Chatbot Arena は、カリフォルニア大学バークレー校、カリフォルニア大学サンディエゴ校、カーネギー メロン大学の学生と教員間のコラボレーションをサポートするオープン モデルに特化した研究組織である Large Model Systems Orgnament (LMSYS ORG) によって運営されています。このプラットフォームは、ラベルのない 2 つの言語モデルをユーザーに提示し、適合すると思われる基準に基づいてどちらのパフォーマンスが優れているかを評価するよう求めます。
参加者の異なる個人的な好みに基づいた主観的なアプローチが、Chatbot Arena を他の AI ベンチマークと区別するものです。モデルトレーナーは、定量的なベンチマークの場合のように、アルゴリズムに勝つようにモデルを調整することで「不正行為」をすることはできません。 Chatbot Arena は、人々が単に好むものを測定することにより、AI 研究者にとって価値のある定性的なリソースとなります。
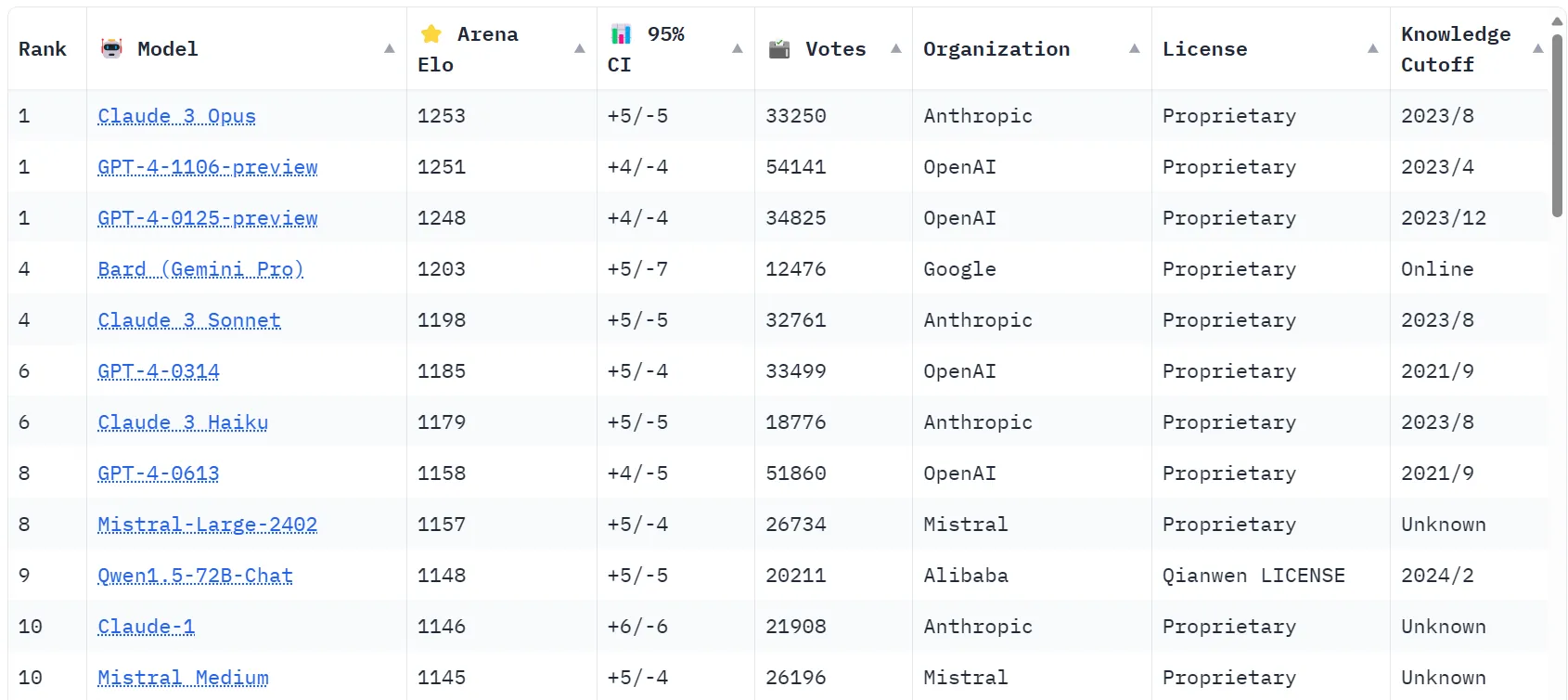
プラットフォームはユーザーのフィードバックを収集し、それを実行します。 ブラッドリー・テリー統計モデル 直接的な競合において、特定のモデルが他のモデルよりも優れたパフォーマンスを発揮する可能性を予測するため。 このアプローチ Elo レーティング推定値の信頼区間範囲を含む包括的な統計の生成を可能にします。これは、チェスプレイヤーのスキルを測定するために使用されるのと同じ手法です。
Chatbot Arena によってランク付けされた上位 10 の LLM。画像: 抱き合う顔
Claude 3 Opus のトップへの上昇は、リーダーボードにおける唯一の重要な進歩ではありません。 Claude 3 Sonnet (無料で利用できる中型モデル) と Claude 3 Haiku (小型で高速なモデル) は、同じく Anthropic によって開発され、現在それぞれ 4 位と 6 位に位置しています。