, przy czym oba mają charakter
step_classPrzetwarzania. - włącz_cache – ([Unia[Prawda, Fałsz]]). Wskazuje, czy włączyć Buforowanie potoków SageMaker dla tego kroku.
- krok_łańcucha_wejściowego_źródła – ([lista[nazwa_kroku]]). Można tego użyć do ustawienia wyjść kanału innego kroku jako wejścia dla tego kroku.
- łańcuch_wejściowy_dodatkowy_prefiks – Jest to dozwolone tylko w przypadku kroków transformacji
step_classi może być używany w połączeniu zchain_input_source_stepparametr wskazujący plik, który powinien zostać użyty jako dane wejściowe w kroku transformacji.
- kroki* -
- {Nazwa modelu}* – Identyfikator modelu, który powinien pasować do identyfikatora {model-name} w sekcji /conf/models.
- Zależności – Ta sekcja określa kolejność, w jakiej należy uruchamiać kroki SageMaker Pipelines. Do tej sekcji dostosowaliśmy notację Apache Airflow (na przykład
{step_name} >> {step_name}). Jeśli ta sekcja pozostanie pusta, jawne zależności określone przezchain_input_source_stepparametry lub ukryte zależności definiują przepływ DAG SageMaker Pipelines.
Należy pamiętać, że zalecamy wykonanie jednego kroku szkoleniowego na jednostkę modelowania. Jeśli dla jednostki modelowania zdefiniowano wiele kroków szkoleniowych, kolejne kroki domyślnie obejmują ostatni krok szkoleniowy w celu utworzenia obiektu modelu, obliczenia metryk i zarejestrowania modelu. Jeśli chcesz wytrenować wiele modeli, zaleca się utworzenie wielu jednostek modelowania.
Przykłady
W tej sekcji przedstawiamy trzy przykłady DAG-ów szkoleniowych w zakresie modelu uczenia maszynowego utworzonych przy użyciu prezentowanego frameworka.
Szkolenie jednomodelowe: LightGBM
To jest przykład pojedynczego modelu dla przypadku użycia klasyfikacji, w którym używamy LightGBM w trybie skryptowym w SageMaker, zestaw danych składa się ze zmiennych kategorycznych i liczbowych pozwalających przewidzieć etykietę binarną Przychód (aby przewidzieć, czy podmiot dokona zakupu, czy nie). The skrypt przetwarzania wstępnego służy do modelowania danych na potrzeby uczenia i testowania, a następnie umieść go w wiadrze S3. Ścieżki S3 są następnie dostarczane do krok treningowy w pliku konfiguracyjnym.
Po uruchomieniu etapu uczenia SageMaker ładuje plik do kontenera pod adresem /opt/ml/input/data/{channelName}/, dostępny poprzez zmienną środowiskową SM_CHANNEL_{channelName} na pojemniku (nazwa_kanału = „pociąg” lub „test”) scenariusz szkolenia wykonuje następujące czynności:
- Załaduj pliki lokalnie z lokalnych ścieżek kontenerów, używając metody NumPy obciążenia moduł.
- Ustaw hiperparametry dla algorytmu szkoleniowego.
- Zapisz przeszkolony model w lokalnej ścieżce kontenera
/opt/ml/model/.
SageMaker pobiera zawartość z katalogu /opt/ml/model/ w celu utworzenia archiwum tar, które jest używane do wdrażania modelu w SageMaker w celu hostingu.
Krok transformacji przyjmuje jako dane wejściowe etap plik testowy jako plik wejściowy oraz przeszkolony model w celu przewidywania wyuczonego modelu. Dane wyjściowe kroku transformacji to przykuty łańcuchem do kroku metryk, aby ocenić model względem podstawowa prawda, który jest jawnie dostarczany do kroku metryk. Na koniec dane wyjściowe kroku metryk są niejawnie powiązane z krokiem rejestru w celu zarejestrowania modelu w rejestrze modelu SageMaker z informacjami o wydajności modelu uzyskanymi w kroku metryk. Poniższy rysunek przedstawia wizualną reprezentację szkoleniowego DAG. Możesz odwołać się do skryptów i pliku konfiguracyjnego dla tego przykładu w pliku GitHub repo.
