Wprowadzenie
Ten przewodnik jest trzecią i ostatnią częścią trzech przewodników dotyczących maszyn wektorów nośnych (SVM). W tym przewodniku będziemy dalej pracować z przypadkiem użycia sfałszowanych banknotów, krótko przypomnimy ogólną ideę SVM, zrozumiemy, na czym polega sztuczka z jądrem i zaimplementujemy różne typy nieliniowych jąder za pomocą Scikit-Learn.
W pełnej serii przewodników SVM, oprócz nauki o innych typach SVM, dowiesz się również o prostych SVM, predefiniowanych parametrach SVM, hiperparametrach C i Gamma oraz o tym, jak można je dostroić za pomocą wyszukiwania siatki i walidacji krzyżowej.
Jeśli chcesz przeczytać poprzednie poradniki, możesz rzucić okiem na pierwsze dwa poradniki lub zobaczyć, które tematy najbardziej Cię interesują. Poniżej znajduje się tabela tematów poruszanych w każdym przewodniku:
- Przypadek użycia: zapomnij o banknotach
- Tło maszyn SVM
- Prosty (liniowy) model SVM
- O zbiorze danych
- Importowanie zestawu danych
- Eksploracja zbioru danych
- Implementacja SVM z Scikit-Learn
- Dzielenie danych na zestawy pociągów/testów
- Trenowanie modelu
- Dokonywanie prognoz
- Ocena modelu
- Interpretowanie wyników
- Hiperparametr C
- Hiperparametr Gamma
3. Implementacja innych smaków SVM za pomocą Scikit-Learn w Pythonie
- Ogólna koncepcja maszyn SVM (podsumowanie)
- Jądro (sztuczka) SVM
- Implementacja SVM z nieliniowym jądrem za pomocą Scikit-Learn
- Importowanie bibliotek
- Importowanie zestawu danych
- Dzielenie danych na cechy (X) i cel (y)
- Dzielenie danych na zestawy pociągów/testów
- Trening algorytmu
- Jądro wielomianowe
- Dokonywanie prognoz
- Ocena algorytmu
- Jądro Gaussa
- Przewidywanie i ocena
- Jądro esicy
- Przewidywanie i ocena
- Porównanie nieliniowych wydajności jądra
Przypomnijmy sobie, czym jest SVM, zanim zobaczymy kilka interesujących odmian jądra SVM.
Ogólna idea maszyn SVM
W przypadku liniowo separowalnych danych w dwóch wymiarach (jak pokazano na rys. 1) typowym podejściem algorytmu uczenia maszynowego byłaby próba znalezienia granicy dzielącej dane w taki sposób, aby zminimalizować błąd błędnej klasyfikacji. Jeśli przyjrzysz się uważnie rysunkowi 1, zauważysz, że może istnieć kilka granic (nieskończonych), które prawidłowo dzielą punkty danych. Dwie linie przerywane oraz linia ciągła to prawidłowe klasyfikacje danych.
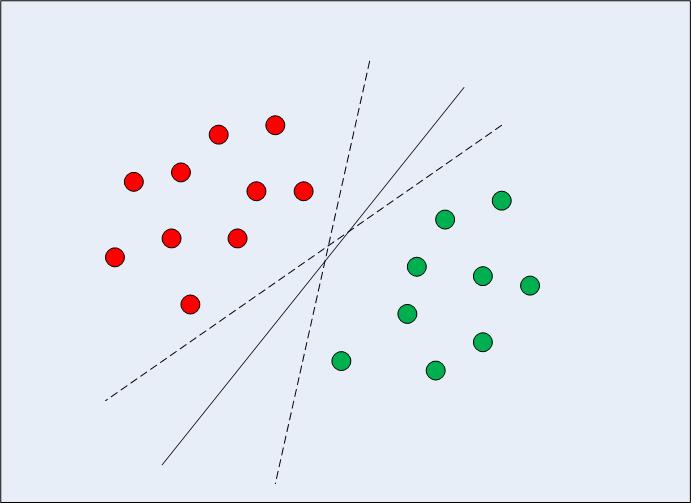
Ryc. 1: Wiele granic decyzyjnych
Gdy SVM wybierze granica decyzji, wybiera granicę, która maksymalizuje odległość między nim a najbliższymi punktami danych klas. Wiemy już, że najbliższymi punktami danych są wektory wsparcia i że odległość można sparametryzować za pomocą obu C i gamma hiperparametry.
