Conversationele kunstmatige intelligentie (AI)-assistenten zijn ontworpen om nauwkeurige, realtime antwoorden te bieden door middel van intelligente routering van vragen naar de meest geschikte AI-functies. Met AWS generatieve AI-services zoals Amazonebodemkunnen ontwikkelaars systemen creëren die gebruikersverzoeken vakkundig beheren en erop reageren. Amazon Bedrock is een volledig beheerde service die een keuze biedt uit goed presterende funderingsmodellen (FM's) van toonaangevende AI-bedrijven zoals AI21 Labs, Anthropic, Cohere, Meta, Stability AI en Amazon met behulp van één enkele API, samen met een brede reeks mogelijkheden die u nodig hebt om generatieve AI-toepassingen te bouwen met beveiliging, privacy en verantwoorde AI.
In dit bericht worden twee primaire benaderingen beoordeeld voor het ontwikkelen van AI-assistenten: het gebruik van beheerde services zoals Agenten voor Amazon Bedrock, en het gebruik van open source-technologieën zoals LangChain. We onderzoeken de voordelen en uitdagingen van elk, zodat u het meest geschikte pad voor uw behoeften kunt kiezen.
Wat is een AI-assistent?
Een AI-assistent is een intelligent systeem dat zoekopdrachten in natuurlijke taal begrijpt en samenwerkt met verschillende tools, gegevensbronnen en API's om namens de gebruiker taken uit te voeren of informatie op te halen. Effectieve AI-assistenten beschikken over de volgende belangrijke capaciteiten:
- Natuurlijke taalverwerking (NLP) en gespreksstroom
- Kennisbankintegratie en semantische zoekopdrachten om relevante informatie te begrijpen en op te halen op basis van de nuances van de gesprekscontext
- Taken uitvoeren, zoals databasequery's en aangepaste taken AWS Lambda functies
- Het afhandelen van gespecialiseerde gesprekken en gebruikersverzoeken
We demonstreren de voordelen van AI-assistenten met behulp van Internet of Things (IoT)-apparaatbeheer als voorbeeld. In dit gebruiksscenario kan AI technici helpen machines efficiënt te beheren met opdrachten die gegevens ophalen of taken automatiseren, waardoor de activiteiten in de productie worden gestroomlijnd.
Agenten voor Amazon Bedrock-aanpak
Agenten voor Amazon Bedrock stelt u in staat generatieve AI-applicaties te bouwen die taken in meerdere stappen kunnen uitvoeren binnen de systemen en gegevensbronnen van een bedrijf. Het biedt de volgende belangrijke mogelijkheden:
- Automatische promptcreatie op basis van instructies, API-details en gegevensbroninformatie, waardoor weken aan snelle engineeringinspanningen wordt bespaard
- Retrieval Augmented Generation (RAG) om agenten veilig te verbinden met de gegevensbronnen van een bedrijf en relevante antwoorden te bieden
- Orkestratie en uitvoering van taken met meerdere stappen door verzoeken op te splitsen in logische reeksen en de benodigde API's aan te roepen
- Inzicht in de redenering van de agent via een Chain of Thought (CoT)-trace, waardoor probleemoplossing en sturing van modelgedrag mogelijk wordt
- Snelle technische mogelijkheden om de automatisch gegenereerde promptsjabloon aan te passen voor verbeterde controle over agenten
U kunt Agents voor Amazon Bedrock en Kennisbanken voor Amazon Bedrock om AI-assistenten te bouwen en in te zetten voor complexe routeringsgebruiksscenario's. Ze bieden ontwikkelaars en organisaties een strategisch voordeel door het infrastructuurbeheer te vereenvoudigen, de schaalbaarheid te verbeteren, de beveiliging te verbeteren en ongedifferentieerd zwaar werk te verminderen. Ze maken ook eenvoudiger applicatielaagcode mogelijk omdat de routeringslogica, vectorisatie en geheugen volledig worden beheerd.