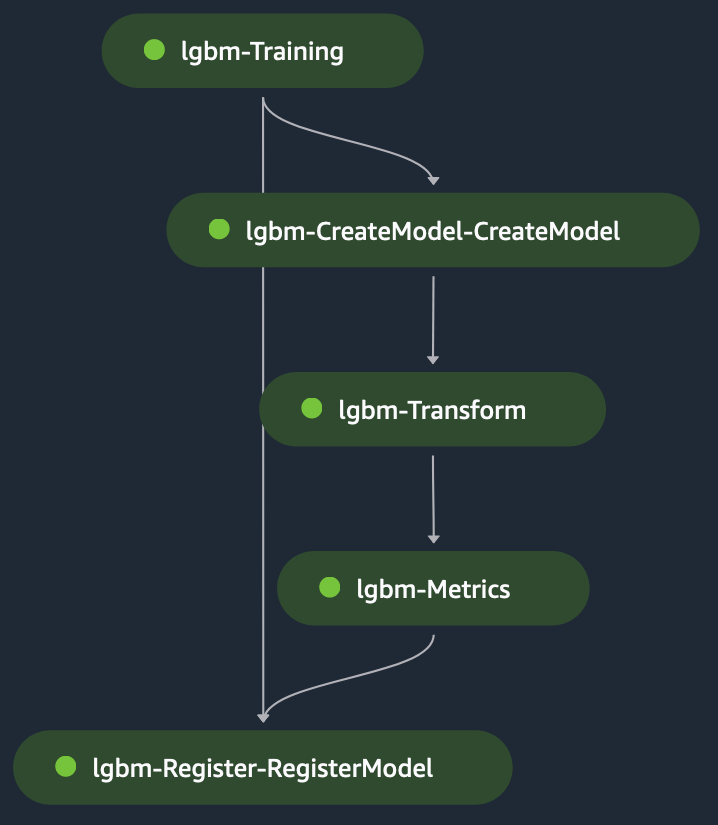
Szkolenie w jednym modelu: dostrajanie LLM
To kolejny przykład szkolenia pojedynczego modelu, w którym koordynujemy dostrajanie dużego modelu językowego (LLM) Falcon-40B z Hugging Face Hub na potrzeby zastosowania podsumowania tekstu. The skrypt przetwarzania wstępnego ładuje samsum zestaw danych z Hugging Face, ładuje tokenizer dla modelu i przetwarza podział danych uczenia/testowania w celu dostrojenia modelu na danych tej domeny na etapie wstępnego przetwarzania falcon-text-summarization-summarization.
Wynik jest przykuty łańcuchem do etapu dostrajania podsumowania tekstu sokoła, gdzie plik scenariusz szkolenia ładuje Falcon-40B LLM z Hugging Face Hub i rozpoczyna przyspieszone dostrajanie za pomocą LoRA w rozstaniu pociągu. Model jest oceniany w tym samym kroku po dostrojeniu, które odźwierni utrata oceny, która nie przejdzie etapu dostrajania podsumowania tekstu falcona, co powoduje zatrzymanie potoku SageMaker, zanim będzie on w stanie zarejestrować dostrojony model. W przeciwnym razie etap dostrajania podsumowania tekstu falcon przebiegnie pomyślnie i model zostanie zarejestrowany w rejestrze modelu SageMaker. Poniższy rysunek przedstawia wizualną reprezentację dostrajającego DAG LLM. Skrypty i plik konfiguracyjny dla tego przykładu są dostępne w pliku GitHub repo.