Obliczając tę granicę decyzyjną, algorytm wybiera, ile punktów należy wziąć pod uwagę i jak daleko może się posunąć margines – konfiguruje to problem maksymalizacji marginesu. Rozwiązując ten problem maksymalizacji marginesu, SVM wykorzystuje wektory nośne (jak widać na ryc. 2) i próbuje ustalić, jakie są optymalne wartości, które utrzymują większą odległość marginesu, jednocześnie poprawnie klasyfikując więcej punktów zgodnie z funkcją, która jest używana do oddzielić dane.
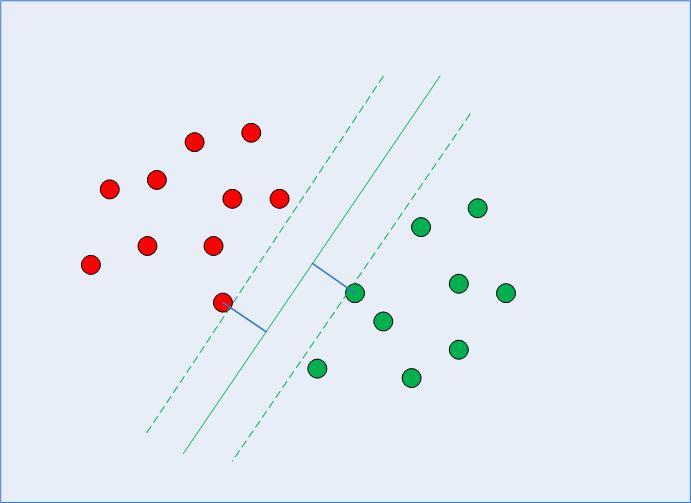
Ryc. 2: Granica decyzyjna z wektorami wsparcia
Właśnie dlatego SVM różni się od innych algorytmów klasyfikacji, gdy nie tylko znajduje granicę decyzyjną, ale ostatecznie znajduje optymalną granicę decyzyjną.
Za znalezieniem wektorów wsparcia, obliczeniem marginesu między granicą decyzyjną a wektorami wsparcia oraz maksymalizacją tego marginesu stoi złożona matematyka wywodząca się ze statystyk i metod obliczeniowych. Tym razem nie będziemy wchodzić w szczegóły tego, jak działa matematyka.
Zawsze ważne jest, aby zanurzyć się głębiej i upewnić się, że algorytmy uczenia maszynowego nie są jakimś tajemniczym zaklęciem, chociaż nieznajomość wszystkich szczegółów matematycznych w tym czasie nie powstrzymała i nie powstrzyma cię przed wykonaniem algorytmu i uzyskaniem wyników.
Rada: teraz, gdy dokonaliśmy podsumowania procesu algorytmicznego, jasne jest, że odległość między punktami danych wpłynie na granicę decyzyjną wybraną przez SVM, z tego powodu, skalowanie danych jest zwykle konieczne, gdy używany jest klasyfikator SVM. Spróbuj użyć Metoda standardowego skalera Scikit-learn aby przygotować dane, a następnie ponownie uruchomić kody, aby zobaczyć, czy są różnice w wynikach.
Jądro (sztuczka) SVM
W poprzedniej sekcji przypomnieliśmy sobie i uporządkowaliśmy ogólną ideę SVM – sprawdzając, jak można ją wykorzystać do znalezienia optymalnej granicy decyzyjnej dla danych liniowo separowalnych. Jednak w przypadku danych separowalnych nieliniowo, takich jak ta pokazana na ryc. 3, wiemy już, że linia prosta nie może służyć jako granica decyzyjna.