Overzicht oplossingen
Deze oplossing introduceert een conversatie-AI-assistent die is afgestemd op het beheer en de bewerkingen van IoT-apparaten bij gebruik van Claude v2.1 van Anthropic op Amazon Bedrock. De kernfunctionaliteit van de AI-assistent wordt bepaald door een uitgebreide reeks instructies, ook wel a systeemprompt, waarin de capaciteiten en expertisegebieden worden afgebakend. Deze begeleiding zorgt ervoor dat de AI-assistent een breed scala aan taken kan uitvoeren, van het beheren van apparaatinformatie tot het uitvoeren van operationele opdrachten.
Uitgerust met deze mogelijkheden, zoals beschreven in de systeemprompt, volgt de AI-assistent een gestructureerde workflow om gebruikersvragen te beantwoorden. De volgende afbeelding biedt een visuele weergave van deze workflow, waarbij elke stap wordt geïllustreerd, van de eerste gebruikersinteractie tot het uiteindelijke antwoord.

De workflow bestaat uit de volgende stappen:
- Het proces begint wanneer een gebruiker de assistent vraagt een taak uit te voeren; bijvoorbeeld door te vragen naar de maximale datapunten voor een specifiek IoT-apparaat
device_xxx. Deze tekstinvoer wordt vastgelegd en naar de AI-assistent gestuurd. - De AI-assistent interpreteert de tekstinvoer van de gebruiker. Het maakt gebruik van de verstrekte gespreksgeschiedenis, actiegroepen en kennisbanken om de context te begrijpen en de noodzakelijke taken te bepalen.
- Nadat de bedoeling van de gebruiker is ontleed en begrepen, definieert de AI-assistent taken. Dit is gebaseerd op de instructies die door de assistent worden geïnterpreteerd volgens de systeemprompt en de invoer van de gebruiker.
- De taken worden vervolgens uitgevoerd via een reeks API-aanroepen. Dit gebeurt met behulp van Reageer prompting, waarbij de taak wordt opgesplitst in een reeks stappen die opeenvolgend worden verwerkt:
- Voor controles van apparaatstatistieken gebruiken we de
check-device-metricsactiegroep, waarbij een API-aanroep naar Lambda-functies betrokken is die vervolgens een query uitvoeren Amazone Athene voor de gevraagde gegevens. - Voor directe apparaatacties zoals starten, stoppen of opnieuw opstarten gebruiken we de
action-on-deviceactiegroep, die een Lambda-functie aanroept. Deze functie initieert een proces dat opdrachten naar het IoT-apparaat verzendt. Voor dit bericht verzendt de Lambda-functie meldingen met behulp van Amazon eenvoudige e-mailservice (Amazone SES). - We gebruiken Knowledge Bases voor Amazon Bedrock om historische gegevens op te halen die zijn opgeslagen als insluitingen in de Amazon OpenSearch-service vectordatabase.
- Voor controles van apparaatstatistieken gebruiken we de
- Nadat de taken zijn voltooid, wordt het definitieve antwoord gegenereerd door de Amazon Bedrock FM en teruggestuurd naar de gebruiker.
- Agenten voor Amazon Bedrock slaan automatisch informatie op met behulp van een stateful sessie om hetzelfde gesprek te onderhouden. De status wordt verwijderd nadat een configureerbare time-out voor inactiviteit is verstreken.
Technisch overzicht
Het volgende diagram illustreert de architectuur voor het inzetten van een AI-assistent met Agents voor Amazon Bedrock.
