Organizacje z różnych branż chcą kategoryzować i wyciągać wnioski z dużych ilości dokumentów w różnych formatach. Ręczne przetwarzanie tych dokumentów w celu klasyfikacji i wyodrębniania informacji pozostaje kosztowne, podatne na błędy i trudne do skalowania. Postęp w generatywna sztuczna inteligencja (AI) dały początek inteligentnym rozwiązaniom do przetwarzania dokumentów (IDP), które mogą zautomatyzować klasyfikację dokumentów i stworzyć opłacalną warstwę klasyfikacji zdolną do obsługi różnorodnych, nieustrukturyzowanych dokumentów korporacyjnych.
Kategoryzacja dokumentów jest ważnym pierwszym krokiem w systemach IDP. Pomaga określić kolejny zestaw działań, które należy podjąć w zależności od typu dokumentu. Na przykład podczas procesu rozpatrywania roszczeń zespół ds. rozliczeń otrzymuje fakturę, natomiast dział roszczeń zarządza dokumentami umowy lub polisy. Tradycyjne mechanizmy reguł lub klasyfikacja oparta na uczeniu maszynowym mogą klasyfikować dokumenty, ale często osiągają ograniczenia dotyczące typów formatów dokumentów i obsługi dynamicznego dodawania nowych klas dokumentów. Aby uzyskać więcej informacji, zobacz Klasyfikator dokumentów Amazon Comprehend dodaje obsługę układu dla większej dokładności.
W tym poście omawiamy klasyfikację dokumentów za pomocą Model osadzania multimodalnego Amazon Titan klasyfikować dowolne typy dokumentów bez konieczności szkolenia.
Multimodalne osadzania Amazon Titan
Niedawno wprowadzony Amazon Multimodalne osadzanie Titan in Amazońska skała macierzysta. Model ten może tworzyć osadzania obrazów i tekstu, umożliwiając tworzenie osadzań dokumentów do wykorzystania w nowych przepływach pracy związanych z klasyfikacją dokumentów.
Generuje zoptymalizowane reprezentacje wektorowe dokumentów zeskanowanych jako obrazy. Kodując zarówno komponenty wizualne, jak i tekstowe w ujednolicone wektory numeryczne, które zawierają znaczenie semantyczne, umożliwia szybkie indeksowanie, wydajne wyszukiwanie kontekstowe i dokładną klasyfikację dokumentów.
Gdy w przepływach pracy biznesowej pojawią się nowe szablony i typy dokumentów, możesz po prostu wywołać API Amazon Bedrock dynamiczną wektoryzację i dołączanie do systemów IDP w celu szybkiego zwiększenia możliwości klasyfikacji dokumentów.
Omówienie rozwiązania
Przyjrzyjmy się następującemu rozwiązaniu do klasyfikacji dokumentów za pomocą modelu Amazon Titan Multimodal Embeddings. Aby uzyskać optymalną wydajność, należy dostosować rozwiązanie do konkretnego przypadku użycia i istniejącej konfiguracji potoku IDP.
To rozwiązanie klasyfikuje dokumenty za pomocą wyszukiwania semantycznego z osadzaniem wektorów, dopasowując dokument wejściowy do już zindeksowanej galerii dokumentów. Używamy następujących kluczowych komponentów:
- zanurzeń - zanurzeń to numeryczne reprezentacje obiektów świata rzeczywistego, których systemy uczenia maszynowego (ML) i sztucznej inteligencji wykorzystują do zrozumienia złożonych dziedzin wiedzy, tak jak robią to ludzie.
- Wektorowe bazy danych - Wektorowe bazy danych służą do przechowywania osadów. Wektorowe bazy danych skutecznie indeksują i organizują osadzania, umożliwiając szybkie wyszukiwanie podobnych wektorów w oparciu o metryki odległości, takie jak odległość euklidesowa lub podobieństwo cosinusa.
- Wyszukiwanie semantyczne – Wyszukiwanie semantyczne uwzględnia kontekst i znaczenie zapytania wejściowego oraz jego związek z przeszukiwaną treścią. Osadzanie wektorów to skuteczny sposób na uchwycenie i zachowanie kontekstowego znaczenia tekstu i obrazów. W naszym rozwiązaniu, gdy aplikacja chce przeprowadzić wyszukiwanie semantyczne, dokument wyszukiwania jest najpierw konwertowany na osadzenie. Następnie przeszukiwana jest baza danych wektorów zawierająca odpowiednią treść w celu znalezienia najbardziej podobnych osadzań.