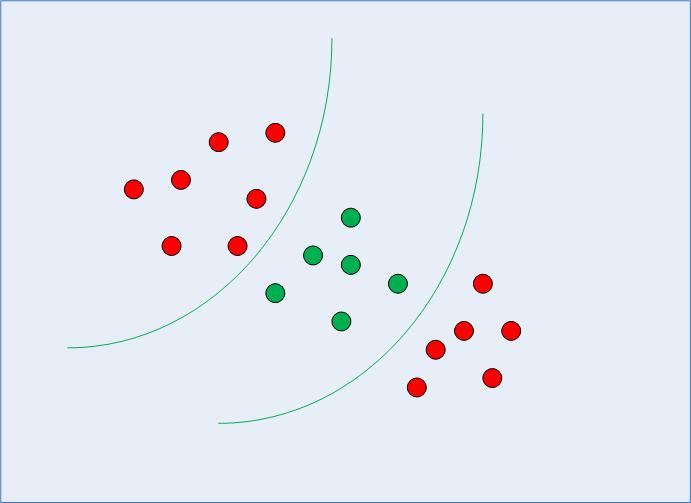
Ryc. 3: Dane nieliniowo separowalne
Zamiast tego możemy użyć zmodyfikowanej wersji SVM, o której mówiliśmy na początku, zwanej Kernel SVM.
Zasadniczo to, co zrobi SVM jądra, to rzutowanie nieliniowo separowalnych danych o niższych wymiarach do ich odpowiedniej postaci w wyższych wymiarach. Jest to sztuczka, ponieważ podczas rzutowania danych nieliniowo separowalnych w wyższych wymiarach kształt danych zmienia się w taki sposób, że stają się one separowalne. Na przykład, myśląc o 3 wymiarach, punkty danych z każdej klasy mogą zostać przydzielone w innym wymiarze, co sprawi, że będzie można je rozdzielić. Jednym ze sposobów zwiększania wymiarów danych może być ich potęgowanie. Ponownie wiąże się to ze złożoną matematyką, ale nie musisz się tym martwić, aby korzystać z SVM. Możemy raczej użyć biblioteki Scikit-Learn Pythona do zaimplementowania i używania nieliniowych jąder w taki sam sposób, w jaki używaliśmy liniowego.
Implementacja SVM z nieliniowym jądrem za pomocą Scikit-Learn
W tej sekcji użyjemy tego samego zestawu danych, aby przewidzieć, czy banknot jest prawdziwy, czy sfałszowany, zgodnie z czterema cechami, które już znamy.
Zobaczysz, że pozostałe kroki są typowymi krokami uczenia maszynowego i wymagają bardzo niewiele wyjaśnień, dopóki nie dojdziemy do części, w której szkolimy nasze SVM z nieliniowym jądrem.
Importowanie bibliotek
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
from sklearn.model_selection import train_test_split
Importowanie zestawu danych
data_link = "https://archive.ics.uci.edu/ml/machine-learning-databases/00267/data_banknote_authentication.txt"
col_names = ["variance", "skewness", "curtosis", "entropy", "class"] bankdata = pd.read_csv(data_link, names=col_names, sep=",", header=None)
bankdata.head()mes)
Dzielenie danych na cechy (X) i cel (y)
X = bankdata.drop('class', axis=1)
y = bankdata['class']
Dzielenie danych na zestawy pociągów/testów
SEED = 42 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.20, random_state = SEED)
Trening algorytmu
Aby wyszkolić SVM jądra, użyjemy tego samego SVC klasa Scikit-Learn's svm biblioteka. Różnica polega na wartości parametru jądra pliku SVC class.
W przypadku prostej SVM użyliśmy „liniowej” jako wartości parametru jądra. Jednak, jak wspomnieliśmy wcześniej, dla jądra SVM możemy użyć jądra gaussowskiego, wielomianowego, sigmoidalnego lub obliczeniowego. Zaimplementujemy jądra wielomianowe, gaussowskie i sigmoidalne i przyjrzymy się jego ostatecznym metrykom, aby zobaczyć, które z nich wydaje się pasować do naszych klas z wyższą metryką.
1. Jądro wielomianowe
W algebrze wielomian jest wyrażeniem postaci:
$$
2a*b^3 + 4a – 9
$$
Ma to zmienne, takie jak a i b, stałe, w naszym przykładzie, 9 oraz współczynniki (stałe towarzyszące zmiennym), takie jak 2 i 4, 3 jest uważany za stopień wielomianu.
Istnieją typy danych, które można najlepiej opisać za pomocą funkcji wielomianu, tutaj jądro zrobi mapowanie naszych danych na wielomian, do którego wybierzemy stopień. Im wyższy stopień, tym bardziej funkcja będzie próbowała zbliżyć się do danych, więc granica decyzyjna jest bardziej elastyczna (i bardziej podatna na przeuczenie) – im niższy stopień, tym mniej elastyczna.
