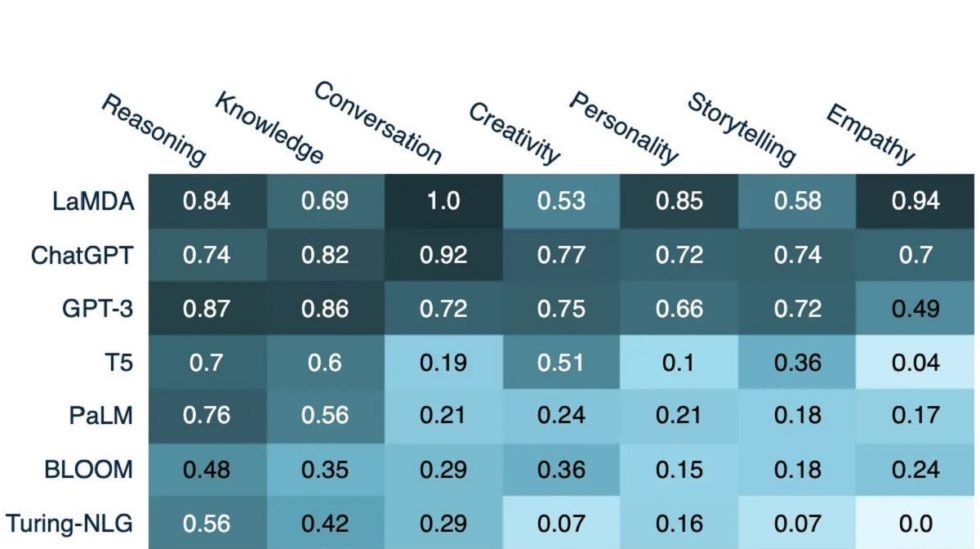
How popular LLMs score along human cognitive skills (source: semantic embedding analysis of ca. 400k AI-related online texts since 2021)
Disclaimer: This article was written without the support of ChatGPT.
In the last couple of years, Large Language Models (LLMs) such as ChatGPT, T5 and LaMDA have developed amazing skills to produce human language. We are quick to attribute intelligence to models and algorithms, but how much of this is emulation, and how much is really reminiscent of the rich language capability of humans? When confronted with the natural-sounding, confident outputs of these models, it is sometimes easy to forget that language per se is only the tip of the communication iceberg. Its full power unfolds in combination with a wide range of complex cognitive skills relating to perception, reasoning and communication. While humans acquire these skills naturally from the surrounding world as they grow, the learning inputs and signals for LLMs are rather meagre. They are forced to learn only from the surface form of language, and their success criterion is not communicative efficiency but the reproduction of high-probability linguistic patterns.
In the business context, this can lead to bad surprises when too much power is given to an LLM. Facing its own limitations, it will not admit them and rather gravitate to the other extreme — produce non-sense, toxic content or even dangerous advice with a high level of confidence. For example, a medical virtual assistant driven by GPT-3 can advise its user to kill themselves at a certain point in the conversation.[4]
Considering these risks, how can we safely benefit from the power of LLMs when integrating them in our product development? On the one hand, it is important to be aware of inherent weak points and use rigorous evaluation and probing methods to target them in specific use cases, instead of relying on happy-path interactions. On the other hand, the race is on — all major AI labs are planting their seeds to enhance LLMs with additional capabilities, and there is plenty of space for a cheerful glance into the future. In this article, we will look into the limitations of LLMs and discuss ongoing efforts to control and enhance LLM behaviour. A basic knowledge of the workings of language models is assumed — if you are a newbie, please refer to this article.
Before diving into the technology, let’s set the scene with a thought experiment — the “Octopus test” as proposed by Emily Bender — to understand how differently humans and LLMs see the world.[1]
In the skin of an octopus
Imagine that Anna and Maria are stranded on two uninhabited islands. Luckily, they have discovered two telegraphs and an underwater cable left behind by previous visitors and start communicating with each other. Their conversations are “overheard” by a quick-witted octopus who has never seen the world above water but is exceptionally good at statistical learning. He picks up the words, syntactic patterns and communication flows between the two ladies and thus masters the external form of their language without understanding how it is actually grounded in the real world. As Ludwig Wittgenstein once put it, “the limits of language are the limits of my world” — while we know today that the world models of humans are composed of much more than language, the octopus would sympathise with this statement, at least regarding his knowledge of the world above water.
If this in-depth educational content is useful for you, subscribe to our AI mailing list to be alerted when we release new material.