W procesie etykietowania przykładowy zestaw dokumentów biznesowych, takich jak faktury, wyciągi bankowe lub recepty, jest konwertowany na elementy osadzone przy użyciu modelu Amazon Titan Multimodal Embeddings i przechowywany w wektorowej bazie danych zgodnie ze wstępnie zdefiniowanymi etykietami. Model Amazon Titan Multimodal Embedding został przeszkolony przy użyciu algorytmu Euclidean L2 i dlatego w celu uzyskania najlepszych wyników używana baza danych wektorów powinna obsługiwać ten algorytm.
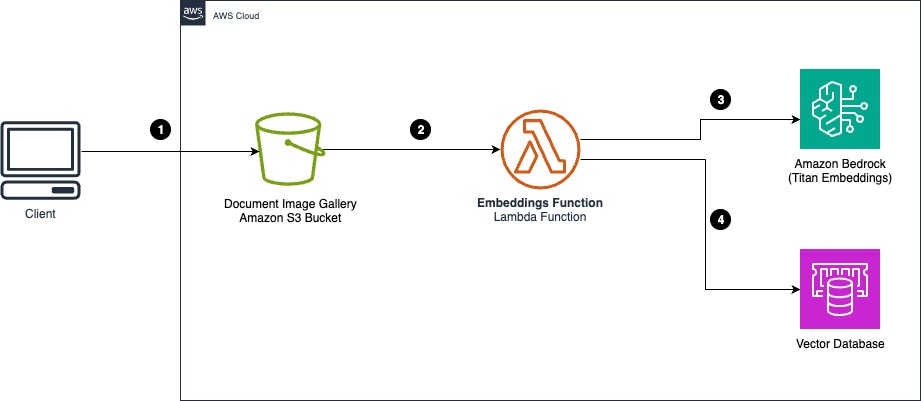
Poniższy diagram architektury ilustruje, w jaki sposób można używać modelu Amazon Titan Multimodal Embeddings z dokumentami w formacie Usługa Amazon Simple Storage Wiadro (Amazon S3) do tworzenia galerii obrazów.
Przepływ pracy składa się z następujących kroków:
- Użytkownik lub aplikacja przesyła przykładowy obraz dokumentu z metadanymi klasyfikacji do galerii obrazów dokumentów. Do klasyfikowania obrazów z galerii można użyć prefiksu S3 lub metadanych obiektu S3.
- Zdarzenie powiadomienia o obiekcie Amazon S3 wywołuje osadzanie AWS Lambda funkcja.
- Funkcja Lambda odczytuje obraz dokumentu i tłumaczy go na osadzanie, wywołując Amazon Bedrock i używając modelu Amazon Titan Multimodal Embeddings.
- Osadzenia obrazów wraz z klasyfikacją dokumentów przechowywane są w bazie danych wektorowych.
Gdy nowy dokument wymaga klasyfikacji, ten sam model osadzania jest używany do konwersji dokumentu zapytania na osadzenie. Następnie przeprowadzane jest semantyczne wyszukiwanie podobieństwa w bazie wektorów przy użyciu osadzania zapytań. Etykieta pobrana z górnego dopasowania osadzania będzie etykietą klasyfikacyjną dla dokumentu zapytania.
Poniższy diagram architektury ilustruje sposób użycia modelu Amazon Titan Multimodal Embeddings z dokumentami w zasobniku S3 do klasyfikacji obrazów.
Przepływ pracy składa się z następujących kroków:
- Dokumenty wymagające klasyfikacji są przesyłane do zasobnika wejściowego S3.
- Funkcja klasyfikacji Lambda odbiera powiadomienie o obiekcie Amazon S3.
- Funkcja Lambda tłumaczy obraz na osadzenie, wywołując interfejs API Amazon Bedrock.
- Baza wektorów jest przeszukiwana pod kątem pasującego dokumentu za pomocą wyszukiwania semantycznego. Klasyfikacja dokumentu zgodnego służy do klasyfikacji dokumentu wejściowego.
- Dokument wejściowy jest przenoszony do docelowego katalogu S3 lub prefiksu przy użyciu klasyfikacji uzyskanej z wektorowego wyszukiwania bazy danych.

Aby pomóc Ci przetestować rozwiązanie na własnych dokumentach, stworzyliśmy przykładowy notatnik Python Jupyter, który jest dostępny na GitHub.
Wymagania wstępne
Do uruchomienia notebooka potrzebny jest plik Konto AWS z odpowiednim AWS Zarządzanie tożsamością i dostępem (IAM) uprawnienia do dzwonienia do Amazon Bedrock. Dodatkowo na Dostęp do modelu stronie konsoli Amazon Bedrock, upewnij się, że dostęp został przyznany dla modelu Amazon Titan Multimodal Embeddings.
Realizacja
W poniższych krokach zastąp każdy symbol zastępczy danych wejściowych użytkownika własnymi informacjami:
- Utwórz bazę wektorów. W tym rozwiązaniu korzystamy z bazy danych FAISS znajdującej się w pamięci, ale można skorzystać z alternatywnej bazy danych wektorowych. Domyślny rozmiar wymiaru Amazon Titan to 1024.