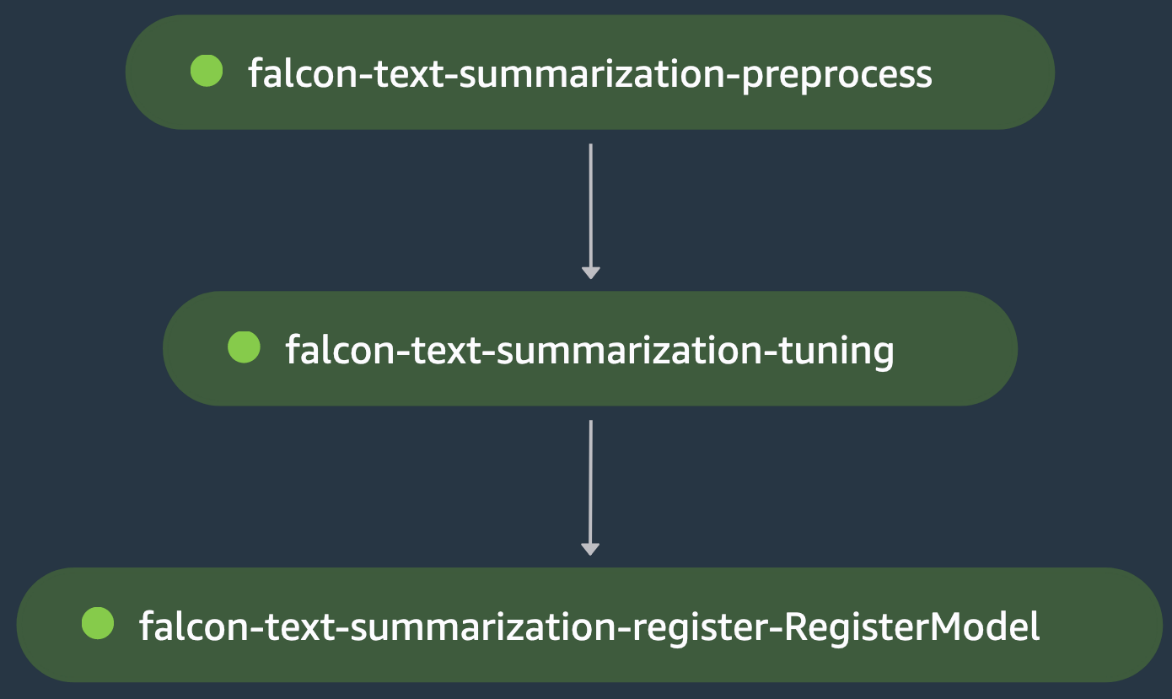
Trening wielomodelowy
Jest to przykład szkolenia obejmujący wiele modeli, w którym model analizy głównych składowych (PCA) jest szkolony pod kątem redukcji wymiarowości, a model wielowarstwowego perceptronu TensorFlow jest szkolony pod kątem Przewidywanie cen mieszkań w Kalifornii. Etap wstępnego przetwarzania modelu TensorFlow wykorzystuje przeszkolony model PCA w celu zmniejszenia wymiarowości danych szkoleniowych. Dodajemy zależność w konfiguracji, aby mieć pewność, że model TensorFlow zostanie zarejestrowany po rejestracji modelu PCA. Poniższy rysunek przedstawia wizualną reprezentację przykładu DAG szkoleniowego z wieloma modelami. Skrypty i pliki konfiguracyjne dla tego przykładu są dostępne w pliku GitHub repo.

Sprzątać
Wykonaj następujące kroki, aby wyczyścić zasoby:
- Użyj interfejsu CLI AWS, aby podstęp i usunąć wszelkie pozostałe potoki utworzone przez skrypty języka Python.
- Opcjonalnie usuń inne zasoby AWS, takie jak zasobnik S3 lub rola IAM utworzona poza SageMaker Pipelines.
Wnioski
W tym poście zaprezentowaliśmy framework do automatyzacji tworzenia SageMaker Pipelines DAG w oparciu o pliki konfiguracyjne. Proponowana struktura oferuje przyszłościowe rozwiązanie problemu koordynowania złożonych obciążeń uczenia maszynowego. Korzystając z pliku konfiguracyjnego, SageMaker Pipelines zapewnia elastyczność tworzenia orkiestracji przy użyciu minimalnej ilości kodu, dzięki czemu można usprawnić proces tworzenia i zarządzania potokami jedno- i wielomodelowymi. Takie podejście nie tylko oszczędza czas i zasoby, ale także promuje najlepsze praktyki MLOps, przyczyniając się do ogólnego sukcesu inicjatyw ML. Aby uzyskać więcej informacji na temat szczegółów implementacji, przejrzyj plik GitHub repo.
O autorach
 Luisa Felipe Yepeza Barriosa, jest inżynierem uczenia maszynowego w AWS Professional Services, zajmującym się skalowalnymi systemami rozproszonymi i narzędziami do automatyzacji w celu przyspieszenia innowacji naukowych w dziedzinie uczenia maszynowego (ML). Ponadto pomaga klientom korporacyjnym w optymalizacji rozwiązań uczenia maszynowego za pośrednictwem usług AWS.