At some point, listening is not enough. Our octopus decides to take control, cuts the cable on Maria’s side and starts chatting with Anna. The interesting question is, when will Anna detect the change? As long as the two parties exchange social pleasantries, there is a reasonable chance that Anna will not suspect anything. Their small talk might go on as follows:
A: Hi Maria!
O: Hi Anna, how are you?
A: Thanks, I’m good, just enjoyed a coconut breakfast!
O: You are lucky, there are no coconuts on my island. What are your plans?
A: I wanted to go swimming but I am afraid there will be a storm. And you?
O: I am having my breakfast now and will do some woodwork afterwards.
A: Have a nice day, talk later!
O: Bye!
However, as their relationship deepens, their communication also grows in intensity and sophistication. Over the next sections, we will take the octopus through a couple of scenes from island life that require the mastery of common-sense knowledge, communicative context and reasoning. As we go, we will also survey approaches to incorporate additional intelligence into agents — be they fictive octopusses or LLMs — that are originally only trained from the surface form of language.
Injecting world knowledge into LLMs
One morning, Anna is planning a hunting trip and tries to forecast the weather for the day. Since the wind is coming from Maria’s direction, she asks “Maria” for a report on current weather conditions as an important piece of information. Being caught in deep waters, our octopus grows embarrassed about describing the weather conditions. Even if he had a chance to glance into the skies, he would not know what specific weather terms like “rain”, “wind”, “cloudy” etc. refer to in the real world. He desperately makes up some weather facts. Later in the day, while hunting in the woods, Anna is surprised by a dangerous thunderstorm. She attributes her failure to predict the storm to a lack of meteorological knowledge rather than a deliberate hallucination by her conversation partner.
At the surface, LLMs are able to truthfully reflect a lot of true facts about the world. However, their knowledge is limited to concepts and facts that they explicitly encountered in the training data. Even with huge training data, this knowledge cannot be complete. For example, it might miss domain-specific knowledge that is required for commercial use cases. Another important limitation, as of now, is the recency of the information. Since language models lack a notion of temporal context, they can’t work with dynamic information such as the current weather, stock prices or even today’s date.
This problem can be solved by systematically “injecting” additional knowledge into the LLM. This new input can come from various sources, such as structured external databases (e.g. FreeBase or WikiData), company-specific data sources and APIs. One possibility to inject it is via adapter networks that are “plugged in” between the LLM layers to learn the new knowledge:[2]
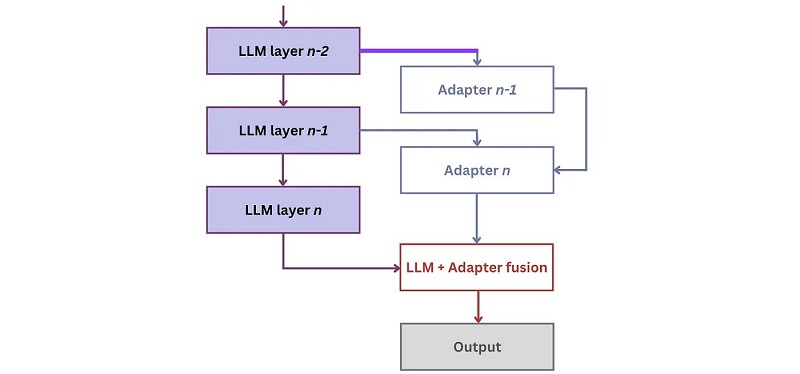
The training of this architecture happens in two steps, namely memorisation and utilisation:
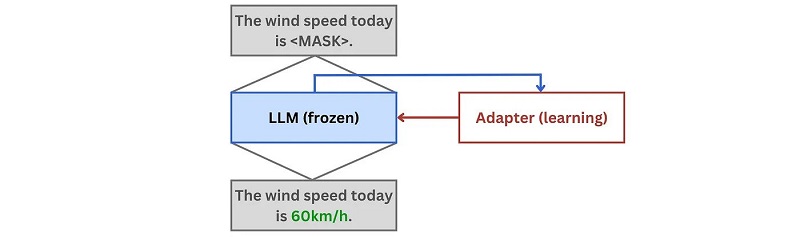
1. During memorisation, the LLM is frozen and the adapter networks learn the new facts from the knowledge base. The learning signal is provided via masked language modelling, whereby parts of the facts are hidden and the adapters learn to reproduce them:
2. During utilisation, the LM learns to leverage the facts memorised by the adapters in the respective downstream tasks. Here, in turn, the adapter networks are frozen while the weights of the model are optimised:

During inference, the hidden state that the LLM provides to the adapter is fused with the adapter’s output using a fusion function to produce the final answer.