Zapoznaj się z naszym praktycznym, praktycznym przewodnikiem dotyczącym nauki Git, zawierającym najlepsze praktyki, standardy przyjęte w branży i dołączoną ściągawkę. Zatrzymaj polecenia Google Git, a właściwie uczyć się to!
Tak więc za wdrożenie jądro wielomianowe, oprócz wyboru poly kernel, przekażemy również wartość dla degree parametr SVC klasa. Poniżej znajduje się kod:
from sklearn.svm import SVC
svc_poly = SVC(kernel='poly', degree=8)
svc_poly.fit(X_train, y_train)
Dokonywanie prognoz
Teraz, po wytrenowaniu algorytmu, następnym krokiem jest przewidywanie danych testowych.
Tak jak zrobiliśmy to wcześniej, możemy w tym celu wykonać następujący skrypt:
y_pred_poly = svclassifier.predict(X_test)
Ocena algorytmu
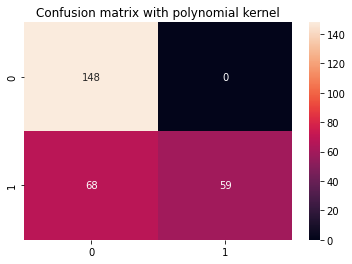
Jak zwykle ostatnim krokiem jest dokonanie oceny jądra wielomianu. Ponieważ kilka razy powtórzyliśmy kod raportu klasyfikacyjnego i macierzy zamieszania, przekształćmy go w funkcję, która display_results po otrzymaniu odpowiednich y_test, y_pred i tytuł do matrycy zamieszania Seaborn z cm_title:
def display_results(y_test, y_pred, cm_title): cm = confusion_matrix(y_test,y_pred) sns.heatmap(cm, annot=True, fmt='d').set_title(cm_title) print(classification_report(y_test,y_pred))
Teraz możemy wywołać funkcję i spojrzeć na wyniki otrzymane za pomocą jądra wielomianu:
cm_title_poly = "Confusion matrix with polynomial kernel"
display_results(y_test, y_pred_poly, cm_title_poly)
Wynik wygląda tak:
precision recall f1-score support 0 0.69 1.00 0.81 148 1 1.00 0.46 0.63 127 accuracy 0.75 275 macro avg 0.84 0.73 0.72 275
weighted avg 0.83 0.75 0.73 275
Teraz możemy powtórzyć te same kroki dla jądra Gaussa i esicy.
2. Jądro Gaussa
Aby użyć jądra gaussowskiego, musimy jedynie określić „rbf” jako wartość dla kernel parametr klasy SVC:
svc_gaussian = SVC(kernel='rbf', degree=8)
svc_gaussian.fit(X_train, y_train)
Podczas dalszej eksploracji tego jądra możesz również użyć wyszukiwania siatki, aby połączyć je z innymi C i gamma wartości.
Przewidywanie i ocena
y_pred_gaussian = svc_gaussian.predict(X_test)
cm_title_gaussian = "Confusion matrix with Gaussian kernel"
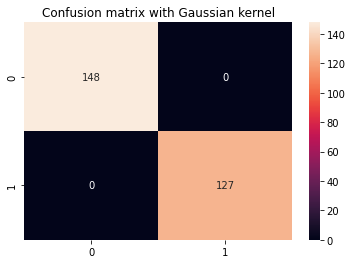
display_results(y_test, y_pred_gaussian, cm_title_gaussian)
Dane wyjściowe SVM z jądrem Gaussa wyglądają następująco:
precision recall f1-score support 0 1.00 1.00 1.00 148 1 1.00 1.00 1.00 127 accuracy 1.00 275 macro avg 1.00 1.00 1.00 275
weighted avg 1.00 1.00 1.00 275
3. Jądro esowate
Na koniec użyjmy jądra sigmoidalnego do implementacji Kernel SVM. Spójrz na następujący skrypt:
svc_sigmoid = SVC(kernel='sigmoid')
svc_sigmoid.fit(X_train, y_train)
Aby użyć jądra sigmoidalnego, musisz określić „sigmoid” jako wartość dla kernel parametr SVC class.