- Po utworzeniu bazy danych wektorowych wylicz przykładowe dokumenty, tworząc osadzania każdego z nich i zapisz je w bazie danych wektorowych
- Przetestuj na swoich dokumentach. Zastąp foldery w poniższym kodzie własnymi folderami zawierającymi znane typy dokumentów:
- Korzystając z biblioteki Boto3, zadzwoń do Amazon Bedrock. Zmienna
inputImageB64to tablica bajtów zakodowana w formacie Base64 reprezentująca Twój dokument. Odpowiedź z Amazon Bedrock zawiera elementy osadzone.
- Dodaj osady do bazy danych wektorów z identyfikatorem klasy reprezentującym znany typ dokumentu:
- Dzięki bazie danych wektorów wypełnionej obrazami (reprezentującej naszą galerię) możesz odkryć podobieństwa z nowymi dokumentami. Na przykład poniżej przedstawiono składnię używaną do wyszukiwania. Wartość k=1 mówi FAISS, aby zwróciła 1 najlepsze dopasowanie.
Dodatkowo zwracana jest także odległość euklidesowa L2 pomiędzy obrazem dostępnym a obrazem znalezionym. Jeśli obraz jest identyczny, wartość ta będzie wynosić 0. Im większa jest ta wartość, tym bardziej obrazy są do siebie podobne.
Dodatkowe uwagi
W tej sekcji omówimy dodatkowe kwestie dotyczące efektywnego korzystania z rozwiązania. Obejmuje to prywatność danych, bezpieczeństwo, integrację z istniejącymi systemami i szacunki kosztów.
Prywatność i bezpieczeństwo danych
AWS model współodpowiedzialności dotyczy Ochrona danych w Amazon Bedrock. Jak opisano w tym modelu, AWS jest odpowiedzialny za ochronę globalnej infrastruktury, na której działa cała chmura AWS. Klienci są odpowiedzialni za utrzymanie kontroli nad swoimi treściami hostowanymi w tej infrastrukturze. Jako klient jesteś odpowiedzialny za konfigurację zabezpieczeń i zadania zarządzania usługami AWS, z których korzystasz.
Ochrona danych w Amazon Bedrock
Amazon Bedrock unika korzystania z podpowiedzi i kontynuacji klientów w celu uczenia modeli AWS lub udostępniania ich stronom trzecim. Amazon Bedrock nie przechowuje ani nie rejestruje danych klientów w swoich dziennikach usług. Dostawcy modeli nie mają dostępu do dzienników Amazon Bedrock ani dostępu do monitów i kontynuacji klientów. W rezultacie obrazy używane do generowania osadzania za pośrednictwem modelu Amazon Titan Multimodal Embeddings nie są przechowywane ani wykorzystywane w modelach szkoleniowych AWS ani w dystrybucji zewnętrznej. Ponadto inne dane dotyczące użycia, takie jak sygnatury czasowe i identyfikatory zarejestrowanych kont, są wykluczone z uczenia modeli.
Integracja z istniejącymi systemami
Model Amazon Titan Multimodal Embeddings został przeszkolony z algorytmem Euclidean L2, dlatego wykorzystywana baza wektorów powinna być kompatybilna z tym algorytmem.
Oszacowanie kosztów
W chwili pisania tego postu, zgodnie z art Ceny Amazon Bedrock w przypadku modelu Amazon Titan Multimodal Embeddings poniżej przedstawiono szacowane koszty przy zastosowaniu wyceny na żądanie dla tego rozwiązania:
- Jednorazowy koszt indeksowania – 0.06 dolara za pojedynczy przebieg indeksowania, przy założeniu galerii zawierającej 1,000 obrazów
- Koszt klasyfikacji – 6 USD za 100,000 XNUMX obrazów wejściowych miesięcznie
Sprzątać
Aby uniknąć przyszłych opłat, usuń utworzone zasoby, takie jak Instancja notebooka Amazon SageMaker, gdy nie jest używany.
Wnioski
W tym poście sprawdziliśmy, jak można wykorzystać model Amazon Titan Multimodal Embeddings do zbudowania niedrogiego rozwiązania do klasyfikacji dokumentów w przepływie pracy IDP. Pokazaliśmy, jak utworzyć galerię obrazów znanych dokumentów i przeprowadzić wyszukiwanie podobieństw z nowymi dokumentami w celu ich klasyfikacji. Omówiliśmy także korzyści wynikające ze stosowania multimodalnego osadzania obrazów do klasyfikacji dokumentów, w tym ich zdolność do obsługi różnych typów dokumentów, skalowalność i niskie opóźnienia.