While architecture-level knowledge injection allows for efficient modular retraining of smaller adapter networks, the modification of the architecture also requires considerable engineering skill and effort. The easier alternative is input-level injection, where the model is directly fine-tuned on the new facts (cf. [3] for an example). The downside is the expensive fine-tuning required after each change — thus, it is not suitable for dynamic knowledge sources. A complete overview over existing knowledge injection approaches can be found in this article.
Knowledge injection helps you build domain intelligence, which is becoming a key differentiator for vertical AI products. In addition, you can use it to establish traceability so the model can point a user to the original sources of information. Beyond structured knowledge injection, efforts are underway to integrate multimodal information and knowledge into LLMs. For instance, in April 2022, DeepMind introduced Flamingo, a visual language model that can seamlessly ingest text, images and video.[5] At the same time, Google is working on Socratic Models, a modular framework in which multiple pre-trained models may be composed zero-shot i.e., via multi-modal prompting, to exchange information with each other.[6]
Embracing communicative context and intent
As Anna wants to share not only her thoughts about life, but also the delicious coconuts from her island with Maria, she invents a coconut catapult. She sends Maria a detailed instruction on how she did it and asks her for instructions to optimise it. At the receiving end, the octopus falls short of a meaningful reply. Even if he had a way of constructing the catapult underwater, he does not know what words such as rope and coconut refer to, and thus can’t physically reproduce and improve the experiment. So he simply says “Cool idea, great job! I need to go hunting now, bye!”. Anna is bothered by the uncooperative response, but she also needs to go on with her daily business and forgets about the incident.
When we use language, we do so for a specific purpose, which is our communicative intent. For example, the communicative intent can be to convey information, socialise or ask someone to do something. While the first two are rather straightforward for an LLM (as long as it has seen the required information in the data), the latter is already more challenging. Let’s forget about the fact that the LLM does not have an ability to act in the real world and limit ourselves to tasks in its realm of language — writing a speech, an application letter etc. Not only does the LLM need to combine and structure the related information in a coherent way, but it also needs to set the right emotional tone in terms of soft criteria such as formality, creativity, humour etc.
Making the transition from classical language generation to recognising and responding to specific communicative intents is an important step to achieve better acceptance of user-facing NLP systems, especially in Conversational AI. One method for this is Reinforcement Learning from Human Feedback (RLHF), which has been recently implemented in ChatGPT ([7]) but has a longer history in human preference learning.[8] In a nutshell, RLHF “redirects” the learning process of the LLM from the straightforward but artificial next-token prediction task towards learning human preferences in a given communicative situation. These human preferences are directly encoded in the training data: during the annotation process, humans are presented with prompts and either write the desired response or rank a series of existing responses. The behaviour of the LLM is then optimised to reflect the human preference. Technically, RLHF is performed in three steps:
- Pre-training and fine-tuning of an initial LLM: An LLM is trained with a classical pre-training objective. Additionally, it can be fine-tuned with human-annotated data (as in the case of InstructGPT and ChatGPT).
- Reward model training: The reward model is trained based on human annotations that reflect communicative preferences in a given situation. Specifically, humans are presented with multiple outputs for a given prompt and rank these according to their suitability. The model learns to reward the higher-ranked outputs and penalise the lower-ranked outputs. The reward is a single scalar number, which makes it compatible with reinforcement learning in the next step.
- Reinforcement Learning: the policy is the initial LLM, while the reward function combines two scores for a given text input:
- The reward model score which ensures that the text responds to the communicative intent.
- A penalty for generating texts that are too far away from the initial LLM output (e. g. Kullback-Leibler divergence), making sure that the text is semantically meaningful.
The LLM is thus fine-tuned to produce useful outputs that maximise human preferences in a given communicative situation, for example using Proximal Policy Optimisation (PPO).
For a more in-depth introduction into RLHF, please check out the excellent materials by Huggingface (article and video).
The RLHF methodology had a mind-blowing success with ChatGPT, especially in the areas of conversational AI and creative content creation. In fact, it not only leads to more authentic and purposeful conversations, but can also positively “bias” the model towards ethical values while mitigating unethical, discriminatory or even dangerous outputs. However, what is often left unsaid amidst the excitement about RLHF is that, while not introducing significant technological breakthroughs, its mega-power comes from linear human annotation effort. RLHF is prohibitively expensive in terms of labelled data, the known bottleneck for all supervised and reinforcement learning endeavours. Beyond human rankings for LLM outputs, OpenAI’s data for ChatGPT also include human-written responses to prompts that are used to fine-tune the initial LLM. It is obvious that only big companies committed to AI innovation can afford the necessary budget for data labelling at this scale.