Przewidywanie i ocena
y_pred_sigmoid = svc_sigmoid.predict(X_test)
cm_title_sigmoid = "Confusion matrix with Sigmoid kernel"
display_results(y_test, y_pred_sigmoid, cm_title_sigmoid)
Wyjście Kernel SVM z jądrem Sigmoid wygląda następująco:
precision recall f1-score support 0 0.67 0.71 0.69 148 1 0.64 0.59 0.61 127 accuracy 0.65 275 macro avg 0.65 0.65 0.65 275
weighted avg 0.65 0.65 0.65 275

Porównanie nieliniowych wydajności jądra
Jeśli pokrótce porównamy wydajność różnych typów jąder nieliniowych, może się wydawać, że jądro sigmoidalne ma najniższe metryki, a więc najgorszą wydajność.
Wśród jąder gaussowskich i wielomianowych widzimy, że jądro gaussowskie osiągnęło doskonały współczynnik predykcji 100% – co zwykle jest podejrzane i może wskazywać na przeuczenie, podczas gdy jądro wielomianowe błędnie sklasyfikowało 68 instancji klasy 1.
Dlatego nie ma sztywnych reguł określających, które jądro działa najlepiej w każdym scenariuszu lub w naszym obecnym scenariuszu bez dalszego wyszukiwania hiperparametrów, zrozumienia kształtu każdej funkcji, eksploracji danych oraz porównywania wyników uczenia i testów w celu sprawdzenia, czy algorytm generalizuje.
Wszystko sprowadza się do przetestowania wszystkich jąder i wybrania tego z kombinacją parametrów i przygotowaniem danych, które dają oczekiwane wyniki zgodnie z kontekstem Twojego projektu.
Idąc dalej — ręczny, kompleksowy projekt
Twoja dociekliwość sprawia, że chcesz iść dalej? Zalecamy sprawdzenie naszego Projekt z przewodnikiem: „Praktyczne przewidywanie cen domów — uczenie maszynowe w Pythonie”.

W tym projekcie z przewodnikiem — dowiesz się, jak tworzyć potężne tradycyjne modele uczenia maszynowego, a także modele głębokiego uczenia się, wykorzystywać Ensemble Learning i szkolić meta-uczniów, aby przewidywać ceny domów na podstawie zestawu modeli Scikit-Learn i Keras.
Korzystając z Keras, interfejsu API do uczenia głębokiego zbudowanego na bazie Tensorflow, będziemy eksperymentować z architekturami, budować zestaw modeli ułożonych w stos i szkolić metauczeń sieć neuronowa (model poziomu 1), aby ustalić wycenę domu.
Głębokie uczenie jest niesamowite – ale zanim się do niego zastosuje, warto również spróbować rozwiązać problem za pomocą prostszych technik, takich jak płytkie uczenie się algorytmy. Nasza wyjściowa wydajność będzie oparta na Regresja losowego lasu algorytm. Dodatkowo – będziemy badać tworzenie zestawów modeli poprzez Scikit-Learn za pomocą technik takich jak parcianka i głosowanie.
Jest to projekt typu end-to-end i tak jak wszystkie projekty uczenia maszynowego, zaczniemy od – od Analiza danych rozpoznawczych, śledzony przez Wstępne przetwarzanie danych i w końcu Budowanie płytkie i Modele głębokiego uczenia aby dopasować dane, które wcześniej zbadaliśmy i oczyściliśmy.
Wnioski
W tym artykule dokonaliśmy szybkiego podsumowania maszyn SVM, zbadaliśmy sztuczkę z jądrem i zaimplementowaliśmy różne warianty nieliniowych maszyn SVM.
Sugeruję wdrożenie każdego jądra i pójście dalej. Możesz zbadać matematykę użytą do stworzenia każdego z różnych jąder, dlaczego zostały stworzone i różnice dotyczące ich hiperparametrów. W ten sposób dowiesz się o technikach i typie jądra najlepiej zastosować w zależności od kontekstu i dostępnych danych.
Jasne zrozumienie, jak działa każde jądro i kiedy ich używać, z pewnością pomoże ci w podróży. Daj nam znać, jak idą postępy i szczęśliwego kodowania!
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- Platoblockchain. Web3 Inteligencja Metaverse. Wzmocniona wiedza. Dostęp tutaj.
- Wybijanie przyszłości w Adryenn Ashley. Dostęp tutaj.
- Źródło: https://stackabuse.com/implementing-other-svm-flavors-with-pythons-scikit-learn/