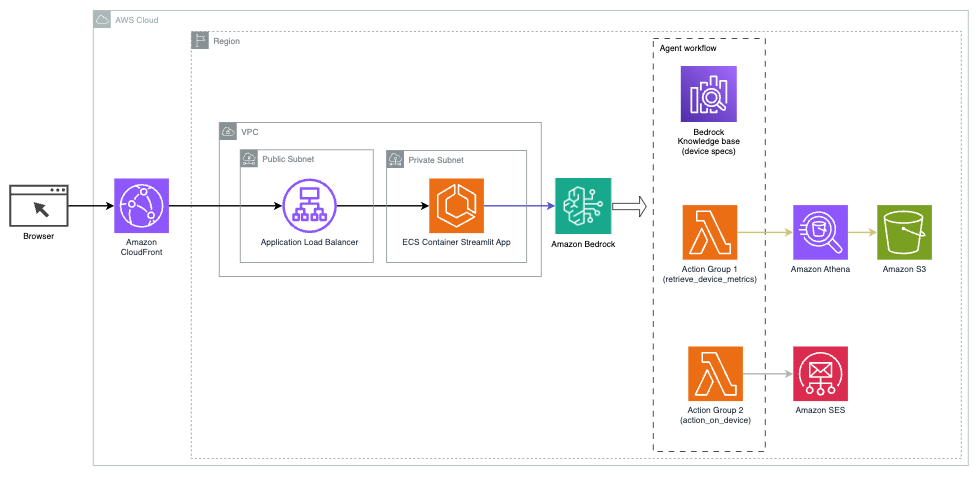
Het bestaat uit de volgende belangrijke componenten:
- Conversatie-interface – De conversatie-interface maakt gebruik van Streamlit, een open source Python-bibliotheek die het maken van aangepaste, visueel aantrekkelijke web-apps voor machine learning (ML) en data science vereenvoudigt. Het wordt gehost op Amazon Elastic Container-service (Amazon ECS) met AWS Fargate, en het is toegankelijk via een Application Load Balancer. U kunt Fargate met Amazon ECS gebruiken om uit te voeren containers zonder dat u servers, clusters of virtuele machines hoeft te beheren.
- Agenten voor Amazon Bedrock – Agents voor Amazon Bedrock voltooit de gebruikersvragen via een reeks redeneerstappen en bijbehorende acties op basis van ReAct-prompts:
- Kennisbanken voor Amazon Bedrock – Knowledge Bases voor Amazon Bedrock biedt volledig beheerde VOD om de AI-assistent toegang te geven tot uw gegevens. In ons gebruiksscenario hebben we apparaatspecificaties geüpload naar een Amazon eenvoudige opslagservice (Amazon S3) bak. Het dient als gegevensbron voor de kennisbank.
- Actie groepen – Dit zijn gedefinieerde API-schema’s die specifieke Lambda-functies aanroepen om te communiceren met IoT-apparaten en andere AWS-services.
- Antropische Claude v2.1 op Amazon Bedrock – Dit model interpreteert gebruikersvragen en orkestreert de stroom van taken.
- Amazon Titan-inbedding – Dit model dient als tekstinbeddingsmodel, waarbij tekst in natuurlijke taal (van losse woorden tot complexe documenten) wordt omgezet in numerieke vectoren. Dit maakt vectorzoekmogelijkheden mogelijk, waardoor het systeem zoekopdrachten van gebruikers semantisch kan matchen met de meest relevante kennisbankgegevens voor effectief zoeken.
De oplossing is geïntegreerd met AWS-services zoals Lambda voor het uitvoeren van code als reactie op API-aanroepen, Athena voor het bevragen van datasets, OpenSearch Service voor het zoeken in kennisbanken en Amazon S3 voor opslag. Deze services werken samen om een naadloze ervaring te bieden voor het beheer van IoT-apparaatactiviteiten via natuurlijke taalopdrachten.
Voordelen
Deze oplossing biedt de volgende voordelen:
- Implementatie complexiteit:
- Er zijn minder regels code nodig, omdat Agents for Amazon Bedrock een groot deel van de onderliggende complexiteit wegneemt, waardoor de ontwikkelingsinspanningen worden verminderd
- Het beheer van vectordatabases zoals OpenSearch Service is vereenvoudigd, omdat Knowledge Bases voor Amazon Bedrock vectorisatie en opslag afhandelt
- Integratie met verschillende AWS-diensten wordt meer gestroomlijnd via vooraf gedefinieerde actiegroepen
- Ervaring van ontwikkelaars:
- De Amazon Bedrock-console biedt een gebruiksvriendelijke interface voor snelle ontwikkeling, testen en analyse van de hoofdoorzaak (RCA), waardoor de algehele ontwikkelaarservaring wordt verbeterd
- Wendbaarheid en flexibiliteit:
- Agents voor Amazon Bedrock zorgt voor naadloze upgrades naar nieuwere FM's (zoals Claude 3.0) wanneer deze beschikbaar komen, zodat uw oplossing up-to-date blijft met de nieuwste ontwikkelingen
- Servicequota en -beperkingen worden beheerd door AWS, waardoor de overhead van het monitoren en schalen van de infrastructuur wordt verminderd
- Veiligheid:
- Amazon Bedrock is een volledig beheerde service die voldoet aan de strenge beveiligings- en compliancenormen van AWS, waardoor de beveiligingsbeoordelingen van de organisatie mogelijk worden vereenvoudigd
Hoewel Agents for Amazon Bedrock een gestroomlijnde en beheerde oplossing biedt voor het bouwen van conversatie-AI-applicaties, geven sommige organisaties misschien de voorkeur aan een open source-aanpak. In dergelijke gevallen kunt u raamwerken zoals LangChain gebruiken, die we in de volgende sectie bespreken.