Luisa Felipe Yepeza Barriosa, jest inżynierem uczenia maszynowego w AWS Professional Services, zajmującym się skalowalnymi systemami rozproszonymi i narzędziami do automatyzacji w celu przyspieszenia innowacji naukowych w dziedzinie uczenia maszynowego (ML). Ponadto pomaga klientom korporacyjnym w optymalizacji rozwiązań uczenia maszynowego za pośrednictwem usług AWS.
 Jinzhao Fenga, jest inżynierem uczenia maszynowego w AWS Professional Services. Koncentruje się na projektowaniu i wdrażaniu wielkoskalowych rozwiązań generatywnej AI i klasycznych rozwiązań potokowych ML. Specjalizuje się w FMops, LLMOps i szkoleniach rozproszonych.
Jinzhao Fenga, jest inżynierem uczenia maszynowego w AWS Professional Services. Koncentruje się na projektowaniu i wdrażaniu wielkoskalowych rozwiązań generatywnej AI i klasycznych rozwiązań potokowych ML. Specjalizuje się w FMops, LLMOps i szkoleniach rozproszonych.
 Surowy Asnani, jest inżynierem uczenia maszynowego w AWS. Jego doświadczenie dotyczy stosowanej nauki o danych, ze szczególnym uwzględnieniem operacjonalizacji obciążeń uczenia maszynowego w chmurze na dużą skalę.
Surowy Asnani, jest inżynierem uczenia maszynowego w AWS. Jego doświadczenie dotyczy stosowanej nauki o danych, ze szczególnym uwzględnieniem operacjonalizacji obciążeń uczenia maszynowego w chmurze na dużą skalę.
 Hasana Shojaei, jest starszym analitykiem danych w AWS Professional Services, gdzie pomaga klientom z różnych branż rozwiązywać problemy biznesowe poprzez wykorzystanie dużych zbiorów danych, uczenia maszynowego i technologii chmurowych. Przed objęciem tej roli Hasan kierował wieloma inicjatywami mającymi na celu opracowanie nowatorskich technik modelowania opartych na fizyce i danych dla czołowych firm energetycznych. Poza pracą Hasan pasjonuje się książkami, turystyką pieszą, fotografią i historią.
Hasana Shojaei, jest starszym analitykiem danych w AWS Professional Services, gdzie pomaga klientom z różnych branż rozwiązywać problemy biznesowe poprzez wykorzystanie dużych zbiorów danych, uczenia maszynowego i technologii chmurowych. Przed objęciem tej roli Hasan kierował wieloma inicjatywami mającymi na celu opracowanie nowatorskich technik modelowania opartych na fizyce i danych dla czołowych firm energetycznych. Poza pracą Hasan pasjonuje się książkami, turystyką pieszą, fotografią i historią.
 Aleca Jenaba, jest inżynierem uczenia maszynowego, który specjalizuje się w opracowywaniu i operacjonalizacji rozwiązań uczenia maszynowego na dużą skalę dla klientów korporacyjnych. Alec pasjonuje się wprowadzaniem na rynek innowacyjnych rozwiązań, szczególnie w obszarach, w których uczenie maszynowe może znacząco poprawić doświadczenie użytkownika końcowego. Poza pracą lubi grać w koszykówkę, jeździć na snowboardzie i odkrywać ukryte skarby w San Francisco.
Aleca Jenaba, jest inżynierem uczenia maszynowego, który specjalizuje się w opracowywaniu i operacjonalizacji rozwiązań uczenia maszynowego na dużą skalę dla klientów korporacyjnych. Alec pasjonuje się wprowadzaniem na rynek innowacyjnych rozwiązań, szczególnie w obszarach, w których uczenie maszynowe może znacząco poprawić doświadczenie użytkownika końcowego. Poza pracą lubi grać w koszykówkę, jeździć na snowboardzie i odkrywać ukryte skarby w San Francisco.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- PlatoData.Network Pionowe generatywne AI. Wzmocnij się. Dostęp tutaj.
- PlatoAiStream. Inteligencja Web3. Wiedza wzmocniona. Dostęp tutaj.
- PlatonESG. Węgiel Czysta technologia, Energia, Środowisko, Słoneczny, Gospodarowanie odpadami. Dostęp tutaj.
- Platon Zdrowie. Inteligencja w zakresie biotechnologii i badań klinicznych. Dostęp tutaj.
- Źródło: https://aws.amazon.com/blogs/machine-learning/automate-amazon-sagemaker-pipelines-dag-creation/