With the help of a brainy community, most bottlenecks eventually get solved. In the past, the Deep Learning community solved the data shortage with self-supervision — pre-training LLMs using next-token prediction, a learning signal that is available “for free” since it is inherent to any text. The Reinforcement Learning community is using algorithms such as Variational Autoencoders or Generative Adversarial Networks to generate synthetic data — with varying degrees of success. To make RLHF broadly accessible, we will also need to figure out a way to crowdsource communicative reward data and/or to build it in a self-supervised or automated way. One possibility is to use ranking datasets that are available “in the wild”, for example Reddit or Stackoverflow conversations where answers to questions are rated by users. Beyond simple ratings and thumbs up/down labels, some conversational AI systems also allow the user to directly edit the response to demonstrate the desired behaviour, which creates a more differentiated learning signal.
Modelling reasoning processes
Finally, Anna faces an emergency. She is pursued by an angry bear. In a panic, she grabs a couple of metal sticks and asks Maria to tell her how defend herself. Of course, the octopus has no clue what Anna means. Not only has he never faced a bear — he also doesn’t know how to behave in a bear attack and how the sticks can help Anna. Solving a task like this not only requires the ability to map accurately between words and objects in the real world, but also to reason about how these objects can be leveraged. The octopus miserably fails and Anna discovers the delusion in the lethal encounter.
Now, what if Maria was still there? Most humans can reason logically, even if there are huge individual differences in the mastery of this skill. Using reasoning, Maria could solve the task as follows:
Premise 1 (based on situation): Anna has a couple of metal sticks.
Premise 2 (based on common-sense knowledge): Bears are intimidated by noise.
Conclusion: Anna can try and use her sticks to make noise and scare the bear away.
LLMs often produce outputs with a valid reasoning chain. Yet, on closer inspection, most of this coherence is the result of pattern learning rather than a deliberate and novel combination of facts. DeepMind has been on a quest to solve causality for years, and a recent attempt is the faithful reasoning framework for question answering.[9] The architecture consists of two LLMs — one for the selection of relevant premises and another for inferring the final, conclusive answer to the question. When prompted with a question and its context, the selection LLM first picks the related statements from its data corpus and passes them to the inference LLM. The inference LLM deduces new statements and adds them to the context. This iterative reasoning process comes to an end when all statements line up into a coherent reasoning chain that provides a complete answer to the question:
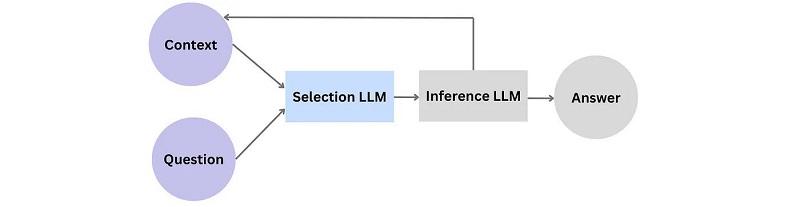
The following shows the reasoning chain for our island incident:

Beyond this general ability to reason logically, humans also access a whole toolbox of more specific reasoning skills. A classical example is mathematical calculation. LLMs can produce these calculations up to a certain level — for example, modern LLMs can confidently perform 2- or 3-digit addition. However, they start to fail systematically when complexity increases, for example when more digits are added or multiple operations need to be performed to solve a mathematical task. And “verbal” tasks formulated in natural language (for example, “I had 10 mangoes and lost 3. How many mangoes do I have left?”) are much more challenging than explicit computations (”ten minus three equals…”). While LLM performance can be improved by increasing training time, training data, and parameter sizes, using a simple calculator will still remain the more reliable alternative.
Just as children who explicitly learn the laws of mathematics and other exact sciences, LLMs can also benefit from hard-coded rules. This sounds like a case for neuro-symbolic AI — and indeed, modular systems like MRKL (pronounced “miracle”) by AI21 Labs split the workload of understanding the task, executing the computation and formulating the output result between different models.[12] MRKL stands for Modular Reasoning, Knowledge and Language and combines AI modules in a pragmatic plug-and-play fashion, switching back and forth between structured knowledge, symbolic methods and neural models. Coming back to our example, to perform mathematical calculations, an LLM is first fine-tuned to extract the formal arguments from a verbal arithmetic task (numbers, operands, parentheses). The calculation itself is then “routed” to a deterministic mathematical module, and the final the result is formatted in natural language using the output LLM.