LangChain dynamische routeringsaanpak
LangChain is een open source-framework dat het bouwen van conversationele AI vereenvoudigt door de integratie van grote taalmodellen (LLM's) en dynamische routeringsmogelijkheden mogelijk te maken. Met LangChain Expression Language (LCEL) kunnen ontwikkelaars de routing, waarmee u niet-deterministische ketens kunt creëren waarbij de uitvoer van een vorige stap de volgende stap definieert. Routing helpt structuur en consistentie te bieden in interacties met LLM's.
Voor dit bericht gebruiken we hetzelfde voorbeeld als de AI-assistent voor IoT-apparaatbeheer. Het belangrijkste verschil is echter dat we de systeemprompts afzonderlijk moeten behandelen en elke keten als een afzonderlijke entiteit moeten behandelen. De routeringsketen bepaalt de bestemmingsketen op basis van de invoer van de gebruiker. De beslissing wordt genomen met de steun van een LLM door de systeemprompt, chatgeschiedenis en de vraag van de gebruiker door te geven.
Overzicht oplossingen
Het volgende diagram illustreert de workflow voor dynamische routeringsoplossingen.

De workflow bestaat uit de volgende stappen:
- De gebruiker stelt een vraag aan de AI-assistent. Bijvoorbeeld: 'Wat zijn de maximale statistieken voor apparaat 1009?'
- Een LLM evalueert elke vraag samen met de chatgeschiedenis van dezelfde sessie om de aard ervan te bepalen en onder welk onderwerp deze valt (zoals SQL, actie, zoeken of SME). De LLM classificeert de invoer en de LCEL-routeringsketen neemt die invoer.
- De routerketen selecteert de bestemmingsketen op basis van de invoer en de LLM krijgt de volgende systeemprompt:
De LLM evalueert de vraag van de gebruiker samen met de chatgeschiedenis om de aard van de vraag te bepalen en onder welk onderwerp deze valt. De LLM classificeert vervolgens de invoer en voert een JSON-antwoord uit in het volgende formaat:
De routerketen gebruikt dit JSON-antwoord om de corresponderende bestemmingsketen aan te roepen. Er zijn vier onderwerpspecifieke bestemmingsketens, elk met een eigen systeemprompt:
- SQL-gerelateerde zoekopdrachten worden voor database-interacties naar de SQL-bestemmingsketen verzonden. U kunt LCEL gebruiken om het SQL-keten.
- Actiegerichte vragen doen een beroep op de aangepaste Lambda-bestemmingsketen voor lopende activiteiten. Met LCEL kunt u uw eigen definitie definiëren aangepaste functie; in ons geval is het een functie om een vooraf gedefinieerde Lambda-functie uit te voeren om een e-mail te verzenden met een geparseerde apparaat-ID. Een voorbeeld van een gebruikersinvoer kan zijn: 'Apparaat 1009 afsluiten'.
- Zoekgerichte onderzoeken gaan naar de VOD bestemmingsketen voor het ophalen van informatie.
- MKB-gerelateerde vragen gaan naar de MKB-/expertbestemmingsketen voor gespecialiseerde inzichten.
- Elke bestemmingsketen neemt de invoer en voert de noodzakelijke modellen of functies uit:
- De SQL-keten gebruikt Athena voor het uitvoeren van query's.