W miarę pojawiania się nowych szablonów i typów dokumentów w przepływach pracy w firmach programiści mogą odwoływać się do interfejsu API Amazon Bedrock, aby dynamicznie je wektoryzować i dołączać do swoich systemów IDP, aby szybko zwiększyć możliwości klasyfikacji dokumentów. Tworzy to niedrogą, nieskończenie skalowalną warstwę klasyfikacyjną, która może obsłużyć nawet najbardziej zróżnicowane, nieustrukturyzowane dokumenty przedsiębiorstwa.
Ogólnie rzecz biorąc, ten post zawiera plan budowy niedrogiego rozwiązania do klasyfikacji dokumentów w przepływie pracy IDP przy użyciu Amazon Titan Multimodal Embeddings.
W kolejnych krokach sprawdź Co to jest Amazonka Bedrock aby rozpocząć korzystanie z usługi. I podążaj Amazon Bedrock na blogu AWS Machine Learning aby być na bieżąco z nowymi możliwościami i przypadkami użycia Amazon Bedrock.
O autorach
 Sumit Bhati jest starszym menedżerem ds. rozwiązań dla klientów w AWS i specjalizuje się w przyspieszaniu podróży do chmury dla klientów korporacyjnych. Celem Sumit jest pomaganie klientom na każdym etapie wdrażania chmury, od przyspieszania migracji po modernizację obciążeń i ułatwianie integracji innowacyjnych praktyk.
Sumit Bhati jest starszym menedżerem ds. rozwiązań dla klientów w AWS i specjalizuje się w przyspieszaniu podróży do chmury dla klientów korporacyjnych. Celem Sumit jest pomaganie klientom na każdym etapie wdrażania chmury, od przyspieszania migracji po modernizację obciążeń i ułatwianie integracji innowacyjnych praktyk.
 Davida Girlinga jest starszym architektem rozwiązań AI/ML z ponad 20-letnim doświadczeniem w projektowaniu, prowadzeniu i rozwijaniu systemów dla przedsiębiorstw. David jest częścią specjalistycznego zespołu, który koncentruje się na pomaganiu klientom w uczeniu się, wprowadzaniu innowacji i wykorzystywaniu tych wysoce wydajnych usług wraz z danymi w konkretnych przypadkach użycia.
Davida Girlinga jest starszym architektem rozwiązań AI/ML z ponad 20-letnim doświadczeniem w projektowaniu, prowadzeniu i rozwijaniu systemów dla przedsiębiorstw. David jest częścią specjalistycznego zespołu, który koncentruje się na pomaganiu klientom w uczeniu się, wprowadzaniu innowacji i wykorzystywaniu tych wysoce wydajnych usług wraz z danymi w konkretnych przypadkach użycia.
 Ravi Avula jest starszym architektem rozwiązań w AWS skupiającym się na architekturze korporacyjnej. Ravi ma 20-letnie doświadczenie w inżynierii oprogramowania i piastował kilka stanowisk kierowniczych w inżynierii oprogramowania i architekturze oprogramowania, pracując w branży płatniczej.
Ravi Avula jest starszym architektem rozwiązań w AWS skupiającym się na architekturze korporacyjnej. Ravi ma 20-letnie doświadczenie w inżynierii oprogramowania i piastował kilka stanowisk kierowniczych w inżynierii oprogramowania i architekturze oprogramowania, pracując w branży płatniczej.
 Jerzy Belsian jest starszym architektem aplikacji chmurowych w AWS. Jego pasją jest pomaganie klientom w przyspieszaniu modernizacji i wdrażania rozwiązań chmurowych. Na swoim obecnym stanowisku George współpracuje z zespołami klientów przy opracowywaniu strategii, projektowaniu i opracowywaniu innowacyjnych, skalowalnych rozwiązań.
Jerzy Belsian jest starszym architektem aplikacji chmurowych w AWS. Jego pasją jest pomaganie klientom w przyspieszaniu modernizacji i wdrażania rozwiązań chmurowych. Na swoim obecnym stanowisku George współpracuje z zespołami klientów przy opracowywaniu strategii, projektowaniu i opracowywaniu innowacyjnych, skalowalnych rozwiązań.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- PlatoData.Network Pionowe generatywne AI. Wzmocnij się. Dostęp tutaj.
- PlatoAiStream. Inteligencja Web3. Wiedza wzmocniona. Dostęp tutaj.
- PlatonESG. Węgiel Czysta technologia, Energia, Środowisko, Słoneczny, Gospodarowanie odpadami. Dostęp tutaj.
- Platon Zdrowie. Inteligencja w zakresie biotechnologii i badań klinicznych. Dostęp tutaj.
- Źródło: https://aws.amazon.com/blogs/machine-learning/cost-effective-document-classification-using-the-amazon-titan-multimodal-embeddings-model/