As opposed to black-box, monolithic LLMs, reasoning add-ons create transparency and trust since they decompose the “thinking” process into individual steps. They are particularly useful for supporting complex, multi-step decision and action paths. For example, they can be used by virtual assistants that make data-driven recommendations and need to perform multiple steps of analytics and aggregation to get to a conclusion.
Conclusion and take-aways
In this article, we have provided an overview of approaches to complement the intelligence of LLMs. Let’s summarise our guidelines for maximising the benefits of LLMs and potential enhancements:
- Make them fail: Don’t be fooled by initial results — language models can produce impressive outputs when you start working with them and anyway, we humans have a bias to attribute too much intelligence to machines. Jump into the role of a mean, adversarial user and explore the weak points. Do this early on, before too much skin has been put in the game.
- Evaluation and dedicated probing: The design of your training task and evaluation procedure are of central importance. As much as possible, it should reflect the context of natural language use. Knowing the pitfalls of LLMs, dedicate your evaluation to them.
- Benefit from neuro-symbolic AI: Symbolic AI is not out — in the context of an individual business or product, setting some of your domain knowledge in stone can be an efficient approach to increase precision. It allows you to control the behaviour of the LLM where it is crucial for your business, while still unfolding its power at generating language based on wide external knowledge.
- Strive towards a flexible architecture: On the surface, LLMs sometimes feel like blackboxes. However, as we have seen, numerous approaches exist — and will become available in the future — not only for fine-tuning, but also for “tweaking” their internal behaviour and learning. Use to open-source models and solutions if you have the technical capability — this will allow you to adapt and maximise the value-add of LLMs in your product.
And even with the described enhancements, LLMs stay far behind human understanding and language use — they simply lack the unique, powerful and mysterious synergy of cultural knowledge, intuition and experience that humans build up as they go through their lifes. According to Yann LeCun, “it is clear that these models are doomed to a shallow understanding that will never approximate the full-bodied thinking we see in humans.”[11] When using AI, it is important to appreciate the wonders and complexity we find in language and cognition. Looking at smart machines from the right distance, we can differentiate between tasks that can be delegated to them and those that will remain the privilege of humans in the foreseeable future.
References
[1] Emily M. Bender and Alexander Koller. 2020. Climbing towards NLU: On Meaning, Form, and Understanding in the Age of Data. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 5185–5198, Online. Association for Computational Linguistics.
[2] Emelin, Denis & Bonadiman, Daniele & Alqahtani, Sawsan & Zhang, Yi & Mansour, Saab. (2022). Injecting Domain Knowledge in Language Models for Task-Oriented Dialogue Systems. 10.48550/arXiv.2212.08120.
[3] Fedor Moiseev et al. 2022. SKILL: Structured Knowledge Infusion for Large Language Models. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 1581–1588, Seattle, United States. Association for Computational Linguistics.
[4] Ryan Daws. 2020. Medical chatbot using OpenAI’s GPT-3 told a fake patient to kill themselves. Retrieved on January 13, 2022.
[5] DeepMind. 2022. Tackling multiple tasks with a single visual language model. Retrieved on January 13, 2022.
[6] Zeng et al. 2022. Socratic Models: Composing Zero-Shot Multimodal Reasoning with Language. Preprint.
[7] OpenAI. 2022. ChatGPT: Optimizing Language Models for Dialogue. Retrieved on January 13, 2022.
[8] Christiano et al. 2017. Deep reinforcement learning from human preferences.
[9] Creswell & Shanahan. 2022. Faithful Reasoning Using Large Language Models. DeepMind.
[10] Karpas et al. 2022. MRKL Systems: A modular, neuro-symbolic architecture that combines large language models, external knowledge sources and discrete reasoning. AI21 Labs.
[11] Jacob Browning & Yann LeCun. 2022. AI And The Limits Of Language. Retrieved on January 13, 2022.
[12] Karpas et al. 2022. MRKL Systems — A modular, neuro-symbolic architecture that combines large language models, external knowledge sources and discrete reasoning.
All images unless otherwise noted are by the author.
This article was originally published on Towards Data Science and re-published to TOPBOTS with permission from the author.
Enjoy this article? Sign up for more AI research updates.
We’ll let you know when we release more summary articles like this one.
Related
- SEO Powered Content & PR Distribution. Get Amplified Today.
- Platoblockchain. Web3 Metaverse Intelligence. Knowledge Amplified. Access Here.
- Source: https://www.topbots.com/overcoming-the-limitations-of-large-language-models/