- De RAG-keten gebruikt OpenSearch Service voor semantisch zoeken.
- De aangepaste Lambda-keten voert Lambda-functies uit voor acties.
- De MKB/expertketen levert inzichten op basis van het Amazon Bedrock-model.
- De antwoorden van elke bestemmingsketen worden door de LLM geformuleerd in samenhangende inzichten. Deze inzichten worden vervolgens aan de gebruiker geleverd, waardoor de querycyclus wordt voltooid.
- Gebruikersinvoer en -reacties worden opgeslagen in Amazon DynamoDB om context te bieden aan de LLM voor de huidige sessie en uit eerdere interacties. De duur van de persistente informatie in DynamoDB wordt bepaald door de applicatie.
Technisch overzicht
Het volgende diagram illustreert de architectuur van de dynamische routeringsoplossing LangChain.
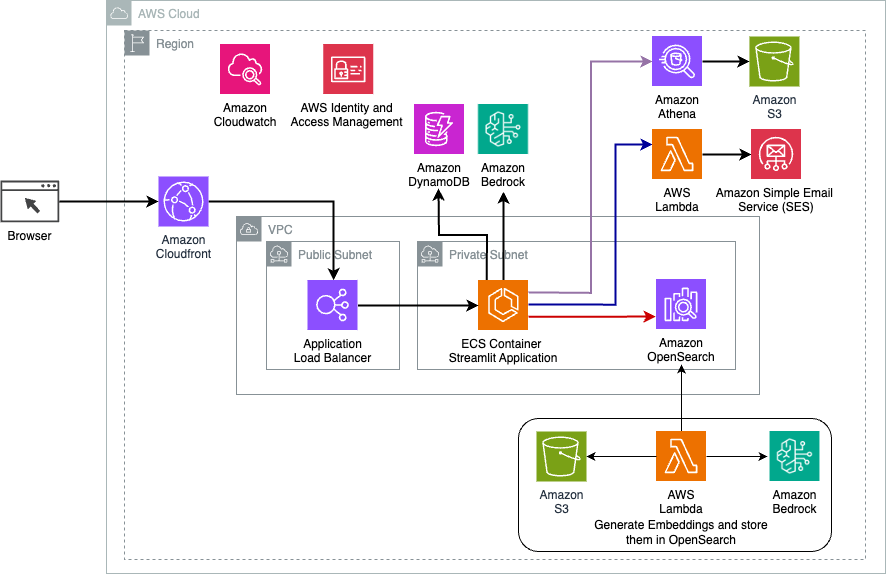
De webapplicatie is gebouwd op Streamlit, gehost op Amazon ECS met Fargate, en is toegankelijk via een Application Load Balancer. We gebruiken Claude v2.1 van Anthropic op Amazon Bedrock als onze LLM. De webapplicatie communiceert met het model met behulp van LangChain-bibliotheken. Het werkt ook samen met verschillende andere AWS-services, zoals OpenSearch Service, Athena en DynamoDB om aan de behoeften van eindgebruikers te voldoen.
Voordelen
Deze oplossing biedt de volgende voordelen:
- Implementatie complexiteit:
- Hoewel het meer code en aangepaste ontwikkeling vereist, biedt LangChain meer flexibiliteit en controle over de routeringslogica en integratie met verschillende componenten.
- Het beheren van vectordatabases zoals OpenSearch Service vereist extra installatie- en configuratie-inspanningen. Het vectorisatieproces wordt in code geïmplementeerd.
- Integratie met AWS-services kan meer aangepaste code en configuratie met zich meebrengen.
- Ervaring van ontwikkelaars:
- De op Python gebaseerde aanpak en uitgebreide documentatie van LangChain kunnen aantrekkelijk zijn voor ontwikkelaars die al bekend zijn met Python en open source-tools.
- Snelle ontwikkeling en foutopsporing vergen mogelijk meer handmatige inspanning vergeleken met het gebruik van de Amazon Bedrock-console.
- Wendbaarheid en flexibiliteit:
- LangChain ondersteunt een breed scala aan LLM's, waardoor u kunt schakelen tussen verschillende modellen of aanbieders, wat de flexibiliteit bevordert.
- Het open source-karakter van LangChain maakt door de gemeenschap aangestuurde verbeteringen en aanpassingen mogelijk.
- Veiligheid:
- Als open source-framework vereist LangChain mogelijk strengere beveiligingsbeoordelingen en doorlichting binnen organisaties, wat mogelijk extra overhead met zich meebrengt.
Conclusie
Conversationele AI-assistenten zijn transformatieve hulpmiddelen voor het stroomlijnen van activiteiten en het verbeteren van gebruikerservaringen. Dit bericht onderzocht twee krachtige benaderingen met behulp van AWS-services: de beheerde agenten voor Amazon Bedrock en de flexibele, open source dynamische routing van LangChain. De keuze tussen deze benaderingen hangt af van de eisen van uw organisatie, de ontwikkelingsvoorkeuren en het gewenste niveau van maatwerk. Ongeacht het pad dat u kiest, stelt AWS u in staat intelligente AI-assistenten te creëren die een revolutie teweegbrengen in de zakelijke en klantinteracties
Vind de oplossingscode en implementatiemiddelen in onze GitHub-repository, waar u de gedetailleerde stappen voor elke conversationele AI-aanpak kunt volgen.
Over de auteurs
 Ameer Hakme is een AWS Solutions Architect gevestigd in Pennsylvania. Hij werkt samen met Independent Software Vendors (ISV's) in de regio Noordoost en assisteert hen bij het ontwerpen en bouwen van schaalbare en moderne platforms op de AWS Cloud. Ameer is een expert op het gebied van AI/ML en generatieve AI en helpt klanten het potentieel van deze geavanceerde technologieën te ontsluiten. In zijn vrije tijd rijdt hij graag op zijn motor en brengt hij graag quality time door met zijn gezin.
Ameer Hakme is een AWS Solutions Architect gevestigd in Pennsylvania. Hij werkt samen met Independent Software Vendors (ISV's) in de regio Noordoost en assisteert hen bij het ontwerpen en bouwen van schaalbare en moderne platforms op de AWS Cloud. Ameer is een expert op het gebied van AI/ML en generatieve AI en helpt klanten het potentieel van deze geavanceerde technologieën te ontsluiten. In zijn vrije tijd rijdt hij graag op zijn motor en brengt hij graag quality time door met zijn gezin.
 Sharon Li is een AI/ML Solutions Architect bij Amazon Web Services gevestigd in Boston, met een passie voor het ontwerpen en bouwen van generatieve AI-applicaties op AWS. Ze werkt samen met klanten om AWS AI/ML-services in te zetten voor innovatieve oplossingen.
Sharon Li is een AI/ML Solutions Architect bij Amazon Web Services gevestigd in Boston, met een passie voor het ontwerpen en bouwen van generatieve AI-applicaties op AWS. Ze werkt samen met klanten om AWS AI/ML-services in te zetten voor innovatieve oplossingen.
 Kawsar Kamal is een senior solutions architect bij Amazon Web Services met meer dan 15 jaar ervaring in de infrastructuurautomatisering en beveiligingsruimte. Hij helpt klanten bij het ontwerpen en bouwen van schaalbare DevSecOps- en AI/ML-oplossingen in de cloud.
Kawsar Kamal is een senior solutions architect bij Amazon Web Services met meer dan 15 jaar ervaring in de infrastructuurautomatisering en beveiligingsruimte. Hij helpt klanten bij het ontwerpen en bouwen van schaalbare DevSecOps- en AI/ML-oplossingen in de cloud.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoData.Network Verticale generatieve AI. Versterk jezelf. Toegang hier.
- PlatoAiStream. Web3-intelligentie. Kennis versterkt. Toegang hier.
- PlatoESG. carbon, CleanTech, Energie, Milieu, Zonne, Afvalbeheer. Toegang hier.
- Plato Gezondheid. Intelligentie op het gebied van biotech en klinische proeven. Toegang hier.
- Bron: https://aws.amazon.com/blogs/machine-learning/enhance-conversational-ai-with-advanced-routing-techniques-with-amazon-bedrock/

